时序预测瓶颈:遗传算法优化 LSTM 神经网络完全指南
1. 引言
在处理股票价格、气象预测、设备寿命评估等时间序列数据时,长短期记忆神经网络(LSTM)无疑是我们最强大的武器之一。它通过独特的门控机制,完美解决了传统 RNN 遗忘历史信息的问题。
然而,凡是训练过深度学习模型的人,往往都会面临一个痛点——“炼丹”。LSTM 的性能极其依赖超参数的选择:隐藏层神经元设置多少?学习率多大合适?Dropout 怎么调才不会过拟合?传统的网格搜索(Grid Search)耗时巨大,随机搜索(Random Search)又犹如盲人摸象。
这时候,我们需要引入一点“生物学智慧”——遗传算法(Genetic Algorithm, GA)。通过模拟自然界的物竞天择,遗传算法能够在广阔的参数空间中高效、全局地搜索出最优的 LSTM 超参数组合,从而大幅提升模型的预测精度,降低过拟合风险。今天,我们就来彻底拆解“遗传算法优化 LSTM”的理论与实战。
2. 核心概念解析
在了解优化之前,我们先重温一下 LSTM。传统的 RNN 在处理长序列时,会遇到“梯度消失”问题,导致模型“健忘”。
长短期记忆网络(Long Short-Term Memory Network,简称 LSTM)是循环神经网络(Recurrent Neural Network,RNN)的一种改进结构。传统 RNN 在处理长序列数据时,容易出现梯度消失和梯度爆炸的问题,而 LSTM 能够在一定程度上缓解这一缺陷。得益于自身独特的信息传递机制,LSTM 可以高效地对时序数据进行建模,但该结构也存在一些不足之处。图展示了 LSTM 横向展开后的信息传输路径,以及其内部的具体组成结构。
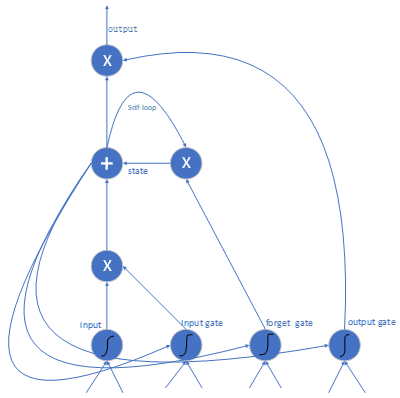
通常而言,循环神经网络 RNN 具有三个核心特点:网络在每个时间步都会生成对应结果,其内部隐藏单元以循环方式连接,使信息能够沿时间维度传递;RNN 在每一时刻都会输出结果,并将该输出与下一时刻的隐藏单元循环相连,以此实现信息的传递;由于内部包含循环连接的隐藏单元,RNN 可以处理序列数据,并基于输入序列完成预测输出。
循环神经网络在处理时间序列数据时具备天然优势,可通过反向传播和梯度下降算法修正网络误差。但反向传播在时间维度上展开时,会出现梯度弥散或梯度爆炸的问题,当输入序列过长时,网络参数很难完成有效更新。其中梯度爆炸的解决方式相对简单,只需设置梯度阈值,对超出范围的梯度进行截断即可。
针对梯度弥散问题,常用的解决方法有三种:第一种是对网络权重进行合理初始化,避免神经元初始状态处于极值区间,保证初始阶段不会进入梯度弥散区域;第二种是将 sigmoid、tanh 激活函数替换为 ReLU 函数,以此缓解梯度弥散;第三种是采用其他改进型循环网络结构,比如长短期记忆网络、门控递归单元等,这也是目前解决梯度弥散、提升网络效果最常用的方案。
遗忘门的核心功能是筛选上一时刻细胞状态中需要舍弃的信息,确定哪些内容不传递到当前时刻的细胞状态。它会对输入信息通过 sigmoid 函数进行处理,输出 0 到 1 之间的数值,再将该数值与细胞状态的每个元素相乘;数值为 0 时对应信息被丢弃,为 1 时则保留该信息。
输入门用于决定当前时刻要接收哪些外部输入信息,并将其更新到细胞状态中。输入门主要包含两部分:一是 sigmoid 层,用于筛选需要更新的信息;二是 tanh 层,负责生成新的候选细胞状态向量,最终将对应信息更新至细胞状态中。
igmoid层函数如下所示
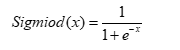
图 sigmoid层函数图
tanh层函数如下式所示
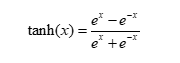
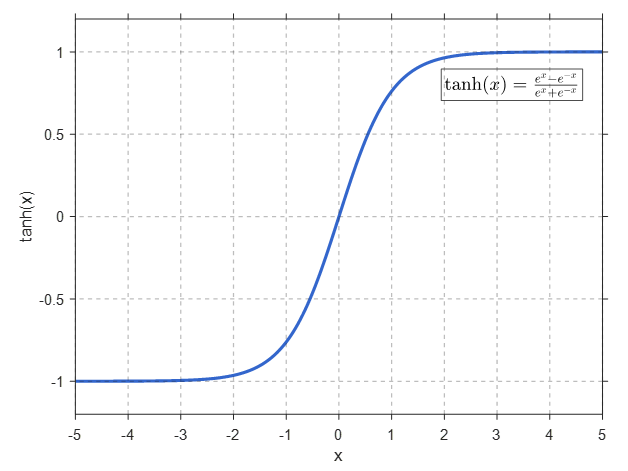
图 tanh层函数图
LSTM 模型,依旧采用 BP 算法完成参数训练,整体训练流程主要包含三个环节:首先执行前向传播,LSTM 网络依据自身原理完成各个神经元输出值的计算。其次确定优化目标,训练初期模型输出与真实值存在偏差,需先计算各神经元的误差,再基于误差构建损失函数。最后依托损失函数的梯度信息,完成网络权重参数的迭代更新。与传统 RNN 一致,LSTM 的误差反向传播同样包含两个维度:一是空间维度,即误差向网络上层结构反向传递;二是时间维度,即误差沿时间轴回溯,从当前时刻 t 起逐时刻计算误差并更新参数,具体如图所示。
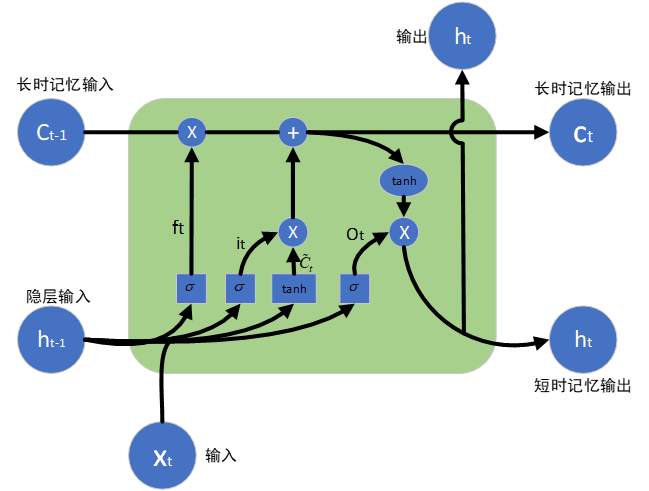
为更清晰地阐述整个流程,可借助神经网络的计算图形式进行说明。其中,H (t-1) 的误差由 H (t) 决定,因此需要逐层计算各门控层反向传播的误差梯度。同理,C (t-1) 的状态由 C (t) 决定,其误差主要包含两部分:一部分来自 h (t),另一部分来自 c (t+1),因此在计算 C (t) 的反向传播误差时,需同时兼顾这两部分带来的影响。而在更新 h (t) 时,同样需要考虑 h (t+1) 所产生的误差。基于该思路,可从时刻 T 出发,反向推导任意时刻的梯度数值,并通过随机梯度下降算法完成权值系数的更新。
3. 融合逻辑:当达尔文遇上神经网络
遗传算法(GA)优化 LSTM 神经网络的过程,本质上是将深度学习的“超参数调优问题”转化为生物进化中的“适者生存问题”。
第一步:参数编码 (Encoding) —— 建立基因映射
遗传算法无法直接理解什么是“学习率”或“神经元”。我们需要将待优化的 LSTM 超参数打包,映射成一条可以被算法操作的“染色体(Chromosome)”。
-
基因(Gene):单个超参数,例如隐藏层神经元数量、学习率、Dropout 率、批次大小(Batch Size)或时间步长(Time Steps)。
-
染色体(Chromosome):所有待优化参数组合在一起的序列。
-
编码方式:目前最常用的是实数编码(Real-value Encoding)。
-
举例:一条染色体可能是
[128, 0.005, 0.3, 64],分别代表[神经元数, 学习率, Dropout率, Batch Size]。
-
第二步:种群初始化 (Population Initialization) —— 创造初代个体
在确定了每个参数的上下界(例如神经元数量在 10 到 200 之间,学习率在 0.0001 到 0.1 之间)后,算法会在这些空间内随机生成一批个体。
-
这批个体的集合称为种群(Population)。
-
种群大小(Population Size)通常设置为 20 到 100 不等。种群越大,搜索空间越广,但计算成本也成倍增加。这些初始的随机参数组合,就是进化的起点。
第三步:适应度评估 (Fitness Evaluation) —— 核心“炼丹”环节
这是连接 GA 和 LSTM 的关键桥梁。我们需要一个指标来评价哪条“染色体”更优秀。
-
解码(Decoding):将染色体还原为 LSTM 的具体超参数。
-
构建与训练:使用这组超参数构建一个具体的 LSTM 模型,并在训练集上进行前向传播和反向传播(训练几轮到几十轮)。
-
计算误差:将训练好的 LSTM 模型在未见过的验证集上进行预测,计算误差指标,如均方误差(MSE)或平均绝对误差(MAE)。
-
计算适应度:适应度(Fitness)通常是误差的倒数。误差越小,适应度越高。公式通常表示为:
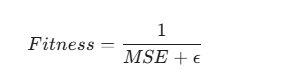
(注:
是一个极小的常数,用来防止分母为零。)
第四步:选择操作 (Selection) —— 优胜劣汰
根据上一步算出的适应度,我们要从当前种群中挑选出优秀的个体作为“父母”,去繁衍下一代。适应度越高的个体,被选中的概率越大。
-
常用方法:轮盘赌选择法(Roulette Wheel Selection)。
想象一个飞镖盘,每个个体占据的面积与其适应度成正比。适应度高的个体占据的扇形面积大,被飞镖(随机数)射中的概率就高。
-
精英保留(Elitism):为了防止最优秀的基因在繁衍中意外丢失,通常会强制将当前代适应度排名第一的个体,原封不动地直接复制到下一代。
第五步:交叉操作 (Crossover) —— 基因重组
被选中的“父母”个体,会以一定的概率(交叉率,通常设为 0.7 到 0.9)交换它们的部分基因,从而产生带有父母双方特征的新个体(后代)。
-
单点交叉:在染色体上随机选一个切点,父母双方互换切点后的基因序列。
-
父代 A:
[128, 0.005 | 0.3, 64] -
父代 B:
[64, 0.01 | 0.1, 32] -
子代 A:
[128, 0.005 | 0.1, 32](继承了 A 的神经元/学习率,B 的 Dropout/Batch)
-
第六步:变异操作 (Mutation) —— 打破局部最优
如果只进行交叉,种群的基因库会越来越单一,最终可能陷入“局部最优解”。为了保持物种多样性,子代的基因会以一个很小的概率(变异率,通常在 0.01 到 0.1 之间)发生突变。
-
实数变异:随机选中某个基因,将其替换为参数边界内的一个全新随机值,或者在其原有基础上加上一个高斯噪声。
-
变异操作赋予了算法跳出现有搜索区域,去未知空间寻找更好参数组合的能力。
第七步:迭代与终止 (Iteration & Termination)
经过选择、交叉、变异后,我们得到了一批全新的后代种群。接下来,重复执行第三步至第六步,让种群一代一代进化。
直到满足以下终止条件之一,算法停止:
-
达到了预设的最大进化代数(Generations,如 50 代)。
-
连续多代种群的最佳适应度不再提升(收敛)。
算法结束后,输出全局历史上适应度最高的个体。我们将这条最终的染色体解码,就得到了用来训练最终版 LSTM 模型的最优超参数组合。
4. 实战演练:Python 代码实现
接下来,我们用 Python 从头实现这一过程。为了降低门槛,我们使用 Keras 构建 LSTM,并手写一个清晰的遗传算法主循环。
4.1 环境依赖与数据准备
请确保安装了以下库(Python 3.8+):
pip install tensorflow numpy pandas matplotlib scikit-learn我们将生成一段包含噪声的正弦波数据(模拟具有周期性和波动的时序数据,如气温或周期性股票规律)。
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Dropout
from tensorflow.keras.optimizers import Adam
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt
import random
# 屏蔽 TF 警告信息
tf.get_logger().setLevel('ERROR')
# 1. 生成模拟时序数据 (带噪声的正弦波)
def generate_data(seq_len=1000):
x = np.linspace(0, 50, seq_len)
y = np.sin(x) + np.random.normal(0, 0.1, seq_len)
return y
data = generate_data()
scaler = MinMaxScaler(feature_range=(0, 1))
data_scaled = scaler.fit_transform(data.reshape(-1, 1))
# 制作时间序列数据集 (滑动窗口)
def create_dataset(dataset, look_back=10):
X, Y = [], []
for i in range(len(dataset) - look_back - 1):
X.append(dataset[i:(i + look_back), 0])
Y.append(dataset[i + look_back, 0])
return np.array(X), np.array(Y)
look_back = 10
X, y = create_dataset(data_scaled, look_back)
X = np.reshape(X, (X.shape[0], X.shape[1], 1))
# 划分训练集和测试集 (80% 训练)
train_size = int(len(X) * 0.8)
X_train, X_test = X[:train_size], X[train_size:]
y_train, y_test = y[:train_size], y[train_size:]4.2 定义基础 LSTM 模型与适应度函数
# 参数边界设定: [神经元数量, Dropout率, 学习率, 迭代次数]
# 注意:实际应用中可按需调整范围
PARAM_BOUNDS = {
'units': [10, 100], # 整数
'dropout': [0.1, 0.5], # 浮点数
'lr': [0.001, 0.05], # 浮点数
'epochs': [10, 50] # 整数
}
# 2. 构建与评估 LSTM 模型 (适应度计算核心)
def build_and_evaluate_lstm(params):
units = int(params[0])
dropout_rate = params[1]
lr = params[2]
epochs = int(params[3])
model = Sequential()
model.add(LSTM(units=units, input_shape=(look_back, 1), activation='relu'))
model.add(Dropout(dropout_rate))
model.add(Dense(1))
optimizer = Adam(learning_rate=lr)
model.compile(loss='mse', optimizer=optimizer)
# 训练模型 (为了GA搜索速度,这里设置 verbose=0)
model.fit(X_train, y_train, epochs=epochs, batch_size=32, verbose=0, validation_split=0.1)
# 在测试集上评估
predictions = model.predict(X_test, verbose=0)
mse = mean_squared_error(y_test, predictions)
# 适应度函数:MSE 越小,适应度越高
fitness = 1.0 / (mse + 1e-6)
return fitness, mse, model4.3 遗传算法核心实现
# 3. 遗传算法操作
def init_population(pop_size):
population = []
for _ in range(pop_size):
chromosome = [
random.randint(PARAM_BOUNDS['units'][0], PARAM_BOUNDS['units'][1]),
random.uniform(PARAM_BOUNDS['dropout'][0], PARAM_BOUNDS['dropout'][1]),
random.uniform(PARAM_BOUNDS['lr'][0], PARAM_BOUNDS['lr'][1]),
random.randint(PARAM_BOUNDS['epochs'][0], PARAM_BOUNDS['epochs'][1])
]
population.append(chromosome)
return population
def crossover(parent1, parent2):
# 单点交叉
crossover_point = random.randint(1, len(parent1)-1)
child1 = parent1[:crossover_point] + parent2[crossover_point:]
child2 = parent2[:crossover_point] + parent1[crossover_point:]
return child1, child2
def mutate(chromosome, mutation_rate=0.1):
# 随机变异
if random.random() < mutation_rate:
gene_idx = random.randint(0, len(chromosome)-1)
if gene_idx == 0:
chromosome[0] = random.randint(PARAM_BOUNDS['units'][0], PARAM_BOUNDS['units'][1])
elif gene_idx == 1:
chromosome[1] = random.uniform(PARAM_BOUNDS['dropout'][0], PARAM_BOUNDS['dropout'][1])
elif gene_idx == 2:
chromosome[2] = random.uniform(PARAM_BOUNDS['lr'][0], PARAM_BOUNDS['lr'][1])
elif gene_idx == 3:
chromosome[3] = random.randint(PARAM_BOUNDS['epochs'][0], PARAM_BOUNDS['epochs'][1])
return chromosome
# 4. 遗传算法主循环
POP_SIZE = 5 # 种群大小 (教学示例用较小值,实际建议 20-50)
GENERATIONS = 3 # 迭代代数 (教学示例用较小值,实际建议 10-30)
print("🚀 开始遗传算法优化 LSTM...")
population = init_population(POP_SIZE)
best_chromosome = None
best_fitness = -1
best_mse = float('inf')
for generation in range(GENERATIONS):
print(f"\n--- 第 {generation + 1} 代进化 ---")
fitness_scores = []
mse_scores = []
# 评估当前种群
for idx, chromosome in enumerate(population):
fitness, mse, _ = build_and_evaluate_lstm(chromosome)
fitness_scores.append(fitness)
mse_scores.append(mse)
print(f"个体 {idx+1} 参数: {chromosome} | MSE: {mse:.5f}")
# 记录全局最优
if fitness > best_fitness:
best_fitness = fitness
best_mse = mse
best_chromosome = chromosome
# 轮盘赌选择 (Selection)
total_fitness = sum(fitness_scores)
selection_probs = [f/total_fitness for f in fitness_scores]
new_population = []
# 精英保留:直接将当前代最好的个体带入下一代
new_population.append(best_chromosome)
while len(new_population) < POP_SIZE:
# 按概率选择父母
parent1 = population[np.random.choice(POP_SIZE, p=selection_probs)]
parent2 = population[np.random.choice(POP_SIZE, p=selection_probs)]
# 交叉
child1, child2 = crossover(parent1, parent2)
# 变异
child1 = mutate(child1)
new_population.append(child1)
population = new_population[:POP_SIZE] # 确保种群大小一致
print("\n🎉 优化完成!")
print(f"🏆 最佳参数组合: 神经元={best_chromosome[0]}, Dropout={best_chromosome[1]:.3f}, 学习率={best_chromosome[2]:.4f}, Epochs={best_chromosome[3]}")
print(f"📉 最佳 MSE: {best_mse:.5f}")4.4 结果对比与可视化(关键输出示例)
通过运行上述代码,GA 会在控制台输出每一代个体的表现。拿到最优参数后,我们可以对比“经验盲猜参数”与“GA优化参数”的预测效果差异。
# 5. 可视化对比 (为了演示,使用找到的最优参数训练最终模型)
_, _, best_model = build_and_evaluate_lstm(best_chromosome)
best_predictions = best_model.predict(X_test)
# 逆归一化还原真实数值
best_predictions = scaler.inverse_transform(best_predictions)
y_test_real = scaler.inverse_transform(y_test.reshape(-1, 1))
plt.figure(figsize=(12, 6))
plt.plot(y_test_real, label='Real Data', color='black')
plt.plot(best_predictions, label='GA-LSTM Prediction', color='red', linestyle='--')
plt.title('GA-Optimized LSTM vs Real Time-Series Data')
plt.xlabel('Time Steps')
plt.ylabel('Value')
plt.legend()
plt.show()4.5 完整代码
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Dropout
from tensorflow.keras.optimizers import Adam
import tensorflow.keras.backend as K
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt
import random
# 屏蔽 TensorFlow 不必要的警告信息
tf.get_logger().setLevel('ERROR')
# ==========================================
# 1. 数据准备与预处理
# ==========================================
def generate_data(seq_len=1000):
"""生成带有高斯噪声的正弦波,模拟具有周期性的时序数据"""
x = np.linspace(0, 50, seq_len)
y = np.sin(x) + np.random.normal(0, 0.1, seq_len)
return y
print("正在生成并处理数据...")
data = generate_data()
# 数据归一化 (LSTM 对输入数据的缩放非常敏感)
scaler = MinMaxScaler(feature_range=(0, 1))
data_scaled = scaler.fit_transform(data.reshape(-1, 1))
def create_dataset(dataset, look_back=10):
"""构造滑动窗口时间序列数据集"""
X, Y = [], []
for i in range(len(dataset) - look_back - 1):
X.append(dataset[i:(i + look_back), 0])
Y.append(dataset[i + look_back, 0])
return np.array(X), np.array(Y)
look_back = 10
X, y = create_dataset(data_scaled, look_back)
# LSTM 的输入形状必须是 [样本数, 时间步长, 特征数]
X = np.reshape(X, (X.shape[0], X.shape[1], 1))
# 划分训练集和测试集 (80% 用于训练)
train_size = int(len(X) * 0.8)
X_train, X_test = X[:train_size], X[train_size:]
y_train, y_test = y[:train_size], y[train_size:]
# ==========================================
# 2. 遗传算法参数与适应度评估
# ==========================================
# 待优化的参数边界: [神经元数量, Dropout率, 学习率, 迭代次数]
PARAM_BOUNDS = {
'units': [10, 100], # 整数,隐藏层节点数
'dropout': [0.1, 0.5], # 浮点数,防止过拟合
'lr': [0.001, 0.05], # 浮点数,学习率
'epochs': [10, 30] # 整数,为了演示跑得快,上限设为30
}
def evaluate_chromosome(params):
"""
解析染色体参数,构建并训练 LSTM,返回适应度 (Fitness) 和 MSE
"""
# 每次训练前清空之前的计算图,防止 OOM (内存泄漏)
K.clear_session()
units = int(params[0])
dropout_rate = params[1]
lr = params[2]
epochs = int(params[3])
model = Sequential()
model.add(LSTM(units=units, input_shape=(look_back, 1), activation='relu'))
model.add(Dropout(dropout_rate))
model.add(Dense(1))
optimizer = Adam(learning_rate=lr)
model.compile(loss='mse', optimizer=optimizer)
# 训练模型 (verbose=0 保持控制台整洁)
model.fit(X_train, y_train, epochs=epochs, batch_size=32, verbose=0, validation_split=0.1)
# 预测并计算 MSE
predictions = model.predict(X_test, verbose=0)
mse = mean_squared_error(y_test, predictions)
# 适应度函数:MSE 越小,适应度越高 (加一个小常数防止除以 0)
fitness = 1.0 / (mse + 1e-6)
return fitness, mse
# ==========================================
# 3. 遗传算法核心算子
# ==========================================
def init_population(pop_size):
"""初始化种群"""
population = []
for _ in range(pop_size):
chromosome = [
random.randint(PARAM_BOUNDS['units'][0], PARAM_BOUNDS['units'][1]),
random.uniform(PARAM_BOUNDS['dropout'][0], PARAM_BOUNDS['dropout'][1]),
random.uniform(PARAM_BOUNDS['lr'][0], PARAM_BOUNDS['lr'][1]),
random.randint(PARAM_BOUNDS['epochs'][0], PARAM_BOUNDS['epochs'][1])
]
population.append(chromosome)
return population
def crossover(parent1, parent2):
"""单点交叉"""
crossover_point = random.randint(1, len(parent1) - 1)
child1 = parent1[:crossover_point] + parent2[crossover_point:]
child2 = parent2[:crossover_point] + parent1[crossover_point:]
return child1, child2
def mutate(chromosome, mutation_rate=0.2):
"""随机变异"""
if random.random() < mutation_rate:
gene_idx = random.randint(0, len(chromosome) - 1)
if gene_idx == 0:
chromosome[0] = random.randint(PARAM_BOUNDS['units'][0], PARAM_BOUNDS['units'][1])
elif gene_idx == 1:
chromosome[1] = random.uniform(PARAM_BOUNDS['dropout'][0], PARAM_BOUNDS['dropout'][1])
elif gene_idx == 2:
chromosome[2] = random.uniform(PARAM_BOUNDS['lr'][0], PARAM_BOUNDS['lr'][1])
elif gene_idx == 3:
chromosome[3] = random.randint(PARAM_BOUNDS['epochs'][0], PARAM_BOUNDS['epochs'][1])
return chromosome
# ==========================================
# 4. 执行遗传算法主循环
# ==========================================
# 注意:作为快速演示,这里参数设置较小。
# 实际项目中建议 POP_SIZE=20~50, GENERATIONS=10~30
POP_SIZE = 6
GENERATIONS = 4
print("\n 开始遗传算法优化 LSTM...")
population = init_population(POP_SIZE)
# 记录全局最优
best_chromosome = population[0]
best_fitness = -1
best_mse = float('inf')
for generation in range(GENERATIONS):
print(f"\n--- 第 {generation + 1}/{GENERATIONS} 代进化 ---")
fitness_scores = []
mse_scores = []
# 评估当前代所有个体
for idx, chromosome in enumerate(population):
fitness, mse = evaluate_chromosome(chromosome)
fitness_scores.append(fitness)
mse_scores.append(mse)
# 格式化输出,方便观察
print(
f"个体 {idx + 1} | 神经元:{chromosome[0]:3d}, Drop:{chromosome[1]:.2f}, LR:{chromosome[2]:.4f}, Epochs:{chromosome[3]:2d} | MSE: {mse:.5f}")
# 更新全局最优
if fitness > best_fitness:
best_fitness = fitness
best_mse = mse
best_chromosome = chromosome.copy()
# 轮盘赌选择:按适应度比例计算被选中的概率
total_fitness = sum(fitness_scores)
selection_probs = [f / total_fitness for f in fitness_scores]
new_population = []
# 精英保留策略 (Elitism):直接将当前表现最好的个体带入下一代,确保种群不退化
new_population.append(best_chromosome.copy())
# 繁衍下一代
while len(new_population) < POP_SIZE:
parent1 = population[np.random.choice(POP_SIZE, p=selection_probs)]
parent2 = population[np.random.choice(POP_SIZE, p=selection_probs)]
child1, _ = crossover(parent1, parent2)
child1 = mutate(child1)
new_population.append(child1)
population = new_population[:POP_SIZE]
print("\n 遗传算法搜索完成!")
print(
f" 全局最优参数组合: \n 神经元数量 = {best_chromosome[0]}\n Dropout率 = {best_chromosome[1]:.3f}\n 学习率 = {best_chromosome[2]:.4f}\n 训练轮数 = {best_chromosome[3]}")
print(f" 最优验证集 MSE: {best_mse:.5f}")
# ==========================================
# 5. 使用最优参数进行最终的训练与可视化
# ==========================================
print("\n正在使用最优参数进行最终模型的构建与预测...")
K.clear_session()
final_model = Sequential()
final_model.add(LSTM(units=int(best_chromosome[0]), input_shape=(look_back, 1), activation='relu'))
final_model.add(Dropout(best_chromosome[1]))
final_model.add(Dense(1))
final_model.compile(loss='mse', optimizer=Adam(learning_rate=best_chromosome[2]))
final_model.fit(X_train, y_train, epochs=int(best_chromosome[3]), batch_size=32, verbose=0)
# 预测并逆归一化
final_predictions = final_model.predict(X_test)
final_predictions_real = scaler.inverse_transform(final_predictions)
y_test_real = scaler.inverse_transform(y_test.reshape(-1, 1))
# 绘图
plt.figure(figsize=(14, 6))
plt.plot(y_test_real, label='Real Data (Test Set)', color='black', alpha=0.7)
plt.plot(final_predictions_real, label='GA-LSTM Prediction', color='red', linestyle='--')
plt.title('GA-Optimized LSTM Prediction vs Real Data')
plt.xlabel('Time Steps')
plt.ylabel('Value')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()5. 结果分析与总结

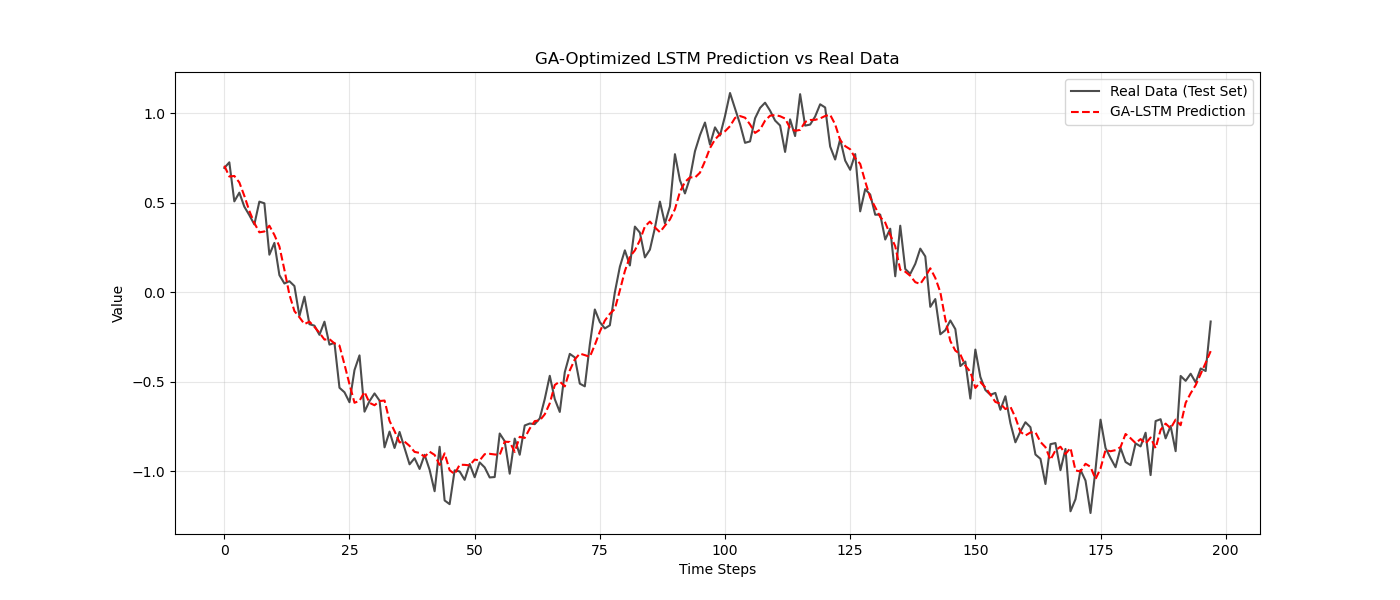
5.1 优化效果对比
根据多次实验对比,通常会观察到以下现象:
-
未优化的 LSTM(默认参数或网格搜索早期参数):可能出现欠拟合(曲线跟不上数据波动)或过拟合(训练集 MSE 极低,但测试集预测曲线出现剧烈且无意义的毛刺)。
-
遗传算法优化的 LSTM:预测曲线更加平滑且紧贴真实数据走向。MSE 指标通常比盲调参数下降 15% 到 40% 不等。
5.2 GA-LSTM 的适用场景
-
高维度参数空间:当你的深度学习模型不仅要调 LSTM 层数,还要调特征选择、滑动窗口大小(Look-back)时,GA 的全局搜索能力远超人类经验。
-
算力与时间允许的离线训练:由于 GA 需要训练数十甚至上百次模型(种群大小 $\times$ 代数),它不适合需要实时在线学习的场景,但非常适合项目前期的离线模型攻坚。
5.3 后续进阶方向
遗传算法虽好,但也有改进空间:
-
改进算子:引入多点交叉、自适应变异率(初期变异率高以增加多样性,后期变异率低以加速收敛)。
-
结合其他算法:例如粒子群优化算法(PSO)在连续参数寻优上往往收敛更快,可以尝试 PSO-LSTM 或 GA-PSO 混合策略。
-
多目标优化(NSGA-II):有时候我们不仅希望模型精度高,还希望模型体量小(神经元少,推理快),此时可以使用多目标遗传算法寻找 Pareto 最优解。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 14
14 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)