强化学习:3 分钟读懂强化学习的底层逻辑
前言
强化学习(Reinforcement Learning,简称 RL)是人工智能领域最具生命力的分支之一 —— 它不像监督学习那样依赖 “标准答案”,也不像无监督学习那样被动挖掘模式,而是让智能体在环境中通过 “试错 + 奖惩” 自主进化,最终学会最大化长期收益的策略。
想理解它?不妨先想想怎么教一只小狗 “坐下”:不用手把手纠正动作,只需要在它偶然坐下时给一块肉干,反复几次,它就会主动把 “听到指令→坐下→得奖励” 绑定成行为准则。这正是强化学习的核心直觉!本文全程用 “训狗” 案例贯穿,避开枯燥公式,从核心直觉到算法流派,再到现实应用,带你从 0 到 1 彻底吃透强化学习。
一、强化学习的核心直觉
一句话定义: 强化学习就是“通过试错(Trial and Error)来学习如何最大化奖励”的过程。
例子:训练小狗 “坐下”我们把小狗当作智能体(Agent),目标是让它学会听到指令后坐下。
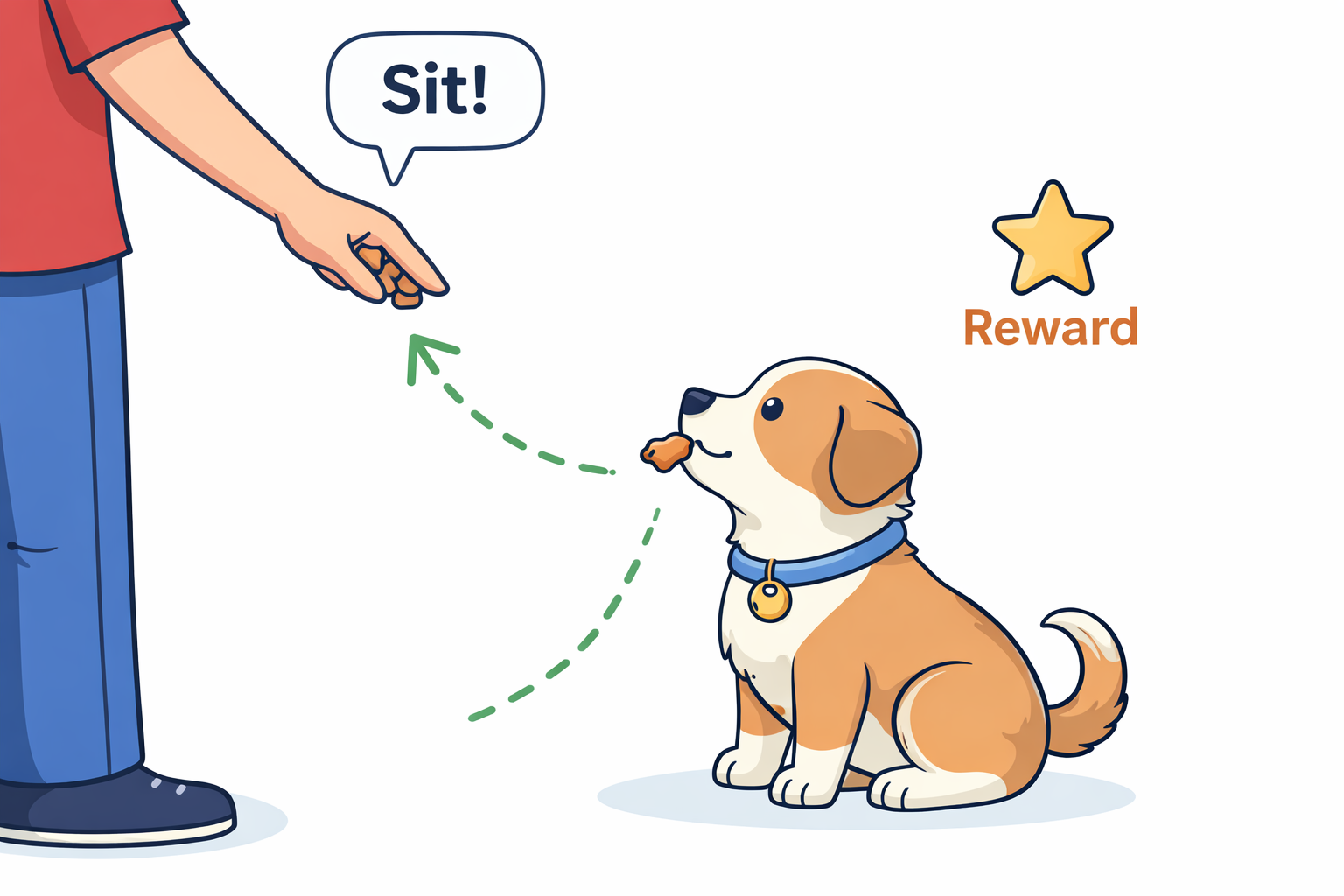
- 初始阶段:你喊 “坐下”,小狗完全无概念,会乱跑、叫唤、打滚(这是智能体的随机试错)。
- 偶然突破:某次它偶然屁股着地坐下 —— 这是一次关键有效动作。
- 即时反馈:你立刻投喂肉干(环境给出正奖励)。
- 认知更新:小狗会把 “‘坐下’这个动作 + 肉干奖励” 强关联,意识到 “这个行为能带来好处”。
- 重复强化:下次再喊指令,它会更倾向于尝试 “坐下”,概率逐步提升。
久而久之,小狗就形成了稳定行为:听到 “坐下”→主动坐下→获得肉干。这就是强化学习最本质的过程 ——通过奖励强化期望行为,通过试错规避无效行为。
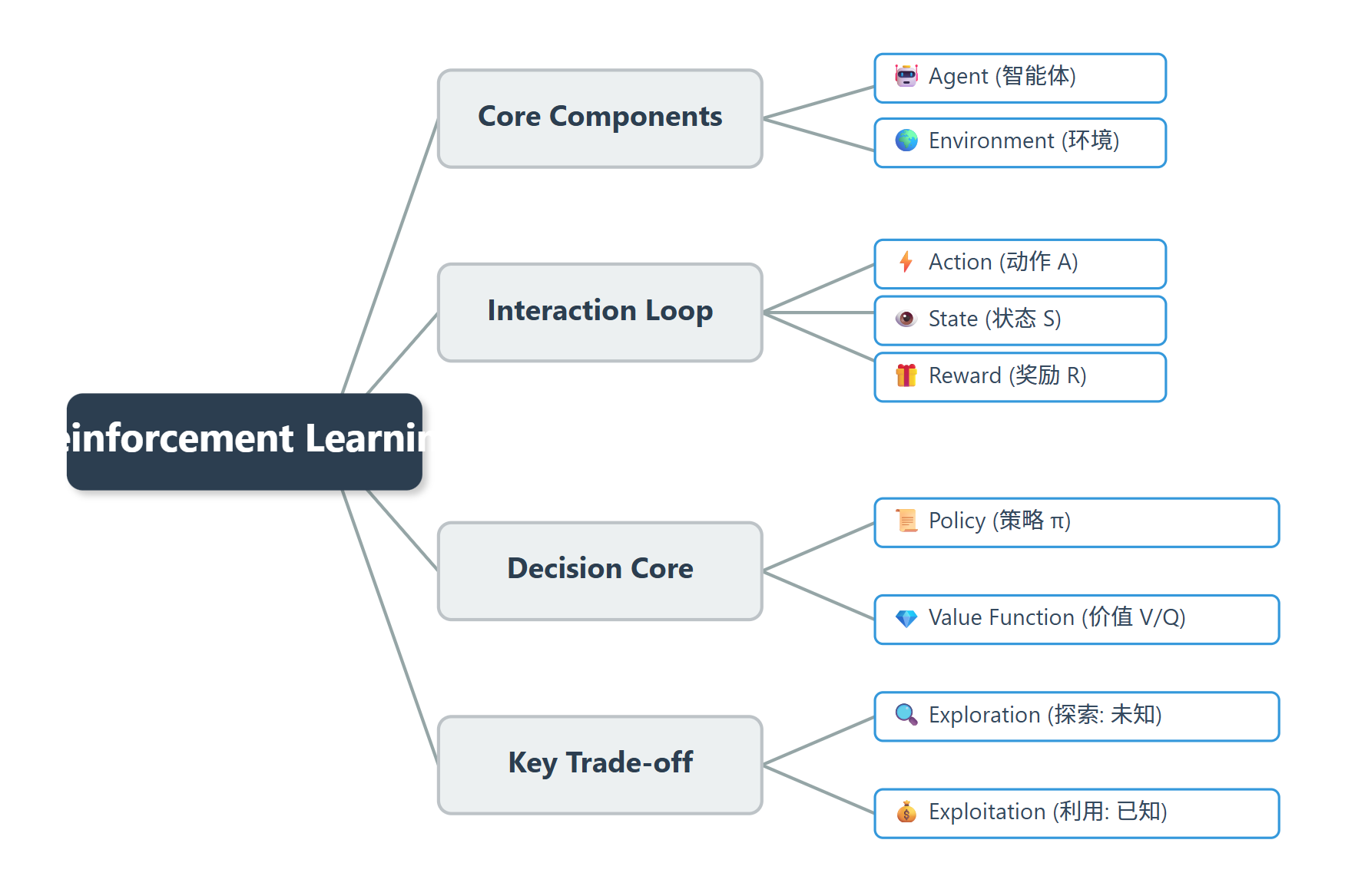
二、强化学习的 5 大核心要素
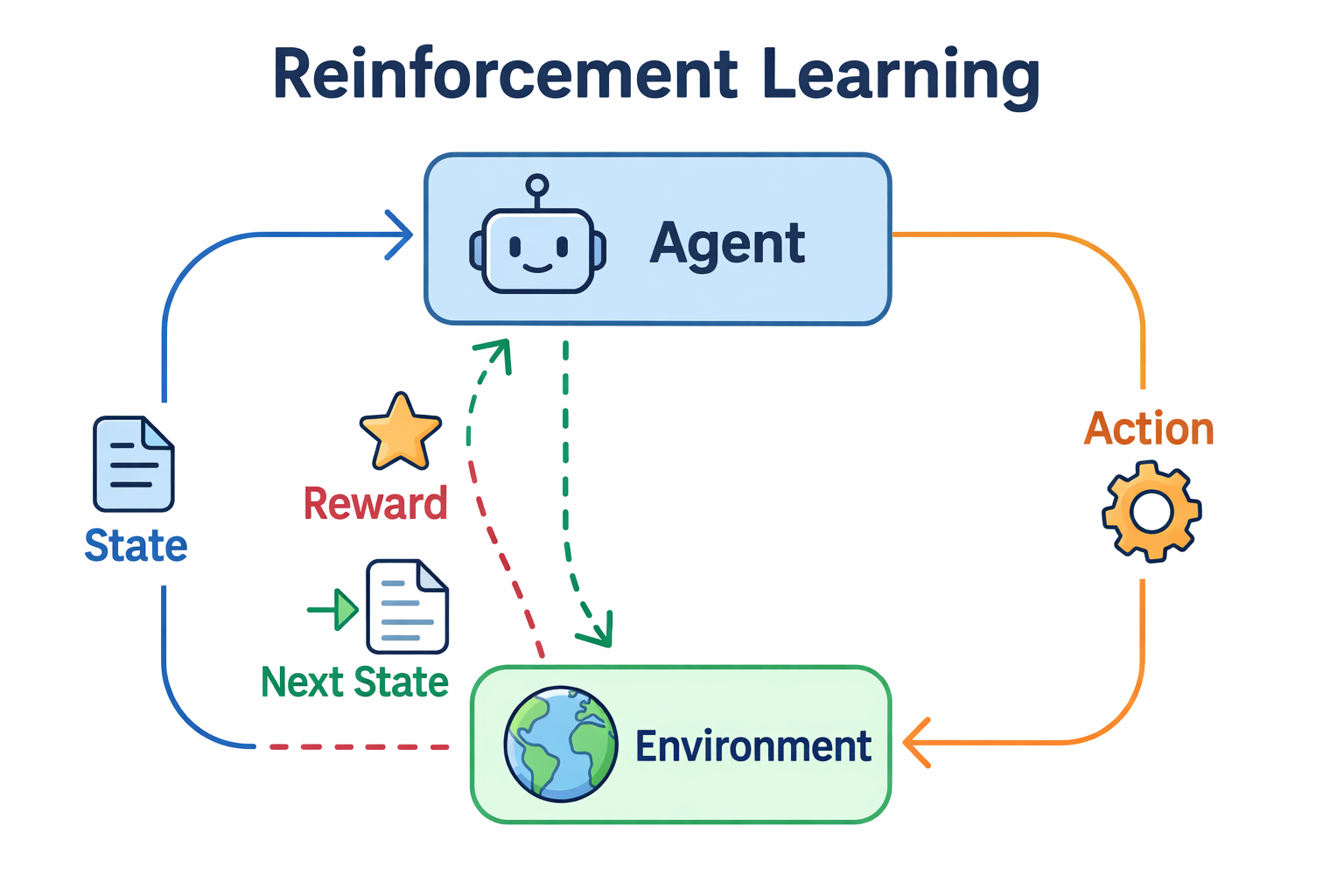
在 RL 的世界里,所有问题都可以拆解为这 5 个要素。请务必记住这几个名词,我们继续用小狗的例子对应:
| 核心要素 | 英文名 | 通俗解释 | 小狗案例对应 | 技术补充 |
|---|---|---|---|---|
| 智能体 | Agent | 做决策、主动学习的核心主体 | 小狗 | 可理解为 “AI 大脑”,负责感知状态、选动作、更新策略 |
| 环境 | Environment | 智能体所处的世界,限制动作并给反馈 | 你的客厅 + 你(持肉干) | 包含所有可交互元素,是智能体学习的 “舞台” |
| 状态 | State (S) | 智能体某一时刻的环境观察信息 | 小狗看到的:你喊指令、手里拿肉干 | 是智能体决策的核心依据,可包含视觉、数据、传感器信息等 |
| 动作 | Action (A) | 智能体在当前状态下可执行的行为 | 跑、跳、叫、坐下、咬拖鞋 | 分离散(如坐下 / 站起)和连续(如移动速度)两类 |
| 奖励 | Reward (R) | 环境给智能体的 “分数反馈”(正 / 负 / 零) | 肉干(+10 分)、被打屁股(-10 分)、无视(0 分) | RL 的灵魂!正奖励强化行为,负惩罚抑制不良行为 |
三、强化学习的“生命循环”
强化学习不是一次性过程,而是智能体与环境持续交互的闭环循环:
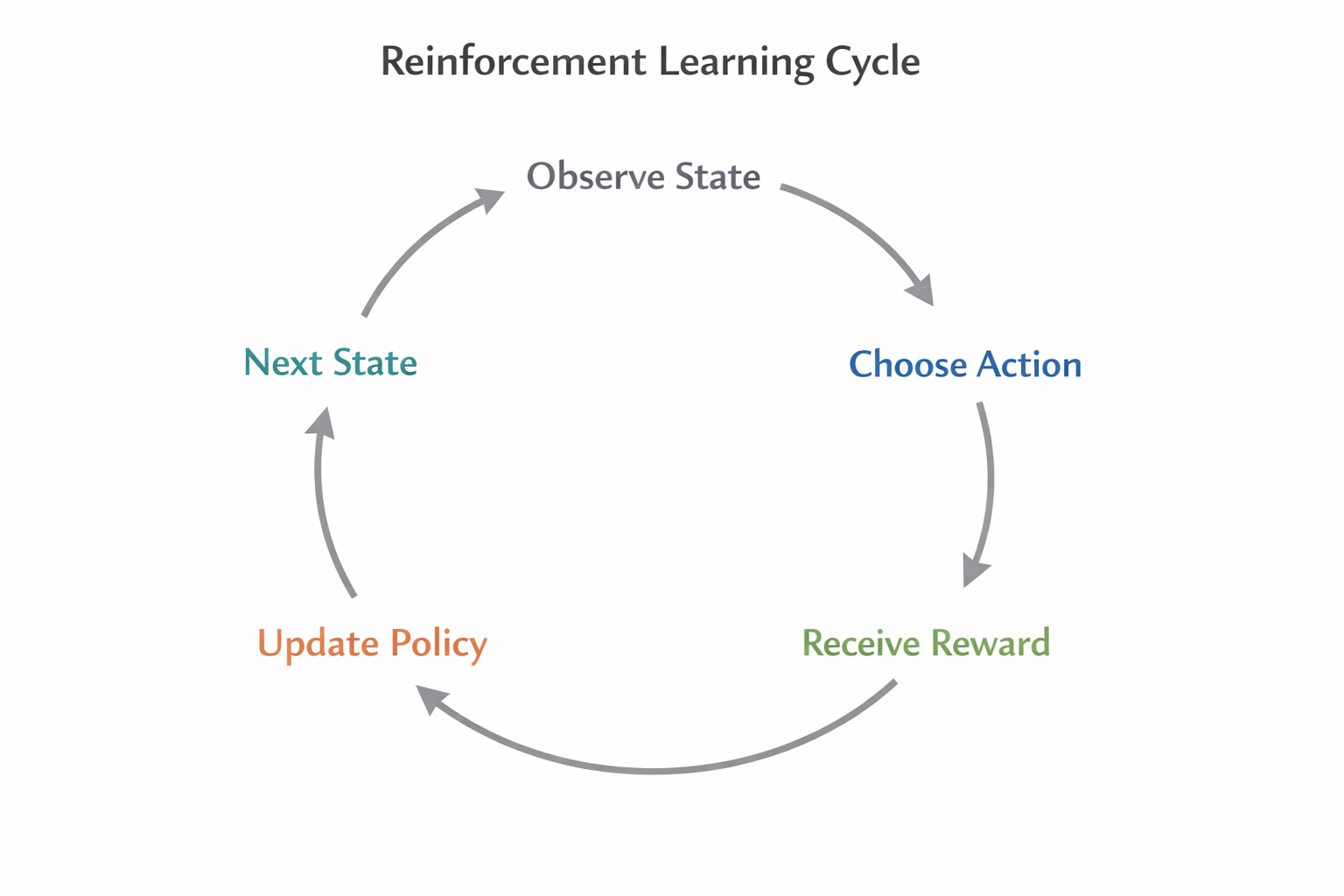
- 观察 (Observe): 小狗看到状态 StS_tSt(主人拿着肉干站在面前)。
- 决策 (Act): 小狗的大脑(策略)决定做一个动作 AtA_tAt(比如尝试“坐下”)。
- 反馈 (Feedback):
- 环境发生变化,变成了新状态 St+1S_{t+1}St+1(主人笑眯眯的,肉干递过来了)。
- 环境给出一个奖励 RtR_tRt(吃到肉干,好开心!)。
- 学习 (Learn): 小狗更新自己的大脑认知——“在这个状态下,做这个动作是对的!”
这个循环不断重复,S0→A0→R0→S1→A1→R1…S_0 \to A_0 \to R_0 \to S_1 \to A_1 \to R_1 \dotsS0→A0→R0→S1→A1→R1…,直到学会为止。
四、进阶概念
如果小狗只是看到肉干就坐下,那还是初级阶段。强化学习之所以强大,是因为它能处理更复杂的问题。这里有两个关键概念:
1. 延迟奖励 (Delayed Reward) —— “放长线钓大鱼”
这是 RL 最难也最强的地方。我们以下围棋(AlphaGo)举例:
-
情况:你在第 10 步下了一颗子,当时可能看不出好坏(奖励是 0)。直到第 200 步棋局结束,你赢了(奖励 +1),你才知道第 10 步那颗子是“神之一手”。
-
原理:智能体不能只看眼前的利益(Immediate Reward),而要学会最大化未来的累计奖励 (Cumulative Reward)。它要学会“为了最后的胜利,现在甚至可以牺牲一点利益”。
2. 探索 vs. 利用 (Exploration vs. Exploitation) —— “要不要尝鲜?”
这是智能体每天都要纠结的哲学问题。
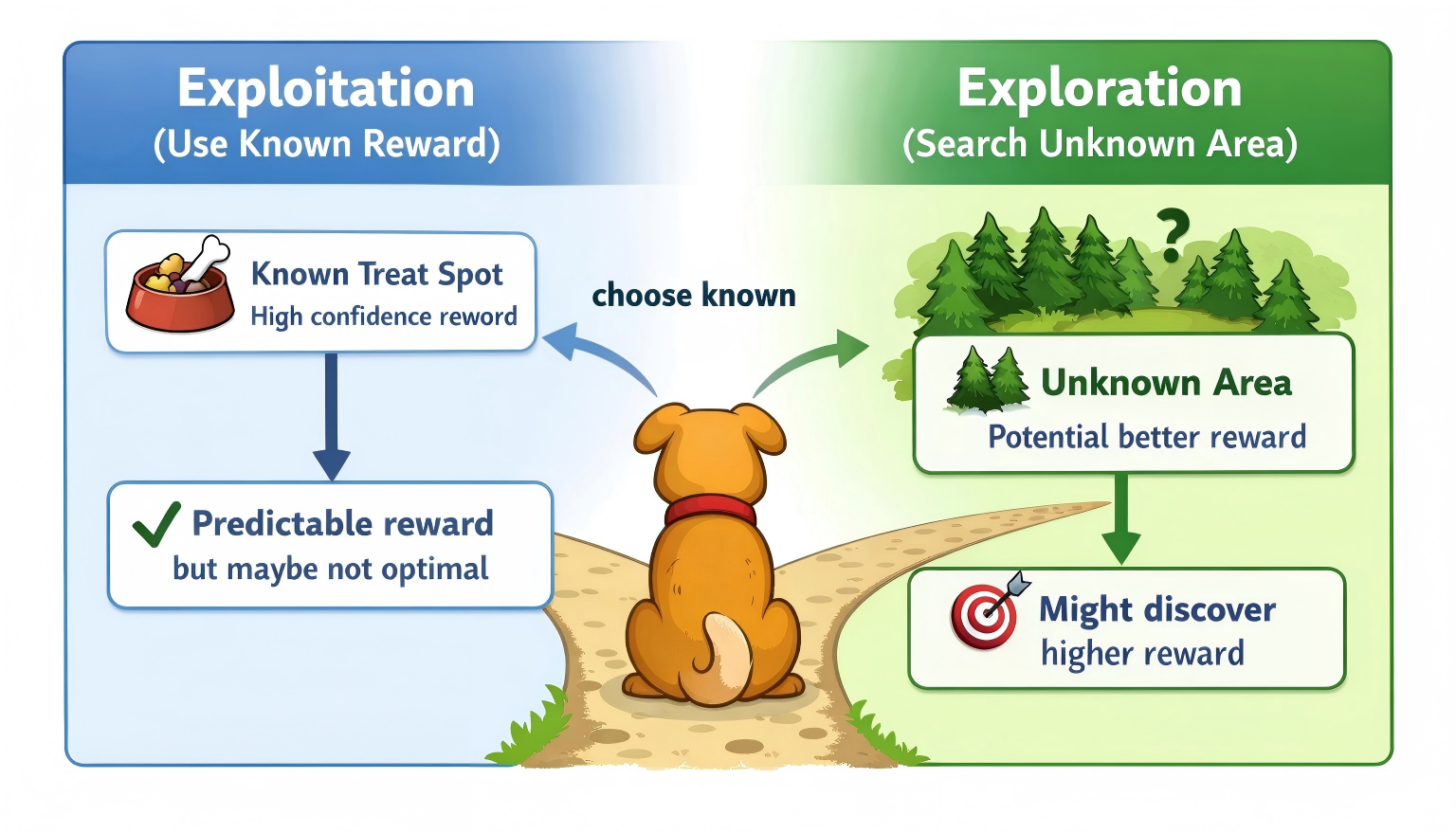
-
利用 (Exploitation):小狗知道“坐下”有肉吃,所以它每次都坐下,确信能拿到奖励。但也有缺点:也许“翻跟头”能拿到两块肉干呢?它如果不试,永远不知道。
-
探索 (Exploration):小狗决定今天不坐下了,试试“转圈圈”。虽然有风险存在:可能没肉吃(0分),甚至被骂(-分)。但也有机会:万一发现转圈圈给两块肉(发现新大陆!)。
-
结论:好的 RL 算法必须在“利用已知经验”和“探索未知可能”之间找平衡。通常在训练初期多探索(乱试),后期多利用(求稳)。
五、强化学习的“大脑” —— 策略与价值
小狗脑子里到底装了什么?在计算机里,通常有两种形式来存储“智慧”:
1. 策略 (Policy, π\piπ) —— “行动指南”
通俗理解:就像一本 “行为手册”,直接告诉智能体 “在这个状态下,该做什么动作”。
-
小狗案例:小狗的大脑里刻下了规则 ——“听到‘坐下’指令 → 执行坐下动作”,这就是它的策略。
-
技术流派:Policy-based(直接学策略),比如 PPO 算法,直接输出动作概率,适合连续动作控制(如机器人走路)。
2. 价值函数 (Value Function, V/Q) —— “局势评分系统”
这就好比一个评分系统。它不直接告诉你要做什么动作,而是评估“你现在处的这个境地,未来大概率能拿多少分”。
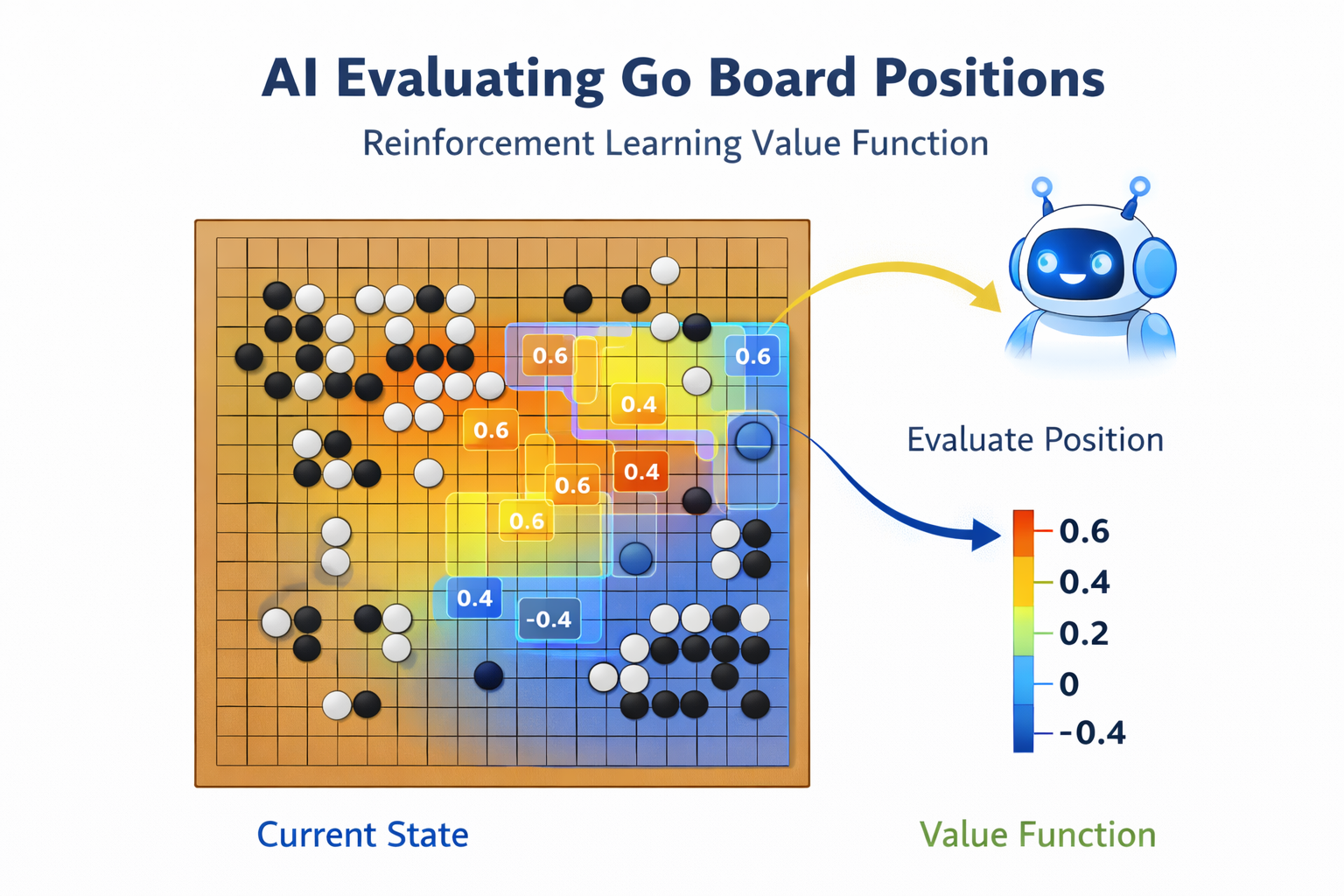
比如下围棋,虽然还没赢,但盘面上我占尽优势,价值函数就会打出“99分”的高分;如果我也许能吃对方一个子,但大局已定我要输了,价值函数就会打低分。其目的是通过判断哪个状态分高,引导智能体往那个方向走。
RL有三大算法流派:Policy-based、Value-based、Actor-Critic,在实际算法中,有的算法直接学习策略(Policy-based),有的先学习价值函数再推导策略(Value-based),还有的同时学习两者(Actor-Critic)。
六、现实生活中的应用
虽然我们用小狗举例,但 RL 正在改变世界:
- ChatGPT (RLHF)这是一个著名的应用。ChatGPT 写出回答后,人类老师会给它打分(这就相当于给小狗肉干)。通过人类反馈的强化学习 (RLHF),ChatGPT 学会了如何说话更像人、更讨喜。
- 推荐系统 (抖音/淘宝): 你(环境)不断刷视频。系统(Agent)决定推什么视频(Action)。你看完了点赞(Reward +1),划走(Reward -1)。系统通过强化学习,疯狂学习怎么推荐才能让你停不下来。
- 机器人控制: 波士顿动力的机器狗,甚至不用写死代码教它怎么走,而是给它设定目标“向前移动不摔倒”,让它在模拟环境里摔几万次,自己学会奔跑和后空翻。
总结
强化学习的本质,就是让智能体在环境中自主学习的闭环系统:以智能体(Agent)为核心,通过观察状态(State)、执行动作(Action)、接收奖励(Reward),不断更新策略(Policy/Value),最终实现 “最大化长期收益” 的目标。
从训狗的简单直觉,到围棋的复杂决策,再到 ChatGPT、推荐系统的现实落地,强化学习始终遵循 “试错 - 奖惩 - 迭代” 的底层逻辑。它不是冰冷的数学公式,而是模拟生物学习方式的 AI 智慧,也是未来机器人、智能助手、游戏体验的核心驱动力。接下来,你可以从 “训狗” 案例延伸到具体算法实践,真正把 RL 的逻辑落地~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 26
26 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)