Open WebUI 项目架构详解
Open WebUI 项目架构详解
项目概述
Open WebUI 是一个功能完整的 AI 聊天 Web 界面,设计为可以对接 Ollama、OpenAI 兼容接口(以及 Gemini、Azure 等)的前后端一体化应用,支持多用户、RAG 检索、插件系统、实时通信等企业级特性。
获取地址:https://github.com/open-webui/open-webui
一、整体技术栈
| 层级 | 技术 |
|---|---|
| 前端框架 | SvelteKit 4 + TypeScript 5 |
| 前端样式 | Tailwind CSS v4 + PostCSS |
| 前端构建 | Vite 5 |
| 后端框架 | Python FastAPI(全异步 async) |
| 数据库 ORM | SQLAlchemy + Alembic 迁移 |
| 实时通信 | Socket.IO(支持 Redis 集群) |
| 数据库 | SQLite(默认)/ PostgreSQL |
| 部署 | Docker / Kubernetes Helm |
| 可观测性 | OpenTelemetry |
技术逐一介绍
- SvelteKit 4 + TypeScript 5(前端框架)
SvelteKit 是基于 Svelte 的全栈前端框架,提供文件路由、服务端渲染(SSR)、预渲染和端点能力,适合做需要良好首屏性能与路由管理的应用。TypeScript 5 为前端代码提供静态类型检查,能显著降低大型项目中的类型错误与重构风险。在本项目中,页面路由、组件通信和 API 调用类型定义都依赖这套组合。
- Tailwind CSS v4 + PostCSS(前端样式)
Tailwind CSS 是实用优先的样式框架,通过原子类快速构建界面,减少样式命名和上下文冲突。PostCSS 是 CSS 处理管道,用于执行 Tailwind 编译、自动转换与插件扩展。该组合让项目在保持统一设计规范的同时,具备较高的样式开发效率。
- Vite 5(前端构建)
Vite 负责本地开发服务器与生产构建。开发时使用基于原生 ES 模块的快速冷启动和热更新(HMR),构建时走 Rollup 产物优化。对于组件多、依赖重的前端项目,Vite 能显著提升开发反馈速度与构建可控性。
- Python FastAPI(全异步 async)(后端框架)
FastAPI 是高性能 Python Web 框架,基于 ASGI,天然适配异步 IO 场景。它结合类型注解可自动生成 OpenAPI 文档,并具备高效的数据校验能力。本项目中,模型请求转发、流式响应、WebSocket 协作等高并发路径都受益于 async 架构。
- SQLAlchemy + Alembic(数据库 ORM)
SQLAlchemy 提供 ORM 与 SQL 表达能力,用于把 Python 对象映射到数据库表,统一数据访问层。Alembic 负责数据库迁移版本管理,确保不同环境下可以按版本演进表结构。二者结合可在迭代功能时稳定维护数据模型一致性。
- Socket.IO(支持 Redis 集群)(实时通信)
Socket.IO 在 WebSocket 基础上增加了连接管理、事件模型和降级策略,适合实现聊天消息流式推送、在线状态同步等实时能力。当服务多实例部署时,可通过 Redis 适配器做跨实例事件广播,实现水平扩展。
- SQLite(默认)/ PostgreSQL(数据库)
SQLite 轻量、零运维,适合本地开发、单机部署或快速验证;PostgreSQL 更适合生产场景,具备更强并发、事务和扩展能力。项目同时支持二者,意味着可以从低门槛启动,再平滑迁移到企业级部署。
- Docker / Kubernetes Helm(部署)
Docker 提供一致化运行环境,降低“本地可跑、线上失败”的环境差异。Kubernetes Helm 通过 Chart 模板化管理集群部署参数,适合多环境配置、滚动升级和弹性扩容。该组合覆盖了从单机容器到云原生集群的完整发布路径。Docker 负责打包和运行单个应用容器;K8s 负责在多机器环境中调度、编排、扩缩容这些容器。
用 Docker 把应用打成镜像;把镜像推到镜像仓库(Docker Hub、Harbor、ECR 等);K8s 通过 Deployment 拉取这个镜像并启动 Pod;Service 给 Pod 提供稳定访问入口;Ingress 暴露到集群外;ConfigMap/Secret 注入配置和密钥;HPA 根据负载自动扩缩容
9. OpenTelemetry(可观测性)
OpenTelemetry 是统一的可观测性标准,支持指标(Metrics)、日志(Logs)、链路追踪(Traces)的采集与导出。在本项目中,它可用于定位请求瓶颈、排查跨服务调用问题,并为容量规划与稳定性治理提供数据基础。
二、目录结构总览
openwebui/
├── src/ # 前端 SvelteKit 源码
│ ├── routes/ # 页面路由
│ └── lib/ # 组件库、API、Store、工具
├── backend/open_webui/ # 后端 Python 源码
│ ├── main.py # FastAPI 应用入口
│ ├── config.py # 全局配置中心
│ ├── env.py # 环境变量读取
│ ├── routers/ # API 路由层(27个模块)
│ ├── models/ # 数据库 ORM 模型
│ ├── migrations/ # Alembic 数据库迁移
│ ├── retrieval/ # RAG 检索系统
│ ├── socket/ # WebSocket 服务
│ ├── utils/ # 工具函数库
│ ├── storage/ # 文件存储抽象层
│ └── internal/ # 数据库连接
├── static/ # 静态资源
└── cypress/ # E2E 测试
三、后端架构详解
1. 应用入口 main.py
FastAPI 应用的核心,负责:
- 注册全部 27 个路由模块(auth、chats、ollama、openai、retrieval、tools 等)
- 挂载 Socket.IO 子应用(实时通信)
- 注册中间件链:CORS → 压缩 → 会话 → 审计日志 → 安全 Headers
- 启动时初始化嵌入模型、重排序模型、连接数据库
这四项职责可以理解为“把后端从一组分散能力,装配成一个可对外服务的统一应用”。
- 注册全部路由模块:统一 API 装配层
main.py 会把 routers/ 目录下的业务路由集中挂载到 FastAPI 实例上。这样做有两个关键价值:
- 业务解耦:用户、聊天、模型、知识库、工具等领域分别维护,避免单文件膨胀。
- 对外统一:虽然内部是多模块,外部看到的是一套一致的 API 命名空间与鉴权规则。
从运行过程看,客户端请求先命中主应用,再根据路径前缀和方法分发到对应 router;也就是说,main.py 是“总路由入口”,routers/*.py 是“领域处理器”。
实际代码(摘自 main.py):
# 每个业务模块以固定前缀挂载,形成清晰的 API 命名空间
app.include_router(auths.router, prefix="/api/v1/auths", tags=["auths"])
app.include_router(users.router, prefix="/api/v1/users", tags=["users"])
app.include_router(chats.router, prefix="/api/v1/chats", tags=["chats"])
app.include_router(ollama.router, prefix="/ollama", tags=["ollama"])
app.include_router(openai.router, prefix="/openai", tags=["openai"])
app.include_router(retrieval.router, prefix="/api/v1/retrieval", tags=["retrieval"])
app.include_router(knowledge.router, prefix="/api/v1/knowledge", tags=["knowledge"])
app.include_router(tools.router, prefix="/api/v1/tools", tags=["tools"])
app.include_router(functions.router, prefix="/api/v1/functions", tags=["functions"])
# ...共 27 个模块,结构完全一致
# SCIM 按需启用:只有管理员开启了企业身份同步功能才挂载
if SCIM_ENABLED:
app.include_router(scim.router, prefix="/api/v1/scim/v2", tags=["scim"])
prefix 即请求路径前缀,tags 用于 OpenAPI 文档分组,每条路由的实际路径 = prefix + router 内部定义的路径。
2. 挂载 Socket.IO 子应用:HTTP 与实时通道并存
Open WebUI 既有常规 REST 请求,也有流式输出、在线状态同步等实时交互需求。main.py 将 Socket.IO 子应用挂载到主应用后,系统形成双通道:
- HTTP 通道:处理登录、配置、文件上传、历史查询等标准请求响应。
- Socket 通道:处理增量消息推送、在线用户状态、协同事件广播。
这种结构让“业务控制面”与“实时数据面”在同一服务进程内协作,减少跨服务通信复杂度。
实际代码(摘自 main.py):
# socket_app 是从 socket/main.py 导入的独立 ASGI 子应用
# 挂载到 /ws 路径,与主 HTTP 应用共享同一进程,但路由互不干扰
app.mount("/ws", socket_app)
前端通过 socket.io-client 连接 /ws/socket.io,之后所有实时事件(消息流、在线状态、协同编辑)都走这个子应用,不占用 HTTP 路由资源。
3. 注册中间件链:把横切能力前置到请求入口
中间件按顺序包裹请求生命周期,典型链路的意义如下:
- CORS:控制跨域访问策略,决定哪些前端来源可调用后端接口。
- 压缩:对响应体进行压缩,降低带宽消耗,提升弱网体验。
- 会话:处理会话上下文与状态读取,给后续鉴权与业务逻辑提供基础信息。
- 审计日志:记录关键操作轨迹,用于安全审计、问题回溯与合规。
- 安全 Headers:统一附加安全响应头,降低常见 Web 攻击面。
要点是:这些能力不是分散在每个路由里重复实现,而是通过中间件“全局一次接入、全站统一生效”。
实际代码(摘自 main.py):
# 1. 按需开启 Brotli/Gzip 压缩(由环境变量 ENABLE_COMPRESSION_MIDDLEWARE 控制)
if ENABLE_COMPRESSION_MIDDLEWARE:
app.add_middleware(CompressMiddleware)
# 2. YouTube 链接重定向中间件(将 /?v=xxx 的 YouTube 链接转为内部路由格式)
app.add_middleware(RedirectMiddleware)
# 3. 安全响应头中间件(注入 X-Frame-Options、CSP 等防攻击头)
app.add_middleware(SecurityHeadersMiddleware)
# 4. CORS 中间件:* 通配符时退化为开发默认来源,生产应显式配置
app.add_middleware(
CORSMiddleware,
allow_origins=CORS_ALLOW_ORIGIN,
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# 5. 审计日志中间件:只在配置了有效 audit_level 时挂载
if audit_level != AuditLevel.NONE:
app.add_middleware(
AuditLoggingMiddleware,
audit_level=audit_level,
excluded_paths=AUDIT_EXCLUDED_PATHS,
max_body_size=MAX_BODY_LOG_SIZE,
)
# 6. 内联装饰器写法:每次请求后提交数据库 Session,保证事务一致性
@app.middleware("http")
async def commit_session_after_request(request: Request, call_next):
response = await call_next(request)
Session.commit()
return response
# 7. 内联装饰器写法:提取 Authorization Token,并在响应头记录处理耗时
@app.middleware("http")
async def check_url(request: Request, call_next):
start_time = int(time.time())
request.state.token = get_http_authorization_cred(
request.headers.get("Authorization")
)
response = await call_next(request)
response.headers["X-Process-Time"] = str(int(time.time()) - start_time)
return response
注意:FastAPI/Starlette 中间件执行顺序是后注册先执行(栈顺序),所以最后
add_middleware的中间件最先处理进入的请求。
- 启动时初始化:把重资源组件预热到可用状态
在应用启动阶段,main.py 会完成数据库连接与模型相关组件初始化,例如嵌入模型、重排序模型、检索函数等。这样设计的好处是:
- 降低首请求延迟:避免第一个用户请求才触发重加载。
- 提前失败:配置错误、模型不可用、数据库不可连会在启动期暴露,而不是运行期随机报错。
- 运行期稳定:关键依赖在服务就绪前已完成检查,便于健康探针和自动化部署判断服务状态。
实际代码(摘自 main.py 的 lifespan 函数):
@asynccontextmanager
async def lifespan(app: FastAPI):
# 1. 启动日志系统
start_logger()
# 2. 按需重置配置(用于测试/调试场景)
if RESET_CONFIG_ON_START:
reset_config()
# 3. 同步安装用户自定义函数和工具的外部依赖(阻塞执行,确保首次使用前就绪)
log.info("Installing external dependencies of functions and tools...")
install_tool_and_function_dependencies()
# 4. 建立 Redis 连接(用于 Socket.IO 集群广播、任务队列)
app.state.redis = get_redis_connection(
redis_url=REDIS_URL,
redis_sentinels=get_sentinels_from_env(REDIS_SENTINEL_HOSTS, REDIS_SENTINEL_PORT),
redis_cluster=REDIS_CLUSTER,
async_mode=True,
)
# 5. 若 Redis 可用,启动任务命令监听协程
if app.state.redis is not None:
app.state.redis_task_command_listener = asyncio.create_task(
redis_task_command_listener(app)
)
# 6. 启动周期性 Socket 用量池清理任务
asyncio.create_task(periodic_usage_pool_cleanup())
# 7. 按需预加载所有模型列表缓存(避免第一个用户等待模型列表加载)
if app.state.config.ENABLE_BASE_MODELS_CACHE:
await get_all_models(mock_request, None)
yield # 应用正式运行,此后为关闭清理逻辑
# 8. 优雅关闭:取消 Redis 监听任务
if hasattr(app.state, "redis_task_command_listener"):
app.state.redis_task_command_listener.cancel()
嵌入模型与重排序模型在模块级(lifespan 之外)同步初始化:
# 根据配置选择嵌入引擎(本地 sentence-transformers / OpenAI / Ollama / Azure)
app.state.EMBEDDING_FUNCTION = get_embedding_function(
app.state.config.RAG_EMBEDDING_ENGINE,
app.state.config.RAG_EMBEDDING_MODEL,
embedding_function=app.state.ef,
url=..., # 根据 engine 类型选择对应 API 地址
key=..., # 对应 API Key
embedding_batch_size=app.state.config.RAG_EMBEDDING_BATCH_SIZE,
)
# 重排序模型同理,支持 ColBERT 本地模型或外部 Reranker API
app.state.RERANKING_FUNCTION = get_reranking_function(
app.state.config.RAG_RERANKING_ENGINE,
app.state.config.RAG_RERANKING_MODEL,
reranking_function=app.state.rf,
)
```6
一个典型请求生命周期可以概括为:
客户端请求
→ 进入 main.py(主应用入口)
→ 依次通过中间件链(跨域/压缩/会话/审计/安全)
→ 路由分发到对应业务模块(如 chats、retrieval、models)
→ 若是流式或协同事件则通过 Socket.IO 推送
→ 返回标准响应或持续事件流
### 2. 路由层 `routers/`
每个业务模块独立一个文件,典型分工:
| 文件 | 职责 |
|---|---|
| `auths.py` | 用户登录/注册/OAuth2/API Key |
| `chats.py` | 聊天历史 CRUD |
| `ollama.py` | 代理转发 Ollama API |
| `openai.py` | 代理转发 OpenAI 兼容 API |
| `retrieval.py` | RAG 文档处理与检索 |
| `tasks.py` | 标题生成、自动标签等后台任务 |
| `audio.py` | STT/TTS 语音接口 |
| `images.py` | 图像生成(A1111/ComfyUI/OpenAI) |
| `functions.py` | 用户自定义 Python 插件 |
| `tools.py` | 工具调用(Function Calling) |
| `knowledge.py` | 知识库管理 |
| `models.py` | 模型配置管理 |
| `channels.py` | 多用户频道 |
| `notes.py` | 协同笔记 |
| `configs.py` | 管理员动态配置 API |
| `scim.py` | 企业 SCIM 用户同步 |
### 3. 数据模型层 `models/`
使用 SQLAlchemy ORM,每个实体独立文件,包含:
- Pydantic 数据验证模型(Request/Response Schema)
- 数据库 Table 定义
- CRUD 操作方法(静态方法模式)
主要实体:`Users`、`Chats`、`Messages`(独立表)、`Files`、`Knowledge`、`Functions`、`Tools`、`Models`、`Channels`、`Notes`、`Folders`、`Groups`、`Memories`、`Feedbacks`
### 4. 数据库迁移 `migrations/`
使用 **Alembic** 管理 Schema 演进,历史可见项目从简单结构逐步演化:
- 早期迁移(001~018):顺序数字命名
- 新迁移:随机 hash 命名(Alembic 标准)
- 支持 SQLite 和 PostgreSQL 双路迁移
这套机制在工程上的实现可以拆成 4 层:
1. 迁移目录与版本链
后端目录里有 `alembic.ini`、`migrations/env.py`、`migrations/versions/*.py`。其中:
- `env.py` 负责读取当前数据库连接并初始化 Alembic 上下文。
- `versions/*.py` 每个文件代表一次结构变更,文件内有 `revision` 和 `down_revision`,通过它们组成一条可追踪的迁移链。
- 执行升级时,Alembic 会在数据库中维护版本表(通常是 `alembic_version`),记录当前迁移到哪个 revision。
2. 从顺序编号到 hash 命名
早期 `001...018` 的命名本质是团队手动维护阶段;后期切到 Alembic 默认 hash 命名,是为了降低多人并行开发时的冲突概率。命名方式变了,但迁移机制不变:
- 每次变更仍然是一个独立 revision 文件。
- 仍通过 `down_revision` 串联前后依赖。
- 升级/回滚仍由 Alembic 统一调度。
3. 为什么能同时支持 SQLite 和 PostgreSQL
核心不是写两套迁移,而是尽量在同一迁移脚本里使用跨方言能力:
- 优先使用 Alembic `op.*` 抽象(如 `op.add_column`、`op.create_index`),让 Alembic 根据方言生成对应 SQL。
- 涉及数据库差异的操作(类型、索引、默认值表达式)在脚本里做条件分支或采用双方都支持的写法。
- 启动时由配置/环境变量决定 SQLAlchemy `database_url`,Alembic 跟随该连接执行同一版本链。
也就是说:代码层面是一套迁移历史,运行时根据连接到 SQLite 或 PostgreSQL 选择具体 SQL 方言。
4. 典型执行流程(开发/部署)
```bash
# 1) 生成迁移(基于模型变更)
alembic revision -m "add_xxx"
# 2) 在 upgrade() / downgrade() 中补充结构变更
# 3) 升级到最新版本
alembic upgrade head
# 4) 必要时回滚一步
alembic downgrade -1
在 CI/CD 或容器启动脚本中,通常会先执行 alembic upgrade head,确保应用代码与数据库结构处于同一版本,再启动 FastAPI 服务。
5. RAG 检索系统 retrieval/
retrieval/
├── main.py # 文档处理主入口(分块、嵌入、存储)
├── reranker/ # 重排序器
│ ├── colbert.py # ColBERT 本地重排
│ └── external.py # 外部 Reranker API
└── web/ # 网络搜索引擎适配
├── google_pse.py, bing.py, brave.py,
├── duckduckgo.py, searxng.py, tavily.py,
├── perplexity.py, exa.py ...(16个搜索引擎)
RAG 数据流:
用户上传文件
→ 内容提取(Tika / Docling / Datalab Marker / 原生解析)
→ 文本分块(Chunk Size / Overlap)
→ 嵌入向量化(本地 sentence-transformers / OpenAI / Ollama)
→ 存入向量数据库(ChromaDB / Qdrant / Milvus 等)
查询时:
向量相似度检索 → (可选)BM25 混合检索 → 重排序 → 注入 Prompt
6. WebSocket 层 socket/
基于 Socket.IO + aiocache:
- 支持单机模式(内存)和 Redis 集群模式(水平扩展)
- 支持 Redis Sentinel 高可用
- 实现流式响应事件推送
- 基于 Yjs CRDT 实现多人协同编辑笔记
- 管理在线用户池和模型使用池
7. 工具函数库 utils/
| 文件 | 功能 |
|---|---|
auth.py |
JWT 签发/验证,角色权限检查 |
chat.py |
消息处理、Prompt 构造、流式响应 |
filter.py |
消息过滤器(插件 Pipeline) |
plugin.py |
自定义函数/工具插件加载执行 |
oauth.py |
OAuth2/OIDC 提供者接入 |
audit.py |
审计日志中间件 |
access_control.py |
资源级访问控制 |
middleware.py |
请求预处理中间件 |
email.py |
邮件发送 |
pdf_generator.py |
聊天导出 PDF |
redis.py |
Redis 连接工具 |
四、前端架构详解
1. 路由结构 src/routes/
routes/
├── (app)/ # 主应用组(需要认证,Layout 保护)
│ ├── +page.svelte # 主页(聊天界面)
│ ├── c/[id]/ # 具体聊天会话
│ ├── admin/ # 管理面板
│ ├── workspace/ # 工作空间
│ ├── channels/ # 频道
│ └── notes/ # 笔记
├── auth/ # 登录/注册页
├── forgot-password/ # 密码找回
├── complete-profile/ # 新用户完善信息
├── s/ # 聊天分享页(无需认证)
└── watch/ # 观察者模式
2. 组件层 src/lib/components/
按功能域划分大目录:
components/
├── chat/ # 核心聊天界面
│ ├── Messages/ # 消息列表与渲染
│ ├── MessageInput/ # 消息输入框(富文本 Tiptap)
│ ├── ContentRenderer/# Markdown/代码/Mermaid/KaTeX 渲染
│ ├── ModelSelector/ # 模型选择器
│ ├── Controls/ # 聊天控制(RAG、参数调整)
│ └── Settings/ # 聊天设置弹窗
├── layout/ # 全局布局
│ ├── Navbar/ # 顶部导航
│ ├── Sidebar/ # 左侧会话列表
│ └── Overlay/ # 模态框容器
├── workspace/ # 工作空间管理面板
│ ├── Models/ # 自定义模型配置
│ ├── Knowledge/ # 知识库管理
│ ├── Prompts/ # Prompt 模板
│ ├── Tools/ # 工具插件
│ └── Functions/ # 自定义函数
├── admin/ # 管理员面板(用户/设置/评估)
├── channel/ # 频道功能
├── notes/ # 协同笔记编辑器
├── papers/ # 论文管理
├── playground/ # 模型 Playground
└── common/ # 通用 UI 组件
3. 状态管理 src/lib/stores/index.ts
使用 Svelte 原生 Writable Stores(无需 Redux/Pinia),核心状态:
// 用户会话
export const user = writable<SessionUser>();
export const config = writable<Config>();
// 实时连接
export const socket = writable<Socket>();
export const activeUserIds = writable<string[]>();
// 聊天状态
export const chatId = writable('');
export const models = writable<Model[]>();
export const chats = writable(null);
export const folders = writable([]);
// UI 状态
export const theme = writable('system');
export const mobile = writable(false);
4. API 调用层 src/lib/apis/
与后端路由一一对应,封装 fetch 调用。每个目录对应一个后端路由模块(如 apis/chats/、apis/ollama/ 等),统一处理错误和认证 Token 注入。
5. 特殊能力
lib/pyodide/:通过 Pyodide 在浏览器端运行 Python 代码(沙盒代码执行)lib/workers/:Web Worker 处理语音合成(Kokoro TTS)等耗时任务lib/i18n/:i18next 国际化,支持多语言切换
五、核心业务流程
聊天请求流程
用户输入
→ 前端 MessageInput(Tiptap 富文本编辑器)
→ 调用 /api/chat/completions
→ 后端 main.py 中 /api/chat/completions 路由
→ 执行 Filter 类型函数插件(inlet 阶段)
→ 注入 RAG 上下文(如有知识库)
→ 注入记忆(Memory)
→ 注入工具定义(Function Calling)
→ 转发到 Ollama / OpenAI
→ 流式响应 → Socket.IO 推送到前端
→ 执行 Filter 类型函数插件(outlet 阶段)
→ 自动触发后台任务(标题生成、Auto Tag)
→ 前端 ContentRenderer 渲染 Markdown / 代码块 / KaTeX / Mermaid
插件/函数系统
用户在工作空间编写 Python 函数
→ 分三类:
Filter(过滤器):修改 inlet/outlet 消息
Pipe(管道):替换整个模型调用流程(自定义 Provider)
Action(动作):在消息上添加按钮触发额外操作
→ 后端 utils/plugin.py 动态加载并执行用户代码
六、部署架构
┌──────────────────────────────────────────┐
│ Docker 单容器 │
│ ┌─────────────┐ ┌───────────────────┐ │
│ │ FastAPI │ │ 静态前端文件 │ │
│ │ + Socket.IO│ │ (SvelteKit 构建) │ │
│ └──────┬──────┘ └───────────────────┘ │
│ │ │
│ ┌──────▼──────┐ ┌───────────────────┐ │
│ │ SQLite / │ │ 本地文件存储 / │ │
│ │ PostgreSQL │ │ S3 / MinIO │ │
│ └─────────────┘ └───────────────────┘ │
└──────────────────────────────────────────┘
水平扩展时:
Redis ← Socket.IO 跨实例消息广播
Redis ← WebSocket Session 共享
集群模式下通过 Redis 实现 Socket.IO 的 AsyncRedisManager,多个后端实例可以共享实时消息状态,前端通过 socket.io-client 透明连接。
七、安全设计
- JWT 认证(HS256),支持 API Key
- RBAC 角色权限:
admin/user/pending - 资源级 ACL:知识库、模型、工具等均有独立访问控制
- 安全 Headers 中间件(
security_headers.py) - 审计日志(
AuditLoggingMiddleware,可分级) - SCIM 2.0 企业用户目录集成
- 插件沙盒:用户函数有 Valve(参数校验)机制
这个项目是一个设计非常成熟的全栈应用,前后端分离但共同构建在同一仓库中,后端通过专门的静态文件服务来托管 SvelteKit 构建产物,形成单容器即可完整部署的模式。
八、前后端调用链图(聊天主链路)
这条链路的核心结论是:
- 前端以
Chat.svelte为编排中心,MessageInput.svelte负责输入聚合。 - 后端以
openai.py为模型调用主入口,retrieval.py提供可插拔检索能力。 main.py只做装配和生命周期,不承载具体业务规则。
九、聊天主链路
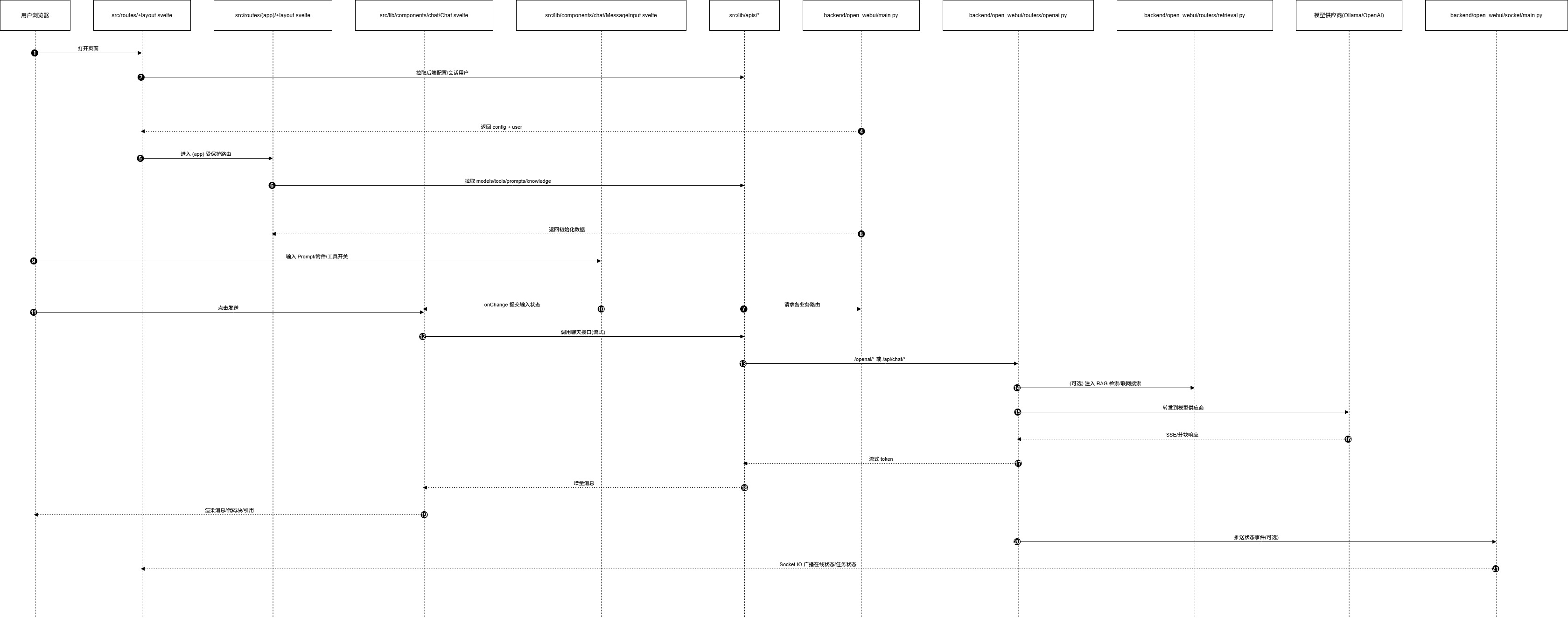
1) 前端顶层入口
-
src/routes/+layout.svelte- 作用:全局启动器。
- 关键职责:初始化 i18n、读取用户会话、建立 Socket 连接、注入全局上下文。
- 二开关注点:
- 新的全局能力(如埋点、全局快捷键、统一错误处理)放在这里。
- 避免在这里塞页面级业务,保持“装配层”职责单一。
-
src/routes/(app)/+layout.svelte- 作用:登录后应用壳。
- 关键职责:拉取模型列表、工具、知识库、用户设置、公告等初始数据。
- 二开关注点:
- 所有“登录后需要一次拉齐的数据”在这里加载。
- 新增全局配置开关,优先从这里注入到 store。
-
src/routes/(app)/+page.svelte- 作用:聊天主页路由,通常很薄。
- 关键职责:挂载
Chat.svelte。 - 二开关注点:
- 这里不宜堆业务逻辑,保持路由层轻量。
2) 前端聊天编排层
-
src/lib/components/chat/Chat.svelte- 作用:聊天主控制器。
- 关键职责:
- 维护当前会话上下文(模型、工具、过滤器、附件、历史消息)。
- 串联发送、停止、重试、流式渲染、错误提示。
- 对接 RAG、搜索、工具调用等高级能力开关。
- 二开关注点:
- 任何“发送前后行为变更”优先从这里切入。
- 新增消息元数据(比如业务标签)通常要在这里拼装并传给 API 层。
-
src/lib/components/chat/MessageInput.svelte- 作用:输入聚合器。
- 关键职责:
- 聚合文本、附件、工具选择、联网搜索开关、代码解释器开关。
- 处理输入变量、快捷命令、上传行为。
- 二开关注点:
- 新输入控件(按钮、开关、快捷命令)应先落这里,再传到
Chat.svelte。
- 新输入控件(按钮、开关、快捷命令)应先落这里,再传到
-
src/lib/components/chat/Messages/*.svelte- 作用:输出渲染层。
- 关键职责:渲染流式结果、代码块、Markdown、引用、错误态。
- 二开关注点:
- 改展示样式看这里;改请求行为不要只改这里。
3) 前端 API 适配层
-
src/lib/apis/openai/index.ts- 作用:聊天主接口封装。
- 关键职责:把前端 payload 发送到后端并处理错误。
- 二开关注点:
- 增加新参数时,这里是前端与后端契约的第一落点。
-
src/lib/apis/chats/index.ts- 作用:会话 CRUD。
- 关键职责:会话创建、读取、更新、标签等。
- 二开关注点:
- 聊天元数据变更(如新增会话字段)需要同步改这里。
4) 后端装配与业务入口
-
backend/open_webui/main.py- 作用:后端装配器。
- 关键职责:注册 routers、挂中间件、挂载 Socket 子应用、启动期初始化。
- 二开关注点:
- 只做“组装”,不要把业务规则散落到这里。
-
backend/open_webui/routers/openai.py
- 作用:聊天推理主入口。
- 关键职责:
- 接收聊天请求并做鉴权/参数整形。
- 按模型配置转发到外部供应商。
- 处理流式输出并返回给前端。
- 二开关注点:
- 新增模型参数、请求前后钩子、响应后处理,通常改这里。 -
backend/open_webui/routers/chats.py
- 作用:会话持久化入口。
- 关键职责:会话列表、会话详情、标签和历史管理。
- 二开关注点:
- 新增会话维度的业务字段时,这里和模型层要同步改。 -
backend/open_webui/routers/retrieval.py
- 作用:RAG 与联网搜索入口。
- 关键职责:检索、网页搜索、结果融合、向量化流程编排。
- 二开关注点:
- 新增检索策略、搜索引擎或重排逻辑从这里扩展。 -
backend/open_webui/models/*.py
- 作用:数据模型与 CRUD。
- 关键职责:实体定义、读写方法、部分 schema。
- 二开关注点:
- 字段变更必然联动迁移脚本与 API 返回结构。
5) 关键阅读原则
- 先读“编排文件”(layout、Chat、openai router),再读“细节文件”(UI 小组件、工具函数)。
- 先确认数据契约(请求/响应字段),再改渲染和样式。
- 一次改造尽量沿一条链路改全:UI -> API -> Router -> Model -> 回写 UI。
开发路径
按目标拆分阅读入口,建议从上到下逐步深入:
1. 改 UI 和交互
- 前端入口:
src/lib/components/chatsrc/lib/components/layoutsrc/lib/components/common
- 样式入口:
src/app.csssrc/tailwind.css
2. 改聊天行为
- 前端入口:
src/lib/components/chat/Chat.sveltesrc/lib/apis/openai
- 后端入口:
backend/open_webui/routers/openai.pybackend/open_webui/utils
3. 改模型管理或新增供应商
- 前端入口:
src/lib/components/workspace/Modelssrc/lib/apis/index.ts
- 后端入口:
backend/open_webui/routers/models.pybackend/open_webui/routers/openai.pybackend/open_webui/routers/ollama.py
4. 改 RAG / 联网搜索 / 知识库
- 前端入口:
src/lib/components/workspace/Knowledgesrc/lib/apis/retrieval
- 后端入口:
backend/open_webui/routers/retrieval.pybackend/open_webui/retrieval
5. 接企业内部系统或做插件生态
- 前端入口:
src/lib/components/workspace/Toolssrc/lib/components/workspace/Functions
- 后端入口:
backend/open_webui/routers/tools.pybackend/open_webui/routers/functions.py

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 3
3 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)