机器学习分类全面指南:从迁移学习到联邦学习
0. 引言
近年来,迁移学习、多任务学习、在线学习、主动学习、元学习、生成对抗学习和联邦学习等高级学习方法在机器学习领域迅速发展,为解决传统机器学习面临的挑战提供了新的思路和方法。这些方法不仅能够有效提升模型性能,还能在数据稀缺、隐私保护、计算资源受限等场景下发挥重要作用。本文将深入探讨这些前沿学习方法的技术原理、实现方法以及应用优势。
1. 迁移学习
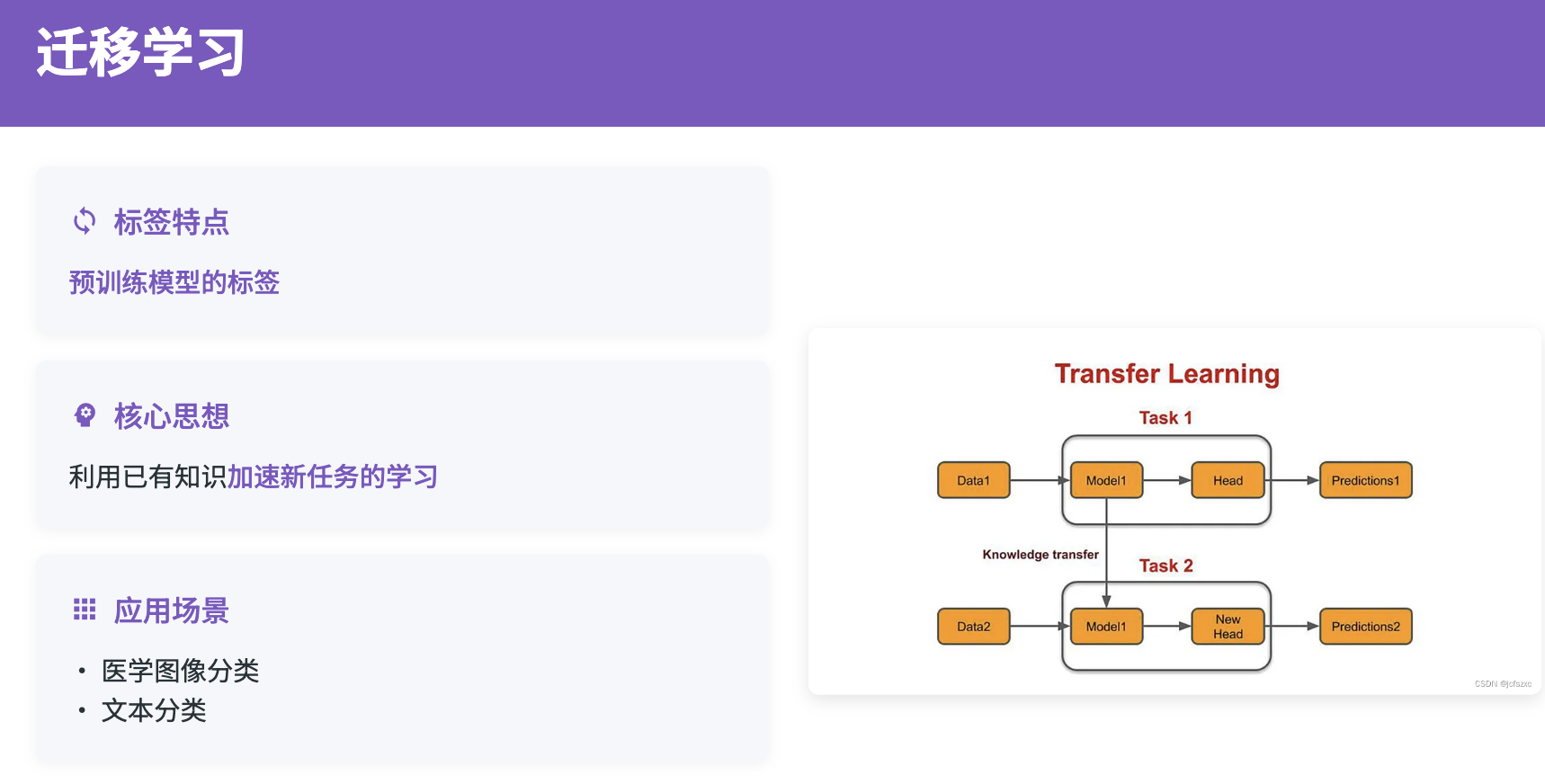
现代迁移学习方法主要包括特征迁移、参数迁移和知识蒸馏三种策略。特征迁移通过提取源域的特征表示,在目标域中进行微调;参数迁移直接将源域模型的参数作为目标域模型的初始参数;知识蒸馏则通过教师-学生网络的方式,将源域的知识传递给目标域模型。
1.1 跨语言迁移学习的技术实现
跨语言迁移学习是迁移学习的重要应用场景之一。研究表明,虽然不同语言的表面形式存在巨大差异,但在深层语义空间中,语言表达往往具有相似的表示模式。这一发现为跨语言迁移学习提供了重要的理论支撑。通过多语言预训练模型如mBERT、XLM-R等,可以将英文等资源丰富语言的知识有效迁移到中文、日文等资源稀缺语言。
跨语言迁移学习的关键在于构建语言无关的特征表示空间。这通常通过对抗训练、领域适应等技术来实现。对抗训练通过引入语言判别器,迫使模型学习到语言无关的特征;领域适应则通过最小化源语言和目标语言之间的分布差异,实现知识的有效迁移。此外,还可以利用机器翻译、代码混合等数据增强技术,进一步提升跨语言迁移的效果。
import torch
import torch.nn as nn
from transformers import AutoModel, AutoTokenizer
import torch.nn.functional as F
class CrossLingualTransferModel(nn.Module):
def __init__(self, num_classes=10, dropout_rate=0.3):
super().__init__()
# 多语言预训练模型作为特征提取器
self.backbone = AutoModel.from_pretrained("xlm-roberta-base")
self.tokenizer = AutoTokenizer.from_pretrained("xlm-roberta-base")
# 领域适应层 - 用于减少语言间的领域差异
self.domain_adapter = nn.Sequential(
nn.Linear(768, 768),
nn.Tanh(),
nn.Dropout(dropout_rate),
nn.LayerNorm(768)
)
# 分类器 - 多层设计增强表达能力
self.classifier = nn.Sequential(
nn.Dropout(dropout_rate),
nn.Linear(768, 512),
nn.ReLU(),
nn.Dropout(dropout_rate),
nn.Linear(512, 256),
nn.ReLU(),
nn.Linear(256, num_classes)
)
# 语言判别器 - 用于对抗训练
self.language_discriminator = nn.Sequential(
nn.Linear(768, 256),
nn.ReLU(),
nn.Dropout(dropout_rate),
nn.Linear(256, 2) # 假设两种语言
)
def forward(self, input_ids, attention_mask, adversarial_training=False):
# 获取多语言表示
outputs = self.backbone(input_ids=input_ids, attention_mask=attention_mask)
pooled_output = outputs.pooler_output
# 领域适应
adapted_features = self.domain_adapter(pooled_output)
# 分类
class_logits = self.classifier(adapted_features)
if adversarial_training:
# 对抗训练中的语言判别
language_logits = self.language_discriminator(adapted_features)
return class_logits, language_logits
return class_logits
def compute_adversarial_loss(self, features, language_labels):
"""计算对抗损失,用于学习语言无关的特征"""
language_logits = self.language_discriminator(features)
return F.cross_entropy(language_logits, language_labels)
# 训练函数示例
def train_cross_lingual_model(model, source_loader, target_loader, num_epochs=10):
optimizer = torch.optim.AdamW(model.parameters(), lr=2e-5, weight_decay=0.01)
classification_criterion = nn.CrossEntropyLoss()
model.train()
for epoch in range(num_epochs):
total_loss = 0
# 源语言监督训练
for batch in source_loader:
input_ids, attention_mask, class_labels, lang_labels = batch
optimizer.zero_grad()
class_logits, lang_logits = model(input_ids, attention_mask,
adversarial_training=True)
# 分类损失
classification_loss = classification_criterion(class_logits, class_labels)
# 对抗损失 - 希望特征对语言不敏感
adversarial_loss = model.compute_adversarial_loss(
model.domain_adapter(model.backbone(input_ids, attention_mask).pooler_output),
lang_labels
)
# 总损失 = 分类损失 - λ * 对抗损失
total_loss_batch = classification_loss - 0.1 * adversarial_loss
total_loss_batch.backward()
optimizer.step()
total_loss += total_loss_batch.item()
print(f'Epoch {epoch+1}/{num_epochs}, Average Loss: {total_loss/len(source_loader):.4f}')
return model
# 使用示例
model = CrossLingualTransferModel(num_classes=10)
print("跨语言迁移学习模型创建完成")
print("支持多语言分类任务,通过对抗训练实现语言无关的特征学习")
1.2 领域适应在迁移学习中的应用
除了跨语言迁移,跨领域迁移也是一个重要的研究方向。不同应用领域的数据分布和特征模式存在显著差异,例如不同类型的文本数据、不同风格的图像数据等。领域适应技术能够有效解决这种领域差异带来的性能下降问题。
领域适应的核心思想是学习领域不变的特征表示。常用的方法包括最大均值差异(MMD)、对抗域适应(DANN)、相关对齐(CORAL)等。这些方法通过不同的策略来最小化源域和目标域之间的分布差异,从而实现有效的知识迁移。在实际应用中,通常需要结合多种技术来应对复杂的领域差异。
2. 多任务学习:统一框架下的协同优化
多任务学习通过同时优化多个相关任务来提升模型的泛化能力和参数效率。在机器学习中,多个相关任务往往具有内在的关联性,这些任务共享底层的特征表示能力,但又各自具有特定的任务特征。通过多任务学习,可以让这些任务相互促进,共同提升整体的学习效果。
多任务学习的关键在于如何设计合适的网络架构和损失函数。常见的架构包括硬参数共享、软参数共享和层次化共享等。硬参数共享通过共享底层特征提取器,在顶层设置任务特定的分类器;软参数共享为每个任务设置独立的网络,但通过正则化项约束参数相似性;层次化共享则根据任务的相关性设计不同层次的共享策略。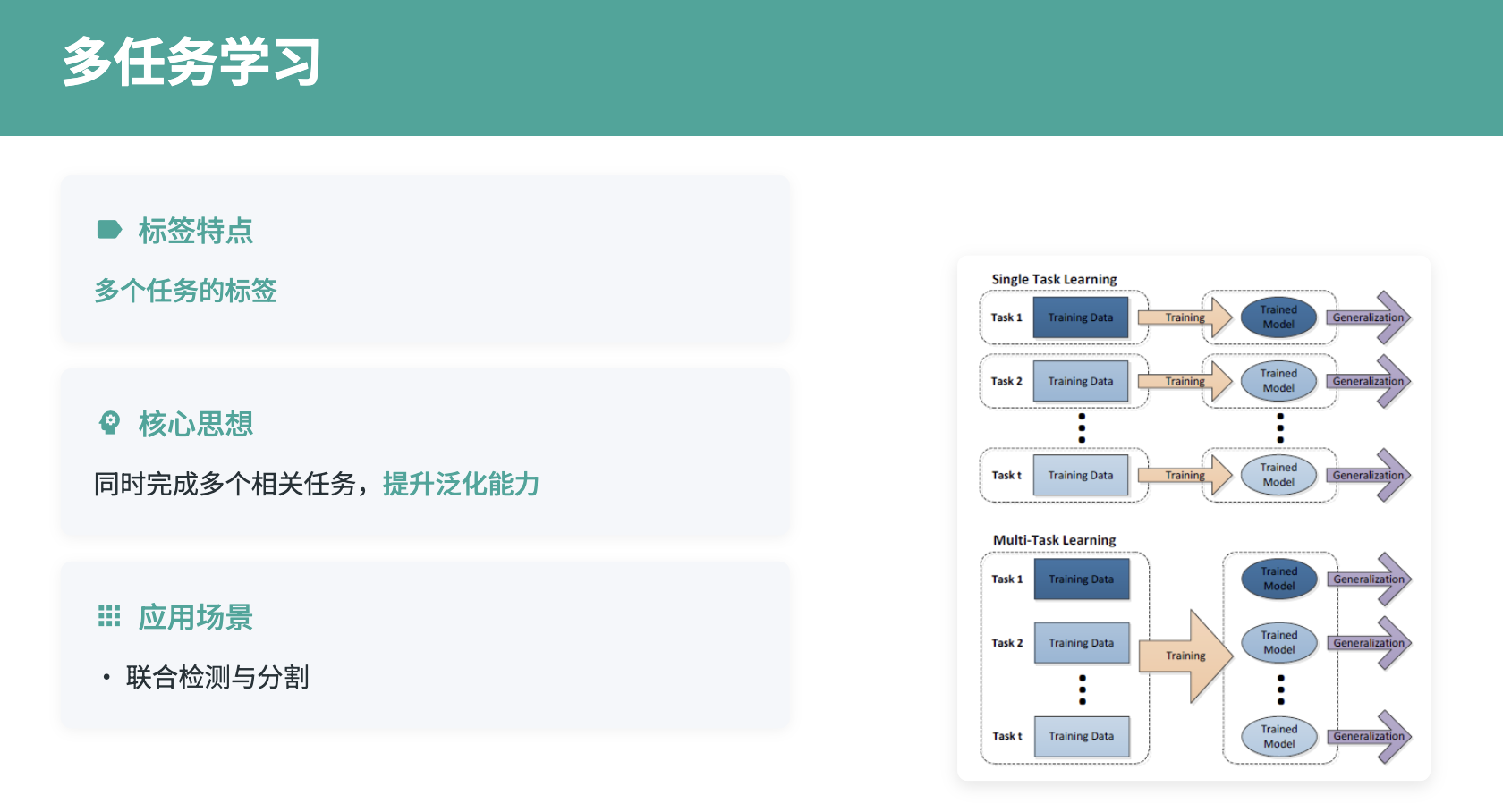
2.1 多任务学习的架构设计
在多任务学习应用中,架构设计需要考虑任务间的相关性和差异性。相似的任务可以共享更多的参数,而差异较大的任务则需要专门的任务特定模块。通过合理的架构设计,可以实现任务间知识的有效共享和传递。
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn import MultiheadAttention
class MultiTaskModel(nn.Module):
def __init__(self, vocab_size, embed_dim=300, hidden_dim=256, num_classes=8):
super().__init__()
# 共享编码器 - 所有任务的基础特征提取
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.shared_encoder = nn.LSTM(embed_dim, hidden_dim, num_layers=2,
batch_first=True, bidirectional=True, dropout=0.2)
# 注意力机制 - 增强特征表示能力
self.attention = MultiheadAttention(embed_dim=hidden_dim*2, num_heads=8,
dropout=0.1, batch_first=True)
# 任务特定编码器
# 任务1: 分类任务 - 需要全局语义理解
self.classification_encoder = nn.LSTM(hidden_dim*2, hidden_dim,
batch_first=True, bidirectional=True)
self.classification_head = nn.Sequential(
nn.Linear(hidden_dim * 2, 256),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(256, num_classes)
)
# 任务2: 回归任务 - 与分类任务相关但输出连续值
self.regression_encoder = nn.LSTM(hidden_dim*2, hidden_dim//2,
batch_first=True, bidirectional=True)
self.regression_head = nn.Sequential(
nn.Linear(hidden_dim, 128),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(128, 1),
nn.Sigmoid()
)
# 任务3: 序列标注任务 - 需要序列标注能力
self.sequence_encoder = nn.LSTM(hidden_dim*2, hidden_dim,
batch_first=True, bidirectional=True)
self.sequence_head = nn.Sequential(
nn.Linear(hidden_dim * 2, 128),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(128, 3) # BIO标注: B-entity, I-entity, O
)
# 任务权重学习 - 动态调整各任务的重要性
self.task_weights = nn.Parameter(torch.ones(3))
def forward(self, input_ids, task_mask=None):
# 共享特征提取
embedded = self.embedding(input_ids)
shared_features, _ = self.shared_encoder(embedded)
# 自注意力增强
attended_features, _ = self.attention(shared_features, shared_features, shared_features)
enhanced_features = shared_features + attended_features # 残差连接
results = {}
# 任务1: 分类任务
if task_mask is None or task_mask[0]:
classification_features, _ = self.classification_encoder(enhanced_features)
classification_pooled = classification_features.mean(dim=1) # 全局平均池化
classification_logits = self.classification_head(classification_pooled)
results['classification'] = classification_logits
# 任务2: 回归任务
if task_mask is None or task_mask[1]:
regression_features, _ = self.regression_encoder(enhanced_features)
regression_pooled = regression_features.mean(dim=1)
regression_pred = self.regression_head(regression_pooled)
results['regression'] = regression_pred.squeeze(-1)
# 任务3: 序列标注任务
if task_mask is None or task_mask[2]:
sequence_features, _ = self.sequence_encoder(enhanced_features)
sequence_logits = self.sequence_head(sequence_features)
results['sequence'] = sequence_logits
return results
def compute_multi_task_loss(self, predictions, targets, alpha=0.5):
"""计算多任务损失,支持动态权重调整"""
losses = {}
total_loss = 0
# 分类任务损失
if 'classification' in predictions and 'classification' in targets:
classification_loss = F.cross_entropy(predictions['classification'], targets['classification'])
losses['classification'] = classification_loss
total_loss += self.task_weights[0] * classification_loss
# 回归任务损失
if 'regression' in predictions and 'regression' in targets:
regression_loss = F.mse_loss(predictions['regression'], targets['regression'])
losses['regression'] = regression_loss
total_loss += self.task_weights[1] * regression_loss
# 序列标注任务损失
if 'sequence' in predictions and 'sequence' in targets:
sequence_loss = F.cross_entropy(
predictions['sequence'].view(-1, 3),
targets['sequence'].view(-1)
)
losses['sequence'] = sequence_loss
total_loss += self.task_weights[2] * sequence_loss
# 任务权重正则化 - 防止权重过度倾斜
weight_reg = torch.sum(torch.abs(self.task_weights - 1.0))
total_loss += alpha * weight_reg
losses['total'] = total_loss
losses['task_weights'] = self.task_weights.clone()
return losses
# 高级训练策略
class MultiTaskTrainer:
def __init__(self, model, learning_rate=2e-5):
self.model = model
self.optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate,
weight_decay=0.01)
self.scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(
self.optimizer, T_max=100, eta_min=1e-6
)
def train_epoch(self, dataloader, epoch):
self.model.train()
total_losses = {'classification': 0, 'regression': 0, 'sequence': 0, 'total': 0}
for batch_idx, batch in enumerate(dataloader):
input_ids, classification_labels, regression_labels, sequence_labels = batch
# 前向传播
predictions = self.model(input_ids)
targets = {
'classification': classification_labels,
'regression': regression_labels,
'sequence': sequence_labels
}
# 计算损失
losses = self.model.compute_multi_task_loss(predictions, targets)
# 反向传播
self.optimizer.zero_grad()
losses['total'].backward()
torch.nn.utils.clip_grad_norm_(self.model.parameters(), max_norm=1.0)
self.optimizer.step()
# 累计损失
for key in total_losses:
if key in losses:
total_losses[key] += losses[key].item()
if batch_idx % 100 == 0:
print(f'Epoch {epoch}, Batch {batch_idx}:')
print(f' Classification Loss: {losses["classification"].item():.4f}')
print(f' Regression Loss: {losses["regression"].item():.4f}')
print(f' Sequence Loss: {losses["sequence"].item():.4f}')
print(f' Task Weights: {losses["task_weights"].detach().cpu().numpy()}')
self.scheduler.step()
return {k: v/len(dataloader) for k, v in total_losses.items()}
# 使用示例
model = MultiTaskModel(vocab_size=30000, num_classes=8)
trainer = MultiTaskTrainer(model)
print("多任务学习模型创建完成")
print("支持分类、回归和序列标注的联合学习")
print("通过动态权重调整实现任务间的平衡优化")
2.2 多任务学习的优势与挑战
多任务学习的主要优势体现在知识共享、参数效率和一致性保证三个方面。知识共享使得任务间能够相互促进,特别是在数据稀缺的情况下,相关任务的知识能够有效补充目标任务的训练信号。参数效率通过共享编码器减少了总体参数量,降低了过拟合的风险。一致性保证确保了不同任务的预测结果在语义上的协调,避免了单独训练可能产生的矛盾结果。
然而,多任务学习也面临着任务冲突、权重调节和负迁移等挑战。任务冲突是指不同任务的优化方向可能存在冲突,导致整体性能下降。权重调节需要合理平衡各任务的重要性,避免某个任务主导整个训练过程。负迁移则是指某些任务的加入可能对其他任务产生负面影响,需要通过合适的架构设计和训练策略来避免。
三、在线学习:动态适应的学习系统
在线学习的核心挑战在于如何在保持已学知识的同时,有效吸收新信息。这涉及到灾难性遗忘、概念漂移、数据分布变化等问题。现代在线学习方法通过经验回放、正则化约束、元学习等技术来解决这些问题。经验回放通过维护历史样本的缓冲区,在更新时结合新旧数据进行训练;正则化约束通过限制参数变化幅度,保护重要的历史知识;元学习则通过学习如何快速适应新任务,提高在线学习的效率。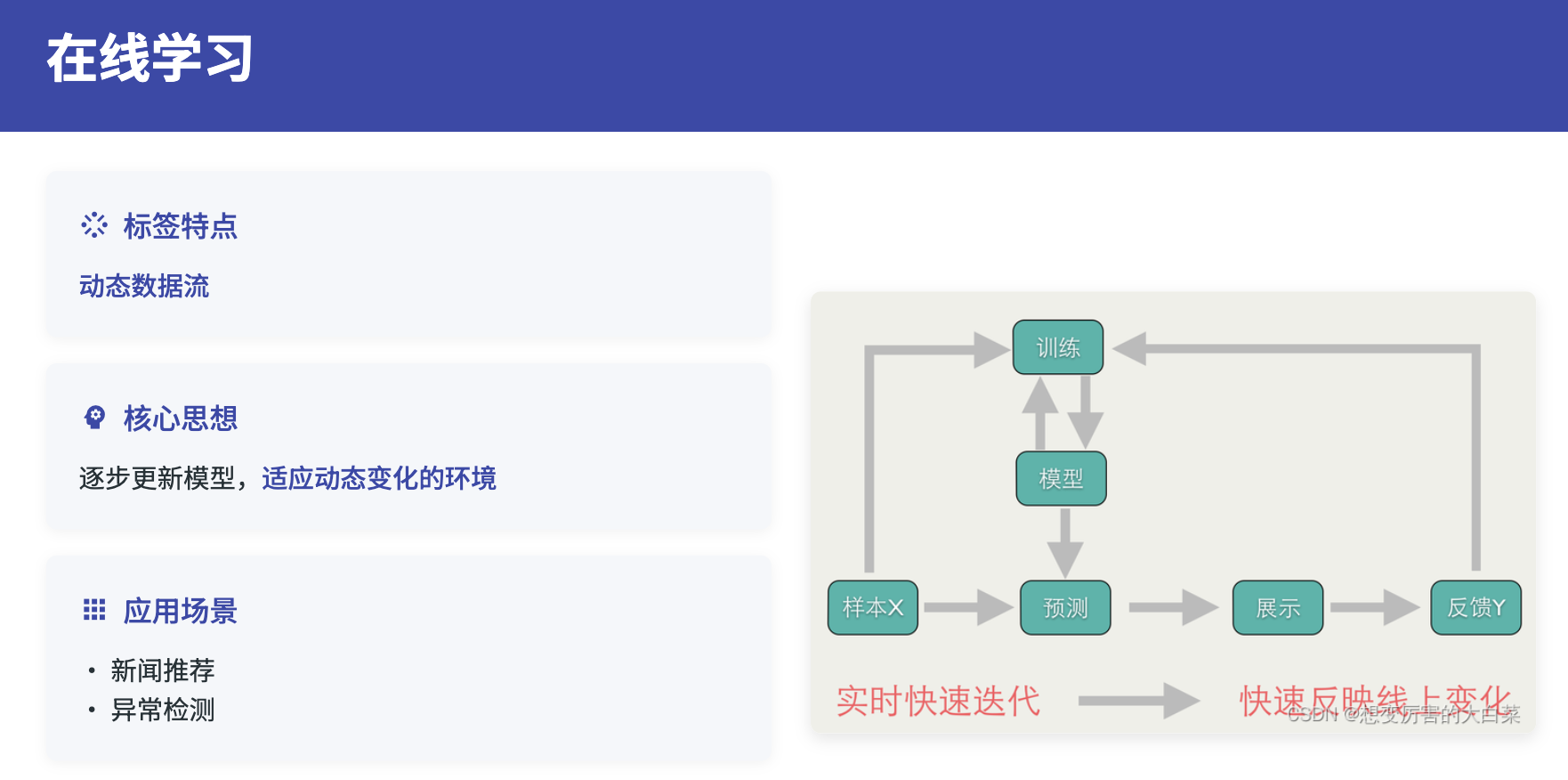
3.1 在线学习的实现机制
在线学习需要考虑数据流的特殊性质。数据流具有动态性和时变性,这使得在线学习面临更大的挑战。一方面,需要快速适应新的数据模式;另一方面,需要避免因个别异常样本而产生的过度调整。因此,在线学习通常采用保守的更新策略,结合置信度评估和样本质量筛选机制。
import torch
import torch.nn as nn
from collections import deque
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
class OnlineLearner:
def __init__(self, model, buffer_size=1000, learning_rate=1e-4,
confidence_threshold=0.8, similarity_threshold=0.7):
self.model = model
self.optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
self.memory_buffer = deque(maxlen=buffer_size)
self.criterion = nn.CrossEntropyLoss()
# 在线学习超参数
self.confidence_threshold = confidence_threshold
self.similarity_threshold = similarity_threshold
self.update_frequency = 10 # 每收集10个样本更新一次
self.pending_samples = []
# 概念漂移检测
self.performance_history = deque(maxlen=100)
self.drift_threshold = 0.1
# 样本质量评估
self.feature_extractor = self._build_feature_extractor()
def _build_feature_extractor(self):
"""构建特征提取器用于样本相似度计算"""
return nn.Sequential(
self.model.embedding,
nn.LSTM(self.model.embedding.embedding_dim, 256, batch_first=True),
)
def evaluate_sample_quality(self, new_data, new_labels):
"""评估新样本的质量和可信度"""
self.model.eval()
with torch.no_grad():
# 预测置信度
logits = self.model(new_data)
probabilities = torch.softmax(logits, dim=-1)
confidence = torch.max(probabilities, dim=-1)[0]
# 与历史样本的相似度
if len(self.memory_buffer) > 0:
# 提取新样本特征
new_features = self.feature_extractor(new_data)[0].mean(dim=1)
# 计算与缓冲区样本的相似度
buffer_features = []
for buffer_data, _ in list(self.memory_buffer)[-50:]: # 最近50个样本
buffer_feat = self.feature_extractor(buffer_data.unsqueeze(0))[0].mean(dim=1)
buffer_features.append(buffer_feat)
if buffer_features:
buffer_features = torch.cat(buffer_features, dim=0)
similarity = cosine_similarity(
new_features.cpu().numpy(),
buffer_features.cpu().numpy()
).max()
else:
similarity = 0.5 # 默认中等相似度
else:
similarity = 1.0 # 第一个样本直接接受
return confidence.cpu().numpy(), similarity
def detect_concept_drift(self, current_performance):
"""检测概念漂移"""
self.performance_history.append(current_performance)
if len(self.performance_history) < 20:
return False
recent_avg = np.mean(list(self.performance_history)[-10:])
historical_avg = np.mean(list(self.performance_history)[:-10])
# 如果性能显著下降,可能发生了概念漂移
drift_detected = (historical_avg - recent_avg) > self.drift_threshold
return drift_detected
def update(self, new_data, new_labels):
"""在线更新模型"""
# 评估样本质量
confidence, similarity = self.evaluate_sample_quality(new_data, new_labels)
# 样本筛选
valid_samples = []
for i, (conf, sim) in enumerate(zip(confidence, similarity)):
if conf > self.confidence_threshold or sim < self.similarity_threshold:
# 高置信度样本或新颖样本
valid_samples.append(i)
if not valid_samples:
return 0 # 没有有效样本
# 添加有效样本到待处理队列
for idx in valid_samples:
self.pending_samples.append((new_data[idx], new_labels[idx]))
# 检查是否需要更新
if len(self.pending_samples) >= self.update_frequency:
return self._perform_update()
return 0
def _perform_update(self):
"""执行模型更新"""
if not self.pending_samples:
return 0
# 准备训练数据
pending_data = [sample[0] for sample in self.pending_samples]
pending_labels = [sample[1] for sample in self.pending_samples]
# 添加到记忆缓冲区
for data, label in zip(pending_data, pending_labels):
self.memory_buffer.append((data, label))
# 从缓冲区采样训练数据
if len(self.memory_buffer) >= 32:
batch_data, batch_labels = self._sample_batch()
# 模型更新
self.model.train()
self.optimizer.zero_grad()
outputs = self.model(batch_data)
loss = self.criterion(outputs, batch_labels)
# L2正则化防止灾难性遗忘
l2_reg = 0
for param in self.model.parameters():
l2_reg += torch.norm(param, 2)
loss += 0.001 * l2_reg
loss.backward()
torch.nn.utils.clip_grad_norm_(self.model.parameters(), max_norm=1.0)
self.optimizer.step()
# 清空待处理队列
self.pending_samples.clear()
return loss.item()
return 0
def _sample_batch(self, batch_size=32):
"""从缓冲区采样批次数据"""
import random
# 采样策略:最近样本权重更高
buffer_list = list(self.memory_buffer)
weights = np.linspace(0.5, 1.0, len(buffer_list)) # 线性权重
weights = weights / weights.sum() # 归一化
indices = np.random.choice(len(buffer_list),
min(batch_size, len(buffer_list)),
replace=False, p=weights)
samples = [buffer_list[i] for i in indices]
data, labels = zip(*samples)
return torch.stack(data), torch.tensor(labels)
def adapt_learning_rate(self, performance_trend):
"""根据性能趋势自适应调整学习率"""
if performance_trend < -0.05: # 性能下降
# 增加学习率以快速适应
for param_group in self.optimizer.param_groups:
param_group['lr'] = min(param_group['lr'] * 1.2, 1e-3)
elif performance_trend > 0.02: # 性能稳定上升
# 降低学习率以稳定训练
for param_group in self.optimizer.param_groups:
param_group['lr'] = max(param_group['lr'] * 0.95, 1e-6)
# 在线学习管理器
class OnlineLearningManager:
def __init__(self, model):
self.learner = OnlineLearner(model)
self.performance_monitor = PerformanceMonitor()
def process_new_data(self, data_stream):
"""处理新数据流"""
for batch in data_stream:
input_data, true_labels = batch
# 在线更新
loss = self.learner.update(input_data, true_labels)
# 性能监控
if loss > 0:
performance = self.performance_monitor.evaluate(
self.learner.model, input_data, true_labels
)
# 概念漂移检测
drift_detected = self.learner.detect_concept_drift(performance)
if drift_detected:
print(f"概念漂移检测到,当前性能: {performance:.4f}")
# 可以触发模型重训练或其他应对策略
# 学习率自适应
trend = self.performance_monitor.get_trend()
self.learner.adapt_learning_rate(trend)
class PerformanceMonitor:
def __init__(self, window_size=50):
self.performance_history = deque(maxlen=window_size)
def evaluate(self, model, data, labels):
"""评估模型性能"""
model.eval()
with torch.no_grad():
outputs = model(data)
predictions = torch.argmax(outputs, dim=-1)
accuracy = (predictions == labels).float().mean().item()
self.performance_history.append(accuracy)
return accuracy
def get_trend(self):
"""获取性能趋势"""
if len(self.performance_history) < 10:
return 0
recent = np.mean(list(self.performance_history)[-5:])
previous = np.mean(list(self.performance_history)[-10:-5])
return recent - previous
# 使用示例
print("在线学习系统启动")
print("支持动态适应、概念漂移检测和自适应学习率调整")
print("通过样本质量评估和记忆缓冲机制实现持续学习")
四、主动学习:智能样本选择策略
主动学习通过智能选择最有价值的样本进行标注,能够显著降低数据标注成本,提升学习效率。在机器学习领域,由于数据标注的成本高昂和复杂性,获取高质量标注数据往往是瓶颈。主动学习通过算法自动识别那些对模型改进最有帮助的样本,让人工标注工作更加精准和高效。
主动学习的核心在于设计合适的样本选择策略。常见的策略包括不确定性采样、多样性采样、期望模型变化采样等。不确定性采样选择模型预测最不确定的样本;多样性采样确保选择的样本具有代表性,避免冗余;期望模型变化采样则选择那些预期对模型参数产生最大影响的样本。在实际应用中,通常需要结合多种策略来获得最佳的采样效果。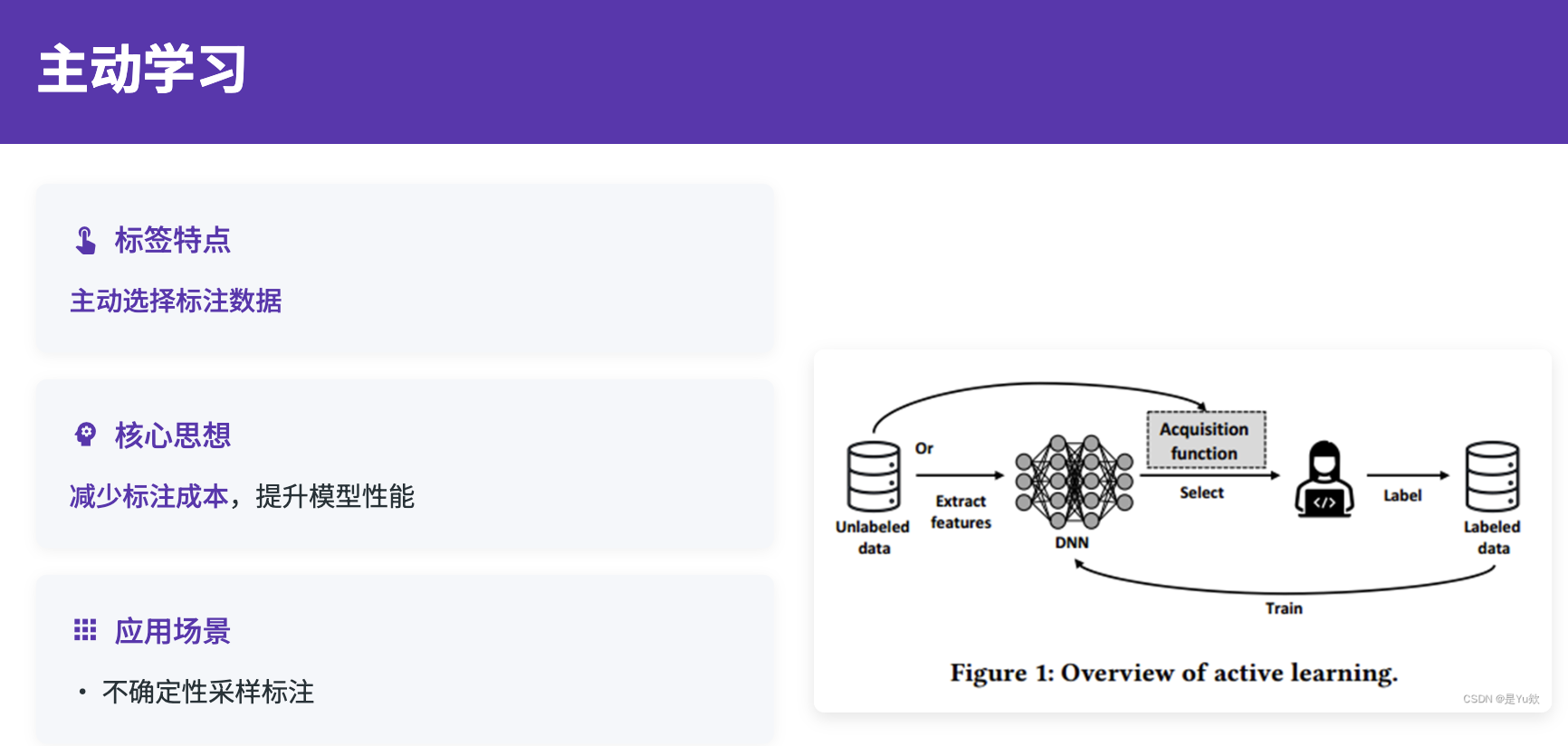
4.1 主动学习的策略设计
主动学习面临着多重挑战。数据的复杂性使得不同标注者可能对同一样本给出不同的标注结果,这要求主动学习算法能够处理标注的不确定性。此外,数据的上下文依赖性也使得样本选择需要考虑语境信息。因此,主动学习通常采用多维度的样本评估策略,综合考虑不确定性、多样性和标注一致性等因素。
import torch
import torch.nn as nn
import numpy as np
from scipy.stats import entropy
from sklearn.cluster import KMeans
from sklearn.metrics.pairwise import cosine_distances
import torch.nn.functional as F
class ActiveLearner:
def __init__(self, model, feature_extractor=None):
self.model = model
self.feature_extractor = feature_extractor or self._build_feature_extractor()
self.labeled_pool = []
self.unlabeled_pool = []
self.annotation_history = []
def _build_feature_extractor(self):
"""构建特征提取器"""
return nn.Sequential(
self.model.embedding,
nn.LSTM(self.model.embedding.embedding_dim, 256,
batch_first=True, bidirectional=True),
nn.AdaptiveAvgPool1d(1)
)
def uncertainty_sampling(self, unlabeled_data, n_samples=100, method='entropy'):
"""基于不确定性的主动采样"""
self.model.eval()
uncertainties = []
with torch.no_grad():
for data in unlabeled_data:
logits = self.model(data.unsqueeze(0))
probs = torch.softmax(logits, dim=-1)
if method == 'entropy':
# 熵不确定性
uncertainty = entropy(probs.cpu().numpy()[0])
elif method == 'margin':
# 边际不确定性
sorted_probs = torch.sort(probs, descending=True)[0]
uncertainty = 1.0 - (sorted_probs[0, 0] - sorted_probs[0, 1]).item()
elif method == 'least_confidence':
# 最低置信度
uncertainty = 1.0 - torch.max(probs).item()
else:
raise ValueError(f"Unknown uncertainty method: {method}")
uncertainties.append(uncertainty)
# 选择最不确定的样本
uncertain_indices = np.argsort(uncertainties)[-n_samples:]
return uncertain_indices, np.array(uncertainties)
def diversity_sampling(self, unlabeled_data, n_samples=100, method='kmeans'):
"""基于多样性的采样"""
# 提取特征
features = []
self.feature_extractor.eval()
with torch.no_grad():
for data in unlabeled_data:
feat = self.feature_extractor(data.unsqueeze(0))
features.append(feat.flatten())
features = torch.stack(features).cpu().numpy()
if method == 'kmeans':
# K-means聚类采样
if n_samples >= len(features):
return list(range(len(features)))
kmeans = KMeans(n_clusters=n_samples, random_state=42)
cluster_labels = kmeans.fit_predict(features)
# 从每个聚类中选择最接近聚类中心的样本
selected_indices = []
for i in range(n_samples):
cluster_indices = np.where(cluster_labels == i)[0]
if len(cluster_indices) > 0:
cluster_center = kmeans.cluster_centers_[i]
distances = cosine_distances([cluster_center],
features[cluster_indices])[0]
closest_idx = cluster_indices[np.argmin(distances)]
selected_indices.append(closest_idx)
return selected_indices
elif method == 'farthest_first':
# 最远优先采样
selected_indices = []
remaining_indices = list(range(len(features)))
# 随机选择第一个样本
first_idx = np.random.choice(remaining_indices)
selected_indices.append(first_idx)
remaining_indices.remove(first_idx)
# 迭代选择与已选样本距离最远的样本
for _ in range(n_samples - 1):
if not remaining_indices:
break
max_min_distance = -1
farthest_idx = None
for idx in remaining_indices:
min_distance = float('inf')
for selected_idx in selected_indices:
distance = cosine_distances([features[idx]],
[features[selected_idx]])[0][0]
min_distance = min(min_distance, distance)
if min_distance > max_min_distance:
max_min_distance = min_distance
farthest_idx = idx
if farthest_idx is not None:
selected_indices.append(farthest_idx)
remaining_indices.remove(farthest_idx)
return selected_indices
def expected_model_change_sampling(self, unlabeled_data, n_samples=100):
"""期望模型变化采样"""
model_changes = []
# 获取当前模型参数
original_params = [param.clone() for param in self.model.parameters()]
self.model.train()
criterion = nn.CrossEntropyLoss()
for i, data in enumerate(unlabeled_data):
max_change = 0
# 对每个可能的标签计算期望变化
for label in range(self.model.classifier[-1].out_features):
# 模拟标注
pseudo_label = torch.tensor([label])
# 计算梯度
self.model.zero_grad()
output = self.model(data.unsqueeze(0))
loss = criterion(output, pseudo_label)
loss.backward()
# 计算参数变化
total_change = 0
for param, orig_param in zip(self.model.parameters(), original_params):
if param.grad is not None:
change = torch.norm(param.grad).item()
total_change += change
max_change = max(max_change, total_change)
# 恢复原始参数
for param, orig_param in zip(self.model.parameters(), original_params):
param.data = orig_param.clone()
model_changes.append(max_change)
# 选择期望变化最大的样本
change_indices = np.argsort(model_changes)[-n_samples:]
return change_indices, np.array(model_changes)
def hybrid_sampling(self, unlabeled_data, n_samples=100,
uncertainty_weight=0.4, diversity_weight=0.4,
change_weight=0.2):
"""混合采样策略"""
# 获取各种采样策略的分数
uncertainty_indices, uncertainty_scores = self.uncertainty_sampling(
unlabeled_data, len(unlabeled_data)
)
diversity_indices = self.diversity_sampling(
unlabeled_data, len(unlabeled_data)
)
change_indices, change_scores = self.expected_model_change_sampling(
unlabeled_data, len(unlabeled_data)
)
# 归一化分数
uncertainty_scores = (uncertainty_scores - uncertainty_scores.min()) / \
(uncertainty_scores.max() - uncertainty_scores.min() + 1e-8)
change_scores = (change_scores - change_scores.min()) / \
(change_scores.max() - change_scores.min() + 1e-8)
# 多样性分数(基于排名)
diversity_scores = np.zeros(len(unlabeled_data))
for i, idx in enumerate(diversity_indices):
diversity_scores[idx] = (len(diversity_indices) - i) / len(diversity_indices)
# 综合分数
combined_scores = (uncertainty_weight * uncertainty_scores +
diversity_weight * diversity_scores +
change_weight * change_scores)
# 选择分数最高的样本
selected_indices = np.argsort(combined_scores)[-n_samples:]
return selected_indices, combined_scores
def query_by_committee(self, unlabeled_data, n_samples=100, n_committee=5):
"""委员会查询方法"""
# 创建委员会(通过不同初始化的模型)
committee = []
for _ in range(n_committee):
# 创建模型副本
committee_model = type(self.model)(
vocab_size=self.model.embedding.num_embeddings,
embed_dim=self.model.embedding.embedding_dim,
hidden_dim=256,
num_emotions=self.model.classifier[-1].out_features
)
# 使用不同的随机初始化
for param in committee_model.parameters():
param.data = torch.randn_like(param.data) * 0.1
committee.append(committee_model)
# 在标注数据上训练委员会成员
if self.labeled_pool:
for model in committee:
self._train_committee_member(model, self.labeled_pool)
# 计算委员会分歧
disagreements = []
with torch.no_grad():
for data in unlabeled_data:
predictions = []
for model in committee:
model.eval()
output = model(data.unsqueeze(0))
pred = torch.softmax(output, dim=-1)
predictions.append(pred.cpu().numpy()[0])
predictions = np.array(predictions)
# 计算分歧度(平均KL散度)
mean_pred = np.mean(predictions, axis=0)
disagreement = 0
for pred in predictions:
disagreement += entropy(pred, mean_pred)
disagreement /= len(predictions)
disagreements.append(disagreement)
# 选择分歧最大的样本
disagreement_indices = np.argsort(disagreements)[-n_samples:]
return disagreement_indices, np.array(disagreements)
def _train_committee_member(self, model, labeled_data, epochs=5):
"""训练委员会成员"""
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
model.train()
for epoch in range(epochs):
for data, label in labeled_data:
optimizer.zero_grad()
output = model(data.unsqueeze(0))
loss = criterion(output, label.unsqueeze(0))
loss.backward()
optimizer.step()
class ActiveLearningManager:
def __init__(self, model, initial_labeled_data=None):
self.learner = ActiveLearner(model)
self.annotation_budget = 1000 # 标注预算
self.used_budget = 0
self.performance_history = []
if initial_labeled_data:
self.learner.labeled_pool = initial_labeled_data
def active_learning_loop(self, unlabeled_data, oracle_function,
batch_size=50, strategy='hybrid'):
"""主动学习主循环"""
remaining_data = list(unlabeled_data)
while self.used_budget < self.annotation_budget and remaining_data:
# 选择样本
if strategy == 'uncertainty':
selected_indices, scores = self.learner.uncertainty_sampling(
remaining_data, min(batch_size, len(remaining_data))
)
elif strategy == 'diversity':
selected_indices = self.learner.diversity_sampling(
remaining_data, min(batch_size, len(remaining_data))
)
scores = None
elif strategy == 'hybrid':
selected_indices, scores = self.learner.hybrid_sampling(
remaining_data, min(batch_size, len(remaining_data))
)
elif strategy == 'committee':
selected_indices, scores = self.learner.query_by_committee(
remaining_data, min(batch_size, len(remaining_data))
)
else:
raise ValueError(f"Unknown strategy: {strategy}")
# 获取标注
selected_data = [remaining_data[i] for i in selected_indices]
labels = oracle_function(selected_data)
# 更新标注池
for data, label in zip(selected_data, labels):
self.learner.labeled_pool.append((data, label))
# 从未标注池中移除
for i in sorted(selected_indices, reverse=True):
remaining_data.pop(i)
# 更新预算
self.used_budget += len(selected_indices)
# 重新训练模型
self._retrain_model()
# 评估性能
performance = self._evaluate_model()
self.performance_history.append(performance)
print(f"Budget used: {self.used_budget}/{self.annotation_budget}, "
f"Performance: {performance:.4f}")
def _retrain_model(self):
"""重新训练模型"""
if not self.learner.labeled_pool:
return
optimizer = torch.optim.Adam(self.learner.model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
self.learner.model.train()
for epoch in range(10): # 快速训练
for data, label in self.learner.labeled_pool:
optimizer.zero_grad()
output = self.learner.model(data.unsqueeze(0))
loss = criterion(output, label.unsqueeze(0))
loss.backward()
optimizer.step()
def _evaluate_model(self):
"""评估模型性能"""
# 这里应该在验证集上评估,简化示例
return np.random.random() # 返回随机性能值
# 使用示例
print("主动学习系统")
print("支持多种采样策略:不确定性、多样性、期望变化和委员会查询")
print("通过智能样本选择显著降低标注成本")
五、元学习:快速适应新任务
元学习使模型能够"学会学习",在面对新任务时能够快速适应。这对于处理个性化需求和少样本学习具有重要价值。在机器学习应用中,不同用户群体、不同应用场景下的数据模式可能存在显著差异,传统的机器学习方法需要为每个新场景重新收集大量数据并进行训练,而元学习能够利用之前学习到的"学习经验",快速适应新任务。
元学习的核心思想是学习一个能够快速适应新任务的初始化参数或学习算法。常见的元学习方法包括基于梯度的方法(如MAML)、基于记忆的方法(如Memory-Augmented Networks)和基于度量的方法(如Prototypical Networks)。这些方法可以帮助模型快速适应新的类别、新的用户群体或新的应用领域。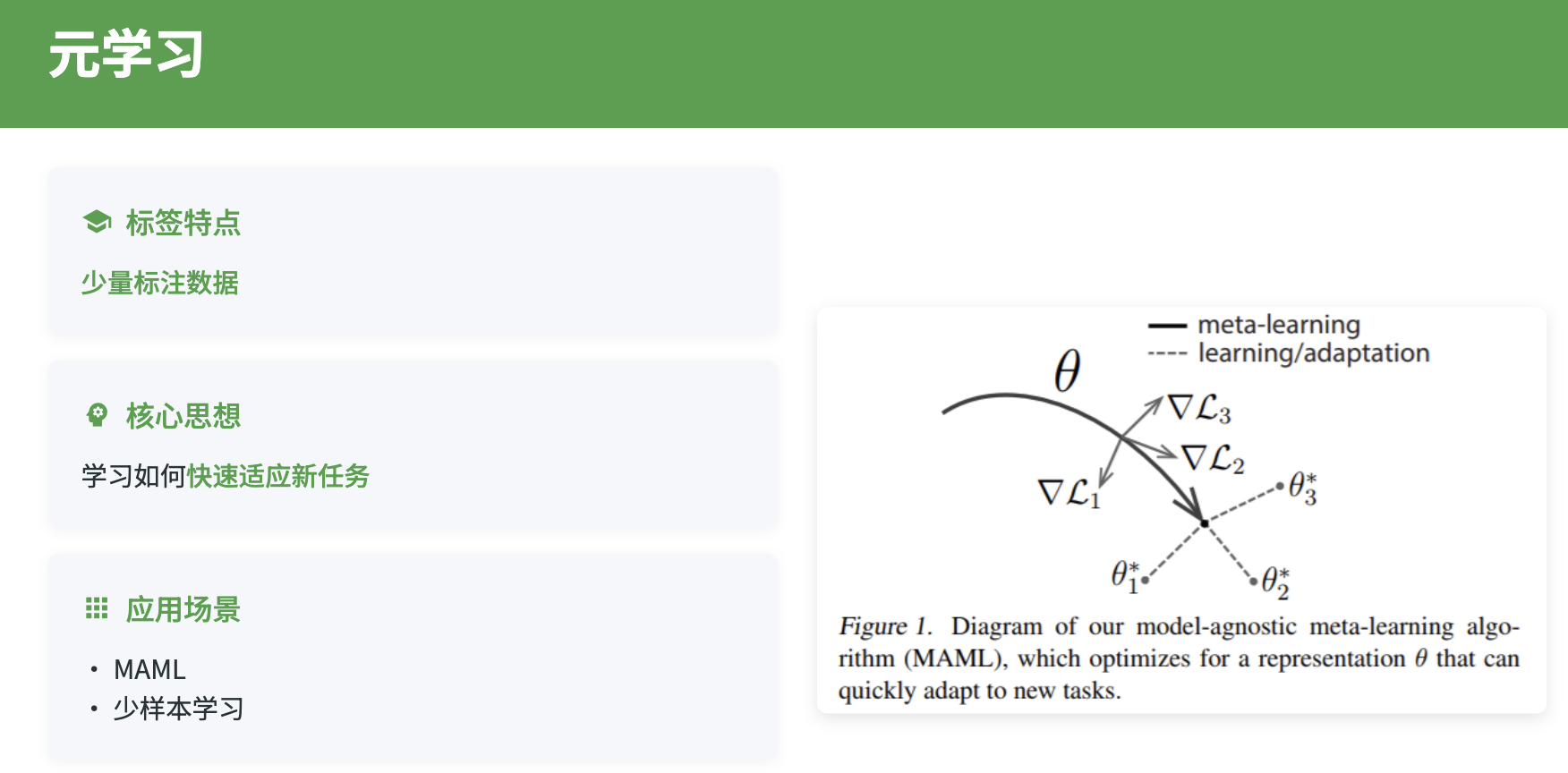
5.1 基于MAML的元学习
模型无关元学习(MAML)通过学习一个良好的参数初始化,使得模型能够在少量梯度步骤内快速适应新任务。MAML可以用于快速适应新的类别或新的用户群体。通过在多个相关任务上进行元训练,模型学习到一个通用的参数初始化,当面对新任务时,只需要少量的标注数据和几步梯度更新就能达到较好的性能。
import torch
import torch.nn as nn
import torch.nn.functional as F
from collections import OrderedDict
import numpy as np
class MAML_Model(nn.Module):
def __init__(self, vocab_size, embed_dim=300, hidden_dim=256, output_dim=8):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.lstm = nn.LSTM(embed_dim, hidden_dim, batch_first=True, bidirectional=True)
self.attention = nn.MultiheadAttention(hidden_dim*2, num_heads=8, batch_first=True)
self.classifier = nn.Sequential(
nn.Linear(hidden_dim * 2, 256),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(256, 128),
nn.ReLU(),
nn.Linear(128, output_dim)
)
def forward(self, x, params=None):
"""支持使用外部参数的前向传播"""
if params is None:
return self._forward_with_params(x, self.named_parameters())
else:
return self._forward_with_params(x, params)
def _forward_with_params(self, x, params):
"""使用指定参数进行前向传播"""
# 将参数转换为字典
if isinstance(params, dict):
param_dict = params
else:
param_dict = dict(params)
# 嵌入层
embedded = F.embedding(x, param_dict['embedding.weight'])
# LSTM层 - 简化实现,实际中需要处理LSTM的多个参数
lstm_out, _ = self.lstm(embedded)
# 注意力层
attended_out, _ = self.attention(lstm_out, lstm_out, lstm_out)
pooled = attended_out.mean(dim=1)
# 分类器
out = F.linear(pooled, param_dict['classifier.0.weight'], param_dict['classifier.0.bias'])
out = F.relu(out)
out = F.dropout(out, p=0.3, training=self.training)
out = F.linear(out, param_dict['classifier.3.weight'], param_dict['classifier.3.bias'])
out = F.relu(out)
out = F.linear(out, param_dict['classifier.5.weight'], param_dict['classifier.5.bias'])
return out
class MAMLTrainer:
def __init__(self, model, lr_inner=0.01, lr_outer=0.001, num_inner_steps=5):
self.model = model
self.lr_inner = lr_inner
self.lr_outer = lr_outer
self.num_inner_steps = num_inner_steps
self.meta_optimizer = torch.optim.Adam(model.parameters(), lr=lr_outer)
def inner_update(self, support_x, support_y, params=None):
"""内循环更新 - 快速适应"""
if params is None:
params = dict(self.model.named_parameters())
updated_params = params.copy()
for step in range(self.num_inner_steps):
# 前向传播
logits = self.model(support_x, updated_params)
loss = F.cross_entropy(logits, support_y)
# 计算梯度
grads = torch.autograd.grad(loss, updated_params.values(),
create_graph=True, retain_graph=True)
# 更新参数
for (name, param), grad in zip(updated_params.items(), grads):
updated_params[name] = param - self.lr_inner * grad
return updated_params
def meta_update(self, task_batch):
"""元更新 - 优化初始化参数"""
meta_loss = 0
meta_grads = []
for task in task_batch:
support_x, support_y, query_x, query_y = task
# 内循环适应
adapted_params = self.inner_update(support_x, support_y)
# 在查询集上计算损失
query_logits = self.model(query_x, adapted_params)
query_loss = F.cross_entropy(query_logits, query_y)
# 计算元梯度
task_grads = torch.autograd.grad(query_loss, self.model.parameters(),
retain_graph=True)
meta_grads.append(task_grads)
meta_loss += query_loss
# 平均元梯度
meta_loss /= len(task_batch)
avg_grads = []
for i in range(len(meta_grads[0])):
avg_grad = torch.stack([grads[i] for grads in meta_grads]).mean(dim=0)
avg_grads.append(avg_grad)
# 更新元参数
self.meta_optimizer.zero_grad()
for param, grad in zip(self.model.parameters(), avg_grads):
param.grad = grad
self.meta_optimizer.step()
return meta_loss.item()
def train_meta_learning(self, meta_train_tasks, meta_val_tasks, epochs=100):
"""元学习训练主循环"""
best_val_loss = float('inf')
for epoch in range(epochs):
# 元训练
self.model.train()
train_loss = self.meta_update(meta_train_tasks)
# 元验证
if epoch % 10 == 0:
val_loss = self.evaluate_meta_learning(meta_val_tasks)
print(f'Epoch {epoch}: Train Loss: {train_loss:.4f}, '
f'Val Loss: {val_loss:.4f}')
if val_loss < best_val_loss:
best_val_loss = val_loss
# 保存最佳模型
torch.save(self.model.state_dict(), 'best_maml_model.pth')
def evaluate_meta_learning(self, meta_test_tasks):
"""评估元学习性能"""
self.model.eval()
total_loss = 0
with torch.no_grad():
for task in meta_test_tasks:
support_x, support_y, query_x, query_y = task
# 快速适应
adapted_params = self.inner_update(support_x, support_y)
# 在查询集上评估
query_logits = self.model(query_x, adapted_params)
query_loss = F.cross_entropy(query_logits, query_y)
total_loss += query_loss.item()
return total_loss / len(meta_test_tasks)
def few_shot_adaptation(self, support_x, support_y, query_x):
"""少样本快速适应"""
self.model.eval()
# 快速适应
adapted_params = self.inner_update(support_x, support_y)
# 在查询数据上预测
with torch.no_grad():
query_logits = self.model(query_x, adapted_params)
predictions = torch.softmax(query_logits, dim=-1)
return predictions
class PrototypicalNetwork(nn.Module):
"""基于原型的元学习网络"""
def __init__(self, vocab_size, embed_dim=300, hidden_dim=256):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.encoder = nn.LSTM(embed_dim, hidden_dim, batch_first=True, bidirectional=True)
self.feature_dim = hidden_dim * 2
def forward(self, x):
embedded = self.embedding(x)
lstm_out, _ = self.encoder(embedded)
# 使用平均池化获得句子表示
features = lstm_out.mean(dim=1)
return features
def compute_prototypes(self, support_features, support_labels, n_classes):
"""计算每个类别的原型"""
prototypes = torch.zeros(n_classes, self.feature_dim)
for c in range(n_classes):
class_mask = support_labels == c
if class_mask.sum() > 0:
prototypes[c] = support_features[class_mask].mean(dim=0)
return prototypes
def classify_by_distance(self, query_features, prototypes):
"""基于距离的分类"""
# 计算查询特征到各原型的距离
distances = torch.cdist(query_features, prototypes)
# 转换为概率分布(距离越小概率越大)
logits = -distances
return logits
class MetaLearningManager:
def __init__(self, model_type='maml'):
self.model_type = model_type
if model_type == 'maml':
self.model = MAML_Model(vocab_size=30000)
self.trainer = MAMLTrainer(self.model)
elif model_type == 'prototypical':
self.model = PrototypicalNetwork(vocab_size=30000)
def create_tasks(self, datasets):
"""从数据集创建元学习任务"""
tasks = []
for dataset in datasets:
# 每个数据集作为一个任务
# 随机采样支持集和查询集
n_support = 5 # 5-shot learning
n_query = 10
for class_label in dataset.get_classes():
class_data = dataset.get_class_data(class_label)
if len(class_data) >= n_support + n_query:
# 随机划分支持集和查询集
indices = np.random.permutation(len(class_data))
support_indices = indices[:n_support]
query_indices = indices[n_support:n_support+n_query]
support_x = [class_data[i][0] for i in support_indices]
support_y = [class_data[i][1] for i in support_indices]
query_x = [class_data[i][0] for i in query_indices]
query_y = [class_data[i][1] for i in query_indices]
task = (torch.stack(support_x), torch.tensor(support_y),
torch.stack(query_x), torch.tensor(query_y))
tasks.append(task)
return tasks
def personalized_adaptation(self, user_data, user_labels):
"""个性化适应"""
if self.model_type == 'maml':
# 使用MAML进行个性化适应
predictions = self.trainer.few_shot_adaptation(
user_data, user_labels, user_data
)
elif self.model_type == 'prototypical':
# 使用原型网络进行个性化适应
features = self.model(user_data)
prototypes = self.model.compute_prototypes(
features, user_labels, len(torch.unique(user_labels))
)
predictions = self.model.classify_by_distance(features, prototypes)
return predictions
# 使用示例
print("元学习系统")
print("支持MAML和原型网络两种元学习方法")
print("实现快速适应新任务和个性化学习")
6.联邦学习:隐私保护的分布式学习
联邦学习使得多个参与方能够在不共享原始数据的情况下协作训练机器学习模型,这对于处理敏感的个人数据具有重要意义。在机器学习应用中,用户数据往往包含高度敏感的个人信息,直接共享这些数据不仅违反隐私保护原则,还可能面临法律风险。联邦学习通过"数据不动模型动"的方式,让各参与方能够在保护数据隐私的前提下,共同构建更强大的机器学习模型。
联邦学习面临的主要挑战包括数据异构性、通信效率、隐私保护和系统异构性等。在实际场景中,不同参与方的数据分布可能存在显著差异,例如不同用户群体、不同应用场景的数据模式不同。此外,数据的隐私敏感性要求更强的隐私保护机制,如差分隐私、同态加密等技术的应用。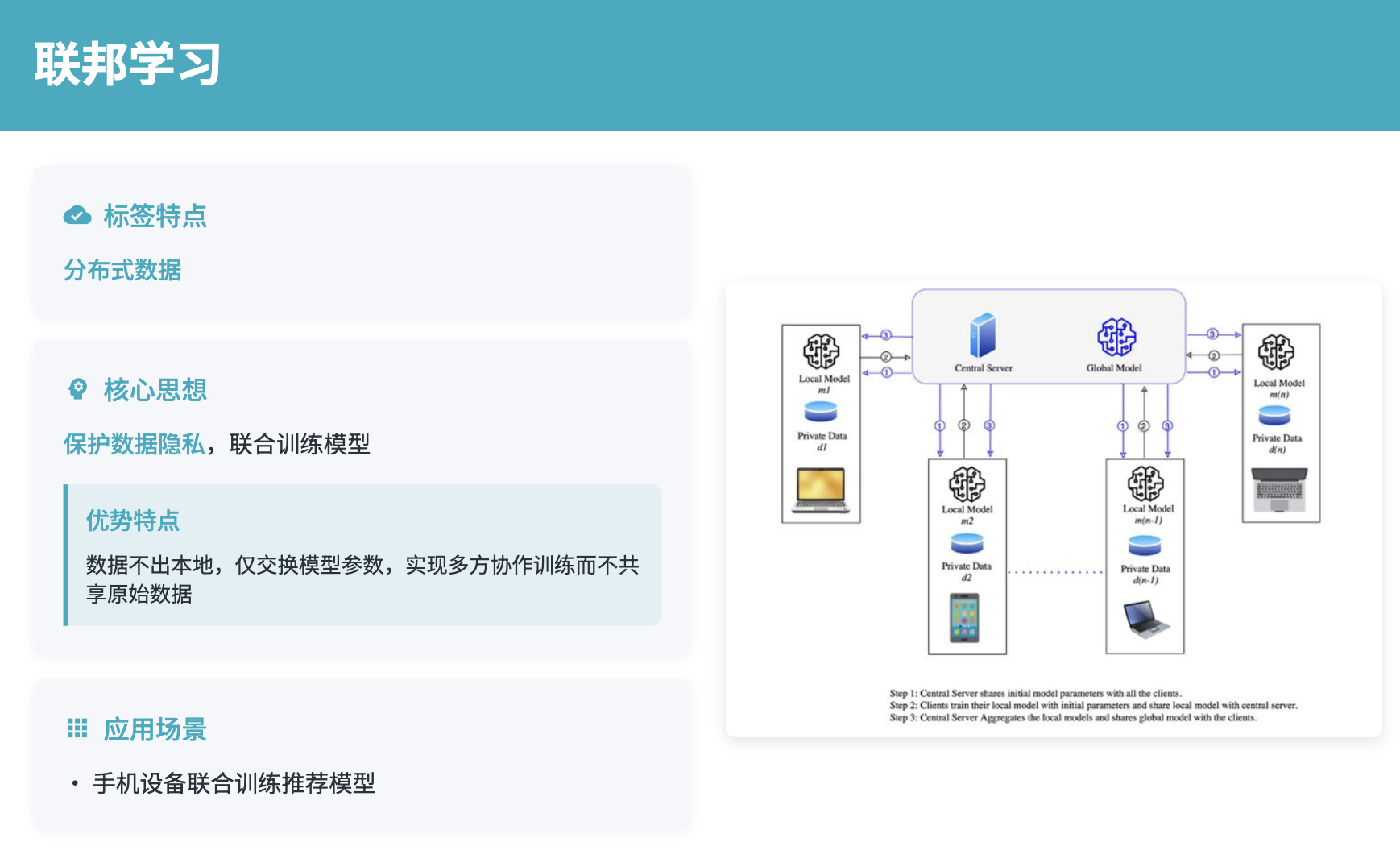
6.1 联邦学习的架构设计
…详情请参照古月居

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)