Veo 3.1模型生成视频更真实?本文带你读懂它的底层技术
在人工智能领域,视频生成技术正在迅速发展。从最初的简单图像生成,到现在可以生成高质量、逼真、符合物理规律的视频,AI的创作能力正在经历革命性的升级。其中,VEO3.1模型作为最新一代多模态视频生成模型,凭借其强大的物理模拟能力、多模态理解能力,以及优化的算法架构,引起了业内和创作者群体的广泛关注。
不过,VEO3.1模型到底是什么呢?与其他模型对于它又有什么优势?哪些领域可以使用到它?...... 对于VEO3.1模型的问题你可能还有很多,但在本文中,我们将为你逐个解答。本文将从技术原理、操作方法、应用场景等多个角度,深入解析VEO3.1,帮助用户全面理解和高效使用这一工具。

一、VEO3.1模型是什么?有什么核心技术?
Veo 3.1是谷歌DeepMind开发的最新视频生成模型,于2025年10月首次发布,2026年1月迎来重大更新。它并非简单的“文字转视频工具”,而是一个完整的云端虚拟摄影棚——通过与Gemini深度整合,让用户仅凭文字或图像就能创作出电影级内容。
1、VEO3.1主要由三个核心模块组成:
编码器:将文本或图像输入转化为高维特征向量;
生成器:基于深度神经网络进行视频帧生成,同时保证连贯性与物理逻辑;
优化器:对生成的视频进行多轮迭代优化,包括物理一致性检测、光影调整及流畅度优化。
2、VEO3.1核心技术
Veo 3.1 的核心技术架构融合了 Transformer 与 扩散模型 的优势,并引入了先进的潜在空间压缩技术。
算法架构:基于扩散变换器,将扩散模型的去噪能力与Transformer的时序理解能力相结合。这种架构让模型不仅能“画”出画面,更能理解画面随时间演变的物理规律,这样可确保每一帧画面的高清与流畅。
数据处理能力:支持多模态输入,包括文本、图像、音频甚至视频片段作为参考。尤其是“素材转视频”功能,允许同时上传多张参考图像,从中提取材质、色调与特征作为“视觉锚点”。
优化机制:通过先进的超分辨率技术,将基础生成的720p视频无损强化至1080p甚至4K分辨率,画面锐利清晰,细节还原精准。
3、与前版本的差异
相比于Veo 3.0,Veo 3.1 的创新点主要集中在两点:
原生音频生成:这是最核心的差异。Veo 3.0 仅支持生成无声视频,而 3.1 可以根据画面内容自动生成匹配的环境音、音效甚至人物台词,实现了视听一体化。
物理一致性增强:Veo 3.0 在处理复杂运动(如多人互动、流体运动)时偶尔会出现崩坏,Veo 3.1 引入了更精细的物理约束机制,大幅减少了“穿模”和形变现象。
二、VEO3.1如何突破“真实”规律?
1. 物理世界模拟器
VEO3.1内置了高级物理模拟器,能够真实再现流体动力学、光影反射及重力作用。
流体动力学模拟:无论是水流、烟雾还是液体混合,模型通过卷积神经网络模拟微观运动规律,实现自然流动感。
光影反射:它可以利用光线追踪算法和深度学习光照修正,实现物体表面反光与阴影真实感。
重力与碰撞检测:VEO3.1模型会对每个物体建立虚拟物理属性(质量、密度、摩擦力),确保动作符合物理逻辑。
举个例子:
在生成“吃播视频”时:
VEO3.0可能出现叉子穿过食物或食物形态扭曲;
VEO3.1则会利用物理模拟器,保证食物质感、形状稳定,动作连贯自然,视觉上不会出现“穿模”或物体漂浮的情况。
2. 多模态理解能力增强
从文本生成视频:对复杂长提示词,VEO3.1可以识别场景、动作、表情和道具,生成连贯视频。可自动优化提示词结构,使抽象概念转化为可操作的“分镜脚本”。
从图像生成视频:通过图像特征映射到视频帧生成器,将静态图像“活”起来,并实现连续动作与物理一致性。例如,一幅名画中的人物可以做出动作,但仍然会遵循光影、质感和物理规律。
三、提示词编写:如何让VEO3.1听懂你的语言?
VEO3.1视频模型虽然强大,但是并不代表它一定能生成完美的视频,因为生成一个高质量且专业的视频,除了选对模型,其实提示词的编写也非常的重要。AI视频生成工具最终也是根据用户给到的提示词或图片内容生成的。
1、为什么你的提示词会失败?
大多数创作者描述的是“抽象概念”,忽略动作、场景和时间逻辑,并且还缺乏关键视觉元素说明,而Veo 3.1则需要的是“分镜脚本”。如果用户给的是抽象概念,那么这将会留给AI太多猜测空间,导致视频生成的结果不可控。
2、提示词示范
错误示范:“一个老人在公园里锻炼,天气很好,看起来很安详。”
这是一个文学描述,而非镜头描述。“锻炼”动作不明(打太极?跑步?),“天气很好”无具体视觉特征,“安详”更是难以量化。生成的视频可能是一个老人在做奇怪的广播体操,背景是一片惨白的天空。
正确示范:
“一位满头银发的老爷爷,身穿白色宽松太极服,在清晨的公园草坪上缓慢打着太极拳。阳光透过树叶洒下斑驳的光影,背景有晨雾缭绕。镜头使用低角度仰拍,捕捉他专注的神情和缓慢的手部动作。画面风格为电影感,高饱和度,伴随清晨鸟鸣声。”
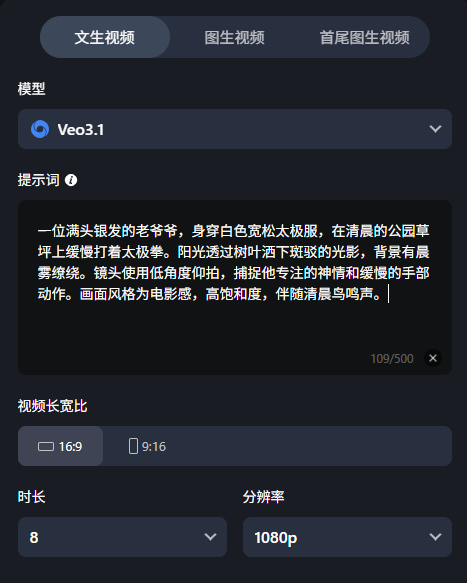
这种提示词给到VEO3.1模型它通常能够生成符合你要求的视频内容,因为它可正确地捕捉到你的关键信息:
主体明确:银发、太极服、打太极拳(动作具体)。
环境具体:清晨、草坪、斑驳光影、晨雾(视觉细节)。
镜头语言:低角度仰拍(视角确定)。
声音指令:清晨鸟鸣声(发挥 Veo 3.1 音频优势)。
3、Veo 3.1提示词的万能公式
为了最大化发挥 Veo 3.1 模型的潜力,建议用户可以遵循以下公式:
核心主体(外貌/衣着)+具体动作(动词)+环境氛围(光影/天气/背景)+运镜方式(推拉摇移)+声音指令+风格修饰
掌握这个公式,你将能够精准指挥 Veo 3.1 生产你想要的视频内容。
四、国内用户如何使用Veo 3.1模型?
对于国内用户而言,如果想要访问并使用Veo 3.1主要有以下两种路径:
路径1:直接访问Google生态
Gemini App:订阅Google AI Plus方案(约NT$260/月),可通过对话方式直接生成视频,支持繁体中文指令
Google AI Studio:开发者平台,定期提供免费试用额度,学生用户可通过教育项目获得一年免费使用权。
Flow平台:专业创作者工具,支持完整的“素材转视频”功能和4K输出。
路径2:移乐AI平台
移乐AI平台作为一个集成化的智能创作入口,通过技术接口打通了国际顶尖模型的壁垒,汇集了Sora 2、Veo等多款主流视频模型。对于国内用户而言,通过移乐AI在线平台就可以直接使用 Veo 3.1模型,注册即送算力值,无需特殊网络环境即可使用。
五、Veo 3.1模型可应用于哪些场景?
由于Veo 3.1 的“音画同步”与“物理真实”特性,使其能应用到的场景也非常之多,比如:
1、影视制作与概念预演:在电影筹备期,导演可以用Veo 3.1快速生成关键场景的动态预演。不仅是画面,连现场的氛围音效都能一并生成,帮助剧组更直观地预判拍摄效果,节省昂贵的实地勘景成本。
2、短视频与自媒体创作:对于自媒体平台的创作者,Veo 3.1是提升产量的神器。无论是故事类账号需要的剧情片段,还是知识类账号需要的演示动画,Veo 3.1都能快速生成。
3、广告营销与电商展示:商家可以利用Veo 3.1让静态的商品图动起来,展示产品的多个细节。广告公司则可以用它快速产出多版样片供客户选择,降低试错成本。
4、教育与培训:在物理、化学、生物教学中,许多微观或宏观的现象难以实拍。Veo 3.1 可以根据教材描述,生成精确的动态演示视频(如细胞分裂、天体运行),并配以旁白解说。
5、游戏开发:可利用Veo 3.1快速生成游戏的过场动画或动态背景素材,甚至用于生成虚拟角色的表情动作,从而提高游戏的制作流程。
六、全文小结
以上就是关于Veo 3.1模型的全部相关信息。总的来说,Veo 3.1模型技术是非常之强大的,它能够涉及的领域非常广泛,无论你是短视频的内容创作者,还是影视制作人,都能通过Veo 3.1模型提高工作效率。当然,虽然Veo 3.1很强大,但是也别忘记提示词的撰写也是非常重要的哦!
如果作为国内用户的你,想要轻松访问并使用Veo 3.1模型,可以从本文提到的聚合平台——移乐AI中体验。最后,希望本文分享的内容对你了解Veo 3.1有所帮助!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 17
17 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)