文本分析与多种算法融合:探索数据的奥秘
python和R语言文本分析LDA主题模型分词词频词云pyLDAvis困惑度 深度学习 遗传算法 机器学习 目标检测 贝叶斯 支持向量机 随机森林 代码注释说明完整
在数据科学领域,文本分析是挖掘信息的重要手段,结合各类强大的算法,能从文本数据中提取出有价值的见解。今天咱就唠唠 Python 和 R 语言在文本分析中的 LDA 主题模型,以及分词、词频、词云这些有趣的玩意儿,再顺带聊聊深度学习、遗传算法、机器学习里的目标检测,还有贝叶斯、支持向量机和随机森林这些经典算法。
Python 实现文本分析
分词与词频统计
在 Python 中,jieba库是常用的中文分词工具。假设我们有一段文本,先来做个简单的分词和词频统计。
import jieba
from collections import Counter
text = "自然语言处理是人工智能领域的重要研究方向,文本分析在其中起着关键作用。"
words = jieba.lcut(text)
word_count = Counter(words)
for word, count in word_count.items():
print(f"{word}: {count}")这段代码里,jieba.lcut 对文本进行精确分词,返回一个列表。Counter 类则用来统计每个词出现的次数。for 循环遍历这个统计结果并打印。
词云绘制
词云能直观展示文本中词汇的重要程度。借助 wordcloud 库可以轻松实现。
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# 假设前面已经得到词频统计结果 word_count
wc = WordCloud(width=800, height=400, background_color='white').generate_from_frequencies(word_count)
plt.figure(figsize=(10, 5))
plt.imshow(wc, interpolation='bilinear')
plt.axis('off')
plt.show()这里 WordCloud 类根据词频生成词云对象,设置了宽度、高度和背景色。generatefromfrequencies 方法从词频数据生成词云。最后用 matplotlib 展示词云。
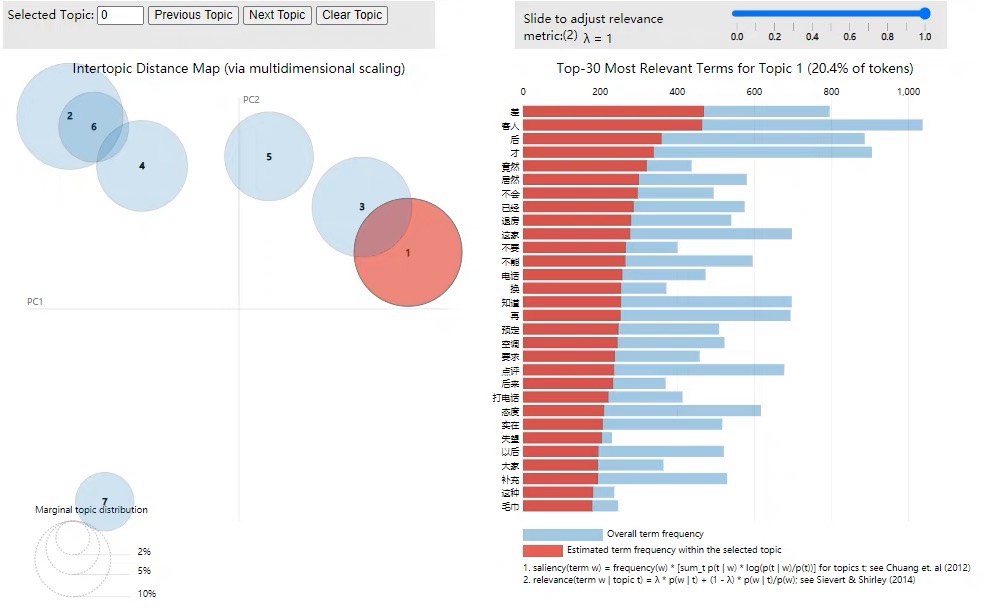
LDA 主题模型与困惑度
gensim 库让 Python 实现 LDA 主题模型变得简单。困惑度常用来评估 LDA 模型的质量。
from gensim import corpora, models
import gensim
texts = [["自然语言处理", "人工智能", "文本分析"], ["深度学习", "机器学习", "目标检测"]]
dictionary = corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
lda_model = models.LdaModel(corpus=corpus, id2word=dictionary, num_topics=2, passes=10)
# 计算困惑度
perplexity = lda_model.log_perplexity(corpus)
print(f"模型困惑度: {perplexity}")Dictionary 类构建词袋模型的词典,doc2bow 方法将文本转换为词袋向量。LdaModel 初始化 LDA 模型,指定主题数和迭代次数。log_perplexity 方法计算困惑度,困惑度越低,模型越好。
R 语言实现文本分析
分词与词频
在 R 中,tm 和 SnowballC 包用于文本处理。
library(tm)
library(SnowballC)
text <- "Natural language processing is an important research direction in the field of artificial intelligence, and text analysis plays a key role in it."
corpus <- Corpus(VectorSource(text))
corpus <- tm_map(corpus, content_transformer(tolower))
corpus <- tm_map(corpus, removePunctuation)
corpus <- tm_map(corpus, removeWords, stopwords("english"))
corpus <- tm_map(corpus, stemDocument)
dtm <- DocumentTermMatrix(corpus)
freq <- colSums(as.matrix(dtm))
freq <- sort(freq, decreasing = TRUE)
head(freq, 10)这段 R 代码中,Corpus 创建文本语料库,一系列 tm_map 操作对文本进行预处理,如转小写、去标点、去停用词和词干提取。DocumentTermMatrix 生成文档 - 词项矩阵,统计词频并排序展示前 10 个高频词。
LDA 主题模型
topicmodels 包可实现 LDA 模型。
library(topicmodels)
data <- as.matrix(dtm)
lda <- LDA(data, k = 2, control = list(seed = 1234))
topics <- topics(lda)
terms <- terms(lda, 10)
print(terms)这里将文档 - 词项矩阵作为输入,LDA 函数构建 LDA 模型,指定主题数 k。topics 提取每个文档的主题分配,terms 展示每个主题下的前 10 个关键词。
其他算法浅探
深度学习、遗传算法与目标检测
深度学习在目标检测上大放异彩,像 YOLO、Faster R-CNN 等模型。遗传算法可用于优化深度学习模型的超参数。比如通过遗传算法寻找卷积神经网络(CNN)的最佳层数、神经元数量等,以提升目标检测的准确率。
贝叶斯、支持向量机和随机森林
贝叶斯算法基于贝叶斯定理,常用于分类和预测,它能处理不确定性信息。支持向量机通过寻找最优超平面来分类数据,在小样本数据上表现出色。随机森林是多个决策树的集成,通过投票或平均等方式进行预测,具有较好的稳定性和泛化能力。
python和R语言文本分析LDA主题模型分词词频词云pyLDAvis困惑度 深度学习 遗传算法 机器学习 目标检测 贝叶斯 支持向量机 随机森林 代码注释说明完整
在实际应用中,根据数据特点和任务需求选择合适的算法,能达到事半功倍的效果。文本分析结合这些强大的算法,将不断拓展数据科学的边界,挖掘出更多隐藏在数据背后的价值。希望大家在数据探索的道路上越走越远,发现更多有趣的现象和规律。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)