CVPR 2025 | HSI-MSI融合:自适应残差引导子空间扩散模型
这篇论文的核心方法是自学习自适应残差引导子空间扩散模型(ARGS-Diff),核心逻辑是“低维组件分解+双轻量网络自学习+扩散模型反向重建+ARGM稳定采样”,全程无需额外成对训练数据,仅依赖输入的LR-HSI和HR-MSI完成HSI-MSI融合。以下按论文3.1-3.4节的逻辑,结合公式、结构和流程,进行逐模块详细拆解:
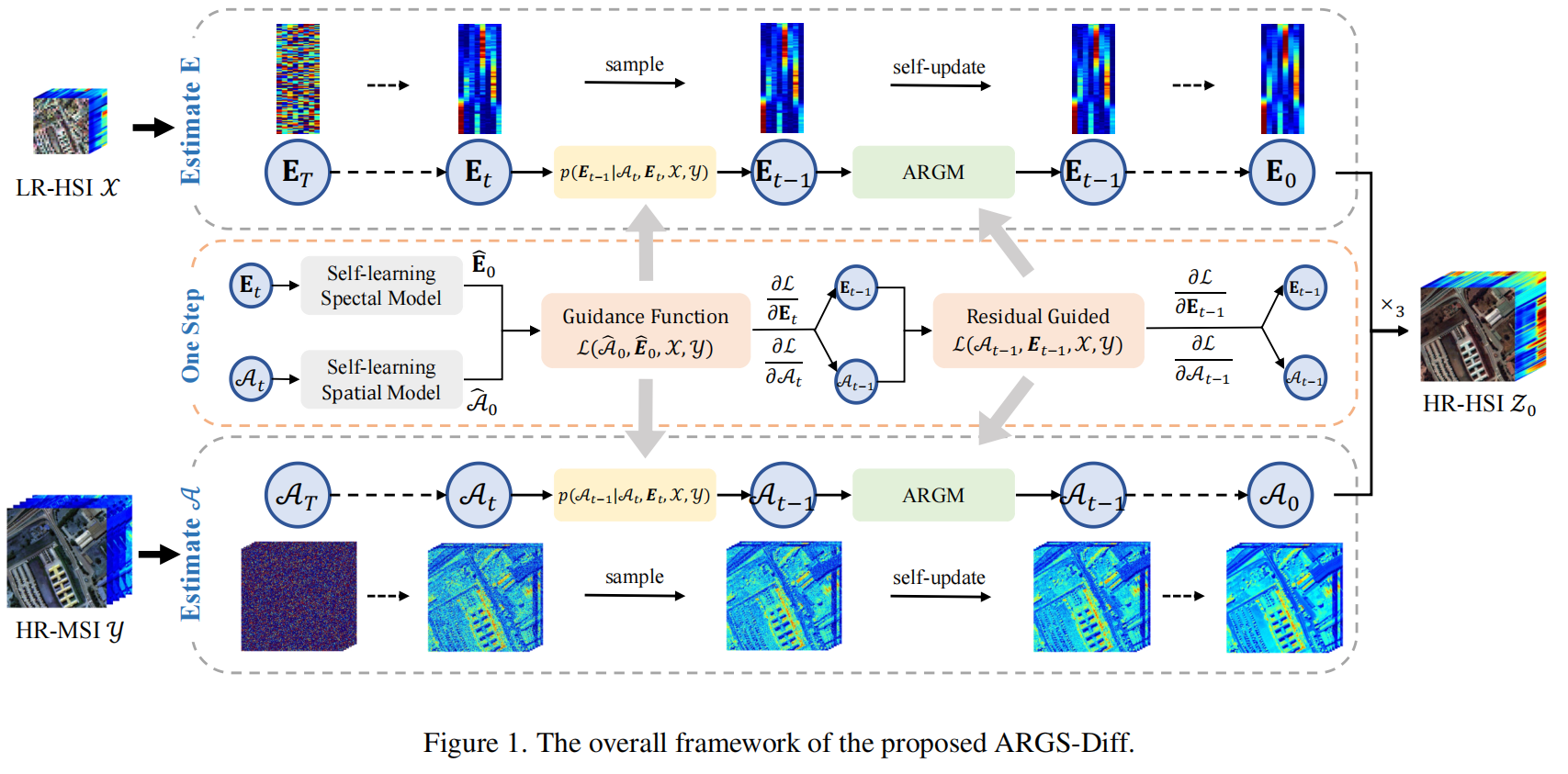
一、方法概述(3.1节)
核心思路
基于HSI可分解为“光谱基(E\mathcal{E}E)+降维系数(A\mathcal{A}A)”的特性(公式Z=A×3E\mathcal{Z} = \mathcal{A} \times_3 \mathcal{E}Z=A×3E),通过3步实现融合:
- 设计双轻量网络(光谱网络+空间网络),仅用输入的LR-HSI和HR-MSI自学习,分别提取光谱分布和空间分布信息;
- 基于扩散模型的反向过程,以LR-HSI(光谱约束)和HR-MSI(空间约束)为条件,迭代重建A\mathcal{A}A和E\mathcal{E}E;
- 引入ARGM模块,解决双组件同步更新的对齐问题,稳定采样过程;
- 最终通过A0×3E0\mathcal{A}_0 \times_3 \mathcal{E}_0A0×3E0生成HR-HSI。
核心优势
- 自学习:无需额外成对训练数据,适配遥感数据稀缺场景;
- 轻量化:双网络参数少、计算开销低,适配边缘设备;
- 高稳定:ARGM+Adam优化避免采样崩溃,提升融合质量。
二、关键模块详解
2.1 自学习子空间网络(3.2节):轻量化网络+样本自构造
核心目标:设计两个专用轻量网络,分别学习光谱基E\mathcal{E}E和降维系数A\mathcal{A}A的分布,避免通用大模型的高开销。
(1)光谱网络(Spectral Model):学习光谱基E\mathcal{E}E
- 网络结构:5层全连接网络(FCN),隐藏层维度为{256,512,256}(经消融实验验证最优);
- 输入输出维度:输入/输出维度均为CCC(LR-HSI的光谱波段数),输出直接对应光谱基E\mathcal{E}E(d×Cd \times Cd×C,d=8d=8d=8);
- 训练样本构造(自学习核心):
从LR-HSI中随机选择ddd个像素的光谱向量(每个像素含CCC个波段),拼接为(d,C)(d, C)(d,C)大小的样本;
无需HR-HSI作为标签,直接利用LR-HSI的光谱信息训练网络,让网络学会“生成符合真实光谱分布的E\mathcal{E}E”。
(2)空间网络(Spatial Model):学习降维系数A\mathcal{A}A
- 网络结构:类UNet架构,共9个卷积层(4下采样+1中间层+4上采样),每层含2个残差块,通道倍数为{1,2,3,4}(平衡性能与参数);
- 输入输出维度:输入/输出通道数为ddd(子空间维度),输出对应降维系数A\mathcal{A}A(H×W×dH \times W \times dH×W×d);
- 训练样本构造(自学习核心):
从HR-MSI中提取一个patch(如128×128),随机选择1个波段,重复ddd次,形成(Hpatch,Wpatch,d)(H_{patch}, W_{patch}, d)(Hpatch,Wpatch,d)大小的样本;
利用HR-MSI的空间信息训练网络,让网络学会“生成符合真实空间结构的A\mathcal{A}A”。
(3)网络设计的核心考量
- 轻量化:光谱网络仅0.39M参数,空间网络仅21.46M参数,远低于其他扩散模型(如PLRDiff 391M参数);
- 针对性:光谱网络用FCN适配“光谱向量的全局分布”,空间网络用UNet适配“图像的局部空间结构”,避免功能冗余。
2.2 子空间反向扩散过程(3.3节):条件约束+迭代重建
核心目标:从随机噪声出发,以LR-HSI和HR-MSI为约束,迭代去噪重建A\mathcal{A}A和E\mathcal{E}E,对应论文Algorithm 1的核心流程。
(1)初始化:噪声起点
反向扩散从t=T=500t=T=500t=T=500步的含噪组件开始,AT\mathcal{A}_TAT和ET\mathcal{E}_TET均从高斯分布N(0,I)\mathcal{N}(0,I)N(0,I)中采样(完全噪声状态)。
(2)迭代步骤(ttt从TTT到1,每步对应图1“One Step”)
每步迭代包含7个关键操作,结合公式逐一拆解:
-
估计干净组件A^0\hat{\mathcal{A}}_0A^0、E^0\hat{\mathcal{E}}_0E^0(公式11):
用训练好的空间网络(sθs_\thetasθ)和光谱网络(cζc_\zetacζ)预测当前含噪组件At\mathcal{A}_tAt、Et\mathcal{E}_tEt中的噪声,反向推导“估计的干净组件”:
A^0=At−1−α‾t⋅sθ(At,t)α‾t\hat{\mathcal{A}}_0 = \frac{\mathcal{A}_t - \sqrt{1-\overline{\alpha}_t} \cdot s_\theta(\mathcal{A}_t,t)}{\sqrt{\overline{\alpha}_t}}A^0=αtAt−1−αt⋅sθ(At,t)
E^0=Et−1−α‾t⋅cζ(Et,t)α‾t\hat{\mathcal{E}}_0 = \frac{\mathcal{E}_t - \sqrt{1-\overline{\alpha}_t} \cdot c_\zeta(\mathcal{E}_t,t)}{\sqrt{\overline{\alpha}_t}}E^0=αtEt−1−αt⋅cζ(Et,t)
其中α‾t\overline{\alpha}_tαt是预设的指数噪声调度(控制每步噪声强度)。 -
计算引导损失L\mathcal{L}L(公式10):
以LR-HSI和HR-MSI为约束,量化A^0×3E^0\hat{\mathcal{A}}_0 \times_3 \hat{\mathcal{E}}_0A^0×3E^0(初步合成的HR-HSI)与输入数据的差异,为更新“定方向”:
L=∥H(A^0×3E^0)−X∥22+λ1⋅∥A^0×3E^0×3R−Y∥22\mathcal{L} = \|\mathcal{H}(\hat{\mathcal{A}}_0 \times_3 \hat{\mathcal{E}}_0) - \mathcal{X}\|_2^2 + \lambda_1 \cdot \|\hat{\mathcal{A}}_0 \times_3 \hat{\mathcal{E}}_0 \times_3 R - \mathcal{Y}\|_2^2L=∥H(A^0×3E^0)−X∥22+λ1⋅∥A^0×3E^0×3R−Y∥22- 第一项:H(⋅)\mathcal{H}(\cdot)H(⋅)是空间降采样,确保光谱基E^0\hat{\mathcal{E}}_0E^0符合LR-HSI的光谱特征;
- 第二项:RRR是光谱响应函数,确保降维系数A^0\hat{\mathcal{A}}_0A^0符合HR-MSI的空间结构;
- λ1=1\lambda_1=1λ1=1(平衡两项约束)。
-
Adam优化梯度(公式13-14):
为避免梯度震荡,用Adam优化器估计引导损失的一阶矩(mmm)和二阶矩(vvv),修正梯度:
mt−1(A)=β1mt(A)+(1−β1)∇AtLm_{t-1}^{(\mathcal{A})} = \beta_1 m_t^{(\mathcal{A})} + (1-\beta_1) \nabla_{\mathcal{A}_t} \mathcal{L}mt−1(A)=β1mt(A)+(1−β1)∇AtL
vt−1(A)=β2vt(A)+(1−β2)(∇AtL)2v_{t-1}^{(\mathcal{A})} = \beta_2 v_t^{(\mathcal{A})} + (1-\beta_2) (\nabla_{\mathcal{A}_t} \mathcal{L})^2vt−1(A)=β2vt(A)+(1−β2)(∇AtL)2
(E\mathcal{E}E的梯度优化逻辑一致,β1=0.9\beta_1=0.9β1=0.9,β2=0.999\beta_2=0.999β2=0.999)
再对矩估计进行偏差修正:
m^t−1(A)=mt−1(A)1−β1T−t\hat{m}_{t-1}^{(\mathcal{A})} = \frac{m_{t-1}^{(\mathcal{A})}}{1-\beta_1^{T-t}}m^t−1(A)=1−β1T−tmt−1(A) -
修正噪声预测(公式15):
将优化后的梯度融入噪声预测,让噪声预测“偏向”输入约束:
s^θ(At,t)=sθ(At,t)−ρ1⋅m^t−1(A)v^t−1(A)+ϵ\hat{s}_\theta(\mathcal{A}_t,t) = s_\theta(\mathcal{A}_t,t) - \rho_1 \cdot \frac{\hat{m}_{t-1}^{(\mathcal{A})}}{\sqrt{\hat{v}_{t-1}^{(\mathcal{A})}} + \epsilon}s^θ(At,t)=sθ(At,t)−ρ1⋅v^t−1(A)+ϵm^t−1(A)
c^ζ(Et,t)=cζ(Et,t)−ρ2⋅m^t−1(E)v^t−1(E)+ϵ\hat{c}_\zeta(\mathcal{E}_t,t) = c_\zeta(\mathcal{E}_t,t) - \rho_2 \cdot \frac{\hat{m}_{t-1}^{(\mathcal{E})}}{\sqrt{\hat{v}_{t-1}^{(\mathcal{E})}} + \epsilon}c^ζ(Et,t)=cζ(Et,t)−ρ2⋅v^t−1(E)+ϵm^t−1(E)
其中ρ1=ρ2=0.05\rho_1=\rho_2=0.05ρ1=ρ2=0.05(步长),ϵ=1e−8\epsilon=1e-8ϵ=1e−8(避免除零)。 -
采样下一步组件At−1\mathcal{A}_{t-1}At−1、Et−1\mathcal{E}_{t-1}Et−1(公式12):
基于修正后的噪声预测,生成噪声更少的下一步组件,逐步逼近干净组件:
At−1=α‾t−1A^0+1−α‾t−1s^θ(At,t)\mathcal{A}_{t-1} = \sqrt{\overline{\alpha}_{t-1}} \hat{\mathcal{A}}_0 + \sqrt{1-\overline{\alpha}_{t-1}} \hat{s}_\theta(\mathcal{A}_t,t)At−1=αt−1A^0+1−αt−1s^θ(At,t)
Et−1=α‾t−1E^0+1−α‾t−1c^ζ(Et,t)\mathcal{E}_{t-1} = \sqrt{\overline{\alpha}_{t-1}} \hat{\mathcal{E}}_0 + \sqrt{1-\overline{\alpha}_{t-1}} \hat{c}_\zeta(\mathcal{E}_t,t)Et−1=αt−1E^0+1−αt−1c^ζ(Et,t) -
ARGM模块修正(后续3.4节详解):
计算At−1×3Et−1\mathcal{A}_{t-1} \times_3 \mathcal{E}_{t-1}At−1×3Et−1与输入数据的残差损失,微调组件对齐。
(3)核心适配改造
- 双条件约束:区别于传统扩散模型的无条件生成,通过引导损失将LR-HSI和HR-MSI的约束融入每步迭代;
- 低维组件采样:仅对A\mathcal{A}A和E\mathcal{E}E采样,而非高维HSI,计算量降低C/dC/dC/d倍(CCC通常为100+,d=8d=8d=8)。
2.3 自适应残差引导模块(ARGM)(3.4节):稳定双组件对齐
(1)设计动机
双组件(A\mathcal{A}A和E\mathcal{E}E)同步更新时,易出现“空间结构与光谱特征错位”(如A\mathcal{A}A的空间细节好,但与E\mathcal{E}E的光谱不匹配),导致采样崩溃或融合质量下降。ARGM的核心是“残差修正+双向对齐”。
(2)工作流程(公式16-17)
-
计算残差损失:量化当前组件乘积与输入数据的差异,聚焦“对齐偏差”:
L(At−1,Et−1)=∥H(At−1×3Et−1)−X∥22+λ2⋅∥At−1×3Et−1×3R−Y∥22\mathcal{L}(\mathcal{A}_{t-1},\mathcal{E}_{t-1}) = \|\mathcal{H}(\mathcal{A}_{t-1} \times_3 \mathcal{E}_{t-1}) - \mathcal{X}\|_2^2 + \lambda_2 \cdot \|\mathcal{A}_{t-1} \times_3 \mathcal{E}_{t-1} \times_3 R - \mathcal{Y}\|_2^2L(At−1,Et−1)=∥H(At−1×3Et−1)−X∥22+λ2⋅∥At−1×3Et−1×3R−Y∥22
与引导损失的区别:引导损失针对“估计的干净组件A^0\hat{\mathcal{A}}_0A^0”,残差损失针对“采样后的下一步组件At−1\mathcal{A}_{t-1}At−1”,更聚焦当前步的实际对齐偏差;λ2=1\lambda_2=1λ2=1。 -
双向修正组件:根据残差损失的梯度,微调At−1\mathcal{A}_{t-1}At−1和Et−1\mathcal{E}_{t-1}Et−1,缩小对齐偏差:
At−1:=At−1−ρ1r∗∇At−1L\mathcal{A}_{t-1} := \mathcal{A}_{t-1} - \frac{\rho_1}{r^*} \nabla_{\mathcal{A}_{t-1}} \mathcal{L}At−1:=At−1−r∗ρ1∇At−1L
Et−1:=Et−1−ρ2r∗∇Et−1L\mathcal{E}_{t-1} := \mathcal{E}_{t-1} - \frac{\rho_2}{r^*} \nabla_{\mathcal{E}_{t-1}} \mathcal{L}Et−1:=Et−1−r∗ρ2∇Et−1L
其中r∗=10r^*=10r∗=10(步长比例,控制修正幅度,避免过度调整)。
(3)核心价值
- 稳定性:消融实验显示,加入ARGM后PSNR提升0.47-0.61dB,SAM降低0.11-0.16°,避免采样震荡;
- 低开销:仅增加1-2秒推理时间,对总耗时影响可忽略(总耗时12-13秒)。
(HR-HSI)分解
这篇论文的核心思想是将高维、复杂的高光谱图像(HR-HSI)分解为两个低维、更容易处理的分量:光谱基 (Spectral Basis, EEE) 和 降维系数 (Reduced Coefficient, AAA)。 论文设定子空间维度 d=8d=8d=8,而原始光谱波段数 CCC 通常较大(例如 100 或更多)。下面我用一个具体的例子来通俗地讲解这两个到底是个什么东西。
1. 场景设定
假设我们要处理一张 256×256 像素的高光谱图像(这就是论文中的 HR-HSI,记为 ZZZ)。
- 空间大小: 256 (高) × 256 (宽)。
- 光谱维度: 假设有 100 个波段 (C=100C=100C=100)。也就是说,每个像素点不仅仅是 RGB 3 个值,而是记录了 100 个不同波长下的数值。
直接处理这个 256×256×100256 \times 256 \times 100256×256×100 的数据块非常困难且计算量大。于是,论文将其分解为 AAA 和 EEE。
2. 光谱基 EEE:“8种基础配方”
- 维度: d×Cd \times Cd×C = 8×1008 \times 1008×100。
- 本质: 它是一个只有 8 行的矩阵,每一行代表一种**“纯净”的光谱曲线**。
举例讲解:
想象这张高光谱图片拍的是一个公园,里面主要只有 8 种不同的物质:草地、水体、泥土、水泥路、树荫、红屋顶、金属杆、塑料椅。
虽然图片有几万个像素,但本质上这些像素的光谱曲线就是这 8 种物质光谱的混合。 - 光谱基 EEE 的第 1 行,就是 “草地” 的标准光谱指纹(100个波段数值)。
- 光谱基 EEE 的第 2 行,就是 “水体” 的标准光谱指纹。
- …
- 光谱基 EEE 的第 8 行,就是 “塑料椅” 的标准光谱指纹。
总结: EEE 告诉了我们这张图里**“存在哪几种本质材料”。它包含的是光谱信息**。
3. 降维系数 AAA:“配比地图”
- 维度: H×W×dH \times W \times dH×W×d = 256×256×8256 \times 256 \times 8256×256×8。
- 本质: 它是一张空间地图,尺寸和普通照片一样大(256×256),但它每个像素有 8 个通道,而不是 3 个(RGB)。这 8 个数值代表了上面 8 种基础配方在像素点上的混合比例。
举例讲解:
现在我们看图片中的某一个像素点,比如坐标 (100, 100)。 - AAA 在这个位置的值可能是一个长度为 8 的向量:
[0.8, 0.1, 0, 0, 0.1, 0, 0, 0]。 - 这是什么意思?
- 0.8:表示这个像素有 80% 是“草地”(对应 EEE 的第 1 行)。
- 0.1:表示这个像素有 10% 是“水体”(对应 EEE 的第 2 行,可能是湿润的草地反光)。
- 0.1:表示这个像素有 10% 是“树荫”(对应 EEE 的第 5 行)。
- 其他为 0,表示这里没有泥土、水泥等其他成分。
如果把这个 AAA 的第 1 通道(草地比例)单独拿出来画成一张灰度图,你会发现它就是一张清晰的“草地分布图”。因此,AAA 捕捉了图像的空间信息。
4. 它们如何合二为一?
论文中的核心公式是 Z=A×3EZ = A \times_3 EZ=A×3E。意思是说,最终的高光谱图像 (ZZZ) 是由“配比地图 (AAA)”把“基础配方 (EEE)”混合出来的。
对于图像中的每一个像素,恢复过程如下:
- 看 AAA 告诉你这个点由哪些材料组成(比如 0.8 的草地 + 0.2 的水泥)。
- 去 EEE 里找到草地和水泥的完整光谱(各 100 个数值)。
- 计算: (0.8 × 草地光谱) + (0.2 × 水泥光谱)。
- 结果: 你得到了这个像素点的最终光谱(100 个数值),这构成了 HR-HSI 的一个像素。
5. 为什么要这样分?(论文的妙处)
- 计算量降低: 原本要处理 100 个波度的复杂相关性,现在只要处理 8 个通道(d=8d=8d=8)。
- 分工明确:
- AAA (空间/降维系数): 既然它长得像地图,主要包含空间细节(边缘、纹理)。所以论文用高分辨率多光谱图像(HR-MSI)来训练生成 AAA 的网络(空间网络)。
- EEE (光谱基): 既然它包含材料的光谱指纹,主要包含光谱特征。所以论文用低分辨率高光谱图像(LR-HSI)来训练生成 EEE 的网络(光谱网络)。
一句话总结:
- EEE (d×Cd \times Cd×C) 是 “颜料”:定义了图像中可能出现的基本光谱类型(共8种)。
- AAA (H×W×dH \times W \times dH×W×d) 是 “涂鸦”:定义了在图像的每个位置,每种颜料涂了多少。
两者结合,就画出了完整的高光谱画作。
×3R\times_3 R×3R
L=∥H(A^0×3E^0)−X∥22+λ1⋅∥A^0×3E^0×3R−Y∥22\mathcal{L} = \|\mathcal{H}(\hat{\mathcal{A}}_0 \times_3 \hat{\mathcal{E}}_0) - \mathcal{X}\|_2^2 + \lambda_1 \cdot \|\hat{\mathcal{A}}_0 \times_3 \hat{\mathcal{E}}_0 \times_3 R - \mathcal{Y}\|_2^2L=∥H(A^0×3E^0)−X∥22+λ1⋅∥A^0×3E^0×3R−Y∥22
这个问题的核心在于理解 高光谱图像 (HSI) 和 多光谱图像 (MSI) 之间的关系,以及公式中的矩阵乘法 ×3R\times_3 R×3R 到底在做什么。
简单来说,第二项的作用是:“把你预测的高清高光谱图,模拟成多光谱图,看看它和真实的高清多光谱图像不像。”
下面我拆解这三步来帮你彻底看懂:
1. 公式拆解:发生了什么?
公式第二项是:
λ1⋅∥A^0×3E^0×3R−Y∥22 \lambda_1 \cdot \|\hat{A}_0 \times_3 \hat{E}_0 \times_3 R - Y\|^2_2 λ1⋅∥A^0×3E^0×3R−Y∥22
我们可以把它拆成三部分来看:
- A^0×3E^0\hat{A}_0 \times_3 \hat{E}_0A^0×3E^0:
这是你模型当前预测出的 HR-HSI(高分辨率高光谱图像)。- 它的维度是 H×W×CH \times W \times CH×W×C(空间大,波段多)。
- 注意:它是我们猜出来的,可能不准确。
- ×3R\times_3 R×3R(关键点!):
RRR 是 光谱响应函数。- 多光谱相机(MSI)和高光谱相机(HSI)看到的波段是不一样的。MSI 只有几个宽波段(比如红、绿、蓝、近红外,共 ccc 个),而 HSI 有上百个窄波段(共 CCC 个)。
- 数学含义:RRR 是一个矩阵,它的作用是把 HSI 的 CCC 个波段,按照一定的权重“折叠”或“混合”成 MSI 的 ccc 个波段。
- 物理含义:这相当于模拟“如果你用多光谱相机去拍这个高光谱图像,会得到什么结果”。
- −Y- Y−Y:
YYY 是真实的 HR-MSI(高分辨率多光谱图像)。- 它的维度是 H×W×cH \times W \times cH×W×c。
- 特点:它的空间分辨率很高(细节清晰),但光谱分辨率低(只有几个波段)。
2. 为什么要乘以 RRR?
因为 A^0×3E^0\hat{A}_0 \times_3 \hat{E}_0A^0×3E^0(你的预测图)和 YYY(真实的 MSI)维度不匹配,物理意义也不一样,不能直接相减。
- 你的预测图有 100 个波段,YYY 只有 4 个波段。
- 为了比较,必须把你的预测图“压缩”成 4 个波段,这就要靠 ×3R\times_3 R×3R。
这一步做完后(A^0×3E^0×3R\hat{A}_0 \times_3 \hat{E}_0 \times_3 RA^0×3E^0×3R),你就得到了“模拟的多光谱图像”。
3. 为什么说它“确保降维系数 A0A^0A0 符合 HR-MSI 的空间结构”?
这是最微妙但也最重要的一点。
- YYY (HR-MSI) 的特点:它是高清的。它包含了丰富的空间细节(如边缘、纹理)。
- 损失函数的作用:公式计算的是
(模拟的多光谱图) - (真实的高清多光谱图)。- 如果你的预测图像 A^0×3E^0\hat{A}_0 \times_3 \hat{E}_0A^0×3E^0 在空间上是模糊的,那么经过 RRR 变换后的模拟图也是模糊的。
- 这就会导致它和真实的、高清的 YYY 差别很大,Loss 就会变大。
- 梯度更新:为了减小 Loss,模型必须让预测图像变清晰。
- E^0\hat{E}_0E^0(光谱基)主要决定颜色/光谱形状,不决定空间位置。
- A^0\hat{A}_0A^0(降维系数) 是一张空间地图,决定了“什么东西在什么位置”。
- 因此,为了让图像变清晰,梯度会主要去修改 A^0\hat{A}_0A^0,强迫它去捕捉 YYY 中那些清晰的边缘和纹理。
总结来说:
这一项就像是在说:“你猜的高光谱图,经过光谱折叠后,在空间结构上必须跟这张高清多光谱照片 (YYY) 一模一样。”
4. 通俗类比
想象你在复原一幅彩色的高清画(HR-HSI),但你手头只有:
- 一张黑白低清照片(LR-HSI)。
- 一张彩色低清照片(HR-MSI ——注:这里对应论文中HR-MSI是高分辨率的假设,但为了理解光谱响应,我们强调它是少波段的)。
你的算法现在在猜这幅画的样子(A^0×3E^0\hat{A}_0 \times_3 \hat{E}_0A^0×3E^0)。
- 第一项(LR-HSI约束):把你的猜画缩小(降采样)后,颜色/光谱得跟那张黑白低清照片对得上。
- 第二项(HR-MSI约束):把你的猜画打个马赛克/过一层滤镜(这就是乘以 RRR,把几百个波段变成几个波段),此时它的清晰度和轮廓必须跟那张彩色低清照片(YYY)一模一样。
正是因为 YYY 是清晰的高分辨率图像(空间上),所以这一项强制了你的猜测结果(主要是 A^0\hat{A}_0A^0)必须也是清晰的。
自适应残差引导模块(ARGM)
好的,这篇论文中的 自适应残差引导模块(ARGM) 是确保模型能够稳定、高质量地重建图像的关键“稳压器”。 下面我将通过通俗类比和数学原理拆解相结合的方式,详细讲解这个模块。
1. 为什么需要 ARGM?(背景与痛点)
在 ARGS-Diff 中,我们不是直接生成最终的高光谱图像(HR-HSI),而是同时生成两个分量:
- 降维系数 AAA(空间部分):负责图像的“结构”和“轮廓”。
- 光谱基 EEE(光谱部分):负责图像的“颜色”和“材质”。
问题所在:
这就好比你让画师 A 负责画轮廓,让画师 E 负责上色。 - 在扩散采样的每一步,你同时要求他们改进。
- 但如果画师 A 把轮廓画歪了,画师 E 还按照旧的位置上色,两者就会**“对不上”**(Misalignment)。
- 在扩散模型中,这种不一致会随着迭代步骤迅速放大,导致最终生成的图像崩溃、充满噪点或完全失真。
ARGM 的作用:
ARGM 就像是一个**“质检总监”**。在两个画师每画完一笔(完成一次采样更新 At−1,Et−1A_{t-1}, E_{t-1}At−1,Et−1)之后,总监立刻介入,检查他们合起来的作品像不像,如果不像,马上强制他们修改,确保他们时刻保持同步。
2. ARGM 的详细流程(举例讲解)
我们将论文中的采样第 ttt 步拆解来看。假设我们已经通过扩散模型得到了这一步的初步结果 At−1A_{t-1}At−1 和 Et−1E_{t-1}Et−1。
第一步:总监检查(计算残差损失 LLL)
总监把画师 A 和画师 E 的成果合在一起,形成一张当前的“预测高光谱图”,然后去对照手里的两张“标准答案”(输入数据)。
论文公式 (16) 定义了这个检查标准:
L(At−1,Et−1,X,Y)=∥H(At−1×3Et−1)−X∥22+λ2∥At−1×3Et−1×3R−Y∥22 L(A_{t-1}, E_{t-1}, X, Y) = \|H(A_{t-1} \times_3 E_{t-1}) - X\|^2_2 + \lambda_2\|A_{t-1} \times_3 E_{t-1} \times_3 R - Y\|^2_2 L(At−1,Et−1,X,Y)=∥H(At−1×3Et−1)−X∥22+λ2∥At−1×3Et−1×3R−Y∥22
这个公式包含两个检查项:
- 空间检查(对比 LR-HSI XXX):
- 操作:把预测图缩小(降采样 HHH),变成低分辨率。
- 对比:看看它和输入的 LR-HSI 像不像。
- 目的:确保**颜色和光谱(EEE)**没有跑偏。因为如果颜色不对,缩小了也不对。
- 结构检查(对比 HR-MSI YYY):
- 操作:把预测图的光谱波段折叠(乘以 RRR),变成多光谱图。
- 对比:看看它和输入的 HR-MSI 像不像。
- 目的:确保**轮廓和结构(AAA)**是清晰的。因为如果轮廓糊了,和高清多光谱图(YYY)肯定差很远。
总结: 这个 LLL 值就是“误差”。误差越大,说明 AAA 和 EEE 配合得越差。
第二步:总监指令(计算梯度)
总监不仅要打分,还要告诉画师怎么改。这需要对误差 LLL 求导数(梯度)。
- ∇At−1L\nabla_{A_{t-1}} L∇At−1L:告诉空间分量 AAA,你的轮廓哪里的误差最大,应该往哪个方向调。
- ∇Et−1L\nabla_{E_{t-1}} L∇Et−1L:告诉光谱分量 EEE,你的颜色哪里不对,应该往哪个方向调。
第三步:强制修正(更新公式)
根据总监的指令,对 At−1A_{t-1}At−1 和 Et−1E_{t-1}Et−1 进行微调。这就是论文公式 (17):
At−1:=At−1−ρ1r∇At−1L(...) A_{t-1} := A_{t-1} - \frac{\rho_1}{r} \nabla_{A_{t-1}} L(...) At−1:=At−1−rρ1∇At−1L(...)
Et−1:=Et−1−ρ2r∇Et−1L(...) E_{t-1} := E_{t-1} - \frac{\rho_2}{r} \nabla_{E_{t-1}} L(...) Et−1:=Et−1−rρ2∇Et−1L(...)
- ρ\rhoρ(步长):控制修改的幅度。
- rrr(比率):一个很重要的参数。比如 r=10r=10r=10,意味着对空间分量 AAA 的修正力度是光谱分量 EEE 的 1/10。这是因为空间信息通常比光谱信息更敏感或变化更快,需要更精细的控制。
3. 通俗举例:拼图游戏
想象你在拼一幅巨大的 1000 片拼图(HR-HSI)。
- 画师 A 负责拼边缘和形状(对应 AAA)。
- 画师 E 负责确认色块的颜色(对应 EEE)。
没有 ARGM 时(普通扩散模型):
你让他们闭着眼睛拼。A 说“我觉得这块是红的”,E 说“我觉得这块是方的”。由于没有参考,拼到最后,发现红的方块插不进方的孔里,整个拼图散架了。
有了 ARGM 时(ARGS-Diff):
每拼好 10 片,你就拿一张缩小版的“小抄照片”(LR-HSI)和一张只有轮廓的“线稿图”(HR-MSI)给他们看。 - 你问 A:“你拼的形状和线稿图一样清晰吗?”如果不一样,A 马上调整位置。
- 你问 E:“你拼的颜色和小抄照片一致吗?”如果不一样,E 马上换色块。
- 结果: 他们时刻被“拉”回到正确的轨道上,最终拼出了一幅完美的画。
4. ARGM 带来的具体好处(基于论文实验)
根据论文 4.4 节的消融研究,引入 ARGM 后带来了显著提升:
- 大幅提升性能:
- 在 Pavia 数据集上,PSNR 提升了 0.47 dB。
- 在 Chikusei 数据集上,PSNR 提升了 0.57 dB。
- 在 KSC 数据集上,PSNR 提升了 0.61 dB。
- 这证明了 ARGM 有效修正了 AAA 和 EEE 的对齐误差,使重建图像更接近真实值。
- 极强的稳定性:
- 论文中提到,如果没有 ARGM,同时更新两个分量会导致“不稳定或崩溃”。
- ARGM 通过引入观测数据的约束(Loss),充当了“锚”的角色,防止扩散过程偏离轨道。
- 抗噪能力增强:
- ARGM 计算的是与观测值(X,YX, YX,Y)的残差。这意味着即使模型预测的噪声很大,只要 AAA 和 EEE 合起来符合观测图像的特征,ARGM 就会把它们“拉”回来。这使得模型对输入噪声不敏感。
- 低成本,高回报:
- 计算 ARGM 只需要大约 1-2 秒(相对于总时间 12 秒),但换来了巨大的精度提升(图 4 的视觉效果也更清晰)。
总结
ARGM 本质上就是一个“基于观测数据的实时校准模块”。
它不参与扩散模型的“去噪”预测(那是神经网络 sθs_\thetasθ 和 cζc_\zetacζ 的事),而是在网络预测结果产生后,强行把结果往物理规律和观测事实的方向靠。这就是为什么论文称其为“残差引导”——利用预测值与真实值之间的残差来引导更新方向。
论文中的扩散模型
这篇论文中的扩散模型的核心是“正向逐步加噪+反向逐步去噪”,并针对HSI-MSI融合任务做了3大关键适配(低维组件加噪、双条件约束、稳定性优化),既保留了扩散模型高质量生成的优势,又解决了融合任务的轻量化、数据依赖问题。下面从“基础理论→论文适配改造→核心逻辑总结”三部分拆解:
一、扩散模型的基础理论(论文2.1节核心)
扩散模型的本质是“通过可控加噪破坏数据结构,再学习反向去噪规律”,核心分为正向过程(加噪) 和反向过程(去噪) ,对应论文公式(1)-(4):
1. 正向过程(Forward Process):逐步添加噪声
目标是将干净数据x0x_0x0(论文中是低维组件A0\mathcal{A}_0A0、E0\mathcal{E}_0E0)逐步转化为纯高斯噪声,过程满足马尔可夫链特性(每一步仅依赖上一步)。
- 核心公式(论文公式1):
xt=α‾tx0+1−α‾tϵ,ϵ∼N(0,I)x_t = \sqrt{\overline{\alpha}_t}x_0 + \sqrt{1-\overline{\alpha}_t}\epsilon, \quad \epsilon \sim \mathcal{N}(0,I)xt=αtx0+1−αtϵ,ϵ∼N(0,I)- α‾t=∏s=1tαs\overline{\alpha}_t = \prod_{s=1}^t \alpha_sαt=∏s=1tαs(αs\alpha_sαs是每步噪声衰减系数,预设为从1逐步趋近于0的序列);
- ttt是扩散步数(论文T=500T=500T=500):t=0t=0t=0时是干净数据x0x_0x0,t=Tt=Tt=T时xTx_TxT近似纯高斯噪声;
- 关键逻辑:加噪是“可控且可逆”的,不是随机加噪——通过固定α‾t\overline{\alpha}_tαt的噪声调度,确保反向过程能学习到稳定的去噪规律。
2. 反向过程(Reverse Process):逐步去噪恢复
目标是从t=Tt=Tt=T的纯噪声出发,迭代预测噪声并去除,最终恢复干净数据x0x_0x0,这是模型学习和推理的核心。
- 核心步骤(对应论文公式3-4):
- 估计干净数据x^0\hat{x}_0x^0:通过模型预测当前含噪数据xtx_txt中的噪声ϵθ(xt,t)\epsilon_\theta(x_t,t)ϵθ(xt,t),反向推导干净数据:
x^0=xt−(1−α‾t)ϵθ(xt,t)α‾t\hat{x}_0 = \frac{x_t - (1-\overline{\alpha}_t)\epsilon_\theta(x_t,t)}{\sqrt{\overline{\alpha}_t}}x^0=αtxt−(1−αt)ϵθ(xt,t) - 生成下一步含噪数据xt−1x_{t-1}xt−1:基于x^0\hat{x}_0x^0和预测噪声,生成噪声更少的xt−1x_{t-1}xt−1,逐步逼近x0x_0x0:
xt−1=α‾t−1x^0+1−α‾t−1ϵθ(xt,t)x_{t-1} = \sqrt{\overline{\alpha}_{t-1}}\hat{x}_0 + \sqrt{1-\overline{\alpha}_{t-1}}\epsilon_\theta(x_t,t)xt−1=αt−1x^0+1−αt−1ϵθ(xt,t)
- 估计干净数据x^0\hat{x}_0x^0:通过模型预测当前含噪数据xtx_txt中的噪声ϵθ(xt,t)\epsilon_\theta(x_t,t)ϵθ(xt,t),反向推导干净数据:
- 模型训练目标:学习噪声预测函数ϵθ(xt,t)\epsilon_\theta(x_t,t)ϵθ(xt,t),最小化“预测噪声”与“真实噪声”的MSE误差(论文公式2)。
二、论文对扩散模型的关键适配改造(核心创新点)
传统扩散模型多用于通用图像生成,论文针对HSI-MSI融合的“高维、数据稀缺、双组件同步更新”需求,做了4点关键改造,让扩散模型适配融合任务:
1. 加噪对象改造:从“高维HSI”到“低维组件”
- 传统扩散模型:直接对高维HR-HSI(H×W×CH×W×CH×W×C)加噪,计算量巨大;
- 论文改造:对HSI分解后的两个低维组件加噪(公式适配为At\mathcal{A}_tAt、Et\mathcal{E}_tEt):
At=α‾tA0+1−α‾tϵ,Et=α‾tE0+1−α‾tϵ\mathcal{A}_t = \sqrt{\overline{\alpha}_t}\mathcal{A}_0 + \sqrt{1-\overline{\alpha}_t}\epsilon, \quad \mathcal{E}_t = \sqrt{\overline{\alpha}_t}\mathcal{E}_0 + \sqrt{1-\overline{\alpha}_t}\epsilonAt=αtA0+1−αtϵ,Et=αtE0+1−αtϵ - 改造原因:A\mathcal{A}A(H×W×dH×W×dH×W×d)和E\mathcal{E}E(d×Cd×Cd×C)的维度远低于HSI(d=8≪Cd=8 \ll Cd=8≪C),加噪和去噪的计算量、内存消耗大幅降低,契合“轻量化”目标。
2. 反向过程改造:加入“双条件约束”(解决融合任务的针对性)
传统扩散模型多为无条件生成,论文需要让生成的组件符合LR-HSI(光谱)和HR-MSI(空间)约束,因此在反向过程中加入条件引导:
- 核心公式(论文公式9-10):在噪声预测函数中融入引导损失的梯度,让噪声预测“偏向”输入数据的特征:
s^θ(At,t)=sθ(At,t)−ρ1∇AtL(A^0,E^0,X,Y)\hat{s}_\theta(\mathcal{A}_t,t) = s_\theta(\mathcal{A}_t,t) - \rho_1 \nabla_{\mathcal{A}_t}\mathcal{L}(\hat{\mathcal{A}}_0,\hat{\mathcal{E}}_0,\mathcal{X},\mathcal{Y})s^θ(At,t)=sθ(At,t)−ρ1∇AtL(A^0,E^0,X,Y)
c^ζ(Et,t)=cζ(Et,t)−ρ2∇EtL(A^0,E^0,X,Y)\hat{c}_\zeta(\mathcal{E}_t,t) = c_\zeta(\mathcal{E}_t,t) - \rho_2 \nabla_{\mathcal{E}_t}\mathcal{L}(\hat{\mathcal{A}}_0,\hat{\mathcal{E}}_0,\mathcal{X},\mathcal{Y})c^ζ(Et,t)=cζ(Et,t)−ρ2∇EtL(A^0,E^0,X,Y) - 引导损失L\mathcal{L}L的作用:量化A^0×3E^0\hat{\mathcal{A}}_0×_3\hat{\mathcal{E}}_0A^0×3E^0与X\mathcal{X}X(光谱约束)、Y\mathcal{Y}Y(空间约束)的差异,确保去噪过程不“跑偏”。
3. 优化策略改造:融入Adam优化(加速收敛)
传统扩散模型的反向过程易出现梯度震荡,论文在噪声预测修正中融入Adam优化器(论文公式13-15):
- 核心逻辑:通过Adam的一阶矩(mmm)和二阶矩(vvv)估计,修正引导损失的梯度,避免步长过大或震荡,让A\mathcal{A}A和E\mathcal{E}E的更新更稳定;
- 最终噪声预测修正公式:
s^θ(At,t)=sθ(At,t)−ρ1m^t−1(A)v^t−1(A)+ϵ\hat{s}_\theta(\mathcal{A}_t,t) = s_\theta(\mathcal{A}_t,t) - \rho_1 \frac{\hat{m}_{t-1}^{(\mathcal{A})}}{\sqrt{\hat{v}_{t-1}^{(\mathcal{A})}}+\epsilon}s^θ(At,t)=sθ(At,t)−ρ1v^t−1(A)+ϵm^t−1(A)
(E\mathcal{E}E的修正逻辑一致)。
4. 稳定性改造:加入ARGM模块(解决双组件对齐问题)
传统扩散模型仅更新单个数据对象,论文需同步更新A\mathcal{A}A和E\mathcal{E}E,易出现对齐偏差,因此在每步反向扩散后加入ARGM模块:
- 核心逻辑:计算At−1×3Et−1\mathcal{A}_{t-1}×_3\mathcal{E}_{t-1}At−1×3Et−1与X\mathcal{X}X、Y\mathcal{Y}Y的残差损失(论文公式16),并微调两个组件(论文公式17),确保两者对齐;
- 对扩散模型的价值:避免双组件同步更新导致的“生成崩溃”,让反向去噪过程更稳定,最终提升HR-HSI的融合质量。
三、论文中扩散模型的核心逻辑总结
1. 完整流程(正向→反向)
- 正向加噪:对干净的低维组件A0\mathcal{A}_0A0、E0\mathcal{E}_0E0,按α‾t\overline{\alpha}_tαt的噪声调度逐步加噪,生成t=Tt=Tt=T的含噪组件AT\mathcal{A}_TAT、ET\mathcal{E}_TET(训练阶段用于学习噪声预测);
- 反向去噪(推理阶段,重复T=500T=500T=500次“One step”):
- 从AT\mathcal{A}_TAT、ET\mathcal{E}_TET(纯噪声)出发,用双轻量网络预测初始噪声;
- 加入双条件引导和Adam优化,修正噪声预测;
- 生成At−1\mathcal{A}_{t-1}At−1、Et−1\mathcal{E}_{t-1}Et−1,并通过ARGM模块微调对齐;
- 迭代至t=0t=0t=0,得到干净组件A0\mathcal{A}_0A0、E0\mathcal{E}_0E0,乘积生成HR-HSI。
2. 与传统扩散模型的核心差异
| 维度 | 传统扩散模型 | 论文中的扩散模型(ARGS-Diff) |
|---|---|---|
| 加噪对象 | 高维原始数据(如图像) | 低维组件(A\mathcal{A}A、E\mathcal{E}E) |
| 生成约束 | 无条件(自由生成)或单条件 | 双条件(LR-HSI光谱约束+HR-MSI空间约束) |
| 更新对象 | 单个数据对象 | 双组件同步更新(A\mathcal{A}A+E\mathcal{E}E) |
| 稳定性优化 | 仅依赖噪声预测函数 | 加入ARGM模块+Adam优化 |
| 核心目标 | 通用图像生成/修复 | HSI-MSI融合(兼顾光谱真实性+空间清晰度) |
成对训练数据
一、成对训练数据的通俗理解(结合HSI-MSI融合场景)
成对训练数据本质是 “一一对应的监督学习样本对”,在HSI-MSI融合任务中,每一组“成对数据”包含3个核心部分,且满足“空间同一场景、时间同步”的约束:
- 核心参考数据:1张高分辨率高光谱图像(HR-HSI)——这是融合任务的“理想目标”,包含完整的空间细节和光谱信息;
- 配对输入数据1:1张低分辨率高光谱图像(LR-HSI)——由上述HR-HSI通过空间降采样(如论文中的双三次插值,缩放因子4)生成,仅保留光谱信息,空间分辨率降低;
- 配对输入数据2:1张高分辨率多光谱图像(HR-MSI)——由上述HR-HSI通过光谱响应函数(SRF)模拟生成,仅保留空间细节,光谱波段减少。
简单说:1个HR-HSI + 它对应的LR-HSI + 它对应的HR-MSI = 1组成对训练数据。
深度学习方法需要大量(通常数千/数万组)这样的样本对,才能通过监督学习训练出“从LR-HSI+HR-MSI映射到HR-HSI”的模型——就像用“标准答案(HR-HSI)”教模型“如何从残缺输入(LR-HSI+HR-MSI)还原完整信息”。
而遥感领域中,这样的成对数据获取极难:
- HR-HSI本身稀缺:高光谱传感器硬件昂贵,成像范围小、耗时久,难以大规模获取;
- “严格对应”难实现:要保证LR-HSI、HR-MSI与HR-HSI是同一地理区域、同一时刻拍摄(避免地形变化、光照差异),实际操作中成本极高。
二、这篇论文的方法:完全无需额外成对训练数据
论文的核心创新之一就是“自学习”,明确摆脱了对大规模成对训练数据的依赖,具体逻辑如下:
- 仅用“观测图像”完成训练:论文的训练过程只依赖测试时输入的单组观测数据(即1张LR-HSI + 1张HR-MSI),不需要任何额外的成对数据集;
- 样本构造不依赖HR-HSI:
- 光谱网络的训练样本:从输入的LR-HSI中随机选择d个像素的光谱向量,拼接成(d, C)大小的样本(利用LR-HSI的光谱信息);
- 空间网络的训练样本:从输入的HR-MSI中提取patch,随机选择1个波段重复d次,形成(H_patch, W_patch, d)的样本(利用HR-MSI的空间信息);
- 监督信号来自观测数据本身:通过“引导函数”和“残差损失”,直接用输入的LR-HSI(光谱约束)和HR-MSI(空间约束)作为监督,无需HR-HSI作为“标准答案”。
简单总结:传统深度学习方法需要“大量历史成对数据”提前训练模型,而这篇论文的方法是“针对单组输入数据现场自学习”,全程无需额外成对训练数据,完美解决了遥感领域数据稀缺的问题。
pavia.mat(预备知识)
这个问题很关键!pavia.mat 是 MATLAB 格式的二进制数据文件,核心用于存储高光谱图像(HSI)相关数据,是遥感图像处理、机器学习领域的经典数据集文件。
一、文件类型本质
- .mat 是 MATLAB 的原生数据格式,采用二进制存储,支持压缩和多种数据结构(数组、矩阵、结构体等)。
- 相比文本文件,它能高效存储大规模数值数据,尤其适合高光谱图像这类“高维度、大数据量”的科研数据。
- 可通过 Python(scipy.io/h5py 库)、MATLAB 直接读取,无需手动解析格式。
二、文件内核心数据(以 Pavia 高光谱数据集为例)
Pavia.mat 对应的是意大利帕维亚地区的高光谱遥感数据集(分 Pavia University 和 Pavia Center 两个子数据集),内部数据结构固定且标准化:
-
高光谱图像立方体(核心数据)
- 3 维矩阵(行数×列数×波段数),例如 Pavia University 是 610×340×103 维度。
- 每个元素代表“对应像素在某一波段的光谱反射率/辐射值”,103 个波段覆盖可见光到近红外光谱(430-860nm)。
- 用途:作为模型输入,进行地物分类、特征提取等任务。
-
地面真值标签(Ground Truth)
- 2 维矩阵(行数×列数),与图像尺寸完全匹配。
- 像素值代表地物类别(如 0=背景/未标注,1=沥青,2=草地,3=砾石,…,9=裸土等,共 9 类地物)。
- 用途:划分训练集/测试集,评估模型分类精度。
-
辅助元数据(可选)
- 以结构体形式存储,包含光谱波段的波长信息、成像时间、传感器参数(如 ROSIS 传感器的空间分辨率 1.3 米)等。
- 用途:辅助光谱特征分析(如选择特定波长范围进行实验)。
三、常见使用场景
- 科研领域:高光谱图像分类、降维、目标检测、小样本学习等算法的基准测试。
- 工具链:MATLAB 用于数据预处理,Python(PyTorch/TensorFlow)用于模型训练,均需读取该文件解析核心数据。
LR-HSI 和 HR-MSI(预备知识)
这个洞察很敏锐!LR-HSI 和 HR-MSI 是遥感图像融合领域的核心输入数据,两者互补短板,共同支撑“高分辨率高光谱图像(HR-HSI)重建”任务。下面用具体例子和直观对比,把两者的本质、特点和关联讲透。
核心结论
LR-HSI = 低分辨率(空间模糊)+ 高光谱(多波段);HR-MSI = 高分辨率(空间清晰)+ 多光谱(少波段),两者通过融合可得到“空间清晰+光谱丰富”的理想图像。
一、LR-HSI:低分辨率高光谱图像(Low-Resolution Hyperspectral Image)
1. 核心定义
- 全称:Low-Resolution Hyperspectral Image,直译“低空间分辨率高光谱图像”。
- 核心特征:光谱维度极丰富(数十到数百个波段),但空间分辨率低(像素对应地面范围大,图像模糊)。
2. 关键特点 + 实际例子
- 空间分辨率低:1个像素对应地面10-30米(甚至更大),比如某LR-HSI的空间分辨率是20米,意味着图像中1个点代表地面20×20米的区域,小目标(如单棵树、小型建筑)会模糊成一个像素。
- 光谱维度高:覆盖可见光、近红外、短波红外等多个光谱范围,波段数通常50+,甚至200+。
- 实例1:NASA的Hyperion传感器生成的LR-HSI,波段数242个(400-2500nm),空间分辨率30米,能精细区分“沥青、草地、水泥、植被品种”等光谱相似的地物。
- 实例2:实验室常用的“Pavia University 高光谱数据集”(对应你之前关注的.mat文件),本质是LR-HSI——空间分辨率1.3米(相对卫星数据较高,但属于高光谱数据的“低分辨率”范畴),波段数103个,能区分9类地物。
- 数据形态:3维矩阵(H×W×B),H/W是图像高度/宽度(如610×340),B是波段数(如103)。
- 优缺点:
- 优点:光谱信息“细”,能识别光谱相似的地物(如区分玉米和小麦、不同材质的屋顶);
- 缺点:空间信息“粗”,无法分辨小目标或地物细节(如分不清单棵树和树下阴影)。
二、HR-MSI:高分辨率多光谱图像(High-Resolution Multispectral Image)
1. 核心定义
- 全称:High-Resolution Multispectral Image,直译“高空间分辨率多光谱图像”。
- 核心特征:空间分辨率高(图像清晰),但光谱维度少(仅几个关键波段)。
2. 关键特点 + 实际例子
- 空间分辨率高:1个像素对应地面1-10米(甚至亚米级),比如某HR-MSI的空间分辨率是3米,能清晰看到单栋建筑、道路标线、单棵树木的轮廓。
- 光谱维度少:仅保留少数关键光谱波段(通常3-10个),聚焦地物的核心光谱差异。
- 实例1:Landsat 8卫星生成的HR-MSI,空间分辨率30米(卫星级高分辨率),仅8个多光谱波段(如蓝色、绿色、红色、近红外等),能区分“植被、水体、建筑、裸土”等大类地物。
- 实例2:大疆无人机搭载的多光谱相机生成的HR-MSI,空间分辨率0.5米(亚米级),仅5个波段(蓝、绿、红、红边、近红外),能清晰监测农田里的作物长势(但分不清作物品种)。
- 数据形态:3维矩阵(H×W×B),H/W通常比LR-HSI大(如1200×1200),B是波段数(如5-8)。
- 优缺点:
- 优点:空间信息“清”,能精准定位地物位置、识别小目标(如农田里的灌溉设备、道路上的车辆);
- 缺点:光谱信息“少”,无法区分光谱相似的地物(如玉米和小麦、沥青和水泥)。
三、LR-HSI 与 HR-MSI 的核心关联:为什么要一起用?
两者是“互补短板”的关系,单独使用都有局限,结合后可实现“1+1>2”:
- 场景需求:既要清晰看到地物细节(如单棵树的轮廓),又要精准识别地物类型(如这棵树是松树还是杨树);
- 融合逻辑:用 HR-MSI 的“高空间信息”弥补 LR-HSI 的“空间模糊”,用 LR-HSI 的“高光谱信息”弥补 HR-MSI 的“光谱不足”;
- 最终目标:生成 HR-HSI(高分辨率高光谱图像)——既清晰又能精细分类地物,广泛用于精准农业、环境监测、城市规划等场景。
直观对比表
| 对比维度 | LR-HSI(低分辨率高光谱) | HR-MSI(高分辨率多光谱) |
|---|---|---|
| 空间分辨率 | 低(10-30米/像素,甚至更大) | 高(0.5-10米/像素,亚米级常见) |
| 光谱波段数 | 多(50-200+个,覆盖全光谱) | 少(3-10个,仅关键波段) |
| 核心优势 | 光谱精细,能区分相似地物 | 空间清晰,能识别地物细节和小目标 |
| 核心局限 | 空间模糊,无法定位小目标 | 光谱粗糙,无法区分相似地物 |
| 典型传感器/数据集 | Hyperion卫星、Pavia高光谱数据集 | Landsat 8卫星、大疆多光谱无人机图像 |
四、实例:融合后的价值
假设用上述两个实例数据融合:
- 输入1:Hyperion的LR-HSI(30米分辨率,242个波段)——能区分“松树、杨树、柳树”,但看不到单棵树的轮廓;
- 输入2:Landsat 8的HR-MSI(30米分辨率,8个波段)——能看到单棵树的轮廓,但分不清树的品种;
- 融合后:HR-HSI(30米分辨率,242个波段)——既能清晰看到单棵树的轮廓,又能精准识别树的品种,还能统计每棵树的分布位置。
光谱和波段(预备知识)
这个问题问得特别基础且关键!理解光谱和波段是搞懂遥感图像(比如LR-HSI/HR-MSI)的核心前提,下面用“生活例子+专业场景”双层解释,保证彻底看明白。
核心结论
光谱 = 电磁波按波长排列的“完整光谱带”(像彩虹的完整颜色范围);波段 = 光谱中被划分出来的“一段特定波长区间”(像彩虹里的“红光段”“绿光段”),多个波段组合起来就是完整光谱。
一、光谱:电磁波的“完整波长序列”
1. 定义
光谱是 电磁波按波长(或频率)从短到长排列形成的连续序列,包含了人类可见和不可见的所有电磁波(如伽马射线、X射线、可见光、红外线、无线电波等)。
2. 通俗例子(生活中能感知的光谱)
- 最直观:彩虹——阳光(白光)经过水滴折射后,按波长分解成红、橙、黄、绿、蓝、靛、紫7种颜色,这就是“可见光谱”(光谱的一小部分)。
- 延伸理解:阳光不只是“7种颜色”,而是包含了波长400nm(紫光)到760nm(红光)的所有可见光,还包含波长760nm以上的“近红外光”(看不见,但能被遥感传感器捕捉)、400nm以下的“紫外光”(看不见,会晒伤皮肤)。
- 专业例子(遥感场景):高光谱传感器捕捉的“完整光谱”,会覆盖400nm(可见光)到2500nm(短波红外)的范围,这个连续的波长序列就是“遥感光谱”,包含了地物(植被、水体、建筑)的全部光谱信息。
3. 核心作用
不同物质(地物)对不同波长的电磁波有“吸收、反射、透射”的差异——比如植被对近红外光反射强,对红光吸收强;水体对可见光反射弱,对红外光几乎全吸收。这种差异就是“光谱特征”,是遥感识别地物的基础。
二、波段:光谱的“特定波长切片”
1. 定义
波段是 从完整光谱中截取的一段连续波长区间(相当于“光谱的一个片段”),每个波段有固定的波长范围(如“红光波段:620-760nm”)。
2. 通俗例子(生活+遥感)
- 生活例子:
- 彩虹的“红光段”(620-760nm)就是一个波段,“绿光段”(495-570nm)是另一个波段——7个颜色段就是7个可见波段,组合起来就是可见光谱。
- 手机相机的“RGB滤镜”:红色滤镜只允许红光波段(620-760nm)通过,绿色滤镜只允许绿光波段(495-570nm)通过,蓝色滤镜只允许蓝光波段(450-495nm)通过,三个波段组合就是我们看到的彩色照片。
- 遥感例子(关键!结合之前的LR-HSI/HR-MSI):
- HR-MSI(高分辨率多光谱)的波段:比如大疆无人机多光谱相机的5个波段——蓝光(450-510nm)、绿光(520-580nm)、红光(630-690nm)、红边(730-790nm)、近红外(800-860nm),每个波段对应光谱的一个“切片”。
- LR-HSI(低分辨率高光谱)的波段:比如Pavia高光谱数据集的103个波段,波长覆盖430-860nm,相当于把“可见光-近红外光谱”切成103个连续的小片段,每个片段的波长范围只有4nm左右(如430-434nm、434-438nm……),能捕捉地物更精细的光谱差异。
3. 核心作用
- 单个波段:只能捕捉地物在该波长的“单一特征”(如红光波段能区分植被和裸土,但分不清玉米和小麦)。
- 多个波段:组合起来就能形成地物的“光谱曲线”(每个波长对应的反射率值),不同地物的光谱曲线差异明显——比如玉米和小麦在“红边波段”的反射率不同,高光谱的103个波段能精准捕捉这种差异,而多光谱的5个波段则做不到。
三、光谱与波段的关系:整体与部分
| 关系维度 | 具体说明 |
|---|---|
| 包含关系 | 波段是光谱的“子集”,多个连续波段按波长排列,就组成了完整光谱。 |
| 数量关系 | 光谱是“连续的1个整体”,波段是“离散的多个片段”(片段越多,光谱越精细)。 |
| 应用关系 | 遥感传感器通过“分割光谱为多个波段”来捕捉信息——波段越多,能识别的地物越细。 |
直观类比
- 光谱 = 一整根“彩虹色的绳子”(从紫到红连续无断点)。
- 波段 = 把绳子剪成的“一段段彩色小段”(每段对应一种颜色/波长范围)。
- LR-HSI = 把绳子剪成103段(每段很短,细节丰富),HR-MSI = 把绳子剪成5段(每段很长,细节粗糙)。
四、遥感场景的关键补充(结合之前的对话)
- 为什么LR-HSI波段多?因为要捕捉地物“精细光谱差异”(比如区分沥青和水泥、松树和杨树)。
- 为什么HR-MSI波段少?因为要平衡“空间分辨率”和“数据量”——波段越多,数据量越大,传感器难以同时保证高空间分辨率。
- 融合的本质:用HR-MSI的“空间细节”(清晰轮廓),结合LR-HSI的“多波段光谱”(精细差异),生成既清晰又能精准分类的图像。
我可以帮你整理一份 “常见遥感波段及其用途表”,包含可见光、近红外、短波红外等常用波段的波长范围和实际应用(如植被监测、水体识别、建筑分类),方便你直接参考。需要吗?

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)