L3ROcc:从单目RGB视频到4D时序Occupancy的开源重建框架深度解析
1. 引言
在具身智能与机器人导航领域,如何低成本、高效率地获取4D时序语义数据,始终是制约算法研究与工程落地的核心瓶颈。传统方案依赖昂贵的LiDAR或深度相机,不仅硬件成本高昂,后续的多传感器标定与坐标系转换流程也极为繁琐。另一方面,仿真环境虽然能零成本生成完美的Ground Truth数据,但渲染纹理与物理特性同真实世界之间存在难以弥合的Domain Gap,导致模型迁移效果大打折扣。
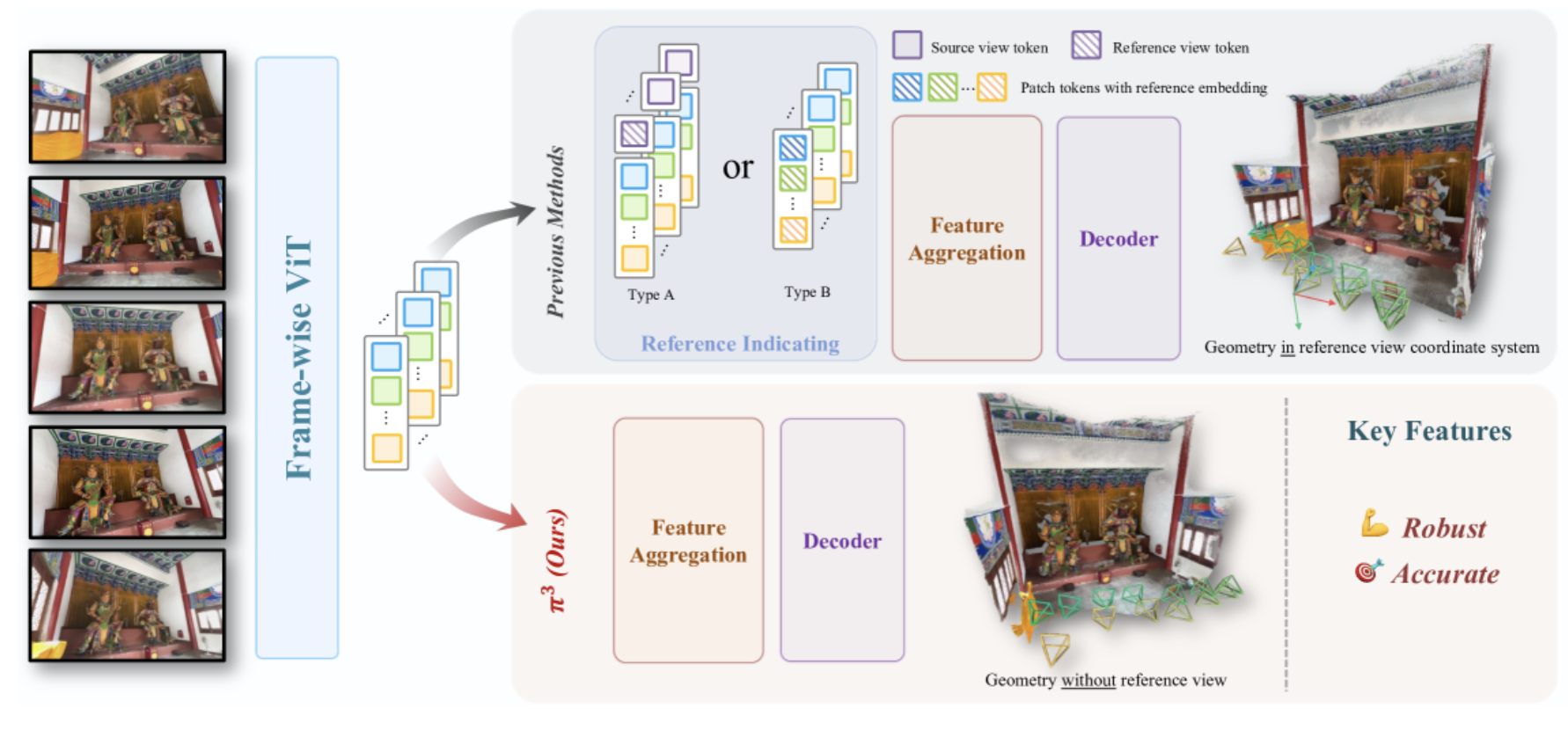
L3ROcc(Local 3D Reconstruction with Occupancy)正是为了打破这一僵局而诞生的开源框架。它的核心能力在于:仅凭一段普通的单目RGB视频输入,即可通过端到端的几何学习算法,自动完成高质量的3D点云重建、3D Occupancy Grid生成以及4D时序观测数据的构建。在一台配备GPU的普通工作站上,处理一段16秒(30FPS)的视频仅需约20秒,这一效率使得大规模数据集的构建成为可能。相关代码已经在Github上开源了。

图1:L3ROcc处理效果总览。左侧为原始RGB视频帧,左下角叠加了对应的3D Occupancy网格,右侧展示了融合Occupancy网格与相机运动轨迹的全局3D点云。
2. 背景与动机
2.1 真实场景数据获取的高门槛
当前主流的Occupancy数据生成流水线高度依赖昂贵的硬件设备。以自动驾驶领域为例,一套高线束LiDAR(如Velodyne VLP-128或Ouster OS1-128)的采购成本动辄数十万元人民币,而高精度深度相机(如Intel RealSense L515)虽然价格相对亲民,但其有效测距范围和精度在室外大场景下往往力不从心。更关键的是,硬件采购仅仅是起点——后续还需要处理复杂的多传感器联合标定(LiDAR-Camera外参标定)、时间同步(硬件触发或PTP协议)以及多坐标系之间的刚体变换。这种"重资产、重运维"的模式,极大限制了大规模真实场景数据的采集与扩充,尤其对于资源有限的高校实验室和初创团队而言,几乎构成了不可逾越的壁垒。
2.2 仿真数据的Sim-to-Real鸿沟
仿真环境(如Habitat、AI2-THOR、Isaac Sim)能够以零边际成本生成完美的Ground Truth——精确的点云、位姿矩阵、语义标签和Occupancy网格一应俱全。然而,仿真渲染的纹理细节、光照模型与物理交互特性始终与真实世界存在显著的域差异(Domain Gap)。大量实验表明,完全依赖仿真数据训练的感知模型,在部署到真实物理环境时往往出现严重的性能退化。虽然域随机化(Domain Randomization)和域适应(Domain Adaptation)等技术能在一定程度上缓解这一问题,但根本性的解决方案仍然是获取足够多的真实世界数据。
2.3 L3ROcc的设计愿景
基于上述分析,L3ROcc的设计目标非常明确:构建一个轻量化、低硬件依赖的通用工具,使得任何一台搭载普通RGB摄像头的设备——无论是手机、运动相机还是机器人上的单目摄像头——都能成为生成高质量3D感知数据的来源。具体而言,L3ROcc摆脱了对LiDAR和深度相机的依赖,仅凭单目RGB视频输入,通过几何学习算法完成局部3D感知重建并生成标准化的Occupancy数据,同时严格对齐LeRobotDataset v2.1格式规范,确保生成的数据能够直接接入主流训练框架。
3. 整体架构与数据流
3.1 项目结构
L3ROcc的代码组织遵循清晰的模块化设计,核心逻辑集中在约2300行Python代码中。整个项目的目录结构如下:
L3ROcc/
├── base.py # 核心DataGenerator基类(约1350行)
├── utils.py # 几何变换、体素化、插值等工具函数(约930行)
├── configs/
│ ├── config.yaml # 体素尺寸、网格分辨率、光线步长等核心参数
│ └── globals.py # 全局常量与语义类别映射表
├── dataset/
│ └── intern_nav_adapter.py # InternNav大规模数据集索引加载器
└── generater/
├── normal_data_vln_env.py # SimpleVideoDataGenerator(单视频模式)
└── intern_vln_env.py # InternNavDataGenerator(大规模数据集模式)
其中,base.py中的DataGenerator类是整个框架的核心引擎,封装了从3D重建到Occupancy生成的全部计算逻辑。两个Generator子类分别面向不同的使用场景:SimpleVideoDataGenerator适用于从零开始处理单个视频文件,InternNavDataGenerator则针对InternData-N1等包含24万条以上轨迹的大规模导航数据集,内置了Sim3尺度对齐和并发安全的元数据更新机制。
3.2 端到端数据流
从一段原始RGB视频到最终的4D时序Occupancy数据集,L3ROcc的处理流水线可以概括为以下六个阶段:
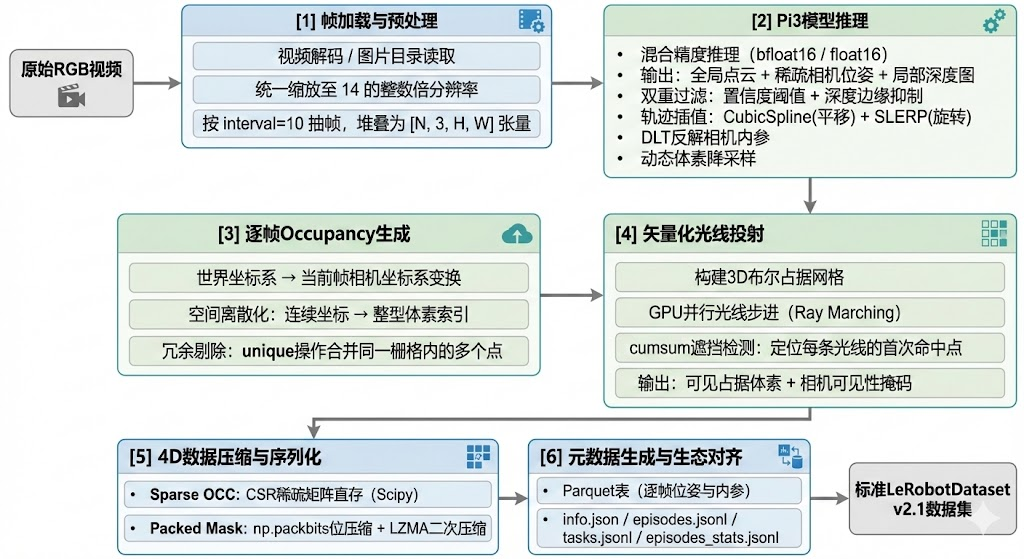
整个流水线的入口函数非常简洁,以下是base.py中run_pipeline方法的核心逻辑:
def run_pipeline(self, input_path, pcd_save=True):
# 阶段1-2:3D重建,获取点云、相机位姿和归一化射线方向
pcd, self.camera_pose, self.norm_cam_ray = self.pcd_reconstruction(input_path)
paths = self.get_io_paths(input_path)
# 阶段3-4:逐帧计算Occupancy序列(体素化 + 光线投射)
arr_4d_occ, arr_4d_mask, all_camera_poses, all_camera_intrinsics = (
self.compute_sequence_data(pcd)
)
# 阶段5:保存全局点云和Occupancy网格
self.save_global_data(paths)
# 阶段5:保存4D时序数据(稀疏OCC + 压缩Mask)
self.save_sequence_data(paths, arr_4d_occ, arr_4d_mask)
3.3 关键配置参数
L3ROcc通过config.yaml文件集中管理所有超参数。以下是几个对重建质量和计算效率影响最大的参数及其含义:
voxel_size: 0.02 # 基础体素边长(米),决定Occupancy网格的空间分辨率
pc_range: [-2, -1.5, -0.5, 2, 1, 3.5] # 感知范围的包围盒 [x_min, y_min, z_min, x_max, y_max, z_max]
occ_size: [200, 125, 200] # Occupancy网格的三维分辨率 [D, H, W]
ray_cast_step_size: 1.0 # 光线步进的步长(以体素为单位)
interval: 10 # 视频抽帧间隔(每10帧取1帧送入Pi3)
voxel_size_scale: 100.0 # 动态体素尺寸的缩放因子
fps: 30.0 # 视频帧率,用于时间戳计算
pc_range定义了一个以相机为中心的长方体感知区域,X轴范围4米、Y轴范围2.5米、Z轴范围4米,这一设置适用于室内导航场景。occ_size与pc_range和voxel_size之间存在严格的数学关系:occ_size[i] = (pc_range[i+3] - pc_range[i]) / voxel_size,即200 = (2 - (-2)) / 0.02。
4. 核心技术一:基于Pi3的几何重建流
4.1 Pi3模型概述
L3ROcc的3D重建能力建立在Pi3(Permutation-Equivariant Visual Geometry Learning)模型之上。与传统的Structure-from-Motion(SfM)流水线不同,Pi3利用视觉特征的排列等变性(Permutation Equivariance),彻底摒弃了对参考帧的依赖。这意味着无论输入帧的顺序如何排列,模型都能产生一致的几何预测结果。这一特性在面对大动态视差、弱纹理区域以及长序列跟踪时,展现出远超传统方法的鲁棒性。Pi3能够以端到端的方式,从视频流中同时预测全局3D点云和相机位姿,无需任何预先标定信息。
4.2 推理流程与双重过滤
pcd_reconstruction方法是整个重建流程的入口。首先,视频帧被加载并统一缩放到适配ViT架构的分辨率(宽高均为14的整数倍,总像素数不超过255000)。随后,帧序列被送入Pi3模型进行混合精度推理:
# 根据GPU计算能力选择精度:Ampere及以上架构使用bfloat16,否则使用float16
dtype = (
torch.bfloat16
if torch.cuda.get_device_capability()[0] >= 8
else torch.float16
)
with torch.no_grad():
with torch.amp.autocast("cuda", dtype=dtype):
res = self.model(imgs[None]) # 输入形状: [1, N, 3, H, W]
模型输出包含全局点云坐标(res["points"])、置信度图(res["conf"])、局部深度点(res["local_points"])和相机位姿(res["camera_poses"])。原始输出中不可避免地包含噪声和伪影,L3ROcc通过双重过滤机制进行清洗:
# 过滤器1:置信度阈值——仅保留sigmoid(conf) > 0.1的高可靠点
masks = (torch.sigmoid(res["conf"][..., 0]) > 0.1)
# 过滤器2:深度边缘抑制——剔除深度不连续处的伪影点
non_edge = ~depth_edge(res["local_points"][..., 2], rtol=0.03)
# 取两个过滤器的交集
masks = torch.logical_and(masks, non_edge)[0]
置信度过滤的阈值设为0.1,这是一个相对宽松的设定,目的是在保留足够多有效点的同时剔除明显的噪声。depth_edge函数通过检测深度图中的梯度突变来识别物体边界处的"飞点"(flying pixels),这类伪影在深度不连续区域(如物体轮廓边缘)尤为常见,若不加处理会严重影响后续体素化的质量。
4.3 相机轨迹插值
Pi3模型按interval=10的间隔对视频抽帧进行推理,因此输出的相机位姿是稀疏的。为了获得全序列的逐帧位姿,L3ROcc对平移分量和旋转分量分别采用不同的插值策略:
def interpolate_extrinsics(extrinsics, x_original, x_target):
# 平移分量:三轴独立的三次样条插值(自然边界条件)
trans = np.array(extrinsics[:, :3, 3]) # 形状: (N, 3)
trans_splines = [
CubicSpline(x_original, trans[:, 0], bc_type="natural"),
CubicSpline(x_original, trans[:, 1], bc_type="natural"),
CubicSpline(x_original, trans[:, 2], bc_type="natural"),
]
trans_interp = np.vstack([s(x_target) for s in trans_splines]).T
# 旋转分量:球面线性插值(SLERP)
R_original = Rotation.from_matrix(extrinsics[:, :3, :3])
slerper = Slerp(x_original, R_original)
R_slerp = slerper(x_target_inner).as_matrix()
# 超出原始范围的帧,旋转矩阵取最后一个有效值
...
平移分量使用CubicSpline(三次样条)插值,自然边界条件(bc_type="natural")意味着端点处的二阶导数为零,这能产生最平滑的轨迹曲线。旋转分量则使用SLERP(Spherical Linear Interpolation,球面线性插值),这是旋转插值的标准做法——直接对旋转矩阵做线性插值会破坏正交性,而SLERP在SO(3)流形上进行插值,保证了中间结果始终是合法的旋转矩阵。对于超出原始帧范围的外推区域,旋转矩阵直接复制最后一个有效帧的值,避免了外推带来的不稳定性。
图2:相机轨迹插值效果。红色点为Pi3稀疏预测的关键帧位姿,蓝色曲线为插值后的连续轨迹,箭头表示相机朝向。
4.4 DLT内参估计
传统的3D重建流水线要求预先标定相机内参(焦距、主点坐标),这对于"随手拍"的视频来说是不现实的。L3ROcc通过直接线性变换(DLT, Direct Linear Transform)算法,从Pi3输出的局部几何信息中反解出相机内参矩阵:
def estimate_intrinsics(coords):
"""
输入: coords - 形状为(H, W, 3)的相机平面坐标点
输出: K - 3x3内参矩阵
"""
# 计算归一化相机坐标
x_prime = X / Z
y_prime = Y / Z
# 最小二乘求解: [x', 1] @ [fx, cx]^T = u
A_u = torch.stack([x_prime, ones], dim=1)
sol_u = torch.linalg.lstsq(A_u, u).solution
fx, cx = sol_u[0], sol_u[1]
# 同理求解fy和cy
A_v = torch.stack([y_prime, ones], dim=1)
sol_v = torch.linalg.lstsq(A_v, v).solution
fy, cy = sol_v[0], sol_v[1]
K = torch.tensor([[fx, 0, cx], [0, fy, cy], [0, 0, 1]])
return K
其数学原理是针孔相机模型的投影方程:u = fx * (X/Z) + cx,其中(X, Y, Z)是相机坐标系下的3D点,(u, v)是对应的像素坐标。将该方程改写为矩阵形式A @ [fx, cx]^T = u后,通过最小二乘法(torch.linalg.lstsq)即可求解焦距和主点。这一方法的前提是Pi3输出的局部3D点与像素坐标之间存在准确的对应关系,而Pi3的端到端训练恰好保证了这一点。
4.5 动态体素降采样
Pi3模型输出的原始点云通常包含数百万个点,直接用于后续计算既不经济也不必要。L3ROcc采用动态体素降采样策略,根据场景的实际尺度自适应地确定降采样粒度:
# 计算场景包围盒的体积
loc_range = pcd.max(0) - pcd.min(0)
loc_vol = np.prod(loc_range)
# 动态计算体素尺寸:体积 / 点数 * 帧数 * 缩放因子
voxel_size = loc_vol / pcd_num * frame_num * self.voxel_size_scale
# 使用Open3D执行体素降采样
pcd_ocd = pcd_ocd.voxel_down_sample(voxel_size=voxel_size)
这一公式的直觉是:场景越大(loc_vol越大)或点云越稀疏(pcd_num越小),体素尺寸就越大,降采样越激进;反之,对于小场景或密集点云,则保留更多细节。voxel_size_scale(默认100.0)作为全局调节旋钮,允许用户在精度与效率之间灵活权衡。
图3:降采样前后的点云对比。左侧为原始稠密点云(数百万点),右侧为动态体素降采样后的结构化点云,叠加了插值后的相机运动轨迹。
5. 核心技术二:自动化体素化与空间离散化
5.1 从连续点云到离散体素
原始的3D点云是连续且无序的浮点坐标集合,无法直接用于Occupancy网格的构建。L3ROcc通过pcd_to_occ方法,将连续的世界坐标映射为离散的整型体素索引,完成从"点"到"格"的转化。这一过程包含四个步骤:空间滤波、坐标量化、冗余剔除和中心恢复。
def pcd_to_occ(self, pcd):
pc_range_min = torch.tensor(self.pc_range[:3], device=device)
pc_range_max = torch.tensor(self.pc_range[3:], device=device)
# 步骤1:空间滤波——仅保留感知范围内的点
mask = (
(pcd[:, 0] > pc_range_min[0]) & (pcd[:, 0] < pc_range_max[0])
& (pcd[:, 1] > pc_range_min[1]) & (pcd[:, 1] < pc_range_max[1])
& (pcd[:, 2] > pc_range_min[2]) & (pcd[:, 2] < pc_range_max[2])
)
pcd = pcd[mask]
# 步骤2:坐标量化——连续坐标 → 整型体素索引
voxel_indices = torch.floor((pcd - pc_range_min) / voxel_size).long()
# 步骤3:冗余剔除——合并落入同一栅格的多个点
unique_voxel_indices = torch.unique(voxel_indices, dim=0)
# 步骤4:中心恢复——将体素索引转回世界坐标(取体素中心)
occ_pcd = (
unique_voxel_indices.float() * voxel_size
+ pc_range_min
+ (voxel_size * 0.5)
)
return occ_pcd
坐标量化的核心公式是 index = floor((point - range_min) / voxel_size),它将每个3D点映射到其所在的体素格子。torch.unique操作则将落入同一个格子的多个点合并为一个体素,这不仅实现了数据的结构化,还起到了进一步降采样的作用。最后,通过 (index + 0.5) * voxel_size + range_min 将体素索引转回世界坐标,其中加0.5是为了取体素的几何中心而非角点。
5.2 坐标系变换
在逐帧处理时,全局点云需要从世界坐标系变换到当前帧的相机坐标系。L3ROcc同时支持NumPy和PyTorch两种计算后端,GPU模式下的变换实现如下:
# GPU优化的世界坐标系 → 相机坐标系变换
if isinstance(points_world, torch.Tensor):
R_cw = T_cw[:3, :3] # 旋转矩阵
t_cw = T_cw[:3, 3] # 平移向量
# P_cam = (P_world - t_cw) @ R_cw
points_camera = (points_world - t_cw) @ R_cw
return points_camera
这里的数学关系是:给定相机外参矩阵 T_cw(Camera-to-World变换),世界坐标系下的点 P_world 变换到相机坐标系的公式为 P_cam = R_wc @ (P_world - t_cw),其中 R_wc = R_cw^T。代码中利用了矩阵转置的性质,将 (R_cw^T @ v^T)^T 简化为 v @ R_cw,避免了显式的转置操作。
6. 核心技术三:矢量化光线投射
6.1 为什么需要光线投射
经过体素化后,我们得到了全局Occupancy网格——它记录了场景中所有被占据的体素。但机器人在某一时刻的单帧观测只能看到"表面",被前方物体遮挡的区域是不可见的。为了模拟真实的物理遮挡关系,区分"可见占据"、"可见空闲"和"未知遮挡"三种状态,L3ROcc实现了一套基于PyTorch的矢量化Ray Casting算法。该算法完全在GPU上并行执行,避免了逐像素逐步的串行循环。
6.2 算法原理
光线投射的核心思想是:从相机光心出发,沿每个像素对应的射线方向进行步进采样,检查每个采样点是否命中了占据体素。一旦某条光线命中了第一个非空体素,该体素之后的所有体素都被标记为"遮挡"。整个过程可以用下面的示意图理解: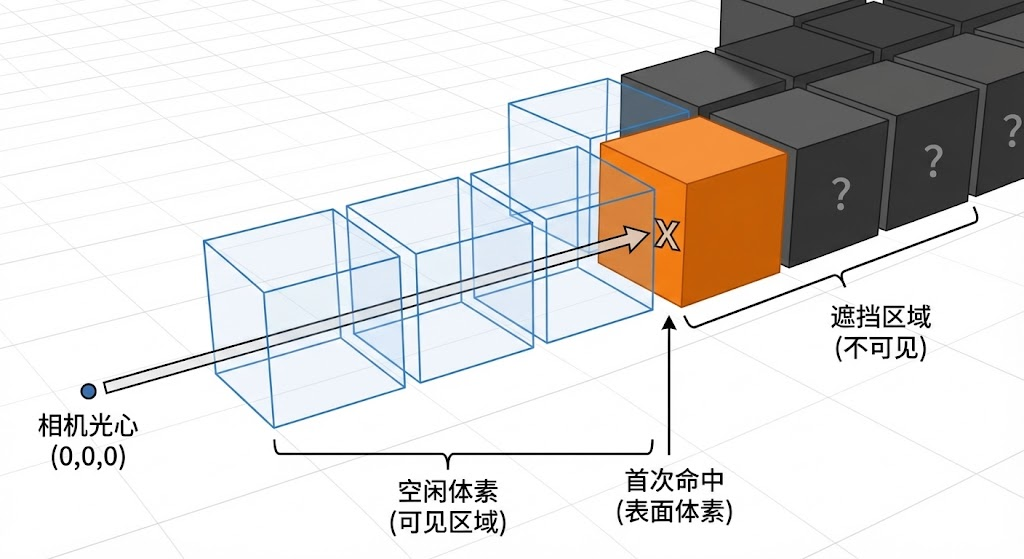
6.3 实现细节
check_visual_occ方法是光线投射的核心实现,其计算流程分为四个阶段:
阶段一:构建3D布尔占据网格
# 初始化空的3D网格 [200, 125, 200]
camera_visible_mask_3d = torch.zeros(
self.config["occ_size"], dtype=torch.bool, device=device
)
occ_voxels_3d = camera_visible_mask_3d.clone()
# 将占据体素的索引展平为1D,填入3D网格
D, H, W = self.config["occ_size"]
idx_1d = occ_voxels[:, 0] * (H * W) + occ_voxels[:, 1] * W + occ_voxels[:, 2]
occ_voxels_3d.view(-1).index_fill_(0, idx_1d.long(), 1)
这里使用index_fill_而非直接索引赋值(grid[x, y, z] = 1),是因为前者在GPU上的执行效率更高——它避免了Python层面的循环,直接在CUDA kernel中完成批量填充。
阶段二:并行光线步进
# 计算最大步进距离(对角线长度 / 体素尺寸)
max_distance = int(np.sqrt(
(self.pc_range[3] - self.pc_range[0]) ** 2
+ (self.pc_range[5] - self.pc_range[2]) ** 2
)) / self.voxel_size + 1
# 生成步进序列 [0, 1, 2, ..., max_distance]
steps = torch.arange(0, max_distance, ray_cast_step_size, device=device)
# 一次性计算所有光线在所有步进位置的3D坐标
# ray_positions 形状: [H*W, num_steps, 3]
ray_positions = (
ray_position.unsqueeze(0)
+ ray_direction_norm.unsqueeze(1) * steps.unsqueeze(0).unsqueeze(-1)
)
# 量化为体素索引
voxel_coords = torch.floor(ray_positions).long()
这段代码的关键在于利用广播机制,将H*W条射线与num_steps个步进位置做外积,一次性生成所有采样点的3D坐标。对于默认配置(200x125x200网格,步长1.0),每帧需要处理的采样点数量约为 H*W * max_distance,全部在GPU上并行完成。
阶段三:遮挡检测
# 将3D体素坐标展平为1D索引,查询占据状态
flat_coords = (
voxel_coords[..., 0] * (H * W)
+ voxel_coords[..., 1] * W
+ voxel_coords[..., 2]
)
occ_flat = occ_voxels_3d.view(-1)
sampled_occ = torch.where(
valid_mask,
occ_flat[flat_coords.clamp(0, occ_flat.size(0) - 1)],
torch.tensor(0, device=device, dtype=torch.bool),
)
# 累积求和检测首次命中:cumsum > 0 表示该位置之前已有命中
hit_mask = (sampled_occ > 0).cumsum(dim=1) > 0
# 右移一位:排除命中体素本身,仅标记其后方为遮挡
hit_mask[:, 1:] = hit_mask[:, :-1]
遮挡检测的核心技巧是cumsum(累积求和)操作。对于每条光线,沿步进方向做累积求和后,值大于0的位置意味着该位置之前已经存在至少一个占据体素——即该位置被遮挡。通过将hit_mask右移一位,确保命中的表面体素本身不被标记为遮挡,而是被保留为"可见占据"。
阶段四:输出结果
# 可见区域掩码:所有光线经过的、未被遮挡的体素
visible_indices = flat_coords[valid_mask & ~hit_mask]
camera_visible_mask_3d.view(-1).index_fill_(0, visible_indices, 1)
# 可见占据体素:既被占据、又在可见区域内的体素
occ_voxels_3d = occ_voxels_3d * camera_visible_mask_3d
最终输出两个结果:camera_visible_mask_3d标记了当前相机视锥内所有光线可达的区域(包括空闲和占据),用于后续的位压缩掩码生成;occ_voxels_3d则仅包含"可见且被占据"的表面体素,用于构建稀疏OCC张量。
图4:光线投射可视化。绿色射线表示从相机出发的光线可达区域,灰色体素为全局Occupancy网格,绿色高亮体素为当前视角下可见的占据表面。
7. 核心技术四:极致的4D数据压缩
7.1 存储挑战
4D时序Occupancy数据的维度为 [T, D, H, W],其中T为帧数,D/H/W为网格三维分辨率。以一段16秒30FPS的视频为例,T=480,网格尺寸为200x125x200,全量稠密矩阵包含约 480 x 200 x 125 x 200 = 24亿个布尔元素。即便每个元素仅占1字节,总存储量也接近2.4GB;若考虑OCC和Mask两份数据,单条轨迹的存储需求将超过11GB。这在大规模数据集场景下(如InternData-N1的24万条轨迹)是完全不可接受的。
L3ROcc根据OCC数据(表面稀疏)和Mask数据(视锥体稠密)的不同几何特性,设计了差异化的压缩方案。
7.2 Sparse OCC:CSR稀疏矩阵直存
真实物理空间中,“空气远多于物体”——在一个200x125x200的网格中,被占据的体素通常不到总数的0.1%。传统做法是先构建完整的稠密矩阵再进行压缩,但这意味着为了存储极少量的有效数据,需要在内存中开辟巨大的全零矩阵。L3ROcc完全跳过了稠密矩阵的构建过程,直接提取非空体素的4D坐标索引并以CSR(Compressed Sparse Row)格式落盘:
def save_sequence_data(self, paths, sparse_occ_indices, packed_mask_data):
N = len(self.camera_pose) # 总帧数
H, W, D = self.config["occ_size"]
flat_dim = H * W * D # 展平后的体素总数
# 提取4D索引的各个分量
times = sparse_occ_indices[:, 0] # 帧ID
xs = sparse_occ_indices[:, 1] # X索引
ys = sparse_occ_indices[:, 2] # Y索引
zs = sparse_occ_indices[:, 3] # Z索引
# 将3D体素索引展平为1D
flat_indices = (
xs.astype(np.int64) * (W * D)
+ ys.astype(np.int64) * D
+ zs.astype(np.int64)
)
# 构建CSR稀疏矩阵:行=帧ID,列=展平体素索引,值=1
data = np.ones(len(flat_indices), dtype=np.uint8)
sparse_mat = sparse.csr_matrix(
(data, (times, flat_indices)), shape=(N, flat_dim)
)
sparse.save_npz(paths["occ_seq"], sparse_mat)
CSR格式仅存储非零元素的值、列索引和行指针三个数组,空间复杂度与非零元素数量成正比,而非与矩阵总尺寸成正比。
7.3 Packed Mask:流式位压缩
与OCC不同,可见性Mask代表相机视锥体扫过的区域,包含大量连续的1(空闲可见区域),使用稀疏存储反而会增加体积。L3ROcc采用"流式处理 + 双重压缩"策略:
# 在compute_sequence_data中,逐帧构建布尔网格并立即压缩
for i in range(total_frames):
frame_grid = torch.zeros(grid_dims, dtype=torch.bool, device=device)
if len(cam_visible_mask) > 0:
frame_grid[
cam_visible_mask[:, 0],
cam_visible_mask[:, 1],
cam_visible_mask[:, 2],
] = True
all_packed_masks.append(frame_grid)
# 合并所有帧,展平,执行位压缩
final_mask_packed = torch.stack(all_packed_masks, dim=0)
final_mask_packed = final_mask_packed.reshape(
final_mask_packed.shape[0], -1
).cpu().numpy()
# 8个布尔值压入1个字节,物理体积减少87.5%
final_mask_packed = np.packbits(final_mask_packed, axis=1)
np.packbits将8个布尔状态(0/1)压入1个Byte,物理体积直接减少87.5%。在此基础上,np.savez_compressed再进行一次LZMA/Deflate压缩,进一步缩小文件体积。
…详情请参照古月居

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)