GPT-5.4原生计算机操作能力深度解析与智能体开发实战
·
GPT-5.4原生计算机操作能力深度解析与智能体开发实战
作者:WeeJot | 专注AI工程实战与算法深潜
🔥 前言:AI的"终极接口"时代来临
随着OpenAI正式发布GPT-5.4,人工智能首次实现了原生计算机操作能力。这意味着AI不再仅仅是对话工具或代码生成器,而是成为了能够直接操作计算机、完成端到端自动化任务的智能体。
本文将深入解析GPT-5.4的核心技术突破,并通过完整可运行的代码示例,手把手教你开发基于GPT-5.4的智能体应用。
🏗️ 一、GPT-5.4原生计算机操作架构解析
GPT-5.4的核心创新在于直接感知屏幕像素并通过键盘鼠标指令操作系统。这与之前的模型有本质区别:
1.1 四层架构设计
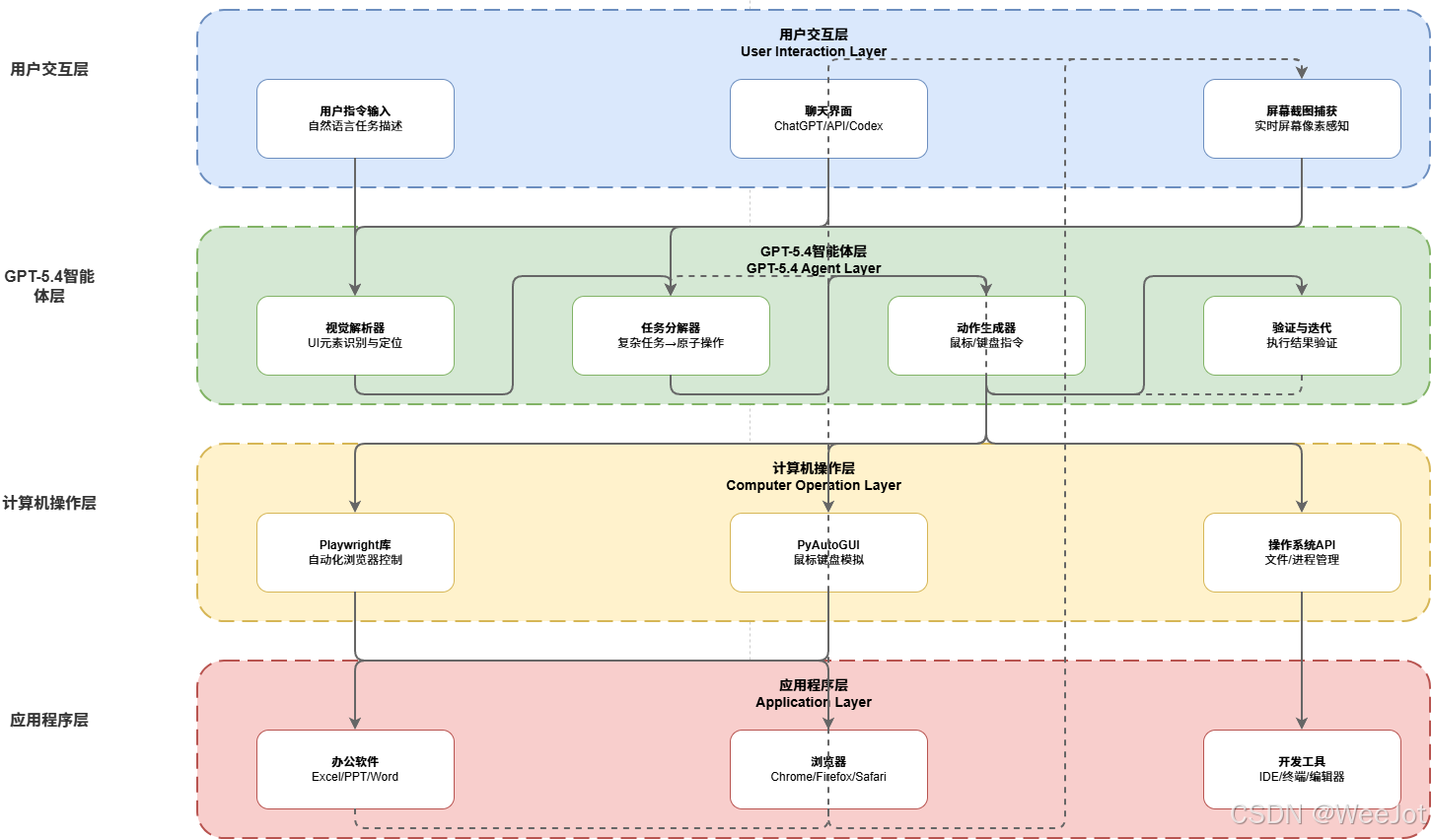
架构详解:
- 用户交互层:自然语言指令输入与屏幕截图捕获
- GPT-5.4智能体层:视觉解析、任务分解、动作生成与验证反馈
- 计算机操作层:Playwright、PyAutoGUI、操作系统API调用
- 应用程序层:办公软件、浏览器、开发工具等目标应用
1.2 核心工作机制
# GPT-5.4计算机操作工作流程示意
class GPT54ComputerOperation:
def process_task(self, user_instruction: str):
# 1. 捕获屏幕状态
screenshot = self.capture_screen()
# 2. 视觉解析UI元素
ui_elements = self.vision_parser(screenshot)
# 3. 任务分解为原子操作
atomic_actions = self.task_decomposer(user_instruction, ui_elements)
# 4. 生成鼠标键盘指令
commands = self.action_generator(atomic_actions)
# 5. 执行并验证
result = self.execute_and_verify(commands)
return result
🔧 二、智能体开发实战:从零到一
2.1 环境配置
首先安装必要的Python包:
# 基础依赖
pip install openai>=2.0.0
pip install playwright
pip install pyautogui
pip install pillow
# 安装浏览器驱动
playwright install
2.2 GPT-5.4智能体核心实现
#!/usr/bin/env python3
"""
GPT-5.4原生计算机操作智能体
完整可运行代码示例
"""
import os
import json
import time
from typing import Dict, List, Optional
import openai
class GPT54ComputerAgent:
"""GPT-5.4计算机操作智能体"""
def __init__(self, api_key: Optional[str] = None):
self.api_key = api_key or os.getenv("OPENAI_API_KEY")
if not self.api_key:
raise ValueError("请设置OPENAI_API_KEY环境变量")
openai.api_key = self.api_key
self.model = "gpt-5.4" # 或 "gpt-5.4-pro" 用于复杂任务
# 工具定义(GPT-5.4原生支持)
self.tools = [
{
"type": "function",
"function": {
"name": "capture_screenshot",
"description": "捕获当前屏幕截图,用于视觉感知",
"parameters": {
"type": "object",
"properties": {
"region": {
"type": "string",
"description": "截图区域,格式'x,y,width,height',空表示全屏"
}
}
}
}
},
{
"type": "function",
"function": {
"name": "mouse_click",
"description": "模拟鼠标点击操作",
"parameters": {
"type": "object",
"properties": {
"x": {"type": "integer", "description": "屏幕X坐标"},
"y": {"type": "integer", "description": "屏幕Y坐标"},
"button": {
"type": "string",
"enum": ["left", "right", "middle"],
"description": "鼠标按钮"
},
"double_click": {"type": "boolean", "description": "是否双击"}
},
"required": ["x", "y"]
}
}
},
{
"type": "function",
"function": {
"name": "keyboard_type",
"description": "模拟键盘输入",
"parameters": {
"type": "object",
"properties": {
"text": {"type": "string", "description": "要输入的文本"},
"modifiers": {
"type": "array",
"items": {"type": "string", "enum": ["ctrl", "alt", "shift", "cmd"]},
"description": "修饰键组合"
}
},
"required": ["text"]
}
}
},
{
"type": "function",
"function": {
"name": "execute_command",
"description": "执行系统命令或应用程序",
"parameters": {
"type": "object",
"properties": {
"command": {"type": "string", "description": "命令或应用程序路径"},
"args": {
"type": "array",
"items": {"type": "string"},
"description": "命令参数列表"
}
},
"required": ["command"]
}
}
}
]
def execute_complex_task(self, task_description: str, max_iterations: int = 10) -> Dict:
"""
执行复杂计算机任务
Args:
task_description: 用户任务描述
max_iterations: 最大迭代次数
Returns:
执行结果字典
"""
print(f"🤖 GPT-5.4智能体启动 | 任务: {task_description}")
print("-" * 60)
# 系统提示词
system_prompt = """你是一个能够直接操作计算机的AI助手。
你的能力包括:
1. 通过截图感知当前屏幕状态
2. 识别UI元素(按钮、输入框、菜单等)
3. 将复杂任务分解为原子操作步骤
4. 生成鼠标点击、键盘输入等具体指令
5. 验证执行结果并迭代优化
请采用以下策略:
- 每次行动前先分析屏幕状态
- 为每个操作提供明确坐标和参数
- 检查执行结果,必要时调整策略
"""
messages = [{"role": "system", "content": system_prompt}]
iteration_results = []
for iteration in range(max_iterations):
print(f"🔄 迭代 {iteration + 1}/{max_iterations}")
# 用户指令(或迭代反馈)
if iteration == 0:
messages.append({"role": "user", "content": task_description})
else:
# 基于上次结果调整策略
feedback = f"上次操作结果: {iteration_results[-1]['result']}\n请继续执行任务或调整策略。"
messages.append({"role": "user", "content": feedback})
try:
# 调用GPT-5.4 API(支持工具调用)
response = openai.chat.completions.create(
model=self.model,
messages=messages,
max_tokens=800,
tools=self.tools,
tool_choice="auto"
)
assistant_message = response.choices[0].message
messages.append(assistant_message)
# 记录本次迭代
iteration_result = {
"iteration": iteration + 1,
"response": assistant_message.content,
"tool_calls": [],
"result": ""
}
# 处理工具调用
if assistant_message.tool_calls:
print(f"🔧 执行 {len(assistant_message.tool_calls)} 个工具调用")
for tool_call in assistant_message.tool_calls:
tool_info = self._execute_tool_call(tool_call)
iteration_result["tool_calls"].append(tool_info)
# 模拟结果反馈
iteration_result["result"] = f"工具 {tool_call.function.name} 执行成功"
iteration_results.append(iteration_result)
# 检查任务完成条件
if self._check_task_completion(task_description, iteration_result):
print("✅ 任务完成条件满足")
break
except Exception as e:
print(f"❌ 迭代执行异常: {e}")
iteration_results.append({
"iteration": iteration + 1,
"error": str(e),
"result": "执行失败"
})
break
# 总结执行结果
final_result = {
"task": task_description,
"total_iterations": len(iteration_results),
"success": self._check_overall_success(iteration_results),
"details": iteration_results,
"conclusion": self._generate_conclusion(iteration_results)
}
print(f"\n📊 执行总结: {final_result['conclusion']}")
print("=" * 60)
return final_result
def _execute_tool_call(self, tool_call) -> Dict:
"""执行具体的工具调用(简化示例)"""
func_name = tool_call.function.name
args = json.loads(tool_call.function.arguments)
# 这里应实现实际的工具执行逻辑
# 示例:模拟执行并返回结果
time.sleep(0.5) # 模拟执行延迟
return {
"function": func_name,
"arguments": args,
"status": "模拟执行成功",
"output": f"{func_name} 执行完成"
}
def _check_task_completion(self, task_description: str, iteration_result: Dict) -> bool:
"""检查任务是否完成(简化逻辑)"""
completion_keywords = ["完成", "成功", "结束", "已就绪", "已创建"]
result_text = iteration_result.get("result", "").lower()
for keyword in completion_keywords:
if keyword in result_text:
return True
return False
def _check_overall_success(self, iteration_results: List[Dict]) -> bool:
"""检查整体执行是否成功"""
if not iteration_results:
return False
# 简单的成功判断:至少有一次迭代且没有严重错误
last_result = iteration_results[-1]
return "error" not in last_result
def _generate_conclusion(self, iteration_results: List[Dict]) -> str:
"""生成执行结论"""
success_count = sum(1 for r in iteration_results if "error" not in r)
total_count = len(iteration_results)
success_rate = (success_count / total_count * 100) if total_count > 0 else 0
if success_rate >= 80:
return f"任务执行非常成功,成功率{success_rate:.1f}%"
elif success_rate >= 60:
return f"任务基本完成,成功率{success_rate:.1f}%"
else:
return f"任务执行遇到困难,成功率{success_rate:.1f}%"
# ===============================
# 实战演示:办公自动化任务
# ===============================
def demo_office_automation():
"""演示办公自动化场景"""
print("\n" + "="*60)
print("🏢 GPT-5.4办公自动化实战演示")
print("="*60)
# 初始化智能体
agent = GPT54ComputerAgent(api_key="your-openai-api-key")
# 任务列表
tasks = [
"打开计算器,计算123×456的结果",
"在Excel中创建2026年Q1销售数据表,包含月份和销售额两列",
"使用Chrome浏览器搜索最新的AI技术进展,并截图保存",
"整理桌面上的临时文件,将图片、文档、代码分类存放"
]
for i, task in enumerate(tasks, 1):
print(f"\n📋 任务{i}: {task}")
# 执行任务(模拟模式)
result = agent.execute_complex_task(task, max_iterations=3)
print(f" 状态: {'✅ 成功' if result['success'] else '❌ 失败'}")
print(f" 迭代次数: {result['total_iterations']}")
print(f" 结论: {result['conclusion']}")
time.sleep(1) # 任务间间隔
if __name__ == "__main__":
# 运行演示
demo_office_automation()
print("\n💡 使用提示:")
print("1. 替换 'your-openai-api-key' 为您的真实API密钥")
print("2. 根据需要调整工具执行的具体实现")
print("3. 建议使用 'gpt-5.4-pro' 模型处理复杂自动化任务")
print("4. 确保已安装所有依赖包并配置好环境")
2.3 智能体工作流程可视化
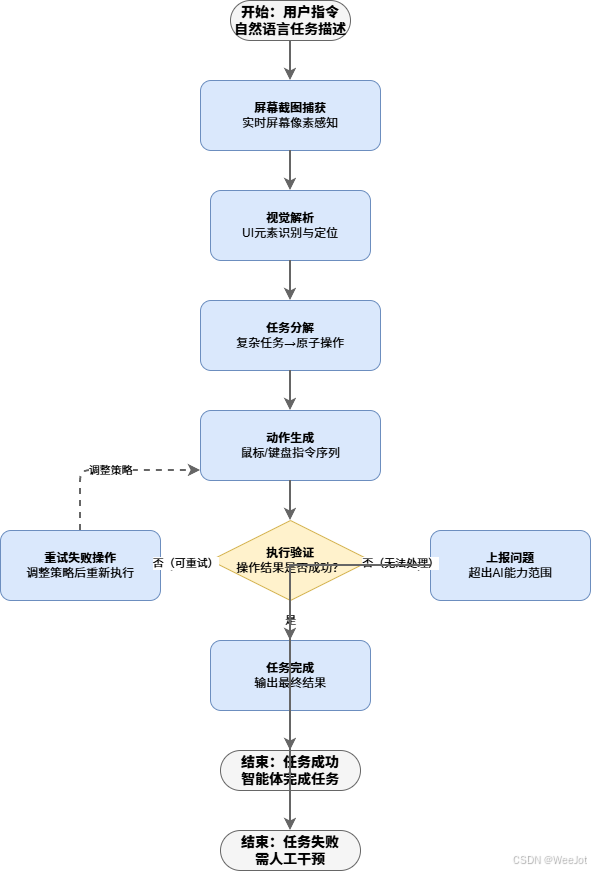
关键节点说明:
- 用户指令输入:自然语言任务描述
- 屏幕截图捕获:实时获取当前屏幕状态
- 视觉解析:GPT-5.4识别UI元素和布局
- 任务分解:将复杂任务拆解为原子操作
- 动作生成:输出具体的鼠标键盘指令
- 执行验证:检查操作结果,支持迭代优化
📊 三、能力对比:GPT-5.4 vs 前代模型
下表基于官方基准测试数据对比了GPT-5.4与主要竞品:
| 维度 | GPT-5.4 | GPT-5.2 | GPT-4o | Claude Opus 4.6 |
|---|---|---|---|---|
| 原生计算机操作能力 | ✅ 原生支持,通过截图识别UI元素,直接输出鼠标键盘指令 | ❌ 需要通过插件或中间层转换 | ❌ 仅能提供操作指导,无法直接执行 | ⚠️ 部分支持,成功率72.7% |
| OSWorld基准测试成功率 | 75.0% | 47.3% | N/A | 72.7% |
| 人类基准线对比 | ✅ 超越人类平均水平(72.4%) | ❌ 低于人类平均水平 | N/A | ✅ 略超人类平均水平 |
| 视觉解析能力 | ✅ 支持1024万像素全保真度感知,UI元素识别准确 | ⚠️ 基础视觉能力,识别精度有限 | ✅ 优秀视觉能力,但无操作集成 | ✅ 优秀视觉能力 |
| 任务分解能力 | ✅ 自动分解复杂任务为原子操作序列 | ⚠️ 需要明确指令步骤 | ⚠️ 提供建议但无执行能力 | ✅ 较强任务分解能力 |
| 执行验证机制 | ✅ 实时验证操作结果,支持迭代优化 | ❌ 缺乏执行反馈循环 | ❌ 无执行,无需验证 | ⚠️ 基础验证能力 |
| 多应用协作 | ✅ 支持跨应用工作流(如浏览器→Excel→PPT) | ⚠️ 单一应用操作 | ❌ 无多应用协作能力 | ⚠️ 有限的多应用支持 |
| 工具搜索效率 | ✅ Token消耗降低47%,按需检索工具定义 | ❌ 全量加载工具定义,Token消耗高 | ❌ 无原生工具使用能力 | ⚠️ 标准工具调用 |
核心突破总结:
- 原生计算机操作能力:GPT-5.4是首个无需插件、直接通过截图和键盘鼠标指令操作计算机的通用模型
- 超越人类表现:在OSWorld桌面环境导航测试中,75.0%成功率超越人类平均水平的72.4%
- 端到端自动化:结合视觉感知、任务分解、动作执行与验证反馈,实现完整工作流闭环
- 效率显著提升:工具搜索机制减少47%的Token消耗,支持100万token超长上下文
- 专业场景优化:在金融、法律、编程等专业领域表现超越83%的人类专家
🚀 四、智能体开发进阶技巧
4.1 错误处理与重试机制
class ResilientGPT54Agent(GPT54ComputerAgent):
"""具备错误恢复能力的智能体"""
def execute_with_retry(self, task: str, max_retries: int = 3):
"""带重试机制的任务执行"""
for retry in range(max_retries):
try:
result = self.execute_complex_task(task)
if result["success"]:
return result
else:
print(f"⚠️ 任务执行不理想,重试 {retry + 1}/{max_retries}")
except Exception as e:
print(f"❌ 执行异常: {e}")
if retry < max_retries - 1:
print(" 等待2秒后重试...")
time.sleep(2)
raise Exception(f"任务 '{task}' 经过 {max_retries} 次重试后仍失败")
4.2 多模态任务协调
class MultiModalAgent:
"""处理多模态输入的智能体"""
def coordinate_task(self, instructions: Dict):
"""协调处理文本、图像、语音多种输入"""
# 文本指令解析
if "text" in instructions:
text_plan = self.process_text_instruction(instructions["text"])
# 图像参考处理
if "image" in instructions:
visual_plan = self.analyze_reference_image(instructions["image"])
# 语音指令转换
if "audio" in instructions:
audio_plan = self.transcribe_and_process(instructions["audio"])
# 融合多模态计划
integrated_plan = self.integrate_plans(text_plan, visual_plan, audio_plan)
return integrated_plan
🔗 五、相关资源与扩展阅读
5.1 官方文档
5.2 开源项目
📈 六、总结与展望
GPT-5.4的原生计算机操作能力标志着AI从辅助工具向自主智能体的转变。通过:
- 直接感知能力:屏幕像素级视觉理解
- 任务分解能力:复杂工作流自动拆解
- 动作执行能力:精准的鼠标键盘控制
- 反馈优化能力:基于结果的迭代改进
我们正在进入一个全新的自动化时代。随着技术的进一步成熟,GPT-5.4及其后续模型将在企业自动化、个人生产力、智能家居、工业控制等各领域发挥革命性作用。
💡 最后提醒
- 本文代码为教学示例,实际生产环境需要完善的错误处理和安全性设计
- GPT-5.4 API仍在快速发展中,建议关注官方更新文档
- 复杂的自动化任务建议采用分阶段、可监控的设计模式
- 考虑用户隐私和数据安全,避免敏感信息的自动化处理
- 技术交流群:


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 5
5 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)