AI大模型之旅——MCP深入理解
文章目录
AI大模型之旅之MCP深入理解
一、基础概念
1.1 什么是MCP?
MCP (Model Context Protocol,模型上下文协议),2024年11月底,由Anthropic推出的一种开放标准,旨在统一大型语言模型(LLM)与外部数据源和工具之间的通 信协议。MCP的主要目的在于解决当前Al模型因数据孤岛限制而无法充分发挥潜力 的难题,MCP使得AI应用能够安全地访问和操作本地及远程数据,为AI应用提供了 连接万物的接口
使用 MCP,您可以:
- 构建为 LLMs 提供工具和数据的服务器
- 将这些服务器连接到兼容 MCP 的客户端
- 通过自定义功能扩展 LLM 的能力
1.2 MCP与Function Calling的区别
| 类别 | MCP | Function Calling |
|---|---|---|
| 定义 | Model Context Protocol,模型上下文协议是一个标准协议,使AI模型与API无缝交互 | Function Calling是Al模型调用函数的机制 |
| 性质 | 协议 | 功能 |
| 范围 | 通用(多数据源、多功能) | 特定场景(单一数据源或功能) |
| 目标 | 统一接口,实现互操作 | 扩展模型能力 |
| 实现 | 基于标准协议 | 依赖特定模型 |
| 开发复杂度 | 低:通过统一协议实现多源兼容 | 高:需要为每个任务单独开发函数 |
| 灵活性 | 高:支持动态适配和扩展 | 低:功能扩展需要额外开发 |
1.3 工作原理
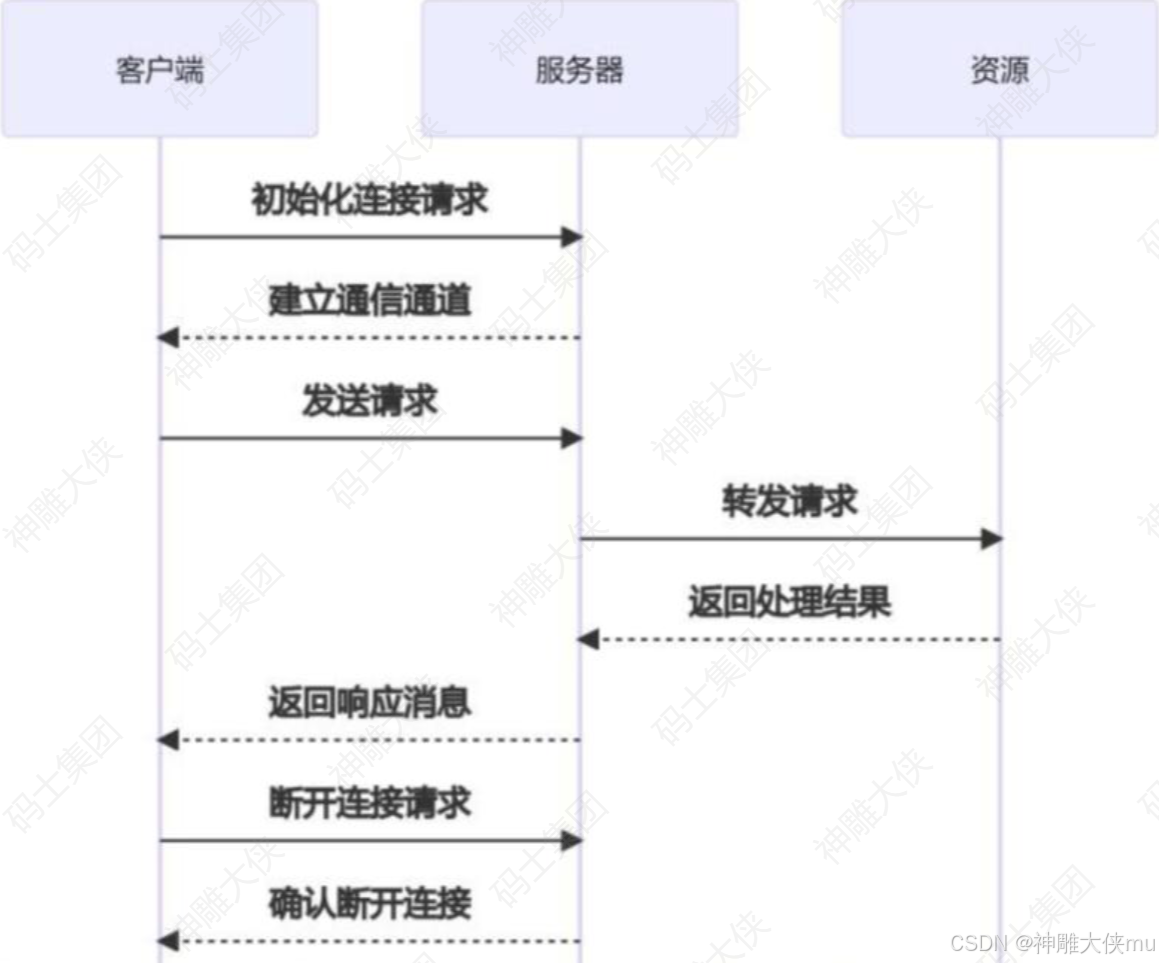
MCP协议采用了一种独特的架构设计,它将LLM与资源之间的通信划分为三个主要 部分:客户端、服务器和资源。客户端负责发送请求给MCP服务器,服务器则将这些请求转发给相应的资源。这种分层的设计使得MCP协议能够更好地控制访问权限,确保只有经过授权的用户才能 访问特定的资源。
以下是MCP的基本工作流程:
初始化连接:客户端向服务器发送连接请求,建立通信通道。发送请求:客户端根据需求构建请求消息,并发送给服务器。处理请求:服务器接收到请求后,解析请求内容,执行相应的为操作(如查询数据 库、读取文件等)。返回结果:服务器将处理结果封装成响应消息,发送回客户站瑞。断开连接:任务完成后,客户端可以主动关闭连接或等待服务各器超时关
1.4 三种传输方式
| 传输方式 | 适用场景 | 特点 |
|---|---|---|
| stdio | 本地 Server | 最简单,通过标准输入输出通信 |
| HTTP + SSE | 远程 Server | Server-Sent Events,兼容性好 |
| Streamable HTTP | 远程 Server(新) | 更灵活,支持双向流 |
mcp.tool()的作用是对函数进行注册,将函数转化为可供MCP框架使用的工具
1.5 MCP架构
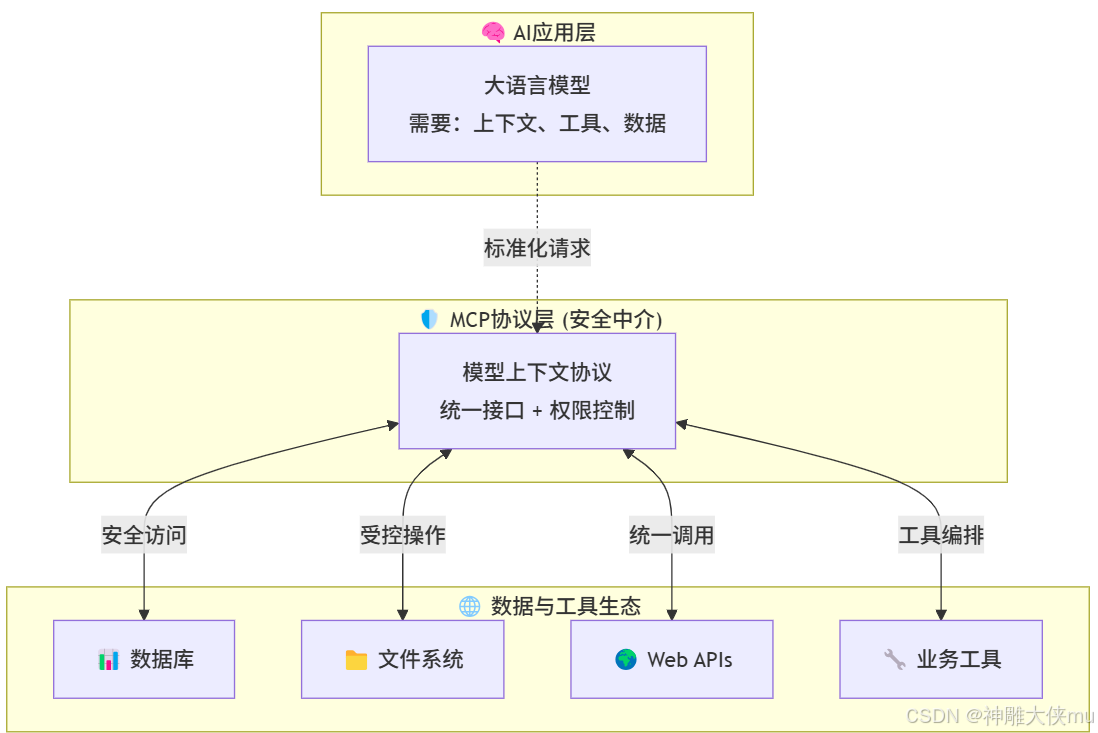
1.5 MCP 服务器可以提供三种主要类型的功能
工具:可被 LLM 调用的函数(需要用户批准)资源:可被客户端读取的类文件数据(如 API 响应或文件内容)提示词:帮助用户完成特定任务的预设模板
| 能力 | 说明 | 场景 | 示例 |
|---|---|---|---|
| @mcp.tool() | 用于 注册一个工具(Tool), 让大模型可以像调用函数一样调用这个能力 |
查询数据库 调用外部 API 执行业务逻辑 计算或处理数据 |
@mcp.tool() def add(a: int, b: int) -> int: “”“计算两个数字之和”“” return a + b |
| @mcp.resource() | 用于 注册资源(Resource), 向大模型提供 只读数据 |
规则文档 FAQ 说明书 知识库 |
@mcp.resource(“docs://refund_policy”) def refund_policy(): return “”“ 退款规则: 1. 7天无理由退货 2. 已发货订单需承担运费 ”“” |
| @mcp.prompt() | 用于 注册 Prompt 模板,供客户端或大模型使用 | 系统 Prompt 任务 Prompt |
|
| @mcp.model() | 用于 在 MCP Server 中注册模型能力 | 提供内部 LLM 提供 embedding 提供 AI 推理能力 |
|
| mcp.run() | 用于 启动 MCP Server 服务。 |
1.6 mcp架构
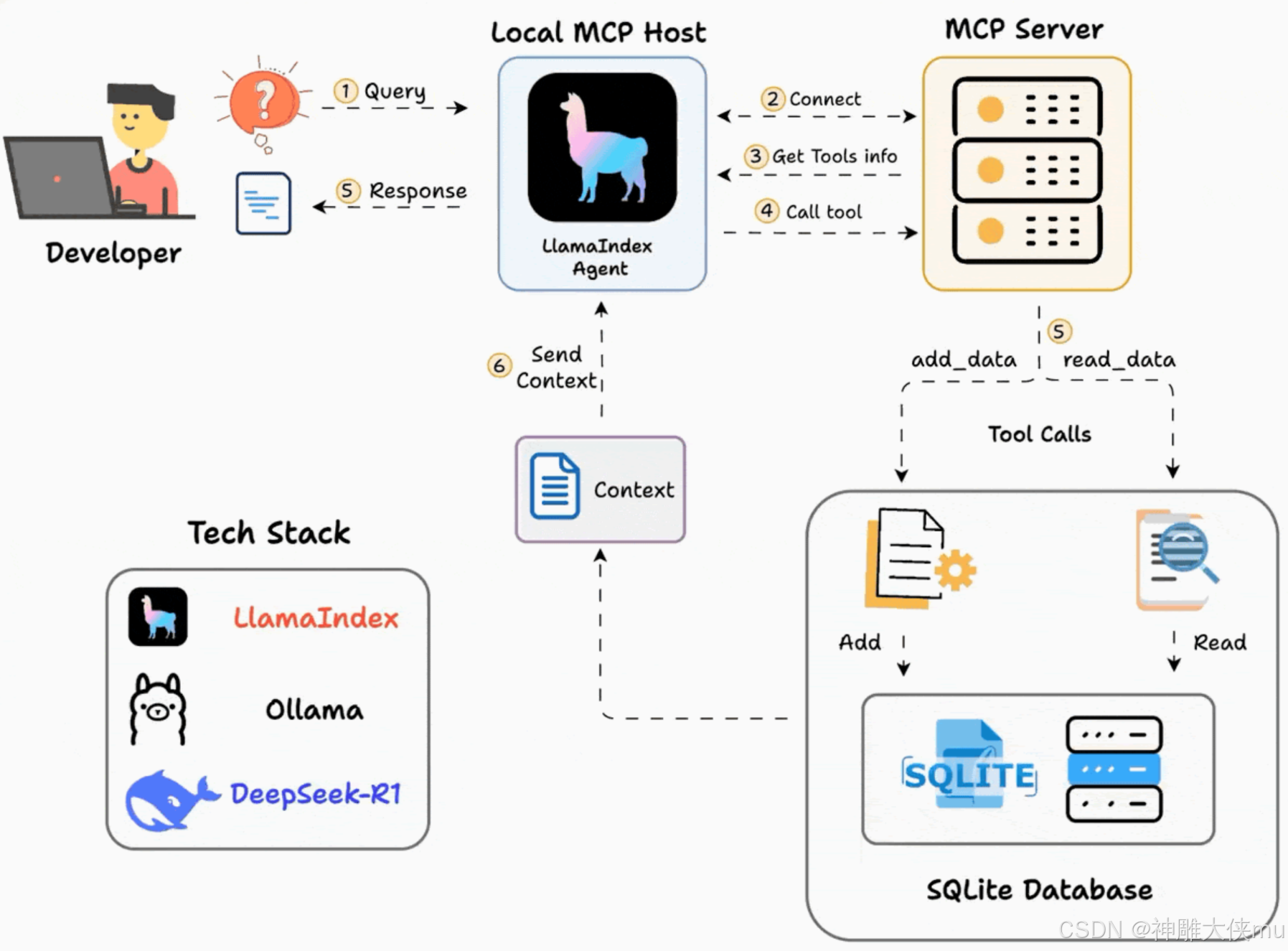
工作流程:
- ⽤⼾提交查询
- 智能体连接到 MCP 服务器以发现⼯具
- 根据查询,智能体调⽤合适的⼯具并获取上下⽂
- 智能体返回上下⽂感知的响应
1.6 中文官网
https://mcpcn.com/docs/
二、一个简单的LangGraph Agent + MCP Server + MCP Client + Tool 调用
2.1 代码结构
ai-agent-mcp
│
├── mcp_server
│ └── server.py
│
├── agent
│ └── client.py
│
├── client
│ └── run_agent.py
│
├── requirements.txt
2.2 代码
requirements.txt
langchain==1.2.8
langgraph==1.0.8
mcp==1.26.0
fastapi
uvicorn
pymysql
redis
weaviate-client
langchain-weaviate
langchain-openai
python-dotenv
google-search-results
server.py
from fastmcp import FastMCP
from datetime import datetime
mcp = FastMCP("AI Tool Server")
@mcp.tool()
def add(a: int, b: int) -> int:
"""计算两个数的和"""
return a + b
@mcp.tool()
def multiply(a: int, b: int) -> int:
"""计算两个数的乘积"""
return a * b
@mcp.tool()
def get_time() -> str:
"""获取当前时间"""
return datetime.now().strftime("%Y-%m-%d %H:%M:%S")
@mcp.tool()
def get_weather(city: str) -> str:
"""获取城市天气"""
return f"{city}天气:23℃ 晴"
if __name__ == "__main__":
mcp.run(
transport="sse",
host="0.0.0.0",
port=9000
)
client.py
import dotenv
from langchain_core.messages import HumanMessage
from langgraph.graph import StateGraph, END
from typing import TypedDict
from mcp.client.session import ClientSession
from mcp.client.sse import sse_client
import logging
from langchain.chat_models import init_chat_model
# =========================================================
# 1️⃣ 加载 .env 环境变量 注意:这里面有
# OPENAI_API_KEY
# OPENAI_BASE_UR
# 等配置
# =========================================================
dotenv.load_dotenv()
# =========================================================
# 2️⃣ 配置日志系统
# level: 日志等级
# format: 输出格式
# datefmt: 时间格式
# =========================================================
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
datefmt='%Y-%m-%d %H:%M:%S'
)
# 创建 logger 对象
# __name__ 表示当前模块名称
logger = logging.getLogger(__name__)
# =========================================================
# 3️⃣ 初始化大模型
# init_chat_model 是 LangChain 统一模型入口
# 这里使用 gpt-4o-mini
# =========================================================
model = init_chat_model("gpt-4o-mini")
# =========================================================
# 4️⃣ 定义 LangGraph 的 State
# Graph 中节点之间通过 State 传递数据
# =========================================================
class State(TypedDict):
# 用户问题
question: str
# 最终答案
answer: str
# =========================================================
# 5️⃣ 封装 LLM 调用函数
# =========================================================
async def call_llm(question: str):
# ainvoke = 异步调用模型
response = await model.ainvoke(
[HumanMessage(content=question)]
)
# 返回模型生成的文本
return response.content
# =========================================================
# 6️⃣ Agent 节点
# 这个节点负责:
# 1. 获取 MCP 工具
# 2. 让 LLM 判断是否需要调用工具
# 3. 调用工具
# 4. 再次调用 LLM 生成最终答案
# =========================================================
async def agent_node(state: State):
# 从 State 中获取用户问题
question = state["question"]
# =====================================================
# 连接 MCP Server
# SSE = Server Sent Event
# =====================================================
async with sse_client("http://localhost:9000/sse") as streams:
# 创建 MCP 会话
async with ClientSession(streams[0], streams[1]) as session:
# 初始化 MCP 会话
await session.initialize()
# =================================================
# 获取 MCP Server 所有可用工具
# =================================================
tools = (await session.list_tools()).tools
logger.info("获取可用tools:%s", tools)
# =================================================
# 构造工具描述字符串
# 格式:
# tool1:description
# tool2:description
# =================================================
tool_desc = "\n".join(
[f"{t.name}:{t.description}" for t in tools]
)
logger.info("获取可用tool_desc:%s", tool_desc)
# =================================================
# 构造 Prompt
# 让 LLM 决策是否调用工具
# =================================================
prompt = f"""
你可以调用以下工具:
{tool_desc}
用户问题:{question}
如果需要工具返回JSON:
{{"tool":"工具名","tool_input":{{}}}}
否则直接回答
"""
# 调用大模型
result = await call_llm(prompt)
# =================================================
# 判断 LLM 是否选择调用工具
# =================================================
if "tool" in result:
import json
# 解析 JSON
tool_json = json.loads(result)
# 获取工具名称
tool_name = tool_json["tool"]
# 获取工具参数
tool_input = tool_json["tool_input"]
# =================================================
# 调用 MCP 工具
# =================================================
ret = await session.call_tool(tool_name, tool_input)
# 工具返回结果
tool_result = ret.content[0].text
logger.info(f"用户问题:{question},使用工具:{tool_name}")
# =================================================
# 再次调用 LLM
# 使用工具结果生成最终回答
# =================================================
final_answer = await call_llm(
f"用户问题:{question},工具返回:{tool_result}"
)
return {"answer": final_answer}
else:
# 如果不需要工具
# 直接返回模型结果
return {"answer": result}
# =========================================================
# 7️⃣ 构建 LangGraph
# =========================================================
def build_graph():
# 创建 Graph Builder
builder = StateGraph(State)
# 添加节点
builder.add_node("agent", agent_node)
# 设置入口节点
builder.set_entry_point("agent")
# agent 执行完后结束
builder.add_edge("agent", END)
# 编译 Graph
return builder.compile()
run_agent.py
import asyncio
from mcp_client.client import build_graph
graph = build_graph()
async def main():
questions = [
"25+38是多少",
"356*125是多少",
"现在时间",
"Shanghai天气",
"讲个笑话"
]
for q in questions:
result = await graph.ainvoke({
"question": q
})
print("问题:", q)
print("回答:", result["answer"])
print("-" * 40)
if __name__ == "__main__":
asyncio.run(main())
2.3 测试
1.启动服务端,直接点击server.py的main函数启动
2.启动客户端,直接点击run_agent.py的main函数即可启动
输出如下:
…… 太多了
三、一个企业级智能客户系统(SSE)
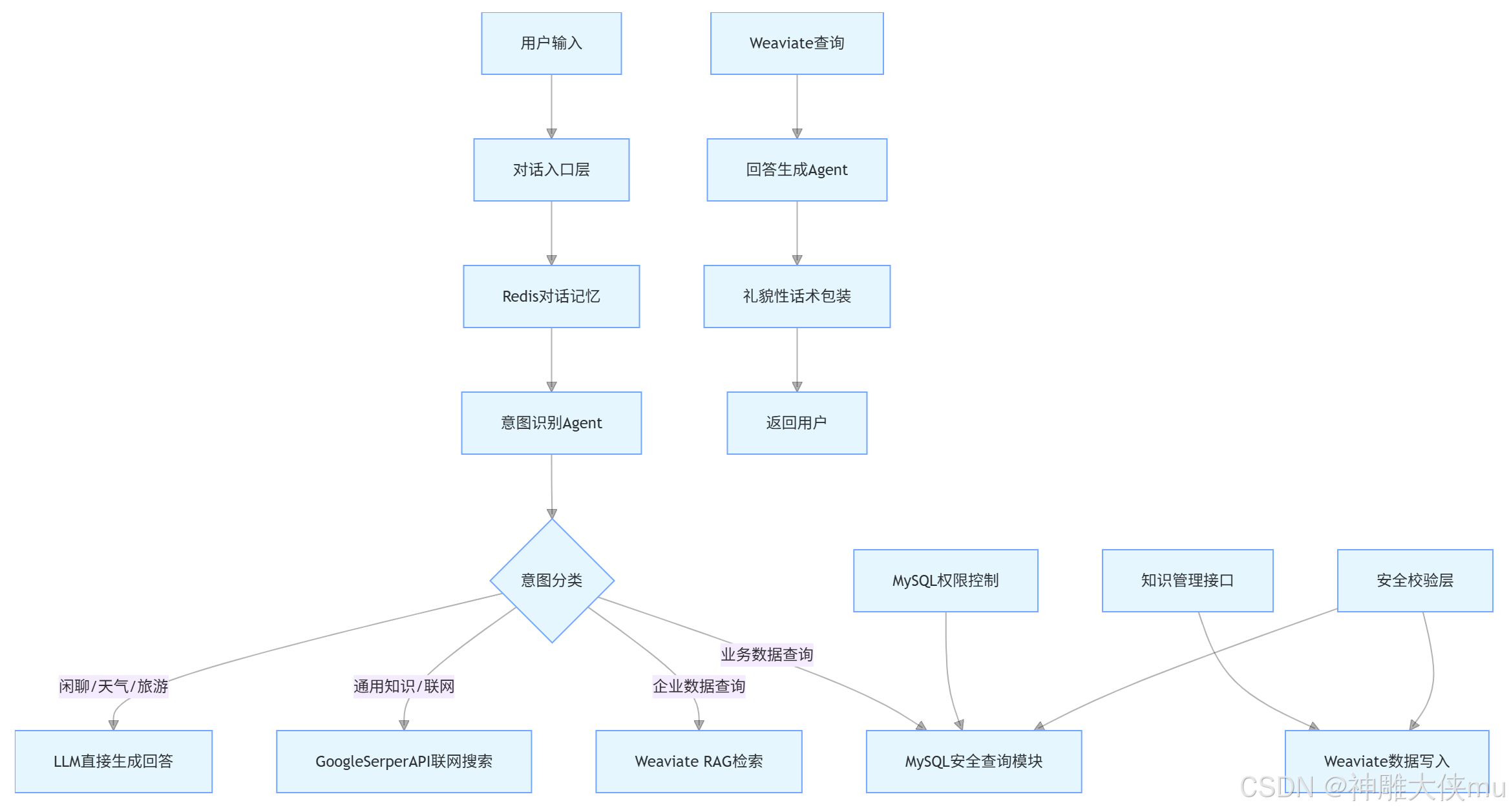
3.1 需求及使用到的知识点
1.使用:Langchain+LangGrap+MCP+agent+rag
2.使用向量数据库weaviate 向量化必要数据,如公司信息、退款规则等(提供单独接口可供postman访问,调用接口向向量数据库更新或存储新知识)
3.使用redis作记忆存储等。redis设置过期时间,防止数据爆炸
4.查询mysql数据库,查询订单信息,商品信息,支付信息等,但要注意安全控制仅允许查询语句(给出用到的SQL建表语句以及少量的数据)
5.可以联网搜索答案(使用GoogleSerperAPIWrapper),可以闲聊查询天气、旅游景点、美食等
6.使用MCP 的SSE 模式完成。server+client
3.2 流程图
3.3 项目代码结构
fast-mcp04
│
├── main.py
│
├── agent/
│ └── graph_agent.py
│ └── prompts.py
│ └── schema_loader.py
│
├── api/
│ └── chat_api.py
│
│
├── mcp_server/
│ └── server.py
├── mcp_client/
│ └── client.py
│
├── rag/
│ └── weaviate_rag.py
│
├── mcp_memory/
│ └── redis_memory.py
│
├── db/
│ └── mysql_schema.sql
├── rag/
│ └── weaviate_client.py
│
├── tools/
│ ├── search_tool.py
│ └── mysql_tool.py
│
└── requirements.txt
3.4 代码展示
mysql_schema.sql
CREATE DATABASE ecommerce;
USE ecommerce;
CREATE TABLE users (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50),
email VARCHAR(100)
);
CREATE TABLE products (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(100),
price DECIMAL(10,2)
);
CREATE TABLE orders (
id INT PRIMARY KEY AUTO_INCREMENT,
user_id INT,
product_id INT,
status VARCHAR(50),
created_at DATETIME
);
INSERT INTO users VALUES
(1,'Alice','alice@test.com'),
(2,'Bob','bob@test.com');
INSERT INTO products VALUES
(1,'iPhone 15',6999),
(2,'MacBook Pro',15999);
INSERT INTO orders VALUES
(1,1,1,'PAID',NOW()),
(2,2,2,'SHIPPED',NOW());
requirements.txt
fastapi~=0.135.1
pydantic~=2.12.5
python-dotenv~=1.2.1
weaviate-client~=4.19.2
langchain-core~=1.2.15
langchain-openai~=1.1.7
langchain-text-splitters~=1.1.0
langgraph~=1.0.10
langchain~=1.2.10
SQLAlchemy~=2.0.35
langchain-community~=0.4.1
uvicorn~=0.40.0
llama-index-core~=0.14.15
fastmcp~=3.1.0
graph_agent.py
import dotenv
import logging
from typing import Annotated, TypedDict
from langchain_core.tools import StructuredTool
from langchain_core.messages import HumanMessage, SystemMessage, BaseMessage, AIMessage
from langchain.chat_models import init_chat_model
from langgraph.graph import StateGraph
from langgraph.graph.message import add_messages
from pydantic import BaseModel, SecretStr
from mcp_client.client import init_mcp
from mcp_memory.redis_memory import init_redis, get_redis_saver
from agent.schema_loader import load_schema
from agent.prompts import build_system_prompt
dotenv.load_dotenv()
# =========================================================
# 1.日志配置
# =========================================================
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s | %(levelname)s | %(message)s"
)
log = logging.getLogger(__name__)
# =========================================================
# 2.LLM 初始化
# =========================================================
# 方式一: OpenAI远端模型
llm = init_chat_model(model="gpt-4o-mini")
# 方式二: 本地模型
# llm = init_chat_model(model="qwen2.5:3b",model_provider="ollama",base_url="http://localhost:11434",api_key=SecretStr("ollama"))
graph = None
# =========================================================
# 3.Agent State
# =========================================================
class AgentState(TypedDict):
"""
LangGraph 状态结构
add_messages 作用:
自动累加 messages,实现对话记忆
"""
messages: Annotated[list[BaseMessage], add_messages]
class QueryInput(BaseModel):
query: str
# =========================================================
# 4.MCP 工具注册
# =========================================================
def build_tools(session, tools):
"""
将 MCP 工具包装为 LangChain Tool
"""
lc_tools = []
for t in tools:
tool_name = t.metadata.name
desc = t.metadata.description or f"MCP tool: {tool_name}"
log.info("发现 MCP 工具: %s", tool_name)
async def run(query: str, name=tool_name):
log.info("调用 MCP 工具: %s", name)
log.info("工具参数: %s", query)
result = await session.call_tool(
name,
{"query": query}
)
tool_result = result.content[0].text
log.info("工具返回结果: %s", tool_result)
return tool_result
lc_tools.append(
StructuredTool.from_function(
name=tool_name,
description=desc,
coroutine=run,
args_schema=QueryInput
)
)
return lc_tools
# =========================================================
# 5.构建 Graph
# =========================================================
async def build_graph():
"""
系统初始化
1 初始化 Redis Memory
2 加载数据库 Schema
3 初始化 MCP 工具
4 构建 LangGraph Agent
"""
global graph
log.info("===== 系统启动 =====")
# 5.1初始化 Redis
await init_redis()
saver = get_redis_saver()
# 5.2加载数据库结构
log.info("加载数据库 Schema")
schema_text = load_schema()
# 5.3构建系统 Prompt
full_system_prompt = build_system_prompt(schema_text)
# 5.4连接 MCP
log.info("连接 MCP Server")
session, tools = await init_mcp()
# 5.5注册 MCP 工具
lc_tools = build_tools(session, tools)
log.info("工具注册完成,共 %d 个工具", len(lc_tools))
# 5.6绑定工具
llm_with_tools = llm.bind_tools(lc_tools)
# 5.7 创建了一个“图结构的工作流构建器”,并定义了整个 Agent 的状态结构
builder = StateGraph(AgentState)
# =========================================================
# 5.8 Agent 节点
# =========================================================
async def agent(state: AgentState):
messages = state["messages"]
question = messages[-1].content
log.info("用户问题: %s", question)
# 5.9 第一次 LLM 调用 作用:让模型判断是否需要调用工具
resp = await llm_with_tools.ainvoke(
[SystemMessage(content=full_system_prompt)] + messages
)
# =====================================================
# 5.10 需要调用工具
# =====================================================
if hasattr(resp, "tool_calls") and resp.tool_calls:
call = resp.tool_calls[0]
tool_name = call["name"]
args = call["args"]
log.info("LLM 决定调用工具:LLM选择工具: %s,工具参数: %s", tool_name, args)
# 调用 MCP 工具
ret = await session.call_tool(tool_name, args)
tool_result = ret.content[0].text
log.info("工具返回: %s", tool_result)
# 第二次调用 LLM
# 作用:根据工具返回结果生成自然语言回答
final_answer = await call_llm(
messages,
question,
full_system_prompt,
tool_result
)
return {
"messages": messages + [
AIMessage(content=final_answer)
]
}
# =====================================================
# 5.11 不需要工具
# =====================================================
else:
log.info("LLM 判断无需调用工具")
return {
"messages": messages + [
AIMessage(content=resp.content)
]
}
builder.add_node("agent", agent)
builder.set_entry_point("agent")
# 构建 LangGraph 带redis存储
graph = builder.compile(checkpointer=saver)
log.info("LangGraph 构建完成")
# =========================================================
# 6.Agent 调用入口
# =========================================================
async def run_agent(user_id: str, msg: str):
"""
Agent 执行入口
"""
log.info("收到请求 user_id=%s", user_id)
result = await graph.ainvoke(
{
"messages": [HumanMessage(content=msg)]
},
config={
"configurable": {
"thread_id": user_id
}
}
)
answer = result["messages"][-1].content
log.info("Agent 返回结果: %s", answer)
return answer
# =========================================================
# 7.二次 LLM 调用
# =========================================================
async def call_llm(messages, question, system_prompt, tool_result):
"""
第二次调用 LLM
作用:
将工具返回结果整理成用户可读的回答
"""
log.info("LLM 根据工具结果生成回答")
response = await llm.ainvoke(
[SystemMessage(content=system_prompt)]
+ messages
+ [
HumanMessage(content=f"""
用户问题:
{question}
工具返回:
{tool_result}
请根据结果回答用户问题
""")
]
)
return response.content
prompts.py
def build_system_prompt(schema_text: str) -> str:
"""
构建系统提示词
作用:
1 让大模型知道数据库结构
2 约束 SQL 生成规则
3 指导工具使用
"""
tool_guideline = """
你是电商智能客服助手“小蜜蜂”,请使用礼貌、专业语气回答客户问题。
可用工具:
1. mysql_query
查询商品、订单、库存等 MySQL 数据库信息
参数: { "query": "SQL语句" }
2. rag
查询公司概况、公告、退款规则等知识库
参数: { "query": "自然语言问题" }
3. search
查询互联网公开信息,闲聊、查询天气、旅游景点、美食等
参数: { "query": "搜索关键词" }
工具使用规则:
- 商品 / 订单 / 库存 → mysql_query
- 公司介绍 / 退款规则 → rag
- 新闻 / 互联网信息 → search
"""
db_prompt = f"""
你是 MySQL 数据库专家。
数据库结构:
{schema_text}
SQL规则:
1 只允许 SELECT
2 禁止 UPDATE DELETE INSERT
3 SQL 必须基于提供的表结构
4 SQL 语句必须正确
"""
return tool_guideline + "\n" + db_prompt
schema_loader.py
import os
import dotenv
from sqlalchemy import create_engine, text
dotenv.load_dotenv()
MYSQL_HOST = os.getenv("MYSQL_HOST")
MYSQL_PORT = os.getenv("MYSQL_PORT")
MYSQL_USER = os.getenv("MYSQL_USER")
MYSQL_PASSWORD = os.getenv("MYSQL_PASSWORD")
MYSQL_DB = os.getenv("MYSQL_DB")
MYSQL_URL = f"mysql+pymysql://{MYSQL_USER}:{MYSQL_PASSWORD}@{MYSQL_HOST}:{MYSQL_PORT}/{MYSQL_DB}"
engine = create_engine(MYSQL_URL)
# 读取数据库表结构
def load_schema():
sql = """
SELECT
table_name AS table_name,
column_name AS column_name,
data_type AS data_type
FROM information_schema.columns
WHERE table_schema = :db
ORDER BY table_name
"""
with engine.connect() as conn:
result = conn.execute(text(sql), {"db": MYSQL_DB})
tables = {}
for r in result:
row = dict(r._mapping)
table = row["table_name"]
column = row["column_name"]
dtype = row["data_type"]
tables.setdefault(table, []).append(f"{column} ({dtype})")
schema_text = ""
for table, cols in tables.items():
schema_text += f"\n表 {table}\n"
for c in cols:
schema_text += f" - {c}\n"
return schema_text
chat_api.py
from fastapi import APIRouter
from agent.graph_agent import run_agent
from rag.weaviate_client import add_knowledge, search_knowledge
from pydantic import BaseModel
import logging
# =========================================================
# 1.日志配置
# =========================================================
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s | %(levelname)s | %(message)s"
)
log = logging.getLogger(__name__)
router = APIRouter()
# 1️.定义客户聊天请求模型
class ChatRequest(BaseModel):
msg: str
user_id: str
# 2.定义添加向量数据库请求模型
class AddEmbeddingRequest(BaseModel):
content: str
@router.post("/chat")
async def chat(request: ChatRequest):
log.info("收到请求,用户:%s,消息:%s", request.user_id, request.msg)
answer = await run_agent(request.user_id, request.msg)
return {"answer": answer}
@router.post("/add_knowledge")
def add(text: AddEmbeddingRequest):
context = text.content
log.info("收到请求,存储向量数据库消息:%s", context)
add_knowledge(context)
return {"msg": "ok"}
@router.post("/search_knowledge")
def add(text: AddEmbeddingRequest):
content = text.content
log.info("收到请求,搜索向量数据库消息:%s", content)
resp = search_knowledge(content)
return {"msg": resp}
client.py
from llama_index.tools.mcp import BasicMCPClient, McpToolSpec
import os
import dotenv
dotenv.load_dotenv()
tools = None
MCP_SERVER_URL = os.getenv("MCP_SERVER_URL")
# 连接MCP 服务器并获取可用工具
async def init_mcp():
global tools
client = BasicMCPClient(MCP_SERVER_URL)
tool_spec = McpToolSpec(client)
tools = await tool_spec.to_tool_list_async()
return client, tools
redis_memory.py
```python
import os
import dotenv
import logging
from langgraph.checkpoint.redis import AsyncRedisSaver
dotenv.load_dotenv()
log = logging.getLogger(__name__)
REDIS_URL = os.getenv("REDIS_URL")
redis_saver: AsyncRedisSaver | None = None
# ===================================
# 带 TTL 的 RedisSaver
# ===================================
class TTLRedisSaver(AsyncRedisSaver):
def __init__(self, *args, ttl_seconds=3600, **kwargs):
super().__init__(*args, **kwargs)
self.ttl_seconds = ttl_seconds
async def aput(self, config, checkpoint, metadata, new_versions):
result = await super().aput(
config,
checkpoint,
metadata,
new_versions
)
await self._apply_ttl(config)
return result
async def aget(self, config):
data = await super().aget(config)
await self._apply_ttl(config)
return data
async def _apply_ttl(self, config):
try:
thread_id = config["configurable"]["thread_id"]
async for key in self._redis.scan_iter(f"*{thread_id}*"):
ttl = await self._redis.ttl(key)
if ttl == -1: # 只有没有 TTL 的 key 才设置
await self._redis.expire(key, self.ttl_seconds)
except Exception as e:
log.warning("TTL设置失败: %s", e)
# ===================================
# 初始化 Redis
# ===================================
async def init_redis():
global redis_saver
log.info("初始化 Redis Checkpoint Saver")
cm = TTLRedisSaver.from_conn_string(REDIS_URL)
redis_saver = await cm.__aenter__()
redis_saver.ttl_seconds = 600
def get_redis_saver() -> AsyncRedisSaver:
if redis_saver is None:
raise RuntimeError("RedisSaver 未初始化")
return redis_saver
server.py
from fastmcp import FastMCP
from tools.mysql_tool import safe_query
from tools.search_tool import search_web
from rag.weaviate_client import search_knowledge
import logging
# =========================================================
# 日志配置
# =========================================================
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s | %(levelname)s | %(message)s"
)
log = logging.getLogger(__name__)
mcp = FastMCP("ecommerce-tools")
@mcp.tool()
def mysql_query(query: str):
log.info("调用 mysql_query")
log.info(f"SQL: {query}")
logging.debug("mysql_query:", query)
sql = query
return safe_query(sql)
@mcp.tool()
def rag(query: str):
print("调用 RAG")
return search_knowledge(query)
@mcp.tool()
def search(query: str):
print("调用 search")
return search_web(query)
if __name__ == "__main__":
mcp.run(
transport="sse",
host="0.0.0.0",
port=9000
)
weaviate_client.py
`mysql_tool.py`
```python
import os
import dotenv
import weaviate
from langchain_core.documents import Document
from langchain_weaviate import WeaviateVectorStore
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
dotenv.load_dotenv()
WEAVIATE_HOST = os.getenv("WEAVIATE_URL", "localhost")
# ==========================
# 1 初始化 Weaviate Client
# ==========================
client = weaviate.connect_to_local(
host=WEAVIATE_HOST,
port=8088,
grpc_port=50051
)
# ==========================
# 2 Embedding
# ==========================
embeddings = OpenAIEmbeddings(
model="text-embedding-3-small"
)
# ==========================
# 3 Vector Store
# ==========================
vector_store = WeaviateVectorStore(
client=client,
embedding=embeddings,
index_name="yunFanDb2",
text_key="text",
)
print("✅ Weaviate 向量数据库连接成功")
# 搜索向量数据库
def search_knowledge(query):
retriever = vector_store.as_retriever(search_kwargs={"k": 2})
resp = retriever.invoke(query)
return "\n".join([d.page_content for d in resp])
# return vector_store.similarity_search(query)
# 向量化数据
def add_knowledge(req: str):
documents = [
Document(page_content=req)
]
# 文档分割器
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=0,
separators=["。", "?", "\n\n", "\n", " ", ""])
docs = text_splitter.split_documents(documents)
vector_store.add_documents(docs)
return {"msg": "知识添加成功"}
mysql_tool.py
import os
import dotenv
from sqlalchemy import create_engine, text
import re
dotenv.load_dotenv()
MYSQL_HOST = os.getenv("MYSQL_HOST")
MYSQL_PORT = os.getenv("MYSQL_PORT")
MYSQL_USER = os.getenv("MYSQL_USER")
MYSQL_PASSWORD = os.getenv("MYSQL_PASSWORD")
MYSQL_DB = os.getenv("MYSQL_DB")
MYSQL_URL = f"mysql+pymysql://{MYSQL_USER}:{MYSQL_PASSWORD}@{MYSQL_HOST}:{MYSQL_PORT}/{MYSQL_DB}"
engine = create_engine(MYSQL_URL)
def safe_query(sql):
print("执行SQL:", sql)
if not re.match(r"^\s*select", sql, re.I):
return "只允许SELECT查询"
with engine.connect() as conn:
result = conn.execute(text(sql))
rows = [dict(r._mapping) for r in result]
return rows
search_tool.py
import os
import dotenv
from langchain_community.utilities import GoogleSerperAPIWrapper
dotenv.load_dotenv()
SERPER_API_KEY = os.getenv("SERPER_API_KEY")
search=GoogleSerperAPIWrapper(
serper_api_key=SERPER_API_KEY
)
def search_web(query):
print("联网搜索:",query)
return search.run(query)
main.py
from fastapi import FastAPI
from contextlib import asynccontextmanager
import uvicorn
import logging
from agent.graph_agent import build_graph
from api.chat_api import router
# =========================================================
# 1.日志配置
# =========================================================
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s | %(levelname)s | %(message)s"
)
log = logging.getLogger(__name__)
@asynccontextmanager
async def lifespan(app: FastAPI):
log.info("初始化 LangGraph Agent ...")
await build_graph()
log.info("Agent 初始化完成")
yield
log.info("===== 系统关闭 =====")
def create_app() -> FastAPI:
app = FastAPI(
title="AI 电商智能客服",
version="1.0",
lifespan=lifespan
)
app.include_router(router)
return app
app = create_app()
if __name__ == "__main__":
uvicorn.run(
"main:app",
host="0.0.0.0",
port=8888,
reload=True
)
3.5 测试
请求一:查询谷歌互联网
http://localhost:8888/chat
{
"msg":"今天有哪些新闻",
"user_id":"20260310-009"
}
返回:
{
"answer": "今天的新闻内容包括:\n\n1. 最新发布的视频证实,击中伊朗学校附近海军基地的是一枚战斧巡航导弹,表明美军是这场冲突中唯一使用战斧导弹的武装力量。\n2. 伊朗向美以展现强硬态度,涉及的潜在军事冲突分析。\n3. 美国及伊朗在战争走向上的误判。\n4. 富裕国家考虑释放石油储备,以应对油价波动。\n5. 特朗普即将访华之际,中国出口机器依然强劲。\n6. 中国“养龙虾”热潮提振科技股,加速人工智能转型。\n\n如果您需要更详细的报道或其他信息,欢迎随时告知我!"
}
请求二:查询mysql
http://localhost:8888/chat
{
"msg":"查询订单号为1 的商品状态",
"user_id":"20260310-009"
}
返回:
{
"answer": "您好,订单号为1的商品状态是:已支付(paid)。如果您还有其他问题,请随时告诉我!"
}
请求三:查询向量数据库weaviate
http://localhost:8888/chat
{
"msg":"请介绍字节公司",
"user_id":"20260310-009"
}
{
"answer": "字节跳动(ByteDance)是一家成立于2012年的中国互联网科技企业,是最早将人工智能应用于移动场景的科技公司之一。公司的使命是“激发创造、丰富生活”,致力于建设全球创作与交流平台。凭借技术出海战略与本土化运营,字节跳动的业务已覆盖全球150个国家和地区,是全球最具价值的科技独角兽之一。如果您还有其他问题,欢迎随时询问!"
}
四、由SSE模式改造为Streamable HTTP模式
4.1 简介
Streamable-httpstreamable HTTP是MCP协议在2025年3月引入的一种新传输机制,旨在取代之前的HTTP+SSE传输模式。它的设计理念是在保留SSE优点的同时克服其限 制,特别是提供更好的可扩展性和企业环境兼容性。 Streamable HTTP的核心思想是提供一个统一的HTTP端点点,同时支持POST和 GET方法:
POST方法: 用于客户端向服务器发送请求和接收响应
GET方法(可选): 用于建立SSE流,接收服务器实时推送的消自息
与传统HTTP+SSE不同,StreamableHTTP不要求维护单独的初始化连接和消 息端点,简化了协议设计并提高了可靠性
4.2 原理
1.连接:在streamableHTTP模式下,并没有和SSE模式类似的"连接"过程(在 sse_client调用时),因为无需事先创建SSE连接2. 客户端发起初始化请求(Initialize):如果是有状态模式,+会在返回消息的 HTTP头中携带session-id;3. 客户端发起初始化确认(Initialized):此时如果已有session-id(有状态),客 户端会首先发起一次HTTPGet请求,以建立独立的SSE通道4.后续正常交互:普通的交互都是通过Post通道来进行,只有两种情况会使用 SSE通道:服务端发起的通知与请求、以及会话恢复的事件发送。
4.3 Streamable HTTP对比SSE的优势
1.简化的通信模型
传统的HTTP+SSE方法需要两个不同的端点:一个用于建立立连接,另一个用于发送消息。而StreamableHTTP提供了一个统一的端点,简化了客户端和服务器之间的交 互。2.支持无状态模式
StreamableHTTP的一个重要创新是支持完全无状态操作。通过设 sessionIdGenerator:() =>undefined,服务器可以在不维护会话状态的情况下 处理请求,非常适合无服务器环境。比如:部署在AWSLambda、Azure Functions 等无服务器环境。短暂交互而非长期连接的场景。3.更好的可伸缩性
由于StreamableHTTP可以在无状态模式下运行,它非常适合容器化和自动扩展场景。服务器不需要维护长期连接,可以根据请求动态分配资源,显著提高可伸缩性。这解决了SSE的一个主要问题:当有大量客户端时,每个客户端都需要维持一个长连接,可能导致服务器资源耗尽。使用StreamableHTTP的无状态模式,服务器只在处 理请求时分配资源,处理完成后即可释放。4.提高的可靠性
StreamableHTTP的简化设计减少了出错机会:
- 会话管理:在有状态模式下,会话ID通过HTTP头而非查询参数传递,减少安 全风险
- 重连处理:客户端可以在会话有效期内随时重连,无需复杂的重连逻辑
- 错误恢复:简化的协议使错误处理和恢复更加直观
5.更好的企业环境兼容性
在企业环境中,代理服务器和防火墙常常会阻止非标准HTTP连主接。Streamable HTTP使用标准HTTP通信,大大减少了这类问题:
- 使用标准HTTPPOST和GET,无需特殊配置 不
- 依赖长连接,减少代理超时问题
- 会话ID通过HTTP头传递,更符合企业安全要
4.4client.py改造
import os
import dotenv
import logging
from mcp.client.streamable_http import streamable_http_client
from mcp import ClientSession
dotenv.load_dotenv()
log = logging.getLogger(__name__)
MCP_SERVER_URL = os.getenv("MCP_SERVER_URL")
# =========================================================
# 获取 MCP tools schema
# =========================================================
async def load_mcp_tools():
log.info("加载 MCP tools")
async with streamable_http_client(MCP_SERVER_URL) as (read, write, _):
async with ClientSession(read, write) as session:
await session.initialize()
tools = await session.list_tools()
log.info("MCP 工具列表: %s", [t.name for t in tools.tools])
return tools
# =========================================================
# 调用 MCP tool
# =========================================================
async def call_mcp_tool(tool_name, args):
log.info("创建 MCP session 调用工具")
async with streamable_http_client(MCP_SERVER_URL) as (read, write, _):
async with ClientSession(read, write) as session:
await session.initialize()
result = await session.call_tool(tool_name, args)
return result
async def close_mcp():
global ctx
if ctx:
await ctx.__aexit__(None, None, None)
4.5 graph_agent.py改造
import dotenv
import logging
from typing import Annotated, TypedDict
from langchain_core.tools import StructuredTool
from langchain_core.messages import HumanMessage, SystemMessage, BaseMessage, AIMessage
from langchain.chat_models import init_chat_model
from langgraph.graph import StateGraph
from langgraph.graph.message import add_messages
from pydantic import BaseModel
from mcp_client.client import load_mcp_tools, call_mcp_tool
from mcp_memory.redis_memory import init_redis, get_redis_saver
from agent.schema_loader import load_schema
from agent.prompts import build_system_prompt
dotenv.load_dotenv()
# =========================================================
# 1.日志配置
# =========================================================
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s | %(levelname)s | %(message)s"
)
log = logging.getLogger(__name__)
# =========================================================
# 2.LLM 初始化
# =========================================================
# 方式一: OpenAI远端模型
llm = init_chat_model(model="gpt-4o-mini")
# 方式二: 本地模型
# llm = init_chat_model(model="qwen2.5:3b",model_provider="ollama",base_url="http://localhost:11434",api_key=SecretStr("ollama"))
graph = None
# =========================================================
# 3.Agent State
# =========================================================
class AgentState(TypedDict):
"""
LangGraph 状态结构
add_messages 作用:
自动累加 messages,实现对话记忆
"""
messages: Annotated[list[BaseMessage], add_messages]
class QueryInput(BaseModel):
query: str
# =========================================================
# 4.MCP 工具注册
# =========================================================
def build_tools(tools_result):
lc_tools = []
for t in tools_result.tools:
tool_name = t.name
desc = t.description or f"MCP tool: {tool_name}"
async def run(query: str, name=tool_name):
log.info("调用 MCP 工具: %s", name)
result = await call_mcp_tool(
name,
{"query": query}
)
tool_result = result.content[0].text
log.info("工具返回结果: %s", tool_result)
return tool_result
lc_tools.append(
StructuredTool.from_function(
name=tool_name,
description=desc,
coroutine=run,
args_schema=QueryInput
)
)
return lc_tools
# =========================================================
# 5.构建 Graph
# =========================================================
async def build_graph():
"""
系统初始化
1 初始化 Redis Memory
2 加载数据库 Schema
3 初始化 MCP 工具
4 构建 LangGraph Agent
"""
global graph
log.info("===== 系统启动 =====")
# 5.1初始化 Redis
await init_redis()
saver = get_redis_saver()
# 5.2加载数据库结构
log.info("加载数据库 Schema")
schema_text = load_schema()
# 5.3构建系统 Prompt
full_system_prompt = build_system_prompt(schema_text)
# 5.4连接 MCP
tools = await load_mcp_tools()
lc_tools = build_tools(tools)
log.info("工具注册完成,共 %d 个工具", len(lc_tools))
# 5.6绑定工具
llm_with_tools = llm.bind_tools(lc_tools)
# 5.7 创建了一个“图结构的工作流构建器”,并定义了整个 Agent 的状态结构
builder = StateGraph(AgentState)
# =========================================================
# 5.8 Agent 节点
# =========================================================
async def agent(state: AgentState):
messages = state["messages"]
question = messages[-1].content
log.info("用户问题: %s", question)
# 5.9 第一次 LLM 调用 作用:让模型判断是否需要调用工具
resp = await llm_with_tools.ainvoke(
[SystemMessage(content=full_system_prompt)] + messages
)
# =====================================================
# 5.10 需要调用工具
# =====================================================
if hasattr(resp, "tool_calls") and resp.tool_calls:
call = resp.tool_calls[0]
tool_name = call["name"]
args = call["args"]
log.info("LLM 决定调用工具:LLM选择工具: %s,工具参数: %s", tool_name, args)
# 调用 MCP 工具
ret = await call_mcp_tool(tool_name, args)
tool_result = ret.content[0].text
log.info("工具返回: %s", tool_result)
# 第二次调用 LLM
# 作用:根据工具返回结果生成自然语言回答
final_answer = await call_llm(
messages,
question,
full_system_prompt,
tool_result
)
return {
"messages": messages + [
AIMessage(content=final_answer)
]
}
# =====================================================
# 5.11 不需要工具
# =====================================================
else:
log.info("LLM 判断无需调用工具")
return {
"messages": messages + [
AIMessage(content=resp.content)
]
}
builder.add_node("agent", agent)
builder.set_entry_point("agent")
# 构建 LangGraph 带redis存储
graph = builder.compile(checkpointer=saver)
log.info("LangGraph 构建完成")
# =========================================================
# 6.Agent 调用入口
# =========================================================
async def run_agent(user_id: str, msg: str):
"""
Agent 执行入口
"""
log.info("收到请求 user_id=%s", user_id)
result = await graph.ainvoke(
{
"messages": [HumanMessage(content=msg)]
},
config={
"configurable": {
"thread_id": user_id
}
}
)
answer = result["messages"][-1].content
log.info("Agent 返回结果: %s", answer)
return answer
# =========================================================
# 7.二次 LLM 调用
# =========================================================
async def call_llm(messages, question, system_prompt, tool_result):
"""
第二次调用 LLM
作用:
将工具返回结果整理成用户可读的回答
"""
log.info("LLM 根据工具结果生成回答")
response = await llm.ainvoke(
[SystemMessage(content=system_prompt)]
+ messages
+ [
HumanMessage(content=f"""
用户问题:
{question}
工具返回:
{tool_result}
请根据结果回答用户问题
""")
]
)
return response.content
五、FASTMCP 与MCP的区别与联系
5.1 对比FASTMCP 与MCP
| 对比 | MCP | FASTMCP |
|---|---|---|
| 类型 | 协议 | 框架 |
| 全称 | Model Context Protocol | Fast Model Context Protocol |
| 作用 | 定义LLM如何调用工具 | 快速实现MCP Server |
| 类似 | HTTP | Fast API |
| 用途 | 规范接口工具 | 写服务工具 |
总结:MCP 是client与server的通信标准,FastMCP 是server端的实现。是两个不同的东西
5.2 对比多种实现MCP服务端的方式
FastMCP 只是一个“快速实现服务器”的框架。如果不用 FastMCP,其实还有多种方式实现 MCP Server
以下是多种实现MCP Server的方法
方式 一:Fast MCP
from fastmcp import FastMCP
mcp = FastMCP("ecommerce-tools")
@mcp.tool()
def mysql_query(query: str):
log.info("调用 mysql_query")
log.info(f"SQL: {query}")
return safe_query(query)
方式 二:MCP Server(官方)
from mcp.server import Server
server = Server("demo-server")
@server.tool()
async def add(a: int, b: int) -> int:
"""加法计算"""
return a + b
方式三 Fast API
from fastapi import FastAPI
app = FastAPI()
@app.post("/mcp")
async def mcp_endpoint(req: dict):

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 15
15 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)