深度学习入门:covid_19预测项目
·
前言
考研结束后,我决定系统学习深度学习的实践应用。这篇博客记录了我第一个完整的深度学习项目——基于PyTorch的COVID-19检测结果预测系统。从数据处理到模型训练,从特征选择到正则化优化。
一、项目背景与数据集
1.1 问题定义
这是一个回归预测问题:根据患者的医疗指标数据,预测COVID-19检测结果的数值。
数据集信息:
- 训练集:
covid.train.csv(包含标签) - 测试集:
covid.test.csv(不包含标签) - 特征维度:93个医疗指标
- 目标变量:COVID-19检测结果(连续值)
1.2 Excel数据样式
id, feature_1, feature_2,..., feature_93, tested_positive
0, 1.2, 3.4,..., 5.6, 0.8
1, 2.3, 4.5,..., 6.7, 1.2
...二、环境配置
2.1 导入必要的库
#导入matplotlib.pyplot模块,用于绘制训练和验证损失曲线
import matplotlib.pyplot as plt
#导入PyTorch深度学习框架核心库,用来计算张量和实现自动微分
import torch
#NumPy库,用于数值运算和数组处理
import numpy as np
#用于读写CSV格式文件
import csv
#pandas数据分析库用于数据预处理
import pandas as pd
#从torch.utils.data导入DataLoader(DataLoader提供批量加载数据的功能)和Dataset
from torch.utils.data import DataLoader, Dataset
#torch.nn模块,包含神经网络构建所需层和函数
import torch.nn as nn
#optim模块,实现优化功能
from torch import optim
#time模块记录训练耗时
import time
#从sklearn.feature_selection导入SelectKBest(特征选择器)和chi2(卡方检验函数)
from sklearn.feature_selection import SelectKBest, chi2
#导入os模块,用于操作系统相关功能(如环境变量设置)
import os
# 解决matplotlib在某些环境下的兼容性问题
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"2.2 检查GPU可用性
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"使用设备: {device}")输出
使用设备: cuda # 如果有GPU
使用设备: cpu # 如果没有GPU三、特征工程:卡方检验特征选择
3.1 为什么需要特征选择?
问题: 93个特征过多,当特征越多,模型参数越多,越容易过拟合
解决方案: 使用卡方检验选出最重要的K个特征
3.2 卡方检验
卡方检验: 利用统计学特性来高效筛选高价值特征:
3.3 代码实现
def get_feature_importance(feature_data, label_data, k=4, column=None):
"""
使用卡方检验选择最重要的k个特征
参数:
feature_data: 特征数据 (n_samples, n_features)
label_data: 标签数据 (n_samples,)
k: 要选择的特征数量
column: 列名列表(用于打印特征名称)
返回:
X_new: 选择后的特征数据
indices: 选中特征的索引
"""
# 定义卡方检验选择器,选择k个最佳特征
model = SelectKBest(chi2, k=k)
# 确保数据类型正确
feature_data = np.array(feature_data, dtype=np.float64)
# 拟合并转换数据
X_new = model.fit_transform(feature_data, label_data)
# 获取每个特征的卡方得分
scores = model.scores_
# 按得分从高到低排序,获取索引
indices = np.argsort(scores)[::-1] # [::-1]表示反转,从大到小
# 如果提供了列名,打印选中的特征
if column:
k_best_features = [column[i+1] for i in indices[0:k].tolist()]
print('选中的最佳特征:', k_best_features)
return X_new, indices[0:k]3.4 特征选择效果
# 原始:93个特征
# 选择后:6个特征
# 参数量对比:
# 93特征 → 模型参数:93×64 + 64×1 = 6016个
# 6特征 → 模型参数:6×64 + 64×1 = 448个
# 参数减少:93%!
# 训练速度提升:约10倍!四、自定义数据集类
4.1 自定义Dataset
PyTorch的DataLoader需要一个Dataset对象来:
- 读取和预处理数据
- 支持索引访问
- 支持批量加载
4.2 完整代码实现
class CovidDataset(Dataset):
def __init__(self, file_path, mode="train", all_feature=False, feature_dim=6):
"""
初始化数据集
参数:
file_path: CSV文件路径
mode: "train"(训练集) / "val"(验证集) / "test"(测试集)
all_feature: 是否使用所有特征
feature_dim: 使用的特征数量
"""
# 第1步:读取CSV文件
with open(file_path, "r") as f:
ori_data = list(csv.reader(f))
column = ori_data[0] # 第一行是列名
csv_data = np.array(ori_data[1:])[:, 1:].astype(float) # 去掉id列
# 第2步:分离特征和标签
feature = np.array(ori_data[1:])[:, 1:-1] # 所有列除了id和最后一列
label_data = np.array(ori_data[1:])[:, -1] # 最后一列是标签
# 第3步:特征选择
if all_feature:
# 使用所有93个特征
col = np.array([i for i in range(0, 93)])
else:
# 使用卡方检验选择k个最佳特征
X_new, col = get_feature_importance(feature, label_data, feature_dim, column)
col = col.tolist()
# 第4步:划分训练集/验证集
if mode == "train":
# 训练集:每5个样本取4个(索引不能被5整除的)
indices = [i for i in range(len(csv_data)) if i % 5 != 0]
data = torch.tensor(csv_data[indices, :-1])
self.y = torch.tensor(csv_data[indices, -1])
elif mode == "val":
# 验证集:每5个样本取1个(索引能被5整除的)
indices = [i for i in range(len(csv_data)) if i % 5 == 0]
data = torch.tensor(csv_data[indices, :-1])
self.y = torch.tensor(csv_data[indices, -1])
else: # test
# 测试集:使用所有数据
indices = [i for i in range(len(csv_data))]
data = torch.tensor(csv_data[indices])
# 第5步:选择特征列
data = data[:, col]
# 第6步:数据标准化
# 标准化公式:(x - mean) / std
self.data = (data - data.mean(dim=0, keepdim=True)) / data.std(dim=0, keepdim=True)
self.mode = mode
def __getitem__(self, idx):
"""
根据索引返回一个样本
"""
if self.mode != "test":
return self.data[idx].float(), self.y[idx].float()
else:
return self.data[idx].float()
def __len__(self):
"""
返回数据集大小
"""
return len(self.data)4.3 技术点详解
4.3.1 训练集/验证集划分策略
逢5取1策略:
# 索引: 0 1 2 3 4 5 6 7 8 9 10 ...
# 类型: V T T T T V T T T T V ...
# ↑ ↑ ↑
# 验证集 验证集 验证集
# 训练集:80%的数据(i % 5 != 0)
# 验证集:20%的数据(i % 5 == 0)4.3.2 数据标准化
# 标准化公式:normalized_data = (data - mean) / std
# 例:原始数据:[10, 20, 30, 40, 50] 均值:30 标准差:14.14 标准化后:[-1.41, -0.71, 0, 0.71, 1.41]五、神经网络模型设计
5.1 模型架构
class MyModel(nn.Module):
def __init__(self, inDim):
"""
初始化模型
参数:
inDim: 输入特征维度(6或93)
"""
super(MyModel, self).__init__()
# 第一层:输入层 → 隐藏层
self.fc1 = nn.Linear(inDim, 64)
# 激活函数
self.relu1 = nn.ReLU()
# 第二层:隐藏层 → 输出层
self.fc2 = nn.Linear(64, 1)
def forward(self, x):
"""
前向传播
"""
x = self.fc1(x) # 线性变换
x = self.relu1(x) # 非线性激活
x = self.fc2(x) # 输出层
# 处理输出维度
if len(x.size()) > 1:
return x.squeeze(1) # 去掉多余的维度
return x5.2 模型结构可视化
输入层 隐藏层 输出层
(6维) (64维) (1维)
x₁ ─┐
x₂ ─┤
x₃ ─┼─→ [64个神经元] ─→ [1个神经元] ─→ 预测值
x₄ ─┤ (ReLU激活)
x₅ ─┤
x₆ ─┘
参数量计算:
- fc1: 6×64 + 64 = 448个参数
- fc2: 64×1 + 1 = 65个参数
- 总计: 513个参数
六、损失函数与正则化
6.1 自定义损失函数
def mseLoss_with_reg(pred, target, model):
"""
带L2正则化的MSE损失函数
参数:
pred: 模型预测值
target: 真实标签
model: 模型对象(用于获取参数)
返回:
总损失 = MSE损失 + L2正则化损失
"""
# 第1步:计算MSE损失
loss = nn.MSELoss(reduction='mean')
mse_loss = loss(pred, target)
# 第2步:计算L2正则化损失
regularization_loss = 0
for param in model.parameters():
# L2正则化:参数的平方和
regularization_loss += torch.sum(param ** 2)
# L1正则化(注释掉的):
# regularization_loss += torch.sum(abs(param))
# 第3步:组合损失
# λ = 0.00075(正则化系数)
total_loss = mse_loss + 0.00075 * regularization_loss
return total_loss6.2 MSE损失详解
# MSE (Mean Squared Error) 均方误差
MSE = (1/n) × Σ(预测值 - 真实值)²
# 例子:
真实值:[1.0, 2.0, 3.0]
预测值:[1.2, 1.8, 3.1]
误差:[0.2, -0.2, 0.1]
平方:[0.04, 0.04, 0.01]
MSE = (0.04 + 0.04 + 0.01) / 3 = 0.03为什么用MSE?
- 回归问题的标准损失函数
- 惩罚大误差(平方项)
- 可微分,便于梯度下降
6.3 L2正则化详解
# L2正则化公式
L2_loss = λ × Σ(参数²)
# 总损失
total_loss = MSE + λ × Σ(参数²)
↑ ↑
拟合数据 保持简单作用机制:
# 没有正则化:
模型只关心降低MSE
→ 参数可能变得很大
→ 模型过度复杂
→ 过拟合
# 有L2正则化:
模型需要平衡两个目标:
1. 降低MSE(拟合数据)
2. 降低参数平方和(保持简单)
→ 参数保持较小
→ 模型简单稳定
→ 泛化能力强λ = 0.00075的含义:
# λ太小(如0.00001):
正则化作用弱,可能过拟合
# λ适中(如0.00075):✓
平衡拟合和简单性
# λ太大(如0.1):
正则化作用太强,可能欠拟合七、模型训练
7.1 训练配置
config = {
"lr": 0.001, # 学习率
"epochs": 20, # 训练轮数
"momentum": 0.9, # 动量
"save_path": "model_save/best_model.pth", # 模型保存路径
"rel_path": "pred.csv" # 预测结果保存路径
}7.2 完整训练函数
def train_val(model, train_loader, val_loader, device, epochs, optimizer, loss, save_path):
"""
训练和验证模型
参数:
model: 神经网络模型
train_loader: 训练数据加载器
val_loader: 验证数据加载器
device: 设备(CPU或GPU)
epochs: 训练轮数
optimizer: 优化器
loss: 损失函数
save_path: 模型保存路径
"""
model = model.to(device)
# 记录每轮的损失
plt_train_loss = []
plt_val_loss = []
# 记录最小验证损失
min_val_loss = 9999999999999
# 开始训练
for epoch in range(epochs):
train_loss = 0.0
val_loss = 0.0
start_time = time.time()
# 训练阶段
model.train() # 设置为训练模式
for batch_x, batch_y in train_loader:
# 数据移到设备上
x, target = batch_x.to(device), batch_y.to(device)
# 前向传播
pred = model(x)
# 计算损失(包含正则化)
train_bat_loss = loss(pred, target, model)
# 反向传播
train_bat_loss.backward()
# 更新参数
optimizer.step()
# 清空梯度
optimizer.zero_grad()
# 累加损失
train_loss += train_bat_loss.cpu().item()
# 计算平均训练损失
plt_train_loss.append(train_loss / len(train_loader))
# 验证阶段
model.eval() # 设置为评估模式
with torch.no_grad(): # 不计算梯度
for batch_x, batch_y in val_loader:
x, target = batch_x.to(device), batch_y.to(device)
# 前向传播
pred = model(x)
# 计算损失
val_bat_loss = loss(pred, target, model)
# 累加损失
val_loss += val_bat_loss.cpu().item()
# 计算平均验证损失
plt_val_loss.append(val_loss / len(val_loader))
# 保存最佳模型
if val_loss < min_val_loss:
torch.save(model, save_path)
min_val_loss = val_loss
print(f"✓ 保存最佳模型(验证损失: {val_loss:.6f})")
# 打印训练信息
print("[%03d/%03d] %2.2f sec(s) Train loss: %.6f | Val loss: %.6f" %
(epoch, epochs, time.time()-start_time,
plt_train_loss[-1], plt_val_loss[-1]))
# 绘制损失曲线
plt.plot(plt_train_loss, label='Train Loss')
plt.plot(plt_val_loss, label='Val Loss')
plt.title("Training and Validation Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
plt.grid(True)
plt.show()7.3 训练过程详解
7.3.1 训练模式 vs 评估模式
# 训练模式
model.train()
- 启用Dropout(如果有)
- 启用BatchNorm的更新(如果有)
- 计算梯度
# 评估模式
model.eval()
- 禁用Dropout
- 使用固定的BatchNorm参数
- 不计算梯度(配合torch.no_grad())7.3.2 梯度清零的重要性
# 为什么需要optimizer.zero_grad()?
# PyTorch的梯度是累加的:
第1次backward():grad = 梯度1
第2次backward():grad = 梯度1 + 梯度2 # 累加!
第3次backward():grad = 梯度1 + 梯度2 + 梯度3
# 如果不清零:
梯度会越来越大 → 参数更新错误 → 训练失败
# 正确做法:
for batch in data_loader:
optimizer.zero_grad() # 清零梯度
loss.backward() # 计算梯度
optimizer.step() # 更新参数7.3.3 保存最佳模型策略
# 为什么保存验证损失最小的模型?
训练损失最小 ≠ 模型最好
验证损失最小 = 泛化能力最强 ✓
# 例子:
Epoch 10: train_loss=0.20, val_loss=0.35 → 保存
Epoch 11: train_loss=0.18, val_loss=0.40 → 不保存(验证损失变大)
Epoch 12: train_loss=0.15, val_loss=0.32 → 保存(验证损失更小)7.4 训练输出示例
k best features are: ['tested_positive', 'tested_positive', 'nohh_cmnty_cli', 'nohh_cmnty_cli', 'nohh_cmnty_cli', 'hh_cmnty_cli']
cuda
[000/020] 2.17 sec(s) Trainloss: 24.923024 |Valloss: 1.101962
[001/020] 0.29 sec(s) Trainloss: 1.307560 |Valloss: 1.073767
[002/020] 0.30 sec(s) Trainloss: 1.236160 |Valloss: 1.528566
[003/020] 0.30 sec(s) Trainloss: 1.169382 |Valloss: 1.005413
[004/020] 0.30 sec(s) Trainloss: 1.132450 |Valloss: 0.986223
[005/020] 0.30 sec(s) Trainloss: 1.129263 |Valloss: 1.044358
[006/020] 0.28 sec(s) Trainloss: 1.137480 |Valloss: 1.008713
[007/020] 0.29 sec(s) Trainloss: 1.125366 |Valloss: 0.958152
[008/020] 0.28 sec(s) Trainloss: 1.157921 |Valloss: 1.735986
[009/020] 0.29 sec(s) Trainloss: 1.144497 |Valloss: 0.945615
[010/020] 0.29 sec(s) Trainloss: 1.164328 |Valloss: 1.145512
[011/020] 0.30 sec(s) Trainloss: 1.137105 |Valloss: 0.990260
[012/020] 0.31 sec(s) Trainloss: 1.119704 |Valloss: 1.120381
[013/020] 0.31 sec(s) Trainloss: 1.123307 |Valloss: 0.974390
[014/020] 0.30 sec(s) Trainloss: 1.105090 |Valloss: 1.004918
[015/020] 0.31 sec(s) Trainloss: 1.111448 |Valloss: 0.941703
[016/020] 0.34 sec(s) Trainloss: 1.111513 |Valloss: 1.115820
[017/020] 0.33 sec(s) Trainloss: 1.097978 |Valloss: 0.975191
[018/020] 0.35 sec(s) Trainloss: 1.158795 |Valloss: 1.250422
[019/020] 0.37 sec(s) Trainloss: 1.157728 |Valloss: 0.979788
八、模型评估与预测
8.1 评估函数
def evaluate(save_path, test_loader, device, rel_path):
"""
在测试集上评估模型并保存预测结果
参数:
save_path: 保存的模型路径
test_loader: 测试数据加载器
device: 设备
rel_path: 预测结果保存路径
"""
# 加载最佳模型
model = torch.load(save_path).to(device)
# 存储预测结果
rel = []
# 预测
with torch.no_grad():
for x in test_loader:
pred = model(x.to(device))
rel.append(pred.cpu().item())
print("预测结果:", rel[:10], "...") # 打印前10个
# 保存到CSV文件
with open(rel_path, "w", newline='') as f:
csvWriter = csv.writer(f)
csvWriter.writerow(["id", "tested_positive"])
for i, value in enumerate(rel):
csvWriter.writerow([str(i), str(value)])
print(f"✓ 预测结果已保存到 {rel_path}")九、损失曲线可视化
本项目的损失曲线
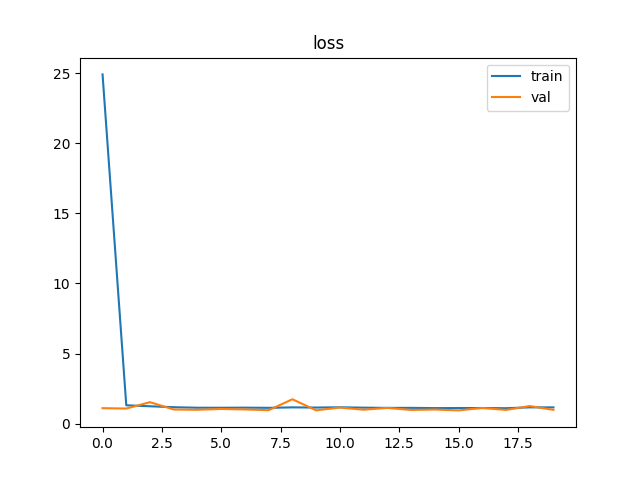
十、常见问题与解决方案
10.1 问题1:KMP_DUPLICATE_LIB_OK错误
错误信息:
OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.解决方案:
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"10.2 问题2:验证损失不下降
可能原因:
- 学习率太大或太小
- 正则化系数太大
- 模型太简单
解决方案:
# 调整学习率
config["lr"] = 0.0001 # 降低学习率
# 调整正则化系数
regularization_loss * 0.0001 # 降低正则化强度
# 增加模型复杂度
self.fc1 = nn.Linear(inDim, 128) # 增加隐藏层神经元10.3 问题3:训练损失和验证损失差距大
原因: 过拟合
解决方案:
# 1. 增强正则化
regularization_loss * 0.001 # 增大λ
# 2. 减少模型复杂度
self.fc1 = nn.Linear(inDim, 32) # 减少神经元
# 3. 增加训练数据
# 或使用数据增强技术10.4 问题4:GPU内存不足
错误信息:
RuntimeError: CUDA out of memory解决方案:
# 1. 减小batch_size
batch_size = 8 # 从16减到8
# 2. 使用CPU训练
device = "cpu"
# 3. 清理GPU缓存
torch.cuda.empty_cache()10.5 问题5:损失变成NaN
可能原因:
- 学习率太大
- 梯度爆炸
- 数据未标准化
解决方案:
# 1. 降低学习率
config["lr"] = 0.0001
# 2. 梯度裁剪
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
# 3. 检查数据标准化
print(data.mean(), data.std()) # 应该接近0和1
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)