图解batchnorm,layernorm以及RMSnorm
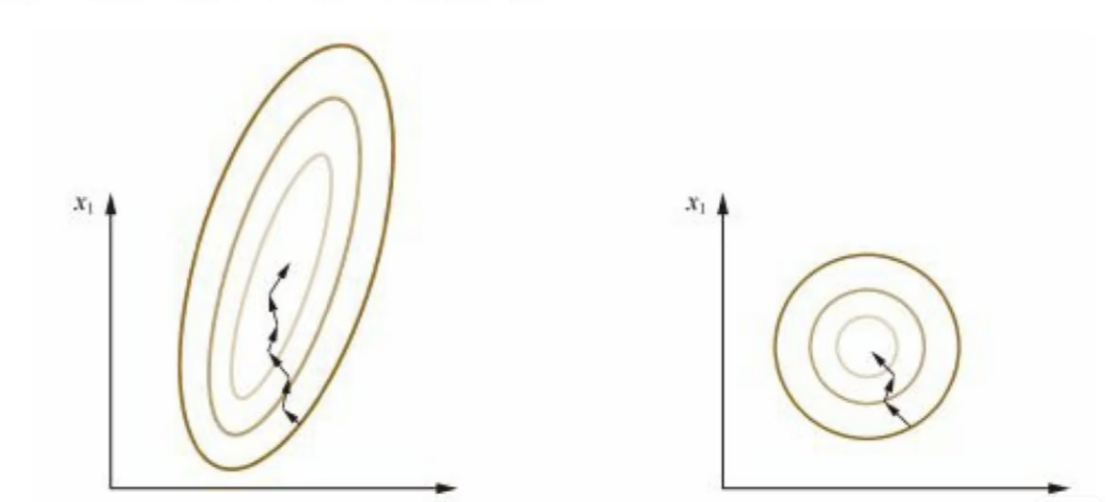
归一化是神经网络训练中控制特征数值范围、稳定梯度的关键操作。归一化将模型输出限制在相对固定的范围(如 $[-1, 1]$),避免参数过大或过小引发的梯度爆炸和弥散。同时,归一化将狭长的椭圆优化空间转化为圆形的分布,降低了梯度下降寻找极小值的难度。
Batchnorm,Layernorm的公式是一样的:
$y = \frac{x - \mathrm{E}[x]}{\sqrt{\mathrm{Var}[x] + \epsilon}} * \gamma + \beta$
但二者期望 $\mathrm{E}[x]$ 和方差 $\mathrm{Var}[x]$ 的计算维度不同。
1. BatchNorm:batch维度上做平均(跨batch)
本文主要探讨最常见的BatchNorm2d,BatchNorm3d和BatchNorm1d原理类似。
以下设定张量的形状为(B,C,H,W),B=3,C等于3,H等于3,W等于3,未归一化之前的张量如下图所示,红色部分为各个像素的R通道,数字代表RGB值。
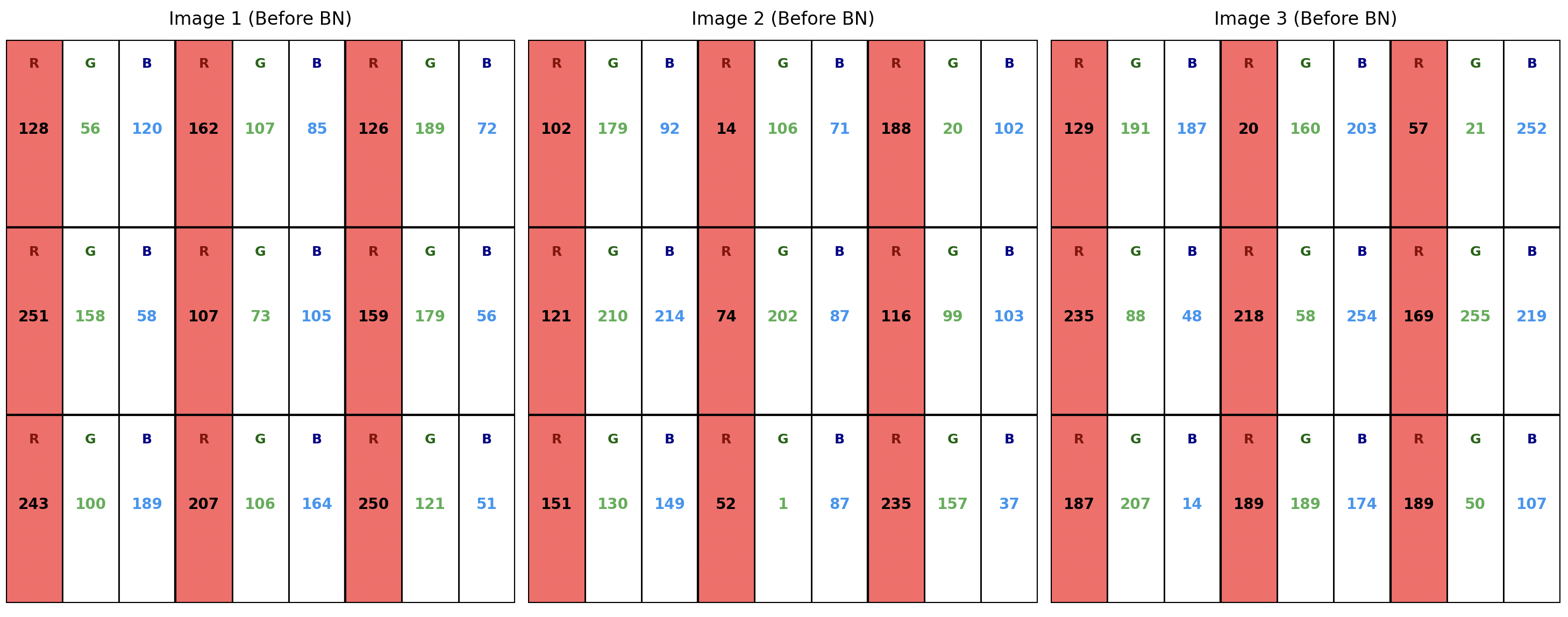
当对R通道进行归一化时,BN 会提取这 3 张图片中所有的红色像素点。在这个设定中,参与单次均值 $\mu$ 和方差 $\sigma^2$ 计算的数据点总数为 $3 (\text{Batch}) \times 3 (\text{Height}) \times 3 (\text{Width}) = 27$ 个,即图中的27个红色方块。R通道归一化之后的结果如下图所示,其余两个通道同理。
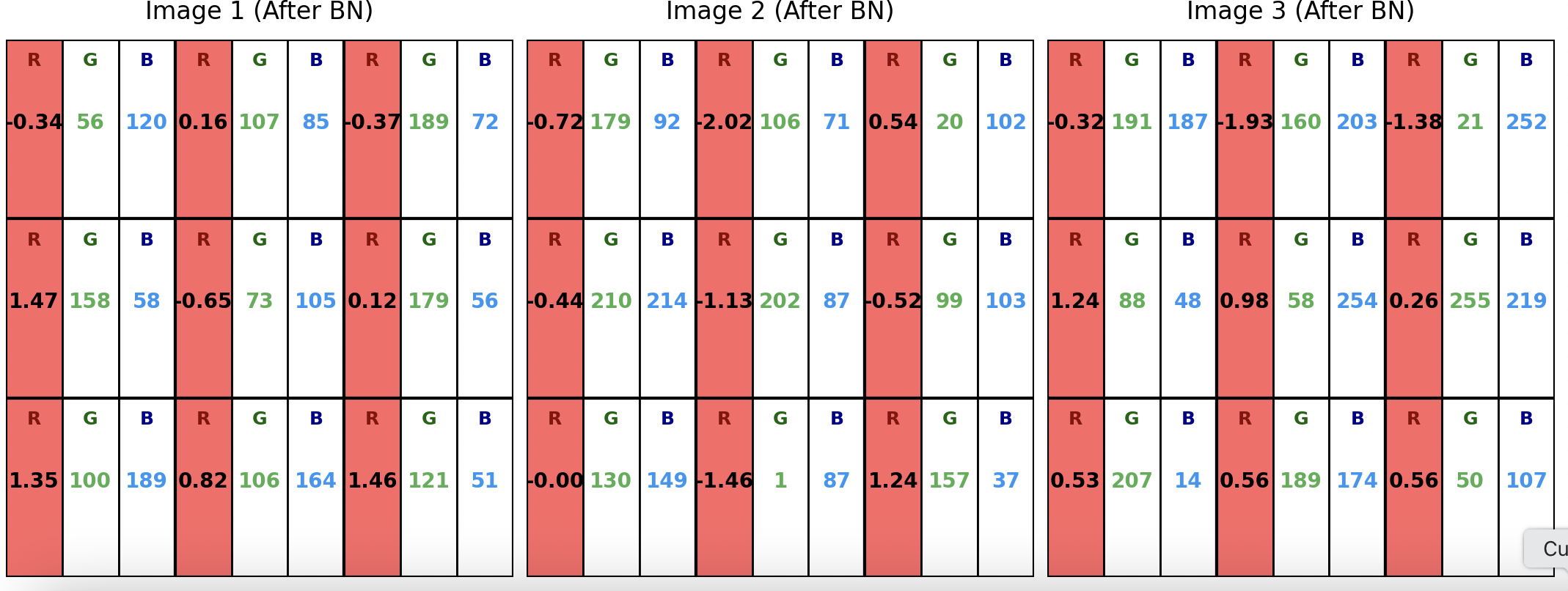
对比归一化前后的数据图可知,原始 0-255 范围的 R 通道整数被转化为以 0 为中心、标准差为 1 的浮点数。在此计算与替换的过程中,G 通道和 B 通道的数据保持绝对不变,证明了 BN 具备通道独立性。由于统计依赖于跨图片聚合,当 Batch Size 过小时,这 27 个或更少的数据点计算出的均值与方差将失去对全局数据分布的代表性,导致训练过程产生震荡。因此Batchnorm适合在batchsize较大时使用
nn.BatchNorm2d 参数解析
bn = nn.BatchNorm2d(
# 1. num_features (int)
# 含义:输入张量的特征通道数 C。
# 对应形状:输入满足 (N, C, H, W) 时,此参数等于 C。
# 作用:决定层内分配多少参数空间。模型会创建长度为 num_features 的一维张量
# 来存储各个通道独立的均值、方差、缩放因子(gamma)和平移因子(beta)。
# 必填性:必填,不可省略。
num_features=num_features,
# 2. eps (float)
# 含义:公式中的 epsilon。
# 默认值:1e-05
# 作用:加在方差分母上的极小值,用于保证数值稳定性。
# 防止方差计算结果为 0 时引发除以 0 的运行时报错 (NaN)。
eps=1e-05,
# 3. momentum (float)
# 含义:计算全局均值和方差移动平均 (Running Average) 的动量系数。
# 默认值:0.1
# 作用机制:在 model.train() 阶段更新全局统计量。
# PyTorch 特殊逻辑:与普通优化器动量方向相反,公式为:
# x_new = (1 - momentum) * x_old + momentum * x_t
# 设为 0.1 意味着每次保留 90% 的历史记录,吸纳 10% 的当前 Batch 新数据。
momentum=0.1,
# 4. affine (bool)
# 含义:是否包含可学习的仿射变换参数。
# 默认值:True
# 作用:
# - True: 实例化可学习参数 weight (gamma) 和 bias (beta)。
# 允许网络在反向传播时按需恢复原本被破坏的特征分布。
# - False: 仅执行纯粹的标准化操作 (相当于 gamma=1, beta=0)。
affine=True,
# 5. track_running_stats (bool)
# 含义:是否跟踪整个训练过程中的全局均值和方差。
# 默认值:True
# 作用:
# - True: 训练期不断更新 running_mean 和 running_var,评估期 (model.eval()) 直接使用。
# - False: 层内部不维护全局统计量,评估期也会强制使用当前测试输入 Batch 的局部统计量。
track_running_stats=True
)
# 前向传播执行
output = bn(x)注:必须手动传入通道数的原因:模型在定义阶段(实例化时),需要在内存中为两个可学习参数——缩放因子 $\gamma$ (weight) 和平移因子 $\beta$ (bias)分配固定长度的张量。Optimizer在数据输入进行前向传播之前,就必须锁定这些参数的地址并进行注册。如果框架等待前向传播时根据输入数据动态推断维度,优化器将无法在初始化阶段获取完整的参数列表。
2. LayerNorm:在channel上做平均
LayerNorm 将聚合方向从“跨样本聚合”改为“样本内独立聚合”。 以 Transformer 处理的 NLP 任务为例,输入张量的形状通常为 [Batch, Sequence_Length, Hidden_Size]。
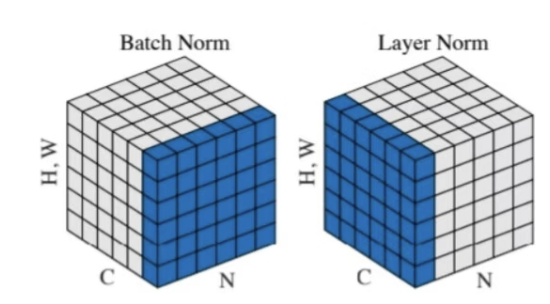
从上图中可以看出,相比于BN,LN 针对每一个Token的特征维度独立计算均值和方差。这种设计的核心优势在于解决了变长序列的 Padding污染问题。在 BN 的跨样本计算逻辑下,短句尾部的 Padding(0)会与长句尾部的真实词向量混合计算,拉低全局均值并干扰方差;而 LN 使得每个词向量的归一化过程仅受自身数值影响。无论 Batch 内有多少 Padding,有效序列部分的特征分布均保持纯净。
ViT(Vision Transformer)同样采用 LN。图像被切分为 Patch 并展平为序列后,模型关注的是单个 Patch 内部特征向量的数值稳定性,强制使用依赖空间位置聚合的归一化方式会破坏图像原本的全局明暗语义。
nn.LayerNorm 参数解析
# =========================================================
# LayerNorm 参数实例化与详细说明
# =========================================================
ln = nn.LayerNorm(
# 1. normalized_shape (int or list or torch.Size)
# 含义:需要进行归一化的维度形状。它必须匹配输入张量的后缀维度(Suffix Matching)。
# 作用:决定了黑框(统计范围)的包裹区域。模型会在这些指定的维度内部计算均值和方差,
# 同时也会根据这个形状初始化可学习的参数 gamma (weight) 和 beta (bias)。
# 示例:
# - 传入 hidden_size (整数): 表示只对最后一个特征维度做归一化,前面所有维度保持独立。
# - 传入 [seq_len, hidden_size] (列表): 表示在序列和特征两个维度构成的块内统一做归一化。
# 必填性:必填,不可省略。
normalized_shape=hidden_size,
# 2. eps (float)
# 含义:公式中的 epsilon。
# 作用:加在方差分母上的极小常数。当特征方差极小或为 0 时,防止出现除以 0 的计算溢出。
# 默认值:1e-05
eps=1e-05,
# 3. elementwise_affine (bool)
# 含义:是否包含逐元素的可学习仿射变换参数。
# 作用:
# True: 实例化对应 normalized_shape 形状的 weight 和 bias。模型可以学习恢复原始特征表达的能力。
# False: 仅执行纯数学的标准化操作,强制均值为 0、方差为 1,不应用任何缩放和平移。
# 默认值:True
elementwise_affine=True,
# 4. bias (bool)
# 含义:是否在仿射变换中保留平移参数 (beta)。
# 作用:仅在 elementwise_affine=True 时生效。如果设为 False,则只学习缩放 weight,
# 忽略 bias,有助于在某些大模型架构中减少微小的参数冗余。
# 默认值:True
bias=True
)
# 前向传播执行
output = ln(x)注:传入的 normalized_shape 必须与输入张量形状的最后几个维度严格一致。例如,对于形状为 (2, 3, 4, 5) 的张量:
-
若传入
[4, 5],模型将在最后两个维度构成的 $4 \times 5$ 的块面上计算单一均值和方差,前两个维度保持独立。 -
若传入
[5],模型仅在最后一个维度(长度为5)的一维数组内计算。未传入的维度之间互不干扰。
为什么transformer使用layernorm?
1.大模型多机多卡训练时,BN 需要在不同机器间进行额外的通信以计算全局分布,而 LN 仅在单样本内部计算,无需跨卡通信。
2.大模型训练更侧重于长上下文(如 8k、32k),导致硬件无法支持较大的 Batch Size。BN 极度依赖大 Batch Size 来保证统计量准确,而 LN 对 Batch Size 不敏感。
3.BN 预测时依赖训练期积累的全局均值和方差,若训练和测试数据分布不一致,会导致预测偏差。
3. RMSNorm:LayerNorm 的高效变体
RMSNorm (Root Mean Square Normalization) 是现代大语言模型(如 LLaMA 等)中广泛采用的归一化方案,属于 LayerNorm 的简化版本。
LN 的完整计算流程包含去中心化(减去均值 $\mu$)与缩放(除以标准差 $\sigma$)。RMSNorm 基于的研究假设是:去中心化操作对网络训练的稳定性贡献极小。因此,RMSNorm 舍弃了均值计算以及对应的平移可学习参数 $\beta$。
计算时,RMSNorm 直接对向量 $x$ 计算均方根:
$$\text{RMS}(x) = \sqrt{\frac{1}{n} \sum x_i^2 + \epsilon}$$
随后使用该 RMS 值直接对数据进行缩放除法操作。
移除均值计算不仅省去了减法步骤,还减少了底层数据在显存中的遍历读取次数,从而在超大规模模型训练中显著提升了计算吞吐量。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)