强化学习RLHF&DPO推导
一、强化学习简介
RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习)是一种让模型学习人类复杂偏好的方法。第一步,监督微调(SFT),第二步,训练奖励模型(RM),第三步,强化学习优化(RL)。
PPO(Proximal Policy Optimization,近端策略优化)是RLHF流程中最常用的强化学习算法,可以把它想象成第三步中学生使用的高效学习方法 。
这个方法的精妙之处在于,它既要根据奖励模型的反馈努力提高分数,又要确保每次修改的步子不能迈得太大。如果这次改得太激进,过犹不及,反而退步了。PPO通过一个巧妙的"裁剪"机制,限制了每次策略更新的幅度,从而保证了学习过程的稳定可靠 。
DPO(Direct Preference Optimization,直接偏好优化)。理解了RLHF的复杂性,就能明白DPO为何被称之为"革命性"的方法。
RLHF虽然有效,但它像一个庞大而精密的机器,需要训练多个模型,流程复杂,训练也不够稳定 。DPO的提出者发现了一个秘密:在RLHF的数学公式背后,其实隐藏着一个可以直接使用的捷径。
DPO的核心洞察是:最优的语言模型策略与人类偏好之间,存在一个可以直接计算的数学关系。通过这个关系,DPO将RLHF中分离的"奖励模型训练"和"强化学习优化"两个步骤,巧妙地融合成了一个单一的、直接的监督学习问题 。
简单来说,DPO不再需要单独训练一个 奖励模型,也不需要PPO这个复杂的学习引擎。它直接利用人类偏好数据,通过一个非常简洁的损失函数(也就是后面推导的公式),一步到位地训练模型。
二、DPO推导
我们来学习DPO算法。我们知道在对大语言模型进行强化学习的时候,首先我们要收集大量的用户偏好数据。也就是对于同一个prompt,让大语言模型给出两个不同的回答,然后让用户选择出两个回答中哪一个更好。比如这里YW的回答好于YL的回答(YW > YL),然后再用极大似然估计的方法训练一个reward model。Reward model可以在给入prompt和大语言模型回答的情况下,对这个回答进行打分。打分越高表明这个单元模型的回答越好,越接近人类的偏好。然后有了这个reward model,我们就可以用强化学习来训练我们的大语言模型。而DPO算法大大简化了这一过程,它可以直接从用户的偏好数据中进行学习,训练我们的大语言模型,让它更贴近人类的偏好。
2.1极大似然估计训练reward model
在基于人类反馈的强化学习(RLHF)中,奖励模型(reward model)用于为语言模型生成的文本打分,以反映人类偏好。通常,我们无法直接获得真实的奖励值,而是通过收集人类对模型输出的比较数据,并利用极大似然估计(MLE)来训练奖励模型。以下是具体步骤:
1. 收集偏好数据
让人类标注员比较同一提示(prompt)下两个模型输出 y1 和 y2 的好坏,记录偏好结果。例如,若人类认为 y1优于 y2,则记 y1>y2。最终数据集由三元组 (x,yw,yl) 组成,其中 x是提示,yw 是更受偏好的输出,yl 是较差的输出。
2. 定义奖励模型
奖励模型 rθ(x,y)是一个参数为 θ 的神经网络(通常基于预训练语言模型),输入提示 x 和输出 y,输出一个标量奖励值。训练目标是让 rθ 的打分与人类偏好一致。
3. 建立偏好概率模型
使用Bradley-Terry模型将奖励差值映射为人类偏好概率:
P(yw>yl∣x)=σ(rθ(x,yw)−rθ(x,yl))
其中 σ(⋅) 是 sigmoid 函数 σ(z)=1/1+e−z1。该公式假设人类选择 yw 的概率随奖励差值增大而增大。
4. 极大似然估计
假设数据集 D={(x(i),yw(i),yl(i))}i=1N中的比较独立同分布,则似然函数为:
L(θ)=∏i=1NP(yw(i)≻yl(i)∣x(i)).
取对数得负对数似然损失(等价于最大化对数似然):
ℓ(θ)=−∑i=1Nlogσ(rθ(x(i),yw(i))−rθ(x(i),yl(i))).
此即二元交叉熵损失:将每次比较视为正类(偏好 yw)的 logistic 回归。
5. 优化
通过梯度下降(如 Adam)最小化损失函数 ℓ(θ),更新奖励模型参数 θ。训练时可加入正则化项(如 L2 正则)防止过拟合。
6. 验证与使用
训练完成后,奖励模型即可为任意输出 y 打分 rθ(x,y)。在后续强化学习阶段(如 PPO),该奖励用于优化语言模型,使其生成更符合人类偏好的内容。
2.2KL散度
首先我们要了解一个概念,KL散度,P相对于Q的KL散度,它的计算公式是任取一个事件X事件X在P分布中的概率除以X在Q分布中的概率,然后取对数,再取它的数学期望值。KL散度的值始终大于或者等于0,P和Q越相似,KL散度越接近于0。如果P和Q的分布完全一致,则KL散度等于0。需要注意的是,P相对于Q的KL散度和Q相对于P的KL散度是不相等的。
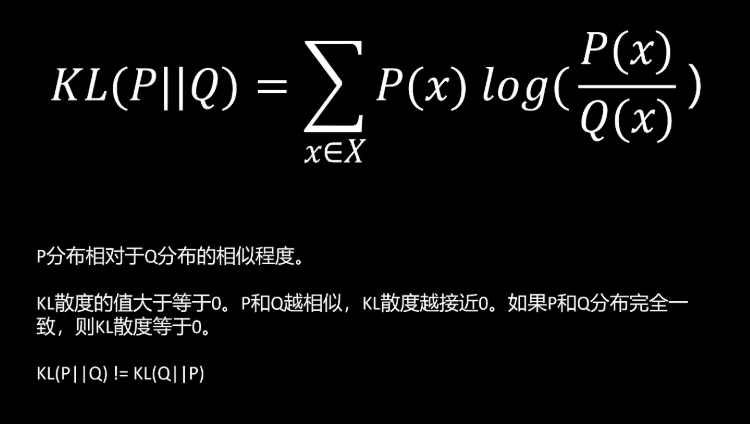
可能有人会疑惑KL散度为什么始终大于等于0?这里给出一个直观的理解。首先来解释为什么P分布和Q分布完全一致的情况下,他们的Q散度等于0。如果P和Q的分布相等,那么在任取一个事件X的情况下,X在P分布和Q分布下它们的概率值是相等的。那么它们的比值为一log一等于0,那么它们的累加还是0。
接下来我们再看,如果P分布和Q分布不相等,为什么P相对于Q的KL散度始终大于0?这里我们以两个实际的分布来看,P分布x=0的情况下它的概率为0.2,x=1的概率为0.8。而Q分布与此刚好相反,x=0的情情况下它的概率为0.8,x=1它的概率为0.2。

这时候我们来计算P相对于Q的KL散度分两部分,前一部分是x=0的情况,后一部分是x=1的情况。在x=0的情况下,P分布下的概率为0.2。相对于Q分布0.8相对较小。所以log函数的输入是小于一的,而log函数的取值是小于零的。而log函数小于零的这种情况,它的概率相对较小,只有0.2。
而后面刚好相反是X等于一的情况,P函数它的概率相对较大,Q函数相对较小。Log函数的输入是大于一的,log函数的取值是大于零的,log函数取值大于零的概率为0.8,相对较大。总体而言就是log函数为负的情况概率较小,log函数为正的情况概率较大,所以它们之和是大于零的。
下一个要了解的概念是Bradley Terry模型。Bradlee Terry模型是对比较关系进行建模,比如下面这个例子,A和B进行对战,A获胜8场,B获胜四场。A和C进行对战,A获胜三场,C获胜5场。问题是B和C进行对战,B战胜C的概率有多大?这样一个问题就可以用Bradley Terry模型来进行建模。

Bradley Terry模型假设每个元素都有一个隐含的实例参数,用αi来表示,αi大于0,元素i战胜元素j它的概率可以用αi除以αi加上αj来表示。其实这个表达式是比较符合直觉的。如果I和J它们的实力相等,那么αi除以αi加上αj就等于0.5。如果I的实力小于J的实力,那么αi除以αi加αj就小于0.5。
对于上面这个问题,我们可以用对数最大似然估计法来进行求解。这个表达式一共由四部分构成。第一部分表示A战胜B8次,第二个部分表示B战胜A4次,第三个表达式表示A战胜C3次,第四部分表示C战胜A5次。然后我们分别对αA、αB、αC求导,让它等于零时取得最大值。假设αA为单位,αB等于2分之1,αC等于3分之5,从而得到B战胜C的概率约等于0.23。
如果我们不想对αA、αB、αC进行直接求导,获取它的最大值。我们也可以通过优化器对它进行迭代优化来进行求解。这时我们可以定义一个loss损失函数,loss损失函数越小越好,所以我们在前面加一个负号。通过这样的转换,我们可以看到这实际就是一个分类问题的交叉熵损失函数。而其中αX除以αX加上αY表示X战胜Y的概率,而这个优化的目标就是让X战胜Y的概率越趋近于1越好。

总结一下Bradley Terry模型。假设每一个元素都有一个隐含的实例参数,用αi来表示,αi必须大于0,然后I元素战胜J元素,它的概率可以用αi除以αi加αj来表示。从此我们可以获得一般的loss函数,表示它和分类问题中的交叉熵损失函数是一致的。
在强化学习里面,大模型输入的prompt是X,回答是Y,回答Y的好坏,是靠reward的模型来进行评估。比如Y1的回答好于Y2的回答就是reward(x, y1)除以reward(x, y1)加上reward(x, y2),我们之前说过实例参数必须大于0,而reward function有可能返回负数。所以说我们对reward函数外部再加一个指数函数来让它变成正数,从而表达式变成这样。
最后我们再对loss函数进行一下化简。上一步我们得到大语言模型,给出YW > YL的概率为这样一个表达式。另外我们也知道sigmoid的函数是这样一个表达式,然后我们对ln函数中分子和分母同除以分子,这样分子为1,分母为如下的一个表达式。我们可以看到ln函数内部目前实际上是一个sigmoid的函数。我们用sigmoid函数对它进行化简,最终得到这样一个loss函数的简化表达。这个loss函数它的目标就是优化大语言模型输出的YW通过reward的方法得分尽可能的 大于 YL通过reward方法的得分。

2.3DPO推导
有了上面的准备,我们就可以学习DPO算法了。DPO训练的目标是什么呢?首先它有几个部分组成,奖励函数r(x, y)表示大语言模型输入的prompt,y表示大语言模型给出的回答。奖励函数可以根据prompt和response给出一个得分,表示这个回答的好坏基准模型。Πref一般是SFT之后的大语言模型训练模型。

DPO的训练目标是尽可能得到更多的奖励,同时保证新训练的模型尽可能的和基准模型分布一致。另外有一个β参数可以调节,β越大表示新训练的模型应当尽可能的和基准模型分布保持一致。这里我们用KL散度来约束我们训练的模型应当尽可能的和基准模型保持一致。
下面我们有了这个训练目标,我们对它进行一步步的化简。首先我们写出KL散度的一个完整表达式,然后将期望提取到前面,变成这样一个形式。然后我们把求最大值通过加上负号变成求最小值。另外这两项同时除以β,变成这样一个表达式。
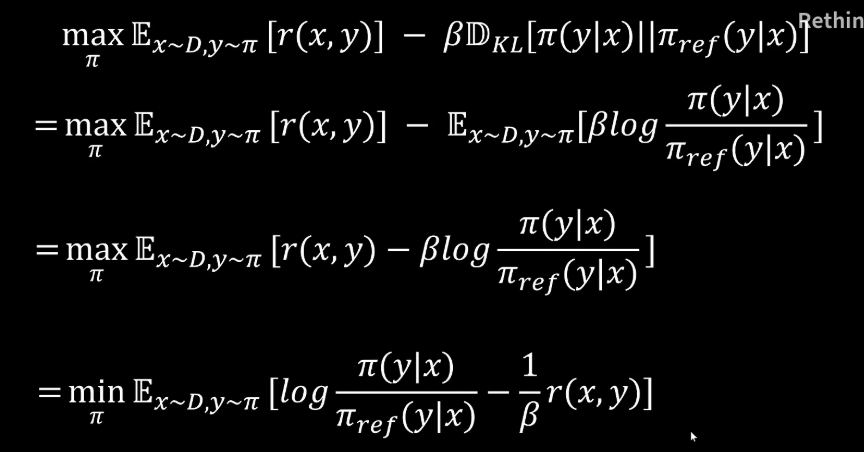
接下来我们对后面这一项先求一个指数运算,再进行一个对数运算。接下来我们把对数相减,转换成内部元素的相除。然后我们再在分母上除以一个Z(x)乘以一个Z(x)并且把Z(x)提取出来。这里需要注意的是Z(x)这个表达式。我们先看一下,目前我们优化到这一步,这个分母部分里面有个Z(x)。
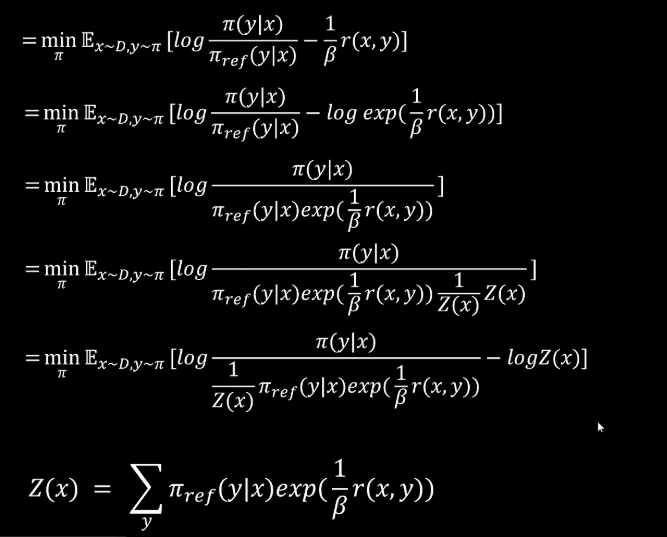
Z(x)的表达式是这样的,我们把Z(x)带入,可以看到这是在给定一个x的情况下,对所有可能的Y进行一个求和,而它的分子部分是其中一个特定的y也就是说下面是各种y的情况,上面是一个特定y的情况,这就是一个概率分布。我们可以用Π*来表示这个概率分布,然后替换到式子中去。
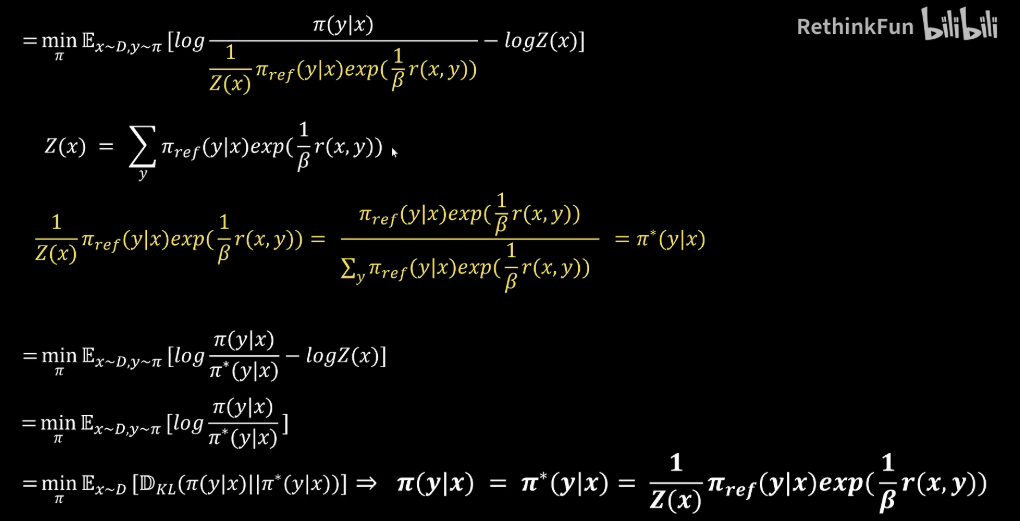
我们的可以进一步对它进行优化。我们这里是求最小,这个表达式是通过优化Π来优化这个网络,而我们看到Z(x)中并没有Π,所以说它并不影响我们对这个式子最小值的优化。我们可以去掉它,变成下面这个样式。然后我们再仔细看,实际上这就是Π相对于Π*这个分布的KL散度的一个表示。然后我们把它用KL散度来表示,这样我们的优化目标就是让这个KL散度尽可能的小。之前我们也说过,KL散度它是一个大于等于零的数,它最小就是等于0,也就是说Π的分布和Π*的分布完全一致。这时候KL散度可以取到最小值0,所以我们的优化目标就变为了Π。
我们要训练的这个神经网络,它的输出的分布应该等于Π*,也就是这么一个表达式。所以到这一步我们可以得到我们要训练的Π这个网络,它的表达式是这样的。
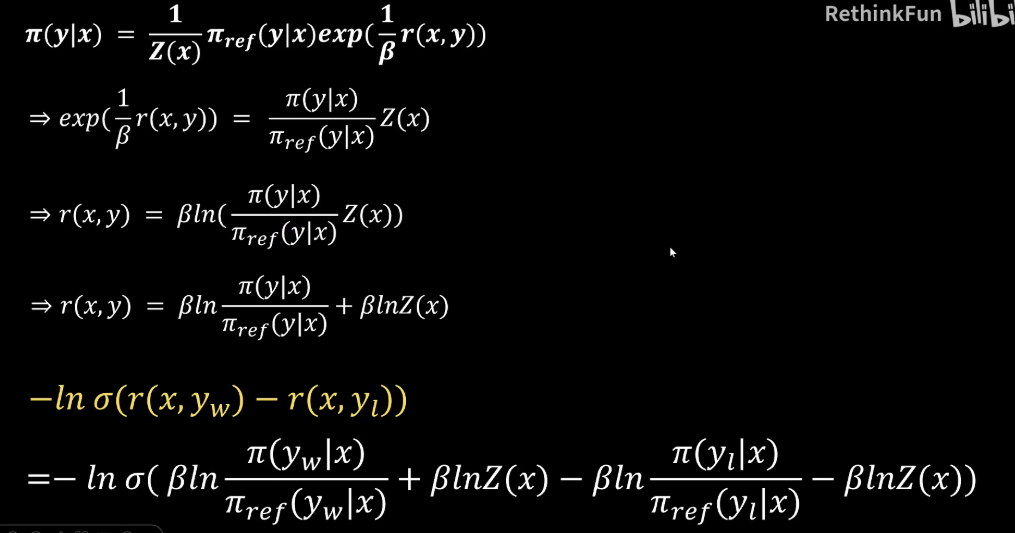
然后我们通过表达式两边进行变换,从而可以求解reward function它的一个表达式。然后我们把Z(x)提取出来,这是reward function的一个表示。另外之前我们也通过Bradley Terry模型知道如何对这种比较关系进行建模。它的loss损失函数是这样一个表达式,这样我们就可以得到。
最终的一个loss函数的表达式。我们可以看到其中这两个部分是可以化解掉的,一个是加,一个是减,这样我们就得到了最终的DPO loss损失函数。其中,这是sigmoid函数。
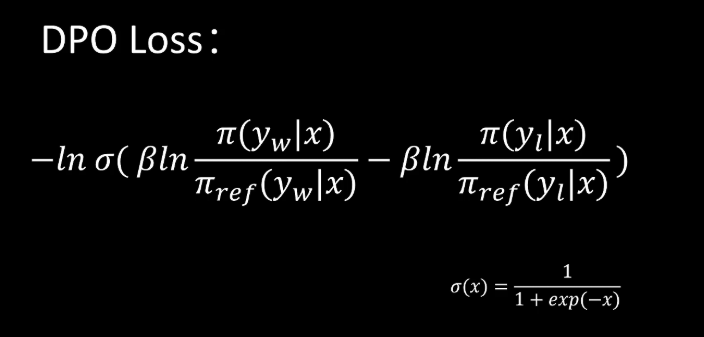

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)