LifeLong-RFT:通过强化微调实现持续学习的VLA模型
26年2月来自北京师范大学、自动化所、中科院大学和北京智源研究院的论文“Towards Long-Lived Robots: Continual Learning VLA Models via Reinforcement Fine-Tuning”。
在基于大规模多样化数据集进行预训练后,VLA 模型展现出强大的泛化能力和适应性,可作为通用机器人策略。然而,作为 VLA 模型适应下游领域的主要机制的监督微调 (SFT) 需要大量的特定任务数据,并且容易发生灾难性遗忘。为了克服这些局限性,提出 LifeLong-RFT,一种简单而有效的强化微调 (RFT) 策略,其适用于独立于在线环境反馈和预训练奖励模型的 VLA 模型。通过将块级在线策略强化学习与提出的多维过程奖励 (MDPR) 机制相结合,LifeLong-RFT 量化中间动作组块在三个维度上的异质贡献,从而促进策略优化。具体而言,(1) 量化动作一致性奖励 (QACR) 确保在离散动作空间内进行准确的动作预测; (2)连续轨迹对齐奖励(CTAR)将解码后的连续动作块与参考轨迹对齐,以确保精确控制;(3)格式一致性奖励(FCR)保证输出的结构有效性。在 SimplerEnv、LIBERO 和真实世界任务上的综合实验表明,LifeLong-RFT 在多任务学习中表现出色。此外,在 LIBERO 基准测试中进行持续学习时,比 SFT 的平均成功率提高 22%,同时仅使用 20% 的训练数据即可有效适应新任务。
如图所示,通过监督微调 (SFT) 将 VLA 模型适应新任务仍然充满挑战。首先,SFT 通常需要大量特定任务的数据,这限制 VLA 模型在数据量少或样本量小的环境下快速适应的能力。其次,SFT 常常导致灾难性遗忘,即学习新技能会削弱先前习得的知识。这些问题阻碍 SFT 支持 VLA 演化为能够持续习得新技能的长寿命智体。
这两个挑战并非相互独立 [65]:提高数据效率的适应能力通常会加剧遗忘,而保留先验知识则会限制从有限的新数据中有效学习。对于机器人而言,在可塑性和稳定性之间取得有效的平衡至关重要,这样才能在不抹去先验知识的情况下从有限的数据中学习。在早期基于专用模型的研究中,这种权衡被广泛认为是固有的 [50],因此人们倾向于采用基于特定任务适配器或手工特征的解决方案 [31, 41, 69, 51]。随着基础模型的出现,从海量且多样化的数据集中学习的表征展现出显著提升的迁移能力,重塑可塑性-稳定性困境,但并未彻底消除该困境[55]。尽管此类表征显著降低学习新任务所需的数据量,但直接应用SFT仍然会导致严重的灾难性遗忘[46]。因此,为特定模型开发的持续学习技术通常被重用于缓解基础模型中的遗忘问题[68, 70, 62]。然而,这些技术难以扩展到涉及海量任务和高容量参数化的VLA场景。
与从标注数据集中学习的SFT不同,大语言模型的最新进展表明,基于策略的强化学习(RL)——它使用从当前分布中抽取的样本更新模型——可以展现出更强的抗遗忘鲁棒性[61, 10, 30]。这一观察结果为机器人学提出了一个重要问题:能否利用在线策略强化学习来实现VLA基础模型的持续适应,从而支持其演化为长寿智体?回答这个问题的关键挑战在于设计高效、可靠且可扩展的奖励信号,用于VLA模型的强化微调。
现有的VLA模型强化微调方法主要依赖于两类奖励信号。第一类使用环境提供的真实奖励[40, 34, 64, 47, 11],这些奖励通常仅在仿真环境中可用,并且依赖于特权信息。由于仿真与现实之间的差距以及在无法访问特权状态的情况下难以计算奖励,这类方法在实际部署中面临着巨大的障碍。第二类方法采用基于模型的奖励估计,例如预测任务成功率[63, 45, 13, 76]、任务进度[43, 14, 75, 33]或基于距离的密集奖励[17, 23, 12, 24, 18]。然而,奖励模型的不准确性和泛化误差使得这些方法极易受到奖励破解攻击[16]。此外,这两类方法都需要与环境进行大量交互——无论是模拟器[34, 40]、世界模型[81, 24]还是真实机器人[13, 54]——这导致在扩展到大型任务集时训练成本过高。重要的是,现有方法主要优化微调任务本身的性能,而很大程度上忽略长期运行的VLA智体所需的持续学习特性。
本文提出一种简单而有效的VLA模型后训练范式,名为LifeLong-RFT。通过设计多维过程奖励(MDPR)机制,实现了无需与环境交互即可进行块级策略内强化微调。具体而言,将该机制分解为三个维度以提供全面的奖励。首先,引入量化动作一致性奖励(QACR)。鉴于VLA基于VLM骨干网络生成离散动作tokens,QACR通过测量预测token与目标token之间的一致性,确保在量化动作空间内进行精确预测。其次,设计连续轨迹对齐奖励(CTAR)。QACR确保量化动作空间内的准确性,而实际执行则需要与连续轨迹对齐。为此,CTAR利用解码后的动作块,根据与参考轨迹的空间偏差计算块级奖励,从而激励模型探索最优运动。第三,引入格式一致性奖励(FCR)。由于VLA骨干网的生成多样性,模型容易产生结构无效的输出(例如,动作维度不匹配和预测范围不一致)。为了缓解这种不稳定性,FCR 作为一种二元奖励机制,鼓励遵循有效格式,从而确保动作的可执行性并提高推理效率。
问题定义和公式化
VLA 和后训练。VLA 建模的目标是学习一个通用的机器人策略 π_θ (a | o, l),该策略将观测值 o 和自然语言指令 l 映射到机器人动作 a。在实践中,VLA 模型首先在大规模且多样化的数据集上进行预训练,以获得丰富的语义理解和可迁移的表示。然后,使用特定任务的数据对预训练参数 θ 进行后训练,以使动作输出 a 适应目标机器人及其下游任务。
持续学习。SFT 仍然是 VLA 模型后训练的主要方法。然而,SFT 主要优化当前训练数据集中任务的性能,而很大程度上忽略先前学习能力的退化。在现实世界中,人们期望一个长期存在的智体能够在保留先前学习技能的同时,不断习得新技能,这一要求通常被称为持续学习。形式上,这涉及智体从一系列任务 {T_k} 中学习,其中每个任务 T_k 都与 N 个专家演示 {τn_k} 相关联。与假设可以同时访问所有任务数据的单一适应阶段不同,持续学习需要在历史数据访问受限的约束下不断获取知识。
在线策略强化学习。虽然SFT可以有效地提高当前目标任务的性能,但它通常会导致先前学习能力的快速退化,这种现象通常被称为灾难性遗忘。相比之下,最近在LLM中的研究 [61, 10, 30] 表明,在线策略强化学习具有更强的抗遗忘能力。与依赖固定标注数据集的 SFT 不同,基于策略的强化学习使用自我生成的答案来更新策略,并优化这些答案的预期收益。
LifeLong-RFT
为了支持 VLA 演化为能够持续获取新技能的长寿智体,本文提出 LifeLong-RFT,一种如图所示的强化微调策略。该策略将块级在线策略强化学习与提出的多维过程奖励 (MDPR) 机制相结合,MDPR 机制无需环境交互即可量化中间动作组块在三个维度上的异质贡献。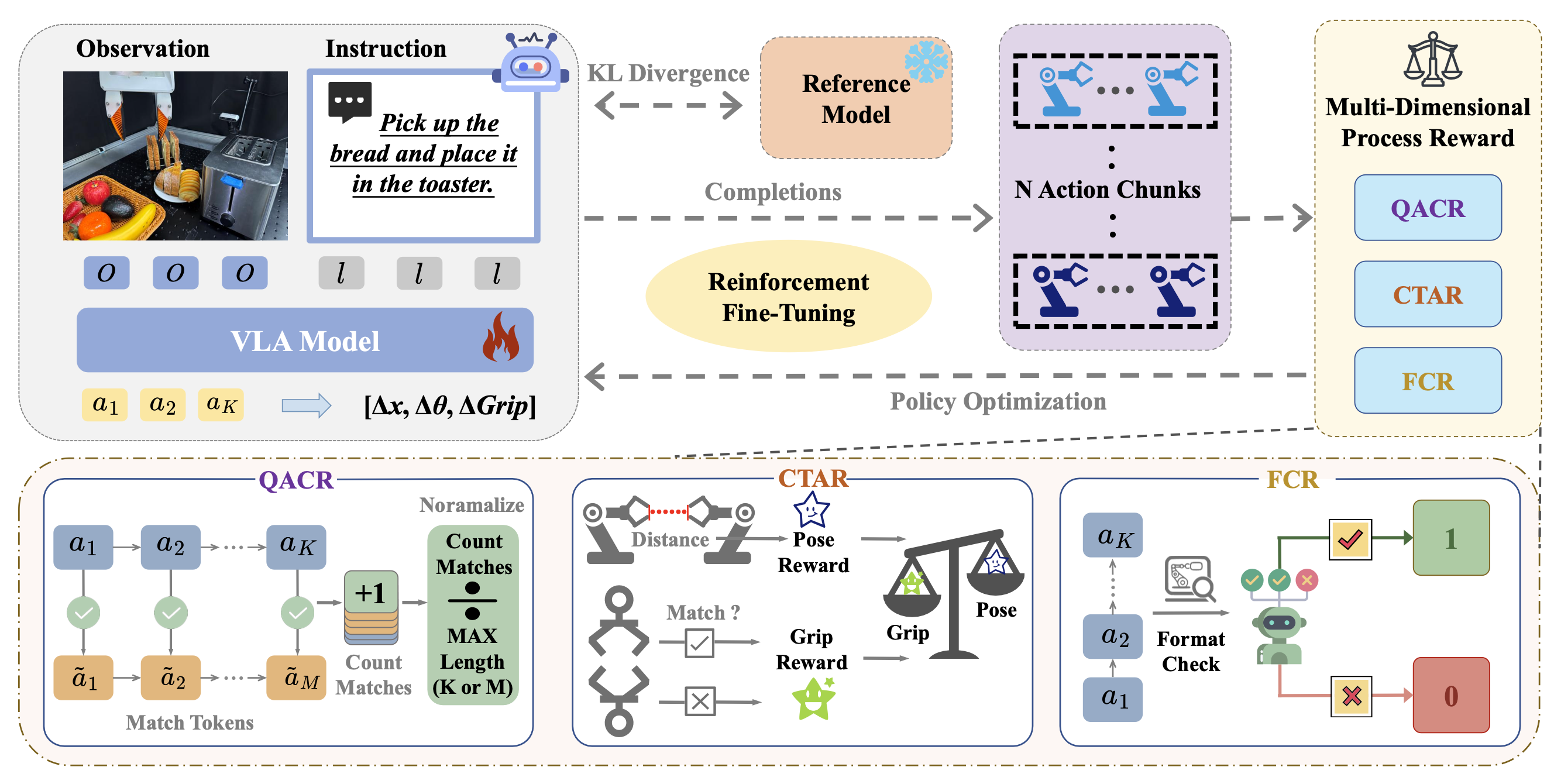
块级在线策略强化学习
大多数现有的 VLA 后训练策略内强化学习方法 [40, 34, 64, 11] 通过收集完整轨迹并依赖环境提供的奖励来优化模型参数。虽然这些方法可以取得不错的性能,但它们需要在训练过程中与环境进行大量交互,导致训练成本高昂,并限制其在大规模和多任务场景下的可扩展性。为了消除环境交互的需要,采用一种简单的替代方案:不评估完整轨迹上的动作,而是独立评估VLA模型采样到的每个动作块,从而消除对环境交互的依赖。
本文采用组相对策略优化(GRPO)[60]。与依赖显式评价网络的传统算法(例如PPO [59])不同,GRPO通过对采样输出进行组间比较来估计优势,从而显著降低计算开销。具体而言,对于每个观测值o和指令l,首先从旧策略π_θ_old(a | o, l)中采样一组G个动作输出{a_i}。然后,通过特定任务的奖励函数计算相应的奖励{r_i}。基于组内奖励的均值和标准差,计算每个输出的相对优势A_i。给定优势 A_i,策略参数 θ 通过最大化目标函数进行优化。
多维过程奖励
为了在无需环境交互的情况下有效指导策略内强化学习过程,设计多维过程奖励(MDPR)机制。该机制将动作块的评估分解为三个互补的维度,从而连接离散的token生成和连续的机器人控制。
1)量化动作一致性奖励:基于VLM骨干网的现代VLA[25, 28, 56]通过解释语言指令和多模态观测来生成动作token。这种范式需要设计一个专门的奖励函数来评估生成的token与真实 token之间的一致性,从而在量化的动作空间中实现精确预测。为此,提出量化动作一致性奖励(QACR)函数,如算法 1 所示。
首先,对模型生成结果进行格式检查,以验证其是否符合动作分词器 Fast+ [56] 的预定义规范(即动作块大小和动作维度)。只有通过验证的生成结果才能进入后续的一致性评估阶段,而未通过验证的生成结果则获得零奖励。其次,通过预测的动作token序列 a = {a_u} 与其对应的真实值 ã = {ã_v} 进行位置匹配来计算一致性奖励,该匹配在定义中给出。基于此,QACR 为序列一致性提供稳健的评估。
- 连续轨迹对齐奖励:虽然 QACR 确保量化动作空间内的准确性,但实际执行需要与连续轨迹对齐。为了解决这个问题,引入连续轨迹对齐奖励 (CTAR)。该机制评估解码后的连续动作块与参考轨迹之间的空间对齐情况,提供密集的反馈以促进灵巧操作。该奖励函数的实现详见算法 2。

与 QACR 一致,首先对预测的动作token序列 a = {a_u } 进行格式验证。只有通过此验证的序列才能进入后续的奖励计算,而无效的序列则直接被赋予零奖励。随后,用 Fast+ [56] token化器将预测的动作tokens解码为连续的动作块 y,该动作块包含 H 个动作序列。对于动作块 y,每个时间步的动作向量 y_t 由姿态分量 ypose_t 和夹爪分量 ygrip_t 组成。其中,ypose_t 表示机器人在时间 t 的末端执行器姿态(或关节角度),而 ygrip_t 表示夹爪的开合状态。基于此,将 CTAR 的计算分解为以下步骤:
(1)为了鼓励精确的姿态对齐,将姿态奖励 rpose_t 定义为相对于真实值的误差指数衰减函数。具体来说,计算预测姿态向量 ypose_t 与真实姿态向量 ỹpose_t 之间的归一化 L1 距离 d。基于此误差,应用指数衰减函数 exp(−α · d_t) 将其转换为奖励信号,其中超参数 α 调节对姿态偏差的敏感度。
(2) 为了激励精确的机械臂操作,采用二元奖励 rgrip_t。该奖励定义为指示函数 I(·),当预测的机械臂状态 ygrip_t 与真实姿态向量 ỹgrip_t 匹配时,I(·) 的值为 1,否则为 0。
(3) 最后,通过对姿态奖励和抓取奖励的加权组合在动作块大小 H 上取平均值来计算归一化 CTAR,其中 H 的定义预先给出。总之,CTAR 函数通过量化机器人姿态和夹爪状态的预测差
异,建立一种密集的奖励机制。
- 格式一致性奖励:虽然 QACR 和 CTAR 侧重于优化预测准确率和控制精度,但它们的有效性取决于生成输出的结构有效性。具体而言,预测序列必须符合指定的动作维度和动作块大小。为此,提出格式一致性奖励 (FCR),以指导模型生成结构良好的token序列。
具体来说,用 Fast+ token化器来验证生成的token序列是否符合所需的输出形状。因此,将 FCR 定义为一个二元奖励函数,如果验证通过则返回 1,否则返回 0。其中“有效”条件表示模型输出符合预定义的输出格式,使得 Fast+ token化器能够将其解码为连续的动作块。通过明确激励模型获取结构有效的输出模式,该奖励为有效的轨迹探索建立了必要的前提条件。
最后,将 QACR、CTAR 和 FCR 综合起来,形成多维过程奖励 (MDPR),如下所示:
MDPR = ω · QACR + (1 − ω) · CTAR + λ · FCR,
其中 ω ∈ [0, 1] 控制离散动作一致性和连续轨迹对齐之间的权衡,λ 缩放结构格式合规性的重要性。
实现细节
在实验中,采用 NORA-Long [25] 作为基础 VLA 模型,该模型使用 Fast+ [56] token化器进行动作表示。在强化微调阶段,模型进行全参数优化。具体来说,将 GRPO 的展开组大小设置为 8,并使用峰值学习率为 1 × 10⁻⁶ 的 AdamW [42] 优化器。对于 CTAR 配置,超参数 α 和 β 分别设置为 5 和 0.8。最后,MDPR 被构建为三个维度奖励的加权组合,权重系数为 ω = 0.7 和 λ = 0.1。所有实验均在 8 个 NVIDIA H20 GPU 上进行。
多任务学习实验
- 实验设置:
a) 训练设置:为了评估模拟环境中的多任务学习,用 SimplerEnv [37] 和 LIBERO [38]。对于 SimplerEnv,用 BridgeData V2 [67] 训练 WidowX 模型,使用 Fractal [7] 训练 Google Robot 模型。对于 LIBERO,针对每个任务套件(即物体、空间、目标和长距离)对模型进行微调,利用所有 10 个任务的第三人称视角和腕部输入。此外,在 Franka 机器人上进行真实环境实验,如图所示。具体来说,联合训练模型时,前三个任务各使用 40 个演示,最后一个任务使用 50 个演示。
b) 评估方案:在 SimplerEnv 中,在 WidowX 和 Google Robot 平台上,在视觉匹配设置下评估模型的性能。为了确保评估的稳健性,每个任务在不同的初始物体姿态和环境配置下重复 24 次试验。对于 LIBERO,在每个任务套件上进行 500 次试验来评估模型。此外,在真实环境实验中,每个任务进行 20 次试验。在上述所有实验中,以平均成功率 (SR) 作为评估指标。
持续学习实验
- 实验设置:
a) 训练设置:用 LIBERO [38] 在模拟环境中进行实验。与 LOTUS [68] 类似,训练过程包含基础任务阶段和终身学习阶段。对于每个任务集,我们使用其前六个任务进行基础任务阶段训练,每个任务包含 50 个演示。随后,终身学习阶段专注于对剩余四个任务进行增量学习。在此阶段,每个新任务仅包含 10 个演示,而每个先前学习的任务保留 5 个演示用于经验回放 (ER) [9]。总的来说,一个完整的实验周期包含一个基础学习步骤和四个连续的终身学习步骤。此外,对于真实世界实验,如上图所示,依次训练模型处理四个任务,每个新任务使用 20 个演示,每个先前任务保留 5 个演示。
b) 评估协议:采用三个指标[38]来评估模型的持续学习能力:前向迁移 (FWT)、负后向迁移 (NBT) 和成功率曲线下面积 (AUC)。这三个指标均源自任务成功率。具体而言,较高的 FWT 值表明模型对新任务的适应性更强;较低的 NBT 值意味着模型能有效缓解对先前学习任务的灾难性遗忘;较高的 AUC 值则反映模型在所有评估任务中的平均成功率更高。假设模型按顺序学习 K 个任务 {T_k},令 s_k,j 表示智体在学习前 k 个任务后,在任务 j 上的成功率。在实验中,评估所有已学习任务上的策略,LIBERO 进行 50 个episodes,真实世界实验进行了 20 个episodes。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)