掌握RAG架构进阶:14个实战案例教你构建知识图谱,告别检索失败,收藏这份程序员学习宝典!
本文深入剖析了标准RAG架构(基于向量检索)的局限性,如推理链断裂、结构识别盲点、无法处理“不存在”等14种常见失败场景。通过14个具体案例,详细阐述了如何利用图遍历和知识图谱技术来弥补这些短板,提升大模型在复杂场景下的准确性和可靠性。内容涵盖了多跳查询、层次化总结、精准过滤等关键方法,为程序员提供了一套系统化的RAG优化方案。
标准的 RAG 架构(基于向量检索)在过去一年里几乎成了 AI 应用的标配。它的逻辑很直观:将文档切片、转化为向量、根据语义相似度找最接近的代码块。
RAG 的思路看似简单,但持续优化却是一场“长跑”。从简单的向量匹配到引入知识图谱,本质上是我们在尝试教给大模型一套结构化的思维方式。
向量检索的核心局限在于它是一种非结构化的模糊匹配。这导致了三个致命的失败点:
- 断裂的推理链:它能找到 A,也能找到 B,但如果你问 A 和 C 之间通过 B 建立的联系,向量搜索往往会因为路径太长而丢掉关键上下文。
- 对结构的盲目:它无法区分“CEO 领导公司”和“公司雇佣 CEO”在层级上的本质区别。
- 处理“不存在”的无能:当用户询问“哪些零件缺失了”时,向量数据库通常只会返回现有的零件,因为它无法检索到“不存在”的东西。
我们针对 14 个常见的 RAG 失败场景,编写了 14 个 案例展示了如何利用图遍历来补全 RAG 的逻辑短板。
https://github.com/FareedKhan-dev/14-rag-failures
- 多跳查询(Multi-hop Reasoning):通过图路径轻松连接相隔数个文档的信息。
- 层次化总结:利用图的社区检测算法,实现对大规模文档集的全局概览。
- 精准过滤:利用属性关系(Directional Relationships)消除语义歧义。
RAG 失败案例 1:多跳逻辑断裂(The Multi-Hop Disconnect)
假设你正在处理一份复杂的项目档案,并向 AI 提出了一个需要“转弯”的问题:
“Chimera 项目负责人出生城市的法定货币是什么?”
要回答这个问题,AI 必须完成以下逻辑链:
- Fact A: Chimera 项目负责人是 Elias Thorne 博士。
- Fact B: Elias Thorne 出生在 Valoria 市。
- Fact C: Valoria 市使用 V-Cred 货币。
标准的向量搜索(Vector Search)是基于语义相似度的。当你搜索上述问题时,向量数据库会找到包含“Project Chimera”和“Currency”的片段。
结果,它检索到了:
- 文档 1:提到项目负责人是 Elias Thorne。
- 噪声文档:提到“Chimera-Next 软件项目”或“国际贸易中的欧元/美元”。
它唯独漏掉了文档 3(Valoria 的货币)。为什么?因为“Valoria 货币”这个片段,在语义上与“Project Chimera 项目负责人”几乎没有任何向量层面的相似性。逻辑链在第二步断开了。
为了解决这种“多跳推理”困境,我们不能只让 AI “搜索”,必须让它“顺藤摸瓜”。这就是 Knowledge Graph (知识图谱) 的用武之地。

通过将文档解析为 节点(Node) 和 关系(Edge),我们构建了一个结构化的思维导图:
(Project Chimera) --[负责人]--> (Dr. Elias Thorne)(Dr. Elias Thorne) --[出生地]--> (Valoria City)(Valoria City) --[使用货币]--> (Valorian Credit)
RAG 失败案例 2:因果合成失效(The Causal Synthesis Failure)
当 RAG 系统遇到需要严格遵守规则(Rule-following)的场景时,语义搜索的“模糊性”可能会导致致命的后果。
“我可以把 Titan-X 和 Solvo-Clean 储存在同一个柜子里吗?”
在后台文档中,隐藏着这样几条关键信息:
- 文档 A:Titan-X 的主要成分是 过氧化氢(Hydrogen Peroxide)。
- 文档 B:Solvo-Clean 是一种基于 丙酮(Acetone) 的有机溶剂。
- 文档 C(核心规则):警告!氧化剂(如过氧化物) 严禁与 有机溶剂 混合存放,否则有自燃风险。
当你搜索“Titan-X 和 Solvo-Clean 是否安全”时,向量数据库会根据关键词匹配到以下内容:
- “Titan-X 是食品级安全的清洁剂。”
- “Solvo-Clean 是环保、可降解的溶剂。”
- “两种产品均符合 Class 9 非危险品运输标准。”
由于这些文档充满了“安全”、“环保”、“批准”等正面词汇,LLM 会愉快地告诉你:“是的,它们很安全,甚至可以用于食品表面。” RAG 检索到了含有产品名称的“营销废话”,却因为语义不直接相关,漏掉了那条不含产品名称、只含化学类别的“安全准则”。

为了防止这种“一本正经胡说八道”的危险行为,我们引入了 Graph RAG 的本体映射。我们不再让 AI 只是简单地找文字,而是让它进行属性继承分析。
RAG 失败案例 3:实体歧义陷阱(The Entity Ambiguity Trap / Polysemy)
当同一个词汇在不同语境下代表不同含义时(即多义词,Polysemy),基于语义相似度的 RAG 往往会“张冠李戴”,导致信息混淆和事实性错误。假设你是一名金融分析师,向 AI 提出问题:
“捷豹(Jaguar)在第三季度的表现如何?”
这个看似简单的问题,却隐藏着一个巨大的陷阱:
- 文档 A(目标):“捷豹路虎(Jaguar Land Rover)第三季度营收增长 12%,主要得益于强劲的 SUV 销量。”
- 文档 B(干扰):“亚马逊地区的捷豹(动物)种群在第三季度展现出高超的捕猎能力,得益于有利的天气。”
- 文档 C(干扰):“macOS 10.2 ‘Jaguar’ 系统的性能基准在最新的第三季度补丁中显著提升。”
当你向传统 RAG 查询时,由于“Jaguar”、“表现(perform)”和“Q3”在所有文档中都出现,向量搜索会一股脑地将这些文档都检索出来。
LLM 会把来自汽车公司、动物和操作系统的“性能”数据混为一谈,可能会生成一个荒谬的答案:“捷豹(动物)在亚马逊地区的捕猎表现带动了捷豹路虎的营收增长……”—— 对于金融分析师而言,这简直是 50% 的“有效信息污染”。
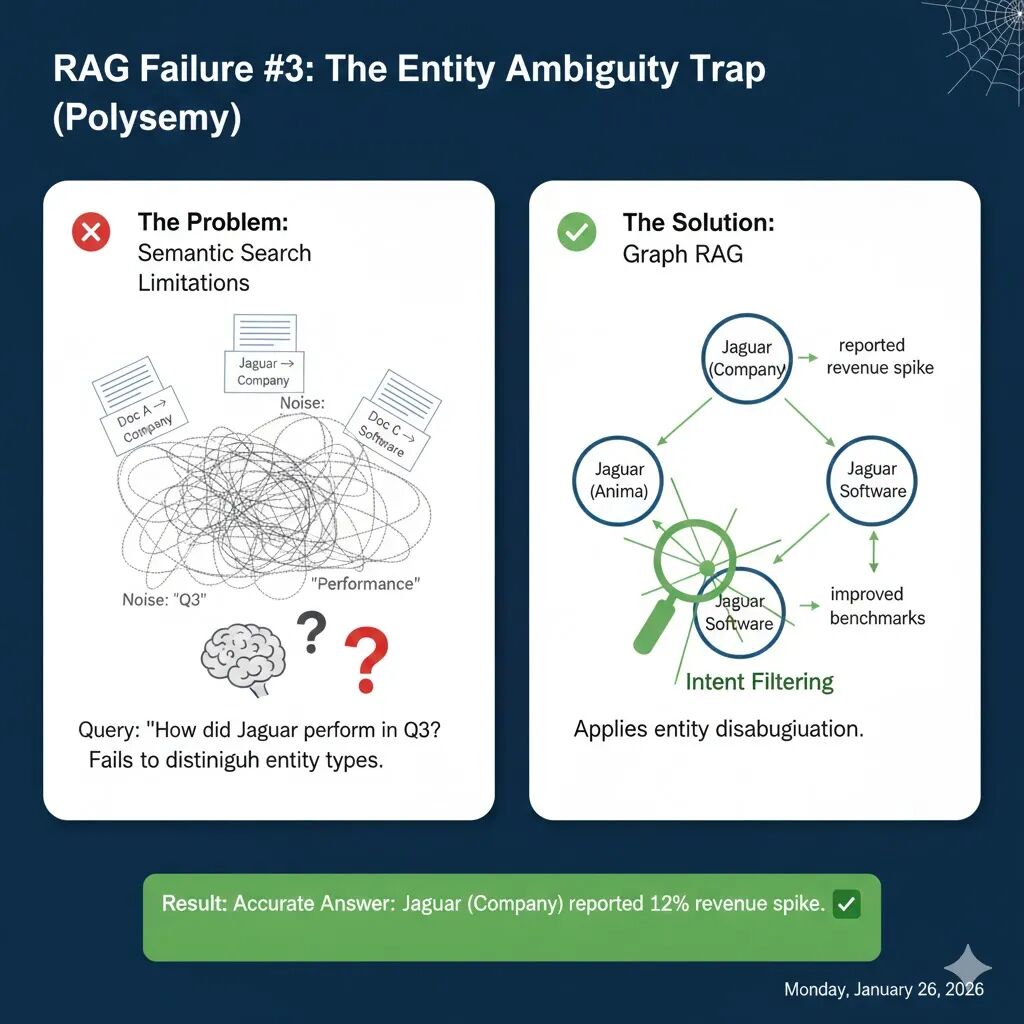
为了避免这种令人啼笑皆非的错误,我们必须在数据摄入阶段就对实体进行“正名”,并结合用户意图进行过滤。这就是 Graph RAG 的实体消歧(Entity Disambiguation) 核心能力。
RAG 失败案例 4:矛盾信息冲突(The Contradictory Information Failure)
当知识库随着时间演进,旧文档(如 2021 版手册)与新政策(如 2024 版备忘录)并存于向量数据库时,RAG 往往会陷入自我矛盾的怪圈。
想象一下,一名员工询问 AI 助手:
“我现在每周可以居家办公几天?”
在你的向量数据库里,静静躺着三份文档:
- 文档 A (2021 年) :为了应对疫情,员工每周可享受 5 天 远程办公。
- 文档 B (2023 年) :随着混合办公推行,远程额度缩减至 2 天。
- 文档 C (2024 年) :最新行政指令,所有远程权限取消,0 天(必须回办公室)。
当你搜索“远程办公天数”时,这三份文档在语义上几乎完全一致。向量检索会把它们一股脑全部喂给 LLM。
LLM 看到三个不同的数字,通常会给出一种极其“保守”且无用的回答:“根据 2021 年规定是 5 天,但 2023 年说是 2 天,最近的 2024 年备忘录又说是 0 天。建议你咨询 HR 确认。”
对于用户来说,这种回答不仅没有解决问题,反而增加了困惑。RAG 在这里失败了,因为它无法区分什么是“事实”,什么是“历史”。

要解决版本冲突,AI 必须具备“时间感”。我们不能只存储“发生了什么”,还必须存储“什么时候有效”。
RAG 失败案例 5:隐式关系幻觉(The Implicit Relationship Hallucination)
在向量搜索的世界里,“靠得近”(语义相关)并不等同于**“有关系”**(逻辑真实)。
假设一家投资机构询问 AI 助手:
“特斯拉(Tesla)和丰田(Toyota)有电池合作伙伴关系吗?”
在你的向量数据库中,可能存在以下三类信息:
- 文档 A (确凿事实) :松下(Panasonic)已签署合同,向特斯拉供应 4680 电池。
- 文档 B (确凿事实) :丰田正在独立研发固态电池技术。
- 文档 C (幻觉陷阱) :“在 2024 年全球能源峰会上,特斯拉、丰田和三星的高管齐聚一堂,共同探讨电池行业监管趋势。”
当你搜索“特斯拉 丰田 电池 合作”时,向量检索会因为文档 C 同时包含了这三个关键词而将其判定为“高度相关”。
LLM 看到特斯拉和丰田在同一个段落里讨论电池,便极易脑补出一段不存在的姻缘:“根据资料,特斯拉和丰田在 2024 年能源峰会上就电池领域展开了深度讨论,暗示双方在电池监管和市场趋势上有紧密的合作关系。”
RAG 仅仅因为实体在物理位置上的“共同出现(Co-occurrence)”,就错误地推断出了“逻辑关联”。在严谨的商业调研中,这种“暗示”或“模糊”的回答是极度危险的。
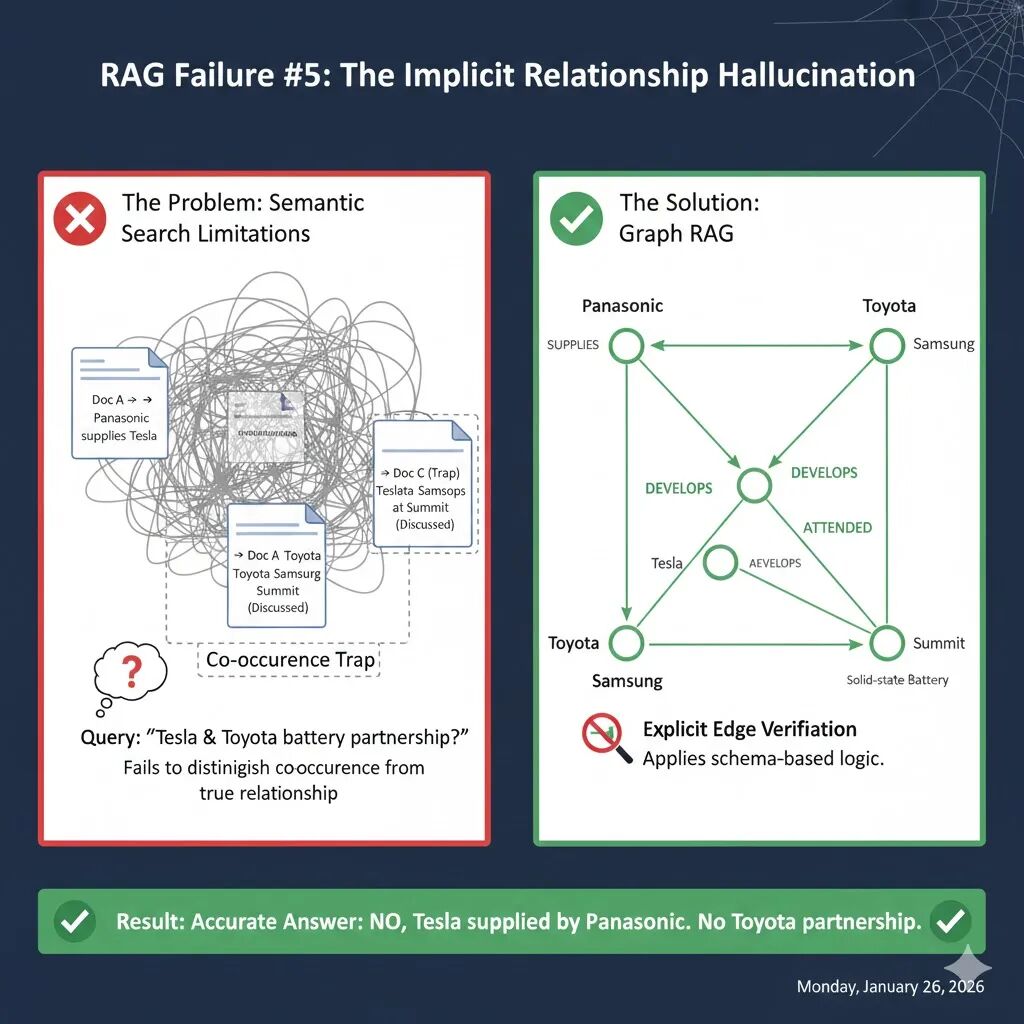
为了斩断这种“无中生有”的联系,Graph RAG 引入了显式图谱约束。它不再问“这两个词近吗?”,而是问“这两个点之间有连线吗?”。
RAG 失败案例 6:聚合盲区(The Aggregation Blindness)
当用户问出“我们有多少个供应商?”或者“清单里一共有多少项内容?”时,标准的向量检索 RAG 几乎注定会给出错误的答案。
假设你正在审计“Zeus 项目”的 Tier-1 供应商数量。你的数据库里散落着以下文档:
- 文档 1 (发票) :向 Apex Corp 支付了 Zeus 项目的钢梁费用。
- 文档 2 (邮件) :提到的 Apex Inc 延迟了 Zeus 项目的涂层交付。
- 文档 3 (报告) :Beta-Tech 正式成为 Zeus 项目的芯片供应商。
- 文档 4 (物流) :Gamma Logistics 负责 Zeus 项目的所有运输。
由于向量数据库的检索机制,它在处理这类聚合问题时会遭遇双重打击:
- Top-K 检索的“截断”效应:如果你的供应商分布在 50 份文档中,而你的检索器只抓取相关性最高的 5 份(k=5),那么剩下的 45 个供应商在模型眼里根本不存在。
- 重复计算陷阱:在语义向量空间,“Apex Corp”和“Apex Inc”非常接近,检索器会把它们都找出来。但 LLM 往往无法识别它们其实是同一家公司,从而导致重复计数。
如果你设置 k=2,LLM 只能看到文档 1 和 2。它会告诉你:“Zeus 项目有 2 个供应商:Apex Corp 和 Apex Inc。”实际有 3 个(Apex、Beta-Tech、Gamma),且 Apex 被重数了。
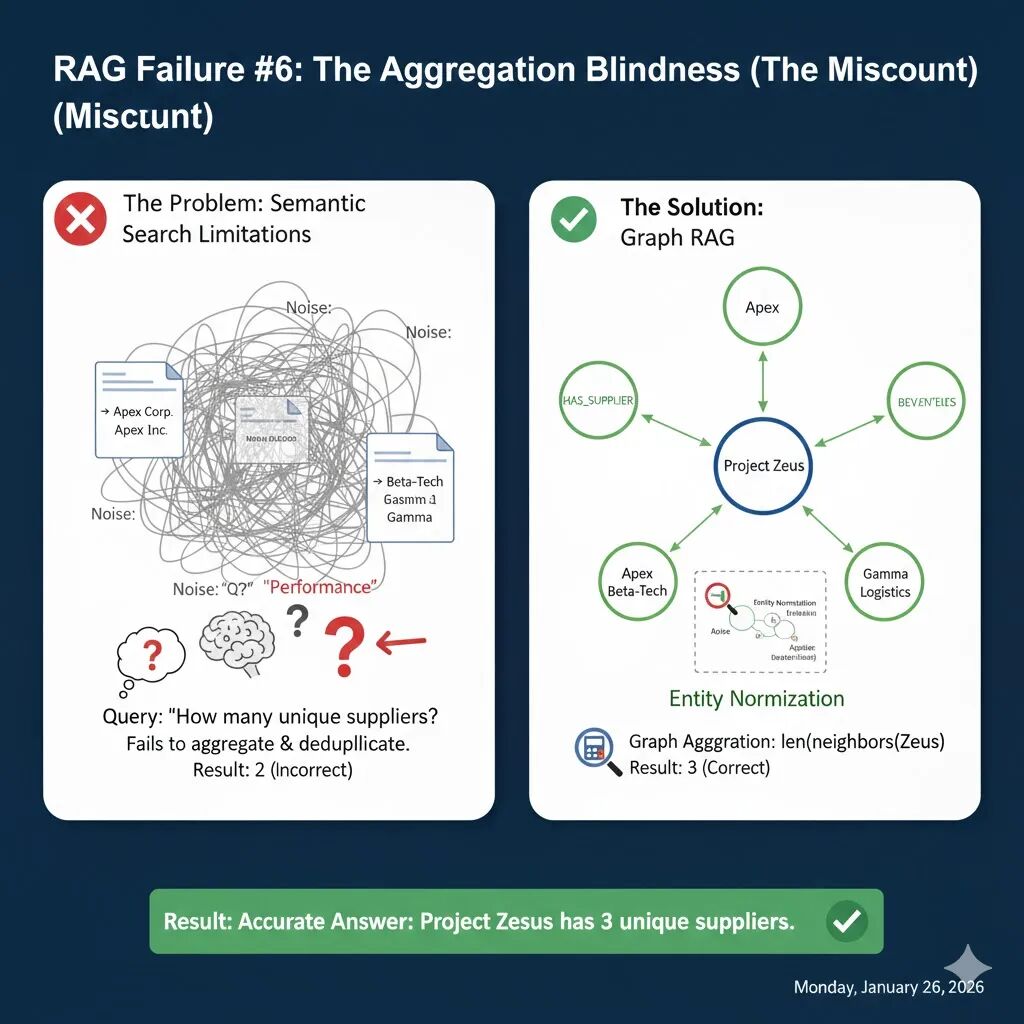
解决聚合问题的关键不在于提高 LLM 的算术水平,而在于改变数据的组织结构。Graph RAG 通过将零散的文本转化为结构化的节点,从根本上解决了“数不清”的问题。
失败案例 7:碎片化证据缺失(The “Scattered Evidence” Fragment / Low Recall)
当用户要求提供一个“完整清单”时,基于向量检索的 RAG 往往会因为窗口限制而导致严重的漏报。
假设你正在审查“Model-X 工业机器人”的安全特性,向 AI 助手提问:
“请列出 Model-X 的所有安全特性和认证。”
在 Model-X 的技术手册中,相关信息并不是集中在一起的,而是分散在不同的章节:
- 第 1 页 (结构):提到使用了 钛合金底盘。
- 第 15 页 (电路):提到具备 浪涌保护 功能。
- 第 22 页 (视觉):提到使用 Lidar 避障。
- 第 40 页 (紧急情况):提到后端配有 红色急停按钮。
- 第 55 页 (合规):提到通过了 ISO-9001 认证。
标准 RAG 依赖于 top_k 参数(通常设置为 3 到 5)。这意味着无论你的文档库有多大,检索器每次只能给 LLM 提供最重要的几块碎片。
结果:如果你设置 k=2,检索器可能会抓取相关性最高的“结构”和“合规”两页。LLM 的回答:“Model-X 的安全特性包括钛合金底盘和 ISO-9001 认证。”
LLM 表现得非常自信,但它实际上漏掉了 60% 的关键信息。对于安全审计、法律合规或医疗诊断等场景,这种漏报可能是灾难性的。
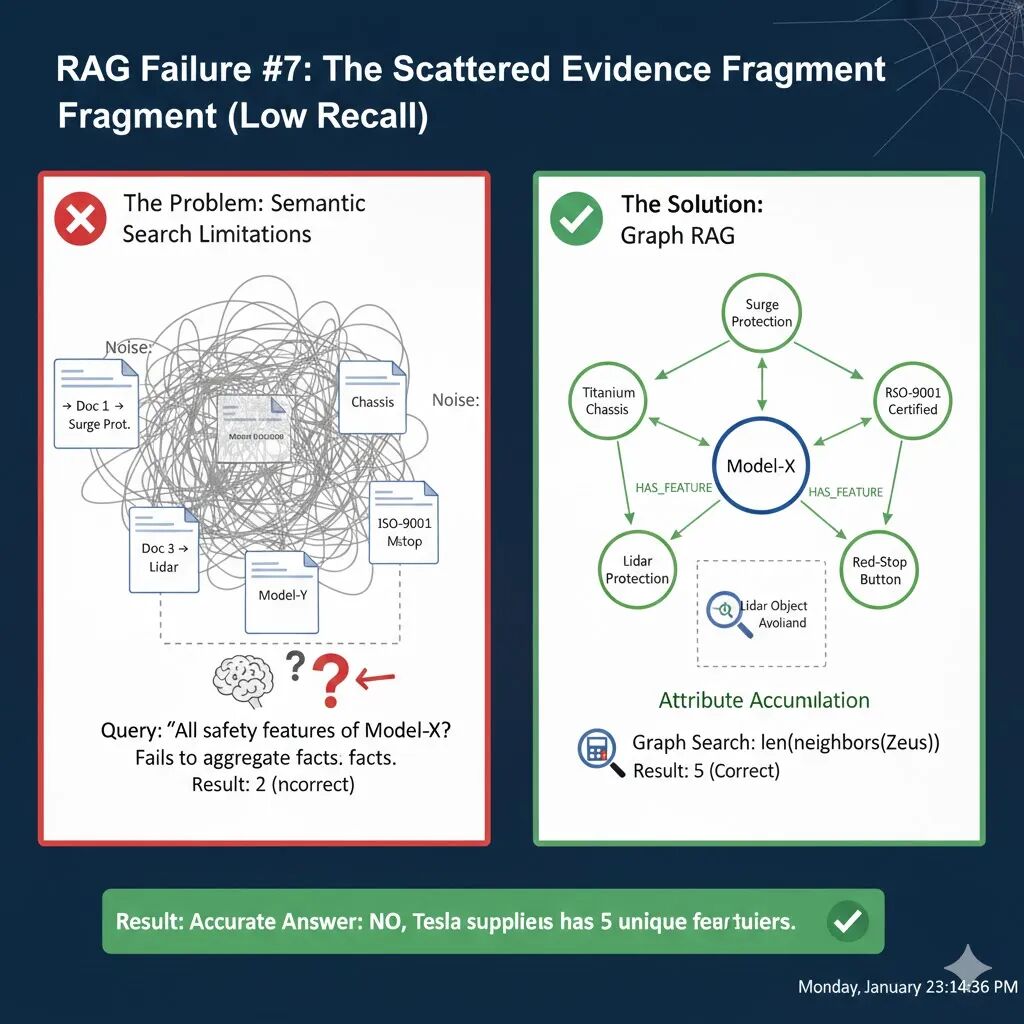
要解决碎片化信息的问题,我们不能寄希望于不断调大 top_k(这会导致上下文冗余和成本激增),而应该在知识摄入阶段就将这些“散落的珍珠”穿成一串。
RAG 失败案例8:结构化层级缺失(The Structural Hierarchy Failure)
当信息以“层层嵌套”的方式分布在不同文档中时,标准的向量检索 RAG 往往会“只见树木,不见森林”。
想象一下,你是一名工程师,正在查看一台名为“Zeus-X”的超级计算机的维护手册,你提问:
“请溯源 Qubit Lattice(比特晶格)的完整系统层级。”
在浩如烟海的 PDF 库中,数据被物理切碎并分布在不同的章节:
- 文档 1 (顶层) :Zeus-X 超级计算机由 核心处理单元(CPU) 和冷却阵列组成。
- 文档 2 (中层) :在核心处理单元内部,安装了 量子芯片组(Quantum Chipset)。
- 文档 3 (底层) :量子芯片组承载着精密的 Qubit Lattice(比特晶格) 组件。
向量检索是基于“语义相似度”的。当你搜索“Qubit Lattice”时,检索器会非常精准地找到文档 3,可能还会找到文档 2。但它几乎不可能找到文档 1。
因为“Zeus-X”和“Qubit Lattice”这两个词在物理上隔得太远,在语义向量空间中也缺乏直接关联。 LLM 只能告诉你:“Qubit Lattice 在量子芯片组里,芯片组在核心处理单元里。”它漏掉了最关键的根节点 —— Zeus-X 超级计算机。
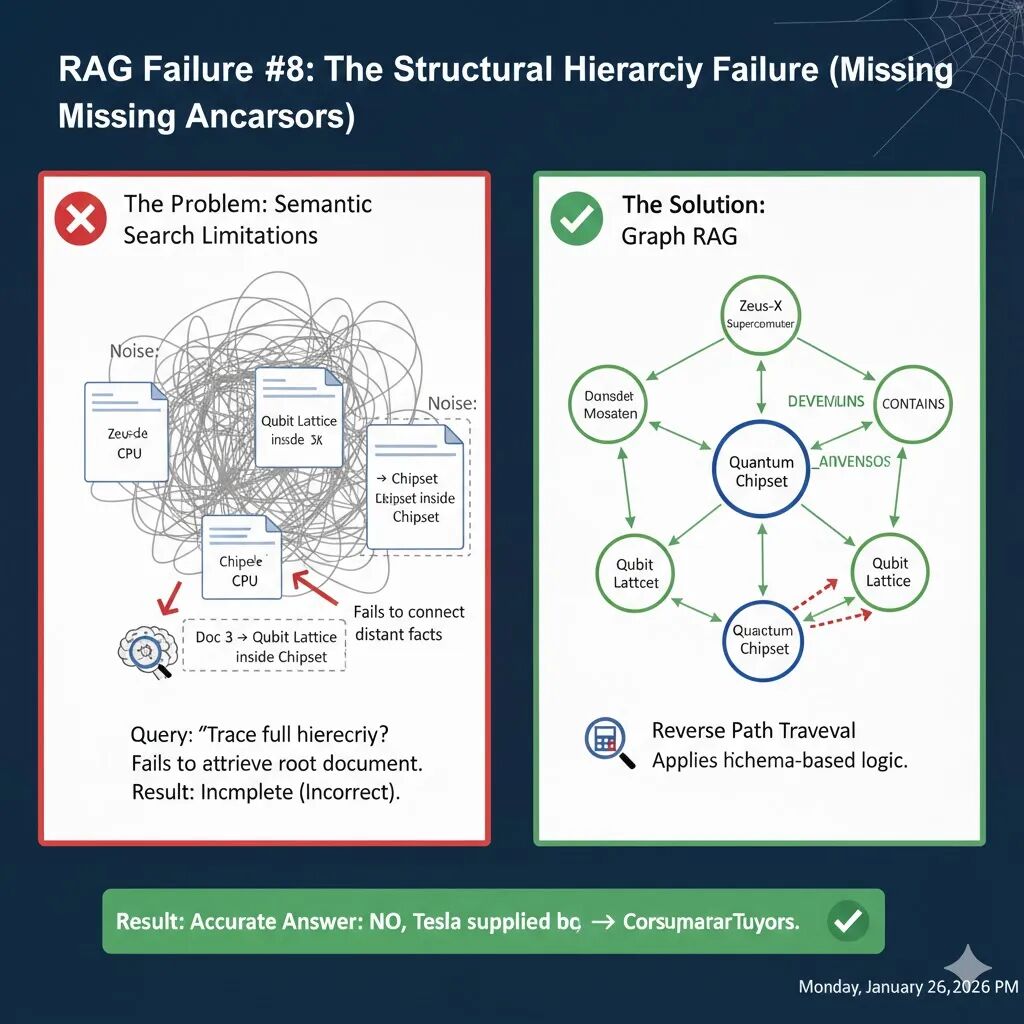
要解决这种“俄罗斯套娃”式的信息丢失,我们不能只靠文本匹配,必须建立一套父子关系导航系统。
失败案例 9:方向性反转(The Directionality Reversal)
在法律合同、企业并购和股权穿透等场景中,“A 拥有 B”和“B 拥有 A”是截然不同的事实。然而,对于传统的 RAG 来说,这两者往往长得“一模一样”。
假设你正在调查两家公司的隶属关系,询问 AI 助手:
“Stratos Global 拥有 Novacorp,还是反过来的?”
你的数据库中有这样几份文档:
- 文档 1 (事实) :“Stratos Global 曾是一家独立实体,现在则在巨头 Novacorp 集团的伞下运营。”
- 文档 2 (干扰) :“Stratos Global 最近表现活跃,通过收购初创公司 TinyAI 扩大了版图。”
- 文档 3 (混淆) :“Novacorp 与 Stratos Global 在伦敦共用一个总部。”
向量搜索的本质是计算“语义距离”。在向量空间里,“A 拥有 B”和“B 拥有 A”的距离近乎为零,因为它们包含完全相同的关键词(Stratos, Novacorp, Owns)。
检索器会把上述三份文档都丢给 LLM。LLM 看到文档 2 中提到“Stratos 正在收购”,同时又看到文档 1 中 Stratos 和 Novacorp 连在一起。由于缺乏明确的方向约束,LLM 极易产生幻觉,回答成:“Stratos Global 正在通过收购 Novacorp 来扩张。”
LLM 像处理“词袋(Bag of Words)”一样处理上下文,尤其在面对被动语态(“under the umbrella of”)或专业术语时,它经常会把主体(Subject)和客体(Object)搞反。
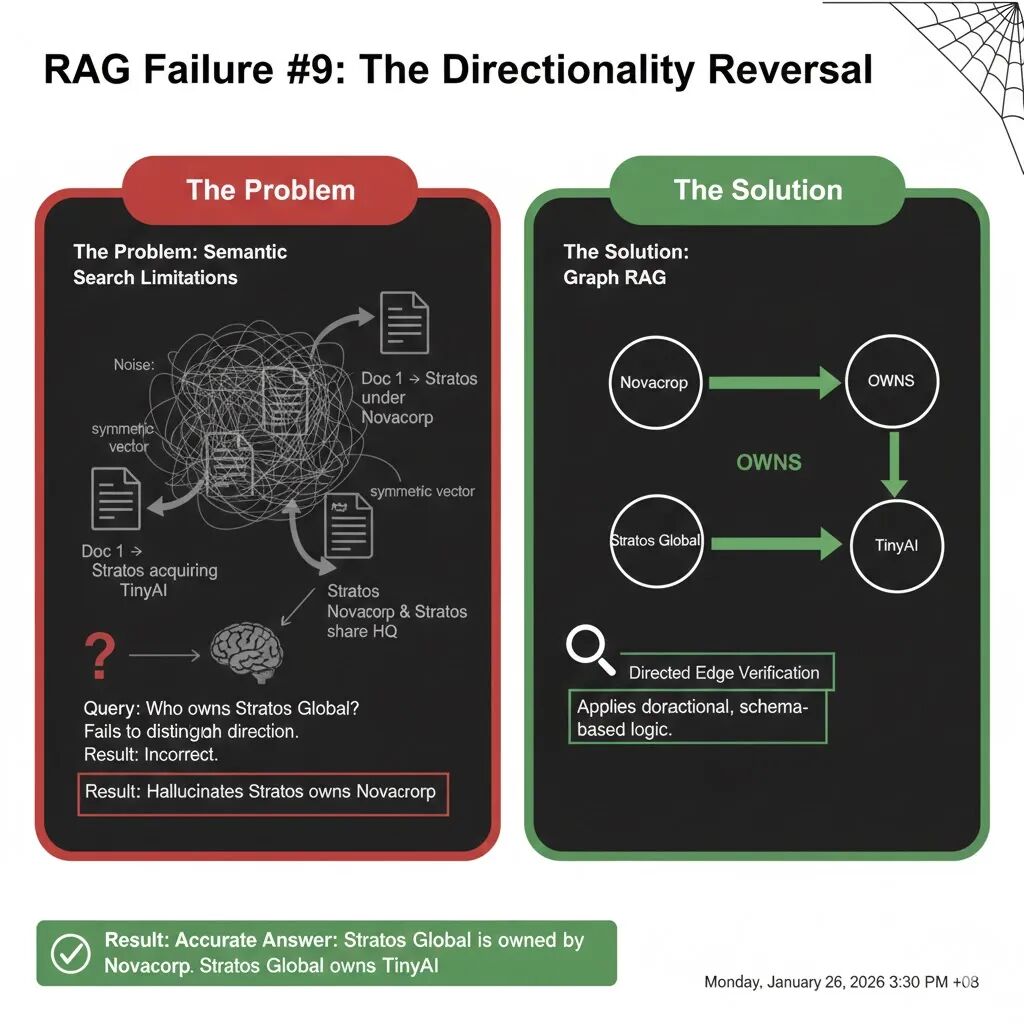
要解决方向性问题,我们不能仅仅依靠语义相似度,必须引入语义角色标注(Semantic Role Labeling),并将其强制转化为有方向的箭头。
在数据摄入阶段,我们不再是简单地切片,而是强迫 LLM 将文本转化为统一的 “父节点 | 拥有 | 子节点” 格式:
- 处理文档 1 时:识别出 Novacorp 是母体,映射为
(Novacorp) --[OWNS]--> (Stratos Global)。 - 处理文档 2 时:识别出 Stratos 是买方,映射为
(Stratos Global) --[OWNS]--> (TinyAI)。
在知识图谱中,每一条边都是有向的。A -> B 永远不等于 B -> A。这种结构化的约束在数据存入的那一刻,就从物理上封死了方向反转的可能。
RAG 失败案例 10:公共邻居交集缺失(The “Common Neighbor” Intersection Gap)
在许多复杂领域,答案并不直接写在某句话里,而是隐藏在两个事实的交集中。即便你的 RAG 把所有相关文档都找齐了,LLM 往往也无法完成那临门一脚的逻辑合成。
“Zenthorax 和 Vira-X 之间是否存在特定的相互作用风险?”
RAG 系统非常精准地检索到了所有相关信息:
- 文档 1 (药理学) :Zenthorax 是一种强效抗真菌剂,它是 CYP3A4 酶的强效抑制剂。
- 文档 2 (药代动力学) :Vira-X 是一种降脂药,它主要通过 CYP3A4 酶进行代谢。
- 文档 3 (市场新闻) :Zenthorax 和 Vira-X 都是目前药房最畅销的 FDA 批准药物。
即使你把这三份文档全部塞进 LLM 的上下文窗口,失败依然大概率发生。
为什么? 因为 LLM 倾向于寻找显性陈述。文档 3 明确地把两个药名放在了一句话里(“都是畅销药”),LLM 会像抓救命稻草一样抓住这个表层联系。而文档 1 和文档 2 虽然都提到了 CYP3A4,但它们是分开描述的。LLM 很难自发地在脑中建立起逻辑链:药物 A 抑制酶 X + 药物 B 依赖酶 X 代谢 = 药物 B 会在体内蓄积中毒。
AI 会自信地回答:“这两者都是 FDA 批准的常见药物,没有提到的相互作用风险。”这是一种可能导致病人肝损伤或中毒的致命组合。
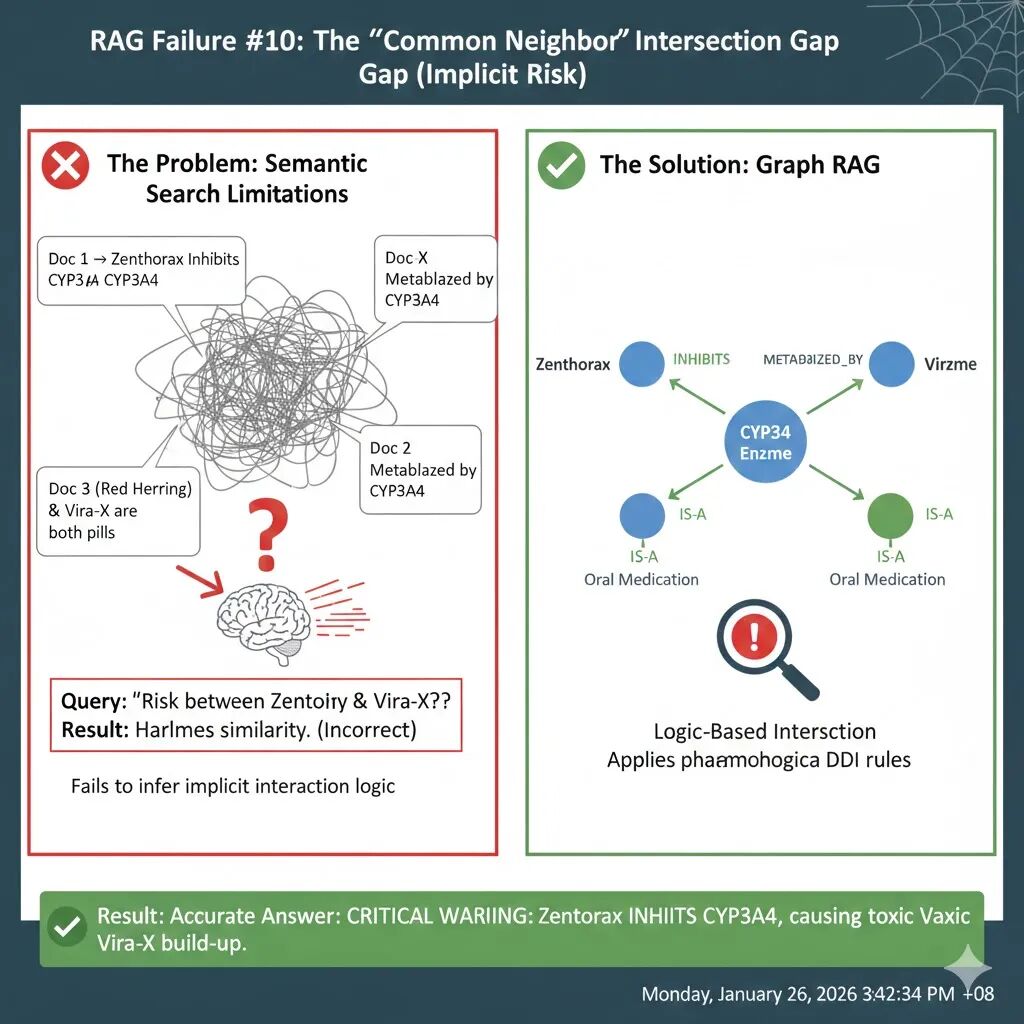
解决“交集盲区”的关键在于:不要让 LLM 在混乱的段落中玩逻辑拼图,而是将知识拆解为节点和边,让系统自动寻找它们的“公共邻居”。
AG 失败案例 11:否定与缺失的盲区(The Negation & Absence Failure)
向量搜索从根本上是加性的。它擅长找到存在的东西,但很难找到缺失的东西。如果你问“哪些产品不含花生?”,向量嵌入会专注于“花生”这个词。检索器会返回大量包含“花生”的文档,而那些真正安全的选项(可能根本没提花生)反而因为相关性低而被忽略。
假设用户患有花生过敏,他向 AI 助手提问:
“哪些谷物棒对花生过敏者是安全的?”
你的产品数据库中有以下信息:
- 文档 1 (Nutty-Crunch):“Nutty-Crunch 能量棒富含蛋白质。成分:燕麦、花生、蜂蜜。”
- 文档 2 (Cocoa-Delight):“Cocoa-Delight 是一款巧克力零食。成分:燕麦片、可可脂、杏仁、糖。”
- 文档 3 (Berry-Blast):“Berry-Blast 是一款水果棒。成分:蔓越莓干、小麦、大豆卵磷脂。”
- 文档 4 (警告):“Berry-Blast 在一个加工花生的工厂中生产。”
检索器收到“花生过敏”的查询时,会优先抓取包含“花生”这个词的文档。
- 关键词匹配偏见:检索器会高度匹配“花生”这个词,导致 Doc 1 和 Doc 4 被优先检索。
- 语义相似度陷阱:Doc 2 (Cocoa-Delight) 虽然是安全的,但因为它没有提及“花生”,其与“花生过敏”查询的语义相似度会很低,从而被检索器忽略。
- LLM 的困境:LLM 收到上下文后,会看到满篇都是关于“花生”的警告和含有花生的产品。它没有看到任何“不含花生”的显性声明,因此无法推荐安全产品。
AI 回答:“根据上下文,Nutty-Crunch 含有花生,Berry-Blast 在加工花生的工厂生产。因此,两者对花生过敏者都不安全。”(用户问的是安全的,AI 只回答了不安全的)。
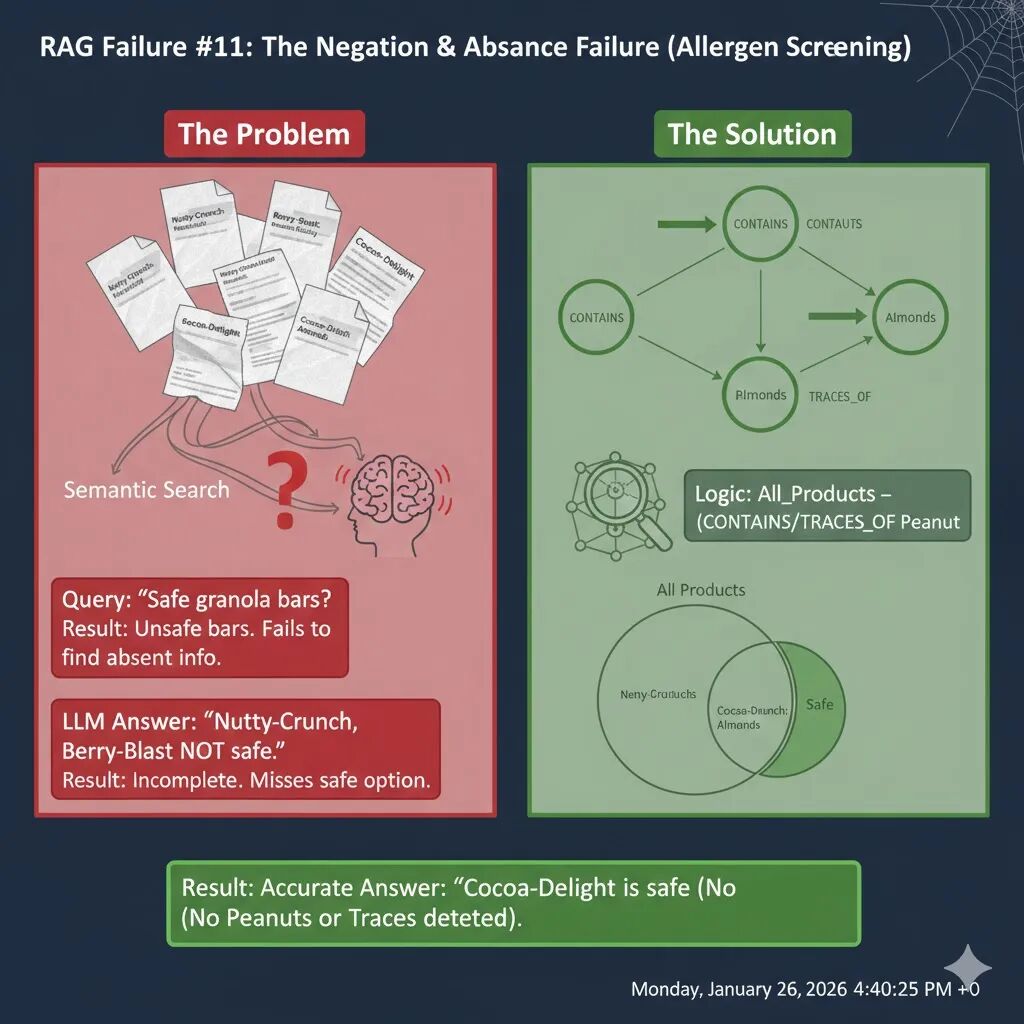
解决“否定与缺失”问题的关键在于:将所有的产品、成分和风险关系明确地构建成图谱,然后进行集合操作。
RAG 失败案例 12:同义词与内部术语断层(The Synonymy & Jargon Disconnect)
在公司内部,我们经常会给项目起代号,或者使用极其专业、只有本部门才懂的缩写。然而,标准的大模型(LLM)和嵌入模型(Embedding Models)主要是用公开的互联网数据训练的。它们知道什么是“结账服务”,但它们可能永远不知道你们公司那个叫 Project Ledger-X 的系统其实就是“结账服务”。
假设你是一名运维工程师,在处理紧急故障时向 AI 助手询问:
“Checkout Service(结账服务)目前的错误率是多少?”
你的日志库里塞满了最实时的信息:
- 日志 A (罪魁祸首)
[System Log] Service: Cart-Flow-V2 | Status: CRITICAL | Error Rate: 15% - 日志 B (干扰项)
[Dev Chat] Checkout UI 团队正在更新按钮颜色,无功能变更。
即使你把这几份日志全部塞进 LLM 的上下文窗口,由于语义断层,它依然会翻车。
- 向量检索的盲区:在通用向量空间里,“Checkout Service”和“Cart-Flow-V2”的距离可能非常遥远,检索器可能根本不会把日志 A 排在前面。
- LLM 的严谨性陷阱:LLM 看到日志 B 提到了“Checkout”,于是它锁定在这个干扰项上。尽管日志 A 就在它眼前,但因为它不知道
Cart-Flow-V2就是Checkout Service的代码代号,为了不乱猜,它会告诉你:“没有找到结账服务的错误信息。”
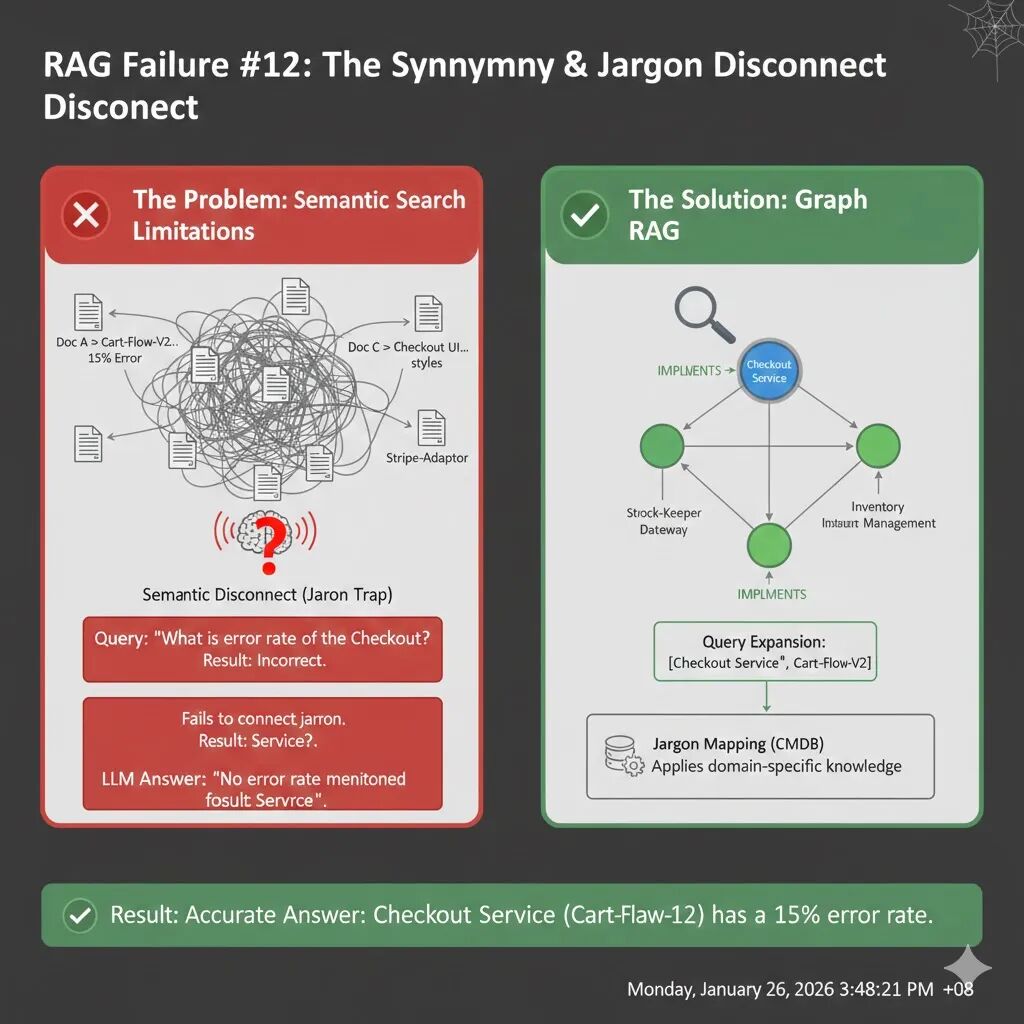
解决“黑话”问题的关键不在于重新训练模型(成本太高且时效性差),而是在 RAG 流程中引入一个内部知识翻译层。
RAG 失败案例 13:结构性影响盲区(The Structural Influence Blindness)
传统的 RAG 擅长从文本中提取事实(例如,“谁是经理?”)。但当问题涉及到结构性模式时(例如,“谁是信息流的瓶颈?”),即便你把所有文档都给它,它也无法理解其中蕴含的复杂网络关系。LLM 倾向于相信显性的职称(如“副总裁”、“项目经理”),而忽略了那些实际连接不同团队的“隐形影响者”。
假设你正在评估“Omega 项目”的风险,向 AI 助手提问:
“Project Omega 项目中,谁是信息流的单一故障点(瓶颈)?”
你的数据包括:
- 文档 1 (组织架构图):Alice 是高级项目经理,负责战略。
- 文档 2 (组织架构图):Bob 是工程副总裁,负责审批预算。
- 文档 3-8 (电子邮件日志):
- 开发团队(Dave, Eve)的邮件都发给 Carol。
- QA 团队(Frank)的 bug 报告都发给 Carol。
- 管理层(Alice, Bob)的进度和预算咨询都发给 Carol。
- 关键事实:Alice 从不直接联系 Dave/Eve,Bob 从不直接联系 Frank。
即便你把所有这些文档都作为上下文提供给 LLM,它依然很可能会给出错误的答案。
- 语义偏见:LLM 会优先处理组织架构图中明确定义的“权威”和“责任”。它看到“Alice 是项目经理”,就会理所当然地认为她是瓶颈。
- 模式识别缺失:LLM 能够阅读所有邮件,但它很难“聚合”这些零散的交互,识别出“Carol 被所有人联系,且负责向高层汇报”这种隐含的结构模式。对于 LLM 而言,所有的邮件日志可能只是一堆“噪音”。
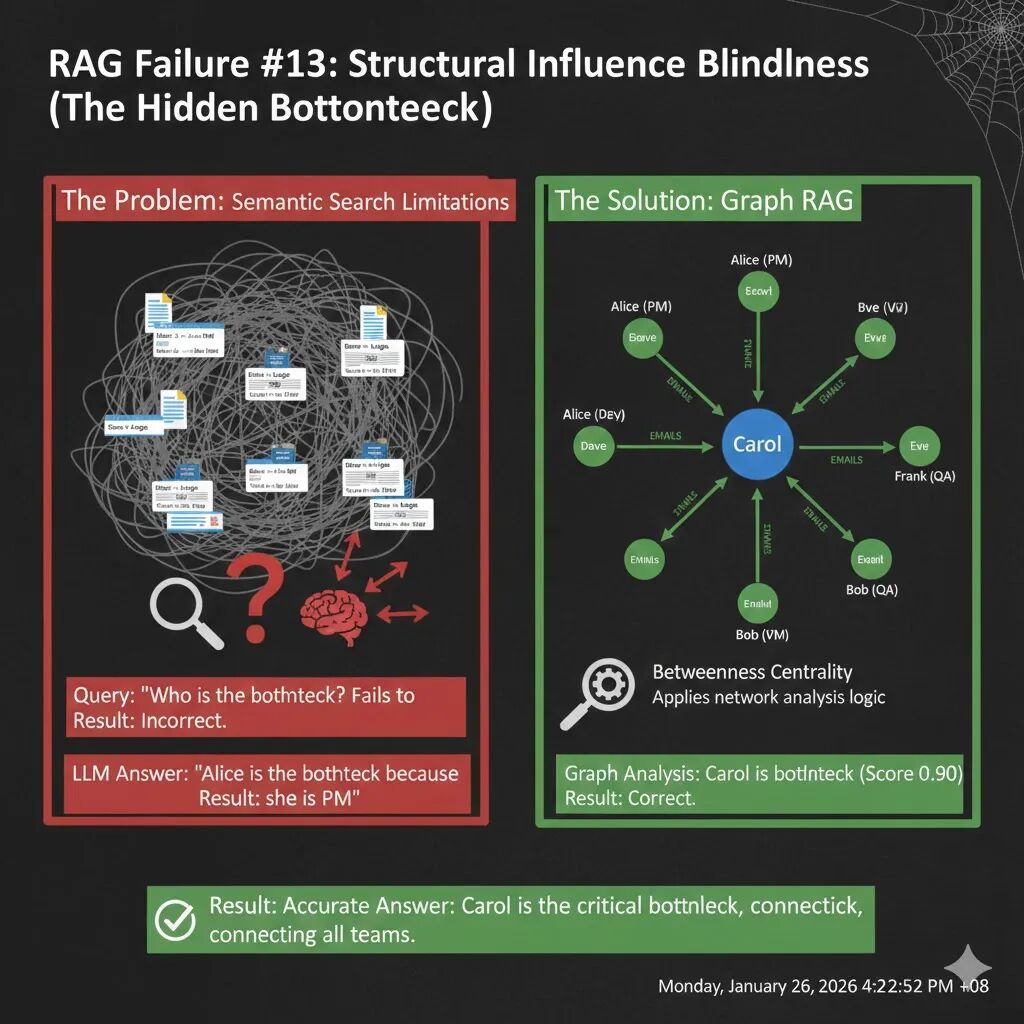
解决“结构性影响盲区”的关键在于:将非结构化的沟通数据转化为结构化的网络,然后用数学方法来识别模式。
RAG 失败案例 14:时间序列错乱(The Temporal Sequence Scramble)
大型语言模型(LLM)对时间的概念非常弱。它们容易受到近因偏见(Recency Bias,偏爱最后读到的信息)或呈现偏见(Presentation Bias,认为文本在提示中的顺序就是时间顺序)的影响。
在 RAG 中,检索器是根据相关性分数而不是时间戳来排序文档的。当你询问“什么导致了服务器崩溃?”时,RAG 会把“服务器崩溃”的日志放在最前面(因为它最相关),而把“根本原因”的日志放在最后。LLM 在阅读时,会先看到结果再看到原因,因此常常无法正确地重建时间线。
假设你正在分析一起网络安全事件,询问 AI 助手:
“在主数据库加密之前,立即触发的事件是什么?”
你的日志数据显示了完整的攻击链,但顺序是混乱的:
- 08:00 AM:管理员点击了网络钓鱼邮件。
- 08:15 AM:恶意软件 ‘Silent-Bot’ 在后台安装。
- 08:45 AM:检测到特权升级。
- 09:00 AM (目标事件):攻击者启动了主数据库加密。
- 09:30 AM:屏幕上显示勒索信息。
即使你把所有这些日志都作为上下文提供给 LLM,它依然很可能会搞混时间顺序。
- 检索器的盲点:向量检索器会根据语义相关性来排序。像“勒索信息”和“数据库加密”这样的词语在语义上高度相关,会被排在前面。而“网络钓鱼邮件”可能因为与“数据库加密”语义距离较远,反而被排在后面。
- LLM 的逻辑缺陷:当 LLM 接收到这些乱序的日志时,它会倾向于将上下文中最接近的两个事件联系起来。它可能看到“勒索信息”紧接着“数据库加密”出现,就误认为“勒索信息触发了加密”。它会忽略时间戳,因为文本的邻近性压倒了时间逻辑。
AI 回答:“在主数据库加密(09:00:00)之前,立即触发的事件是 09:30:00 的 UI 警告,即勒索信息显示在屏幕上。”(颠倒了因果)。勒索信息是加密的结果,而不是原因。真正的触发事件是“特权升级”。
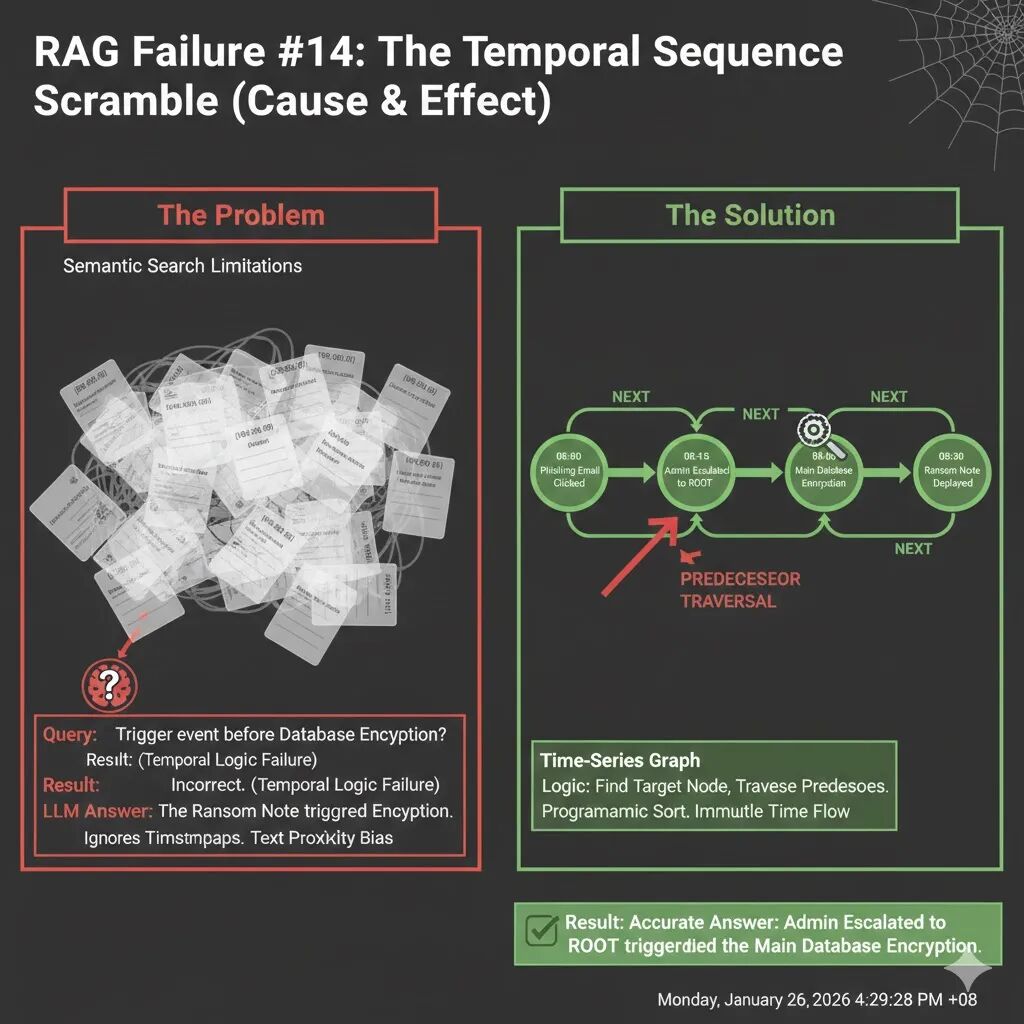
解决“时间序列错乱”的关键在于:将每个事件视为一个节点,将时间关系明确地编码为有向边,然后进行图遍历。
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线科技企业深耕十二载,见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。我们整理出这套 AI 大模型突围资料包:
- ✅ 从零到一的 AI 学习路径图
- ✅ 大模型调优实战手册(附医疗/金融等大厂真实案例)
- ✅ 百度/阿里专家闭门录播课
- ✅ 大模型当下最新行业报告
- ✅ 真实大厂面试真题
- ✅ 2026 最新岗位需求图谱
所有资料 ⚡️ ,朋友们如果有需要 《AI大模型入门+进阶学习资源包》,下方扫码获取~
① 全套AI大模型应用开发视频教程
(包含提示工程、RAG、LangChain、Agent、模型微调与部署、DeepSeek等技术点)
② 大模型系统化学习路线
作为学习AI大模型技术的新手,方向至关重要。 正确的学习路线可以为你节省时间,少走弯路;方向不对,努力白费。这里我给大家准备了一份最科学最系统的学习成长路线图和学习规划,带你从零基础入门到精通!
③ 大模型学习书籍&文档
学习AI大模型离不开书籍文档,我精选了一系列大模型技术的书籍和学习文档(电子版),它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。
④ AI大模型最新行业报告
2025最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。
⑤ 大模型项目实战&配套源码
学以致用,在项目实战中检验和巩固你所学到的知识,同时为你找工作就业和职业发展打下坚实的基础。
⑥ 大模型大厂面试真题
面试不仅是技术的较量,更需要充分的准备。在你已经掌握了大模型技术之后,就需要开始准备面试,我精心整理了一份大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

以上资料如何领取?

为什么大家都在学大模型?
最近科技巨头英特尔宣布裁员2万人,传统岗位不断缩减,但AI相关技术岗疯狂扩招,有3-5年经验,大厂薪资就能给到50K*20薪!

不出1年,“有AI项目经验”将成为投递简历的门槛。
风口之下,与其像“温水煮青蛙”一样坐等被行业淘汰,不如先人一步,掌握AI大模型原理+应用技术+项目实操经验,“顺风”翻盘!

这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。

以上全套大模型资料如何领取?


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 25
25 0
0- 0



 已为社区贡献225条内容
已为社区贡献225条内容

所有评论(0)