Redis基础
目录
4.1.3.3 .SpringDataRedis的序列化方式
缓存
对于经常访问的数据,每次都从数据库(硬盘)中获取是比较慢的,所以可以利用性能更高的存储来提高系统响应速度,俗称缓存。
合理使用缓存可以显著降低数据库的压力、提高系统性能。
什么样的数据适合缓存?对于“读多写少”的数据就非常适合缓存,也就是要频繁查询的,不怎么修改的数据。
具体来说:
- 高频访问的数据:如系统首页、热门推荐内容等。
- 计算成本较高的数据:如复杂查询结果、大量数据的统计结果。
- 允许短时间延迟的数据:如不需要实时更新的排行榜、图片列表等。
redis分布式缓存
Redis分布式缓存是指将缓存数据分布存储在多台服务器上,以便在高并发场景下提供更高的吞吐量和更好的容错性。
Redis是实现分布式缓存的主流方案,也是后端开发必学的技能, 主要是由于它具有下面几个优势:
- 高性能:基于内存操作,访问速度极快。单节点Redis的读写QPS可达10w次每秒!
- 丰富的数据结构:支持字符串、列表、集合、哈希、位图等,适用于各种数据结构存储。
- 分布式支持:可以通过Redis Cluster构建高可用、高性能的分布式缓存,还提供哨兵集群机制提升可用性、提供分片集群机制提高可扩展性。
缓存设计
使用redis前一定要先明确如何设计缓存,比如需要缓存首页的图片列表数据,也就是对listPictureVOByPage接口进行缓存,首先要按照缓存的三要素“key、value、过期时间"进行设计。
1)缓存key设计
由于接口支持传入不同的查询条件,不同查询条件查询到的数据也不同,因此需要将查询条件作为缓存key的一部分。
可以将查询条件对象转换为SON字符串,但这个JSON会比较长,可以利用哈希算法(md5)来压缩key。
此外,由于使用分布式缓存,可能有多个项目和业务共享,因此需要在key的开头拼接前缀进行隔离。设计出的key如下:
项目名:listPictureVOByPage:${查询条件key}
2)缓存value设计
缓存从数据库中查到的Page分页对象,存储为什么格式呢?这里有2种选择:
- 为了可读性,可以转换为JSON结构的字符串。
- 为了压缩空间,可以存为二进制等其他结构
但是对应的Redis数据结构都是string
3)缓存的过期时间设置
必须设置缓存的过期时间!根据实际业务场景和缓存空间的大小、数据的一致性的要求设置,合适即可,此处由于查询条件较多、而且考虑到图片会持续更新,设置为5~60分钟即可。
1. Redis入门
1.1 Redis简介
Redis是一个基于内存的键值型(key-value)NoSQL数据库,其中的数据都是以key-value对的形式来存储的。Redis 是互联网技术领域使用最为广泛的存储中间件。
官网:https://redis.io 中文网:Redis中文网
key-value结构存储:
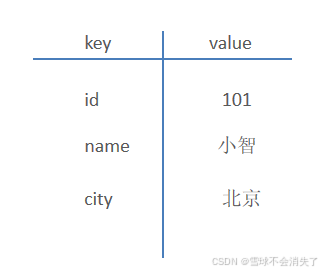
主要特点:
-
基于内存存储,读写性能高
-
存储键值(key-value)型数据,value支持多种不同的数据类型,功能丰富
-
单线程,每个命令具备原子性
-
适合存储热点数据(热点商品、资讯、新闻)
-
企业应用广泛
-
支持数据持久化
-
支持主从集群.分片集群
-
支持多语言客户端
Redis是用C语言开发的一个开源的高性能键值对(key-value)数据库,官方提供的数据是可以达到100000+的QPS(每秒内查询次数)。它存储的value类型比较丰富,也被称为结构化的NoSql数据库。
NoSql(Not Only SQL),不仅仅是SQL,泛指非关系型数据库。NoSql数据库并不是要取代关系型数据库,而是关系型数据库的补充。
结构化与非结构化:
传统关系型数据库是结构化数据,每一张表都有严格的约束信息:字段名、字段的数据类型、字段的约束等等信息,插入的数据必须遵守这些约束:
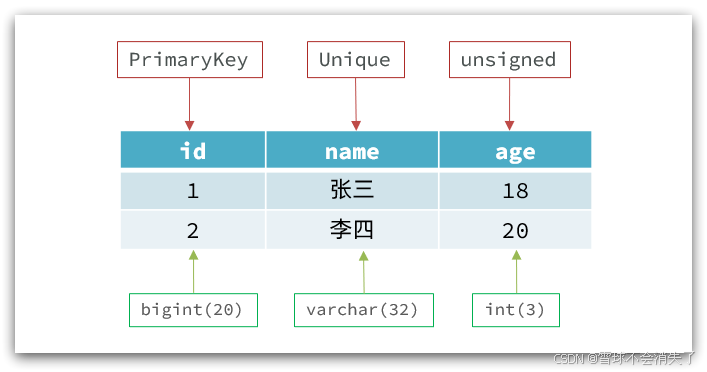
而NoSql数据库则没有严格约束,往往形式松散,自由。
可以是键值型:
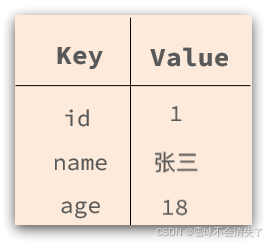
也可以是文档型:

甚至可以是图格式:
关联和非关联:
传统数据库的表与表之间往往存在关联,例如外键:
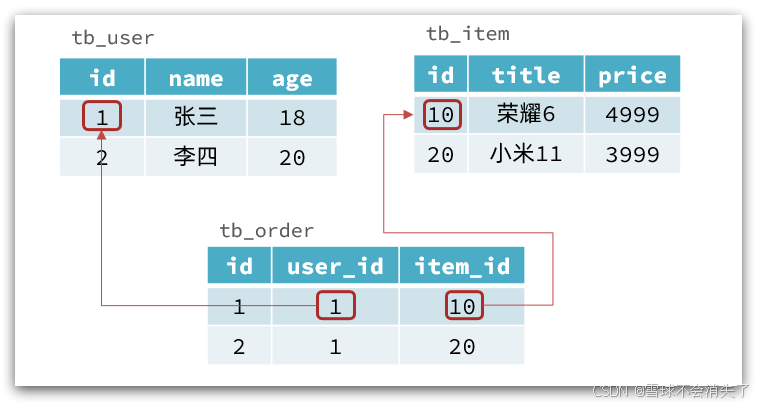
而非关系型数据库不存在关联关系,要维护关系要么靠代码中的业务逻辑,要么靠数据之间的耦合:
{
id: 1,
name: "张三",
orders: [
{
id: 1,
item: {
id: 10, title: "荣耀6", price: 4999
}
},
{
id: 2,
item: {
id: 20, title: "小米11", price: 3999
}
}
]
}此处要维护“张三”的订单与商品“荣耀”和“小米11”的关系,不得不冗余的将这两个商品保存在张三的订单文档中,不够优雅。还是建议用业务来维护关联关系。
查询方式
传统关系型数据库会基于Sql语句做查询,语法有统一标准;
而不同的非关系数据库查询语法差异极大,五花八门各种各样。
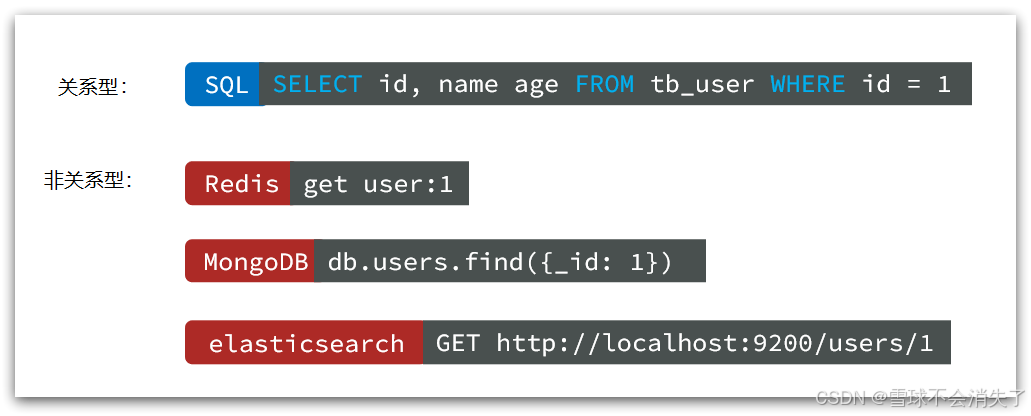
事务
传统关系型数据库能满足事务ACID的原则。
而非关系型数据库往往不支持事务,或者不能严格保证ACID的特性,只能实现基本的一致性。
总结:
除了上述四点以外,在存储方式、扩展性、查询性能上关系型与非关系型也都有着显著差异,总结如下:
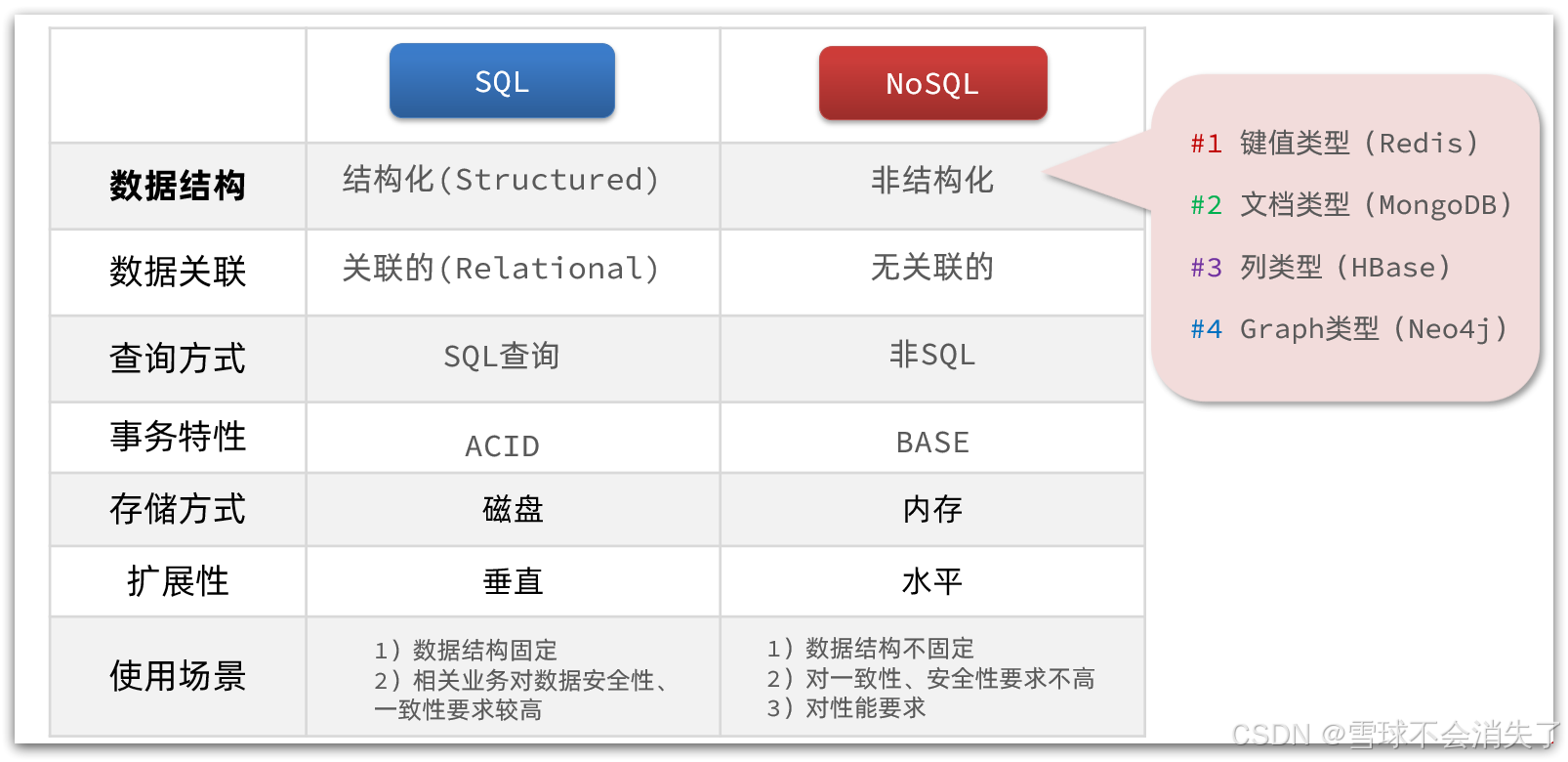
-
存储方式
-
关系型数据库基于磁盘进行存储,会有大量的磁盘IO,对性能有一定影响
-
非关系型数据库,他们的操作更多的是依赖于内存来操作,内存的读写速度会非常快,性能自然会好一些
-
-
扩展性
-
关系型数据库集群模式一般是主从,主从数据一致,起到数据备份的作用,称为垂直扩展。
-
非关系型数据库可以将数据拆分,存储在不同机器上,可以保存海量数据,解决内存大小有限的问题。称为水平扩展。
-
关系型数据库因为表之间存在关联关系,如果做水平扩展会给数据查询带来很多麻烦
-
关系型数据库(RDBMS):
-
Mysql
-
Oracle
-
DB2
-
SQLServer
非关系型数据库(NoSql):
-
Redis
-
Mongo db
-
MemCached
1.2 Redis下载与安装
1.2.1 Redis下载
Redis安装包分为windows版和Linux版:
-
Windows版下载地址:Releases · microsoftarchive/redis · GitHub
-
Linux版下载地址: Index of /releases/

1.2.2 Redis安装
1)在Windows中安装Redis
Redis的Windows版属于绿色软件,直接解压即可使用,解压后目录结构如下:
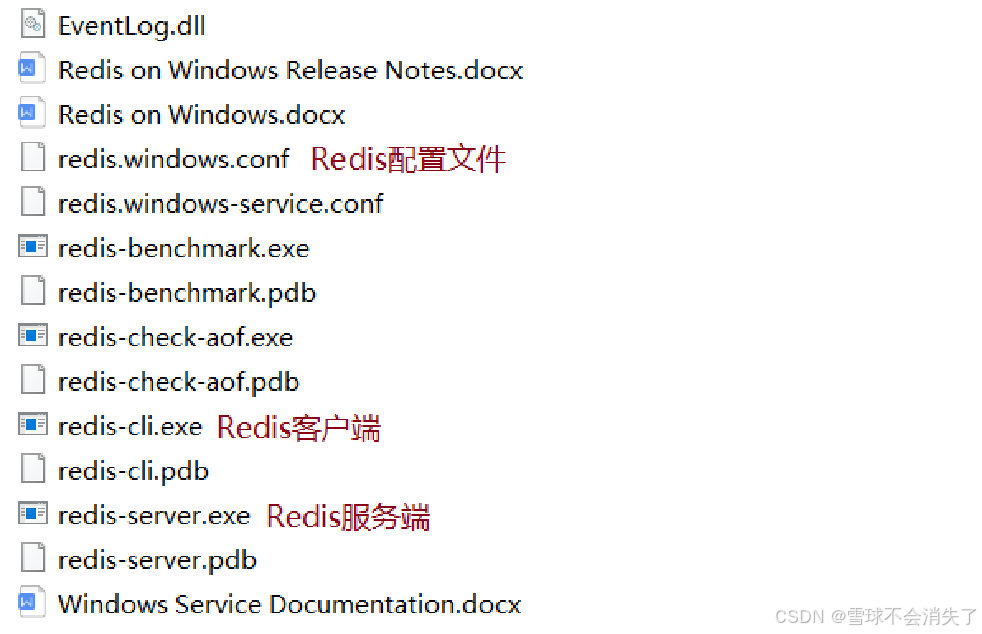
2)在Linux中安装Redis(简单了解)
在Linux系统安装Redis步骤:
-
将Redis安装包上传到Linux
-
解压安装包,命令:tar -zxvf redis-4.0.0.tar.gz -C /usr/local
-
安装Redis的依赖环境gcc,命令:yum install gcc-c++
-
进入/usr/local/redis-4.0.0,进行编译,命令:make
-
进入redis的src目录进行安装,命令:make install
安装后重点文件说明:
-
/usr/local/redis-4.0.0/src/redis-server:Redis服务启动脚本
-
/usr/local/redis-4.0.0/src/redis-cli:Redis客户端脚本
-
/usr/local/redis-4.0.0/redis.conf:Redis配置文件
1.3 Redis服务启动与停止
以window版Redis进行演示:
1.3.1 redis服务的启动命令
redis-server.exe redis.windows.conf
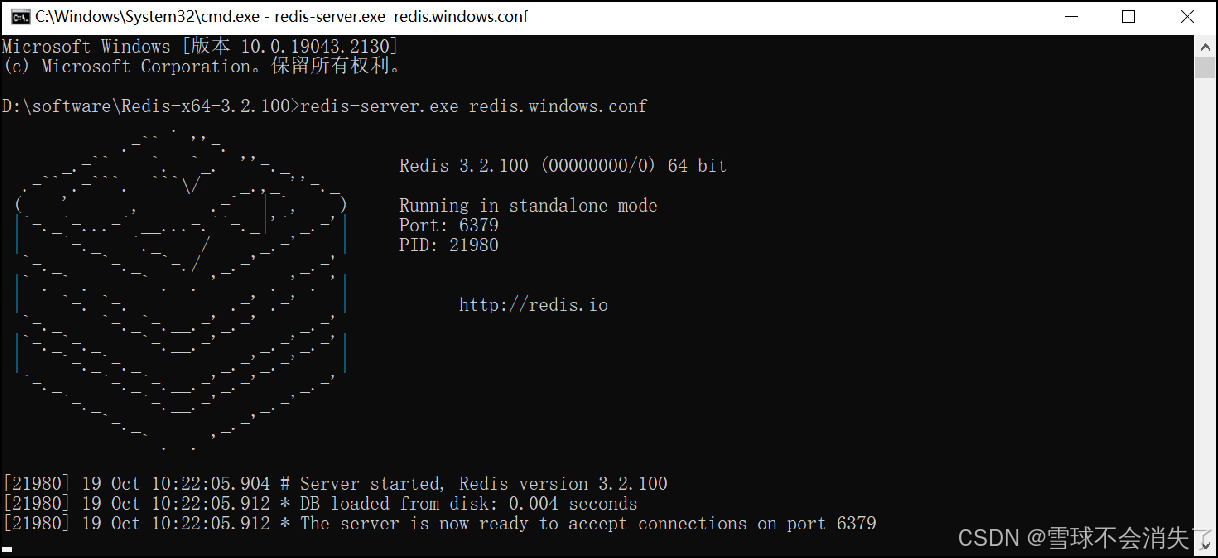
Redis服务的默认端口号为 6379 ,通过快捷键Ctrl + C 即可停止Redis服务
当Redis服务启动成功后,可通过客户端进行连接。
1.3.2 客户端连接redis服务的命令
redis-cli.exe

通过redis-cli.exe命令默认连接的是本地的redis服务,并且使用默认6379端口。也可以通过指定如下参数连接:
-
-h 要连接的redis节点的IP地址,默认是127.0.0.1
-
-p 指定要连接的redis节点的端口,默认是6379
-
-a 指定redis的访问密码
1.3.3 修改Redis配置文件
如何设置Redis服务的密码,需要修改redis.windows.conf(redis的配置文件)
#requirepass 123456
requirepass 123456 将前面的#去掉,表示去除注释注意:
-
修改密码后需要重启Redis服务才能生效
-
Redis配置文件中 # 表示注释
重启Redis后,再次连接Redis时,需加上密码,否则连接失败。
redis-cli.exe -h localhost -p 6379 -a 123456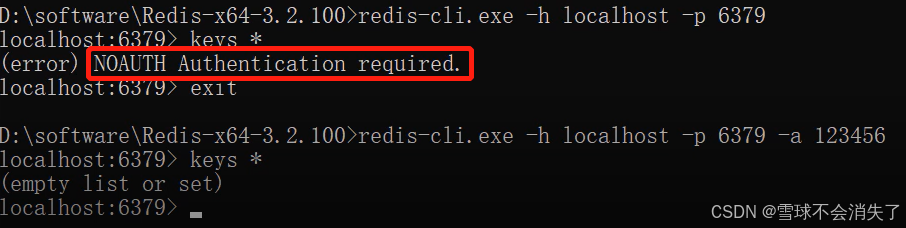
此时,-h 和 -p 参数可省略不写。
1.3.4 Redis客户端图形工具
默认提供的客户端连接工具界面不太友好,同时操作也较为麻烦,接下来,引入一个Redis客户端图形工具。
安装完毕后,直接双击启动
新建连接
连接成功
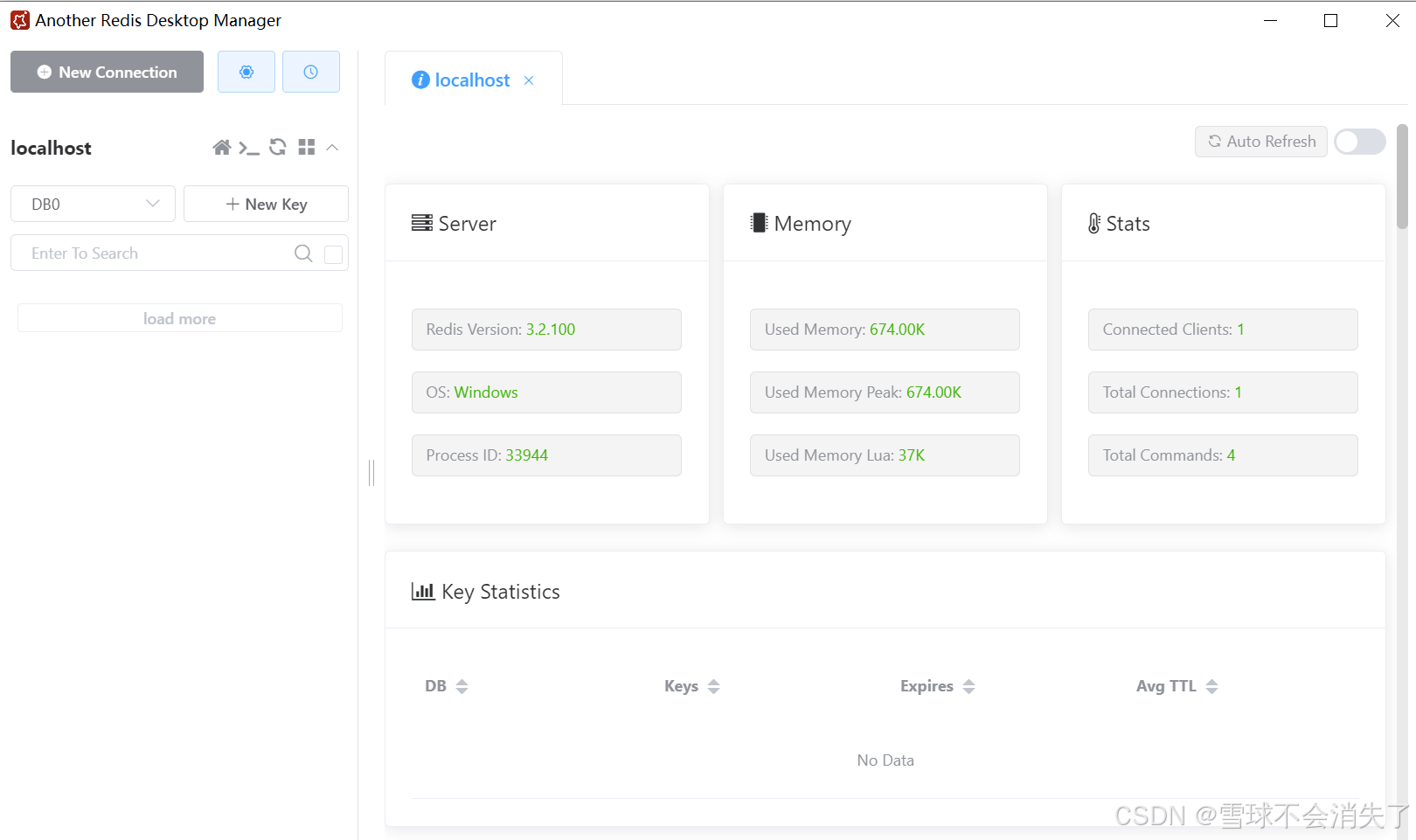
2. Redis中的数据类型
2.1 五种常用数据类型介绍
Redis中存储的都是key-value对结构的数据,其中:
key一般都是字符串类型。
而value的数据类型多种多样:
-
字符串 string
-
哈希 hash
-
列表 list
-
集合 set
-
有序集合 sorted set / zset
-
GEO
-
BitMap
-
HyperLog

2.2 各种数据类型特点
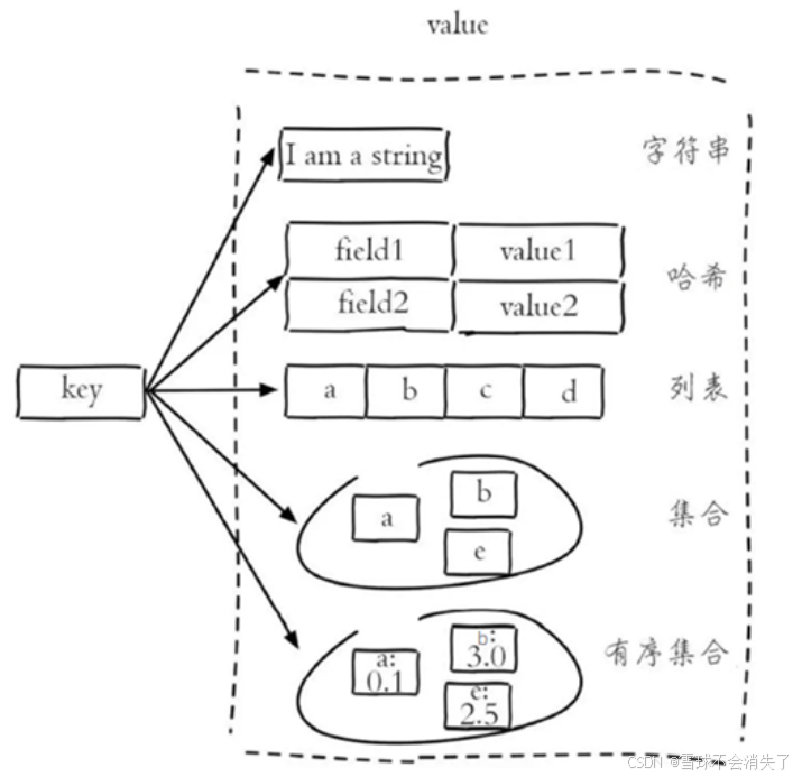
解释说明:
-
字符串(string):普通字符串,Redis中最简单的数据类型,根据字符串的格式不同又可以分为三类(不管是哪种格式,底层都是字节数组形式存储,只不过是编码方式不同。字符串类型的最大空间不能超过512m. ):
-
string:普通字符串
-
int:整数类型,可以做自增、自减操作
-
float:浮点类型,可以做自增、自减操作
-
-
哈希(hash):也叫散列,类似于Java中的HashMap结构
-
列表(list):按照插入顺序排序,可以有重复元素,类似于Java中的LinkedList,可以看做是一个双向链表结构。既可以支持正向检索和也可以支持反向检索,特征也与LinkedList类似
-
有序,和插入顺序有关
-
元素可以重复
-
插入和删除快
-
查询速度一般
-
常用来存储一个有序数据,例如:朋友圈点赞列表,评论列表等。
-
-
集合(set):无序(数据的存储顺序和插入顺序无关),且没有重复元素,类似于Java中的HashSet,查找快,支持交集.并集.差集等功能
-
有序集合(sorted set/zset):集合中每个元素关联一个分数(score),根据分数升序排序,没有重复元素
Redis中Key的设计结构
redis中key必须是唯一的,一般用id作为key,但还有一个问题,该如何区分不同类型的key呢?
例如,需要存储用户信息、商品信息到redis,有一个用户id是1,有一个商品id恰好也是1,此时如果使用id作为key,就会冲突,该怎么办?
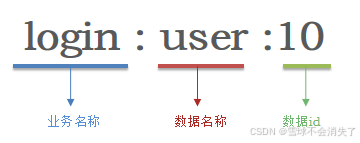
通过给key添加前缀来区分,不过这个前缀不是随便加的,有一定的规范:
Redis的key允许是多个单词形成的层级结构,多个单词之间用':'隔开,格式如下:

这个格式并非固定,也可以根据自己的需求来删除或添加词条:
- 项目名:业务名:数据名:数据id
- 业务名:数据名:数据id
例如项目名称叫 heima,有user和product两种不同类型的数据,可以这样定义key:
-
user相关的key:heima:user:1
-
product相关的key:heima:product:1
再例如我们的登录业务,保存用户信息,其key可以设计成如下格式:
如果Value是一个Java对象,例如一个User对象,则可以将对象序列化为JSON字符串后存储:
| KEY | VALUE |
|---|---|
| heima:user:1 | {"id":1, "name": "Jack", "age": 21} |
| heima:product:1 | {"id":1, "name": "小米11", "price": 4999} |
一旦我们向redis采用这样的方式存储,那么在可视化界面中,redis会以层级结构来进行存储,形成类似于这样的结构,更加方便Redis获取数据

这样设计的好处:
-
可读性强
-
避免key冲突
-
方便管理
当 key 对应的value是string类型时,string类型的底层编码包含int、embstr和raw三种。
- embstr在小于44字节时自动使用,采用连续内存空间,内存占用更小。
- 当字节数大于44字节时,会转为raw模式存储,在raw模式下,内存空间不是连续的,而是采用一个指针指向了另外一段内存空间,在这段空间里存储SDS内容,这样空间不连续,访问的时候性能也就会收到影响,还有可能产生内存碎片
-
如果全是数字的字符串,使用的编码是int(这种占用的内存很小)
-
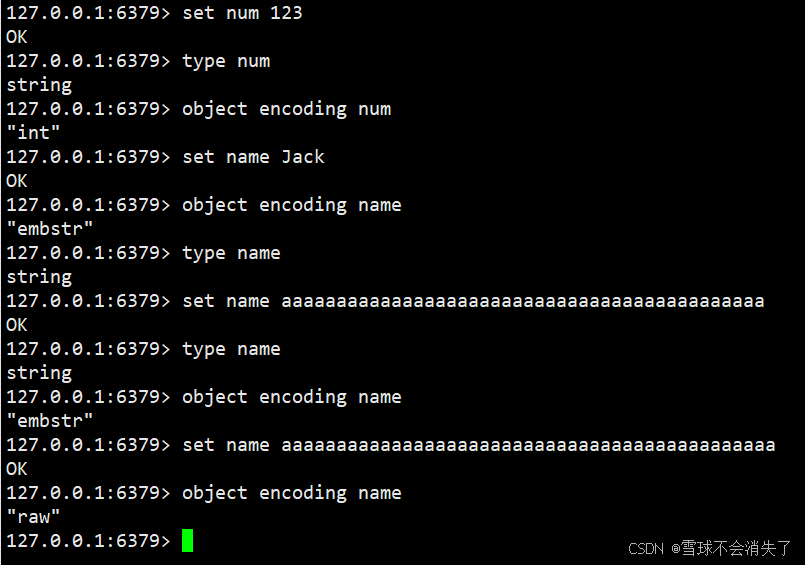
所以,尽量长度不超过44字节,不包含特殊字符
3. Redis的常用命令
3.1 操作字符串类型的命令
Redis 中操作字符串类型常用的命令:
-
SET key value 设置指定key的值为value
-
GET key 获取指定key对应的值
-
MSET:批量添加多个String类型的键值对
-
MGET:根据多个key获取多个String类型的value
-
INCR:让一个整型的key自增1
-
INCRBY:让一个整型的key自增并指定步长,例如:incrby num 2 让num值自增2
-
INCRBYFLOAT:让一个浮点类型的数字自增并指定步长
-
SETEX key seconds value 设置指定key的过期时间设为 seconds 秒,值为value
-
SETNX key value 当 key不存在时,设置 key 的值
SET 和GET: 如果key不存在则是新增,如果存在则是修改
更多命令可以参考Redis中文网:https://www.redis.net.cn
3.2 操作哈希的命令
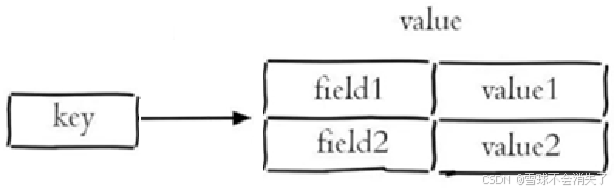
Redis hash 是一个string类型的 field 和 value 的映射表,hash特别适合用于存储对象,常用命令:
-
HSET key field value 设置哈希表key中,field字段的值为value
-
HGET key field 获取哈希表key中field字段对应的值
-
HMSET:批量添加多个hash类型key的field的值
-
HMGET:批量获取多个hash类型key的field的值
-
HGETALL:获取一个哈希类型的key中的所有的field和value
-
HDEL key field 删除哈希表key中 指定的字段
-
HKEYS key 获取哈希表key中 所有的field
-
HVALS key 获取哈希表key中 所有的值
-
HINCRBY:让一个hash类型key的字段值自增并指定步长
-
HSETNX:添加一个hash类型的key的field值,前提是这个field不存在,否则不执行
3.3 操作列表类型命令
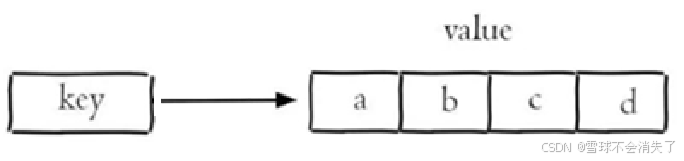
Redis中的列表类型是简单的字符串列表,按照插入顺序排序,常用命令:
-
LPUSH key value1 [value2] 向列表左侧依次插入一个或多个元素
-
LPOP key:移除并返回列表左侧的第一个元素,没有则返回nil
-
RPUSH key element ... :向列表右侧依次插入一个或多个元素
-
RPOP key 移除并获取列表key中的最后一个元素
-
LRANGE key start stop 获取列表key中指定下标内的元素
-
LLEN key 获取列表key的长度
-
BRPOP key1 [key2 ] timeout 移出并获取列表的最后一个元素, 如果列表没有元素会阻塞直到等待超时或发现可弹出元素为止
-
BLPOP和BRPOP:与LPOP和RPOP类似,只不过在没有元素时等待指定的时间,而不是直接返回nil

3.4 操作集合类型命令
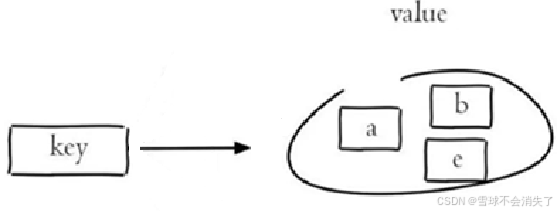
Redis set 是string类型元素的无序集合。集合中的元素是唯一的,常用命令:
-
SADD key member1 [member2] 向集合key添加一个或多个成员
-
SREM key member1 [member2] 移除集合中一个或多个成员
-
SMEMBERS key 返回集合key中的所有成员
-
SCARD key 获取集合key的成员数
-
SISMEMBER key member:判断一个元素是否存在于set中
-
SINTER key1 [key2] 返回给定所有集合的交集
-
SUNION key1 [key2] 返回所有给定集合的并集
-
SDIFF key1 key2 ... :求key1与key2的差集
3.5 操作有序集合的命令
Redis有序集合是string类型的元素集合,不允许有重复的成员,每个元素都会关联一个double类型的分数。常用命令:
常用命令:
-
ZADD key score1 member1 [score2 member2] 向有序集合key中添加一个或多个成员
-
ZREM key member [member ...] 移除有序集合中的一个或多个成员
-
ZSCORE key member : 获取sorted set中的指定元素的score值
-
ZRANK key member:获取sorted set 中的指定元素的排名,排名其实也就是下标,从0开始
-
ZCARD key:获取sorted set中的元素个数
-
ZCOUNT key min max:统计score值在给定范围内的所有元素的个数
-
ZINCRBY key increment member:给sorted set中指定的元素自增,步长为指定的increment值
-
ZRANGE key start stop [WITHSCORES] 返回有序集合key中指定下标区间内的成员,其中成员的位置按分数值递增(从小到大)来排序。
-
ZRANGEBYSCORE key min max:按照score排序后,获取指定score范围内的元素
-
ZINCRBY key increment member 对有序集合中指定成员的分数加上 increment增量
-
ZDIFF.ZINTER.ZUNION:求差集.交集.并集
注意:所有的排名score默认都是升序排序的,如果要降序则在命令的Z后面添加REV即可,例如:
-
升序获取sorted set 中的指定元素的排名:ZRANK key member
-
降序获取sorted set 中的指定元素的排名:ZREVRANK key memeber
-
-
3.6 通用命令
Redis的通用命令是不分数据类型的,都可以使用的命令:
-
KEYS pattern:查找所有符合指定模式( pattern)的 key
-
EXISTS key:判断指定 key 是否存在
-
TYPE key 返回 key 所储存的值的类型
-
DEL key:在 key 存在时,删除一个指定的key
-
EXPIRE key time:给一个key设置有效期,有效期到时,该key会被自动删除
-
TTL key:查看一个KEY的剩余有效期
在生产环境下,不推荐使用keys 命令,因为这个命令在key过多的情况下,效率不高
127.0.0.1:6379> keys *
1) "name"
2) "age"
127.0.0.1:6379>
# 查询以a开头的key
127.0.0.1:6379> keys a*
1) "age"
127.0.0.1:6379>127.0.0.1:6379> exists age
(integer) 1
127.0.0.1:6379> exists name
(integer) 0127.0.0.1:6379> del name #删除单个
(integer) 1 #成功删除1个
127.0.0.1:6379> del k1 k2 k3 k4
(integer) 3 #此处返回的是成功删除的key的数量,由于redis中只有k1,k2,k3 所以只成功删除3个,最终返回
127.0.0.1:6379>127.0.0.1:6379> expire age 10
(integer) 1
127.0.0.1:6379> ttl age
(integer) 8
127.0.0.1:6379> ttl age
(integer) 6
127.0.0.1:6379> ttl age
(integer) -2
127.0.0.1:6379> ttl age
(integer) -2 #当这个key过期了,那么此时查询出来就是-2
127.0.0.1:6379> keys *
(empty list or set)
127.0.0.1:6379> set age 10 #如果没有设置过期时间
OK
127.0.0.1:6379> ttl age
(integer) -1 # ttl的返回值就是-14.在Java中操作Redis
在Redis官网中提供了各种语言的客户端,地址:https://redis.io/docs/clients/

其中Java客户端也包含很多:
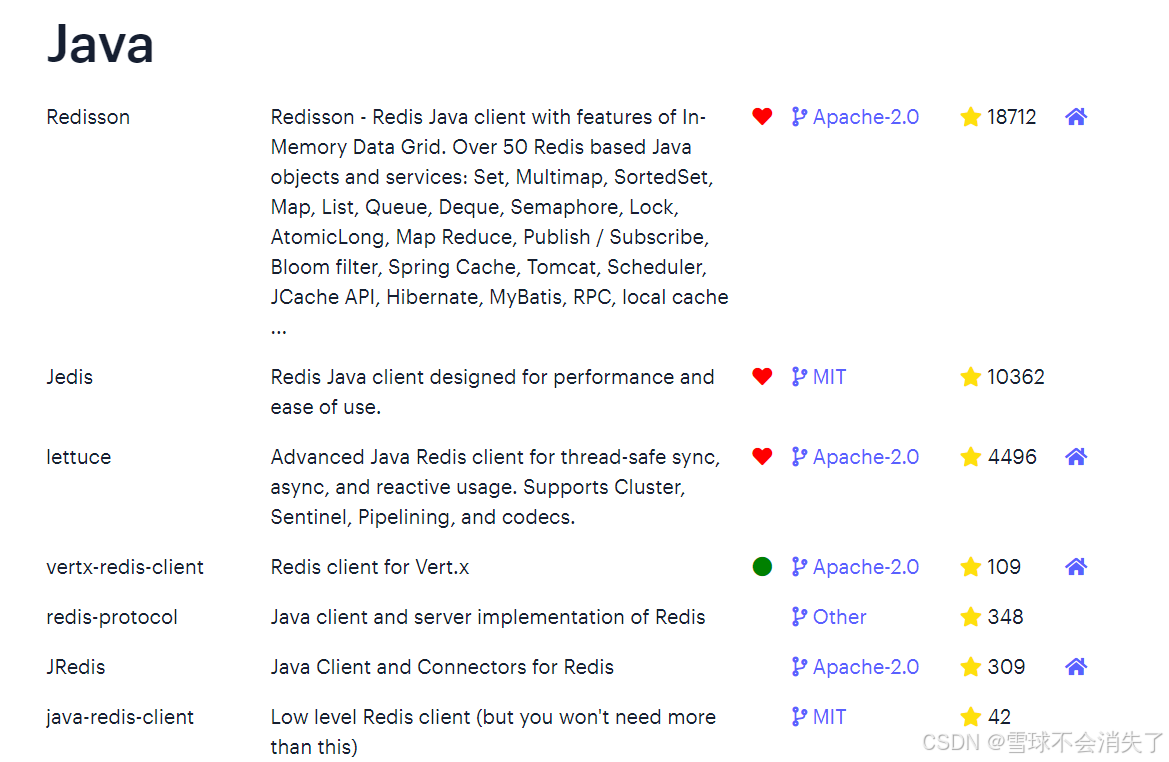
标记为❤的就是推荐使用的java客户端
4.1 Redis的Java客户端
Redis的Java客户端就是用java代码来操作redis依赖,就如同我们使用JDBC操作MySQL数据库一样。
Redis 的 Java 客户端很多,常用的几种:
-
Jedis和Lettuce:这两个主要是提供了Redis命令对应的API,方便我们操作Redis。
-
Jedis的java客户端以redis的命令作为方法名称,学习成本低,但是Jedis实例是线程不安全的,在多线程环境下需要为每一个线程创建独立的Jedis连接,所以多线程环境下必须基于连接池来使用
-
Lettuce是基于Netty实现的,支持同步,异步和响应式编程方式,并且是线程安全的,支持redis的哨兵模式、集群模式和管道模式,在Spring官方默认使用的是这个客户端
-
-
Spring Data Redis:Spring的一部分,在SpringBoot项目中还提供了对应的Starter,即 spring-boot-starter-data-redis,SpringDataRedis对Jedis和Lettuce两种客户端做了抽象和封装,因此我们后期会直接以SpringDataRedis来学习
-
Redisson:是一个基于Redis实现的分布式、可伸缩的java数据结构的集合,包含了如Map、Queue、Lock、Semaphore、AtomicLong等强大的功能,而且支持跨进程的同步机制:Lock.Semaphore等待,比较适合用来实现特殊的功能需求。
4.1.1Jedis快速入门
1)引入jedis的客户端依赖:
<!--jedis-->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.7.0</version>
</dependency>
<!--单元测试-->
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter</artifactId>
<version>5.7.0</version>
<scope>test</scope>
</dependency>2)建立连接,并操作redis
package com.heima;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.boot.autoconfigure.data.redis.RedisProperties;
import redis.clients.jedis.Jedis;
import java.util.Map;
public class JedisTest {
private Jedis jedis;
//@BeforeEach注解:在每个 @Test 测试方法执行之前自动调用被标注的方法
@BeforeEach
void setUp() {
// 1.创建Jedis对象,并指定id和端口,建立和redis的连接
jedis = new Jedis("你的ip", 6379);
// 2.连接reids的密码
jedis.auth("200203");
// 3.选择库,如果不选择,默认使用0号库
jedis.select(0);
}
@Test
void testString() {
// 存入数据
String result = jedis.set("name", "虎哥");
System.out.println("result = " + result);
// 获取数据
String name = jedis.get("name");
System.out.println("name = " + name);
}
@Test
void testHash() {
// 插入hash数据
jedis.hset("user:1", "name", "Jack");
jedis.hset("user:1", "age", "21");
// 获取
Map<String, String> map = jedis.hgetAll("user:1");
System.out.println(map);
}
//@AfterEach注解:在每个 @Test 测试方法执行之后自动调用被标注的方法
@AfterEach
void tearDown() {
if (jedis != null) {
jedis.close();
}
}
}4.1.2 Jedis连接池
Jedis本身是线程不安全的,在多线程环境下使用会出现线程安全问题,并且频繁的创建和销毁连接会有性能损耗,因此我们推荐大家使用Jedis连接池代替Jedis的直连方式
①编写Jedis连接池工具类:
package com.heima.jedis;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
public class JedisConnectionFacotry {
private static final JedisPool jedisPool; //官方提供的Jedis连接池对象
static {
//配置Jedis连接池的参数
JedisPoolConfig poolConfig = new JedisPoolConfig();
poolConfig.setMaxTotal(8); //连接池中的允许创建的最大连接数
poolConfig.setMaxIdle(8); //连接池中最大的空闲连接数
poolConfig.setMinIdle(0); //连接池中最小的空闲连接数
poolConfig.setMaxWaitMillis(2000); //当连接池中没有空闲连接可用时,最长等待多长时间来获取一个连接,ms
//创建连接池对象,第四个参数代表客户端尝试连接到 Redis 服务器的最大等待时间
jedisPool = new JedisPool(poolConfig,
"你的ip",6379,5000,"200203");
}
//从连接池中获取Jedis连接对象,每次调用这个方法的时候都从连接池中获取,用完后归还到连接池中
public static Jedis getJedis(){
return jedisPool.getResource();
}
}代码说明:
-
1) JedisConnectionFacotry:工厂设计模式是实际开发中非常常用的一种设计模式,我们可以使用工厂,去降低代的耦合,比如Spring中的Bean的创建,就用到了工厂设计模式
-
2)静态代码块:随着类的加载而加载,确保只能执行一次,我们在加载当前工厂类的时候,就可以执行static的操作完成对 连接池的初始化
-
3)最后提供返回连接池中连接的方法.
②操作redis:
package com.heima;
import com.heima.jedis.JedisConnectionFacotry;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.boot.autoconfigure.data.redis.RedisProperties;
import redis.clients.jedis.Jedis;
import java.util.Map;
public class JedisTest {
private Jedis jedis;
//@BeforeEach注解:在每个 @Test 测试方法执行之前自动调用被标注的方法
@BeforeEach
void setUp() {
// 1.从连接池中获取Jedis对象,建立和redis的连接
jedis = JedisConnectionFacotry.getJedis();
// 2.选择库,如果不选择,默认使用0号库
jedis.select(0);
}
@Test
void testString() {
// 存入数据
String result = jedis.set("name", "虎哥");
System.out.println("result = " + result);
// 获取数据
String name = jedis.get("name");
System.out.println("name = " + name);
}
@Test
void testHash() {
// 插入hash数据
jedis.hset("user:1", "name", "Jack");
jedis.hset("user:1", "age", "21");
// 获取
Map<String, String> map = jedis.hgetAll("user:1");
System.out.println(map);
}
//@AfterEach注解:在每个 @Test 测试方法执行之后自动调用被标注的方法
@AfterEach
void tearDown() {
if (jedis != null) {
//当我们使用了连接池后,关闭连接时其实并不是关闭连接,而是将Jedis连接还回到连接池中
jedis.close();
}
}
}
4.1.3 Spring Data Redis
4.1.3.1 介绍
Spring Data Redis 是 Spring 的一部分,提供了在 Spring 应用中通过简单的配置就可以访问 Redis 服务,对 Redis 底层开发包进行了高度封装。在 Spring 项目中,可以使用Spring Data Redis来简化 Redis 操作。
SpringData是Spring中数据操作的模块,包含对各种数据库的集成,其中对Redis的集成模块就叫做SpringDataRedis,官网地址:https://spring.io/projects/spring-data-redis
-
提供了对不同Redis客户端的整合(Lettuce和Jedis)
-
提供了RedisTemplate统一API来操作Redis
-
支持Redis的发布订阅模型
-
支持Redis哨兵和Redis集群
-
支持基于Lettuce的响应式编程
-
支持基于JDK、JSON、字符串、Spring对象数据的序列化及反序列化,redis底层都是以字节数组的形式存储的,只不过是编码方式不同
-
支持序列化将各种数据变成字节或字符串,然后往redis中写
-
支持反序列化将读到的字节变成Java中的对象或字符串
-
-
支持基于Redis的JDKCollection实现
Spring Boot提供了对应的Starter,maven坐标:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>Spring Data Redis中有一个高度封装的类:RedisTemplate类,其中封装了各种对Redis的操作,并且将操作不同数据类型的API都封装到了不同的类型中:
-
ValueOperations:操作string类型数据的接口
-
SetOperations:操作set类型数据的接口
-
ZSetOperations:操作zset类型数据的接口
-
HashOperations:操作hash类型数据的接口
-
ListOperations:操作list类型数据的接口
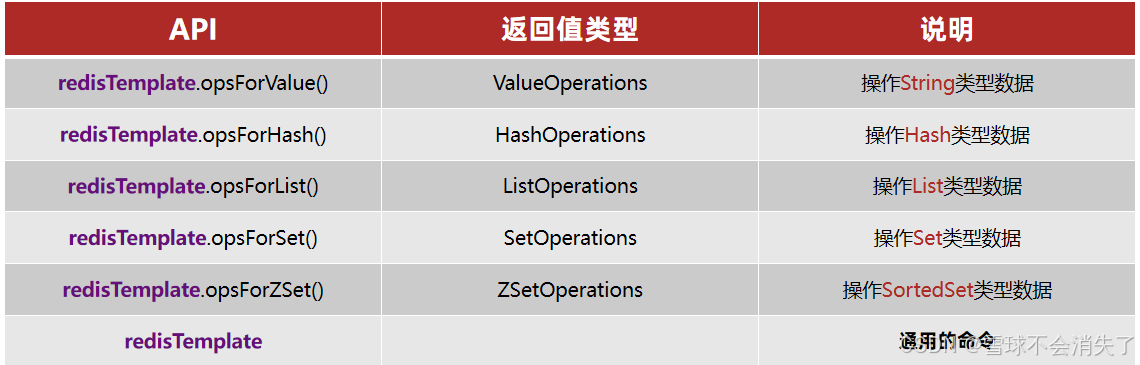
使用步骤:①先创建RedisTemplate类的对象②通过它调用opsForxxx()方法,获取到操作各种数据类型的对象③使用operations对象操作Redis
4.1.3.2 快速入门
1). 导入Spring Data Redis的maven坐标
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.5.7</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.heima</groupId>
<artifactId>redis-demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>redis-demo</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<!--spring-data-redis的起步依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!--common-pool:不管是Jedis还是Lucttures底层都会基于这个依赖来实现连接池-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
<!--Jackson依赖-->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>2). 配置Redis连接信息
在application-dev.yml中添加
spring:
redis:
host: 你的ip地址
port: 6379
password: 200203
lettuce: # redis连接池的配置,可以配置使用lettuce还是jedis实现,如果要使用jedis的实现还需要引入jedis依赖
pool: # 因为Spring默认使用lettuce实现,所以不需要单独引入lettuce依赖
max-active: 8 #最大连接
max-idle: 8 #最大空闲连接
min-idle: 0 #最小空闲连接
max-wait: 100ms #连接等待时间操作redis:
package com.heima;
import com.heima.redis.pojo.User;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;
@SpringBootTest
class RedisDemoApplicationTests {
//注入RedisTemplate对象
@Autowired
private RedisTemplate redisTemplate;
@Test
void testString() {
// 写入一条String数据
redisTemplate.opsForValue().set("name", "虎哥");
// 获取string数据
Object name = redisTemplate.opsForValue().get("name");
System.out.println("name = " + name);
}
@Test
void testSaveUser() {
// 写入数据
redisTemplate.opsForValue().set("user:100", new User("虎哥", 21));
// 获取数据
User o = (User) redisTemplate.opsForValue().get("user:100");
System.out.println("o = " + o);
}
}
4.1.3.3 .SpringDataRedis的序列化方式
执行6.1.3的测试代码可以发现
RedisTemplate可以接收任意类型(Object)的数据作为值写入到Redis中,只不过在写入redis前会把其序列化为redis可以处理的字节,而SpringDataRedis默认采用的是JDK序列化方式,而JDK序列化方式序列化数据后得到的结果是这样的:
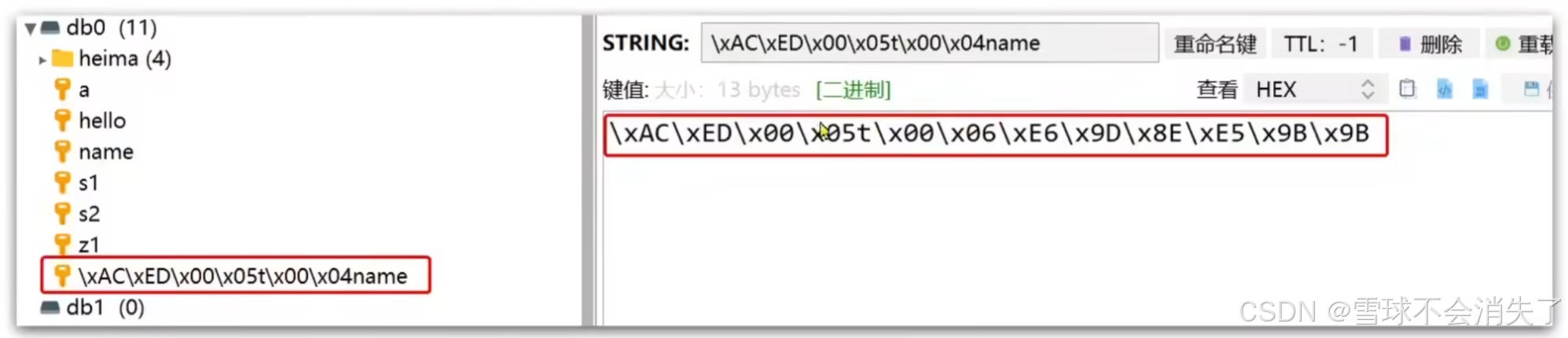
JDK序列化方式的缺点:
-
可读性差
-
内存占用较大
所以我们需要修改设置一下RedisTemplate的序列化方式,代码如下:
package com.heima.redis.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.RedisSerializer;
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory connectionFactory){
// 创建RedisTemplate对象
RedisTemplate<String, Object> template = new RedisTemplate<>();
// 设置连接工厂
template.setConnectionFactory(connectionFactory);
// 创建JSON序列化工具
GenericJackson2JsonRedisSerializer jsonRedisSerializer = new GenericJackson2JsonRedisSerializer();
// 设置Key的序列化器为字符串序列化方式
template.setKeySerializer(RedisSerializer.string());
template.setHashKeySerializer(RedisSerializer.string());
// 设置Value的序列化器为JSON序列化方式
template.setValueSerializer(jsonRedisSerializer);
template.setHashValueSerializer(jsonRedisSerializer);
// 返回
return template;
}
}再次执行执行6.1.3的测试代码可以发现,采用了JSON序列化来代替默认的JDK序列化方式。最终结果如图:
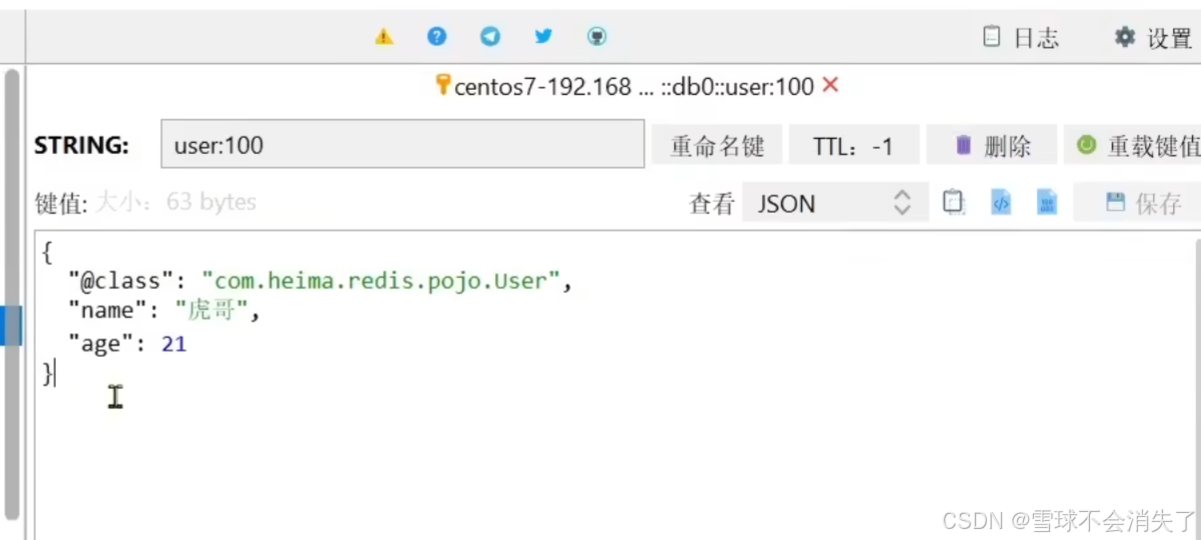
整体可读性有了很大提升
-
存的时候能将Java对象自动序列化为JSON字符串
-
查询时能自动把JSON反序列化为Java对象。不过,其中记录了序列化时对应的class名称,目的是为了查询时实现自动反序列化。这会带来额外的内存开销。
4.1.3.4 StringRedisTemplate
尽管JSON序列化方式可以满足我们的需求,但依然存在一些问题,如图:
-
JSON序列化器为了在反序列化时知道对象的类型,会将类的class类型写入json结果中,存入Redis,会带来额外的内存开销。
-
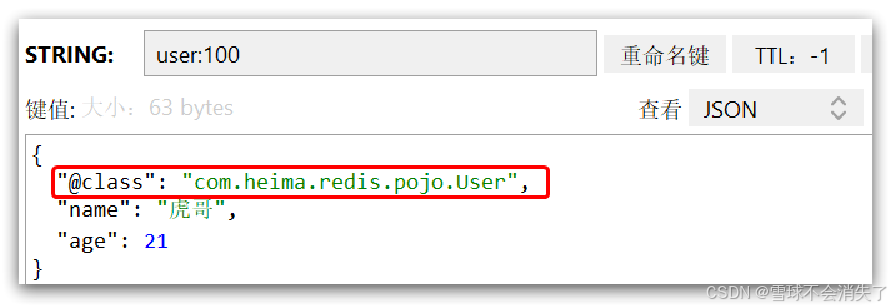
所以,为了节省内存空间,我们并不会使用JSON序列化器来处理value,而是统一使用String序列化器,要求只能存储String类型的key和value,当需要存储java对象时,自己手动完成对象的序列化和反序列化.
因为这种用法比较普遍,所以SpringDataRedis提供了RedisTemplate的子类:StringRedisTemplate,其key和value的序列化方式默认都是使用String序列化方式。
省去了我们自定义RedisTemplate的序列化方式的步骤,而是直接使用:
package com.heima;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.heima.redis.pojo.User;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.StringRedisTemplate;
@SpringBootTest
class RedisStringTests {
@Autowired
private StringRedisTemplate stringRedisTemplate;
private static final ObjectMapper mapper = new ObjectMapper();
@Test
void testString() {
// 写入一条String数据
stringRedisTemplate.opsForValue().set("name", "虎哥");
// 获取string数据
Object name = stringRedisTemplate.opsForValue().get("name");
System.out.println("name = " + name);
}
@Test
void testSaveUser() throws JsonProcessingException {
User user = new User("虎哥", 21);
//手动将java对象序列化为json字符串
String json = mapper.writeValueAsString(user);
// 写入数据
stringRedisTemplate.opsForValue().set("user:100", json);
// 获取数据
String jsonUser = stringRedisTemplate.opsForValue().get("user:100");
//手动将json字符串反序列化为java对象
User user1 = mapper.readValue(jsonUser, User.class);
System.out.println("user1 = " + user1);
}
}此时再来看一看存储的数据,就会发现那个class数据已经不在了,节约了我们的空间~
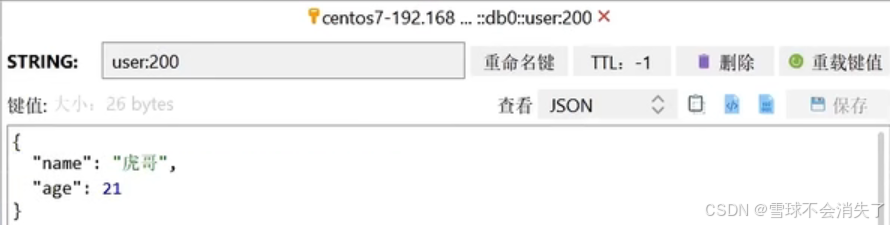
获取操作其他数据类型对象的演示
在test下新建测试类
package com.sky.test;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.*;
@SpringBootTest
public class SpringDataRedisTest {
@Autowired
private RedisTemplate redisTemplate;
@Test
public void testRedisTemplate(){
System.out.println(redisTemplate);
//获取操作string数据类型的对象
ValueOperations valueOperations = redisTemplate.opsForValue();
//操作hash数据类型的对象
HashOperations hashOperations = redisTemplate.opsForHash();
//操作list数据类型的对象
ListOperations listOperations = redisTemplate.opsForList();
//set类型数据操作对象
SetOperations setOperations = redisTemplate.opsForSet();
//zset类型数据操作对象
ZSetOperations zSetOperations = redisTemplate.opsForZSet();
}
}测试:
说明RedisTemplate对象注入成功,并且通过该RedisTemplate对象获取操作5种数据类型相关对象。
上述环境搭建完毕后,接下来,我们就来具体对常见5种数据类型进行操作。
操作常见类型数据演示
1). 操作字符串类型数据
/**
* 操作字符串类型的数据
*/
@Test
public void testString(){
// set get setex setnx
redisTemplate.opsForValue().set("name","小明");
String city = (String) redisTemplate.opsForValue().get("name");
System.out.println(city);
redisTemplate.opsForValue().set("code","1234",3, TimeUnit.MINUTES);
redisTemplate.opsForValue().setIfAbsent("lock","1");
redisTemplate.opsForValue().setIfAbsent("lock","2");
}2). 操作哈希类型数据
/**
* 操作哈希类型的数据
*/
@Test
public void testHash(){
//hset hget hdel hkeys hvals
HashOperations hashOperations = redisTemplate.opsForHash();
hashOperations.put("100","name","tom");
hashOperations.put("100","age","20");
String name = (String) hashOperations.get("100", "name");
System.out.println(name);
Set keys = hashOperations.keys("100");
System.out.println(keys);
List values = hashOperations.values("100");
System.out.println(values);
hashOperations.delete("100","age");
}3). 操作列表类型数据
/**
* 操作列表类型的数据
*/
@Test
public void testList(){
//lpush lrange rpop llen
ListOperations listOperations = redisTemplate.opsForList();
listOperations.leftPushAll("mylist","a","b","c");
listOperations.leftPush("mylist","d");
List mylist = listOperations.range("mylist", 0, -1);
System.out.println(mylist);
listOperations.rightPop("mylist");
Long size = listOperations.size("mylist");
System.out.println(size);
}4). 操作集合类型数据
/**
* 操作集合类型的数据
*/
@Test
public void testSet(){
//sadd smembers scard sinter sunion srem
SetOperations setOperations = redisTemplate.opsForSet();
setOperations.add("set1","a","b","c","d");
setOperations.add("set2","a","b","x","y");
Set members = setOperations.members("set1");
System.out.println(members);
Long size = setOperations.size("set1");
System.out.println(size);
Set intersect = setOperations.intersect("set1", "set2");
System.out.println(intersect);
Set union = setOperations.union("set1", "set2");
System.out.println(union);
setOperations.remove("set1","a","b");
}5). 操作有序集合类型数据
/**
* 操作有序集合类型的数据
*/
@Test
public void testZset(){
//zadd zrange zincrby zrem
ZSetOperations zSetOperations = redisTemplate.opsForZSet();
zSetOperations.add("zset1","a",10);
zSetOperations.add("zset1","b",12);
zSetOperations.add("zset1","c",9);
Set zset1 = zSetOperations.range("zset1", 0, -1);
System.out.println(zset1);
zSetOperations.incrementScore("zset1","c",10);
zSetOperations.remove("zset1","a","b");
}6). 通用命令操作
/**
* 通用命令操作
*/
@Test
public void testCommon(){
//keys exists type del
Set keys = redisTemplate.keys("*");
System.out.println(keys);
Boolean name = redisTemplate.hasKey("name");
Boolean set1 = redisTemplate.hasKey("set1");
for (Object key : keys) {
DataType type = redisTemplate.type(key);
System.out.println(type.name());
}
redisTemplate.delete("mylist");
}
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)