论文分享:热力学仿真辅助随机森林 (TSRF) 在故障诊断中的应用
这是对发表在Measurement的Thermodynamic simulation-assisted random forest: Towards explainable fault diagnosis of combustion chamber components of marine diesel engines的解读。在大型船用柴油机等复杂设备的故障诊断中,由于实际故障样本获取困难,且纯数据驱动模型(如深度学习)往往面临可解释性不足的问题。针对这些挑战,该论文提出了一种热力学仿真辅助的随机森林(TSRF)框架。该方法的主要思路是:首先通过一维热力学仿真构建包含多种故障状态的样本集,缓解数据稀缺问题;随后利用 Tree SHAP 方法进行特征降维;最后结合随机森林进行故障分类,并通过 SHAP 值对模型的决策过程进行解释。本文将对该论文的核心技术流程和实验方法进行客观的梳理和记录,供大家交流参考。
1 研究背景与待解决问题
船用柴油机作为船舶动力系统中的核心设备,其燃烧室组件在高温、高压和复杂工况下长期运行,容易出现裂纹、烧蚀、积碳等多种故障形态。一旦相关部件发生异常,不仅会影响发动机的工作效率,还可能带来安全隐患。因此,对燃烧室关键组件进行可靠的故障诊断,对于保障船舶动力系统的稳定运行具有重要意义。
在实际工业环境中,故障诊断方法的应用仍然面临一些现实困难。工业现场中能够获取的故障数据往往数量有限,而且不同类型故障的样本分布极不均衡,构建覆盖全面的故障数据集难度较大。这种数据稀缺问题在一定程度上限制了数据驱动方法的训练效果,也影响了模型在实际场景中的泛化能力。
与此同时,近年来广泛应用的机器学习与深度学习方法虽然在模式识别方面表现出较强能力,但模型内部决策过程通常缺乏直观的物理解释。在安全性要求较高的工业系统中,这种“黑箱”特性往往降低了模型结果的可信度,使其在工程应用中的推广受到一定限制。
针对上述问题,越来越多的研究开始尝试将基于机理的物理模型与数据驱动方法相结合。通过引入热力学仿真等物理建模手段,可以在一定程度上弥补真实故障样本不足的问题,同时为模型结果提供更具物理意义的解释。基于这一思路,本文尝试将物理模型与数据模型结合起来,在样本生成与模型可解释性方面开展探索,以期为船用柴油机燃烧室组件的故障诊断提供一种更加可靠的技术路径。
2. 核心方法论:TSRF 框架拆解
论文提出了一种名为热力学仿真辅助随机森林(Thermodynamic Simulation-assisted Random Forest, TSRF)的框架。该框架的整体逻辑是利用物理仿真生成数据来弥补实际故障样本的不足,随后利用 SHAP 值进行特征降维和模型解释。下图1为TSRF的主要技术框架。
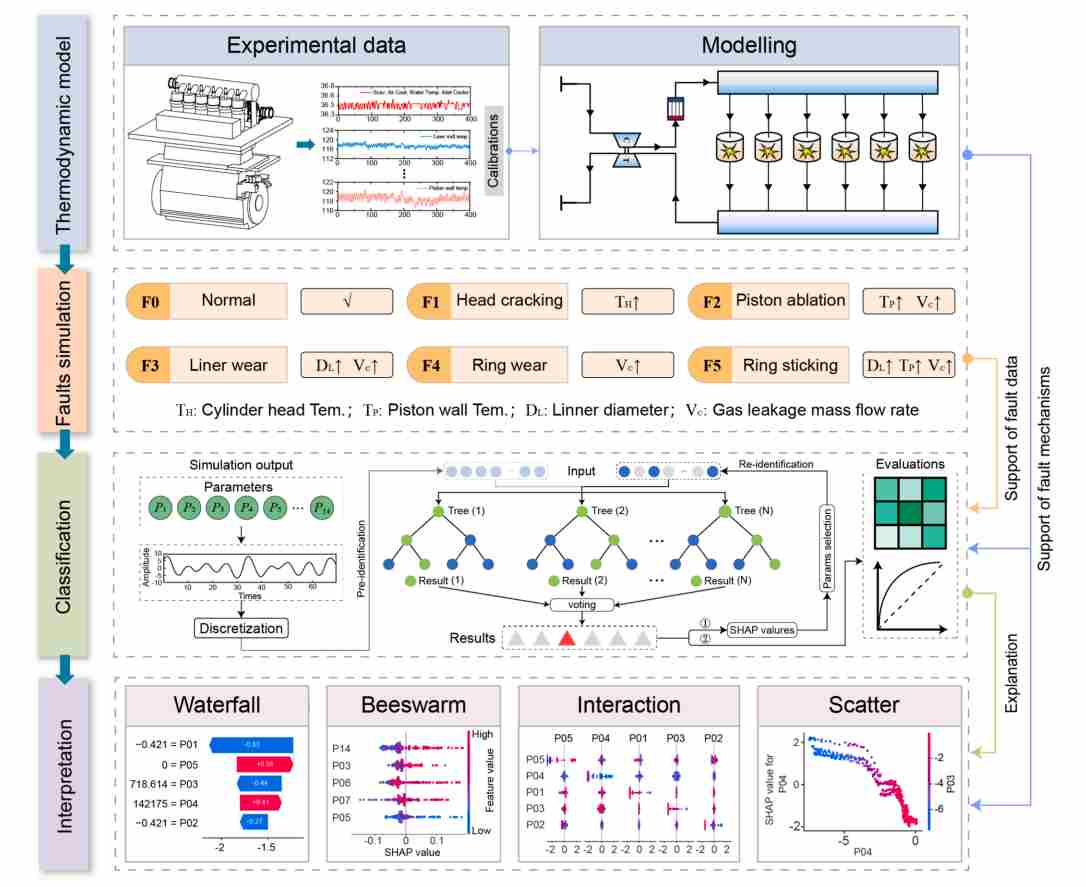
图1 热力学仿真辅助随机森林TSRF的主要技术框架
2.1 一维热力学仿真与故障样本生成
针对实际船舶运行中故障数据难以收集的问题,论文采用了一维热力学仿真技术来生成数据集。
(1)模型构建与校准:首先,作者基于船用柴油机的物理结构建立了一维热力学模型。为了保证仿真数据的可靠性,模型使用了从某造船设备制造商的主机传感器系统(数据收集模块 DCM)获取的实际测试数据进行标定。
(2)故障模拟机制:在模型校准后,研究重点转向了故障状态的模拟。论文选取了燃烧室组件的5种典型故障:气缸盖开裂 (F1)、活塞烧蚀 (F2)、气缸套磨损 (F3)、活塞环磨损 (F4) 和活塞环黏着 (F5)。模拟的方法是通过微调特定的核心系统参数来实现的。例如,通过调节漏气质量流量(Blow-by mass flow)来模拟活塞环磨损,通过调节气缸盖表面温度来模拟气缸盖开裂。
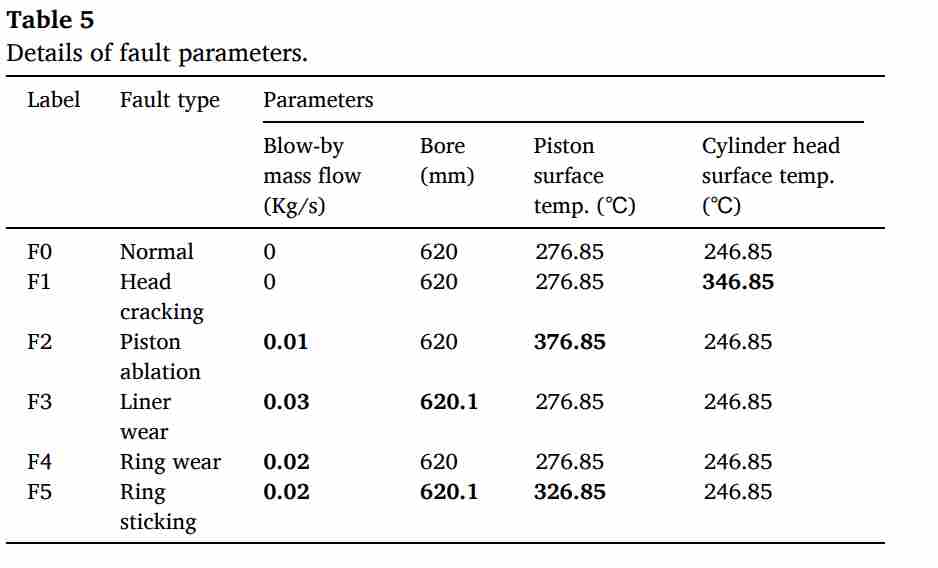
(3)数据集输出:通过上述仿真,模型输出了包含14个关键热力学参数(如气缸压力、活塞壁热流、排气温度等)的时间序列数据。这些数据随后经过 min-max 归一化处理,按 7:3 的比例划分为训练集和测试集。
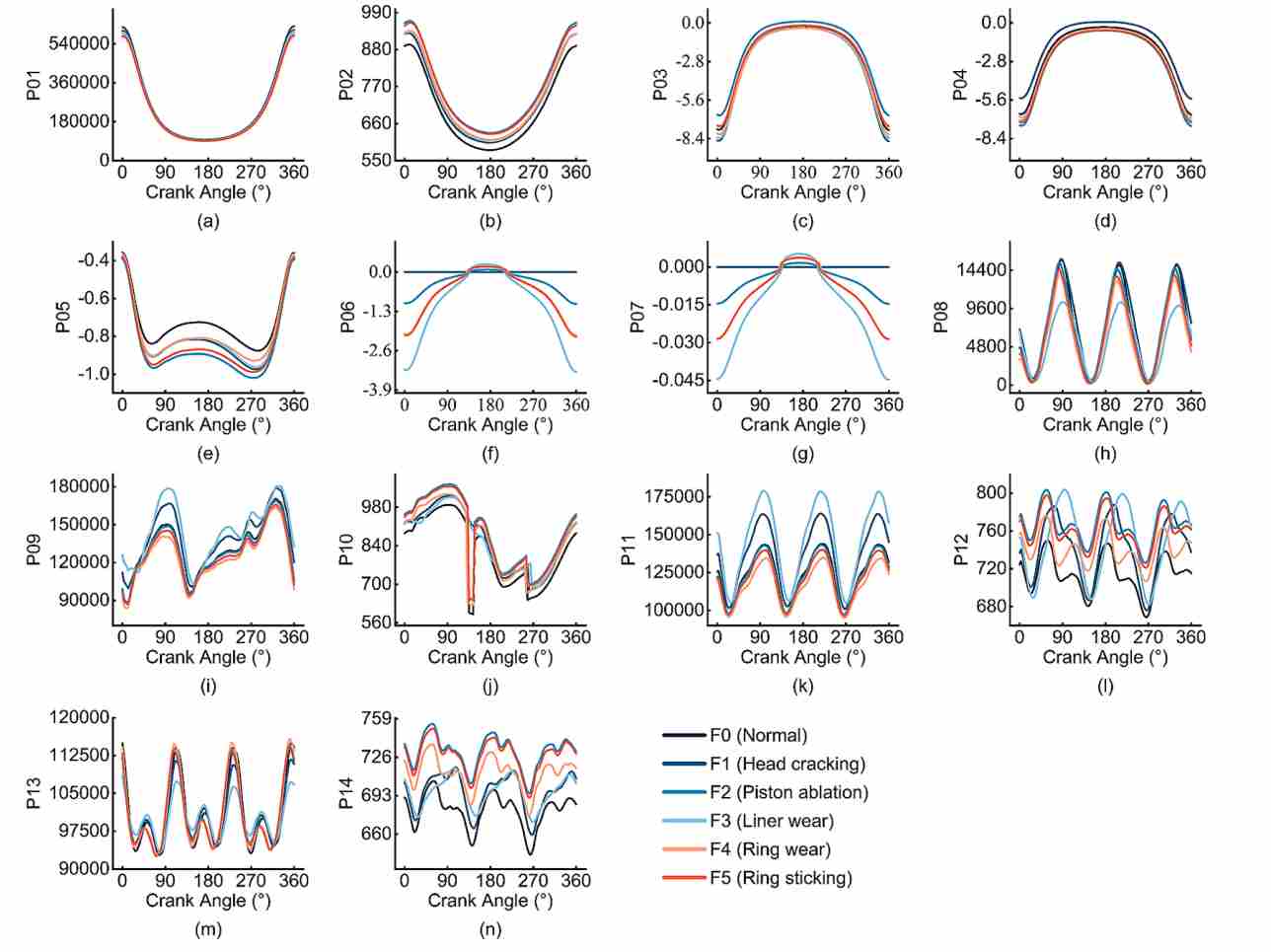
图2故障模拟结果图
2.2 基于 Tree SHAP 的特征选择 (降维)
柴油机包含众多热力学参数,如果全部输入模型,不仅会增加计算负担,还可能引入噪声干扰。因此,论文采用了基于 SHAP(SHapley Additive exPlanations)值的方法进行特征降维。
(1)SHAP 值计算:SHAP 方法的核心思想是将模型的预测值分解为各个输入特征的边际贡献。论文中特别指出,由于后续采用的是基于树的分类模型(随机森林),因此使用了优化的 Tree SHAP 算法。该算法利用树模型的层次结构,仅沿特定决策路径计算边际贡献,大幅降低了传统 SHAP 方法指数级的计算复杂度。
(2)特征筛选过程:首先,将包含14个参数的初始数据集输入到一个初步的随机森林模型中。随后,计算每个参数的 SHAP 值,评估其对模型预测结果的贡献度。
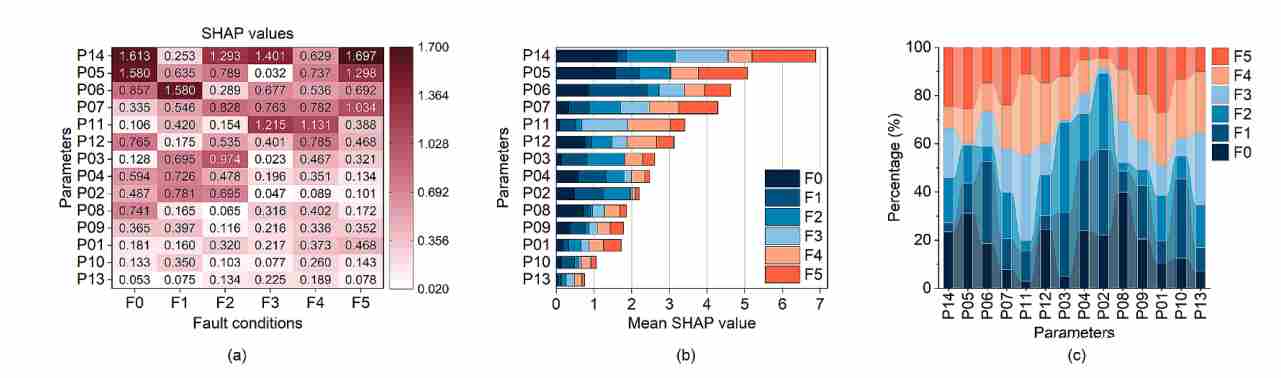
图3 由 SHAP 计算的各个特征的重要性排序图
(3)筛选结果与对比:根据重要性排序,论文最终从14个参数中筛选出了累计贡献率最高的8个核心参数(如涡轮增压器后排气温度 P14、气缸套壁热流 P05 等)。值得一提的是,论文还将 SHAP 方法与传统的卡方检验(Chi-Square Test)、递归特征消除(RFE)和基尼系数(Gini index)进行了量化对比,验证了 SHAP 在特征选择上的有效性。下图中橙色代表被选中的高贡献参数,通过直观对比可以发现,基于 SHAP 选出的特征子集与其他传统统计学方法存在显著差异,更倾向于挑选出具备物理耦合意义的核心参数。

图4 不同特征选择方法的最优子集对比图
2.3 故障分类模型构建
在确定了最优特征子集后,论文选择了随机森林(Random Forest, RF)作为最终的故障分类器。
(1)模型选择依据:论文指出,随机森林作为一种集成学习方法,在处理样本量有限的多分类问题时具有一定优势,且对数据预处理的要求相对较低,适合处理包含多种热力学参数的复杂故障场景。
(2)参数离散化:由于热力学参数(如温度、压力)是连续变量,论文简要描述了决策树在处理这些连续变量时所采用的离散化过程(基于信息增益或基尼系数寻找最优划分点),为后续的模型训练奠定基础。
3. 实验验证:多模型对比与性能剖析
在看完其核心的 TSRF(热力学仿真辅助随机森林)框架后,我比较关注的是该模型在实际分类任务中的具体表现,以及 SHAP 降维到底带来了多大的增益。
论文的实验设置比较标准:仿真生成的数据集按 70% 训练、30% 测试的比例划分,并通过五折交叉验证与网格搜索确定超参数。客观来说,对于这种有限样本(Limited sample size)的工业故障诊断场景,这种设置是合理且稳妥的。

从论文提供的结果数据来看,在未进行特征筛选的原始数据集上,各模型的表现存在明显差异。上表清晰对比了 KNN、SVM 和 RF 在原始数据集和基于 SHAP 优选特征集上的各项指标。例如,KNN 在识别某些故障类型时准确率偏低,这可能是因为它对高维空间中复杂的非线性关系不够敏感;而 SVM 虽然整体略好,但在识别 F1(缸盖开裂)和 F4(活塞环磨损)时也出现了明显的误判。
然而,当模型应用了基于 SHAP 值筛选出的 8 个核心参数子集后,各项指标均有显著提升。其中,随机森林(RF)模型的平均准确率达到了99.07%,召回率和 F1-score 也保持在极高水平。这一数据对比直观地证明了,剔除冗余参数对于降低模型噪声干扰、提升分类精度的必要性。
为了更深入地分析模型的决策边界,论文给出了三种模型在不同数据集上的混淆矩阵。
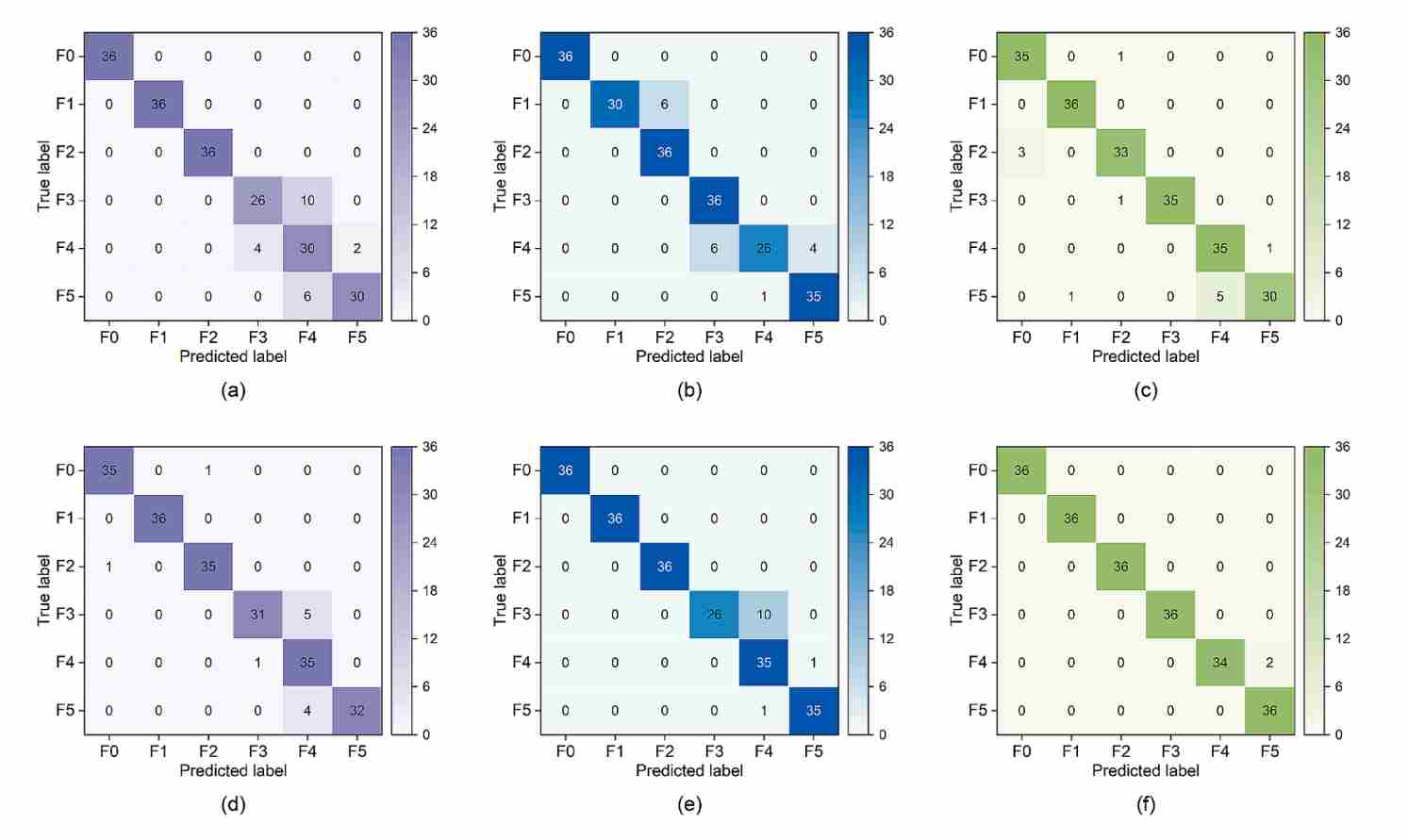 图5原始数据集混淆矩阵图以及最优子集混淆矩阵
图5原始数据集混淆矩阵图以及最优子集混淆矩阵
仔细观察上图(f)中 RF 模型的混淆矩阵,我注意到了一个非常有意思的细节:尽管 RF 取得了最佳的整体性能,但在区分 F4(活塞环磨损) 和 F5(活塞环黏着) 这两种故障时,依然存在极少量的混淆。
起初我有些疑惑,但在结合柴油机热力学原理后,这个现象就说得通了。因为从物理机制上看,这两种故障的最终宏观表现高度相似——它们都会破坏气缸的密封性,导致漏气(Blow-by)加剧以及异常的摩擦发热。换言之,这两种故障在特征空间中的分布距离本身就极近。模型在此处的“微小误差”,恰恰反映了仿真数据在物理逻辑上的真实性,而不是模型本身的过拟合。
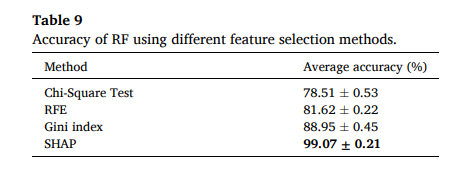
最后,作者做了一组很有说服力的消融实验(如表9)。如果将特征选择方法替换为卡方检验(Chi-Square)、递归特征消除(RFE)或基尼系数(Gini index),RF 模型的准确率分别骤降至 78.51%、81.62% 和 88.95%。
这个对比结果让我印象深刻。它说明,对于柴油机这种内部热力学参数存在严重交叉耦合(Cross-coupling)的复杂系统,仅仅依靠简单的统计学过滤是不够的。SHAP 方法之所以能拿到 99.07% 的精度,核心原因在于它能够有效地量化参数间的非线性交互作用,从而挑出真正具备物理鉴别力的特征子集。这为同类复杂装备的特征工程提供了一个非常好的参考范式。
4. 窥进“黑盒”:基于热力学机理的模型解释
以往的数据驱动故障诊断模型,往往止步于输出混淆矩阵。而本文作者引入了双视角的 SHAP 可解释性分析,试图将随机森林的黑盒决策逻辑与柴油机的热力学物理机理进行交叉验证。这对于安全性要求极高的船舶工业来说,具有很强的现实意义。
论文以 F4(活塞环磨损) 作为典型案例,从局部(单个样本)和全局(整体分布)两个维度进行了深度剖析。
4.1 局部视角:单一样本的归因推演
作者首先利用瀑布图(Waterfall Plot)展示了模型在面对一个具体的 F4 故障样本时,是如何“思考”并得出结论的。
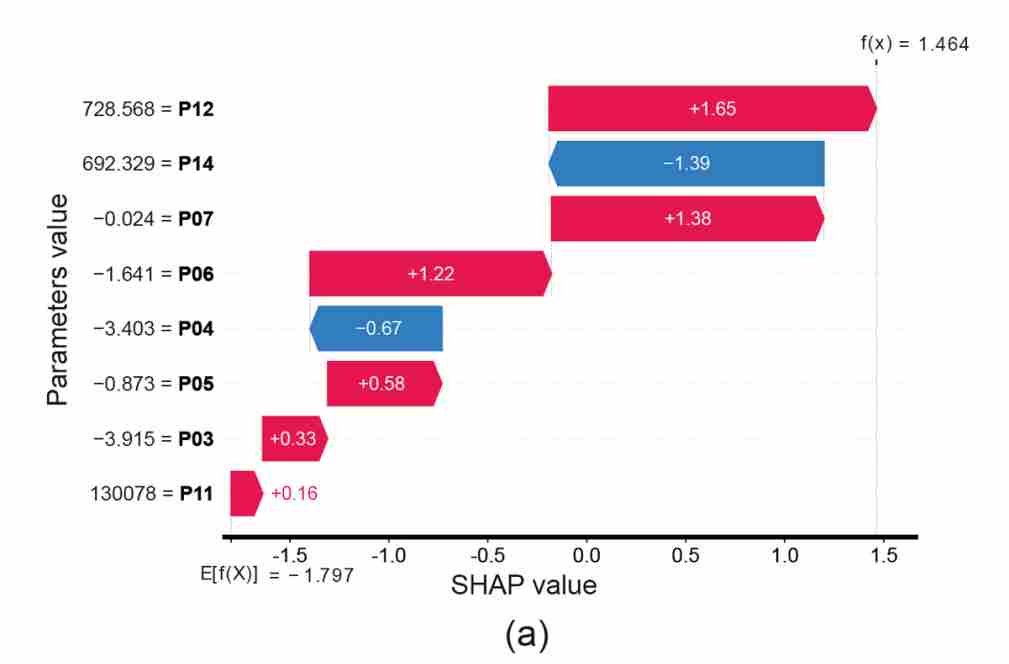
图6 各个热力学参数的瀑布图
从瀑布图中可以清晰地看到,参数 P06(漏气热流量)、P07(漏气质量流量)、P12(涡轮增压器前排气温度)等特征的值,直接影响了模型的最终预测方向。
论文中提到一个很有意思的细节验证:在某一个特定的 F4 样本中,P14(涡轮增压器后排气温度)和 P04(气缸盖壁热流)的值异常偏低,这给模型预测带来了负面贡献(蓝色条带)。作者结合先验物理知识进行了解释:活塞环磨损理应加剧漏气(Blow-by),进而导致 P14 和 P04 升高。该样本中这两项数值的异常降低违背了这一常理,从而降低了模型在此处的置信度。这种“算法捕捉到了违背物理常理的异常”的现象,非常直观地展示了 SHAP 分析在样本级 Debug 上的潜力。
4.2 全局视角:参数重要性与物理耦合关系
局部解释验证了单一样本,而蜂群图(Beeswarm Plot)和依赖图(Dependence Plot)则揭示了模型在整个 F4 故障状态下的全局判别逻辑。
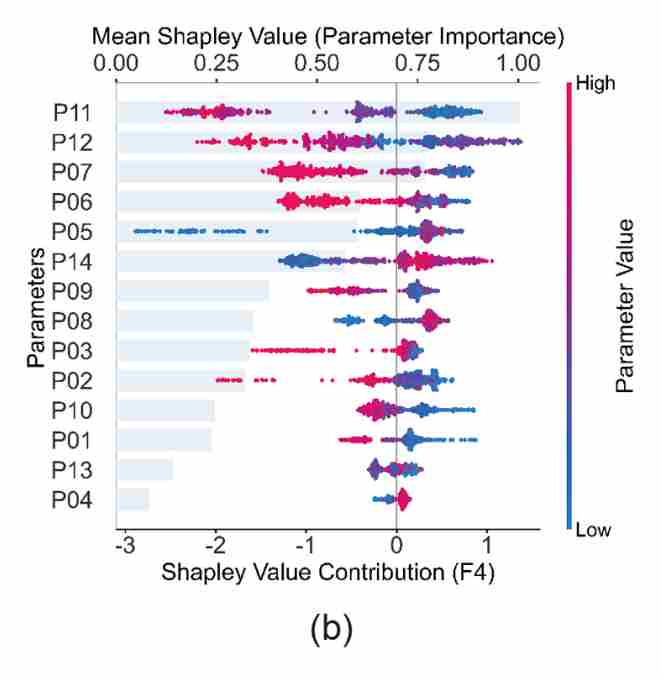
图7 蜂群图
该蜂群图的横轴代表 SHAP 值(对预测 F4 的影响),纵轴是参数重要性排名,颜色代表特征本身的数值大小。观察它可以发现,P11(涡轮前排气压力)、P12(涡轮前排气温度)、P07(漏气质量流量)和 P06(漏气热流量)的数值偏低(蓝色点聚集区),是驱使模型做出 F4 故障判定的最强动力。
为了进一步挖掘这些关键参数之间的隐式联系,作者计算了 SHAP 交互值(Interaction values)。
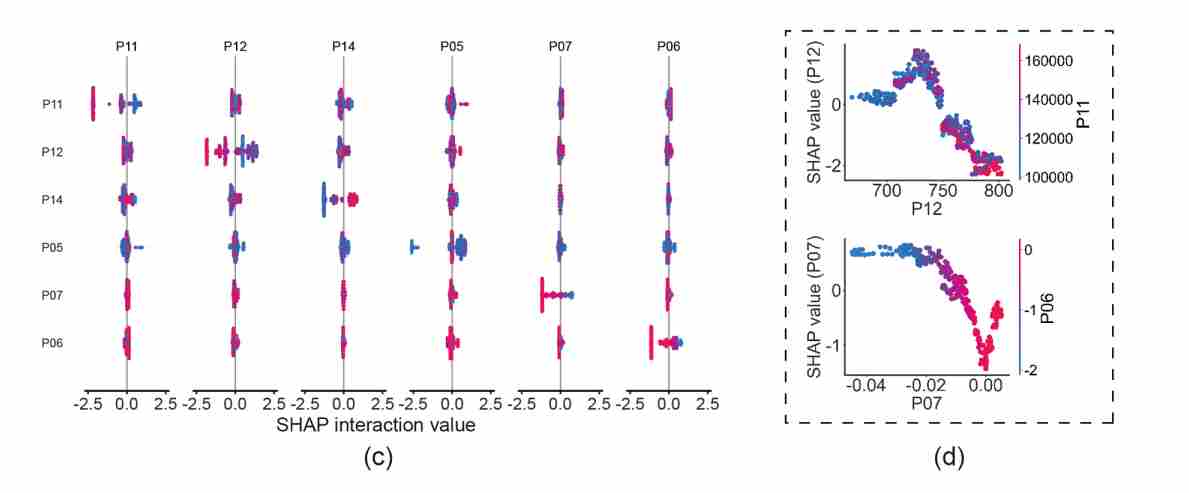
图8 参数间的非线性耦合关系图
在这组依赖图中,我注意到一个极其符合经典热力学定律的结论:
(1)P11 与 P12 的正相关互作:在所有的健康状态中,发生 F4 故障时 P11 的值跌至最低。由于压力(P11)与温度(P12)的正相关物理属性,P11 的降低不可避免地导致了 P12 的降低。SHAP 交互图精准地捕捉到了这种正向的耦合关系。
(2)P06 与 P07 的指示作用:虽然直觉上漏气加剧可能让人联想到流量升高,但论文模型分析表明,在活塞环磨损(F4)的特定工况下,漏气热流量(P06)和漏气质量流量(P07)实际上与漏气严重程度呈现负相关。因此,当这两个参数的值显著偏低时,它们成为了模型精准识别和判定 F4 故障的强效指标。
读到这里,可以说作者利用 SHAP 工具完成了对随机森林模型的“破译”。它证明了,经过良好机理仿真的数据喂养后,机器学习模型学习到的并不是随机的统计噪声,而是高度符合底层物理规律的客观映射。这种“机理引导数据,数据印证机理”的闭环,是这篇论文在可解释性诊断研究中提供的最大价值。
5. 总结与延伸思考
整体梳理下来,这篇发表在《Measurement》上的工作为复杂装备的智能诊断提供了一个逻辑非常自洽的“机理+数据”融合方式。
文章没有盲目追求堆砌复杂的深度网络,而是从工业痛点出发:用一维热力学仿真解决“无米之炊(故障数据稀缺)”,用 Tree SHAP 解决“大海捞针(特征冗余)”,用随机森林解决“小样本分类”,最后再用 SHAP 双视角分析对算法的可解释性进行分析,实现与物理常识的交叉印证。这种务实且严谨的研究闭环,对于设备健康管理(PHM)领域的落地应用具有很强的参考价值。
当然,任何研究都有其特定的应用边界,这也是我们在实际工程探索中需要继续攻克的方向。结合论文末尾的展望与我个人的阅读思考,该方法在未来或许还有以下几个维度的探讨空间:
- 故障演化程度的细化
目前模型在仿真时,针对每种故障设定了特定的参数微调值(如将活塞烧蚀的漏气率设定为固定值)。然而,工业现场的机械退化往往是一个连续演变的过程。如果未来能将故障状态细分为“早期-中期-晚期”,构建渐进式的退化数据集,模型的早期预警价值将得到进一步放大。 - 多变复杂工况的适应性
船舶在真实的海洋环境中航行时,不可避免地会遭遇风浪交加、负载剧烈波动的复杂瞬态工况。当前的热力学模型标定与测试主要基于相对稳定的转速条件。如何让仿真模型和分类算法在剧烈变工况下依然保持如此高的解释性与准确率,是下一步走向实船应用必须跨越的门槛。 - 高保真机理与深度学习的深度融合
正如作者在文末提到的,未来的研究可以尝试将先进的深度学习模型与更为精细的热力学模型(例如多区燃烧模型或包含复杂化学动力学的模型)相融合。如何在机理模型高昂的算力消耗与深度学习实时性需求之间找到最佳的工程折中点,将是一个非常有挑战性的课题。
总而言之,这篇论文通过严谨的特征工程设计和细致的物理可解释性分析,为复杂机械系统的故障诊断提供了一种“机理+数据”融合的参考方案。
附:论文信息
为了方便大家查阅原文,在此附上详细的文献信息:
论文标题:Thermodynamic simulation-assisted random forest: Towards explainable fault diagnosis of combustion chamber components of marine diesel engines
刊载期刊:Measurement (Elsevier), 2025
DOI:10.1016/j.measurement.2025.117252
完整资源包(包含论文、代码及数据): https://ts-rf.github.io/zh-CN/
C. Luo, M. Zhao, X. Fu, S. Zhong, S. Fu, K. Zhang, X. Yu. Thermodynamic simulation-assisted random forest: Towards explainable fault diagnosis of combustion chamber components of marine diesel engines [J]. Measurement, 2025, 251: 117252.

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)