深度强化学习在电气工程自主电压控制中的应用:多智能体系统的探索
深度强化学习电气工程复现文章,适合小白学习 关键词:多智能体系统、自主电压控制、深度强化学习、集中训练和分散执行控制、数据驱动、深度神经网络。 编程语言:python平台 主题:使用深度强化学习的数据驱动的多智能体自主电压控制框架 内容简介: 现代电网的复杂性不断增加,由于可再生能源资源的扩展和快速需求响应的要求,对传统的电网控制系统提出了很大的挑战。 现有的电网自主控制方法需要精确的系统模型和强大的计算平台,难以针对具有更多控制选项和运行条件的大规模能源系统进行扩展。 面对这些挑战,本文提出了一种使用深度强化学习(DRL)方法的数据驱动的多智能体电网控制方案。 具体来说,以经典的自主电压控制(AVC)问题为例,将其表述为马尔可夫博弈,采用启发式方法来划分代理。 然后,基于集中训练和分散执行的多智能体深度确定性策略梯度(MADDPG)方法,开发了一种多智能体AVC(MA-AVC)算法来解决AVC问题。 该方法可以从零开始学习,通过输入输出数据逐步掌握系统运行规则。 为了证明所提出的 MA-AVC 算法的有效性,在伊利诺伊 200 总线系统上进行了综合案例研究,考虑了负载/发电变化、N-1 突发事件和弱集中式通信环境。 复现论文截图:
在当今电力领域,现代电网的复杂度如脱缰野马般不断攀升。随着可再生能源的大规模接入,以及快速需求响应的迫切要求,传统的电网控制系统正面临着前所未有的巨大挑战。以往的电网自主控制方法,就像被惯坏的孩子,依赖精确的系统模型和强大的计算平台。但当面对大规模能源系统,那些繁多的控制选项和复杂的运行条件,这些传统方法便难以招架,扩展性问题暴露无遗。
深度强化学习(DRL)来救场
为了攻克这些难题,一种基于深度强化学习(DRL)的数据驱动多智能体电网控制方案应运而生。这里,我们以经典的自主电压控制(AVC)问题为例,将其巧妙地表述为马尔可夫博弈。想象一下,每个智能体就像一个独立的小探险家,在电网这个大迷宫里寻找最优路径。为了让这些小探险家们更好地协作,我们采用启发式方法来划分代理。
基于MADDPG的MA - AVC算法
接下来,基于集中训练和分散执行的多智能体深度确定性策略梯度(MADDPG)方法,开发出多智能体AVC(MA - AVC)算法。它就像一个聪明的学生,可以从零开始学习,通过不断分析输入输出数据,慢慢掌握系统运行的规则。
深度强化学习电气工程复现文章,适合小白学习 关键词:多智能体系统、自主电压控制、深度强化学习、集中训练和分散执行控制、数据驱动、深度神经网络。 编程语言:python平台 主题:使用深度强化学习的数据驱动的多智能体自主电压控制框架 内容简介: 现代电网的复杂性不断增加,由于可再生能源资源的扩展和快速需求响应的要求,对传统的电网控制系统提出了很大的挑战。 现有的电网自主控制方法需要精确的系统模型和强大的计算平台,难以针对具有更多控制选项和运行条件的大规模能源系统进行扩展。 面对这些挑战,本文提出了一种使用深度强化学习(DRL)方法的数据驱动的多智能体电网控制方案。 具体来说,以经典的自主电压控制(AVC)问题为例,将其表述为马尔可夫博弈,采用启发式方法来划分代理。 然后,基于集中训练和分散执行的多智能体深度确定性策略梯度(MADDPG)方法,开发了一种多智能体AVC(MA-AVC)算法来解决AVC问题。 该方法可以从零开始学习,通过输入输出数据逐步掌握系统运行规则。 为了证明所提出的 MA-AVC 算法的有效性,在伊利诺伊 200 总线系统上进行了综合案例研究,考虑了负载/发电变化、N-1 突发事件和弱集中式通信环境。 复现论文截图:
下面我们来看一段简单的Python代码示例,来模拟这个算法的部分逻辑(这里只是一个示意性代码,实际应用会复杂得多):
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
# 定义智能体网络
class AgentNetwork(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(AgentNetwork, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
return out
# 初始化智能体网络
agent1 = AgentNetwork(input_size=10, hidden_size=20, output_size=2)
agent2 = AgentNetwork(input_size=10, hidden_size=20, output_size=2)
# 定义优化器
optimizer1 = optim.Adam(agent1.parameters(), lr=0.001)
optimizer2 = optim.Adam(agent2.parameters(), lr=0.001)
# 模拟训练过程
for episode in range(100):
# 生成随机输入数据
state1 = torch.FloatTensor(np.random.randn(1, 10))
state2 = torch.FloatTensor(np.random.randn(1, 10))
# 智能体1和智能体2根据当前状态生成动作
action1 = agent1(state1)
action2 = agent2(state2)
# 这里假设我们有一个奖励函数,根据动作计算奖励
reward1 = torch.FloatTensor([np.random.randn()])
reward2 = torch.FloatTensor([np.random.randn()])
# 计算损失
loss1 = -reward1 * torch.sum(action1)
loss2 = -reward2 * torch.sum(action2)
# 反向传播和优化
optimizer1.zero_grad()
loss1.backward()
optimizer1.step()
optimizer2.zero_grad()
loss2.backward()
optimizer2.step()在这段代码里,我们定义了简单的智能体网络,它接收输入状态,通过全连接层和激活函数处理后输出动作。然后,我们模拟了多个智能体的训练过程,每个智能体根据自己的状态生成动作,并根据奖励计算损失来更新网络参数。在实际的MA - AVC算法中,这个过程会涉及到电网状态的准确描述、合理的奖励机制设计以及更复杂的网络结构,但核心思想是类似的。
案例研究
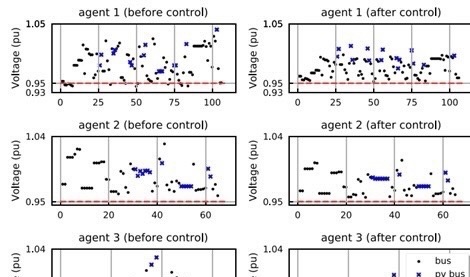
为了验证MA - AVC算法的有效性,我们在伊利诺伊200总线系统上展开了全面的案例研究。这个研究考虑了各种实际情况,像负载/发电变化,就像现实中用电需求的起起伏伏;N - 1突发事件,模拟了电网中某一线路或设备出现故障的情况;还有弱集中式通信环境,考虑到了实际通信可能出现的不理想状况。通过这样全方位的测试,来证明我们这个算法在实际电网运行中的可靠性和实用性。
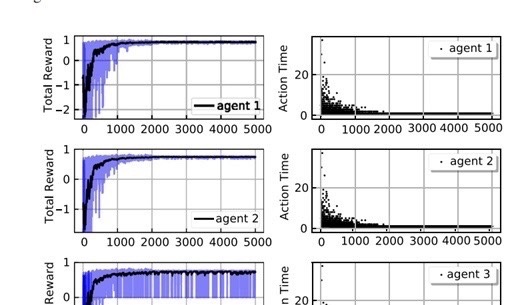
对于小白来说,深度强化学习在电气工程中的应用可能一开始有点摸不着头脑,但只要像这样从简单的概念和代码入手,逐步深入,就能慢慢掌握这个强大工具在电网控制中的奥秘,为未来智能电网的发展贡献自己的力量。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 2
2 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)