笔试文献翻译部分+面试翻译
笔试文献翻译部分
Gemini 2.5: Pushing the Frontier(前沿) with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic(智能体的) Capabilities. (Gemini)---Gemini 2.5:凭借高级推理、多模态、长上下文和下一代智能体能力突破前沿。(Gemini)
摘要
In this report, we introduce the Gemini 2.X model family: Gemini 2.5 Pro and Gemini 2.5 Flash, as well as our earlier Gemini 2.0 Flash and Flash-Lite models. Gemini 2.5 Pro is our most capable model yet, achieving SoTA performance on frontier coding and reasoning benchmarks. In addition to its incredible coding and reasoning skills, Gemini 2.5 Pro is a thinking model that excels at multimodal understanding and it is now able to process up to 3 hours of video content. Its unique combination of long context, multimodal and reasoning capabilities can be combined to unlock new agentic workflows. Gemini 2.5 Flash provides excellent reasoning abilities at a fraction of the compute and latency requirements and Gemini 2.0 Flash and Flash-Lite provide high performance at low latency and cost. Taken together, the Gemini 2.X model generation spans the full Pareto frontier of model capability vs cost, allowing users to explore the boundaries of what is possible with complex agentic problem solving.
In this report, we introduce the Gemini 2.X model family: Gemini 2.5 Pro and Gemini 2.5 Flash, as well as our earlier Gemini 2.0 Flash and Flash-Lite models. Gemini 2.5 Pro is our most capable(有能力的) model yet, achieving SoTA(state-of-the-art 现有技术水平/业界行业水平) performance on frontier coding(前沿编码) and reasoning benchmarks(基准测试). In addition to(除了) its incredible(极好的) coding and reasoning(推理的) skills, Gemini 2.5 Pro is a thinking model(思考模型) that excels(擅长) at multimodal understanding(多模态理解) and it is now able to process up to 3 hours of video content. Its unique combination of long context(长上下文), multimodal and reasoning capabilities can be combined to unlock new agentic workflows(智能体工作流). Gemini 2.5 Flash provides excellent reasoning abilities at a fraction(少量) of the compute and latency(延迟) requirements and Gemini 2.0 Flash and Flash-Lite provide high performance at low latency and cost. Taken together(综上所诉), the Gemini 2.X model generation spans(跨越) the full Pareto frontier(帕累托前沿) of model capability vs cost, allowing users to explore the boundaries of what is possible with complex agentic problem solving(智能体问题解决).
在本报告中,我们介绍了 Gemini 2.X 模型系列:Gemini 2.5 Pro 和 Gemini 2.5 Flash,以及我们早期的 Gemini 2.0 Flash 和 Flash-Lite 模型。Gemini 2.5 Pro 是我们迄今为止能的力最强模型,在前沿编程和推理基准测试中取得了 SoTA (现有技术水平) 的表现。除了其惊人的编程和推理技能外,Gemini 2.5 Pro 还是一个擅长 多模态理解 的思考模型,现在能够处理长达 3 小时的视频内容。其独特的长上下文、多模态和推理能力的结合,可以解锁新的智能体工作流。Gemini 2.5 Flash 以极低的计算和延迟需求提供了卓越的推理能力,而 Gemini 2.0 Flash 和 Flash-Lite 则以低延迟和低成本提供了高性能。综上所述,Gemini 2.X 模型代际跨越了模型能力与成本的完整帕累托前沿,允许用户探索复杂智能体问题求解的可能性边界。
In this report, we introduce the Gemini 2.X model family: Gemini 2.5 Pro and Gemini 2.5 Flash, as well as our earlier Gemini 2.0 Flash and Flash-Lite models.在本报告中,我们介绍 Gemini 2.X 模型系列:Gemini 2.5 Pro 和 Gemini 2.5 Flash,以及我们早期的 Gemini 2.0 Flash 和 Flash-Lite 模型。
Gemini 2.5 Pro is our most capable(有能力的) model yet, achieving SoTA(state-of-the-art 现有技术水平 / 业界行业水平) performance on frontier coding(前沿编码) and reasoning benchmarks(基准测试).Gemini 2.5 Pro 是我们迄今为止最有能力的模型,在前沿编码与推理基准测试中达到业界行业水平的性能。
In addition to (除了) its incredible(极好的) coding and reasoning(推理的) skills, Gemini 2.5 Pro is a thinking model(思考模型) that excels(擅长) at multimodal understanding(多模态理解) and it is now able to process up to 3 hours of video content.除了拥有极好的编码和推理能力,Gemini 2.5 Pro 还是一款擅长 **** 多模态理解的思考模型,如今可处理长达 3 小时的视频内容。
Its unique combination of long context(长上下文), multimodal and reasoning capabilities can be combined to unlock new agentic workflows(智能体工作流).它将长上下文、多模态与推理能力独特结合,能够解锁全新的智能体工作流。
Gemini 2.5 Flash provides excellent reasoning abilities at a fraction(少量) of the compute and latency(延迟) requirements.Gemini 2.5 Flash 以少量的计算与延迟需求,提供出色的推理能力。
Gemini 2.0 Flash and Flash-Lite provide high performance at low latency and cost.Gemini 2.0 Flash 和 Flash-Lite 以低延迟、低成本实现高性能。
Taken together(综上所诉), the Gemini 2.X model generation spans(跨越) the full Pareto frontier(帕累托前沿) of model capability vs cost, allowing users to explore the boundaries of what is possible with complex agentic problem solving(智能体问题解决).综上所诉,Gemini 2.X 系列模型跨越了模型能力与成本的完整帕累托前沿,支持用户探索智能体问题解决的可能性边界。
引言
We present our latest multimodal models from the Gemini line: Gemini 1.5 Pro and Gemini 1.5 Flash. They are members of Gemini 1.5, a new family of highly-capable multimodal models which incorporates our latest innovations in sparse and dense scaling as well as major advances in training, distillation and serving infrastructure that allow it to push the boundary of efficiency, reasoning, planning, multi-linguality, function calling and long-context performance. Gemini 1.5 models are built to handle extremely long contexts; they have the ability to recall and reason over fine-grained information from up to at least 10M tokens. This scale is unprecedented among contemporary large language models (LLMs), and enables the processing of long-form mixed-modality inputs including entire collections of documents, multiple hours of video, and almost five days long of audio.
We present our latest multimodal(多模态) models from the Gemini line: Gemini 1.5 Pro and Gemini 1.5 Flash. They are members of Gemini 1.5, a new family of highly-capable(能力极强的) multimodal(多模态) models which incorporates(将某物融入、包含到某物) our latest innovations in sparse(稀疏的) and dense scaling(扩展) as well as major advances in training, distillation(蒸馏) and serving infrastructure that allow it to push the boundary of efficiency, reasoning, planning, multi-linguality(多语言能力), function calling(函数调用) and long-context performance(长上下文性能). Gemini 1.5 models are built to(旨在) handle extremely long contexts; they have the ability to recall(召回) and reason over(对什么进行推理) fine-grained(细粒度的) information from up to at least 10M tokens. This scale is unprecedented(前所未有的) among contemporary(同时代的) large language models (LLMs), and enables the processing of long-form(长形式) mixed-modality(混合模态) inputs including entire collections of documents, multiple hours of video, and almost five days long of audio.
我们推出了Gemini系列的最新多模态模型:Gemini 1.5 Pro和Gemini 1.5 Flash。它们属于Gemini 1.5这一全新的高性能多模态模型家族,该家族融合了我们在稀疏和密集扩展方面的最新创新,以及在训练、蒸馏和服务基础设施方面的重大进展,这些进展使其能够突破效率、推理、规划、多语言能力、函数调用和长上下文性能的边界。Gemini 1.5模型旨在处理极长的上下文,它们能够从至少1000万个token中召回并对细粒度信息进行推理。这一规模在当代大型语言模型(LLMs)中是前所未有的,它能够处理长形式的混合模态输入,包括完整的文档集合、数小时的视频以及近五天时长的音频。
We present our latest multimodal (多模态) models from the Gemini line: Gemini 1.5 Pro and Gemini 1.5 Flash.我们推出了 Gemini 系列的最新multimodal(多模态) 模型:Gemini 1.5 Pro 和 Gemini 1.5 Flash。
They are members of Gemini 1.5, a new family of highly-capable (能力极强的) multimodal (多模态) models which incorporates (将某物融入、包含到某物) our latest innovations in sparse (稀疏的) and dense scaling (扩展) as well as major advances in training, distillation (蒸馏) and serving infrastructure that allow it to push the boundary of efficiency, reasoning, planning, multi-linguality (多语言能力), function calling (函数调用) and long-context performance (长上下文性能).它们属于 Gemini 1.5,这是一个全新的highly-capable(能力极强的)multimodal(多模态) 模型家族,它incorporates(将某物融入、包含到某物) 我们在sparse(稀疏的) 和密集scaling(扩展) 方面的最新创新,以及在训练、distillation(蒸馏) 和服务基础设施上的重大进展,使其能够突破效率、推理、规划、multi-linguality(多语言能力)、function calling(函数调用) 和long-context performance(长上下文性能) 的边界。
Gemini 1.5 models are built to (旨在) handle extremely long contexts; they have the ability to recall (召回) and reason over (对什么进行推理) fine-grained (细粒度的) information from up to at least 10M tokens.Gemini 1.5 模型built to(旨在) 处理极长上下文;它们能够从至少 1000 万个 token 中recall(召回) 并reason over(对什么进行推理)fine-grained(细粒度的) 信息。
This scale is unprecedented (前所未有的) among contemporary (同时代的) large language models (LLMs), and enables the processing of long-form (长形式) mixed-modality (混合模态) inputs including entire collections of documents, multiple hours of video, and almost five days long of audio.这一规模在当代contemporary(同时代的) 大型语言模型 (LLMs) 中是unprecedented(前所未有的),并支持处理long-form(长形式)mixed-modality(混合模态) 输入,包括完整的文档集、数小时视频以及近五天时长的音频。
Qwen2.5 Technical Report(国产大模型通义千问)---Qwen2.5技术报告
原文部分1:训练与技术改进
In this report, we introduce Qwen2.5, a comprehensive series of large language models (LLMs) designed to meet diverse needs. Compared to previous iterations, Qwen 2.5 has been significantly improved during both the pre-training and post-training stages. In terms of pre-training, we have scaled the high-quality pre-training datasets from the previous 7 trillion tokens to 18 trillion tokens. This provides a strong foundation for commonsense, expert knowledge, and reasoning capabilities. In terms of post-training, we implement intricate supervised finetuning with over 1 million samples, as well as multistage reinforcement learning, including offline learning DPO and online learning GRPO. Post-training techniques significantly enhance human preference, and notably improve long text generation, structural data analysis, and instruction following.
在本报告中,我们介绍了 Qwen2.5,这是一个旨在满足多样化需求的大型语言模型(LLMs)综合系列。与之前的迭代版本相比,Qwen 2.5 在预训练和后训练阶段都进行了显著改进。在预训练方面,我们将高质量预训练数据集的规模从之前的 7 万亿 token 扩展到了 18 万亿 token。这为常识、专家知识和推理能力提供了坚实的基础。在后训练方面,我们实施了复杂的监督微调(包含超过 100 万个样本),以及多阶段强化学习,包括离线学习 DPO 和在线学习 GRPO。后训练技术显著增强了人类偏好(对齐),并显著改善了长文本生成、结构化数据分析和指令遵循能力。
In this report, we introduce Qwen2.5, a comprehensive(全面的) series of large language models (LLMs) designed to meet diverse needs.在本报告中,我们介绍了 Qwen2.5,这是一个旨在满足多样化需求的大型语言模型(LLMs)综合系列。
Compared to previous iterations(迭代版本), Qwen 2.5 has been significantly improved during both the pre-training and post-training(后训练) stages.与之前的迭代版本相比,Qwen 2.5 在预训练和后训练阶段都进行了显著改进。
In terms of(在什么方面) pre-training, we have scaled(扩大) the high-quality pre-training datasets from the previous 7 trillion(万亿) tokens(标记) to 18 trillion tokens.在预训练方面,我们将高质量预训练数据集的规模从之前的 7 万亿 token 扩展到了 18 万亿 token。
This provides a strong foundation for commonsense(常识), expert knowledge, and reasoning capabilities(能力).这为常识、专家知识和推理能力提供了坚实的基础。
In terms of post-training, we implement intricate(复杂的) supervised(有监督的) finetuning(微调) with over 1 million samples, as well as multistage reinforcement(强化) learning, including offline(离线的) learning DPO and online learning GRPO.在后训练方面,我们实施了复杂的监督微调(包含超过 100 万个样本),以及多阶段强化学习,包括离线学习 DPO 和在线学习 GRPO。
Post-training techniques significantly enhance human preference(偏好), and notably improve long text generation(生成), structural data analysis, and instruction following.后训练技术显著增强了人类偏好(对齐),并显著改善了长文本生成、结构化数据分析和指令遵循能力。
原文部分2:模型规格与发布
To handle diverse and varied use cases effectively, we present Qwen2.5 LLM series in rich configurations.The open-weight offerings include base models and instruction-tuned models in sizes of 0.5B, 1.5B, 3B, 7B, 14B, 32B, and 72B parameters. Quantized versions of the instruction-tuned models are also provided. Over 100 models can be accessed from Hugging Face Hub, ModelScope, and Kaggle. In addition, for hosted solutions, the proprietary models currently include two mixture-of-experts (MoE) variants: Qwen2.5 Turbo and Qwen2.5-Plus, both available from Alibaba Cloud Model Studio.
为了有效处理多样化的用例,我们推出了配置丰富的 Qwen2.5 LLM 系列。开放权重产品包括基础模型和指令微调模型,参数规模涵盖 0.5B、1.5B、3B、7B、14B、32B 和 72B。同时也提供了指令微调模型的量化版本。在 Hugging Face Hub、ModelScope 和 Kaggle 上可访问超过 100 个模型。此外,对于托管解决方案,目前的专有模型包括两个混合专家(MoE)变体:Qwen2.5 Turbo 和 Qwen2.5-Plus,均可在阿里云 Model Studio 上获取。
To handle diverse(多样的) and varied use cases effectively, we present Qwen2.5 LLM series in rich configurations.为了有效处理多样化的用例,我们推出了配置丰富的 Qwen2.5 LLM 系列。
The open-weight(开放权值) offerings(产品) include base models and instruction-tuned models in sizes of 0.5B, 1.5B, 3B, 7B, 14B, 32B, and 72B parameters.开放权重产品包括基础模型和指令微调模型,参数规模涵盖 0.5B、1.5B、3B、7B、14B、32B 和 72B。
Quantized(被量化的) versions of the instruction-tuned models are also provided.同时也提供了指令微调模型的量化版本。
Over 100 models can be accessed from Hugging Face Hub(平台), ModelScope, and Kaggle.在 Hugging Face Hub、ModelScope 和 Kaggle 上可访问超过 100 个模型。
In addition, for hosted(被托管的) solutions, the proprietary(专有的) models currently include two mixture-of-experts (MoE)(混合专家) variants(变体): Qwen2.5 Turbo and Qwen2.5-Plus, both available(可获取的) from Alibaba Cloud Model Studio(工作室).此外,对于托管解决方案,目前的专有模型包括两个混合专家(MoE)变体:Qwen2.5 Turbo 和 Qwen2.5-Plus,均可在阿里云 Model Studio 上获取。
原文部分3:性能表现
Qwen2.5 has demonstrated top-tier performance on a wide range of benchmarks evaluating language understanding, reasoning, mathematics, coding, human preference alignment, etc. Specifically, the open-weight flagship Qwen2.5-72B-Instruct outperforms a number of open and proprietary models and demonstrates competitive performance to the state-of-the-art open-weight model, Llama-3-405B-Instruct, which is around 5 times larger. Qwen2.5-Turbo and Qwen2.5-Plus offer superior cost-effectiveness while performing competitively against GPT-4o-mini and GPT-4o respectively. Additionally, as the foundation, Qwen2.5 models have been instrumental in training specialized models such as Qwen2.5-Math (Yang et al., 2024b), Qwen2.5-Coder (Hui et al., 2024), QwQ (Qwen Team, 2024d), and multimodal models.
Qwen2.5 在评估语言理解、推理、数学、编程、人类偏好对齐等广泛的基准测试中展现了顶尖性能。具体而言,开放权重旗舰模型 Qwen2.5-72B-Instruct 优于许多开放和专有模型,并展现出与现有技术水平(SOTA)的开放权重模型 Llama-3-405B-Instruct(其规模约为 Qwen 的 5 倍)相当的竞争力。Qwen2.5-Turbo 和 Qwen2.5-Plus 在分别与 GPT-4o-mini 和 GPT-4o 竞争时提供了卓越的成本效益。此外,作为基础,Qwen2.5 模型在训练专用模型(如 Qwen2.5-Math、Qwen2.5-Coder、QwQ 和多模态模型)方面发挥了重要作用。
Qwen2.5 has demonstrated(展示了) top-tier(顶级的) performance on a wide range of benchmarks(基准测试) evaluating language understanding, reasoning, mathematics, coding, human preference alignment(对齐), etc.Qwen2.5 在评估语言理解、推理、数学、编程、人类偏好对齐等广泛的基准测试中展现了顶尖性能。
Specifically(具体地), the open-weight(开放权值) flagship(旗舰) Qwen2.5-72B-Instruct outperforms(优于) a number of open and proprietary(专有的) models and demonstrates competitive(竞争力的) performance to the state-of-the-art(最先进的) open-weight model, Llama-3-405B-Instruct, which is around 5 times larger.具体而言,开放权重旗舰模型 Qwen2.5-72B-Instruct 优于许多开放和专有模型,并展现出与现有技术水平(SOTA)的开放权重模型 Llama-3-405B-Instruct(其规模约为 Qwen 的 5 倍)相当的竞争力。
Qwen2.5-Turbo and Qwen2.5-Plus offer superior(更好的) cost-effectiveness(成本效益) while performing competitively against GPT-4o-mini and GPT-4o respectively.Qwen2.5-Turbo 和 Qwen2.5-Plus 在分别与 GPT-4o-mini 和 GPT-4o 竞争时提供了卓越的成本效益。
Additionally, as the foundation, Qwen2.5 models have been instrumental(起重要作用的) in training specialized(专门的) models such as Qwen2.5-Math (Yang et al., 2024b), Qwen2.5-Coder (Hui et al., 2024), QwQ (Qwen Team, 2024d), and multimodal(多模态) models.此外,作为基础,Qwen2.5 模型在训练专用模型(如 Qwen2.5-Math、Qwen2.5-Coder、QwQ 和多模态模型)方面发挥了重要作用。
原文
The use of retrieval-augmented generation (RAG) to retrieve relevant information from an external knowledge source enables large language models (LLMs) to answer questions over private and/or previously unseen document collections. However, RAG fails on global questions directed at an entire text corpus, such as "What are the main themes in the dataset?", since this is inherently a query focused summarization (QFS) task, rather than an explicit retrieval task. Prior QFS methods, meanwhile, do not scale to the quantities of text indexed by typical RAG systems. To combine the strengths of these contrasting methods, we propose GraphRAG, a graph-based approach to question answering over private text corpora that scales with both the generality of user questions and the quantity of source text. Our approach uses an LLM to build a graph index in two stages: first, to derive an entity knowledge graph from the source documents, then to pre-generate community summaries for all groups of closely related entities. Given a question, each community summary is used to generate a partial response, before all partial responses are again summarized in a final response to the user. For a class of global sensemaking questions over datasets in the 1 million token range, we show that GraphRAG leads to substantial improvements over a conventional RAG baseline for both the comprehensiveness and diversity of generated answers.
利用检索增强生成(RAG)从外部知识源检索相关信息,使大型语言模型(LLMs)能够回答关于私有和 / 或以前从未见过的文档集的问题。然而,RAG 在针对整个文本语料库的全局性问题(例如 “数据集中的主要主题是什么?”)上表现失效,因为这本质上是一个以查询为中心的摘要(QFS)任务,而不是一个显式的检索任务。与此同时,先前的 QFS 方法无法扩展(Scale)到典型 RAG 系统所索引的文本量级。为了结合这些截然不同的方法的优势,我们提出了 GraphRAG,这是一种基于图的方法,用于在私有文本语料库上进行问答,它能够随着用户问题的通用性和源文本的数量而扩展。我们的方法使用 LLM 分两个阶段构建图索引:首先,从源文档中推导出一个实体知识图谱;然后,为所有紧密相关的实体组(即社区)预生成社区摘要。给定一个问题,每个社区摘要被用来生成一个部分响应,随后所有部分响应被再次汇总,生成给用户的最终响应。对于在 100 万 token 范围内的数据集上的一类全局意义构建(Global sensemaking)问题,我们表明 GraphRAG 在生成答案的全面性和多样性方面,均比传统的 RAG 基线有实质性的提升。
The use of retrieval-augmented(检索增强) generation (RAG) to retrieve(找回) relevant information from an external knowledge source enables large language models (LLMs) to answer questions over private and/or previously(以前) unseen(未见得) document collections(文件集).利用检索增强生成(RAG)从外部知识源检索相关信息,使大型语言模型(LLMs)能够回答关于私有和 / 或以前从未见过的文档集的问题。
However, RAG fails on global questions directed at(针对) an entire text corpus(语料库), such as "What are the main themes in the dataset?", since this is inherently(本质上) a query focused summarization(总结) (QFS) task, rather than an explicit(明确的) retrieval task.然而,RAG 在针对整个文本语料库的全局性问题(例如 “数据集中的主要主题是什么?”)上表现失效,因为这本质上是一个以查询为中心的摘要(QFS)任务,而不是一个显式的检索任务。
Prior QFS methods, meanwhile, do not scale(扩展) to the quantities(数量) of text indexed(索引得) by typical RAG systems.与此同时,先前的 QFS 方法无法扩展到典型 RAG 系统所索引的文本量级。
To combine(结合) the strengths of these contrasting(形成对比的) methods, we propose GraphRAG, a graph-based approach to question answering over private text corpora(语料库) that scales with both the generality(普遍性) of user questions and the quantity(数量) of source text.为了结合这些截然不同的方法的优势,我们提出了 GraphRAG,这是一种基于图的方法,用于在私有文本语料库上进行问答,它能够随着用户问题的通用性和源文本的数量而扩展。
Our approach uses an LLM to build a graph index in two stages: first, to derive(推导) an entity knowledge graph from the source documents, then to pre-generate(预生成) community(社区) summaries(摘要) for all groups of closely(紧密地) related entities.我们的方法使用 LLM 分两个阶段构建图索引:首先,源文档从中推导出一个实体知识图谱;然后,为所有紧密相关的实体组(即社区)预生成社区摘要。
Given a question, each community summary is used to generate a partial(部分的) response, before all partial responses are again summarized in a final response to the user.给定一个问题,每个社区摘要被用来生成一个部分响应,随后所有部分响应被再次汇总,生成给用户的最终响应。
For a class of global sensemaking(意义构建) questions over datasets in the 1 million token range, we show that GraphRAG leads to substantial(大量的) improvements over a conventional(传统的) RAG baseline(基准) for both the comprehensiveness(全面性) and diversity(多样性) of generated answers.对于在 100 万 token 范围内的数据集上的一类全局意义构建(Global sensemaking)问题,我们表明 GraphRAG 在生成答案的全面性和多样性方面,均比传统的 RAG 基线有实质性的提升。
引言
Retrieval augmented generation (RAG) (Lewis et al., 2020) is an established approach to using LLMs to answer queries based on data that is too large to contain in a language model's context window, meaning the maximum number of tokens (units of text) that can be processed by the LLM at once (Kuratov et al., 2024; Liu et al., 2023).In the canonical RAG setup, the system has access to a large external corpus of text records and retrieves a subset of records that are individually relevant to the query and collectively small enough to fit into the context window of the LLM. The LLM then generates a response based on both the query and the retrieved records (Baumel et al., 2018; Dang, 2006; Laskar et al., 2020; Yao et al., 2017).This conventional approach, which we collectively call vector RAG, works well for queries that can be answered with information localized within a small set of records. However, vector RAG approaches do not support sensemaking queries, meaning queries that require global understanding of the entire dataset, such as "What are the key trends in how scientific discoveries are influenced by interdisciplinary research over the past decade?"
检索增强生成(RAG)是一种既定的方法,用于利用 LLMs 回答基于特定数据的问题,而这些数据过于庞大,无法放入语言模型的上下文窗口中(上下文窗口指 LLM 一次能处理的最大 token 即文本单位数量)。在标准 RAG 设置中,系统可以访问一个大型的外部文本记录语料库,并检索出一个记录子集,这些记录既与查询单独相关,又在总体上足够小,以适应 LLM 的上下文窗口。然后,LLM 基于查询和检索到的记录生成响应。这种传统方法(我们将统称为向量 RAG)对于那些可以通过一小部分记录中的局部信息来回答的查询效果很好。然而,向量 RAG 方法不支持意义构建(Sensemaking)查询,即那些需要对整个数据集进行全局理解的查询,例如 “在过去十年中,跨学科研究如何影响科学发现的主要趋势是什么?”
Retrieval augmented generation (RAG) (Lewis et al., 2020) is an established approach to using LLMs to answer queries based on data that is too large to contain in a language model's context window, meaning the maximum number of tokens (units of text) that can be processed by the LLM at once (Kuratov et al., 2024; Liu et al., 2023).检索增强生成(RAG)是一种既定的方法,用于利用 LLMs 回答基于特定数据的问题,而这些数据过于庞大,无法放入语言模型的上下文窗口中(上下文窗口指 LLM 一次能处理的最大 token 即文本单位数量)。
In the canonical RAG setup, the system has access to a large external corpus of text records and retrieves a subset of records that are individually relevant to the query and collectively small enough to fit into the context window of the LLM.在标准 RAG 设置中,系统可以访问一个大型的外部文本记录语料库,并检索出一个记录子集,这些记录既与查询单独相关,又在总体上足够小,以适应 LLM 的上下文窗口。
The LLM then generates a response based on both the query and the retrieved records (Baumel et al., 2018; Dang, 2006; Laskar et al., 2020; Yao et al., 2017).然后,LLM 基于查询和检索到的记录生成响应。
This conventional approach, which we collectively call vector RAG, works well for queries that can be answered with information localized within a small set of records.这种传统方法(我们将统称为向量 RAG)对于那些可以通过一小部分记录中的局部信息来回答的查询效果很好。
However, vector RAG approaches do not support sensemaking queries, meaning queries that require global understanding of the entire dataset, such as "What are the key trends in how scientific discoveries are influenced by interdisciplinary research over the past decade?"然而,向量 RAG 方法不支持意义构建(Sensemaking)查询,即那些需要对整个数据集进行全局理解的查询,例如 “在过去十年中,跨学科研究如何影响科学发现的主要趋势是什么?”
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent(多智能体) Conversation(agent 方向)---AutoGen:通过多智能体对话赋能下一代大语言模型应用(智能体方向)
摘要
AutoGen2 is an open-source framework that allows developers to build LLM applications via multiple agents that can converse with each other to accomplish tasks. AutoGen agents are customizable, conversable, and cn opaerate in various modes that employ combinations of LLMs, human inputs, and tools. Using AutoGen, developers can also flexibly define agent interaction behaviors. Both natural language and computer code can be used to program flexible conversation patterns for different applications. AutoGen serves as a generic framework for building diverse applications of various complexities and LLM capacities. Empirical studies demonstrate the effectiveness of the framework in many example applications, with domains ranging from mathematics, coding, question answering, operations research, online decision-making, entertainment, etc.
AutoGen2 is an open-source(开源) framework(框架) that allows developers to build LLM applications via multiple agents that can converse with each other to accomplish tasks. AutoGen agents are customizable, conversable, and can operate in various modes that employ combinations of LLMs, human inputs, and tools. Using AutoGen, developers can also flexibly define agent interaction behaviors. Both natural language and computer code can be used to program flexible conversation patterns for different applications. AutoGen serves as a generic framework for building diverse applications of various complexities and LLM capacities. Empirical studies demonstrate the effectiveness of the framework in many example applications, with domains ranging from mathematics, coding, question answering, operations research, online decision-making, entertainment, etc.
AutoGen2 是一个开源框架,允许开发者通过多个能够相互对话以完成任务的智能体(agents)来构建 LLM 应用。AutoGen 智能体是可定制的、可对话的,并且可以在多种模式下运行,这些模式结合了 LLM、人类输入和工具。使用 AutoGen,开发者还可以灵活地定义智能体交互行为。自然语言和计算机代码都可以用来为不同的应用编写灵活的对话模式。AutoGen 作为一个通用框架,用于构建具有不同复杂度和 LLM 能力的多样化应用。实证研究证明了该框架在许多示例应用中的有效性,领域涵盖数学、编码、问答、运筹学、在线决策、娱乐等。
AutoGen2 is an open-source (开源) framework (框架) that allows developers to build LLM applications via multiple agents that can converse with each other to accomplish tasks.AutoGen2 是一个open-source(开源) framework(框架),它允许开发者通过多个能够相互对话以完成任务的智能体来构建大语言模型应用。
AutoGen agents are customizable, conversable, and can operate in various modes that employ combinations of LLMs, human inputs, and tools.AutoGen 智能体可定制、可交互,并能够以多种模式运行,这些模式结合使用大语言模型、人类输入与工具。
Using AutoGen, developers can also flexibly define agent interaction behaviors.使用 AutoGen,开发者还可以灵活地定义智能体的交互行为。
Both natural language and computer code can be used to program flexible conversation patterns for different applications.自然语言和计算机代码都可以用来为不同的应用编程实现灵活的对话模式。
AutoGen serves as a generic framework for building diverse applications of various complexities and LLM capacities.AutoGen 作为一个通用框架,用于构建复杂度各异、大语言模型能力不同的各类应用。
Empirical studies demonstrate the effectiveness of the framework in many example applications, with domains ranging from mathematics, coding, quesion answerintg, operations research, online decision-making, entertainment, etc.实证研究证明了该框架在许多示例应用中的有效性,其应用领域涵盖数学、编码、问答、运筹学、在线决策、娱乐等。
引用
Large language models (LLMs) are becoming a crucial building block in developing powerful agents that utilize LLMs for reasoning, tool usage, and adapting to new observations (Yao et al., 2022; Xi et al., 2023; Wang et al., 2023b) in many real-world tasks. Given the expanding tasks that could benefit from LLMs and the growing task complexity, an intuitive approach to scale up the power of agents is to use multiple agents that cooperate. Prior work suggests that multiple agents can help encourage divergent thinking (Liang et al., 2023), improve factuality and reasoning (Du et al., 2023), and provide validation (Wu et al., 2023). In light of the intuition and early evidence of promise, it is intriguing to ask the following question: how can we facilitate the development of LLM applications that could span a broad spectrum of domains and complexities based on the multi-agent approach?
大型语言模型(LLMs)正成为开发强大智能体(agents)的关键基石,这些智能体在许多现实世界任务中利用 LLM 进行推理、工具使用以及适应新观察(Yao et al., 2022; Xi et al., 2023; Wang et al., 2023b)。鉴于能从 LLM 中受益的任务不断扩展,且任务复杂度日益增加,扩展智能体能力的一个直观方法是使用多个协作的智能体。先前的研究表明,多智能体有助于鼓励发散性思维(Liang et al., 2023),提高事实性和推理能力(Du et al., 2023),并提供验证(Wu et al., 2023)。鉴于这种直觉和早期的希望证据,提出以下问题是很有趣的:我们如何促进基于多智能体方法的、涵盖广泛领域和复杂度的 LLM 应用的开发?
Large language models (LLMs) are becoming a crucial building block in developing powerful agents that utilize LLMs for reasoning, tool usage(使用方式), and adapting to new observations (Yao et al., 2022; Xi et al., 2023; Wang et al., 2023b) in many real-world(现实世界的) tasks.大型语言模型(LLMs)正成为开发强大智能体(agents)的关键基石,这些智能体在许多现实世界任务中利用 LLM 进行推理、工具使用以及适应新观察(Yao et al., 2022; Xi et al., 2023; Wang et al., 2023b)。
Given the expanding(扩展的) tasks that could benefit from LLMs and the growing task complexity, an intuitive(凭直觉的、易懂的) approach(方式) to scale up(扩大规模) the power(能力) of agents is to use multiple(多个) agents that cooperate.鉴于能从 LLM 中受益的任务不断扩展,且任务复杂度日益增加,扩展智能体能力的一个直观方法是使用多个协作的智能体。
Prior(先前的) work(研究成果) suggests that multiple agents can help encourage divergent(分歧的) thinking (Liang et al., 2023), improve factuality(真实性) and reasoning (Du et al., 2023), and provide validation(验证) (Wu et al., 2023).先前的研究表明,多智能体有助于鼓励发散性思维(Liang et al., 2023),提高事实性和推理能力(Du et al., 2023),并提供验证(Wu et al., 2023)。
In light of(鉴于) the intuition and early evidence of promise(承诺), it is intriguing(有趣的) to ask the following(接下来的) question: how can we facilitate(促进) the development of LLM applications that could span(涵盖) a broad spectrum(范围) of domains(领域) and complexities based on the multi-agent approach?鉴于这种直觉和早期的希望证据,提出以下问题是很有意义的:我们如何促进基于多智能体方法的、涵盖广泛领域和复杂度的 LLM 应用的开发?
Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG---智能体检索增强生成:智能体检索增强生成(Agentic RAG)综述
摘要:
Large Language Models (LLMs) have revolutionized artificial intelligence (AI) by enabling humanlike text generation and natural language understanding. However, their reliance on static training data limits their ability to respond to dynamic, real-time queries, resulting in outdated or inaccurate outputs. Retrieval-Augmented Generation (RAG) has emerged as a solution, enhancing LLMs by integrating real-time data retrieval to provide contextually relevant and up-to-date responses. Despite its promise, traditional RAG systems are constrained by static workflows and lack the adaptability required for multi-step reasoning and complex task management.
Agentic Retrieval-Augmented Generation (Agentic RAG) transcends these limitations by embedding autonomous AI agents into the RAG pipeline. These agents leverage agentic design patterns reflection, planning, tool use, and multi-agent collaboration to dynamically manage retrieval strategies, iteratively refine contextual understanding, and adapt workflows through clearly defined operational structures ranging from sequential steps to adaptive collaboration. This integration enables Agentic RAG systems to deliver unparalleled flexibility, scalability, and context-awareness across diverse applications.
This survey provides a comprehensive exploration of Agentic RAG, beginning with its foundational principles and the evolution of RAG paradigms. It presents a detailed taxonomy of Agentic RAG architectures, highlights key applications in industries such as healthcare, finance, and education, and examines practical implementation strategies. Additionally, it addresses challenges in scaling these systems, ensuring ethical decision-making, and optimizing performance for real-world applications, while providing detailed insights into frameworks and tools for implementing Agentic RAG.
翻译:
大型语言模型(LLMs)通过实现类人文本生成和自然语言理解,彻底改变了人工智能(AI)领域。然而,它们对静态训练数据的依赖限制了其响应动态、实时查询的能力,往往会导致输出的信息过时或不准确。检索增强生成(RAG)作为一种解决方案应运而生,它通过集成实时数据检索来增强 LLM 的能力,从而提供与上下文高度相关且最新的响应。尽管前景广阔,但传统的 RAG 系统受到静态工作流程的制约,缺乏进行多步推理和复杂任务管理所需的适应性。
代理检索增强生成(Agentic RAG)通过将自主 AI 代理(Agent)嵌入到 RAG 管道中,打破了这些局限。这些代理利用代理设计模式(包括反思、规划、工具使用和多代理协作),来动态管理检索策略,迭代地优化对上下文的理解,并通过明确定义的操作结构(从顺序步骤到自适应协作)来调整工作流程。这种整合使得 Agentic RAG 系统能够在各种不同的应用场景中,提供无与伦比的灵活性、可扩展性和上下文感知能力。
本综述对 Agentic RAG 进行了全面的探讨,从其基本原理和 RAG 范式的演变讲起。文中详细介绍了 Agentic RAG 架构的分类体系,重点展示了其在医疗保健、金融和教育等行业的关键应用,并考察了实际的实施策略。此外,该综述还探讨了在扩展此类系统、确保合乎道德的决策以及优化现实世界应用性能方面所面临的挑战,同时为实施 Agentic RAG 的框架和工具提供了深入的见解。
Large Language Models (LLMs) have revolutionized(彻底改变) artificial intelligence (AI) by enabling humanlike text generation and natural language understanding.大型语言模型(LLMs)通过实现类人文本生成和自然语言理解,彻底改变了人工智能(AI)领域。
However, their reliance on static training data limits their ability to respond to dynamic, real-time queries, resulting in outdated or inaccurate outputs.然而,它们对静态训练数据的依赖限制了其响应动态、实时查询的能力,导致输出信息过时或不准确。
Retrieval-Augmented Generation (RAG) has emerged as a solution, enhancing LLMs by integrating real-time data retrieval to provide contextually relevant and up-to-date responses.检索增强生成(RAG)作为一种解决方案应运而生,它通过集成实时数据检索来增强大语言模型的能力,从而提供与上下文高度相关且最新的响应。
Despite its promise, traditional RAG systems are constrained by static workflows and lack the adaptability required for multi-step reasoning and complex task management.尽管前景广阔,但传统 RAG 系统受限于静态工作流,缺乏进行多步推理和复杂任务管理所需的适应性。
Agentic Retrieval-Augmented Generation (Agentic RAG) transcends these limitations by embedding autonomous(自主的) AI agents into the RAG pipeline.代理检索增强生成(Agentic RAG)通过将自主 AI 代理嵌入到 RAG 管道中,突破了这些局限。
These agents leverage agentic design patterns: reflection, planning, tool use, and multi-agent collaboration to dynamically manage retrieval strategies, iteratively refine(改进) contextual understanding, and adapt workflows through clearly defined operational structures ranging from sequential steps to adaptive collaboration.这些代理利用代理设计模式(包括反思、规划、工具使用和多代理协作)来动态管理检索策略,迭代优化上下文理解,并通过从顺序步骤到自适应协作的明确定义操作结构来调整工作流程。
This integration enables Agentic RAG systems to deliver unparalleled(无与伦比的) flexibility, scalability, and context-awareness across diverse applications.这种整合使得 Agentic RAG 系统能够在各种应用场景中提供无与伦比的灵活性、可扩展性和上下文感知能力。
This survey provides a comprehensive exploration of Agentic RAG, beginning with its foundational principles and the evolution of RAG paradigms.本综述对 Agentic RAG 进行了全面探讨,首先介绍了其基本原理和 RAG 范式的演变。
It presents a detailed taxonomy(分类体系) of Agentic RAG architectures, highlights key applications in industries such as healthcare, finance, and education, and examines practical implementation strategies.文中详细介绍了 Agentic RAG 架构的分类体系,重点展示了其在医疗保健、金融和教育等行业的关键应用,并考察了实际的实施策略。
Additionally, it addresses challenges in scaling these systems, ensuring ethical decision-making, and optimizing performance for real-world applications, while providing detailed insights into frameworks and tools for implementing Agentic RAG.此外,本文还探讨了在扩展这些系统、确保合乎道德的决策以及优化现实世界应用性能方面所面临的挑战,同时为实现 Agentic RAG 的框架和工具提供了深入见解。
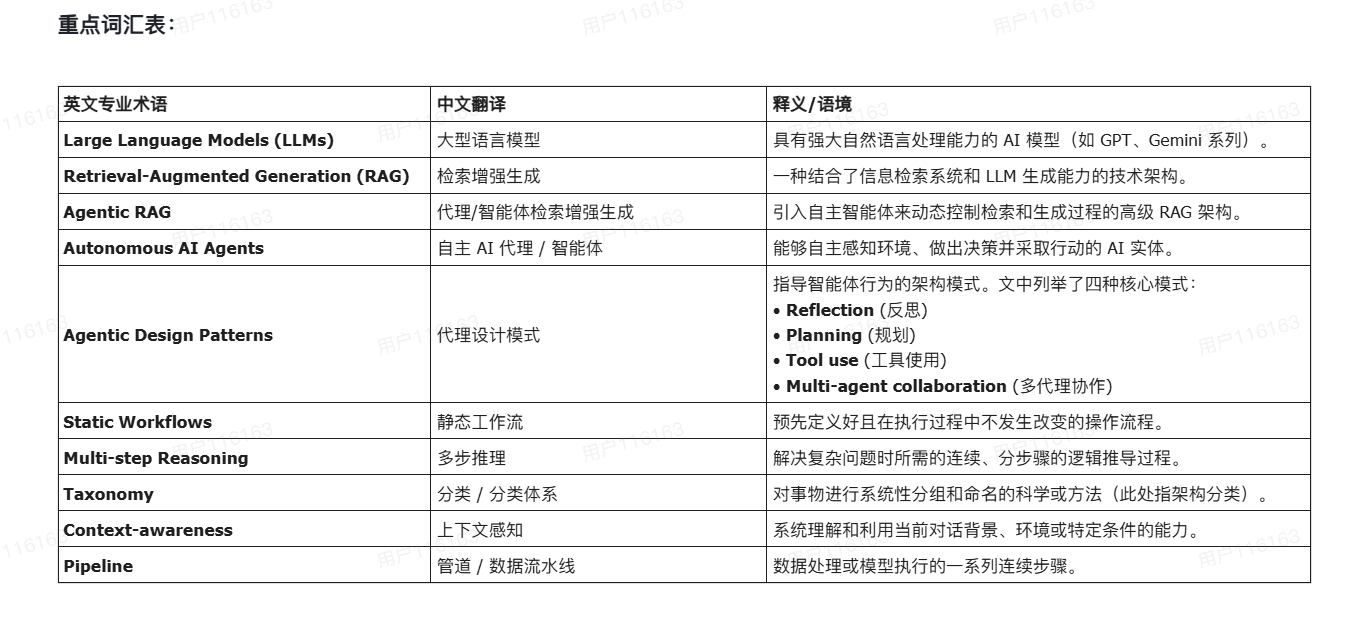
Search-o1: Agentic Search-Enhanced Large Reasoning Models---Search-o1:智能体搜索增强型大型推理模型
摘要:
Large reasoning models (LRMs) like OpenAI-o1 have demonstrated impressive long stepwise reasoning capabilities through large-scale reinforcement learning. However, their extended reasoning processes often suffer from knowledge insufficiency, leading to frequent uncertainties and potential errors. To address this limitation, we introduce Search-o1, a framework that enhances LRMs with an agentic retrieval-augmented generation (RAG) mechanism and a Reason-in-Documents module for refining retrieved documents. Search-o1 integrates an agentic search workflow into the reasoning process, enabling dynamic retrieval of external knowledge when LRMs encounter uncertain knowledge points. Additionally, due to the verbose nature of retrieved documents, we design a separate Reason-in-Documents module to deeply analyze the retrieved information before injecting it into the reasoning chain, minimizing noise and preserving coherent reasoning flow. Extensive experiments on complex reasoning tasks in science, mathematics, and coding, as well as six open-domain QA benchmarks, demonstrate the strong performance of Search-o1. This approach enhances the trustworthiness and applicability of LRMs in complex reasoning tasks, paving the way for more reliable and versatile intelligent systems.
翻译:
像 OpenAI-o1 这样的大型推理模型(LRMs)通过大规模强化学习,展现出了令人瞩目的长步骤推理能力。然而,它们冗长的推理过程经常受限于知识不足,从而导致频繁的不确定性和潜在的错误。
为了解决这一局限性,我们引入了 Search-o1:这是一个通过代理检索增强生成(Agentic RAG)机制和用于优化检索文档的 “文档内推理”(Reason-in-Documents)模块来增强 LRM 的框架。Search-o1 将代理搜索工作流整合到推理过程中,使得 LRM 在遇到不确定的知识点时能够动态检索外部知识。
此外,由于检索到的文档往往具有冗长性,我们设计了一个独立的 “文档内推理” 模块。该模块在将检索到的信息注入推理链之前,会对其进行深度分析,从而最大程度地减少噪声并保持连贯的推理流。在科学、数学和编程等复杂推理任务,以及六个开放域问答基准测试上进行的大量实验,证明了 Search-o1 的强大性能。这种方法增强了 LRM 在复杂推理任务中的可信度和适用性,为构建更可靠、更通用的智能系统铺平了道路。
Large reasoning models (LRMs) like OpenAI-o1 have demonstrated impressive long stepwise reasoning capabilities through large-scale reinforcement(强化) learning.像 OpenAI-o1 这样的大型推理模型(LRMs)通过大规模强化学习,展现出了令人瞩目的长步骤推理能力。
However, their extended reasoning processes often suffer from knowledge insufficiency, leading to frequent uncertainties and potential errors.然而,它们冗长的推理过程经常受限于知识不足,从而导致频繁的不确定性和潜在的错误。
To address this limitation, we introduce Search-o1, a framework that enhances LRMs with an agentic retrieval-augmented generation (RAG) mechanism and a Reason-in-Documents module for refining retrieved documents.为了解决这一局限性,我们引入了 Search-o1:这是一个通过代理检索增强生成(Agentic RAG)机制和用于优化检索文档的 “文档内推理”(Reason-in-Documents)模块来增强 LRM 的框架。
Search-o1 integrates an agentic search workflow into the reasoning process, enabling dynamic retrieval of external knowledge when LRMs encounter uncertain knowledge points.Search-o1 将代理搜索工作流整合到推理过程中,使得 LRM 在遇到不确定的知识点时能够动态检索外部知识。
Additionally, due to the verbose(冗长的) nature of retrieved documents, we design a separate Reason-in-Documents module to deeply analyze the retrieved information before injecting it into the reasoning chain, minimizing noise and preserving coherent reasoning flow.此外,由于检索到的文档往往具有冗长性,我们设计了一个独立的 “文档内推理” 模块,在将检索到的信息注入推理链之前对其进行深度分析,从而最大程度地减少噪声并保持连贯的推理流。
Extensive(大量的) experiments on complex reasoning tasks in science, mathematics, and coding, as well as six open-domain QA benchmarks, demonstrate the strong performance of Search-o1.在科学、数学和编程等复杂推理任务,以及六个开放域问答基准测试上进行的大量实验,证明了 Search-o1 的强大性能。
This approach enhances the trustworthiness and applicability of LRMs in complex reasoning tasks, paving the way for more reliable and versatile(多功能的) intelligent systems.这种方法增强了 LRM 在复杂推理任务中的可信度和适用性,为构建更可靠、更通用的智能系统铺平了道路。
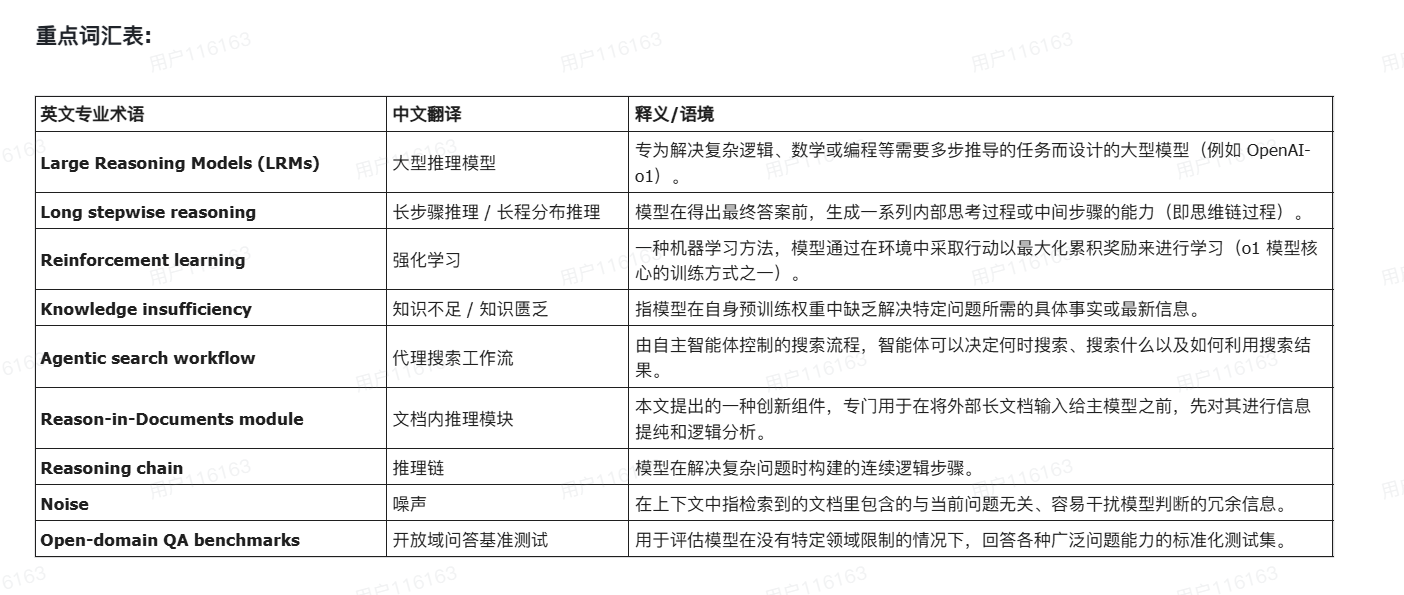
Agent Laboratory: Using LLM Agents as Research Assistants---智能体实验室:将大语言模型智能体用作研究助手
摘要:
Historically, scientific discovery has been a lengthy and costly process, demanding substantial time and resources from initial conception to final results. To accelerate scientific discovery, reduce research costs, and improve research quality, we introduce Agent Laboratory, an autonomous LLM-based framework capable of completing the entire research process. This framework accepts a human-provided research idea and progresses through three stages—literature review, experimentation, and report writing—to produce comprehensive research outputs, including a code repository and a research report, while enabling users to provide feedback and guidance at each stage. We deploy Agent Laboratory with various state-of-the-art LLMs and invite multiple researchers to assess its quality by participating in a survey, providing human feedback to guide the research process, and then evaluate the final paper. We found that: (1) Agent Laboratory driven by o1-preview generates the best research outcomes; (2) The generated machine learning code is able to achieve state-of-the-art performance compared to existing methods; (3) Human involvement, providing feedback at each stage, significantly improves the overall quality of research; (4) Agent Laboratory significantly reduces research expenses, achieving an 84% decrease compared to previous autonomous research methods. We hope Agent Laboratory enables researchers to allocate more effort toward creative ideation rather than low-level coding and writing, ultimately accelerating scientific discovery.
翻译:
历史上,科学发现一直是一个漫长且成本高昂的过程,从最初的构想到最终得出结果,都需要投入大量的时间和资源。为了加速科学发现、降低研究成本并提高研究质量,我们引入了 Agent Laboratory(代理实验室)—— 这是一个基于大型语言模型(LLM)的自主框架,能够完成整个研究流程。
该框架接收人类提供的研究想法,并逐步推进三个阶段 —— 文献综述、实验操作和报告撰写,以产出全面的研究成果,包括一个代码存储库和一份研究报告,同时允许用户在每个阶段提供反馈和指导。我们在 Agent Laboratory 中部署了多种最先进的 LLM,并邀请多位研究员参与调查来评估其质量:他们通过提供人类反馈来指导研究过程,随后对最终的论文进行评估,以此来衡量该框架的质量。
我们发现:(1) 由 o1-preview 驱动的 Agent Laboratory 产生了最佳的研究成果;(2) 与现有方法相比,它生成的机器学习代码能够达到最先进的(SOTA)性能;(3) 人类的参与(在每个阶段提供反馈)显著提升了研究的整体质量;(4) Agent Laboratory 大幅削减了研究开销,与之前的自主研究方法相比,成本降低了 84%。
我们希望 Agent Laboratory 能够让研究人员将更多精力投入到创造性的构思中,而不是耗费在低层级的编码和写作上,从而最终加速科学发现的进程。
Historically, scientific discovery has been a lengthy and costly process, demanding substantial time and resources from initial conception to final results.历史上,科学发现一直是一个漫长且成本高昂的过程,从最初的构想到最终得出结果,都需要投入大量的时间和资源。
To accelerate scientific discovery, reduce research costs, and improve research quality, we introduce Agent Laboratory, an autonomous LLM-based framework capable of completing the entire research process.为了加速科学发现、降低研究成本并提高研究质量,我们引入了 Agent Laboratory(代理实验室)—— 这是一个基于大型语言模型(LLM)的自主框架,能够完成整个研究流程。
This framework accepts a human-provided research idea and progresses through three stages—literature review, experimentation, and report writing—to produce comprehensive research outputs, including a code repository and a research report, while enabling users to provide feedback and guidance at each stage.该框架接收人类提供的研究想法,并逐步推进三个阶段 —— 文献综述、实验操作和报告撰写,以产出全面的研究成果,包括一个代码存储库和一份研究报告,同时允许用户在每个阶段提供反馈和指导。
We deploy Agent Laboratory with various state-of-the-art LLMs and invite multiple researchers to assess its quality by participating in a survey, providing human feedback to guide the research process, and then evaluate the final paper.我们在 Agent Laboratory 中部署了多种最先进的 LLM,并邀请多位研究员参与调查来评估其质量:他们通过提供人类反馈来指导研究过程,随后对最终的论文进行评估,以此来衡量该框架的质量。
We found that: (1) Agent Laboratory driven by o1-preview generates the best research outcomes;我们发现:(1) 由 o1-preview 驱动的 Agent Laboratory 产生了最佳的研究成果;
(2) The generated machine learning code is able to achieve state-of-the-art performance compared to existing methods;(2) 与现有方法相比,它生成的机器学习代码能够达到最先进的(SOTA)性能;
(3) Human involvement, providing feedback at each stage, significantly improves the overall quality of research;(3) 人类的参与(在每个阶段提供反馈)显著提升了研究的整体质量;
(4) Agent Laboratory significantly reduces research expenses, achieving an 84% decrease compared to previous autonomous research methods.(4) Agent Laboratory 大幅削减了研究开销,与之前的自主研究方法相比,成本降低了 84%。
We hope Agent Laboratory enables researchers to allocate more effort toward creative ideation rather than low-level coding and writing, ultimately accelerating scientific discovery.我们希望 Agent Laboratory 能够让研究人员将更多精力投入到创造性的构思中,而不是耗费在低层级的编码和写作上,从而最终加速科学发现的进程。
面试翻译
(一)
While the benefit of running regression tests is increased quality, there is also a cost to this effort in terms of resources to run the suites and to analyze their results. Testing processes by which fewer tests are run while maintaining the same ability to detect defects are therefore beneficial in reducing costs while maintaining quality, and many researchers have proposed various regression testing techniques to achieve this goal.
While the benefit of running regression(回归) tests is increased quality, there is also a cost to this effort in terms of resources to run the suites(套件、组件) and to analyze their results. Testing processes by which fewer tests are run while maintaining(维持) the same ability to detect defects are therefore beneficial in reducing costs while maintaining quality, and many researchers have proposed various regression testing techniques to achieve this goal.
运行回归测试的好处是提高质量,但运行测试套件和分析结果也需要资源成本。因此,在保持相同缺陷检测能力的前提下减少测试运行次数的测试流程,既能降低成本又能保持质量。许多研究人员提出了各种回归测试技术来实现这一目标。
While the benefit of running regression(回归) tests is increased quality, there is also a cost to this effort in terms of resources to run the suites(套件、组件) and to analyze their results.虽然运行regression(回归)测试的好处是提高质量,但这项工作在运行suites(套件、组件)和分析结果方面也存在资源成本。
Testing processes by which fewer tests are run while maintaining (维持) the same ability to detect defects are therefore beneficial in reducing costs while maintaining quality, and many researchers have proposed various regression testing techniques to achieve this goal.因此,在maintaining(维持)相同缺陷检测能力的同时减少测试运行次数的测试流程,有助于在降低成本的同时保持质量,许多研究者也提出了各种回归测试技术来实现这一目标。
(二)
We present a novel and practical deep fully convolutional neural network architecture for semantic pixel-wise segmentation termed SegNet. This core trainable segmentation engine consists of an encoder network, a corresponding decoder network followed by a pixel-wise classification layer. The role of the decoder network is to map the low resolution encoder feature maps to full input resolution feature maps for pixel-wise classification. The novelty of SegNet lies is in the manner in which the decoder upsamples its lower resolution input feature map(s). Specifically, the decoder uses pooling indices computed in the max-pooling step of the corresponding encoder to perform non-linear upsampling.
We present a novel(新颖的) and practical deep fully convolutional neural network architecture(架构) for semantic(语义的) pixel-wise(逐像素的) segmentation(分割) termed(被称为) SegNet. This core trainable(可训练的) segmentation engine consists of an encoder(编译器) network, a corresponding(相应的) decoder network followed by a pixel-wise classification(分类) layer. The role of the decoder network is to map the low resolution(分辨率) encoder feature maps to full input resolution feature maps for pixel-wise classification. The novelty of SegNet lies is in the manner(方式) in which the decoder upsamples(上采样) its lower resolution input feature map(s). Specifically(具体的), the decoder uses pooling indices computed in the max-pooling step of the corresponding(相应的) encoder to perform(完成) non-linear upsampling.
我们提出了一种新的实用深度全卷积神经网络架构 SegNet,用于语义像素级分割。该核心可训练分割引擎由编码器网络、对应的解码器网络和像素级分类层组成。解码器网络的作用是将低分辨率的编码器特征图映射到全输入分辨率的特征图,以进行像素级分类。SegNet 的创新之处在于解码器对低分辨率输入特征图的上采样方式。具体来说,解码器使用对应编码器最大池化步骤中计算的池化索引来执行非线性上采样。
We present a novel (新颖的) and practical deep fully convolutional neural network architecture (架构) for semantic (语义的) pixel-wise (逐像素的) segmentation (分割) termed (被称为) SegNet.我们提出了一种novel(新颖的) 且实用的深度全卷积神经网络architecture(架构),用于semantic(语义的)pixel-wise(逐像素的)segmentation(分割),termed(被称为) SegNet。
This core trainable (可训练的) segmentation engine consists of an encoder (编码器) network, a corresponding (相应的) decoder network followed by a pixel-wise classification (分类) layer.该核心trainable(可训练的) 分割引擎由一个encoder(编码器) 网络、一个corresponding(相应的) 解码器网络以及紧随其后的pixel-wise classification(逐像素分类) 层组成。
The role of the decoder network is to map the low resolution (分辨率) encoder feature maps to full input resolution feature maps for pixel-wise classification.解码器网络的作用是将低resolution(分辨率) 的编码器特征图映射为完整输入分辨率的特征图,以用于逐像素分类。
The novelty of SegNet lies is in the manner (方式) in which the decoder upsamples (上采样) its lower resolution input feature map (s).SegNet 的创新之处在于解码器对其较低分辨率输入特征图进行upsamples(上采样) 的manner(方式)。
Specifically (具体地), the decoder uses pooling indices computed in the max-pooling step of the corresponding (相应的) encoder to perform (完成) non-linear upsampling. upsampling.Specifically(具体地),解码器使用在corresponding(相应的) 编码器的最大池化步骤中计算得到的池化索引来perform(完成) 非线性上采样。
(三)
Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with reference to the layer inputs, instead of learning unreferenced functions. We provide comprehensive empirical evidence showing that these residual networks are easier to optimize, and can gain accuracy from considerably increased depth. On the ImageNet dataset we evaluate residual nets with a depth of up to 152 layers---8x deeper than VGG nets but still having lower complexity. An ensemble of these residual nets achieves 3.57% error on the ImageNet test set.
深度神经网络更难训练。我们提出了一个残差学习框架,以简化比以前使用的网络更深的网络训练。我们明确地将层重新表述为学习相对于层输入的残差函数,而不是学习无参考函数。我们提供了全面的实证证据,表明这些残差网络更容易优化,并且可以通过显著增加深度来提高准确性。在 ImageNet 数据集上,我们评估了深度达 152 层的残差网络 —— 比 VGG 网络深 8 倍,但复杂度仍然较低。这些残差网络的集合在 ImageNet 测试集上达到了 3.57% 的错误率。
Deeper neural networks are more difficult to train.深度神经网络更难训练。
We present a residual(残留的) learning framework(框架) to ease(减轻) the training of networks that are substantially(显著的) deeper than those used previously.我们提出了一个残差学习框架,以简化比以前使用的网络更深的网络训练。
We explicitly(明确地) reformulate(重新表述) the layers as learning residual functions with reference to(关于) the layer inputs, instead of learning unreferenced(无参考的) functions.我们明确地将层重新表述为学习相对于层输入的残差函数,而不是学习无参考函数。
We provide comprehensive empirical(基于观察或经验的) evidence showing that these residual networks are easier to optimize, and can gain accuracy from considerably increased depth.我们提供了全面的实证证据,表明这些残差网络更容易优化,并且可以通过显著增加深度来提高准确性。
On the ImageNet dataset we evaluate residual nets with a depth of up to 152 layers---8x deeper than VGG nets but still having lower complexity.在 ImageNet 数据集上,我们评估了深度达 152 层的残差网络 —— 比 VGG 网络深 8 倍,但复杂度仍然较低。
An ensemble(整体) of these residual nets achieves 3.57% error on the ImageNet test set.这些残差网络的集合在 ImageNet 测试集上达到了 3.57% 的错误率。
(四)
Genetic algorithms are randomized search algorithms that have been developed in an effort to imitate the mechanics of natural selection and natural genetics. Genetic algorithms operate on string structures, like biological structures, which are evolving in time according to the rule of survival of the fittest by using a randomized yet structured information exchange.
遗传算法是一种随机搜索算法,旨在模仿自然选择和自然遗传的机制。遗传算法作用于类似生物结构的字符串结构,通过使用随机但结构化的信息交换,根据适者生存的规则随时间进化。
Genetic(遗传有关的) algorithms are randomized(随机化的) search algorithms that have been developed in an effort to imitate the mechanics(机制) of natural selection and natural genetics.遗传算法是一种随机搜索算法,旨在模仿自然选择和自然遗传的机制。
Genetic algorithms operate on(作用于) string structures, like biological structures, which are evolving in time according to the rule of survival of the fittest by using a randomized yet(然而) structured information exchange.遗传算法作用于类似生物结构的字符串结构,通过使用随机但结构化的信息交换,根据适者生存的规则随时间进化。
(五)
The recently proposed Temporal Ensembling has achieved state-of-the-art results in several semi-supervised learning benchmarks. It maintains an exponential moving average of label predictions on each training example, and penalizes predictions that are inconsistent with this target. However, because the targets change only once per epoch, Temporal Ensembling becomes unwieldy when learning large datasets. To overcome this problem, we propose Mean Teacher, a method that averages model weights instead of label predictions. As an additional benefit, Mean Teacher improves test accuracy and enables training with fewer labels than Temporal Ensembling.
最近提出的 Temporal Ensembling 在多个半监督学习基准测试中取得了最先进的结果。它维护每个训练样本标签预测的指数移动平均值,并惩罚与该目标不一致的预测。然而,由于目标每 epoch 仅更新一次,当处理大型数据集时,Temporal Ensembling 变得难以处理。为了克服这个问题,我们提出了 Mean Teacher 方法,该方法平均模型权重而不是标签预测。作为额外的好处,Mean Teacher 提高了测试准确性,并且能够在使用比 Temporal Ensembling 更少标签的情况下进行训练。
The recently proposed Temporal(与时间有关的) Ensembling(集成方法) has achieved state-of-the-art results in several semi-supervised(半监督的) learning benchmarks.最近提出的 Temporal Ensembling 在多个半监督学习基准测试中取得了最先进的结果。
It maintains(维持着) an exponential(指数的) moving average of label predictions on each training example, and penalizes(惩罚) predictions that are inconsistent with this target.它维护每个训练样本标签预测的指数移动平均值,并惩罚与该目标不一致的预测。
However, because the targets change only once per epoch, Temporal Ensembling becomes unwieldy(难以处理地) when learning large datasets.然而,由于目标每 epoch 仅更新一次,当处理大型数据集时,Temporal Ensembling 变得难以处理。
To overcome this problem, we propose Mean Teacher, a method that averages model weights instead of label predictions.为了克服这个问题,我们提出了 Mean Teacher 方法,该方法平均模型权重而不是标签预测。
As an additional benefit, Mean Teacher improves test accuracy and enables training with fewer labels than Temporal Ensembling.作为额外的好处,Mean Teacher 提高了测试准确性,并且能够在使用比 Temporal Ensembling 更少标签的情况下进行训练。
(六)
There is an immense variety to be found in development procedures, organizational culture, and products. This breadth implies that empirical studies based on observing or measuring some aspect of software development in a particular company must report a great deal of contextual information if any results and their implications are to be properly understood.
在开发过程、组织文化和产品中存在着巨大的多样性。这种广泛性意味着,如果要正确理解任何结果及其影响,基于观察或测量特定公司软件开发某些方面的实证研究必须报告大量的背景信息。
There is an immense variety(多样性) to be found in development procedures(过程), organizational culture, and products.在开发过程、组织文化和产品中存在着巨大的多样性。
This breadth(广泛性) implies that empirical studies based on observing or measuring some aspect of software development in a particular(特定的) company must report a great deal of(大量的) contextual(上下文的) information if any results and their implications(影响) are to be properly understood.这种广泛性意味着,如果要正确理解任何结果及其影响,基于观察或测量特定公司软件开发某些方面的实证研究必须报告大量的背景信息。
(七)
The Doc2Vec is one of the most promising NLP techniques to obtain a vector representation of a document. For a pair of similar documents, a well-trained Doc2Vec produces a pair of vectors that are close to each other in the vector space. The Doc2Vec is an extension of the Word2Vec technique that vectorizes a word. Both of these techniques utilize a neural network that learns words.
Doc2Vec 是获得文档向量表示最有前途的 NLP 技术之一。对于一对相似的文档,训练良好的 Doc2Vec 会生成一对在向量空间中彼此接近的向量。Doc2Vec 是 Word2Vec 技术的扩展,后者将单词向量化。这两种技术都利用神经网络来学习单词。
The Doc2Vec is one of the most promising(有前途的) NLP techniques to obtain a vector representation(表示) of a document.Doc2Vec 是获得文档向量表示最有前途的 NLP 技术之一。
For a pair of similar documents, a well-trained Doc2Vec produces a pair of vectors that are close to each other in the vector space.对于一对相似的文档,训练良好的 Doc2Vec 会生成一对在向量空间中彼此接近的向量。
The Doc2Vec is an extension of the Word2Vec technique that vectorizes(将数据转化为向量) a word.Doc2Vec 是 Word2Vec 技术的扩展,后者将单词向量化。
Both of these techniques utilize a neural network that learns words.这两种技术都利用神经网络来学习单词。
(八)
Word representations learned from neural language models have been shown to improve many NLP tasks. These low-dimensional representations are learned as parameters in a language model and trained to maximize the likelihood of a large corpus of raw text. They are then incorporated as features along side hand-engineered features, or used to initialize the parameters of neural networks targeting tasks for which substantially less training data is available。
从神经语言模型中学习到的词表示已被证明可以改善许多 NLP 任务。这些低维表示作为语言模型中的参数被学习,并经过训练以最大化大型原始文本语料库的似然性。然后,它们被用作与手工设计特征结合的特征,或者用于初始化针对训练数据量少的任务的神经网络参数。
Word representations(表示) learned from neural language models have been shown to improve many NLP tasks.从神经语言模型中学习到的词表示已被证明可以改善许多 NLP 任务。
These low-dimensional representations are learned as parameters in a language model and trained to maximize the likelihood(似然性) of a large corpus(语料库) of raw(原始的) text.这些低维表示作为语言模型中的参数被学习,并经过训练以最大化大型原始文本语料库的似然性。
They are then incorporated(被包含在内的) as features along side(与什么一起) hand-engineered(手工设计的) features, or used to initialize(初始化) the parameters of neural networks targeting tasks for which substantially(显著地) less training data is available.然后,它们被用作与手工设计特征结合的特征,或者用于初始化针对训练数据量少的任务的神经网络参数。
(九)
Semi-supervised learning (SSL) provides an effective means of leveraging unlabeled data to improve a model's performance. In this paper, we demonstrate the power of a simple combination of two common SSL methods: consistency regularization and pseudo-labeling. Our algorithm, FixMatch, first generates pseudo-labels using the model's predictions on weakly-augmented unlabeled images. For a given image, the pseudo-label is only retained if the model produces a high-confidence prediction. The model is then trained to predict the pseudo-label when fed a strongly-augmented version of the same image.
半监督学习(SSL)提供了一种利用未标记数据来提高模型性能的有效方法。在本文中,我们展示了两种常见 SSL 方法的简单组合的强大之处:一致性正则化和伪标签。我们的算法 FixMatch 首先使用模型对弱增强未标记图像的预测生成伪标签。对于给定的图像,仅当模型产生高置信度预测时才保留伪标签。然后,模型在输入同一图像的强增强版本时被训练来预测该伪标签。
Semi-supervised learning (SSL) provides an effective means of leveraging(利用) unlabeled data to improve a model's performance(性能).半监督学习(SSL)提供了一种利用未标记数据来提高模型性能的有效方法。
In this paper, we demonstrat(证明) the power of a simple combination of two common SSL methods: consistency(一致性) regularization(正则化) and opseud-labeling(伪标签标注).在本文中,我们展示了两种常见 SSL 方法的简单组合的强大之处:一致性正则化和伪标签。
Our algorithm, FixMatch, first generates pseudo-labels using the model's predictions(预测) on weakly-augmented(弱增强的) unlabeled images.我们的算法 FixMatch 首先使用模型对弱增强未标记图像的预测生成伪标签。
For a given(给定的) image, the pseudo-label is only retained(被保留) if the model produces a high-confidence prediction.对于给定的图像,仅当模型产生高置信度预测时才保留伪标签。
The model is then trained to predict the pseudo-label when fed(输入) a strongly-augmented(强增强的) version of the same image.然后,模型在输入同一图像的强增强版本时被训练来预测该伪标签。
(十)
There is large consent that successful training of deep networks requires many thousand annotated training samples. In this paper, we present a network and training strategy that relies on the strong use of data augmentation to use the available annotated samples more efficiently. The architecture consists of a contracting path to capture context and a symmetric expanding path that enables precise localization. We show that such a network can be trained end-to-end from very few images and outperforms the prior best method (a sliding-window convolutional network) on the ISBI challenge for segmentation of neuronal structures in electron microscopic stacks.
人们普遍认为,深度网络的成功训练需要数千个带注释的训练样本。在本文中,我们提出了一种网络和训练策略,通过大量使用数据增强来更有效地利用可用的带注释样本。该架构由一个收缩路径来捕获上下文,以及一个对称的扩展路径来实现精确的定位。我们表明,这种网络可以仅从少量图像中进行端到端训练,并且在 ISBI 挑战中,在电子显微镜堆栈中神经元结构的分割任务上优于之前的最佳方法(滑动窗口卷积网络)。
There is large consent(许可) that successful training of deep networks requires many thousand annotated(带注释的) training samples.人们普遍认为,深度网络的成功训练需要数千个带注释的训练样本。
In this paper, we present a network and training strategy that relies on the strong use of data augmentation(增强) to use the available annotated samples more efficiently.在本文中,我们提出了一种网络和训练策略,通过大量使用数据增强来更有效地利用可用的带注释样本。
The architecture(构架) consists of a contracting(收缩的) path to capture context and a symmetric(对称的) expanding path that enables precise localization(定位).该架构由一个收缩路径来捕获上下文,以及一个对称的扩展路径来实现精确的定位。
We show that such a network can be trained end-to-end(端到端) from very few images and outperforms(优于) the prior best method (a sliding-window(滑动窗口) convolutional network) on the ISBI challenge for segmentation(分割) of neuronal(神经元相关的) structures in electron(电子) microscopic stacks.我们表明,这种网络可以仅从少量图像中进行端到端训练,并且在 ISBI 挑战中,在电子显微镜堆栈中神经元结构的分割任务上优于之前的最佳方法(滑动窗口卷积网络)。
(十一)
We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation models (Peters et al., 2018a; Radford et al., 2018), BERT is designed to pre-train deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers. As a result, the pre-trained BERT model can be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inference, without substantial task-specific architecture modifications. BERT is conceptually simple and empirically powerful.
我们介绍了一种新的语言表示模型,称为 BERT,即来自 Transformer 的双向编码器表示。与最近的语言表示模型(Peters 等人,2018a;Radford 等人,2018)不同,BERT 旨在通过在所有层中联合利用左右上下文,从未标记文本中预训练深层双向表示。因此,预训练的 BERT 模型只需添加一个额外的输出层即可进行微调,从而为各种任务(如问答和语言推理)创建最先进的模型,而无需对特定任务的架构进行重大修改。BERT 在概念上简单且在实证上强大。
We introduce a new language representation model called BERT, which stands for(代表) Bidirectional Encoder Representations from Transformers.我们介绍了一种新的语言表示模型,称为 BERT,即来自 Transformer 的双向编码器表示。
Unlike(与什么不同) recent language representation models (Peters et al., 2018a; Radford et al., 2018), BERT is desigd to pre-train deep bidirectional representations from unlabeled text by jointly(联合地) conditioning on both left and right context in all layers.与最近的语言表示模型(Peters 等人,2018a;Radford 等人,2018)不同,BERT 旨在通过在所有层中联合利用左右上下文,从未标记文本中预训练深层双向表示。
As a result, the pre-trained BERT model can be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inference(推理), without substantial(大量的) task-specific(特定任务) architecture(架构) modifications.因此,预训练的 BERT 模型只需添加一个额外的输出层即可进行微调,从而为各种任务(如问答和语言推理)创建最先进的模型,而无需对特定任务的架构进行重大修改。
BERT is conceptually simple and empirically powerful.BERT 在概念上简单且在实证上强大。
(十二)
Recent progress has shown that large-scale pre-training using contrastive image-text pairs can be a promising alternative for high-quality visual representation learning from natural language supervision. Benefiting from a broader source of supervision, this new paradigm exhibits impressive transferability to downstream classification tasks and datasets. In this work, we present a new framework for dense prediction by implicitly and explicitly leveraging the pre-trained knowledge from CLIP. Specifically, we convert the original image-text matching problem in CLIP to a pixel-text matching problem and use the pixel-text score maps to guide the learning of dense prediction models.
最近的进展表明,使用对比图像 - 文本对进行大规模预训练可以成为从自然语言监督中学习高质量视觉表示的有希望的替代方法。受益于更广泛的监督来源,这种新范式在下游分类任务和数据集上表现出令人印象深刻的可迁移性。在这项工作中,我们提出了一个新的框架,通过隐式和显式地利用从 CLIP 预训练中获得的知识来进行密集预测。具体来说,我们将 CLIP 中的原始图像 - 文本匹配问题转换为像素 - 文本匹配问题,并使用像素 - 文本得分图来指导密集预测模型的学习。
Recent progress has shown that large-scale pre-training using contrastive(对比的) image-text(图文) pairs(对) can be a promising(有希望的) alternative(替代方案) for high-quality visual representation learning from natural language supervision(监督).最近的进展表明,使用对比图像 - 文本对进行大规模预训练可以成为从自然语言监督中学习高质量视觉表示的有希望的替代方法。
Benefiting from a broader source of supervision, this new paradigm(范式) exhibits impressive transferability(可转移性) to downstream classification tasks and datasets.受益于更广泛的监督来源,这种新范式在下游分类任务和数据集上表现出令人印象深刻的可迁移性。
In this work, we present(呈现) a new framework for dense prediction by implicitly(隐式地) and explicitly(明确地) leveraging the pre-trained knowledge from CLIP.在这项工作中,我们提出了一个新的框架,通过隐式和显式地利用从 CLIP 预训练中获得的知识来进行密集预测。
Specifically(具体地), we convert the original image-text matching problem in CLIP to a pixel-text matching problem and use the pixel-text score maps to guide the learning of dense prediction models.具体来说,我们将 CLIP 中的原始图像 - 文本匹配问题转换为像素 - 文本匹配问题,并使用像素 - 文本得分图来指导密集预测模型的学习。
(十三)
While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to replace certain components of convolutional networks while keeping their overall structure in place. We show that this reliance on CNNs is not necessary and a pure transformer applied directly to sequences of image patches can perform very well on image classification tasks. When pre-trained on large amounts of data and transferred to multiple mid-sized or small image recognition benchmarks, Vision Transformer (ViT) attains excellent results compared to state-of-the-art convolutional networks.
虽然 Transformer 架构已成为自然语言处理任务的事实上的标准,但其在计算机视觉中的应用仍然有限。在视觉中,注意力要么与卷积网络结合使用,要么用于替换卷积网络的某些组件,同时保持其整体结构不变。我们表明,这种对 CNN 的依赖是不必要的,直接应用于图像块序列的纯 Transformer 可以在图像分类任务中表现得非常好。当在大量数据上进行预训练并迁移到多个中型或小型图像识别基准时,Vision Transformer(ViT)与最先进的卷积网络相比取得了优异的结果。
While the Transformer architecture has become the de-facto(事实上) standard for natural language processing tasks, its applications to computer vision remain limited.虽然 Transformer 架构已成为自然语言处理任务的事实上的标准,但其在计算机视觉中的应用仍然有限。
In vision, attention is either applied in conjunction(结合) with convolutional networks, or used to replace certain components of convolutional networks while keeping their overall(总体的) structure in place.在视觉中,注意力要么与卷积网络结合使用,要么用于替换卷积网络的某些组件,同时保持其整体结构不变。
We show that this reliance on CNNs is not necessary and a pure(纯粹的) transformer applied directly to sequences of image patches(小块) can perform very well on image classification tasks.我们表明,这种对 CNN 的依赖是不必要的,直接应用于图像块序列的纯 Transformer 可以在图像分类任务中表现得非常好。
When pre-trained on large amounts of data and transferred to(迁移到) multiple mid-sized or small image recognition benchmarks, Vision Transformer (ViT) attains excellent results compared to state-of-the-art convolutional networks.当在大量数据上进行预训练并迁移到多个中型或小型图像识别基准时,Vision Transformer(ViT)与最先进的卷积网络相比取得了优异的结果。
(十四)
We propose a new framework for estimating generative models via an adversarial process, in which we simultaneously train two models: a generative model G that captures the data distribution, and a discriminative model D that estimates the probability that a sample came from the training data rather than G. The training procedure for G is to maximize the probability of D making a mistake. This framework corresponds to a minimax two-player game. In the space of arbitrary functions G and D, a unique solution exists, with G recovering the training data distribution and D equal to ½ everywhere. In the case where G and D are defined by multilayer perceptrons, the entire system can be trained with backpropagation.
我们提出了一种通过对抗过程估计生成模型的新框架,其中我们同时训练两个模型:一个生成模型 G,用于捕获数据分布;一个判别模型 D,用于估计样本来自训练数据而不是 G 的概率。G 的训练过程是最大化 D 犯错误的概率。该框架对应于一个极大极小双人游戏。在任意函数 G 和 D 的空间中,存在唯一的解,其中 G 恢复训练数据分布,D 在任何地方都等于 1/2。当 G 和 D 由多层感知机定义时,整个系统可以通过反向传播进行训练。
We propose a new framework for estimating generative models via an adversarial(对抗性的) process, in which we simultaneously train two models: a generative model G that captures the data distribution, and a discriminative(区分性的) model D that estimates the probability that a sample came from the training data rather than G.我们提出了一种通过对抗过程估计生成模型的新框架,其中我们同时训练两个模型:一个生成模型 G,用于捕获数据分布;一个判别模型 D,用于估计样本来自训练数据而不是 G 的概率。
The training procedure for G is to maximize the probability of D making a mistake. This framework corresponds to(相当于) a minimax(极大极小) two-player game.G 的训练过程是最大化 D 犯错误的概率。该框架对应于一个极大极小双人游戏。
In the space of arbitrary(任意的) functions G and D, a unique solution(解) exists, with G recovering(恢复) the training data distribution and D equal to ½ everywhere.在任意函数 G 和 D 的空间中,存在唯一的解,其中 G 恢复训练数据分布,D 在任何地方都等于 1/2。
In the case where G and D are defined by multilayer(多层的) perceptrons(感知机), the entire system can be trained with backpropagation(反向传播).当 G 和 D 由多层感知机定义时,整个系统可以通过反向传播进行训练。
(十五)
We present a conceptually simple, flexible, and general framework for object instance segmentation. Our approach efficiently detects objects in an image while simultaneously generating a high-quality segmentation mask for each instance. The method, called Mask R-CNN, extends Faster R-CNN by adding a branch for predicting an object mask in parallel with the existing branch for bounding box recognition. Mask R-CNN is simple to train and adds only a small overhead to Faster R-CNN, running at 5 fps. Moreover, Mask R-CNN is easy to generalize to other tasks, e.g., allowing us to estimate human poses in the same framework. We show top results in all three tracks of the COCO suite of challenges, including instance segmentation, bounding-box object detection, and person keypoint detection.
我们提出了一个概念简单、灵活且通用的对象实例分割框架。我们的方法能够高效地检测图像中的对象,同时为每个实例生成高质量的分割掩码。该方法称为 Mask R-CNN,它通过在现有边界框识别分支的基础上添加一个预测对象掩码的分支来扩展 Faster R-CNN。Mask R-CNN 训练简单,仅给 Faster R-CNN 增加少量开销,运行速度为 5 帧 / 秒。此外,Mask R-CNN 易于推广到其他任务,例如允许我们在同一框架中估计人体姿势。我们在 COCO 挑战的所有三个赛道中都取得了最好的成绩,包括实例分割、边界框对象检测和人体关键点检测。
We present a conceptually simple, flexible, and general framework for object instance(实例) segmentation(分割).我们提出了一个概念简单、灵活且通用的对象实例分割框架。
Our approach efficiently detects objects in an image while simultaneously generating a high-quality segmentation mask for each instance.我们的方法能够高效地检测图像中的对象,同时为每个实例生成高质量的分割掩码。
The method, called Mask R-CNN, extends Faster R-CNN by adding a branch for predicting an object mask in parallel with(与什么同时) the existing branch for bounding(有边界的) box(框) recognition.该方法称为 Mask R-CNN,它通过在现有边界框识别分支的基础上添加一个预测对象掩码的分支来扩展 Faster R-CNN。
Mask R-CNN is simple to train and adds only a small overhead(开销) to Faster R-CNN, running at 5 fps.Mask R-CNN 训练简单,仅给 Faster R-CNN 增加少量开销,运行速度为 5 帧 / 秒。
Moreover, Mask R-CNN is easy to generalize(概括) to other tasks, e.g., allowing us to estimate human poses in the same framework.此外,Mask R-CNN 易于推广到其他任务,例如允许我们在同一框架中估计人体姿势。
We show top results in all three tracks(赛道) of the COCO suite(一系列) of challenges, including instance(实例) segmentation, bounding-box object detection, and person keypoint detection.我们在 COCO 挑战的所有三个赛道中都取得了最好的成绩,包括实例分割、边界框对象检测和人体关键点检测。
(十六)
In this work we address the task of semantic image segmentation with Deep Learning and make three main contributions that are experimentally shown to have substantial practical merit. First, we highlight convolution with upsampled filters, or 'atrous convolution', as a powerful tool in dense prediction tasks. Atrous convolution allows us to explicitly control the resolution at which feature responses are computed within Deep Convolutional Neural Networks. It also allows us to effectively enlarge the field of view of filters to incorporate larger context without increasing the number of parameters or the amount of computation. Second, we propose atrous spatial pyramid pooling (ASPP) to robustly segment objects at multiple scales.
在这项工作中,我们利用深度学习解决语义图像分割任务,并做出了三个主要贡献,实验表明这些贡献具有显著的实际价值。首先,我们强调使用上采样滤波器的卷积,即 “空洞卷积”,作为密集预测任务中的有力工具。空洞卷积使我们能够在深度卷积神经网络中显式控制特征响应的计算分辨率。它还使我们能够有效扩大滤波器的视野,以纳入更大的上下文,而无需增加参数数量或计算量。其次,我们提出了空洞空间金字塔池化(ASPP),以鲁棒地分割多尺度的对象。
In this work we address the task of semantic(与语义相关的) image segmentation with Deep Learning and make three main contributions that are experimentally(实验性地) shown to have substantial(大量的) practical(实际的) merit.在这项工作中,我们利用深度学习解决语义图像分割任务,并做出了三个主要贡献,实验表明这些贡献具有显著的实际价值。
First, we highlight convolution with upsampled(上采样的) filters(滤波器), or 'atrous(空洞的) convolution', as a powerful tool in dense prediction tasks.首先,我们强调使用上采样滤波器的卷积,即 “空洞卷积”,作为密集预测任务中的有力工具。
Atrous convolution allows us to explicitly control the resolution(分辨率) at which feature responses are computed within Deep Convolutional Neural Networks.空洞卷积使我们能够在深度卷积神经网络中显式控制特征响应的计算分辨率。
It also allows us to effectively enlarge the field of view of filters to incorporate(将某物包含进去) larger context without increasing the number of parameters or the amount of computation.它还使我们能够有效扩大滤波器的视野,以纳入更大的上下文,而无需增加参数数量或计算量。
Second, we propose atrous spatial(与空间相关的) pyramid(金字塔) pooling (ASPP) to robustly(强健地) segment objects at multiple scales.其次,我们提出了空洞空间金字塔池化(ASPP),以鲁棒地分割多尺度的对象。
(十七)
The deficiency of segmentation labels is one of the main obstacles to semantic segmentation in the wild. To alleviate this issue, we present a novel framework that generates segmentation labels of images given their image-level class labels. In this weakly supervised setting, trained models have been known to segment local discriminative parts rather than the entire object area. Our solution is to propagate such local responses to nearby areas which belong to the same semantic entity. To this end, we propose a Deep Neural Network (DNN) called AffinityNet that predicts semantic affinity between a pair of adjacent image coordinates. The semantic propagation is then realized by random walk with the affinities predicted by AffinityNet.
分割标签的缺乏是自然场景下语义分割的主要障碍之一。为了缓解这个问题,我们提出了一个新的框架,该框架在给定图像的图像级类别标签的情况下生成图像的分割标签。在这种弱监督设置下,已知训练好的模型会分割局部判别性部分,而不是整个对象区域。我们的解决方案是将这种局部响应传播到属于同一语义实体的附近区域。为此,我们提出了一种称为 AffinityNet 的深度神经网络(DNN),它预测相邻图像坐标对之间的语义亲和力。然后,通过使用 AffinityNet 预测的亲和力进行随机游走,实现语义传播。
The deficiency(缺乏) of segmentation labels is one of the main obstacles to semantic(语义的) segmentation in the wild(野生的).分割标签的缺乏是自然场景下语义分割的主要障碍之一。
To alleviate(缓解) this issue, we present a novel framework that generates segmentation labels of images given their image-level class labels.为了缓解这个问题,我们提出了一个新的框架,该框架在给定图像的图像级类别标签的情况下生成图像的分割标签。
In this weakly(虚弱地) supervised(有监督的) setting, trained models have been known to segment(片段) local discriminative(有区别能力的) parts rather than the entire object area.在这种弱监督设置下,已知训练好的模型会分割局部判别性部分,而不是整个对象区域。
Our solution is to propagate(传播) such local responses to nearby areas which belong to the same semantic(语义相关的) entity.我们的解决方案是将这种局部响应传播到属于同一语义实体的附近区域。
To this end(为此), we propose a Deep Neural Network (DNN) called AffinityNet that predicts semantic affinity(亲和力) between a pair of adjacent image coordinates(坐标).为此,我们提出了一种称为 AffinityNet 的深度神经网络(DNN),它预测相邻图像坐标对之间的语义亲和力。
The semantic propagation is then realized by random walk with the affinities(亲和力) predicted by AffinityNet.然后,通过使用 AffinityNet 预测的亲和力进行随机游走,实现语义传播。
(十八)
The Synthesis operating system kernel combines several techniques to provide high performance, including kernel code synthesis, fine-grain scheduling, and optimistic synchronization. Kernel code synthesis reduces the execution path for frequently used kernel calls. Optimistic synchronization increases concurrency within the kernel. Their combination results in significant performance improvement over traditional operating system implementations. Using hardware and software emulating a SUN 3/160 running SUNOS, Synthesis achieves several times to several dozen times speedup for UNIX kernel calls and context switch times of 21 microseconds or faster.
Synthesis 操作系统内核结合了多种技术以提供高性能,包括内核代码合成、细粒度调度和乐观同步。内核代码合成减少了常用内核调用的执行路径。乐观同步增加了内核内的并发性。它们的结合使性能比传统操作系统实现有了显著提高。使用模拟运行 SUNOS 的 SUN 3/160 的硬件和软件,Synthesis 在 UNIX 内核调用和上下文切换时间方面实现了数倍到数十倍的加速,达到 21 微秒或更快。
The Synthesis(合成) operating system kernel combines several techniques to provide high performance(性能), including kernel code synthesis, fine-grain(细粒度) scheduling(调度), and optimistic(乐观的) synchronization(同步).Synthesis 操作系统内核结合了多种技术以提供高性能,包括内核代码合成、细粒度调度和乐观同步。
Kernel code synthesis reduces the execution(执行) path for frequently used kernel calls.内核代码合成减少了常用内核调用的执行路径。
Optimistic synchronization(同步) increases concurrency(并发) within the kernel.乐观同步增加了内核内的并发性。
Their combination results in significant performance improvement over traditional operating system implementations.它们的结合使性能比传统操作系统实现有了显著提高。
Using hardware and software emulating(模拟) a SUN 3/160 running SUNOS, Synthesis achieves several times to several dozen(一打) times speedup(加速) for UNIX kernel calls and context switch times of 21 microseconds(微秒) or faster.使用模拟运行 SUNOS 的 SUN 3/160 的硬件和软件,Synthesis 在 UNIX 内核调用和上下文切换时间方面实现了数倍到数十倍的加速,达到 21 微秒或更快。
(十九)
A training algorithm that maximizes the margin between the training patterns and the decision boundary is presented. The technique is applicable to a wide variety of the classification functions, including Perceptrons, polynomials, and Radial Basis Functions. The effective number of parameters is adjusted automatically to match the complexity of the problem. The solution is expressed as a linear combination of supporting patterns. These are the subset of training patterns that are closest to the decision boundary. Bounds on the generalization performance based on the leave-one-out method and the VC-dimension are given. Experimental results on optical character recognition problems demonstrate the good generalization obtained when compared with other learning algorithms.
提出了一种最大化训练模式与决策边界之间裕度的训练算法。该技术适用于多种分类函数,包括感知机、多项式和径向基函数。有效参数数量会自动调整以匹配问题的复杂度。解表示为支持模式的线性组合。这些是最接近决策边界的训练模式子集。给出了基于留一法和 VC 维的泛化性能界限。在光学字符识别问题上的实验结果表明,与其他学习算法相比,该算法具有良好的泛化能力。
A training algorithm that maximizes the margin between the training patterns and the decision boundary is presented.提出了一种最大化训练模式与决策边界之间裕度的训练算法。
The technique is applicable(可应用的) to a wide variety of the classification functions, including Perceptrons(感知机), polynomials(多项式), and Radial(径向的) Basis Functions(基函数).该技术适用于多种分类函数,包括感知机、多项式和径向基函数。
The effective number of parameters is adjusted automatically to match the complexity of the problem.有效参数数量会自动调整以匹配问题的复杂度。
The solution is expressed as a linear combination of supporting patterns.解表示为支持模式的线性组合。
These are the subset of training patterns that are closest to the decision boundary.这些是最接近决策边界的训练模式子集。
Bounds(界限) on the generalization(概括) performance based on the leave-one-out(留一法) method and the VC-dimension are given.给出了基于留一法和 VC 维的泛化性能界限。
Experimental(实验性的) results on optical(光学的) character(字符) recognition problems demonstrate the good generalization(泛化) obtained when compared with other learning algorithms.在光学字符识别问题上的实验结果表明,与其他学习算法相比,该算法具有良好的泛化能力。
(二十)
A network protocol is a set of established rules that specify how to format, send and receive data so that computer network endpoints, including computers, servers, routers and virtual machines, can communicate despite differences in their underlying infrastructures, designs or standards. To successfully send and receive information, devices on both sides of a communication exchange must accept and follow protocol conventions. In networking, support for protocols can be built into the software, hardware or both.
网络协议是一组既定规则,规定了如何格式化、发送和接收数据,以便计算机网络端点(包括计算机、服务器、路由器和虚拟机)能够在底层基础设施、设计或标准不同的情况下进行通信。为了成功发送和接收信息,通信双方的设备必须接受并遵循协议约定。在网络中,对协议的支持可以内置到软件、硬件或两者中。
A network protocol is a set of established rules that specify(明确说明) how to format, send and receive data so that computer network endpoints(端点), including computers, servers, routers and virtual machines, can communicate despite differences in their underlying(底层的) infrastructures, designs or standards.网络协议是一组既定规则,规定了如何格式化、发送和接收数据,以便计算机网络端点(包括计算机、服务器、路由器和虚拟机)能够在底层基础设施、设计或标准不同的情况下进行通信。
To successfully send and receive information, devices on both sides of a communication exchange must accept and follow protocol conventions(约定).为了成功发送和接收信息,通信双方的设备必须接受并遵循协议约定。
In networking, support for protocols can be built into the software, hardware or both.在网络中,对协议的支持可以内置到软件、硬件或两者中。
(二十一)
Attention is a machine learning method that determines the relative importance of each component in a sequence relative to the other components in that sequence. In natural language processing, importance is represented by "soft" weights assigned to each word in a sentence. More generally, attention encodes vectors called token embeddings across a fixed-width sequence that can range from tens to millions of tokens in size.
注意力是一种机器学习方法,用于确定序列中每个组件相对于其他组件的相对重要性。在自然语言处理中,重要性由分配给句子中每个单词的 “软” 权重表示。更一般地说,注意力在固定宽度的序列上编码称为令牌嵌入的向量,该序列的大小可以从几十个到数百万个令牌不等。
Attention is a machine learning method that determines the relative importance of each component(组件) in a sequence relative(相对的) to the other components in that sequence.注意力是一种机器学习方法,用于确定序列中每个组件相对于其他组件的相对重要性。
In natural language processing, importance is represented by "soft" weights assigned to(分配给) each word in a sentence.在自然语言处理中,重要性由分配给句子中每个单词的 “软” 权重表示。
More generally(更一般地说), attention encodes vectors called token(令牌) embeddings across a fixed-width sequence that can range from tens to millions of tokens in size.更一般地说,注意力在固定宽度的序列上编码称为令牌嵌入的向量,该序列的大小可以从几十个到数百万个令牌不等。
(二十二)
Research quality is vital to scientific progress, relying on integrity, cooperation, and diligence. Integrity ensures honest reporting of methods and results, fostering trust akin to clear societal norms. Cooperation, through transparent data sharing and peer review, strengthens collaboration, much like standardized protocols enable network communication. Diligence drives rigorous methodologies and persistence, overcoming challenges like funding pressures. Together, these qualities uphold reliable, reproducible science, advancing knowledge for the collective good.
研究质量对科学进步至关重要,它依赖于诚信、合作和勤奋。诚信确保方法和结果的诚实报告,培养类似于明确社会规范的信任。通过透明的数据共享和同行评审,合作加强了协作,就像标准化协议使网络通信成为可能一样。勤奋推动严谨的方法和坚持,克服资金压力等挑战。这些品质共同维护了可靠、可重复的科学,促进了集体利益的知识进步。
Research quality is vital to scientific progress, relying on integrity(诚信), cooperation, and diligence.研究质量对科学进步至关重要,它依赖于诚信、合作和勤奋。
Integrity ensures honest reporting of methods and results, fostering(培养) trust akin(相似的) to clear societal norms(规范).诚信确保方法和结果的诚实报告,培养类似于明确社会规范的信任。
Cooperation, through transparent(透明的) data sharing and peer review(评审), strengthens collaboration(协作), much like(很像) standardized protocols enable network communication.通过透明的数据共享和同行评审,合作加强了协作,就像标准化协议使网络通信成为可能一样。
Diligence drives rigorous methodologies(方法论) and persistence(坚持), overcoming challenges like funding pressures.勤奋推动严谨的方法和坚持,克服资金压力等挑战。
Together, these qualities uphold(维护) reliable, reprodcible(可u重复的) science, advancing(推进) knowledge for the collective(集体的) good.这些品质共同维护了可靠、可重复的科学,促进了集体利益的知识进步。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 20
20 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)