多GPU分布式训练
一、多GPU分布式训练
1.1 如何把任务分给多个GPU?
假设你现在有4 张 GPU,你怎么分工最快?
深度学习中有三种主流的并行策略:
1. 模型并行(网络拆分 / Pipeline Parallelism)
- 做法:GPU 1 算前 5 层,算完把特征图传给 GPU 2 算后 5 层。
- 缺点:极其容易造成**“阻塞”**。GPU1在计算时,GPU2处于空闲。而且层与层之间传输特征图极其消耗带宽。通常只有在模型大到单张 GPU 显存完全装不下时(如 GPT-3)才被迫使用。
2. 张量并行(层内拆分 / Tensor Parallelism)
- 做法:把一个巨大的矩阵乘法切成好几块,每个 GPU 算一部分。
- 缺点:同步成本极高。每算完一层,4 个厨师都必须停下来对齐一下进度。这需要极快的硬件连接(如 NVLink)。
3. 数据并行(Data Parallelism)
- 做法:4个GPU都有一套完整且相同的模型参数,来了Batch Size = 128的数据,直接分成 4 份,每张GPU独立做 32 份数据。做完之后,再进行汇总。
- 优点:最简单,最高效。所有的 GPU 都在做完全一样的工作,只是数据不同。
- 整体流程:
- 把一个 Batch 的数据均分给 kkk 个 GPU。
- 每个 GPU 独立进行前向传播和反向传播,算出各自的梯度。
- 汇总梯度(All-Reduce):把 kkk 个 GPU 算出的梯度全部加起来。
- 广播(Broadcast):把加起来的最终梯度再发回给每个 GPU。
- 每个 GPU 用这个最终梯度更新自己手里的参数(保证每个 GPU 的模型始终一模一样)。
1.2 代码实现
为了演示底层的参数传递,我们放弃了方便的 nn.Module,手动定义了权重 W 和偏置 b,并用 F.conv2d 等函数式 API 来写一个 LeNet:
1.模型定义
from d2l import torch as d2l
import torch
from torch import nn
from torch.nn import functional as F
# 初始化模型参数(W1到W4,b1到b4),注意这里都在 CPU 上
scale = 0.01
W1 = np.random.normal(scale=scale, size=(20, 1, 3, 3))
b1 = np.zeros(20)
W2 = np.random.normal(scale=scale, size=(50, 20, 5, 5))
b2 = np.zeros(50)
W3 = np.random.normal(scale=scale, size=(800, 128))
b3 = np.zeros(128)
W4 = np.random.normal(scale=scale, size=(128, 10))
b4 = np.zeros(10)
params = [W1, b1, W2, b2, W3, b3, W4, b4]
# 手动定义 LeNet 的前向传播
def lenet(X, params):
h1_conv = npx.convolution(data=X, weight=params[0], bias=params[1],
kernel=(3, 3), num_filter=20)
h1_activation = npx.relu(h1_conv)
h1 = npx.pooling(data=h1_activation, pool_type='avg', kernel=(2, 2),
stride=(2, 2))
h2_conv = npx.convolution(data=h1, weight=params[2], bias=params[3],
kernel=(5, 5), num_filter=50)
h2_activation = npx.relu(h2_conv)
h2 = npx.pooling(data=h2_activation, pool_type='avg', kernel=(2, 2),
stride=(2, 2))
h2 = h2.reshape(h2.shape[0], -1)
h3_linear = np.dot(h2, params[4]) + params[5]
h3 = npx.relu(h3_linear)
y_hat = np.dot(h3, params[6]) + params[7]
return y_hat
# 定义交叉熵损失,注意 reduction='none' 表示不要自动求平均,保留每个样本的损失
loss = nn.CrossEntropyLoss(reduction='none')
2.把参数分发到各个 GPU 上
def get_params(params, device):
# 把存在 CPU 上的参数列表 params,复制一份到指定的 GPU (device) 上
new_params = [p.to(device) for p in params]
# 告诉 PyTorch,这批刚复制到 GPU 上的参数是需要求梯度的!
for p in new_params:
p.requires_grad_()
return new_params # 返回在指定 GPU 上的一整套模型参数
3.聚合所有 GPU 的数据 (All-Reduce)
假设有两张 GPU,GPU0 算出了梯度 A,GPU1 算出了梯度 B。我们需要让两张 GPU 上的梯度都变成 A+B。
def allreduce(data):
# data 是一个列表,里面装着各个 GPU 上的同名参数(或梯度)
# len(data) 就是 GPU 的数量
# 第一步:把所有其他 GPU (从 1 开始) 上的数据,全累加到 GPU 0 上
for i in range(1, len(data)):
# data[i].to(data[0].device) 意思是把 GPU i 的数据搬到 GPU 0 的显存里
# 然后加到 data[0] 上
data[0][:] += data[i].to(data[0].device)
# 第二步:现在 GPU 0 上已经是总和了,把这个总和广播(复制)回所有其他 GPU
for i in range(1, len(data)):
# 把求和后的 data[0] 搬到 GPU i 的显存里,覆盖掉它原来的值
data[i][:] = data[0].to(data[i].device)
4. 把数据切分给各个 GPU
def split_batch(X, y, devices):
"""将X和y均匀地拆分到多个设备上"""
assert X.shape[0] == y.shape[0]
# nn.parallel.scatter 是 PyTorch 底层函数
# 假设 X 有 256 张图,devices 包含 [cuda:0, cuda:1]
# 它会自动把 X 切成两半,前 128 张发给 cuda:0,后 128 张发给 cuda:1
return (nn.parallel.scatter(X, devices),
nn.parallel.scatter(y, devices))
5. 在一个 Batch 上执行多 GPU 训练
def train_batch(X, y, device_params, devices, lr):
# 1. 拆分数据:X_shards 包含了分布在各个 GPU 上的数据碎片
X_shards, y_shards = split_batch(X, y, devices)
# 2. 分别在每个 GPU 上计算前向传播和损失
# zip 把 数据碎片、标签碎片 和 该 GPU 专属的模型参数打包在一起
ls = [loss(lenet(X_shard, device_W), y_shard).sum()
for X_shard, y_shard, device_W in zip(
X_shards, y_shards, device_params)]
# 3. 反向传播:各个 GPU "各自为战",算出各自参数的局部梯度
for l in ls:
l.backward()
# 4. 同步梯度(灵魂步骤)
with torch.no_grad(): # 同步梯度的过程不需要被 PyTorch 记录到计算图中
# 遍历模型的每一个参数矩阵(如 W1, b1...)
for i in range(len(device_params[0])):
# 把所有 GPU 上的这个参数的梯度拿出来,执行刚才写的 allreduce
# 这样一来,所有 GPU 上对应参数的梯度都变成了相同的总和!
allreduce([device_params[c][i].grad for c in range(len(devices))])
# 5. 更新参数:由于每个 GPU 的参数一模一样,而且刚刚同步的梯度也一模一样
# 所以各自执行 SGD 后,每个 GPU 的参数更新后仍然保持完全一致!
for param in device_params:
d2l.sgd(param, lr, X.shape[0])
6. 训练函数
def train(num_gpus, batch_size, lr):
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
devices = [d2l.try_gpu(i) for i in range(num_gpus)]
# 将模型参数复制到num_gpus个GPU
device_params = [get_params(params, d) for d in devices]
num_epochs = 10
animator = d2l.Animator('epoch', 'test acc', xlim=[1, num_epochs])
timer = d2l.Timer()
for epoch in range(num_epochs):
timer.start()
for X, y in train_iter:
# 为单个小批量执行多GPU训练
train_batch(X, y, device_params, devices, lr)
torch.cuda.synchronize()
timer.stop()
# 在GPU0上评估模型
animator.add(epoch + 1, (d2l.evaluate_accuracy_gpu(
lambda x: lenet(x, device_params[0]), test_iter, devices[0]),))
print(f'测试精度:{animator.Y[0][-1]:.2f},{timer.avg():.1f}秒/轮,'
f'在{str(devices)}')
如果我们运行这段代码,我们会发现 2 个 GPU 跑得可能和 1 个 GPU 一样慢,甚至更慢。
- 原因 1(模型太小):LeNet 的计算量极小。GPU 瞬间就计算完了前向和反向传播。
- 原因 2(通信开销太大):我们写的
allreduce函数非常低效,需要把数据通过主板总线(PCIe)搬来搬去。通信耗费的时间远远大于 GPU 计算的时间。 - 在真实工业界,我们会使用 ResNet-50 级别以上的大模型,并且使用 NVIDIA 专门提供的 NCCL 库来进行通信,那时多 GPU 的威力才会真正显现。
一些练习
1. 在 kkk 个 GPU 上进行训练时,将批量大小从 bbb 更改为 k⋅bk \cdot bk⋅b。
- 解析:这是深度学习界著名的**“线性缩放法则 (Linear Scaling Rule)”**。如果单卡跑 batch_size = 256,现在有 4 张卡,你的全局 batch_size 应该设为 1024。因为如果还用 256,每张卡只分到 64 张图,GPU 根本“吃不饱”,利用率极低。
2. 随着 GPU 数量的增加,学习率应该如何扩展?
- 解析:如果 Batch Size 扩大了 kkk 倍,学习率 (Learning Rate) 也应该扩大 kkk 倍!
- 数学原因:Batch Size 越大,每次计算出来的梯度越准确(方差越小,噪声越少)。既然方向已经很准确了,我们就可以放心大胆地迈出更大的一步(更大的学习率)。如果不扩大学习率,大 Batch Size 会导致模型陷入极其尖锐的局部最优解。
3. 实现一个更高效的
allreduce函数用于在不同的GPU上聚合不同的参数?为什么这样的效率更高?
- 解析:我们写的
allreduce是中心化(Parameter Server)模式:所有人都把数据传给 GPU 0,GPU 0 算完再发给大家。GPU 0 成为了可怕的通信瓶颈。- 高效实现:业界通用的是 Ring-AllReduce(环形同步算法),这是百度提出的。GPU 0 传给 GPU 1,GPU 1 传给 GPU 2… 形成一个环。每个人在传数据的同时也在收数据,把带宽利用到了极致。PyTorch底层的
torch.distributed.all_reduce默认就是用这种高级算法。4. 实现模型在多 GPU 下测试精度的计算。
- 解析:思路和训练一模一样:
- 把测试集的 Batch 也用
split_batch分给各个 GPU。- 每个 GPU 独立跑前向传播,算出自己分到的那几十个样本里“对了多少个”。
- 用类似
allreduce的方法,把各个 GPU 算出的“正确个数”加起来。- 最后除以测试集总人数,得到准确率。这比只把数据塞给 GPU 0 慢慢测要快得多。
1.3 简洁实现
下面使用深度学习框架提供的高级 API(比如 PyTorch 的 DataParallel)来实现多 GPU 训练。
我们要训练的模型从玩具级别的 LeNet 换成了工业级别的 ResNet-18。
- 为什么换模型? 因为多 GPU 训练是有“通信开销”的(GPU 之间传数据需要时间)。如果模型太小(如 LeNet),算得还没传得快,多卡反而比单卡慢。只有像 ResNet 这样计算量庞大的模型,才能体现出多卡的加速优势。
PyTorch 的一键多卡神器:nn.DataParallel (简称 DP)
它的底层工作流程(假设有 GPU0 和 GPU1):
- 参数复制:每次前向传播前,把 GPU0 上的最新模型参数,复制一份到 GPU1 上。
- 数据分发(Scatter):你只需要把整批数据(比如 Batch Size=512)丢给 GPU0。
DataParallel会自动把前 256 个切给 GPU0,后 256 个切给 GPU1。 - 并行计算:两张卡同时独立计算自己那部分数据的前向传播。
- 结果收集(Gather):GPU1 把算出来的输出结果发回给 GPU0,GPU0 把结果拼起来计算总 Loss。
- 反向传播与聚合:各自计算梯度后,GPU1 把梯度发给 GPU0,GPU0 自动求和(All-Reduce),最后更新 GPU0 上的模型参数。
代码实现:
1.修改版ResNet-18
之前学的标准 ResNet-18 是为 224x224 分辨率设计的。但这次用的 Fashion-MNIST 图片只有 28x28。如果不做修改,图片一进去经过 7x7 大卷积和池化,尺寸直接变成 7x7,再经过几个残差块就变成 0 了。
from d2l import torch as d2l
import torch
from torch import nn
def resnet18(num_classes, in_channels=1):
"""稍加修改的ResNet-18模型"""
def resnet_block(in_channels, out_channels, num_residuals,
first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(d2l.Residual(in_channels, out_channels,
use_1x1conv=True, strides=2))
else:
blk.append(d2l.Residual(out_channels, out_channels))
return nn.Sequential(*blk)
# 修改的核心在这里
net = nn.Sequential(
# 原版是 kernel_size=7, stride=2 和一个 MaxPool。
# 这里改成了极其温和的 kernel_size=3, stride=1,且去掉了池化层。
# 这样 28x28 的图片进去,出来还是 28x28,给后面的残差块留足了空间。
nn.Conv2d(in_channels, 64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(64),
nn.ReLU())
# 加入 4 个残差阶段
net.add_module("resnet_block1", resnet_block(64, 64, 2, first_block=True))
net.add_module("resnet_block2", resnet_block(64, 128, 2))
net.add_module("resnet_block3", resnet_block(128, 256, 2))
net.add_module("resnet_block4", resnet_block(256, 512, 2))
# 头部:全局平均池化 + 全连接分类
net.add_module("global_avg_pool", nn.AdaptiveAvgPool2d((1,1)))
net.add_module("fc", nn.Sequential(nn.Flatten(),
nn.Linear(512, num_classes)))
return net
2. 多 GPU 训练的终极代码
这段代码是日后你做任何单机多卡项目的标准模板:
def train(net, num_gpus, batch_size, lr):
# 加载数据集
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
# 获取可用的 GPU 列表,比如 [device(type='cuda', index=0), device(type='cuda', index=1)]
devices = [d2l.try_gpu(i) for i in range(num_gpus)]
# 初始化权重参数的辅助函数
def init_weights(m):
if type(m) in [nn.Linear, nn.Conv2d]:
nn.init.normal_(m.weight, std=0.01)
# 应用初始化
net.apply(init_weights)
# 这行代码,把原来的单卡网络包装成了多卡网络
# device_ids 告诉它使用哪几张卡。主卡默认是 devices[0]。
net = nn.DataParallel(net, device_ids=devices)
# 优化器不需要改,它会自动追踪被 DataParallel 包装后的参数
trainer = torch.optim.SGD(net.parameters(), lr)
loss = nn.CrossEntropyLoss()
timer, num_epochs = d2l.Timer(), 10
animator = d2l.Animator('epoch', 'test acc', xlim=[1, num_epochs])
for epoch in range(num_epochs):
net.train()
timer.start()
for X, y in train_iter:
trainer.zero_grad()
# 关键细节
# 为什么只 to(devices[0])(即主卡 cuda:0)?
# 因为 DataParallel 要求你先把所有数据(512张图)都放在主卡上。
# 然后 DataParallel 会在底层自动帮你把数据切分并发送给其他卡!
X, y = X.to(devices[0]), y.to(devices[0])
# 前向传播:此时网络内部已经在多张卡上并行计算了!
l = loss(net(X), y)
# 反向传播:梯度会自动在 GPU0 上汇聚(All-Reduce)
l.backward()
# 更新参数:在 GPU0 上更新,下一次 forward 时自动同步给其他卡
trainer.step()
timer.stop()
# 评估精度
animator.add(epoch + 1, (d2l.evaluate_accuracy_gpu(net, test_iter),))
print(f'测试精度:{animator.Y[0][-1]:.2f},{timer.avg():.1f}秒/轮,在{str(devices)}')
3. 运行与验证线性缩放法则
- **单 GPU **:
train(net, num_gpus=1, batch_size=256, lr=0.1) - 双 GPU:
train(net, num_gpus=2, batch_size=512, lr=0.2)
train(net, num_gpus=1, batch_size=256, lr=0.1)
输出:
测试精度:0.92,41.3秒/轮,在[device(type='cuda', index=0)]
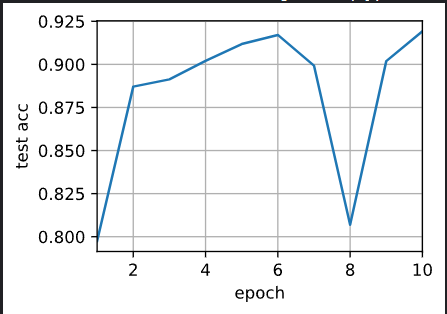
train(net, num_gpus=2, batch_size=512, lr=0.2)
输出:
测试精度:0.83,22.8秒/轮,在[device(type='cuda', index=0), device(type='cuda', index=1)]
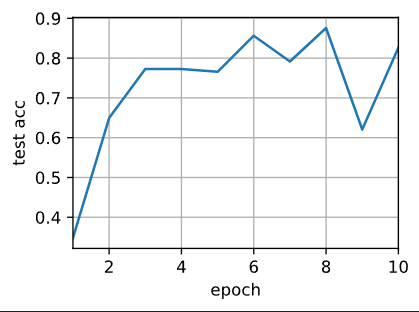
GPU 变成了 2 倍 →\rightarrow→ 为了喂饱两张卡,Batch Size 也翻倍成了 512 →\rightarrow→ 根据线性缩放法则,学习率(LR)也必须翻倍成了 0.2。
最终结果:两张卡跑完一轮的时间几乎是单卡的一半,实现了极好的加速比。
一些练习
1. 如果使用 16 个 GPU(例如在 AWS p2.16xlarge 上)尝试此操作,会发生什么?
解答:会遇到严重的“通信瓶颈”,加速效果极差
- 原理剖析:
nn.DataParallel(DP) 的架构是典型的**“单节点中心化”**结构。GPU0 被当做了“主节点”。- 当扩展到 16 张卡时,每次反向传播,GPU1 到 GPU15 都必须把自己算出来的巨大梯度文件全部发给 GPU0。GPU0 的网络带宽和总线会被瞬间挤爆!等 GPU0 算完更新后,又要向 15 张卡分发参数。
- 工业界解法:在超过 4 张显卡或者跨多台机器时,我们绝对不会使用
DataParallel,而是使用 PyTorch 的终极杀器:DistributedDataParallel(DDP)。DDP 采用前面讲过的 Ring-AllReduce(环形同步)算法,去中心化,16 张卡甚至 1000 张卡也能保持近乎线性的加速比。2. 有时候不同的设备计算能力不同,我们可以同时使用 GPU 和 CPU 分配工作吗?为什么?
解答:理论上可以,但现实中绝对不要这么做。
- 木桶效应(短板效应):深度学习每一层的计算都是同步的(必须等大家把这一批数据都算完,汇总了梯度,才能进入下一批次)。
- 假设你把一个 Batch 分给了一张 RTX 3090 和一块 Intel CPU。
- GPU 算完自己那份数据只要 0.1 秒;CPU 算完需要 5 秒。
- 结果:价值上万块钱的 GPU 会在 0.1 秒后停下来,干瞪眼等 CPU 等 4.9 秒!整体的训练速度完全被 CPU 拖累,不仅毫无加速,反而比只用单张 GPU 慢几十倍。
- 结论:多设备并行训练时,不仅不能混用 CPU 和 GPU,甚至强烈建议使用完全同型号、同算力的 GPU(比如全是 3090,或者全是 A100),否则算得快的卡永远在等算得慢的卡。
家把这一批数据都算完,汇总了梯度,才能进入下一批次)。
- 假设你把一个 Batch 分给了一张 RTX 3090 和一块 Intel CPU。
- GPU 算完自己那份数据只要 0.1 秒;CPU 算完需要 5 秒。
- 结果:价值上万块钱的 GPU 会在 0.1 秒后停下来,干瞪眼等 CPU 等 4.9 秒!整体的训练速度完全被 CPU 拖累,不仅毫无加速,反而比只用单张 GPU 慢几十倍。
- 结论:多设备并行训练时,不仅不能混用 CPU 和 GPU,甚至强烈建议使用完全同型号、同算力的 GPU(比如全是 3090,或者全是 A100),否则算得快的卡永远在等算得慢的卡。
1.4 分布式计算

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)