qwen3-->qwen3.5架构分析
一、qwen3系列
1、模型种类概览
稠密模型:
0.6B------1.7B------4B-------8B-------14B------32B
MOE架构模型:
30B-A3B--------------235B-A22B
与qwen2.5对比:
qwen3-1.7B
qwen2.5-3B
qwen3-4B
qwen3-8B
qwen3-14B
qwen3-32B
2、模型规模与适用场景
超小型模型(0.6B–1.7B)
适用于:
-
移动设备
-
边缘计算
-
资源受限环境
小型模型(4B–8B)
适用于:
-
个人电脑
-
汽车端侧
-
单 GPU 服务器部署
中型模型(14B–32B)
适用于:
-
企业级应用
-
高性能服务
大型 MoE 模型(30B-A3B / 235B-A22B)
特点:
-
提供顶级性能
-
同时优化计算资源需求
3、模型结构
Qwen2.5 与 Qwen3 结构对比
-
Qwen2.5-7B
-
28层
-
hidden dim = 3584
-
-
Qwen3-8B
-
36层
-
hidden dim = 4096
-
部分模型结构参数:
| 模型 | 层数 |
|---|---|
| Qwen3-0.6B | 28 |
| Qwen3-1.7B | 28 |
| Qwen3-4B | 36 |
| Qwen3-8B | 36 |
| Qwen3-14B | 40 |
| Qwen3-32B | 64 |
各尺寸架构(GQA):
| 模型 | 参数量 | 层数 | 头数(Q/KV) | 上下文 |
|---|---|---|---|---|
| Qwen3-0.6B | 0.6B | 28 | 16 / 8 | 32K |
| Qwen3-1.7B | 1.7B | 28 | 16 / 8 | 32K |
| Qwen3-4B | 4B | 36 | 32 / 8 | 32K |
| Qwen3-8B | 8B | 36 | 32 / 8 | 128K |
| Qwen3-14B | 14B | 40 | 40 / 8 | 128K |
| Qwen3-32B | 32B | 64 | 64 / 8 | 128K |
| Qwen3-30B-A3B | 总参数30B,激活3B | 48 | 32 / 4 | 128K |
| Qwen3-235B-A22B | 总参数235B,激活22B | 94 | 64 / 4 | 128K |
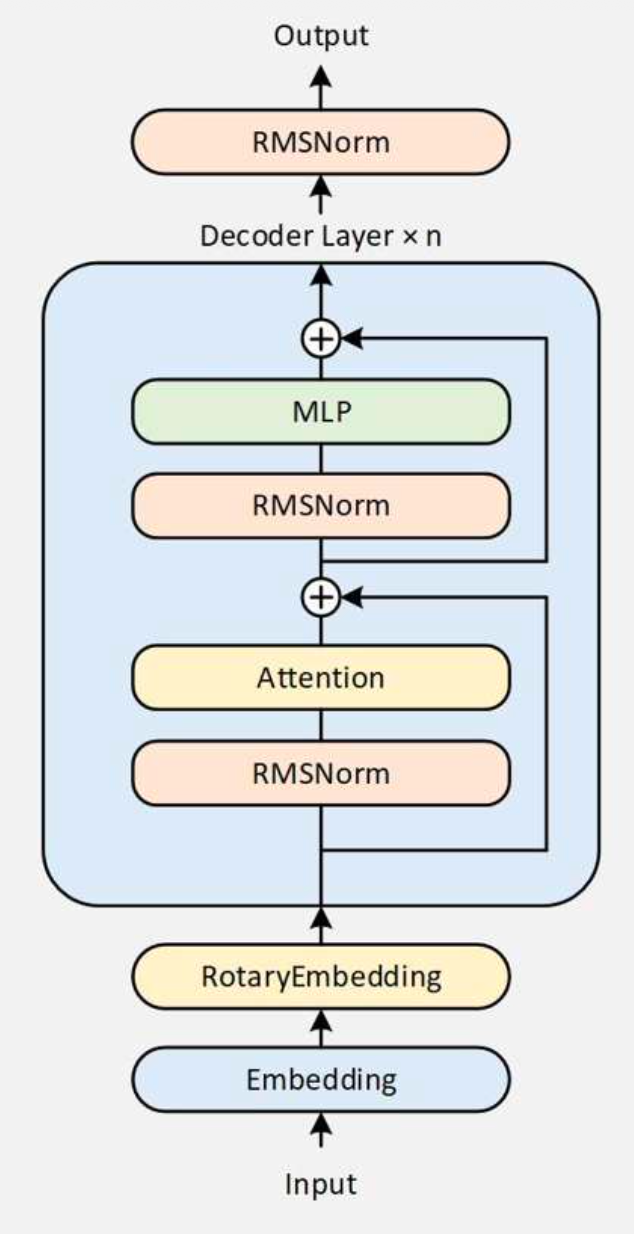
4、核心技术点分析
稠密模型:
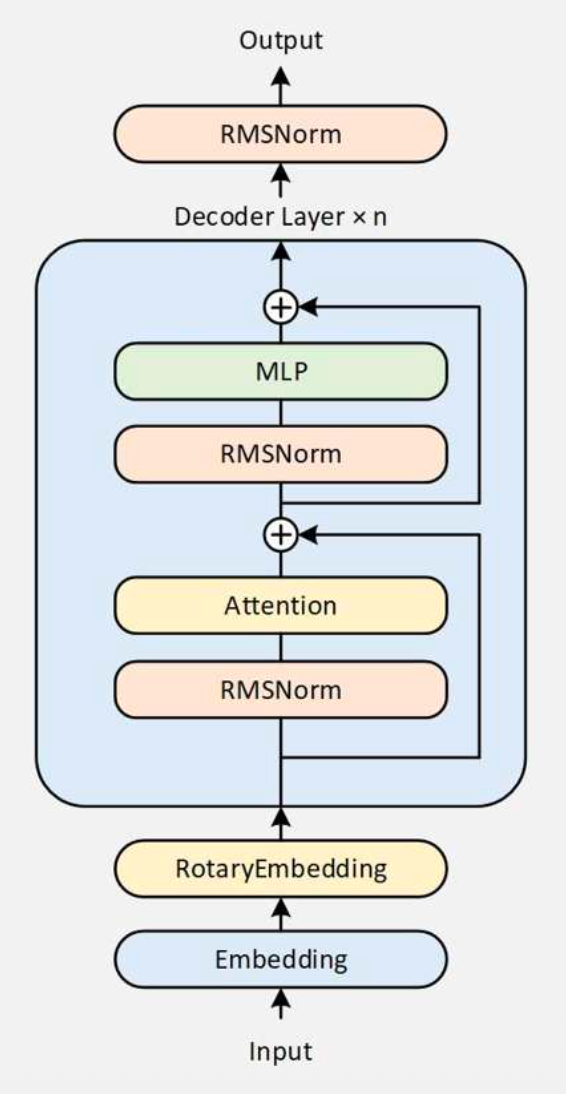
MLP 使用 SwiGLU
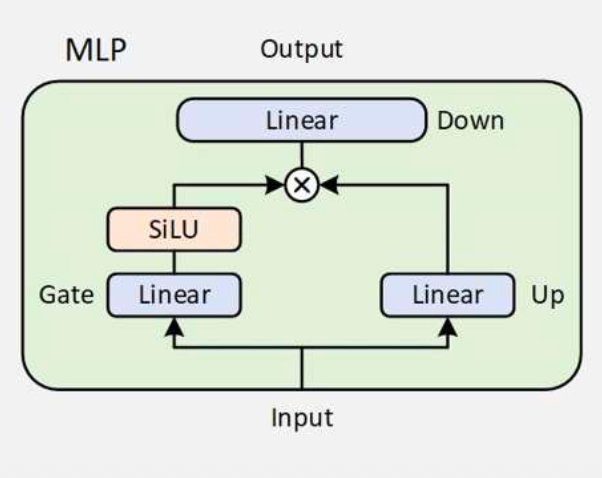
SwiGLU ( Gated Linear Unit with SiLU activation)
右侧 Linear 做信息的筛选和选择。
Attention
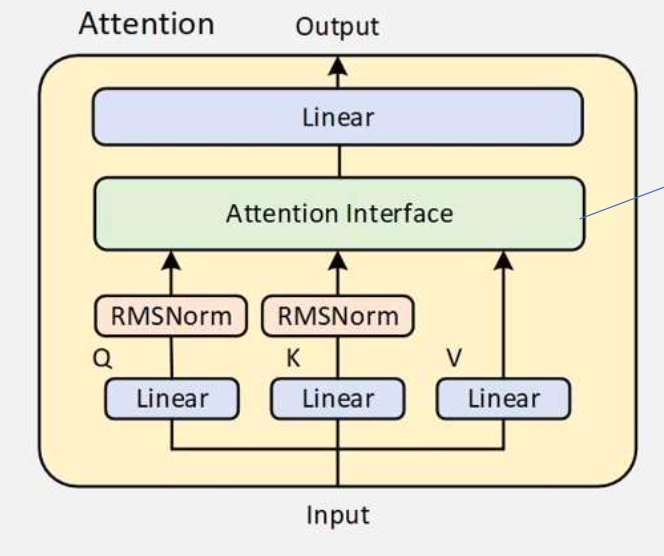
Attention中的 Attention Interface 采用GQA的格式,可降低显存。
RMSNorm作用:对Q和K做标准化,提高训练稳定性。
对于某个token,区别于传统Attention,它并不会看到其前面的全部 Attention 的信息。
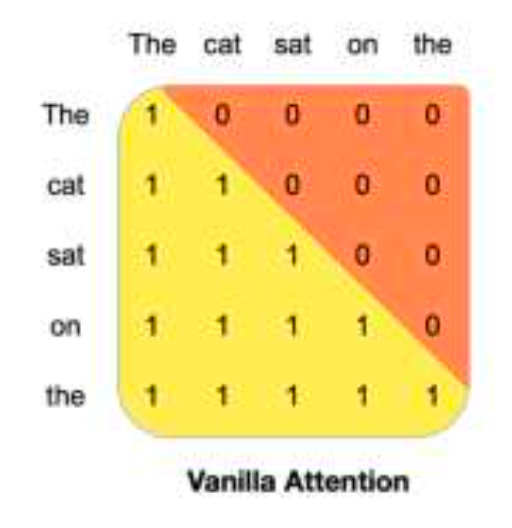

使用滑动窗口,只能看到前4096个(包含自己),上面例图只有3个,作用是增强长文本能力(长上下文)
MOE模型:
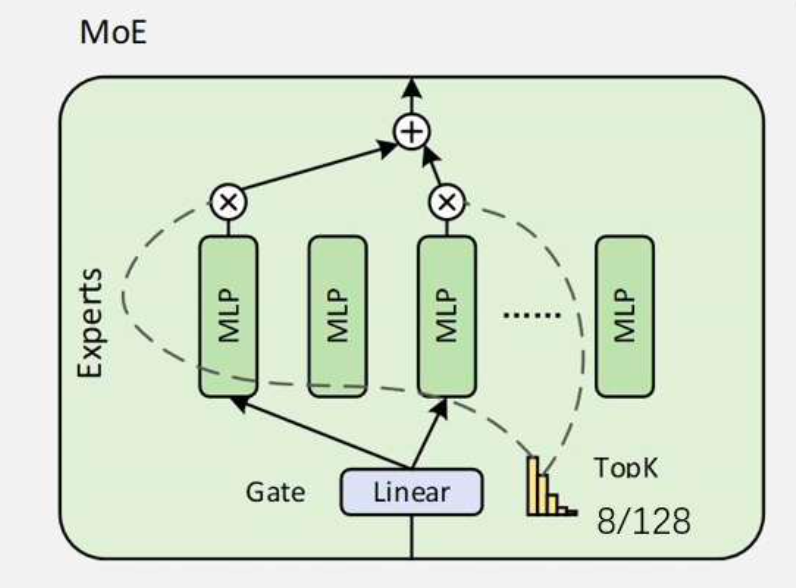
5、控制思考长度
思考情况下比不思考准确率要高,下面在4个数据集上的是测试结果
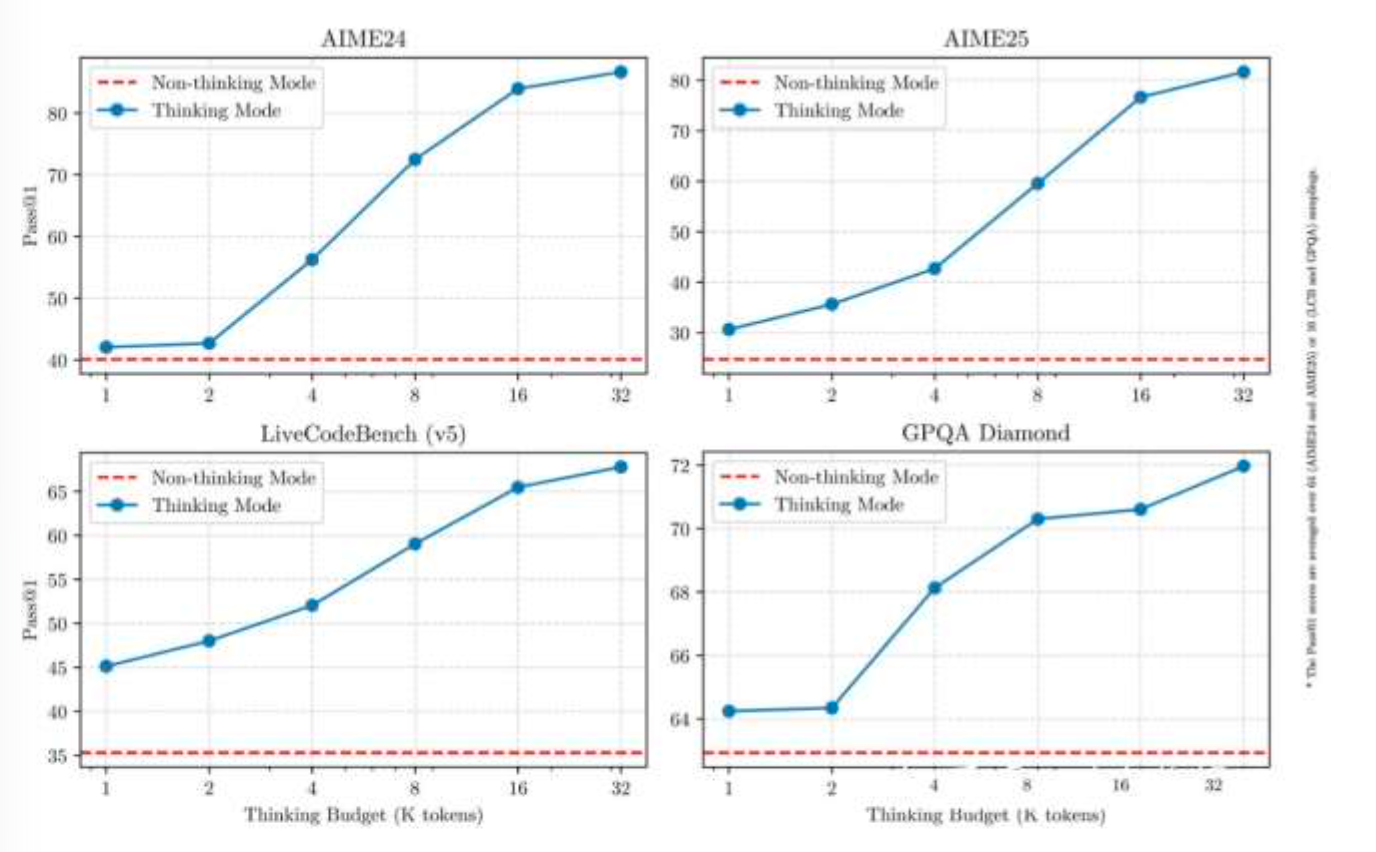
可以控制思考长度:
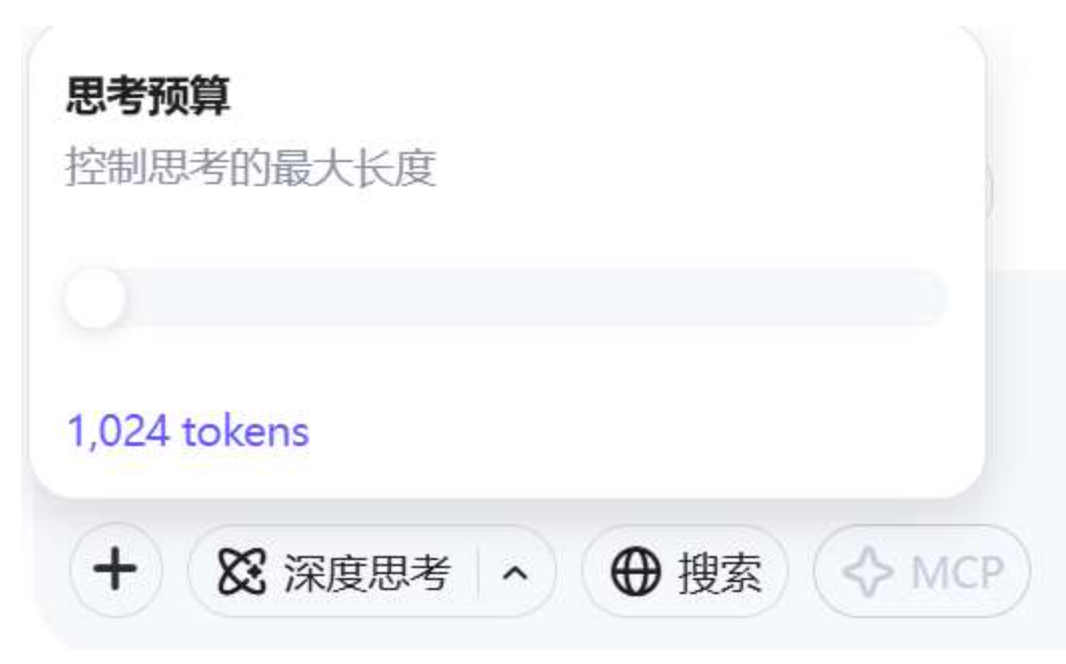
思考内容夹在 <think> </think> 之间,如果在prompt中传入了</think>,则输出不再进行think,如果不传入,则进行思考。(指令遵循能力比较强)
部署一个模型就可实现思考模型和非思考模型两种模式。
6、超参数
官方推荐的超参数配置:
Think模式:Temperature=0.6, TopP=0.95, TopK=20, MinP=0
非Think模式:Temperature=0.7, TopP=0.8, TopK=20, MinP=0
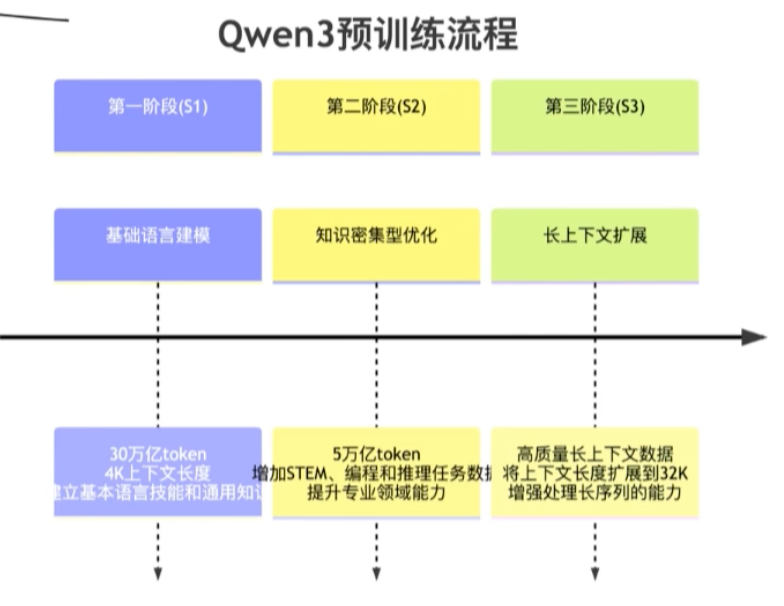
7、训练数据和方法
支持语言

训练主流语言 中文,英文,法文 数据量会比较大; 通过极为少量的平行语料对小语种启发和激活。
预训练
预训练数据来源多样化:
•• 网络爬取的高质量文本
•• 使用Qwen2.5-VL从PDF文档中提取的内容
•• 由Qwen2.5-Math和Qwen2.5-Coder合成的专业领域数据
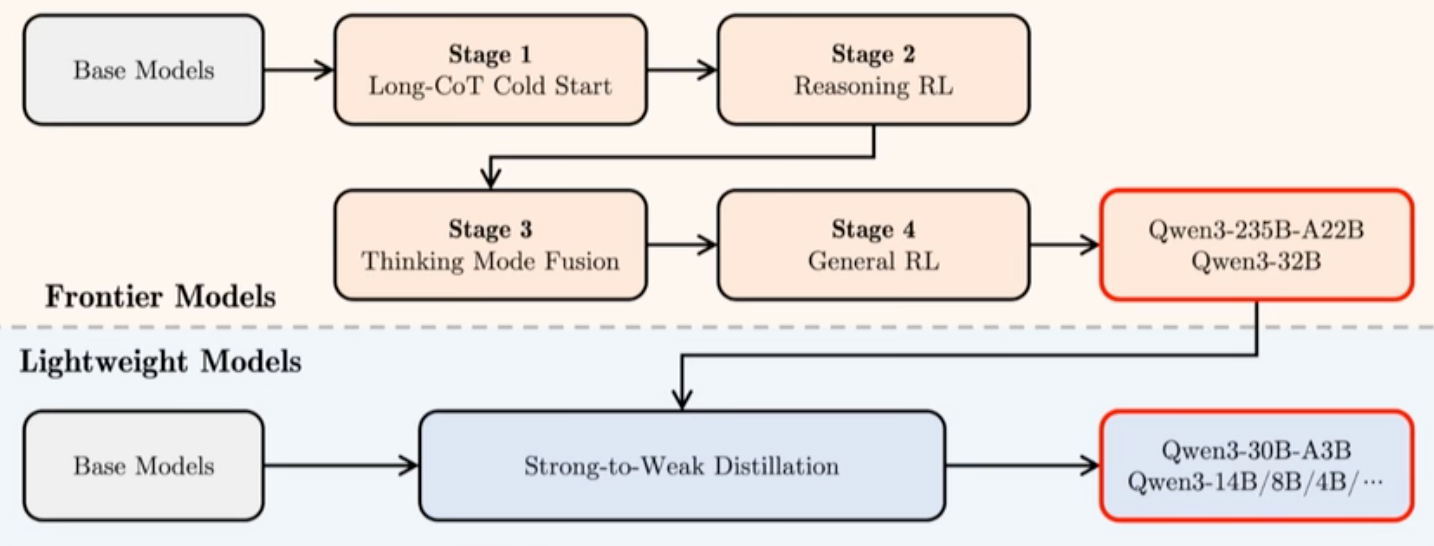
后训练
阶段1:长思维链冷启动
多样长思维链数据微调
涵盖数学、代码、逻辑推理等
说明:
第一阶段,使用多样的长思维链数据对模型进行了微调,涵盖了数学、代码、逻辑推理和 STEM 问题等多种任务和领域。这一过程旨在为模型配备基本的推理能力。
阶段2:基于规则的强化学习
利用规则奖励增强探索能力
大规模计算资源投入
说明:
第二阶段的重点是大规模强化学习,利用基于规则的奖励来增强模型的探索和钻研能力。
阶段3:思维模式融合
结合长思维链和指令微调数据
整合思考与非思考能力
说明:
第三阶段,在一份包括长思维链数据和常用的指令微调数据的组合数据上对模型进行微调,将非思考模式整合到思考模型中。确保了推理和快速响应能力的无缝结合。
阶段4:通用强化学习
20+领域任务RL优化
增强指令遵循和格式控制
说明:
第四阶段,我们在包括指令遵循、格式遵循和 Agent 能力等在内的 20 多个通用领域的任务上应用了强化学习,以进一步增强模型的通用能力并纠正不良行为。
为了开发能够同时具备思考推理和快速响应能力的混合模型,
四阶段的训练流程:
(1)长思维链冷启动,
(2)长思维链强化学习,
(3)思维模式融合,
(4)通用强化学习。
二、qwen3.5系列
1、快速了解
简介
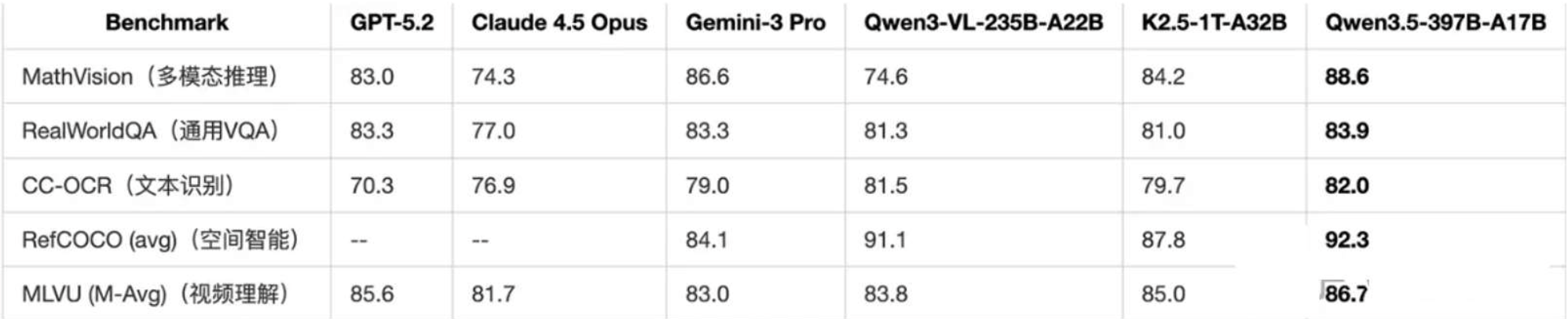
Qwen3.5系列397B-A17B原生视觉语言模型,基于混合架构设计,融合了线性注意力机制与稀疏混合专家模型,实现了更高的推理效率。在语言理解、逻辑推理、代码生成、智能体任务、图像理解、视频理解、图形用户界面(GUI)等多种任务中,均展现出与当前顶尖前沿模型相媲美的卓越性能。具备强大的代码生成与智能体能力,对于各类智能体场景具有良好的泛化性。
多项基准媲美甚至超越 GPT-5.2 和 Gemini-3-Pro 等顶级闭源模型。
- Coding (LiveCodeBench): 83.6 分。虽然略低于 Thinking 模式的 Qwen3-Max (85.9),但这是 Base 模型的能力,且仅激活 17B 参数,这效率非常恐怖。
- Math (AIME26): 91.3 分。这个分数意味着它基本上能解决绝大多数竞赛级数学题,接近人类顶尖选手水平。
- 长文本 (LongBench v2): 63.2 分,虽然不是最高,但考虑到线性注意力的引入,这是一个在于“精度”和“无限长度”之间做的极佳权衡。
语言扩展到了 201 种,一跃成为全球通用的世界模型。对小语种兼容性更强,意味着模型后续能够学习到更密集的世界知识和推理逻辑,
原生多模态训练也给千问3.5的视觉理解能力带来了飞跃。在多模态推理、通用视觉问答VQA、文本识别和文件理解、空间智能、视频理解等视觉基准测试中,Qwen3.5-Plus 已经超过GPT-5.2和Gemini 3 Pro等国外顶尖模型,达到了 SOTA。
示例:
按表格的方式,列出图片中菜品用到的食材,并计算出对应的市场价格,最后汇总一下,做这样一段饭,大概需要多长时间,多少钱?

稀疏化策略
Qwen 3.5-397B 采用了极致的稀疏化策略,在总参数量近 4000 亿的情况下,单次激活仅 170 亿参数,甚至低于 Qwen 3-235B 的激活规模 。
这意味着在保持更大知识容量的同时,单次推理的实际计算负担反而更低,整体效率进一步提升。
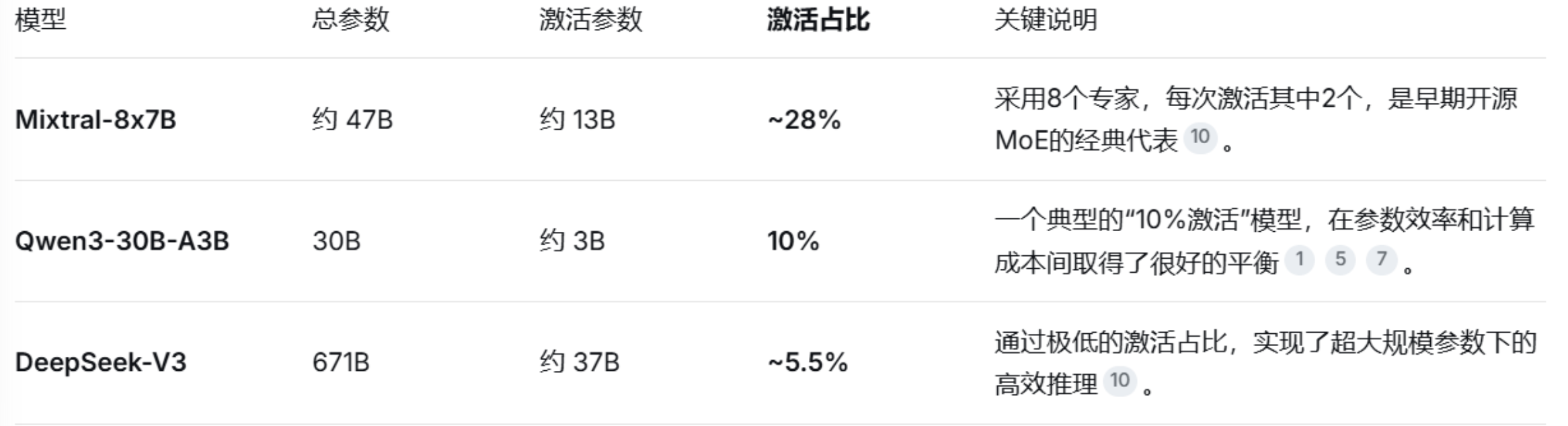
对比
Qwen3.5-Plus 的「以小博大」架构革命 397B vs 1000B
在过去两年的大模型军备竞赛中,行业普遍信奉「大力出奇迹」,参数量从千亿一路狂飙至万亿级别。这种「力大砖飞」的模式虽然推高了性能上限,但也让算力成本和部署门槛水涨船高。
Qwen3.5-Plus 则展示了一种更为灵巧的解法:不拼绝对体量,拼「聪明程度」与底层架构的极致效率。
具体而言,Qwen3.5-Plus 以 397B 的总参数量,实现了对自家万亿参数模型 Qwen3-Max 的性能超越,且多项基准测试媲美 Gemini-3-pro 和 GPT-5.2 等闭源第一梯队模型。
9月24日,2025云栖大会开幕,阿里通义旗舰模型Qwen3-Max重磅亮相,性能超过GPT5、Claude Opus 4等,跻身全球前三。Qwen3-Max包括指令(Instruct)和推理(Thinking)两大版本,其预览版已在 ChatbotArena 排行榜上位列第三,正式版性能可望再度实现突破。
相较上一代Qwen3-Max,部署成本下降60%、推理速度提升8倍。
Qwen3.5-Plus的API价格每百万Token低至0.8元,仅为Gemini 3 Pro的1/18
对于开发者来说,Qwen3.5-Plus只用了不到3970亿参数,激活仅170亿,性能就超过上一代万亿模型Qwen3.0-Max
2、模型架构
原生多模态意味着模型从第一层开始就在同时处理视觉和文本 Token。

从Qwen2.5补强多模态与长上下文,到Qwen3引入MoE与推理增强,再到Qwen3.5强化综合能力与真实场景表现,Qwen几乎每代都在关键能力上前进一步。
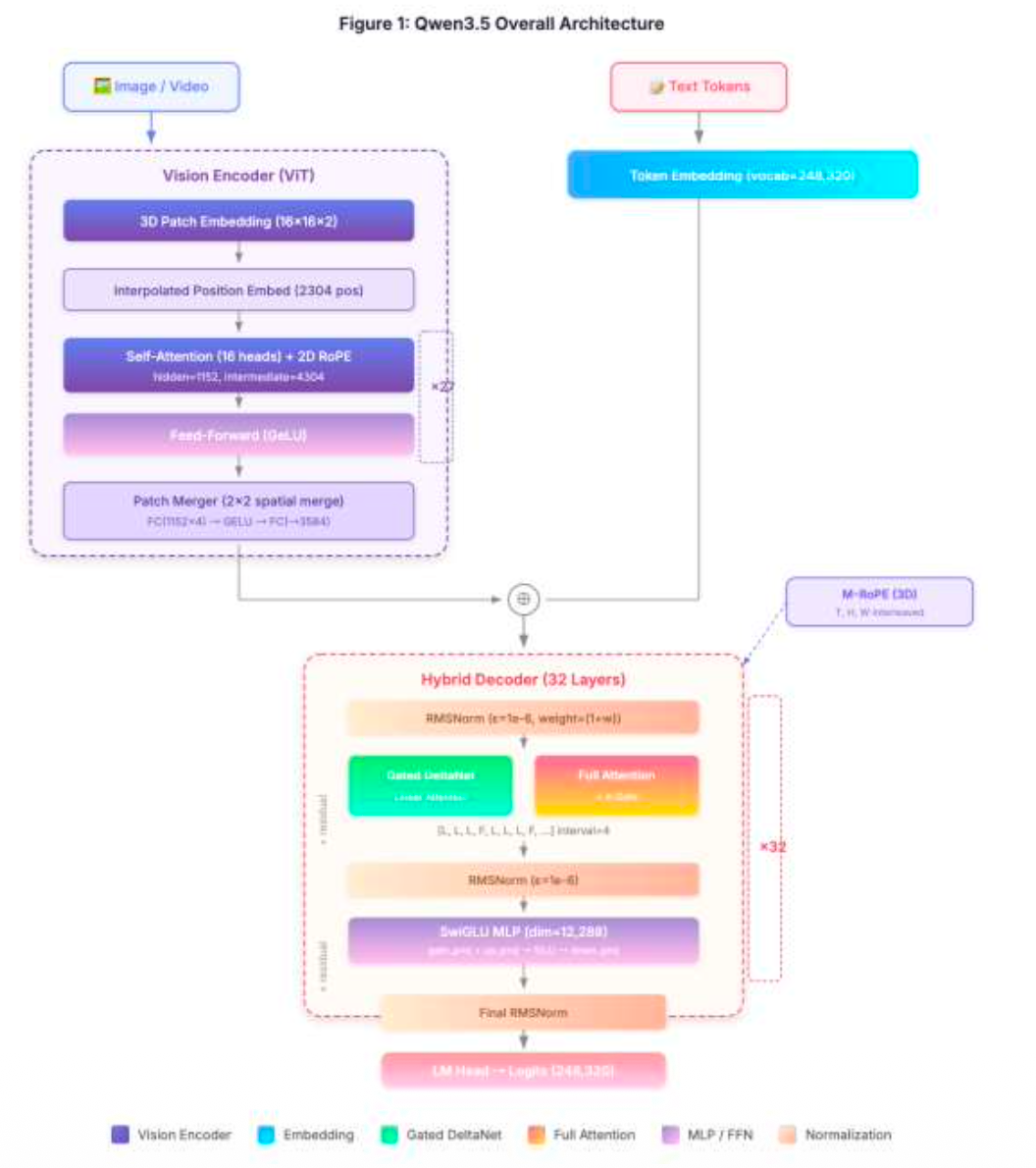
Qwen3.5 在能力、效率与通用性三个维度上推进预训练:
- 能力(Power):在更大规模的视觉-文本语料上训练,并加强中英文、多语言、STEM 与推理数据,采用更严格的过滤,实现跨代持平:Qwen3.5-397B-A17B 与参数量超过 1T 的 Qwen3-Max-Base 表现相当。
- 效率(Efficiency):基于 Qwen3-Next 架构——更高稀疏度的 MoE、Gated DeltaNet + Gated Attention 混合注意力、稳定性优化与多 token 预测。在 32k/256k 上下文长度下,Qwen3.5-397B-A17B 的解码吞吐量分别是 Qwen3-Max 的8.6 倍/19.0 倍,且性能相当。Qwen3.5-397B-A17B 的解码吞吐量分别是 Qwen3-235B-A22B 的 3.5 倍/7.2 倍。
- 通用性(Versatility):通过早期文本-视觉融合与扩展的视觉/STEM/视频数据实现原生多模态,在相近规模下优于 Qwen3-VL。多语言覆盖从 119 增至 201 种语言/方言;25 万词表(vs. 15 万)在多数语言上带来约 10–60% 的编码/解码效率提升。
核心技术能力:
- 混合注意力机制(qwen3-next): 传统大模型在处理长文本时,每个 Token 都需要进行全量的上下文注意力计算,这导致算力消耗随文本长度呈指数级增长。Qwen3.5-Plus 引入的混合机制赋予了模型「有详有略」的阅读能力,能够根据信息权重动态分配注意力资源,实现了精度与效率的双重提升。
- 极致稀疏的 MoE 架构(deepseek V3最先落地):不同于每次推理都需要激活全量参数的稠密模型,Qwen3.5-Plus 将 MoE(混合专家)架构推向了极致。在其 397B 的总参数中,每次推理仅需激活 17B 的参数量。这意味着模型只需动用不到 5% 的算力,就能调用全局的知识储备。
- 原生多 Token 预测(deepseek,meta,Google 均有落地) :模型打破了传统大模型「逐字吐出」的生成逻辑,在训练阶段就掌握了对后续多个位置进行联合预测的能力。这种「一次想好几步再说」的机制,使其在代码补全、长文本生成等高频场景中,推理速度接近翻倍,为用户带来几乎「秒回」的交互体验。
3、核心优化点
关于注意力机制的各种优化方式请参考:
(1)混合注意力机制
Gated DeltaNet与Gated Attention的融合优势
Gated DeltaNet 相比常用的滑动窗口注意力(Sliding Window Attention)和 Mamba2 有更强的上下文学习(in-context learning)能力,在 3:1 的混合比例(即 75% 层使用 Gated DeltaNet,25% 层保留标准注意力)下能一致超过超越单一架构,实现性能与效率的双重优化。
线性注意力的效率与局限性
线性注意力:长序列建模上效率高但召回能力弱
标准注意力的挑战
标准注意力:计算开销大、推理不友好。
标准注意力的增强设计
在保留的标准注意力中,引入多项增强设计:(1)沿用我们先前工作中的输出门控机制,缓解注意力中的低秩问题。(2)将单个注意力头维度从 128 扩展至 256。(3)仅对注意力头前 25% 的位置维度添加旋转位置编码,提高长度外推效果。
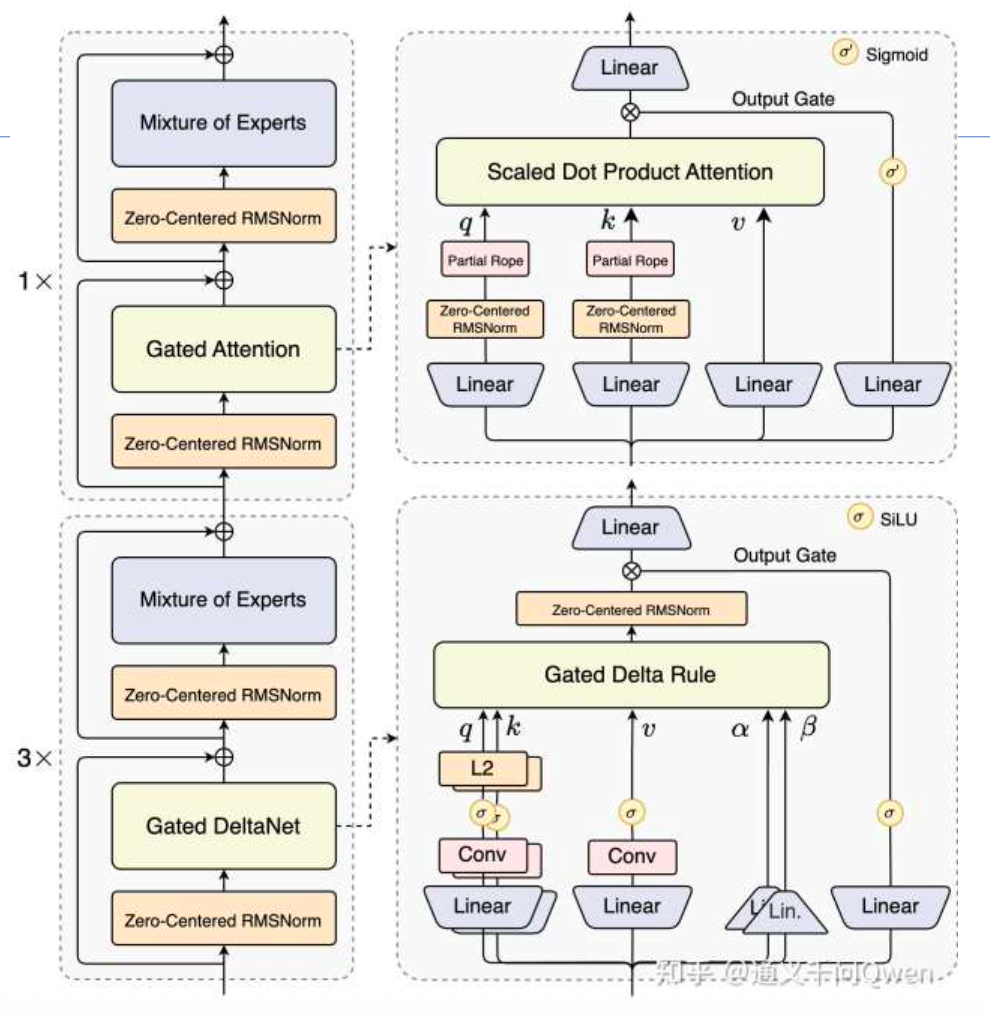
标准Attention(Softmax Attention)的特性:
-
标准Attention包含
和 Softmax 操作。
-
其最大的问题是动态性:在处理序列时,如果输入句子的长度不同(例如第一句10个字,第二句100个字),中间的注意力矩阵(Attention Matrix)大小是不同的。
-
在推理过程中,标准Attention通常依赖 KV Cache,这也会导致计算图在迭代过程中发生变化。
传统Attention
线性Attention
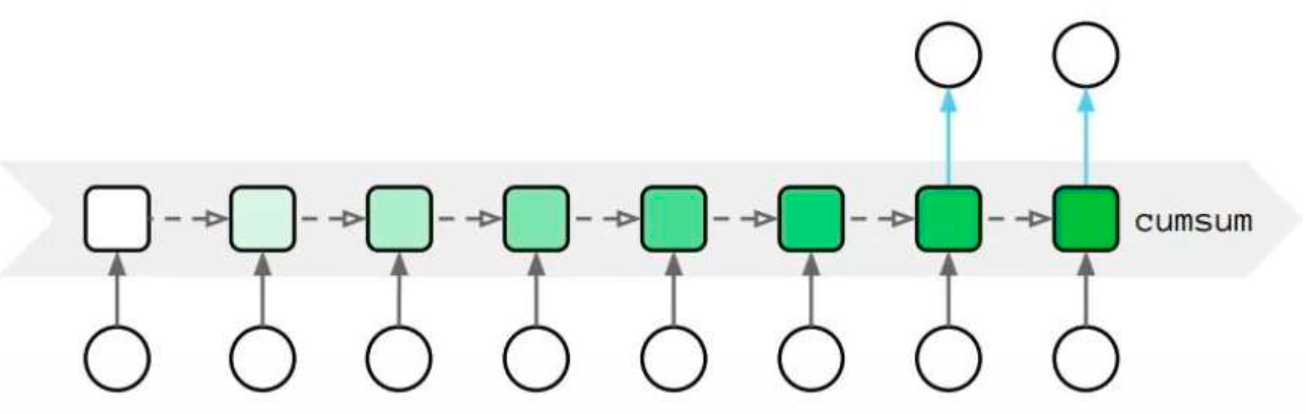
(2)门控注意力
NIPS 2025 的 Best Paper
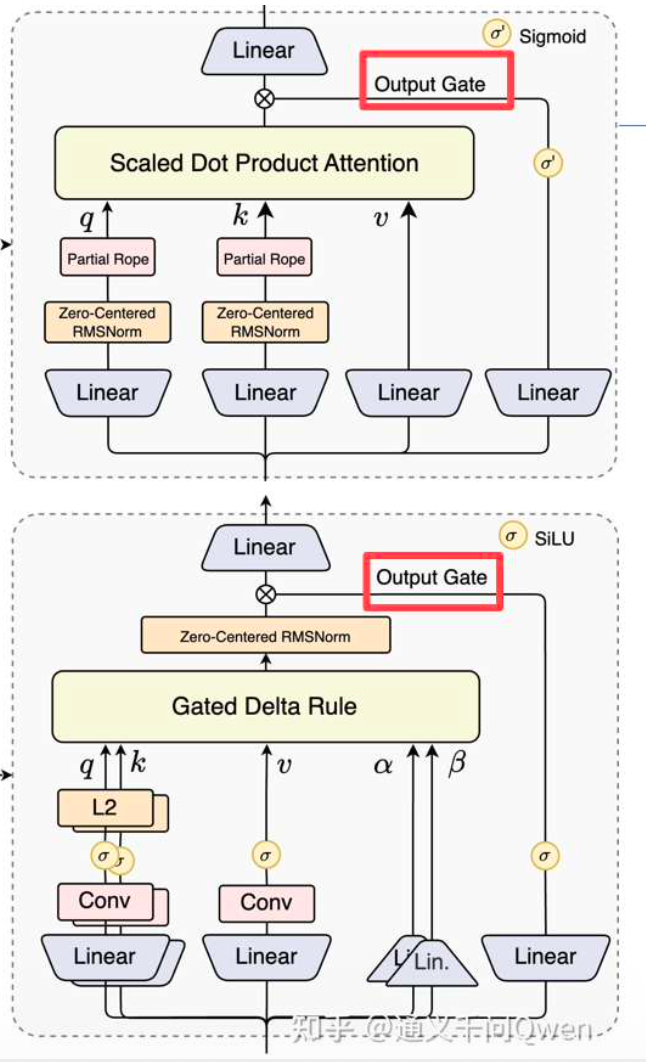
这个新加的门控能带来哪些收益呢? (带来可选择性的非线性)
1、性能提升:在15B MoE和1.7B Dense模型(训练数据达3.5T token)上,PPL和下游任务(MMLU,GSM8k等)均有显著提升。
2、训练极其稳定:该机制几乎消除了训练过程中的Loss Spikes,使得模型可以使用更大的学习率进行训练,这对于大规模模型训练至关重要。
3、消除 Attention Sink:模型不再需要将注意力强行分配给首个Token,从而天然地消除了Attention Sink现象。
4、长窗口外推能力增强:在进行长Context扩展(如使用YaRN)时,Gated Attention的表现显著优于 Baseline。
(3)混合注意力机制和门控注意力的效果
Linear Attention 的使用比较看场景,如果上下文长度比较小的话,和 传统Attention的计算时间上的差距是拉不开的。
在 Function Call 、 Agent、VLA的场景下面可能会用处比较大。
1. 先从标准注意力出发
文件先给出标准形式:

在自回归 decode 场景里,还要加 causal mask,只看见过去 token。
关键问题是:
标准注意力要先算,这是
的相关矩阵,所以序列长度是 n 时,复杂度是
。
2. 线性化的核心:去掉 softmax 的 exp,并交换乘法顺序
先把 softmax 的分母视作主要是数值稳定用途,简写后把核心项写成:

然后进一步去掉 exp,得到最早的朴素线性 attention 形式:

接着利用矩阵乘法结合律,把它改写成:

这一步就是“线性”的本质。因为:
先算
:
,成本约
再算
:
,成本约
如果 d 固定,整体随序列长度 n 线性增长,总计算量
。
所以,线性注意力实现,第一原则就是:
不显式构造
3. 真正可实现的形式:把历史压成状态
进一步写成递推形式,这是实现层面最关键的一步。
定义:

于是当前时刻输出可以写成:
并且
可递推更新:

这意味着推理时你根本不需要缓存全部 KV 序列,只需要缓存一个状态矩阵 St。两点好处:
计算速度线性增长
只需缓存 S,存储量小
这就是它在工程上怎么实现的核心:
每来一个 token,先线性层算出
用当前 token 的
去更新状态
再用
得到输出
也就是一种 RNN/状态空间式的在线更新,而不是 Transformer 标准注意力那种“每步都和全部历史做一次两两匹配”。
4. 为什么说“纯线性注意力召回弱”
这个问题:
线性注意力长序列效率高
但召回能力弱
因为历史信息在状态里是“累加”的,token 越多,单个 token 的贡献越容易被淹没
用 RetNet 的思路解释了这个问题:
如果所有历史都等权叠加,那么上下文一长,每个历史 token 的占比都会很小。于是引入遗忘/衰减机制。
5. 为了缓解历史淹没,加入“遗忘衰减”
可以概括为:

也就是给旧状态乘一个衰减因子
。这样更近的历史保留更多,远处历史逐渐淡化。
这一步很重要,因为它说明文件中的线性注意力不是简单做矩阵重排就结束,而是在状态更新规则里显式加入了“记忆管理”。
6. 再往前一步:DeltaNet 不是单纯累加,而是“误差驱动更新”
进入 DeltaNet。它把标准线性注意力的更新:

改成:

展开成:

它和标准线性注意力的区别是:
不只是加上
,还多减去了
。
这里的 可以理解成当前模型在 key
上的“已有预测”。
实现思想:
先看当前状态
对
再用真实目标
去纠正
更新量正比于误差
所以 DeltaNet 本质上是把线性注意力写成一种在线学习/在线记忆写入过程,而不是盲目累加所有历史。
7. 最终在这里采用的是 Gated DeltaNet
真正落到 Qwen3-Next 里的,不是最早的线性 attention,而是 Gated DeltaNet(GDN)。
状态更新是:

可以这样理解:
:控制旧记忆保留多少,类似遗忘门
:控制新信息写入多少,类似输入门
:先擦除和当前 key 相关的旧内容
:再把新内容写进去
所以 Gated DeltaNet 相当于把:
衰减/遗忘
误差纠正
门控写入
三者统一到了一个递推状态更新式里:
q、k、v 由线性层得到
有 Conv / Linear 生成门控信号
通过 “Gated Delta Rule” 更新状态
上面再接 output gate 输出
这已经很接近一种“注意力 + RNN 门控 + 在线学习”的混合体。
8. 其他几个实现细节
Qwen3-Next 里怎么把它做强:
混合堆叠,不是全用线性注意力
75% 层使用 GatedDeltaNet
25% 层保留标准注意力
即 3:1 混合比例。
原因是:线性注意力效率高,但标准注意力在精确召回上仍有优势,所以混合堆叠来兼顾性能与效率。保留输出门控
文件说沿用了先前工作的输出门控机制,用来缓解注意力中的低秩问题。
头维度加大
单个 attention head 维度从 128 扩展到 256。
只对部分维度加 RoPE
只对注意力头前 25% 的位置维度加旋转位置编码(Partial RoPE),以提升长度外推。
9. 文件最后给出的统一公式总结
把各种 attention 统一列了个表,最能说明“实现路线”:
Softmax Attention
最早的线性 Attention
加入遗忘后
DeltaNet
Gated DeltaNet
其中 M 是 causal mask,
是带衰减的下三角结构。
这里的“线性注意力”最终不是一个单点技巧,而是一整套从:
核简化 → 状态递推 → 衰减记忆 → 在线纠错 → 门控更新
逐步演化出来的实现体系。
10. 一句话总结
它把 attention 从“显式计算所有 token 两两相关性”改成了“维护一个随时间递推的状态矩阵
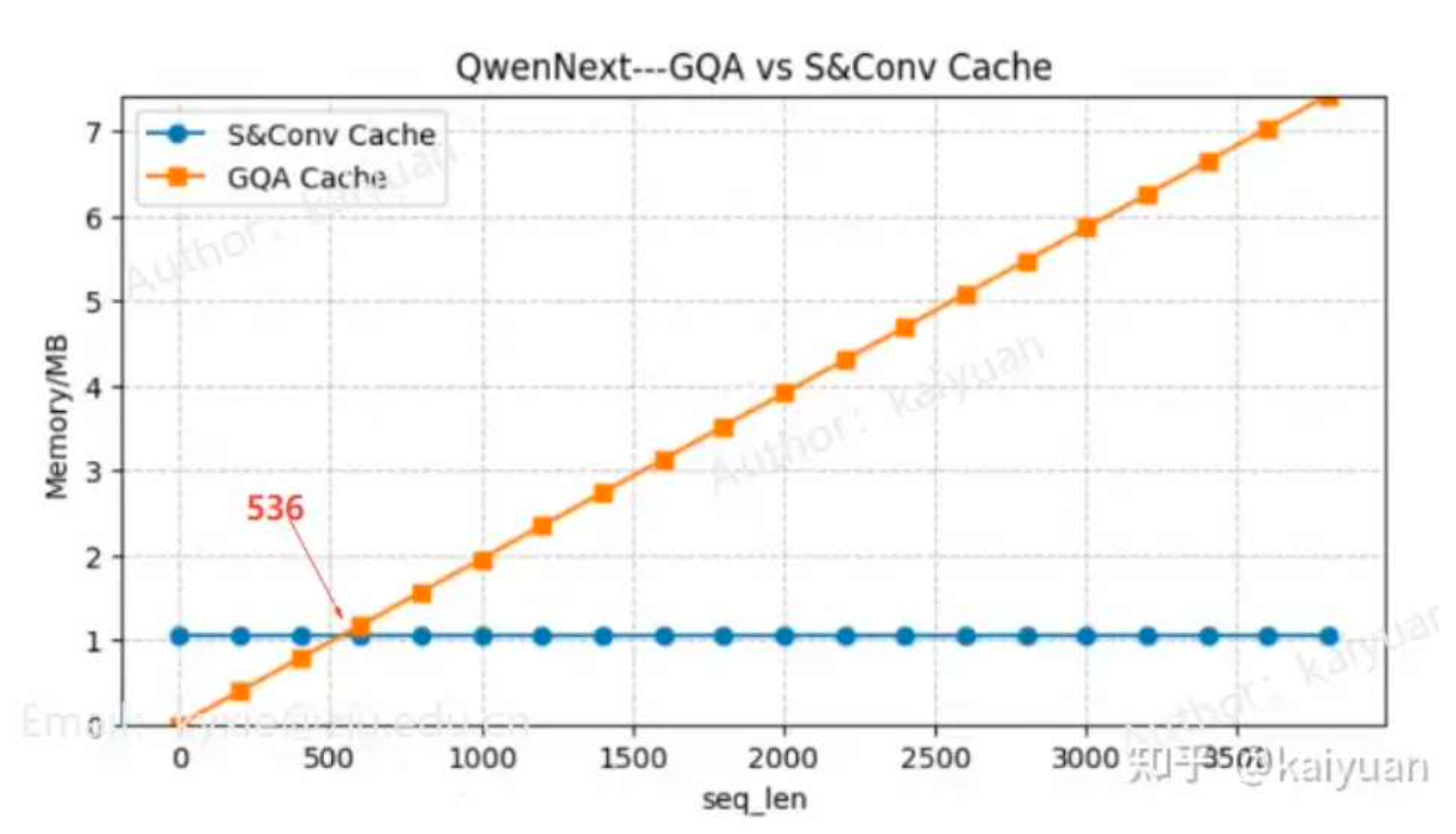
Long-context下,推理成本的降低
计算量&显存

(4)极致稀疏的 MoE 架构
在其 397B 的总参数中,每次推理仅需激活 17B 的参数量。这意味着模型只需动用不到 5% 的算力,就能调用全局的知识储备。
预测:有可能会带动专门适合稀疏Moe芯片的发展
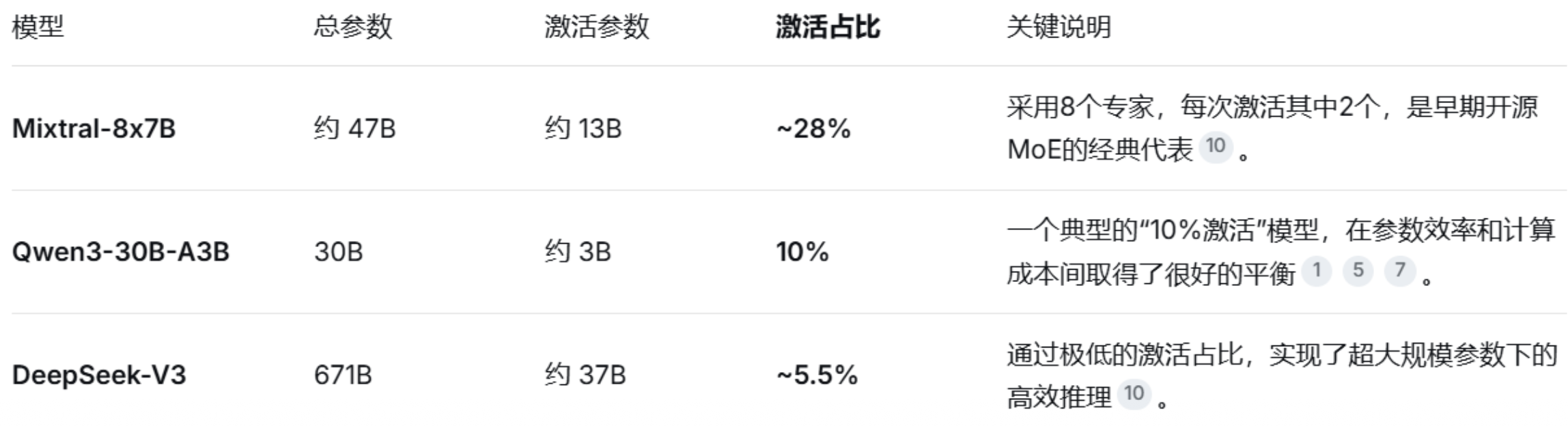
为什么其他 MoE 模型普遍只激活约 10% 的参数?
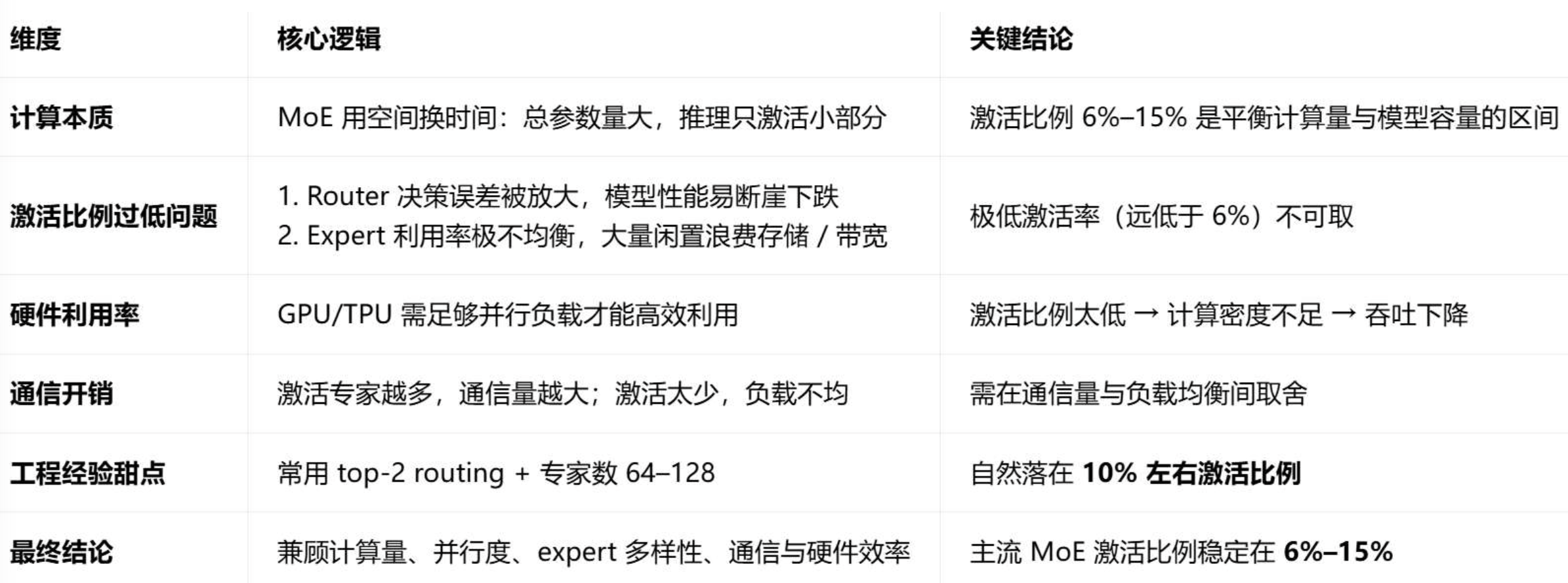
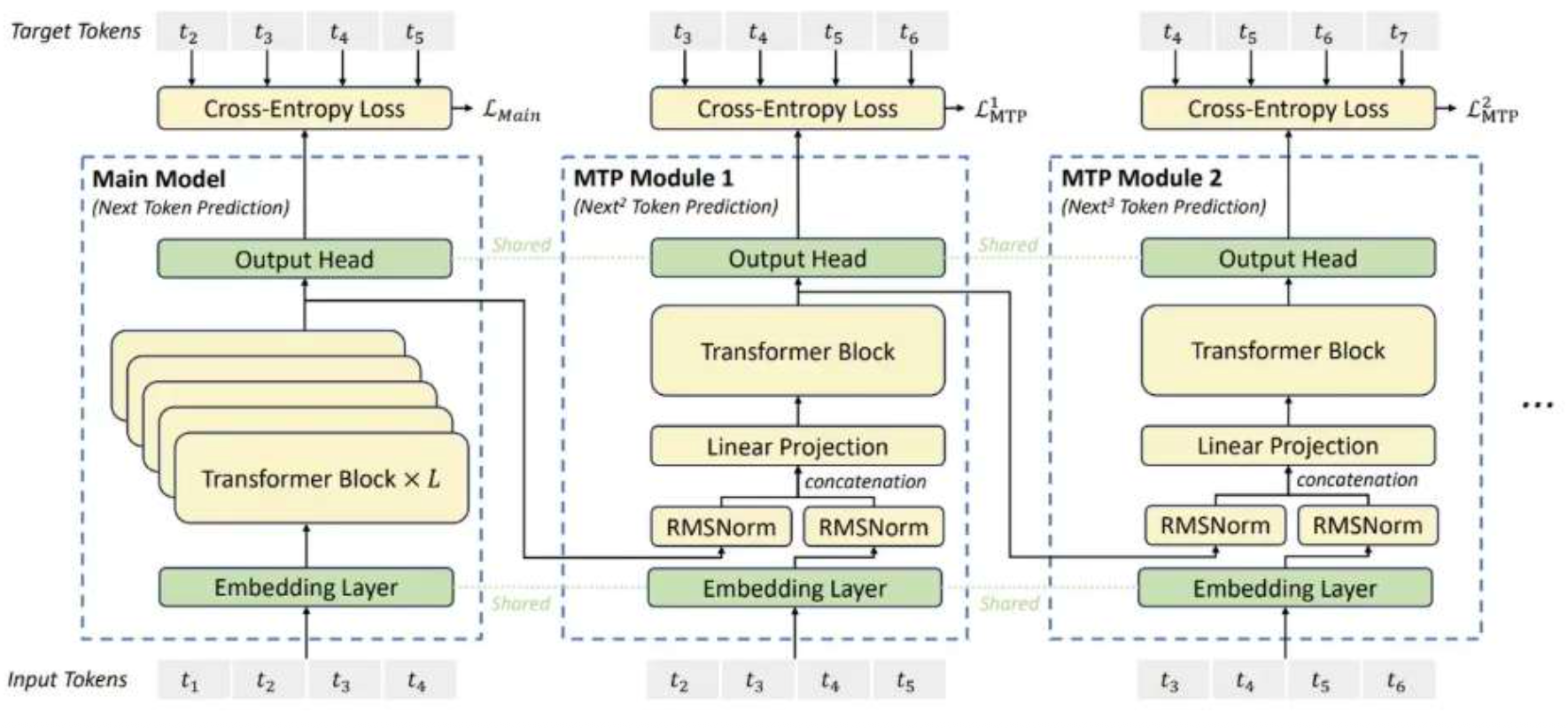
(5)原生多 Token 预测
采用了多Token预测机制(MTP) 来提升推理效率。传统大模型是自回归生成,一次只生成一
个token,逐步往下推理,速度相对较慢。MTP在训练阶段就让模型学会一次预测多个token,因此在推理时可以单步输出多个token,从而显著提升解码速度。
算力部署成本较 Qwen3-Max 也降低了 60%,推理吞吐量在 256K 长文本下提升 19 倍
线性注意力:长度越长,优势越大长上下文被混合注意力放大出来的 ~5× + MoE 的 ~2× + MTP 的 ~1.5× 叠加的系统级结果。
Qwen3.5-Plus 在训练时做的工作
• “原生 FP8 流水线”:这不仅仅是推理量化,而是训练时就采用了 FP8 对激活值、MoE 路由和 GEMM 进行运算。这能节省接近 50% 的显存。
• 训推分离的异步 RL 框架:为了支持大规模的强化学习(Thinking 模式),他们构建了一套支持“数万亿 Token”回放的系统。这解释了为什么 Qwen 能这么快跟进 o1 的推理能力——他们的工程基建已经 Ready 了。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)