(论文速读)Synthesizer:重新思考变压器模型的自我关注
论文题目:Synthesizer: Rethinking Self-Attention for Transformer Models(合成器:重新思考变压器模型的自我关注)
会议:ICML2020
摘要:点积自注意力机制被认为是最先进的变压器模型的核心和不可或缺的。但这真的是必须的吗?本文研究了基于点积的自注意力机制机制对变压器模型性能的真正重要性和贡献。通过广泛的实验,我们发现(1)随机对齐矩阵令人惊讶地表现出相当强的竞争力,(2)从令牌-令牌(查询键)交互中学习注意力权重是有用的,但毕竟不是那么重要。为此,我们提出了一个模型SYNTHESIZER,它可以在没有令牌与令牌交互的情况下学习综合注意力权重。在我们的实验中,我们首先展示了简单的合成器在一系列任务中与香草Transformer模型相比具有高度竞争力的性能,包括机器翻译、语言建模、文本生成和GLUE/SuperGLUE基准测试。当组成与点积注意,我们发现合成器始终优于变压器。此外,我们对合成器与动态卷积进行了额外的比较,表明简单的随机合成器不仅快了60%,而且相对提高了3.5%的困惑度。最后,我们证明了简单的分解合成器可以在编码任务上优于线性合成器。
对于代码示例有需求的小伙伴,可以看这里的博客:
Synthesizer——挑战Transformer自注意力的必要性
引言:一个大胆的问题
当我们谈论Transformer模型时,点积自注意力机制(dot product self-attention)几乎被视为金科玉律——它是Transformer成功的核心,没有它就没有现代NLP的辉煌成就。但Google Research的研究团队在ICML 2020上发表的这篇论文《Synthesizer: Rethinking Self-Attention for Transformer Models》向我们抛出了一个惊人的问题:
我们真的需要点积自注意力吗?通过token-token的成对交互来学习注意力权重真的那么重要吗?
这篇论文不仅提出了这个问题,还通过大量实验给出了令人意外的答案。
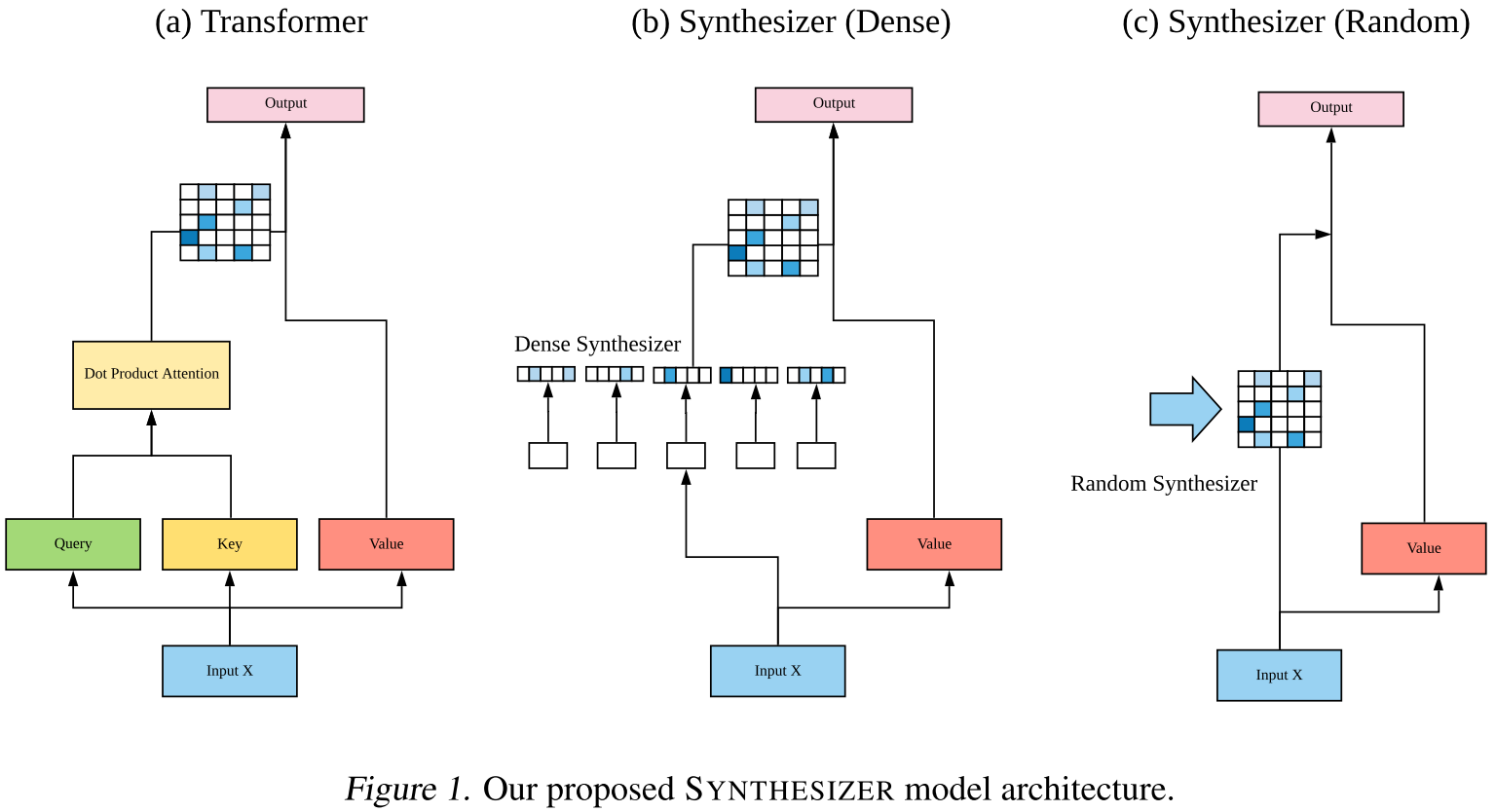
背景:自注意力的"记忆检索"范式
传统Transformer的自注意力通过Query-Key-Value机制工作: $
![]()
这种设计基于"内容检索"的直觉:每个token(Query)通过与所有其他token(Keys)的相似度来决定应该关注谁。这是一种实例级(instance-level)的机制,每个样本都有自己独特的注意力模式。
但论文指出,这种实例级交互缺乏全局一致性——不同样本的注意力权重可能随意波动,因为它们没有一个统一的全局上下文。
核心创新:合成注意力(Synthetic Attention)
Synthesizer的核心思想是:不再计算点积,而是直接"合成"注意力矩阵。论文提出了几种合成函数,我按从激进到保守的顺序介绍:
1. Random Synthesizer:最激进的尝试
这是论文中最令人震惊的设计:注意力权重完全随机初始化,不依赖任何输入token!
![]()
其中![]() 是一个随机矩阵,可以是:
是一个随机矩阵,可以是:
- Fixed Random:固定不训练
- Random:可训练的随机矩阵
作者自己都承认:"我们原本没期望这个变体能work,但它竟然是一个强基线!"
直觉理解:Random Synthesizer学习的是一种任务特定的全局对齐模式,在所有样本间共享。它不关心具体的token内容,而是学习"在这个任务中,位置i通常应该关注位置j"。
2. Dense Synthesizer:条件化的合成
Dense Synthesizer对每个输入token学习一个投影:
![]()
其中F是一个两层前馈网络,将d维输入映射到序列长度N维:
![]()
直觉理解:每个token独立地"预测"它应该关注序列中哪些位置,而不是通过与其他token的相似度来决定。
3. Factorized Variants:降低参数复杂度
为了应对长序列,论文提出因子化版本:
- Factorized Random: R_1R_2^T,属于R^(N*K),k=8
- Factorized Dense: 分解为a*b两个维度
4. Mixture of Synthesizers:组合的力量
最强大的变体是混合模型,例如:
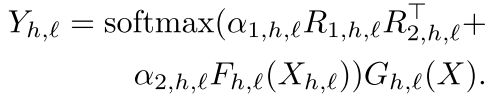
这种设计结合了全局模式(Random)和局部条件化(Dense)的优势。

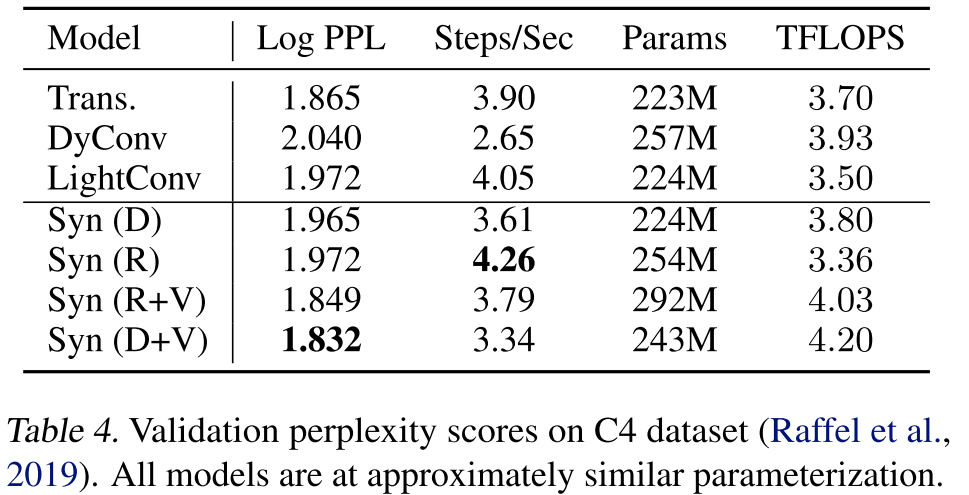
表1列出了SYNTHESIZER框架中探索的不同模型变体。“Condition on”列指的是合成输出是作为Xi的函数还是每个Xi,Xj对的函数产生。“Sample”列指示给定的变体是利用本地上下文还是全局上下文。随机合成器是全局的,因为它们在所有样本中共享相同的全局对齐模式。密集合成器被认为是局部的,因为它们是Xi的条件,这使得对齐模式依赖于每个单独的样品。为此,综合模型必须具有多个头部才能有效。
实验结果
发现1:随机矩阵竟然能Work!
在WMT'14英德翻译任务上:
- Transformer: 27.67 BLEU
- Random Synthesizer: 27.27 BLEU(仅差0.4!)
- Fixed Random(完全不训练): 23.89 BLEU
即使是固定的随机权重也能达到约24 BLEU,这完全颠覆了我们对注意力机制的理解。
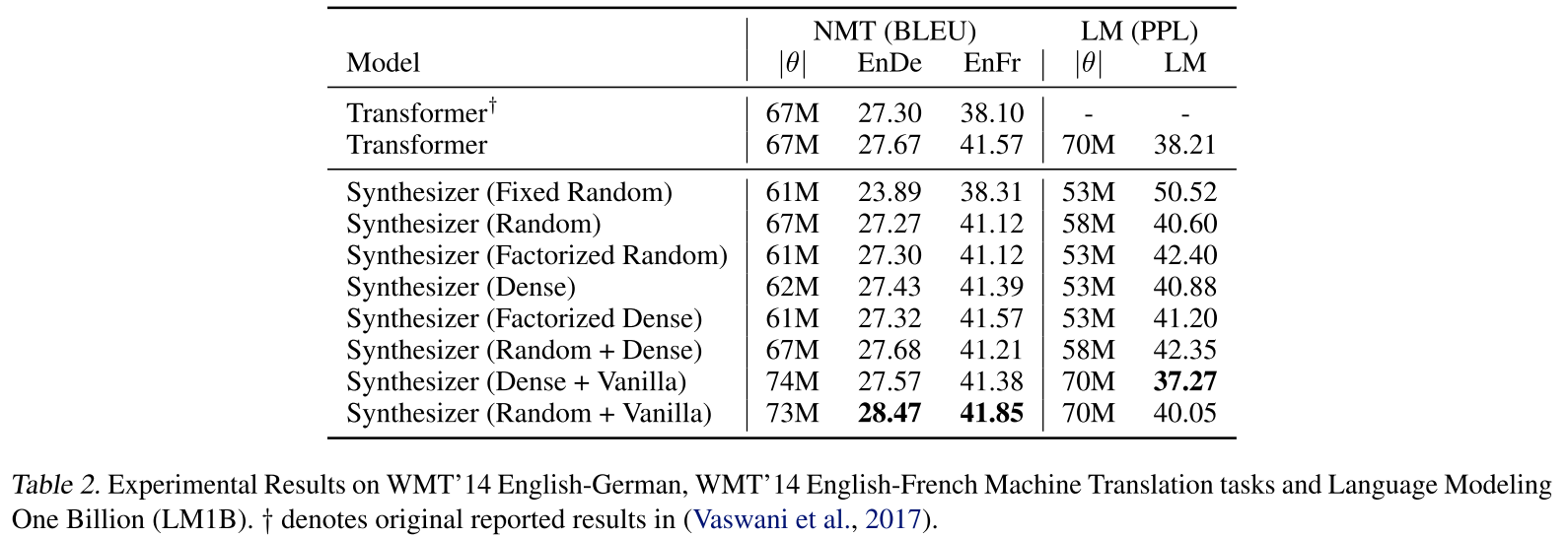
在语言建模(LM1B)任务上:
- Transformer: 38.21 PPL
- Random Synthesizer: 40.60 PPL
- Dense Synthesizer: 40.88 PPL
性能差距仅1-2个困惑度点!
发现2:混合模型带来一致性提升
当将Synthesizer与传统点积注意力混合时,几乎所有任务都有提升:
英德翻译:
- Random + Vanilla (R+V): 28.47 BLEU (+0.8相比Transformer)
- Dense + Vanilla (D+V): 27.57 BLEU
语言建模:
- Dense + Vanilla: 37.27 PPL(优于Transformer的38.21)
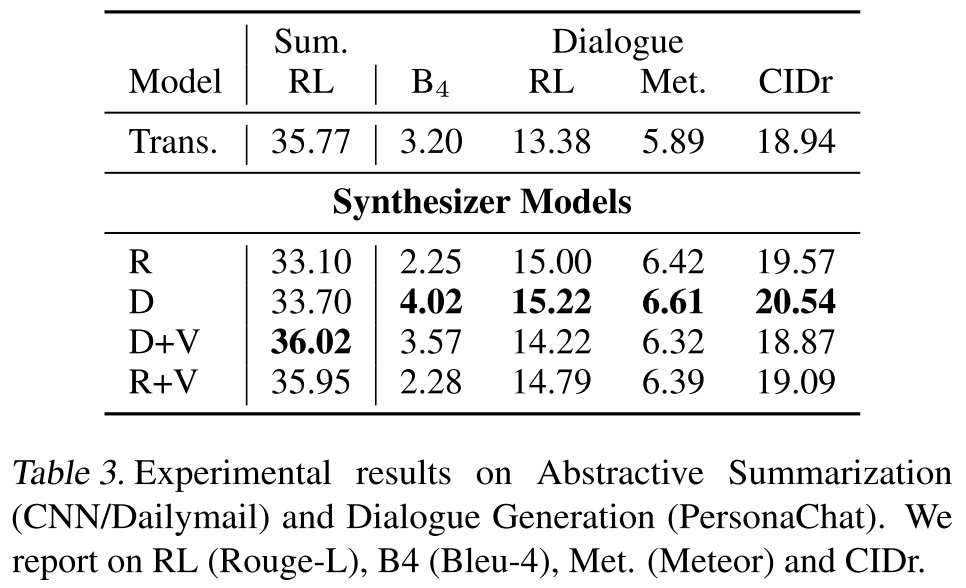
发现3:某些任务中点积反而有害!
在对话生成(PersonaChat)任务上出现了反直觉的结果:
- Transformer: Rouge-L 13.38, Meteor 5.89
- Random Synthesizer: 15.00, 6.42 ✓
- Dense Synthesizer: 15.22, 6.61 ✓
- Dense + Vanilla: 14.22, 6.32 ✗(加入点积反而下降)
这说明在某些生成任务中,实例级的token交互可能引入噪声。
发现4:速度和效率的惊喜
在C4数据集的掩码语言建模中,与Dynamic Convolutions对比:
| 模型 | Log PPL | Steps/Sec | 参数量 |
|---|---|---|---|
| Transformer | 1.865 | 3.90 | 223M |
| DyConv | 2.040 | 2.65 | 257M |
| Syn (R) | 1.972 | 4.26 | 254M |
| Syn (R+V) | 1.849 | 3.79 | 292M |
Random Synthesizer相对Dynamic Convolutions:
- 困惑度提升3.5%
- 速度快60%!
- FLOPS更低
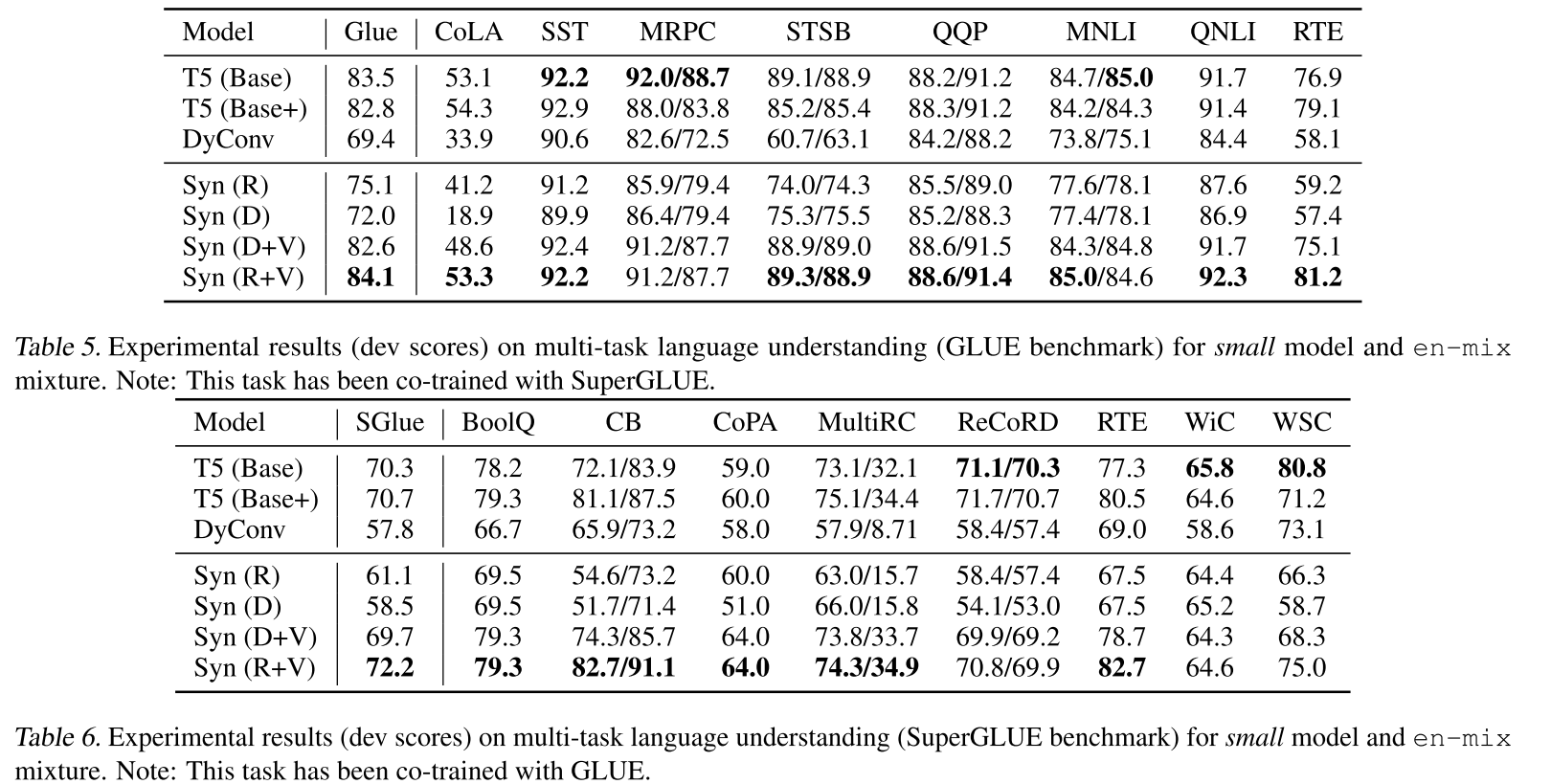
发现5:GLUE/SuperGLUE上的表现
这里出现了有趣的分化:
单句任务(如SST情感分类):Synthesizer表现出色
配对任务(如MNLI蕴含):Random和Dense单独使用时显著下降
原因是:在T5框架中,编码器的自注意力同时充当跨句子注意力(premise和hypothesis拼接在一起)。这种设置下,token-token交互至关重要。
但混合模型仍然大幅领先:
SuperGLUE:
- Transformer: 70.3
- Syn (R+V): 72.2 (+1.9)
GLUE:
- Transformer: 83.5
- Syn (R+V): 84.1 (+0.6)
注意这里Syn (R+V)比同等参数量的T5 (Base+)还要好,排除了"仅因参数更多"的可能。
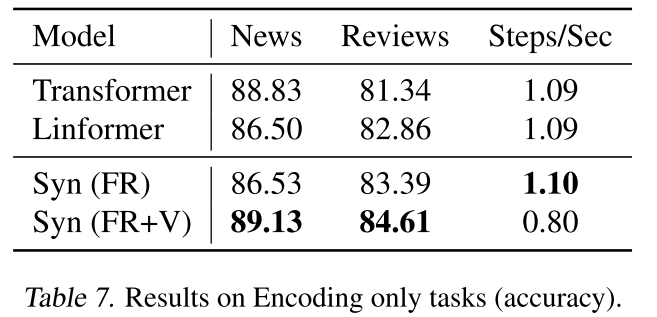
发现6:与Linformer的比较
在编码任务(AGnews和Movie Reviews)上:
| 模型 | AGnews | Reviews | 速度 |
|---|---|---|---|
| Transformer | 88.83 | 81.34 | 1.09 |
| Linformer | 86.50 | 82.86 | 1.09 |
| Syn (FR) | 86.53 | 83.39 | 1.10 |
| Syn (FR+V) | 89.13 | 84.61 | 0.80 |
Factorized Random Synthesizer在单独使用时与Linformer相当,混合版本则全面领先。
深入分析:Synthesizer学到了什么?
权重分布的差异
论文对比了Transformer和Synthesizer的注意力权重分布:
- Transformer:权重集中在0附近,方差较小
- Random Synthesizer:权重分布更分散,方差更大
- Dense Synthesizer:最大值更高,更多权重在0.1-0.2范围
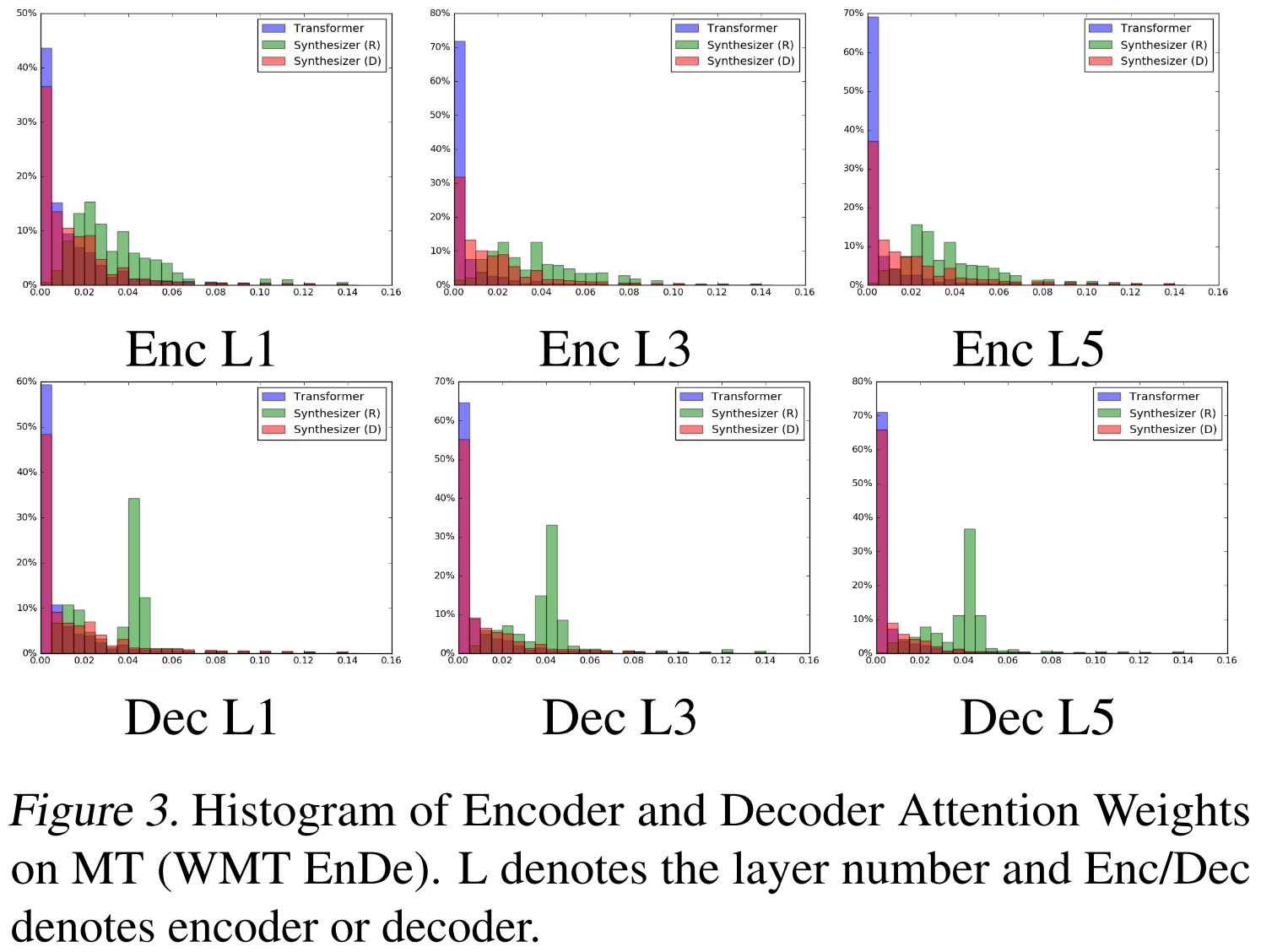
学到的模式可视化
在语言建模任务(LM1B)中,Random Synthesizer学到的模式:
- 能够学习局部窗口,类似Transformer
- 但权重更平滑、连续(因为不依赖具体token)
- 起始状态虽然随机,但经过训练能收敛到合理的局部关注模式

在机器翻译任务中,不同Synthesizer变体展现出不同的模式:
- Random: 学习相对均匀的全局模式
- Factorized Random: 低秩结构,更规则
- Dense: 更动态,每个样本不同
- Factorized Dense: 块状结构明显


理论意义:重新思考注意力
这篇论文的发现挑战了几个基本假设:
1. Token-Token交互不是必需的
Random Synthesizer的成功表明,全局的、任务特定的对齐模式在许多任务上足够有效。这类似于学习"在翻译任务中,源语言的位置i通常对应目标语言的位置j附近"。
2. 点积注意力不是唯一答案
Dense Synthesizer通过简单的前馈网络就能达到接近的性能,说明query-key相似度计算可能被高估了。
3. 组合才是王道
最一致的发现是:混合多种注意力机制总是有益的。这说明:
- 全局模式(Random)捕获任务结构
- 实例条件化(Dense)提供灵活性
- 点积交互(Vanilla)补充细粒度信息
三者互补,缺一不可。
4. 任务差异性
不同任务对注意力机制的需求大不相同:
- 翻译/LM:对点积依赖较小
- 对话生成:点积可能有害
- 配对任务(蕴含/QA):必须有跨句子交互
- 单句分类:Synthesizer足矣
与MLP-Mixer的关系
论文后续补充指出,Random Synthesizer本质上是多头版本的MLP-Mixer(虽然Synthesizer早了一年提出):
- Random Synthesizer在长度维度应用权重矩阵$R \in \mathbb{R}^{L \times L}$
- 等价于转置轴后进行线性投影(MLP-Mixer的token-mixer)
- 区别:(1) Synthesizer用softmax归一化;(2) 多头设计
这为理解两类模型提供了统一视角。
实践建议
基于论文的发现,这里有一些实践建议:
1. 何时使用Synthesizer?
- 速度敏感场景:Random Synthesizer比Transformer快,比Dynamic Convolutions快60%
- 长序列编码:Factorized Random降低O(N^2)复杂度
- 生成任务:Dense Synthesizer可能优于Transformer
- 预算有限:Random Synthesizer参数效率高
2. 混合策略
几乎所有场景都建议使用混合模型:
- R+V: 平衡速度和性能
- D+V: 最大化性能
- R+D: 纯Synthesizer,去除点积
3. 多头至关重要
论文强调:Synthesizer模型必须使用多头才有效,因为不同头可以学习不同的全局模式。
局限性和未来方向
论文也诚实地指出了一些局限:
1. 序列长度依赖
Random和Dense Synthesizers的参数都依赖序列长度N(类似位置编码)。解决方案:
- 定义最大长度,动态截断
- 投影到更小维度b,然后平铺
2. 跨注意力仍需点积
论文发现自注意力可以被合成替代,但跨注意力(cross-attention)不行。这在编码器-解码器架构中很重要。
3. 配对任务的挑战
GLUE/SuperGLUE上的结果显示,当自注意力需要充当跨句子注意力时,单纯的Synthesizer不够。
结论:注意力机制的新视角
这篇论文的价值不在于提出了一个全面超越Transformer的新模型,而在于:
- 打破迷思:点积自注意力不是Transformer成功的唯一原因
- 提供工具:Synthesizer是一个灵活的框架,可以探索各种合成函数
- 启发思考:全局对齐 vs 局部交互,哪个更重要?
- 实用价值:混合模型一致性优于基线,Random Synthesizer速度快且有效
正如作者所说:
"我们相信这些发现将激发对Transformer自注意力机制真正作用和效用的进一步研究和讨论。"
从工程角度看,Synthesizer提供了速度-性能的新权衡点;从科学角度看,它迫使我们重新审视:注意力机制到底在学什么?
也许,Transformer的成功不仅仅来自于query-key相似度计算,而更多来自于:
- 全连接的token图结构
- 多头带来的表示多样性
- 深度堆叠形成的层次化表示
Synthesizer通过简化甚至移除token交互,帮助我们隔离和理解这些因素的独立贡献。这种"减法"研究范式,值得更多关注。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 12
12 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)