CVPR 2026 | 手机视频秒变4D场景!清华&理想联合提出MoRe:实时、抗动态干扰的4D重建神器
想象一下,你拿着手机随手拍了一段街景视频,里面有走动的人群、穿梭的车辆。如果能立刻把这段视频转化为一个包含时间维度的动态3D数字孪生世界(即4D重建),是不是非常酷炫?
传统的重建技术在静态场景下表现完美,但一旦遇到动态物体,模型常常会“晕头转向”,导致相机轨迹和深度估计全部崩溃 。现有的优化方法虽然能缓解这个问题,但计算成本太高,根本无法做到“实时” 。
今天,我们要解读由清华大学和理想汽车团队联合提出的一项重磅研究:MoRe (Motion-aware Feed-forward 4D Reconstruction Transformer) 。它不仅能从单目视频中高效恢复动态3D场景,还能做到极速的流式推理 。

- 论文标题:MoRe: Motion-aware Feed-forward 4D Reconstruction Transformer
- 论文链接:https://arxiv.org/abs/2603.05078v2
- 代码链接:https://hellexf.github.io/MoRe/
为什么4D重建这么难?
在进行3D或4D重建时,模型需要准确估计每一帧画面的“相机姿态”(也就是你拿着手机的位姿)和“深度信息” 。
但是,当场景中有物体在移动时(比如突然跑过去一只狗),模型常常会分不清“到底是相机在动,还是世界在动” 。传统的基于 Transformer 的大模型(如 VGGT)在处理这类视频时,注意力会被移动的物体分散,导致特征被污染,最终预测出的相机参数精度大打折扣 。
为了解决这个问题,MoRe 团队提出了两个绝妙的思路:
-
让模型学会“无视”动态物体,专注静态背景 。
-
专门设计适合视频流的“记忆机制”,保证实时处理且不丢失全局视野 。
核心黑科技一:Attention-Forcing(注意力强制)机制
怎么才能让模型自动忽略画面里的移动物体呢?MoRe 的做法非常巧妙:在训练阶段“打个小抄”,但在推理阶段“闭卷考试”。
研究团队在训练时引入了真实的动态遮罩(Ground-truth motion masks)。他们将画面分成一个个小块(Patch),并通过遮罩计算出每一个图像 Token 的“静态得分”(Motion score,值越大代表越静止):
ai=1−1s2∑(u,v)∈mimi(u,v)a_{i}=1-\frac{1}{s^{2}}\sum_{(u,v)\in m_{i}}m_{i}(u,v)ai=1−s21(u,v)∈mi∑mi(u,v)
这个得分 aia_{i}ai 的范围在 [0,1][0,1][0,1] 之间,代表了我们对图像 Token 先验的认知 。
接着,MoRe 采用了一种 Attention-forcing(注意力强制) 策略,用一个专门的损失函数来监督相机的注意力权重 αi\alpha_{i}αi:
Latn=1M∑i=1Mmax(0,ai−C)⋅αi\mathcal{L}_{atn}=\frac{1}{M}\sum_{i=1}^{M}max(0,a_{i}-C)\cdot\alpha_{i}Latn=M1i=1∑Mmax(0,ai−C)⋅αi
简单来说,这个公式的作用是:如果某个区域明明在剧烈运动,但相机的注意力 αi\alpha_{i}αi 却死死盯着它,模型就会受到严厉的“惩罚” 。

论文中的 Figure 3 直观展示了这种机制的威力。在对比中,传统的 VGGT 模型把注意力均匀地分散在了骑车的人(动态)和背景上,导致预测混乱 。而经过 Attention-forcing 训练的 MoRe 模型,其注意力如同被“净化”了一般,牢牢锁定在静态的地面和墙壁上 。
最棒的是,这完全是训练时的技巧。在实际使用(推理)时,你不需要输入任何遮罩,模型已经形成了肌肉记忆,自动懂得避开动态干扰 。
核心黑科技二:分组因果注意力与全局优化
解决了动态干扰,接下来要解决的是“速度”和“连贯性”问题。处理长视频如果一次性把所有帧塞进大模型,显存会瞬间爆炸 。
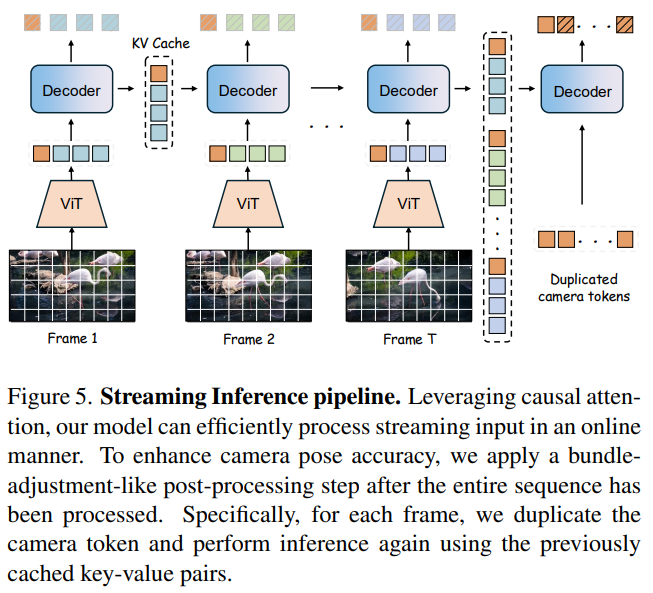
因此,MoRe 采用了类似大语言模型(LLM)的 流式推理(Streaming Inference)。
1. 分组因果注意力 (Grouped Causal Attention)
传统的因果注意力(Causal Attention)会把所有 Token 排成一列,后面只能看前面。但这在图像里行不通,因为同一帧画面里的左上角和右下角是需要互相看到的 。
MoRe 创新性地设计了 分组因果注意力:
-
在同一帧画面内,Token 可以互相看到(保持空间一致性)。
-
在不同帧之间,严格遵守时间顺序,当前帧只能看到过去的帧(保持时间因果性)。
每一帧的特征提取可以用以下公式表示:
Ft=Attn(Qt,[K1:t−1,Kt],[V1:t−1,Vt])F_{t}=Attn(Q_{t},[K_{1:t-1},K_{t}],[V_{1:t-1},V_{t}])Ft=Attn(Qt,[K1:t−1,Kt],[V1:t−1,Vt])
这种设计让 MoRe 可以像看直播一样,一帧一帧顺畅地处理视频,而不需要把之前的画面重新计算一遍,大大提升了效率 。
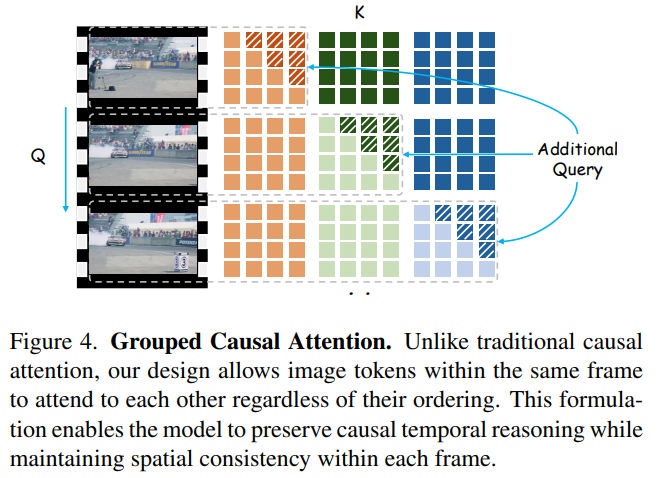
论文中的 Figure 4 清晰地画出了这种“楼梯状”的注意力掩码矩阵,确保了时间上的因果性与空间上的双向可见性 。
2. 轻量级全局优化 (BA-like Refinement)
不过,流式处理有个通病:走得太远,容易忘了初心(误差累积)。
为了解决这个问题,MoRe 在处理完整个视频序列后,会进行一次类似 BA(Bundle Adjustment,光束平差法)的全局修正。系统会把缓存的相机查询 Token(Camera Queries)拿出来,对着所有帧的特征重新做一次全局注意力计算:
Ctopt=Attn(Qtcam,[K1:T],[V1:T])C_{t}^{opt}=Attn(Q_{t}^{cam},[K_{1:T}],[V_{1:T}])Ctopt=Attn(Qtcam,[K1:T],[V1:T])
这相当于在极短的时间内,对全局的相机轨迹进行了一次快速的“对齐和微调”,保证了长序列中的几何一致性 。
性能表现:快、准、狠!
经过大模型时代的“暴力美学”微调(在多达12个不同的动静态数据集上训练),MoRe 展现出了极其强悍的泛化能力 。
-
极高的精度: 在 Sintel、TUM-dynamics 等极其具有挑战性的动态数据集上,MoRe 无论是在相机位姿估计还是视频深度估计上,都全面碾压了现有的流式处理基线模型(如 Stream3R, CUT3R)。
-
丝滑的速度: 尽管能够输出高质量的 4D 几何结构,MoRe 在 KITTI 数据集上的推理速度仍然达到了惊人的 30.09 FPS!这意味着它完全具备了在自动驾驶、AR/VR 设备上进行实时重建的潜力 。

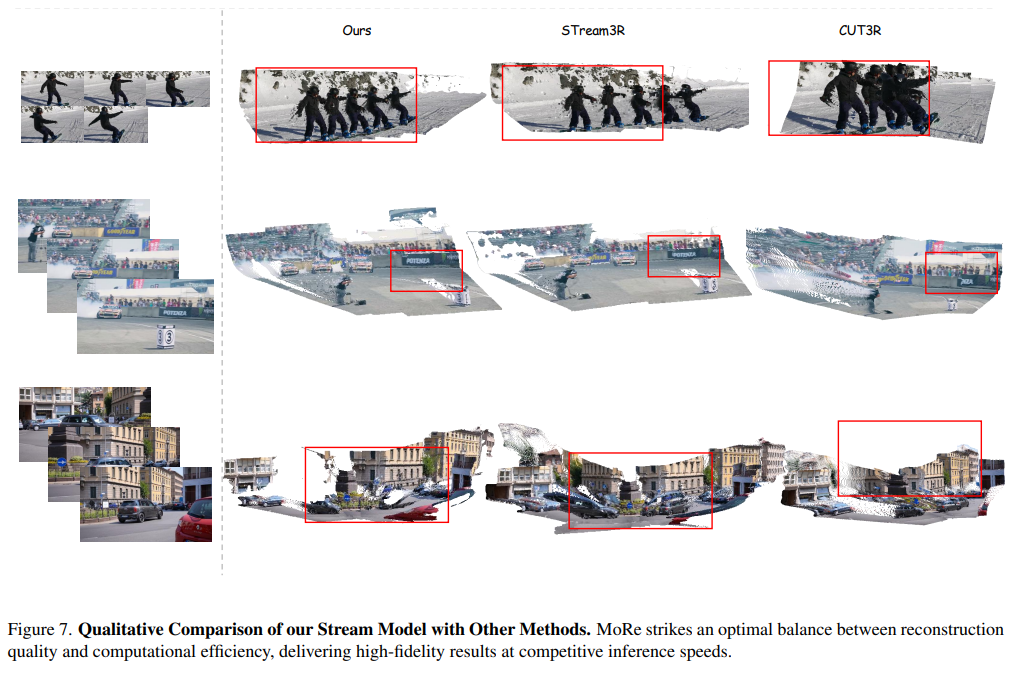
论文 Figure 6 和 7 展示了定性的点云重建对比。其他方法往往在人群移动或复杂背景下产生大面积的几何扭曲,而 MoRe 重建出的场景不仅清晰,且物体的运动轨迹与静态背景层次分明 。
总结
MoRe 为我们展示了一条优雅且高效的 4D 重建新路径:
-
不需要额外的运动分割模块,仅仅通过巧妙的 Attention-Forcing 训练策略,就让大模型具备了分离动态物体和静态背景的本能 。
-
融合分组因果注意力和全局对齐,在保证极高实时性的同时,守住了长时间几何一致性的底线 。
从学术走向落地,MoRe 让单目视频实时 4D 重建变得更加触手可及。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)