LLM基本原理全解析:从预测下一个词到智能对话的奥秘
你有没有想过,当你在对话框中输入一个问题,AI是如何在几秒钟内给出一个看似"有思想"的回答的?它真的在思考吗?还是只是在"背书"?今天,我们就来揭开大语言模型(LLM)的神秘面纱,看看这个超级大脑到底是如何工作的。
一、核心逻辑:它其实是个"预测大师"
大语言模型的本质,并不是真正"理解"文字,而是在做一道复杂的数学概率题。
想象一下,你正在玩一个填字游戏。当你看到"今天天气真"这几个字时,你的大脑会本能地预测下一个字很可能是"好"。大语言模型做的事情,本质上和你一样——预测下一个词(Token)出现的概率。
具体是怎么操作的呢?当你输入一段文字,模型会:
- 分析你输入的所有内容
- 计算词汇表中成千上万个可能的词,哪个最可能出现在下一个位置
- 选择概率最高的那个词
- 把这个新词加入上下文,继续预测下一个词
- 如此循环,直到生成完整的回答
这就像多米诺骨牌,一个词触发下一个词,最终形成连贯的文本。模型通过学习海量文本中词与词之间的关联规律,掌握了语法结构、逻辑关系,甚至部分世界知识。但它并不真正"知道"这些知识的含义,只是掌握了它们出现的统计规律。
二、技术架构:Transformer的魔法
要让模型能够处理长文本并理解词与词之间的关系,需要一个强大的架构。这就是Transformer,它是当前所有大语言模型的基石。
Transformer最核心的创新是自注意力机制(Self-Attention)。这个机制让模型在处理每一个词时,能够同时"关注"句子中其他所有词的重要性。
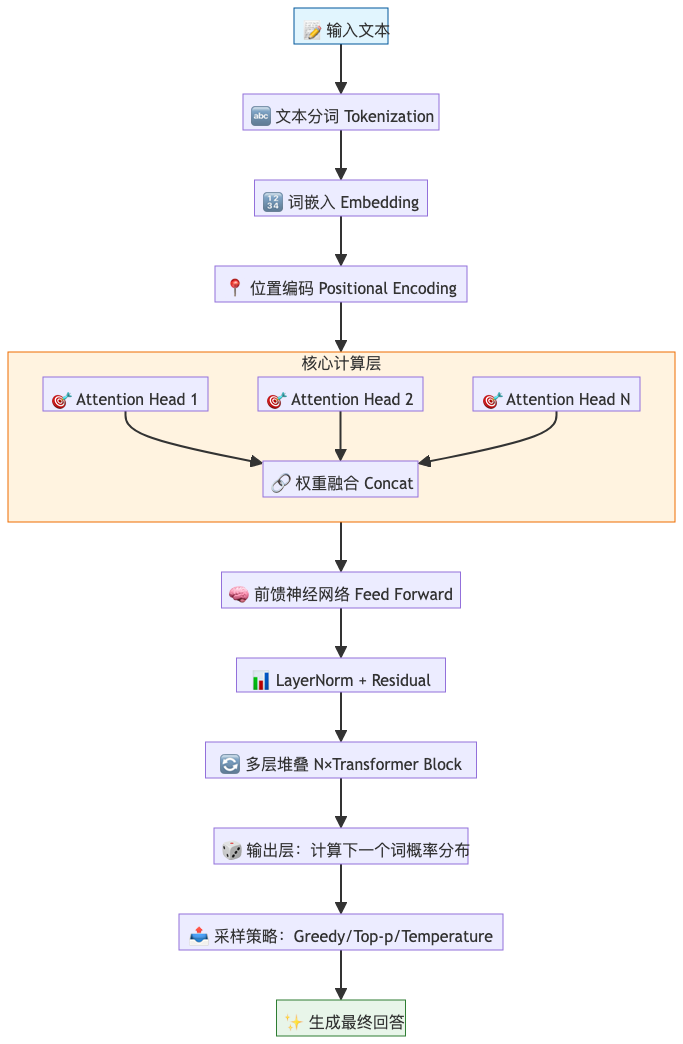
举个例子,在句子"我把苹果放进箱子,因为它很轻"中,当模型处理"它"这个词时,自注意力机制会帮助模型判断"它"指的是"苹果"还是"箱子"。通过计算词与词之间的关联权重,模型能够捕捉到这种指代关系。
此外,Transformer还采用了位置编码技术。因为模型是并行处理所有词的,它本身不知道词的先后顺序。位置编码就像给每个词贴上"座位号",让模型清楚地知道谁在前、谁在后。
三、训练过程:三阶段的进化之路
大语言模型的能力不是一蹴而就的,它需要经历三个关键阶段的训练,才能从"书呆子"变成"聊天高手"。
第一阶段:预训练(Pre-training)—— 博览群书
这是最耗资源、最基础的阶段。模型需要"阅读"互联网上几乎所有的公开文本,包括网页、书籍、代码、维基百科等,数据量达到TB级别。
在这个阶段,模型的任务非常简单粗暴:预测下一个词。就像一个学生不停地做"完形填空"练习,通过海量训练,模型逐渐掌握了语言的语法规则、事实知识和推理模式。
训练完成后,我们得到一个基座模型(Base Model)。这个模型知识渊博,但它还不会聊天。如果你问它"中国的首都是哪里?",它可能会接着你的话续写"是一个历史悠久的城市",而不是直接回答"北京"。
第二阶段:有监督微调(SFT)—— 学会对话
为了让模型学会听懂指令并回答问题,我们需要进行第二阶段训练。这个阶段使用高质量的人工问答对数据,教模型如何遵循指令、如何组织回答。
经过SFT训练,模型变成了对话模型(Chat Model),它知道用户提问时应该给出答案,而不是继续续写。
第三阶段:人类反馈强化学习(RLHF)—— 精益求精
最后一个阶段,是让模型的回答更符合人类价值观。我们会让人类标注员对模型的多个回答进行打分或排序,训练一个奖励模型,然后引导大语言模型生成人类更喜欢的高质量回答。
这个阶段的目标是让模型变得有用、诚实、无害,减少有害输出和偏见内容。

四、关键概念:你必须知道的术语
在理解大语言模型时,有几个核心概念必须掌握:
Token(词元):模型不认识完整的单词或汉字,它会将文本切分成最小的单元。英文通常是词根或子词(比如"playing"会被切分成"play"和"ing"),中文通常是字或常用词。
Embedding(嵌入):这是将Token转换成一串数字向量的过程。神奇的是,语义相近的词,在向量空间中的距离也更近。比如"国王"和"王后"的向量关系,类似于"男人"和"女人"的向量关系。
参数(Parameters):这是模型内部的可调整变量(权重)。参数量越大,模型能够存储的知识细节和推理能力通常越强。现在的模型参数量从几十亿到几千亿不等。
上下文窗口(Context Window):这是模型一次能"记住"的最大文本长度。如果对话超过了这个长度,模型就会"忘记"最早的内容。这也是为什么长对话中,AI有时会忘记你开头说的话。
五、局限性与挑战:它并非万能
尽管大语言模型表现惊人,但我们必须清醒地认识到它的局限性:
幻觉问题(Hallucination):由于是概率预测,模型可能会一本正经地胡说八道,尤其是遇到它不知道的知识时。它可能会编造看似合理但完全错误的事实。
没有真实意识:模型没有自我意识,不懂情感,只是在进行复杂的模式匹配。它的所有"思考"都是数学计算的结果。
知识截止:预训练数据是有时间截止的,除非联网搜索,否则它不知道训练之后发生的新事件。
黑盒性质:即使是开发者,也很难完全解释模型为什么在特定情况下输出了特定内容,可解释性较差。
六、结语:理解才能更好使用
大语言模型就像一个读过互联网上几乎所有书的超级鹦鹉,它通过规模(数据量+参数量)带来的涌现能力,能够处理复杂的逻辑推理、代码生成和创意写作任务。
理解它的工作原理,不是为了成为技术专家,而是为了更理性地使用它。知道它会"幻觉",你就会对它的回答保持审慎;知道它是概率预测,你就不会期待它100%准确;知道它的知识有截止时间,你就会主动核实最新信息。
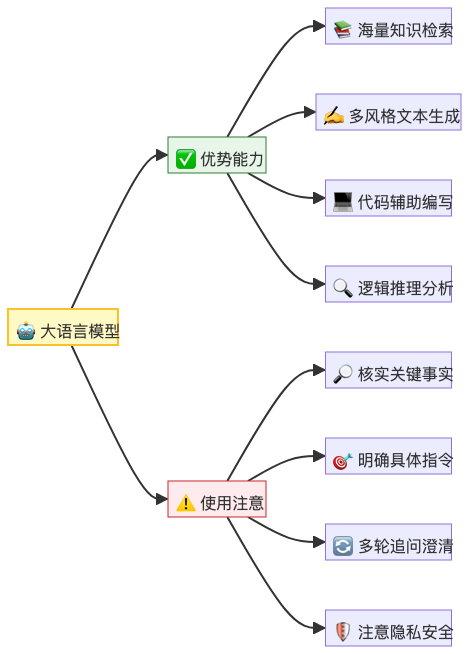
AI不是神,也不是魔,它只是一个强大的工具。真正聪明的使用者,既不会盲目崇拜,也不会全盘否定,而是了解其原理,发挥其优势,规避其缺陷。这,才是与AI共处的正确姿势。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)