Redis的原理与使用
一、Redis 核心原理
1.1 什么是 Redis
Redis(Remote Dictionary Server)是一个开源的内存数据结构存储系统,它可以用作:
- 数据库(Database)
- 缓存(Cache)
- 消息队列(Message Broker)
1.2 核心架构设计
┌─────────────────────────────────────────┐
│ Redis Server │
├─────────────────────────────────────────┤
│ 网络层 → 命令解析 → 命令执行 → 返回结果 │
├─────────────────────────────────────────┤
│ 数据存储层: │
│ • 内存存储(主存储) │
│ • 持久化(RDB/AOF) │
├─────────────────────────────────────────┤
│ 数据结构层: │
│ String / Hash / List / Set / ZSet │
│ Bitmap / HyperLogLog / Geo / Stream │
└─────────────────────────────────────────┘1.3 单线程模型(核心特性)
Redis 使用单线程事件循环处理所有命令,但这并不意味着它慢:
|
特性 |
说明 |
|
单线程优势 |
无锁竞争、无上下文切换、原子性操作 |
|
IO多路复用 |
基于 epoll/kqueue/select 处理并发连接 |
|
性能瓶颈 |
内存带宽和网络延迟,而非 CPU |
💡 为什么快? 所有操作都在内存中完成,单线程避免了锁开销,配合高效的 C 语言实现。
1.4 持久化机制
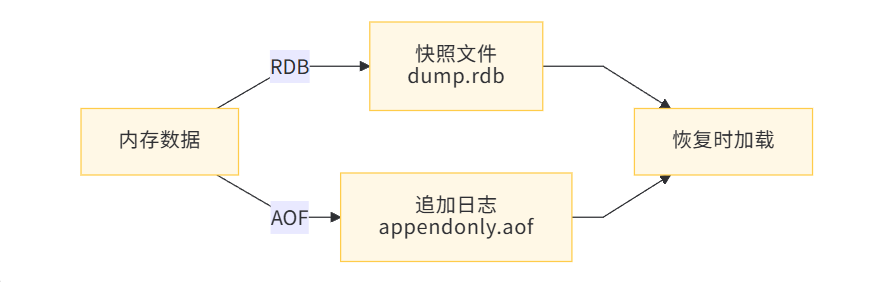
|
方式 |
原理 |
优点 |
缺点 |
适用场景 |
|
RDB |
定时快照 |
文件紧凑、恢复快 |
可能丢数据 |
备份、灾难恢复 |
|
AOF |
记录写命令 |
数据安全、可读 |
文件大、恢复慢 |
数据可靠性要求高 |
|
混合 |
RDB+AOF |
兼顾两者 |
配置复杂 |
生产环境推荐 |
二、数据类型详解
2.1 基础类型速查表
|
类型 |
存储结构 |
适用场景 |
时间复杂度 |
|
String |
字符串/整数/浮点 |
缓存、计数器、Session |
O(1) |
|
Hash |
键值对集合 |
对象存储、用户信息 |
O(1) |
|
List |
双向链表 |
消息队列、时间线 |
O(1)头尾/O(n)中间 |
|
Set |
无序唯一集合 |
标签、共同好友、去重 |
O(1) |
|
ZSet |
有序集合(Skip List) |
排行榜、延迟队列 |
O(log N) |
2.2 String(字符串)
最基础类型,最大 512MB:
# 基础操作
SET user:1001 "Alice" # 设置键值
GET user:1001 # 获取值
SET counter 100 # 设置计数器
INCR counter # 原子+1(101)
INCRBY counter 10 # 原子+10(111)
DECR counter # 原子-1
# 批量操作(减少网络往返)
MSET user:1001 "Alice" user:1002 "Bob"
MGET user:1001 user:1002
# 设置过期(NX=不存在才设置,XX=存在才设置)
SET temp_key "value" EX 60 NX # 60秒后过期,仅当不存在实战场景:
# 1. 分布式锁(简单版)
SET lock:order:123 "owner_id" EX 30 NX
# 2. 限流计数(每分钟最多100次)
INCR rate_limit:user:1001
EXPIRE rate_limit:user:1001 60
# 3. 存储对象(JSON序列化)
SET user:profile:1001 '{"name":"Alice","age":25}'2.3 Hash(哈希)
存储对象的最佳选择,比 String 更省内存:
# 用户对象存储
HSET user:1001 name "Alice" age 25 city "Beijing"
HGET user:1001 name # 获取单个字段
HGETALL user:1001 # 获取所有字段
HMGET user:1001 name age # 获取多个字段
# 原子操作
HINCRBY user:1001 age 1 # 年龄+1
HDEL user:1001 city # 删除字段
HLEN user:1001 # 字段数量
HKEYS user:1001 # 所有字段名
HVALS user:1001 # 所有字段值String vs Hash 存储对比:
|
方式 |
存储结构 |
内存占用 |
灵活性 |
|
|
一个 String |
高(JSON冗余) |
低(需全量更新) |
|
|
一个 Hash |
低(ziplist优化) |
高(单字段更新) |
2.4 List(列表)
双向链表,支持两端操作:
# 队列操作(FIFO)
LPUSH queue:tasks "task1" # 左侧插入
RPUSH queue:tasks "task2" # 右侧插入
RPOP queue:tasks # 右侧弹出(消费)
BLPOP queue:tasks 30 # 阻塞弹出(30秒超时)
# 栈操作(LIFO)
LPUSH stack:ops "op1"
LPOP stack:ops
# 范围查询(适合时间线)
LRANGE timeline:user:1001 0 9 # 获取前10条
LTRIM timeline:user:1001 0 99 # 只保留100条经典应用:消息队列
# 生产者
LPUSH mq:orders '{"order_id":"123","amount":100}'
# 消费者(阻塞式,优雅处理空队列)
BRPOP mq:orders 0 # 0表示永久阻塞2.5 Set(集合)
无序唯一集合,支持集合运算:
# 基础操作
SADD tags:article:1001 "redis" "database" "cache"
SMEMBERS tags:article:1001 # 获取所有成员
SISMEMBER tags:article:1001 "redis" # 判断是否包含
SREM tags:article:1001 "cache" # 移除成员
SCARD tags:article:1001 # 成员数量
# 集合运算(社交场景)
SADD followers:user:1001 2001 2002 2003
SADD followers:user:1002 2001 2002 2004
SINTER followers:user:1001 followers:user:1002 # 交集:共同关注
SUNION followers:user:1001 followers:user:1002 # 并集:所有关注
SDIFF followers:user:1001 followers:user:1002 # 差集:1001独有的实战:抽奖系统
# 初始化奖池
SADD lottery:pool:user:1001 "prize1" "prize2" "prize3" "prize4"
# 随机抽取3个不重复奖品(不删除)
SRANDMEMBER lottery:pool:user:1001 3
# 随机抽取并移除(确保不重复中奖)
SPOP lottery:pool:user:1001 12.6 ZSet(有序集合)
Skip List + Hash Table 实现,支持按分数排序:
# 排行榜
ZADD leaderboard:game1 1000 "player:A" 950 "player:B" 1200 "player:C"
ZREVRANGE leaderboard:game1 0 2 WITHSCORES # 前三名(降序)
ZRANGE leaderboard:game1 0 2 WITHSCORES # 后三名(升序)
# 范围查询
ZRANGEBYSCORE leaderboard:game1 1000 2000 # 分数在1000-2000之间
ZREMRANGEBYRANK leaderboard:game1 0 0 # 删除第一名
ZREMRANGEBYSCORE leaderboard:game1 0 500 # 删除500分以下的
# 排名相关
ZRANK leaderboard:game1 "player:A" # 获取排名(升序,从0开始)
ZREVRANK leaderboard:game1 "player:A" # 获取排名(降序)
ZSCORE leaderboard:game1 "player:A" # 获取分数
ZINCRBY leaderboard:game1 50 "player:A" # 增加分数实战:延迟队列
# 任务执行时间作为score(时间戳)
ZADD delay_queue 1672531200 "task:send_email:123"
ZADD delay_queue 1672534800 "task:push_notify:456"
# 轮询待执行任务(当前时间戳)
ZRANGEBYSCORE delay_queue 0 1672533000 LIMIT 0 1
# 执行后删除
ZREM delay_queue "task:send_email:123"2.7 高级类型
|
类型 |
用途 |
关键命令 |
|
Bitmap |
位图统计(签到、在线状态) |
|
|
HyperLogLog |
基数统计(UV计算) |
|
|
Geo |
地理位置(附近的人) |
|
|
Stream |
日志型消息队列 |
|
三、性能优化与最佳实践
3.1 性能指标
Redis 基准测试(redis-benchmark):
• 单机 QPS:100,000+(简单命令)
• 延迟:亚毫秒级(P99 < 1ms)
• 内存操作:100万键值对 ≈ 100MB3.2 关键优化策略
1. 避免 Big Key
# 检测 Big Key
redis-cli --bigkeys
redis-cli --mem-keys "user:*"
# 优化方案:
# String > 10KB → 拆分为 Hash 或分片
# Hash/Set/ZSet > 5000 成员 → 拆分为多个 Key
# List > 10000 元素 → 分片或使用 Stream2. 批量操作与 Pipeline
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>5.1.0</version>
</dependency>import redis.clients.jedis.Jedis;
import redis.clients.jedis.Pipeline;
import redis.clients.jedis.JedisPool;
public class RedisBatchExample {
// 错误:N次网络往返
public void wrongWay(Jedis jedis, String value) {
for (int i = 0; i < 1000; i++) {
jedis.set("key:" + i, value); // 每次循环都发起一次网络请求
}
}
// 正确:Pipeline 合并请求(1次往返)
public void correctPipeline(Jedis jedis, String value) {
Pipeline pipe = jedis.pipelined();
for (int i = 0; i < 1000; i++) {
pipe.set("key:" + i, value); // 命令先缓冲在本地
}
pipe.sync(); // 一次性发送所有命令,减少网络往返
}
// Lua 脚本(原子性批量操作)
public void luaScript(Jedis jedis) {
String luaScript =
"local sum = 0 " +
"for i=1,#KEYS do " +
" sum = sum + redis.call('GET', KEYS[i]) " +
"end " +
"return sum";
// 执行 Lua 脚本,传入 3 个 key
Object result = jedis.eval(luaScript, 3, "key1", "key2", "key3");
System.out.println("Sum: " + result);
}
// 使用连接池的完整示例
public static void main(String[] args) {
try (JedisPool pool = new JedisPool("localhost", 6379);
Jedis jedis = pool.getResource()) {
RedisBatchExample example = new RedisBatchExample();
// 测试 Pipeline
long start = System.currentTimeMillis();
example.correctPipeline(jedis, "value");
System.out.println("Pipeline 耗时: " + (System.currentTimeMillis() - start) + "ms");
// 测试 Lua 脚本
jedis.set("key1", "10");
jedis.set("key2", "20");
jedis.set("key3", "30");
example.luaScript(jedis); // 输出: Sum: 60
}
}
}3. 内存优化技巧
|
策略 |
说明 |
配置 |
|
哈希压缩 |
ziplist 编码小 Hash |
|
|
整数集合 |
intset 编码小 Set |
|
|
内存淘汰 |
控制最大内存 |
|
# 内存淘汰策略(maxmemory-policy)
volatile-lru # 从过期Key中淘汰最近最少使用(默认)
allkeys-lru # 从所有Key中淘汰LRU(推荐)
volatile-ttl # 淘汰即将过期的Key
allkeys-random # 随机淘汰
noeviction # 不淘汰,直接报错(写保护)3.3 高可用架构
单机 → 主从复制 → 哨兵模式 → 集群模式
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ Master │◄────►│ Slave 1 │ │ Slave 2 │
│ (读写) │ │ (只读/备份) │ │ (只读/备份) │
└─────────────┘ └─────────────┘ └─────────────┘
▲
│ 哨兵监控(Sentinel)
▼
┌─────────────────────────────────────────────────────┐
│ Sentinel ×3:故障自动转移、服务发现 │
└─────────────────────────────────────────────────────┘
集群模式(Redis Cluster):
┌─────────┐ ┌─────────┐ ┌─────────┐
│ Master A│◄───►│ Master B│◄───►│ Master C│
│(0-5460) │ │(5461-10922) │(10923-16383)
└────┬────┘ └────┬────┘ └────┬────┘
│ │ │
└────┴────┘ └────┴────┘ └────┴────┘
Slave A1,A2 Slave B1,B2 Slave C1,C2四、监控与运维
5.1 关键监控指标
# INFO 命令查看状态
redis-cli INFO
# 关键指标
connected_clients: 50 # 当前连接数
used_memory: 1048576 # 已用内存(字节)
used_memory_rss: 2097152 # 系统分配内存
mem_fragmentation_ratio: 2.0 # 内存碎片率(>1.5需关注)
instantaneous_ops_per_sec: 1000 # 实时QPS
keyspace_hits: 9000 # 命中次数
keyspace_misses: 1000 # 未命中次数
hit_rate: 90% # 命中率(需>95%)
# 慢查询监控
SLOWLOG GET 10 # 获取前10条慢查询
slowlog-log-slower-than 10000 # 配置:超过10ms记录5.2 配置文件核心项
# redis.conf 关键配置
bind 0.0.0.0 # 监听地址
port 6379 # 端口
requirepass your_password # 密码
maxmemory 4gb # 最大内存
maxmemory-policy allkeys-lru # 淘汰策略
# 持久化
save 900 1 # 900秒内有1次修改则RDB
save 300 10 # 300秒内有10次修改则RDB
appendonly yes # 开启AOF
appendfsync everysec # 每秒刷盘(折中方案)
# 安全
rename-command FLUSHALL "" # 禁用危险命令
rename-command CONFIG "CONFIG_abc123" # 重命名命令六、总结速查
|
场景 |
推荐方案 |
关键命令 |
|
Session 存储 |
String + TTL |
|
|
商品详情页 |
String/Hash + 缓存策略 |
|
|
购物车 |
Hash |
|
|
消息队列 |
List/Stream |
|
|
排行榜 |
ZSet |
|
|
社交网络 |
Set |
|
|
附近的人 |
Geo |
|
|
统计UV |
HyperLogLog |
|
|
分布式锁 |
String + Lua |
|
|
限流 |
ZSet/令牌桶 |
|

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 12
12 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)