梯度消失与爆炸:究竟是什么让深层网络难以训练?
当我们谈起深度学习,往往会惊叹于它在计算机视觉、自然语言处理等领域取得的惊人成就。然而,在这些耀眼成就的背后,有一个困扰了研究者几十年的顽疾——梯度消失与爆炸问题。这两个问题就像是深层网络训练中的“隐形杀手”,悄无声息地阻碍着模型学习,让无数深度学习实践者头疼不已。
你是否曾经训练一个深层网络时,发现损失下降得异常缓慢,甚至几乎不变?或者突然遇到损失变成NaN的情况?如果是这样,很可能你已经与梯度消失或爆炸问题不期而遇了。
本文将深入浅出地剖析梯度消失与爆炸的本质,通过数学原理解释它们为何发生,并为你提供一系列实用的解决方案。无论你是深度学习新手,还是希望深入理解这一问题的研究者,相信这篇文章都能给你带来启发。
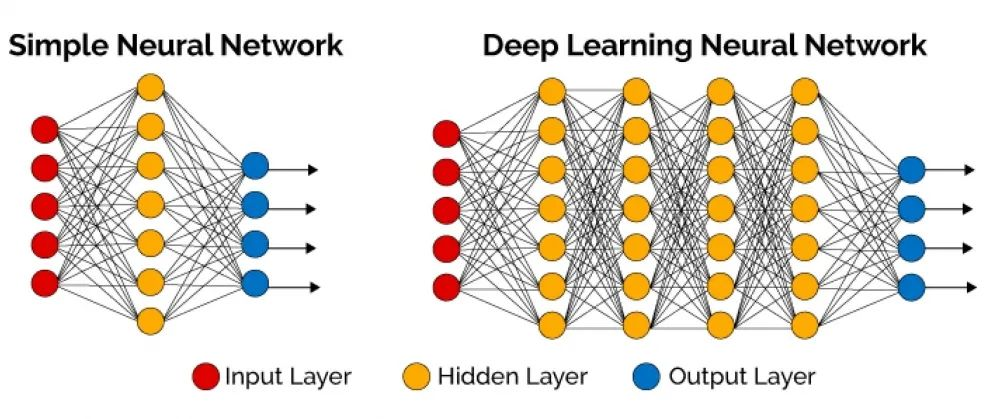
1. 揭秘梯度消失与爆炸:深层网络训练的双重困境
梯度消失和梯度爆炸,简单来说,是在深度神经网络训练过程中,梯度在反向传播时出现异常的两个极端情况。当梯度在反向传播中逐渐变小,趋近于零时,就是梯度消失;相反,当梯度不断增大,变得极大时,就是梯度爆炸。
梯度消失:当学习停止时
想象一下,你正在教一个孩子认识动物。你反复展示图片并纠正错误,但奇怪的是,无论你教多少次,孩子对最基本的猫狗区分仍然毫无进步。这就是梯度消失问题的直观类比——网络的前面层几乎停止学习,无法提取基础特征。
在深层网络中,梯度消失的表现通常是模型无法从训练数据中获得有效更新,损失几乎保持不变。靠近输入层的参数几乎不变,而靠近输出层的参数则在不断优化。结果就是,网络虽然很深,但实际起作用的只是最后几层,前面的层无法提取有意义特征,整个网络的表达能力大打折扣。
梯度爆炸:当学习失控时
与梯度消失相反,梯度爆炸则是梯度在反向传播过程中指数级增长,导致权重更新过大,网络变得极度不稳定。你可以把它想象成开车时猛踩油门,车速瞬间失控。
梯度爆炸的典型表现包括模型训练不稳定,损失值出现显著波动,甚至因为数值溢出而变成NaN(Not a Number)。在极端情况下,参数可能会变得过大,导致整个网络的计算崩溃。
有趣的是,虽然梯度爆炸问题听起来更猛烈,但实际上梯度消失在训练RNN时更为常见。不过梯度爆炸一旦发生,其破坏性却更为直接和明显。
2. 数学根源:链式法则的“诅咒”
要真正理解梯度消失与爆炸,我们需要从数学角度揭开它的面纱。这个过程的核心就是反向传播算法和链式法则。
反向传播中的连乘效应
在深度神经网络中,误差信号从输出层向输入层传播时,需要经过一系列链式求导。具体来说,对于网络前层的参数,其梯度等于后面所有层的局部梯度乘积。
想到这个长长的乘积,问题就一目了然了——梯度是一系列因子的乘积。当层数n很大时,这个乘积的结果会如何变化呢?
梯度消失的数学解释
如果这些因子的绝对值大多数都小于1,那么随着层数增加,乘积的结果会指数级衰减,趋近于0。这就是梯度消失。
特别地,当我们使用Sigmoid激活函数时,其导数的最大值仅为0.25。这意味着即使是最理想的情况,每经过一层,梯度的上界都会缩小到原来的1/4。经过10层传播,梯度就会衰减到原来的 (0.25)^10 ≈ 9.5e-7,几乎可以忽略不计。
梯度爆炸的数学解释
反过来,如果这些因子的绝对值大多数都大于1,那么随着层数增加,乘积的结果会指数级增长,变得极大。这就是梯度爆炸。
梯度爆炸通常发生在网络权重初始化过大时。如果初始权重让每一层的输出放大,那么反向传播时的梯度也会被不断放大,最终导致参数更新步长过大,网络发散。
从本质上讲,梯度消失和爆炸都是因为网络太深,网络权值更新不稳定造成的,其根源在于梯度反向传播中的连乘效应。
3. 罪魁祸首:谁在让梯度消失与爆炸?
隐藏层过多的困境
隐藏层层数过多是导致梯度问题的直接原因之一。从深层网络角度来看,不同层的学习速度存在巨大差异——靠近输出的层学习情况良好,而靠近输入的层学习缓慢,甚至训练很久后,前几层的权值仍与初始随机值相差无几。这正是梯度消失的典型症状。
激活函数的“饱和效应”
激活函数的选择对梯度问题有着决定性影响。以经典的Sigmoid函数为例,它会把输入值“挤压”到0到1之间,当输入值很大或很小时,函数进入饱和区,导数接近0。
Sigmoid导数的图像像一个钟形曲线,最大值仅有0.25。这意味着使用Sigmoid作为激活函数时,梯度每反向传播一层,就会至少缩小到原来的1/4。在深层网络中,这种衰减效应累积起来,必然导致梯度消失。
tanh函数虽然比Sigmoid稍好,导数范围在0到1之间,但最大值也只有1,且饱和区同样存在梯度接近于0的问题。因此,tanh也无法从根本上解决梯度消失。
权重初始化的影响
权重初始化是另一个关键因素。如果初始权重过大,当反向传播时,连乘效应会让梯度以指数形式增加,导致梯度爆炸。相反,如果初始权重过小,信号在前向传播时就可能衰减,反向传播时梯度更难以维持。
在早期研究中,人们发现将权重初始化为均值为0、标准差为1的高斯分布会导致梯度问题。这也促使研究者开发出更科学的初始化方法。
RNN的特殊困境
对于循环神经网络(RNN),梯度问题有其特殊的表现形式。RNN在处理长序列时,相当于一个展开后极深的网络——处理1000个时间步的数据,就相当于一个1000层的网络。
在这种结构下,长期依赖关系难以捕捉。例如在语言模型中,句子开头的名词单复数形式可能影响句子结尾的动词形态,中间可能隔着很长的修饰成分。由于梯度消失,网络难以让较早的输入影响较后的输出。这也正是为什么基础的RNN难以处理长序列的原因。
4. 破解之道:实战解决方案
面对梯度消失与爆炸,研究者们已经开发出多种有效的解决方案。下面我们来逐一剖析这些方法。
梯度裁剪:防止爆炸的“安全阀”
梯度裁剪是解决梯度爆炸最直接有效的方法。其核心思想是设置一个阈值,当梯度的范数超过这个阈值时,对梯度进行缩放,使其回到安全范围内。
这种方法就像为梯度流动安装了一个安全阀——当梯度爆炸即将发生时,强行将其限制在合理范围内,保证训练的稳定性。梯度裁剪特别适合处理RNN中可能出现的梯度爆炸问题。
以下是用PyTorch实现梯度裁剪的示例:
python
import torch
# 定义模型和优化器
model = DeepNetwork()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 训练循环中应用梯度裁剪
for data, target in dataloader:
optimizer.zero_grad()
output = model(data)
loss = loss_function(output, target)
loss.backward()
# 梯度裁剪:设置最大范数为1.0
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
optimizer.step()
激活函数的明智选择
既然饱和激活函数(如Sigmoid、tanh)是梯度消失的元凶之一,那么选择非饱和激活函数自然成为解决方案。
ReLU(Rectified Linear Unit)及其变体成为当前的主流选择。ReLU在正半轴的导数为1,这意味着梯度不会因为激活函数而衰减。下面的代码示例清晰地展示了ReLU相比Sigmoid在维持梯度大小上的优势:
python
import torch
import torch.nn as nn
# 使用Sigmoid的网络
class DeepSigmoidNet(nn.Module):
def __init__(self):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(100, 128), nn.Sigmoid(),
nn.Linear(128, 128), nn.Sigmoid(),
nn.Linear(128, 128), nn.Sigmoid(),
nn.Linear(128, 10)
)
# 使用ReLU的网络
class DeepReLUNet(nn.Module):
def __init__(self):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(100, 128), nn.ReLU(),
nn.Linear(128, 128), nn.ReLU(),
nn.Linear(128, 128), nn.ReLU(),
nn.Linear(128, 10)
)
# 对比第一层的梯度范数
# Sigmoid网络第一层梯度: 0.004324
# ReLU网络第一层梯度: 0.118170
可以看到,ReLU网络第一层的梯度比Sigmoid网络大了近30倍,这意味着前面层能够获得有效的更新。
此外,Leaky ReLU、ELU等ReLU变体进一步改进了ReLU在负半轴的问题,为负输入提供小的梯度,避免神经元死亡。
智能权重初始化
合适的权重初始化方法能够在前向传播和反向传播过程中维持信号的合理方差,防止指数级衰减或放大。
Xavier初始化(也称Glorot初始化)和He初始化是两种最常用的方法。Xavier初始化适用于tanh等对称激活函数,而He初始化专为ReLU及其变体设计。
He初始化的核心思想是:在第l层,权重从均值为0、方差为2/n_l的高斯分布中采样,其中n_l是该层的输入神经元数量(fan-in)。这种初始化方式确保了信号在经过ReLU后仍能保持适当的方差。
在PyTorch中,可以直接使用内置初始化函数:
python
import torch.nn.init as init
# 对模型的线性层应用Xavier初始化
for layer in model.layers:
if isinstance(layer, nn.Linear):
init.xavier_normal_(layer.weight)
批量归一化:稳定训练的利器
批量归一化(Batch Normalization,BN)是另一种解决梯度问题的强大工具。它的工作原理是对每一层的输入进行归一化,使其均值为0、方差为1,然后再进行缩放和平移变换。
BN为什么能缓解梯度问题?主要有几个原因:
-
它将每层的输出从激活函数的饱和区拉到了非饱和区,确保梯度有较大的值
-
它消除了前层参数变化引起的分布偏移,减少了梯度对参数尺度的依赖
-
它使网络对初始化不再那么敏感,可以使用更大的学习率
以下是在PyTorch中添加批量归一化层的示例:
python
import torch.nn as nn
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(10, 20)
self.bn1 = nn.BatchNorm1d(20) # 批量归一化层
self.relu = nn.ReLU()
self.fc2 = nn.Linear(20, 1)
def forward(self, x):
x = self.fc1(x)
x = self.bn1(x) # 在激活函数前应用BN
x = self.relu(x)
x = self.fc2(x)
return x
残差连接:梯度的高速公路
残差网络(ResNet)的提出是深度学习史上的里程碑之一。其核心思想是引入跳跃连接(skip connection),让信息可以直接跨层传播。
在残差块中,输出不是简单的F(x),而是F(x) + x。这种结构在反向传播时,梯度可以直接通过跳跃连接传回前层,就像为梯度流动开辟了一条“高速公路”。因此,即使在上百层甚至上千层的网络中,梯度也能顺利传播。
研究表明,残差连接的原理可以进一步推广。一种名为随机正交加性滤波器的方法,通过正交滤波器和加性组合,理论上可以保证即使在无限深的网络中梯度也不会消失或爆炸。
针对RNN的特殊设计:LSTM与GRU
对于RNN的梯度问题,研究者专门设计了长短期记忆网络(LSTM)和门控循环单元(GRU)。
LSTM通过精心设计的门控结构——遗忘门、输入门和输出门——来控制信息的流动。这些门允许网络选择性地记住或忘记信息,为梯度提供了一条随时间保持恒定的通道。这条通道使得梯度能够跨越长时间步传播而不衰减,从而解决了RNN中的长期依赖问题。
GRU是LSTM的简化版本,将遗忘门和输入门合并为更新门,同时引入重置门。它在保持类似效果的同时减少了参数量,计算效率更高。
5. 未来展望:更稳定的深度网络
梯度消失与爆炸问题的研究仍在继续。近年来,Transformer架构通过自注意力机制和层归一化,在很大程度上规避了传统RNN中的梯度问题。同时,新的激活函数(如Swish、GELU)和归一化方法(如LayerNorm、GroupNorm)不断涌现,进一步提升了训练的稳定性。
值得注意的是,最新的研究已经开始探索从架构设计上彻底解决梯度问题。通过追求动态等距(dynamical isometry)——即输入-输出雅可比矩阵的奇异值紧密分布在1附近——可以构建理论上不会出现梯度消失或爆炸的网络。这类研究或许会指引我们走向更深、更强大的网络架构。
总结
梯度消失与爆炸问题是深度学习的核心挑战之一,它们源于反向传播中的链式法则带来的连乘效应。网络过深、饱和激活函数的使用以及不当的权重初始化都是导致这些问题的常见原因。
幸运的是,研究者们已经发展出了一套完整的解决方案:
-
针对梯度爆炸,梯度裁剪提供了一种简单而有效的防护
-
针对梯度消失,ReLU等非饱和激活函数、He/Xavier初始化、批量归一化和残差连接共同构建了坚固的防线
-
针对RNN的长期依赖问题,LSTM和GRU等门控架构提供了专门设计
理解这些技术的原理和适用场景,不仅能帮助我们更好地训练深度网络,也能让我们在设计模型时做出更明智的选择。随着研究的深入,我们有理由相信,未来的网络将能够更深、更稳定、更强大,解锁人工智能的更多可能性。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)