FedCP:通过条件策略分离特征信息以用于个性化联邦学习
FedCP:通过条件策略分离特征信息以用于个性化联邦学习
(FedCP: Separating Feature Information for Personalized Federated Learning via Conditional Policy)
论文下载地址:https://arxiv.org/abs/2307.01217
摘要
近期,个性化联邦学习(pFL)在隐私保护、协作学习以及解决客户端(例如医院、智能手机等)之间的统计异质性方面引起了越来越多的关注。大多数现有的pFL方法主要集中于在客户端级别的模型参数中利用全局信息和个性化信息,而忽略了数据才是这两种信息的来源。为了解决这个问题,我们提出了联邦条件策略(FedCP)方法,该方法为每个样本生成一个条件策略,以将其特征中的全局信息和个性化信息分离,然后分别通过全局头部和个性化头部对它们进行处理。与现有的pFL方法相比,FedCP在考虑以样本特定的方式进行个性化方面粒度更细。在计算机视觉和自然语言处理领域的广泛实验表明,FedCP以最高6.69%的优势超越了十一个最先进的方法。此外,当部分客户端意外掉线时(这在移动环境中经常发生),FedCP依然保持其优越性。我们的代码已开源于:https://github.com/TsingZ0/FedCP。
CCS概念
• 计算方法论 → 多智能体系统;分布式算法;监督学习。
关键词
联邦学习;统计异质性;个性化;条件计算;特征分离
1 引言
如今,许多基于网络的服务(如个性化推荐)受益于人工智能(AI)以及在各种客户端(例如医院、智能手机、物联网等)本地生成的海量数据。同时,关于数据隐私保护的立法工作不断加强,例如欧洲的通用数据保护条例(GDPR)和加州消费者隐私法案(CCPA)。由于隐私问题和法规,中心化AI面临着重大挑战。另一方面,由于数据稀疏性问题,很难在每个客户端上独立地为给定任务学习到一个合理的模型。
联邦学习(FL)被提出作为一种协作学习范式,旨在利用参与全局模型训练的客户端上的本地数据,而无需共享客户端的私有数据。作为著名的FL方法之一,FedAvg在每次通信迭代中执行四个步骤:(1)服务器将旧的全局模型参数发送给选定的客户端。(2)每个选定的客户端用接收到的全局参数初始化局部模型,并在本地数据上训练局部模型。(3)选定的客户端将更新后的局部模型参数上传到服务器。(4)服务器通过聚合接收到的客户端模型参数来生成新的全局模型参数。然而在实践中,客户端上的数据通常是非独立同分布的(non-IID)且不平衡的。面对这种统计异质性挑战,传统FL方法(如FedAvg)中的单一全局模型很难在每个客户端上很好地拟合本地数据并取得良好的性能。
为了满足每个客户端的个性化需求并应对FL中统计异质性的挑战,个性化联邦学习(pFL)应运而生,它侧重于学习个性化模型而不是单一的全局模型。大多数现有的pFL方法将全局模型视为一个存储全局信息并通过全局模型中的参数丰富个性化模型的容器。然而,它们只关注客户端级别的模型参数,即全局/个性化模型,以利用全局/个性化信息。具体而言,基于元学习的方法(如Per-FedAvg)仅微调全局模型参数以拟合本地数据,而基于正则化的方法(如pFedMe、FedAMP和Ditto)仅在局部训练期间对模型参数进行正则化。尽管基于个性化头部的方法(如FedPer、FedRep和FedRoD)明确地将主干网络拆分为全局部分(特征提取器)和个性化部分(头部),但它们仍然专注于利用模型参数中的全局和个性化信息,而不是信息的来源:数据。由于模型是在数据上训练的,模型参数中的全局/个性化信息源自客户端数据。换句话说,客户端上的异质数据同时包含全局和个性化信息。如图1所示,图像中广泛使用的颜色(例如蓝色)和极少使用的颜色(例如紫色和粉色)分别包含了全局信息和个性化信息。
[图1:FedCP的示例。hi/jh_{i/j}hi/j:提取的特征向量,CPN i/ji/ji/j:条件策略网络,WhdW^{hd}Whd:冻结的全局头部,Wi/jhdW_{i/j}^{hd}Wi/jhd:个性化头部。最好在彩色模式下查看。]
为了分别利用数据中的全局和个性化信息,我们提出了一种基于条件计算技术的**联邦条件策略(FedCP)方法。由于原始输入数据的维度远大于特征提取器提取的特征向量,为了效率,我们将重点放在特征向量上。由于全局信息和个性化信息在不同样本和客户端的特征中所占比例不同,我们提出了一个辅助的条件策略网络(CPN)**来生成特定于样本的策略,用于特征信息分离。然后,我们通过全局头部和个性化头部在不同的路径中分别处理全局特征信息和个性化特征信息,如图1所示。我们将个性化信息存储在个性化头部中,并通过冻结全局头部(不在本地进行训练)来保留全局信息。通过端到端的学习,CPN自动学习生成样本特定的策略。我们在第5.1节中可视化了六个案例,以展示特征信息分离能力的有效性。
为了评估FedCP,我们在两种广泛使用的场景(即病态设置和实际设置)下对各种数据集进行了广泛的实验。FedCP在这两种场景下均优于十一个最先进的(SOTA)方法,我们在第6.1节中分析了原因。总之,我们的主要贡献如下:
- 据我们所知,我们是第一个在FL中考虑对样本特定的特征信息进行个性化处理的研究。它比大多数现有FL方法中使用客户端级别模型参数的粒度更细。
- 我们提出了一种新颖的FedCP,它生成样本特定的策略以分离每个客户端特征中的全局信息和个性化信息。它分别通过每个客户端上的冻结全局头部和个性化头部来处理这两种特征信息。
- 我们在计算机视觉(CV)和自然语言处理(NLP)领域进行了广泛的实验,以证明FedCP的有效性。此外,即使在某些客户端意外掉线的情况下,FedCP仍能保持其卓越的性能。
2 相关工作
2.1 个性化联邦学习
为了在保护隐私的同时在客户端的本地私有数据上协作学习模型,传统的FL方法(如FedAvg和FedProx)应运而生。在FedAvg的基础上,FedProx通过正则化项提高了FL过程的稳定性。然而在实践中,统计异质性在FL设置中广泛存在,因此很难学习到一个能很好地拟合每个客户端本地数据的单一全局模型。
近期,pFL因其应对FL中统计异质性的能力而受到越来越多的关注。在基于元学习的方法中,Per-FedAvg学习一个初始共享模型作为满足每个客户端学习趋势的全局模型。在基于正则化的方法中,pFedMe使用Moreau包络在本地为每个客户端学习一个额外的个性化模型。除了为所有客户端只学习一个全局模型之外,FedAMP通过注意力引导函数寻找相似的客户端,从而为一个客户端生成一个服务器模型。在Ditto中,每个客户端在本地学习其个性化模型时带有一个近端项,以从全局模型参数中获取全局信息。在基于个性化头部的方法中,FedPer和FedRep学习一个全局特征提取器和一个特定于客户端的头部。前者使用特征提取器在本地训练头部,而后者在每次迭代训练特征提取器之前,在本地微调头部直至收敛。为了桥接传统FL和pFL,FedRoD利用一个全局特征提取器和两个头部明确地学习两个预测任务。它对全局预测任务使用平衡softmax(BSM)损失,并通过个性化头部处理个性化任务。在其他pFL方法中,FedFomo使用来自其他客户端的个性化模型,在每个客户端上计算用于聚合的客户端特定权重。FedPHP使用滑动平均在本地聚合全局模型和旧的个性化模型,以保留历史个性化信息。它还通过广泛使用的最大均值差异(MMD)损失在全局特征提取器中传递信息。上述pFL方法仅侧重于利用模型参数中的全局和个性化信息,而没有深入挖掘数据。
[图2:(a) 条件策略在红色菱形框中将信息 hih_ihi 分离为 ri⊙hir_i \odot h_iri⊙hi 和 si⊙his_i \odot h_isi⊙hi。除了特征向量和向量 viv_ivi 之外,标准矩形和圆角矩形分别代表一个层和一个模块。带有虚线边框的圆角矩形是公式(6)中的 W^ihd\widehat{W}_i^{hd}W ihd。WifeW_i^{fe}Wife(灰色边框)不是个性化模型的一部分,数据在训练期间仅在其中前向流动。在训练期间,数据在所有线条中流动,但在推理期间,它只在实线中流动。(b) 为了清晰起见,我们分别展示了特征提取器、头部和CPN的上传和下载流。在实践中,我们仍然将它们作为一个整体在服务器和每个客户端之间进行上传或下载。最好在彩色模式下查看。]
2.2 条件计算
条件计算是一种根据任务相关的条件输入将动态特征引入模型的技术。形式上,给定一个条件输入 CCC(例如,图像/文本、模型参数向量或其他辅助信息)和一个辅助模块 AM(⋅;θ)AM(\cdot;\theta)AM(⋅;θ),可以生成一个信号 S=AM(C;θ)S=AM(C;\theta)S=AM(C;θ),并将其用于干预模型,例如动态路由和特征自适应。
为了激活模型中的特定部分并为每个输入样本在不同路径中处理数据,许多方法生成了样本特定的策略来进行路径选择。以输入图像为条件,ConvNet-AIG可以在推理期间使用Gumbel Softmax决定需要哪些层。借助策略网络,SpotTune为每张图像做出决策,以选择预训练残差网络中的哪些块进行微调。
除了专注于动态模型拓扑之外,一些方法提出自适应学习到的特征。在少样本学习领域,TADAM通过由提取的任务表示为条件的仿射变换来自适应特征。在视频目标检测领域,TMA提出了一种以视频帧为条件的可学习仿射变换来进行特征自适应。
上述方法使用了条件计算技术,但它们是为中心化AI场景和特定任务设计的。结合动态路由和特征自适应的思想,我们在FedCP中设计了CPN模块,以分离全局特征信息和个性化特征信息,然后在pFL场景和各种任务中通过不同的路径处理它们。
3 方法
3.1 概述
在统计异质的pFL设置中,NNN 个客户端上存在non-IID和不平衡的数据,它们以协作的方式训练各自的个性化模型 W1,…,WNW_1,\ldots,W_NW1,…,WN。NNN 个客户端分别拥有私有数据集 D1,…,DN\mathcal{D}_1,\ldots,\mathcal{D}_ND1,…,DN,这些数据集从 NNN 个不同的分布中采样且互不重叠。
类似于FedPer,FedRep和FedRoD,我们将主干网络拆分为一个特征提取器 f:RD→RKf:\mathbb{R}^D \rightarrow \mathbb{R}^Kf:RD→RK,它将输入样本映射到特征空间,以及一个头部 g:RK→RCg:\mathbb{R}^K \rightarrow \mathbb{R}^Cg:RK→RC,它从低维特征空间映射到标签空间。遵循FedRep,我们将给定主干网络中的最后一个全连接(FC)层视为头部。DDD、KKK 和 CCC 分别是输入空间、特征空间和标签空间的维度。KKK 由给定的主干网络决定,并且通常 D≫KD \gg KD≫K。
与FedPer、FedRep和FedRoD不同的是,在客户端 iii 上,我们有一个全局特征提取器(由 WfeW^{fe}Wfe 参数化)、一个全局头部(由 WhdW^{hd}Whd 参数化)、一个个性化特征提取器(由 WifeW_i^{fe}Wife 参数化)、一个个性化头部(由 WihdW_i^{hd}Wihd 参数化)和一个CPN(由 Θi\Theta_iΘi 参数化)。具体而言,对于特征提取器,在每次迭代时,我们通过使用对应的全局参数 WfeW^{fe}Wfe 覆盖它来初始化 WifeW_i^{fe}Wife,然后在本地学习个性化特征提取器。由不断变化的个性化特征提取器生成的特征可能无法适应本地学习期间冻结的全局头部。因此,我们在接收后冻结全局特征提取器,并通过MMD损失将个性化特征提取器输出的特征与全局特征提取器生成的特征进行对齐,如图2(a)所示。对于全局头部,在它被 WhdW^{hd}Whd 初始化后我们就将其冻结,以保留全局信息。简而言之,在每次迭代开始时,我们用新的 WfeW^{fe}Wfe 覆盖 WifeW_i^{fe}Wife,然后冻结 WfeW^{fe}Wfe 和 WhdW^{hd}Whd。如图2(a)中的非透明模块所示,用于推理的个性化模型(由 WiW_iWi 参数化)由个性化特征提取器、全局头部、个性化头部和CPN组成,即 Wi:={Wife,Whd,Wihd,Θi}W_i := \{ W_i^{fe}, W^{hd}, W_i^{hd}, \Theta_i \}Wi:={Wife,Whd,Wihd,Θi}。冻结的全局特征提取器仅用于本地学习,不是个性化模型的一部分。为简便起见,我们省略了迭代符号、样本索引符号和偏置。给定局部损失 Fi\mathcal{F}_iFi(后文描述),我们的目标是
{W1,…,WN}=argminG(F1,…,FN).(1) \{W_1,\dots,W_N\} = \arg\min \mathcal{G}(\mathcal{F}_1,\dots,\mathcal{F}_N). \quad (1) {W1,…,WN}=argminG(F1,…,FN).(1)
通常,G(F1,…,FN)=∑i=1NniFi\mathcal{G}(\mathcal{F}_1,\dots,\mathcal{F}_N) = \sum_{i=1}^N n_i \mathcal{F}_iG(F1,…,FN)=∑i=1NniFi,ni=∣Di∣/∑j=1N∣Dj∣n_i = |\mathcal{D}_i|/\sum_{j=1}^N |\mathcal{D}_j|ni=∣Di∣/∑j=1N∣Dj∣,并且 ∣Di∣|\mathcal{D}_i|∣Di∣ 是客户端 iii 上的样本数量。
3.2 联邦条件策略(FedCP)
我们专注于对特征向量进行特征信息分离:
hi=f(xi;Wife),∀(xi,yi)∈Di.(2) h_i = f(x_i; W_i^{fe}), \forall (x_i, y_i) \in \mathcal{D}_i. \quad (2) hi=f(xi;Wife),∀(xi,yi)∈Di.(2)
由于统计异质性,hi∈RKh_i \in \mathbb{R}^Khi∈RK 包含了全局和个性化特征信息。为了分别利用这两种信息,我们提出了FedCP,以端到端的方式学习样本特定的分离,如图2所示。
3.2.1 分离特征信息。
在冻结的全局头部中的全局信息和个性化头部中的个性化信息的引导下,CPN(FedCP的核心)可以学习生成样本特定的策略,并自动分离 hih_ihi 中的全局和个性化信息。
具体而言,我们将CPN设计为一个FC层和一个层归一化(layer-normalization)层的串联,随后加上ReLU激活函数,如图2(a)所示。在客户端 iii 上,我们通过以下公式生成样本特定的策略:
{ri,si}:=CPN(Ci;Θi),(3) \{r_i, s_i\} := \text{CPN}(C_i; \Theta_i), \quad (3) {ri,si}:=CPN(Ci;Θi),(3)
其中 ri∈RK,si∈RKr_i \in \mathbb{R}^K, s_i \in \mathbb{R}^Kri∈RK,si∈RK,对于 ∀k∈[K]\forall k \in [K]∀k∈[K] 有 rik+sik=1r_i^k + s_i^k = 1rik+sik=1,且 Ci∈RKC_i \in \mathbb{R}^KCi∈RK 是CPN的样本特定输入。我们对输入 CiC_iCi 和输出 {ri,si}\{r_i, s_i\}{ri,si} 的细节描述如下。
生成 CiC_iCi 是为了获取样本特定特征并引入个性化(客户端特定)信息。我们可以直接获取样本特定向量 hih_ihi,所以在这里我们只介绍如何获取客户端特定信息。基于FedRep和FedRoD,个性化头部中的参数,即 WihdW_i^{hd}Wihd,自然包含客户端特定的信息。然而,WihdW_i^{hd}Wihd 是一个矩阵,而不是向量。因此,我们通过降维 WihdW_i^{hd}Wihd 来生成 viv_ivi。回想一下,FedCP中的头部是一个FC层,即 Wihd∈RC×KW_i^{hd} \in \mathbb{R}^{C \times K}Wihd∈RC×K,因此 WihdW_i^{hd}Wihd 的第 kkk 列对应于 hih_ihi 中的第 kkk 个特征。我们通过 vi:=∑c=1CwcTv_i := \sum_{c=1}^C w_c^Tvi:=∑c=1CwcT 获得 viv_ivi,其中 wcw_cwc 是 WihdW_i^{hd}Wihd 中的第 ccc 行,且 vi∈RKv_i \in \mathbb{R}^Kvi∈RK。通过这种方式,我们获得了一个形状与特征级语义同 hih_ihi 相同的客户端特定向量。然后,我们通过 Ci:=(vi/∣∣vi∣∣2)⊙hiC_i := (v_i/||v_i||_2) \odot h_iCi:=(vi/∣∣vi∣∣2)⊙hi 结合样本特定的 hih_ihi 和客户端特定的 viv_ivi,其中 ∣∣vi∣∣2||v_i||_2∣∣vi∣∣2 是 viv_ivi 的 ℓ2\ell_2ℓ2-范数,⊙\odot⊙ 是Hadamard乘积。在每次迭代的本地学习之前我们获取 viv_ivi,并在训练期间将其视为常数。在推理期间,我们重复使用最新的 viv_ivi。
我们通过将策略 {ri,si}\{r_i, s_i\}{ri,si} 乘以 hih_ihi 来获得全局特征信息 ri⊙hir_i \odot h_iri⊙hi 和个性化特征信息 si⊙his_i \odot h_isi⊙hi,从而实现信息分离。特征之间存在关联,因此我们输出的 {ri,si}\{r_i, s_i\}{ri,si} 是实数而不是布尔值,即 rik∈(0,1)r_i^k \in (0,1)rik∈(0,1) 且 sik∈(0,1)s_i^k \in (0,1)sik∈(0,1)。受策略生成中Gumbel-Max技巧的启发,我们借助中间变量和一个softmax操作,通过以下两步生成策略。首先,CPN生成中间变量 ai∈RK×2a_i \in \mathbb{R}^{K \times 2}ai∈RK×2,其中 aik={ai,1k,ai,2k}a_i^k = \{a_{i,1}^k, a_{i,2}^k\}aik={ai,1k,ai,2k}, k∈[K]k \in [K]k∈[K],并且 ai,1ka_{i,1}^kai,1k 和 ai,2ka_{i,2}^kai,2k 是没有约束的标量。其次,我们通过以下公式获得 rikr_i^krik 和 siks_i^ksik:
rik=exp(ai,1k)∑j∈{1,2}exp(ai,jk),sik=exp(ai,2k)∑j∈{1,2}exp(ai,jk).(4) r_i^k = \frac{\exp(a_{i,1}^k)}{\sum_{j\in\{1,2\}} \exp(a_{i,j}^k)}, \quad s_i^k = \frac{\exp(a_{i,2}^k)}{\sum_{j\in\{1,2\}} \exp(a_{i,j}^k)}. \quad (4) rik=∑j∈{1,2}exp(ai,jk)exp(ai,1k),sik=∑j∈{1,2}exp(ai,jk)exp(ai,2k).(4)
请注意,rik∈(0,1),sik∈(0,1)r_i^k \in (0,1), s_i^k \in (0,1)rik∈(0,1),sik∈(0,1) 且 rik+sik=1,∀k∈[K]r_i^k + s_i^k = 1, \forall k \in [K]rik+sik=1,∀k∈[K] 依然成立。
[算法 1:FedCP 中的学习过程
输入: NNN 个带有本地数据的客户端,Wfe,0W^{fe,0}Wfe,0:全局特征提取器的初始参数,Whd,0W^{hd,0}Whd,0:全局头部的初始参数,Θ0\Theta^0Θ0:全局 CPN 的初始参数,η\etaη:本地学习率,λ\lambdaλ:MMD损失的超参数,ρ∈(0,1]\rho \in (0, 1]ρ∈(0,1]:一次迭代中的客户端参与率,TTT:总训练迭代次数。
输出: 合理的个性化模型 {W1,…,WN}\{W_1, \ldots, W_N\}{W1,…,WN}。
1: 服务器发送 Wfe,0W^{fe,0}Wfe,0 和 Whd,0W^{hd,0}Whd,0 以初始化客户端 i,∀i∈[N]i, \forall i \in [N]i,∀i∈[N] 上的 WfeW^{fe}Wfe、WhdW^{hd}Whd、WifeW_i^{fe}Wife 和 WihdW_i^{hd}Wihd。
2: 服务器发送 Θ0\Theta^0Θ0 以初始化客户端 i,∀i∈[N]i, \forall i \in [N]i,∀i∈[N] 上的 CPN。
3: for 迭代 t=0,…,Tt=0, \ldots, Tt=0,…,T do
4: 服务器基于 ρ\rhoρ 随机采样一个客户端子集 It\mathcal{I}^tIt。
5: 服务器向选定的客户端发送 Wfe,tW^{fe,t}Wfe,t、Whd,tW^{hd,t}Whd,t 和 Θt\Theta^tΘt。
6: for 客户端 i∈Iti \in \mathcal{I}^ti∈It 并行 do
▹\triangleright▹ 局部初始化
7: 客户端 iii 用参数 Wfe,tW^{fe,t}Wfe,t 覆盖 WfeW^{fe}Wfe 和 WifeW_i^{fe}Wife,并冻结 WfeW^{fe}Wfe。
8: 客户端 iii 用参数 Whd,tW^{hd,t}Whd,t 覆盖 WhdW^{hd}Whd,并冻结 WhdW^{hd}Whd。
9: 客户端 iii 用参数 Θt\Theta^tΘt 覆盖 Θi\Theta_iΘi。
10: 客户端 iii 生成客户端特定向量 viv_ivi。
▹\triangleright▹ 局部学习
11: 客户端 iii 同时更新 WifeW_i^{fe}Wife、WihdW_i^{hd}Wihd 和 Θi\Theta_iΘi:
12: Wife←Wife−η∇WifeFiW_i^{fe} \leftarrow W_i^{fe} - \eta \nabla_{W_i^{fe}} \mathcal{F}_iWife←Wife−η∇WifeFi;
13: Wihd←Wihd−η∇WihdFiW_i^{hd} \leftarrow W_i^{hd} - \eta \nabla_{W_i^{hd}} \mathcal{F}_iWihd←Wihd−η∇WihdFi;
14: Θi←Θi−η∇ΘiFi\Theta_i \leftarrow \Theta_i - \eta \nabla_{\Theta_i} \mathcal{F}_iΘi←Θi−η∇ΘiFi。
15: 客户端 iii 通过公式(6)获得 W^ihd\widehat{W}_i^{hd}W ihd。
16: 客户端 iii 向服务器上传 {Wife,W^ihd,Θi}\{W_i^{fe}, \widehat{W}_i^{hd}, \Theta_i\}{Wife,W ihd,Θi}。
17: end for
▹\triangleright▹ 服务器聚合
18: 服务器计算 nt=∑i∈Itnin^t = \sum_{i\in\mathcal{I}^t} n_int=∑i∈Itni 并获得
19: Wfe,t+1=1nt∑i∈ItniWifeW^{fe,t+1} = \frac{1}{n^t} \sum_{i\in\mathcal{I}^t} n_i W_i^{fe}Wfe,t+1=nt1∑i∈ItniWife;
20: Whd,t+1=1nt∑i∈ItniW^ihdW^{hd,t+1} = \frac{1}{n^t} \sum_{i\in\mathcal{I}^t} n_i \widehat{W}_i^{hd}Whd,t+1=nt1∑i∈ItniW ihd;
21: Θt+1=1nt∑i∈ItniΘi\Theta^{t+1} = \frac{1}{n^t} \sum_{i\in\mathcal{I}^t} n_i \Theta_iΘt+1=nt1∑i∈ItniΘi。
22: end for
23: return {W1,…,WN}\{W_1, \ldots, W_N\}{W1,…,WN}]
3.2.2 处理特征信息。
然后,我们将 ri⊙hir_i \odot h_iri⊙hi 和 si⊙his_i \odot h_isi⊙hi 分别输入到全局头部和个性化头部。全局头部和个性化头部的输出分别是 outir=g(ri⊙hi;Whd)out_i^{r} = g(r_i \odot h_i; W^{hd})outir=g(ri⊙hi;Whd) 和 outis=g(si⊙hi;Wihd)out_i^{s} = g(s_i \odot h_i; W_i^{hd})outis=g(si⊙hi;Wihd)。我们定义最终输出 outi:=outir+outisout_i := out_i^{r} + out_i^{s}outi:=outir+outis。那么局部损失为
Ei=E(xi,yi)∼DiL(outi,yi),(5) \mathcal{E}_i = \mathbb{E}_{(x_i, y_i) \sim \mathcal{D}_i} \mathcal{L}(out_i, y_i), \quad (5) Ei=E(xi,yi)∼DiL(outi,yi),(5)
其中 L\mathcal{L}L 是交叉熵损失函数。
从每个样本的角度来看,提取的特征由全局头部和个性化头部共同处理。为简便起见,我们通过平均这两个头部来聚合它们,从而形成要上传的头部 W^ihd\widehat{W}_i^{hd}W
ihd:
W^ihd=Whd+Wihd2.(6) \widehat{W}_i^{hd} = \frac{W^{hd} + W_i^{hd}}{2}. \quad (6) W
ihd=2Whd+Wihd.(6)
在每次迭代中,我们向服务器上传 {Wife,W^ihd,Θi}\{W_i^{fe}, \widehat{W}_i^{hd}, \Theta_i\}{Wife,W
ihd,Θi}。
3.2.3 对齐特征。
为了使个性化特征提取器输出的特征适应冻结的全局头部,我们通过MMD损失 Eid\mathcal{E}_i^dEid 来对齐个性化特征提取器和全局特征提取器输出的特征,
Eid=∣∣E(xi,yi)∼Diϕ(hi)−E(xi,yi)∼Diϕ(f(xi;Wfe))∣∣H2,(7) \mathcal{E}_i^d = ||\mathbb{E}_{(x_i, y_i) \sim \mathcal{D}_i} \phi(h_i) - \mathbb{E}_{(x_i, y_i) \sim \mathcal{D}_i} \phi(f(x_i; W^{fe}))||^2_{\mathcal{H}}, \quad (7) Eid=∣∣E(xi,yi)∼Diϕ(hi)−E(xi,yi)∼Diϕ(f(xi;Wfe))∣∣H2,(7)
其中 H\mathcal{H}H 是再生核希尔伯特空间(RKHS),而 ϕ\phiϕ 由特定的核函数(例如径向基函数(RBF))诱导,即 κ(hi,hj)=⟨ϕ(hi),ϕ(hj)⟩\kappa(h_i, h_j) = \langle \phi(h_i), \phi(h_j) \rangleκ(hi,hj)=⟨ϕ(hi),ϕ(hj)⟩。最后,我们得到局部损失 Fi=Ei+λEid\mathcal{F}_i = \mathcal{E}_i + \lambda \mathcal{E}_i^dFi=Ei+λEid,其中 λ\lambdaλ 是超参数。具体为,
Fi=E(xi,yi)∼DiL[g(ri⊙hi;Whd)+g(si⊙hi;Wihd),yi] \mathcal{F}_i = \mathbb{E}_{(x_i, y_i) \sim \mathcal{D}_i} \mathcal{L}[g(r_i \odot h_i; W^{hd}) + g(s_i \odot h_i; W_i^{hd}), y_i] Fi=E(xi,yi)∼DiL[g(ri⊙hi;Whd)+g(si⊙hi;Wihd),yi]
+λ∣∣E(xi,yi)∼Diϕ(hi)−E(xi,yi)∼Diϕ(f(xi;Wfe))∣∣H2,(8) + \lambda ||\mathbb{E}_{(x_i, y_i) \sim \mathcal{D}_i} \phi(h_i) - \mathbb{E}_{(x_i, y_i) \sim \mathcal{D}_i} \phi(f(x_i; W^{fe}))||^2_{\mathcal{H}}, \quad (8) +λ∣∣E(xi,yi)∼Diϕ(hi)−E(xi,yi)∼Diϕ(f(xi;Wfe))∣∣H2,(8)
其中 hih_ihi 是通过公式(2)提取的特征向量,rir_iri 和 sis_isi 是通过公式(3)获得的。我们在算法1中展示了完整的学习过程,并在图2(a)中展示了用于推理的模型。
3.3 隐私分析
根据图2(b)和算法1,我们提出的FedCP共享一个特征提取器、一个头部和一个CPN的参数。至于头部部分,我们在通过公式(6)聚合 WhdW^{hd}Whd 和 WihdW_i^{hd}Wihd 之后,在每个客户端上上传 W^ihd\widehat{W}_i^{hd}W ihd。这个过程可以看作是在 W^ihd\widehat{W}_i^{hd}W ihd 中加入噪声(全局参数 WhdW^{hd}Whd),从而在上传和下载过程中保护了隐私。此外,样本特定的特征进一步提升了FedCP的隐私保护能力。一方面,由于 CiC_iCi 是动态生成的而无需与服务器共享,因此很难利用CPN或通过模型反演攻击恢复出样本特定的策略。另一方面,如果没有样本特定策略,特征提取器和头部之间的连接就会被打破,这增加了基于共享模型参数的攻击难度。我们在附录B中评估了FedCP的隐私保护能力。
4 实验设置
我们在各种图像/文本分类任务上评估FedCP。对于图像分类任务,我们使用四个著名的数据集,包括MNIST、Cifar10、Cifar100和Tiny-ImageNet(包含200个类的10万张图像),使用的是著名的4层CNN。为了在比4层CNN更大的主干模型上评估FedCP,我们还在Tiny-ImageNet上使用了ResNet-18。我们将4层CNN的局部学习率 η\etaη 设为0.005,ResNet-18的 η\etaη 设为0.1。对于文本分类任务,我们在fastText上使用AG News数据集,设定 η=0.1\eta=0.1η=0.1,其他设置与图像分类任务相同。
我们在两种广泛使用的场景(即病态设置和实际设置)下模拟异质环境。对于病态设置,我们为每个客户端从总共10/10/100个类中采样2/2/10个类,用于MNIST/Cifar10/Cifar100,并使用不重叠的数据。具体而言,与FedAvg相似,我们将客户端划分为具有相同标签的不平衡数据的组。遵循MOON的方法,我们通过狄利克雷分布(表示为 Dir(β)Dir(\beta)Dir(β))创建实际设置。具体而言,我们采样 qc,i∼Dir(β)q_{c,i} \sim Dir(\beta)qc,i∼Dir(β) 并将类 ccc 的 qc,iq_{c,i}qc,i 比例的样本分配给客户端 iii。针对默认的实际设置,我们设置 β=0.1\beta=0.1β=0.1。然后,我们将每个客户端上的数据拆分为训练数据集(75%)和测试数据集(25%)。
遵循FedAvg的方法,我们将局部批大小设为10,局部学习轮次设为1。我们运行所有任务直到所有方法根据经验收敛,最高运行2000次迭代。基于pFedMe、FedFomo和FedRoD的方法,我们将客户端总数设为20,默认客户端参与率 ρ=1\rho=1ρ=1。遵循pFedMe的方法,我们报告传统FL方法最佳全局模型的测试准确率,以及pFL方法最佳个性化模型的平均测试准确率。我们所有实验均运行五次并报告平均值和标准差。此外,我们在一台配备两颗 Intel Xeon Gold 6140 CPU(36核)、128G内存、八块 NVIDIA 2080 Ti GPU 和 CentOS 7.8 系统的机器上运行了所有实验。更多结果和详细信息,请参阅附录。
[图3:第一行展示了Tiny-ImageNet的六个样本。第二行和第三行分别展示了仅激活全局头部或仅激活个性化头部时,学习到的个性化模型的Grad-CAM可视化结果。高亮区域是模型关注的部分。]
5 消融研究
5.1 特征信息可视化
为了可视化在使用ResNet-18时分离的全局和个性化特征信息,我们在只激活全局头部或个性化头部的情况下,对学习到的个性化模型应用Grad-CAM。图3中展示了来自Tiny-ImageNet的六个案例。
根据图3,当仅激活全局头部时,个性化模型关注相对全局的信息,如背景中的树木(案例0和案例4)、草地(案例1)或天空(案例2和案例5)。当仅激活个性化头部时,个性化模型关注相对个性化的信息,如前景(案例2和案例5)或物体(案例0、案例1和案例4)。对于案例3,极少使用的粉色比广泛使用的蓝色更具个性化。
[图4:用于模块消融研究变体的图示。]

[表1:在Tiny-ImageNet上使用ResNet-18进行消融研究的准确率(%)。]
5.2 CPN输入的有效性
为了展示CPN输入各部分的有效性,我们逐个移除它们并获得了不同的变体:无客户端特定向量(w.o. cs)、无样本特定向量(w.o. ss)、无客户端特定和样本特定向量(w.o. cs & ss)。对于 w.o. cs & ss,我们将随机初始化的冻结向量视为CPN的输入,该向量与样本特定向量的形状相同。
在表1中,移除客户端特定向量或样本特定向量都会导致准确率下降。然而,w.o. cs 的表现优于 w.o. ss,这说明样本特定向量比客户端特定向量更重要。根据表1和表2,即便去除了这两种信息并使用随机向量,w.o. cs & ss 仍然获得了比所有基线方法更高的准确率,因为CPN模块仍然可以通过端到端的训练学习分离特征信息。
5.3 FedCP模块的有效性
为了展示FedCP中每个模块的有效性,我们逐个移除它们并获得变体:无冻结全局特征提取器且无MMD损失(简称无GFM,即 w.o. GFM)、无CPN(w.o. CPN)、无CPN和GFM(w.o. CPN & GFM)、无CPN和冻结全局头部(w.o. CPN & GH)、无CPN、无GFM且无冻结全局头部(w.o. CPN & GFM & GH,类似于FedPer),如图4所示。在移除冻结全局头部的同时保留CPN是无效的,因为它们为了实现特征分离的目标是一个整体。
在表1中,在没有GFM对齐特征的情况下,w.o. GFM 的准确率与FedCP相比下降了1.31%,但它仍然优于其他基线方法(见表2)。在没有CPN的情况下,w.o. CPN 的准确率下降了3.01%,因此在存在冻结全局头部的情况下,CPN比GFM更为关键。同时移除CPN和GFM(w.o. CPN & GFM)比仅移除其中一个的退化更严重,这意味着这两个模块可以相互促进。CPN和冻结全局头部是FedCP中的关键模块。没有它们,w.o. CPN & GH 的性能显著下降,与FedCP相比下降了8.74%。此外,w.o. CPN & GFM & GH(移除所有模块)的表现优于 w.o. CPN & GH。这意味着仅仅向 w.o. CPN & GFM & GH 添加GFM会导致性能退化。
6 评估与分析
6.1 主实验
由于篇幅有限,我们用“TINY”和“TINY*”分别表示在Tiny-ImageNet上使用4层CNN和使用ResNet-18。表2显示,无论使用4层CNN还是ResNet-18,FedCP均优于所有基线方法,尤其是在相对具有挑战性的任务上。在Cifar100的默认实际设置中,FedCP比最佳基线(Ditto)高出6.69%。我们的CPN在每个客户端上仅引入了额外的0.527M(百万)个参数,分别占4层CNN(5.695M)和ResNet-18(11.279M)参数的9.25%和4.67%。在下文中,我们将分析为何FedCP的表现优于所有基线方法。
[表2:主实验中图像/文本分类任务的准确率(%)。]
在表2中,FedAvg和FedProx表现不佳,因为全局模型无法很好地拟合所有客户端上的本地数据。无论特征中的个性化信息如何,它们直接将特征馈送到全局头部。相比之下,FedCP分离出特征中的全局信息和个性化信息,并将它们分别输入到全局头部和个性化头部。
Per-FedAvg在pFL方法中表现不佳,因为聚合的学习趋势很难满足每个个性化模型的趋势。相反,FedCP考虑的是以客户端特定向量为条件的样本特定维度的个性化,这满足了每个客户端的需求,从而表现更好。
pFedMe和FedAMP分别利用正则化项从局部模型和客户端特定服务器模型中提取信息。然而,过度关注个性化不利于FL的协作目标。由于Ditto从全局模型中提取全局信息,因此它的表现优于pFedMe和FedAMP。像Ditto一样,FedCP也为每个客户端利用了全局信息。
FedPer和FedRep仅共享特征提取器而不共享头部。它们忽略了头部中的部分全局信息,因此表现比FedCP差。FedRoD通过学习带有两个目标的两个头部,架起了传统FL和pFL的桥梁。然而,这两个目标是相互竞争的,所以FedRoD的表现比FedRep差,而后者同样学习个性化头部但只专注于pFL目标。像FedRep一样,FedCP仅关注pFL目标,因此表现最好。
与FedAMP类似,FedFomo使用客户端特定的权重聚合客户端模型,从而丢失了一些全局信息。FedPHP仅通过MMD损失在全局特征提取器中传递全局信息。尽管它取得了优异的性能,但FedPHP在局部训练期间丢失了全局头部中的全局信息,所以它的表现比FedCP差。
6.2 计算与通信开销
在此,我们专注于训练阶段。我们记录了每种方法收敛所需的总时间和迭代次数,并计算每次迭代的平均时间消耗,如表3所示。由于额外的个性化模型训练需要大量额外的时间,Ditto和pFedMe在每次迭代中耗费的时间比大多数方法都多。与大多数基线方法(如Per-FedAvg、pFedMe、Ditto、FedRep和FedPHP)相比,FedCP在每次迭代中的训练时间更少。在FedCP中,使用ResNet-18与FedAvg相比,CPN模块中的参数在每次迭代仅需要额外的4.67%通信开销。
[表3:在Tiny-ImageNet上使用ResNet-18的计算时间和通信迭代次数。]
6.3 不同的异质性程度
除了表2之外,我们通过改变 β\betaβ,在Tiny-ImageNet和AG News上进行了不同统计异质程度的实验。β\betaβ 越小,设置的异质性越强。我们在表4中展示了准确率,其中FedCP依然超越了所有基线方法。在异质性更强的设置中,大多数pFL方法比传统FL方法实现了更高的准确率。在具有较大 β\betaβ 的设置中,大多数方法在Tiny-ImageNet上的准确率都无法超过FedAvg。相反,那些在局部学习期间利用全局信息的方法(FedPHP、FedRoD和FedCP)保持了出色的性能。FedRoD的表现比FedRep差,因为后者仅专注于pFL目标。pFedMe和FedAMP在pFL方法中表现不佳。当 β=1\beta=1β=1 时,它们的准确率低于传统FL方法。
6.4 不同客户端数量的可扩展性
遵循MOON的方法,我们进行了另外六组实验(即 N=10,N=30,N=50,N=100,N=200N=10, N=30, N=50, N=100, N=200N=10,N=30,N=50,N=100,N=200 和 N=500N=500N=500)来研究FedCP的可扩展性并保持其他设置不变。Per-FedAvg比其他方法需要更多的数据,因为元学习至少需要两个批次的数据,而这在 N≥200N \geq 200N≥200 时的不平衡设置下,某些客户端上是无效的。由于Cifar100上的数据总量是恒定的,局部数据量(平均而言)随着客户端数量的增加而减少。由于 NNN 和局部数据量都在改变,比较表4中不同 NNN 之间的结果是不合理的。部分pFL方法(包括Per-FedAvg和pFedMe)在 N=10N=10N=10 的设置下表现相对较差,在该设置下只有少数客户端(例如医院)参与FL,且每个客户端拥有大型数据仓库。当 N=500N=500N=500 时(例如智能手机),每个客户端平均只有90个样本用于训练,这对于FedFomo中的权重计算来说是不够的,因此其表现比FedAvg差。FedAMP因为在数据量很少时难以找到相似的客户端而发散。根据表4,FedCP仍然优于所有基线方法。
为了模拟一个在FL中客户端越多意味着总数据量越多的真实场景,我们将上述使用的设置 Cifar100 (β=0.1,ρ=1,N=50\beta=0.1, \rho=1, N=50β=0.1,ρ=1,N=50) 作为基准设置,并从现有的50个客户端中随机抽取10个和30个客户端,分别组成 Cifar100 (β=0.1,ρ=1,N=10∣50\beta=0.1, \rho=1, N=10|50β=0.1,ρ=1,N=10∣50) 和 Cifar100 (β=0.1,ρ=1,N=30∣50\beta=0.1, \rho=1, N=30|50β=0.1,ρ=1,N=30∣50) 的设置。当我们增加客户端数量时,因为利用了更多数据来训练全局共享模块,从而促进了客户端之间的信息传递,准确率随之提高。表5中FedCP的出色表现展示了其在这种真实场景中的可扩展性。
[表4:异质性和可扩展性方面图像/文本分类任务的准确率(%)。]

[表5:在Cifar100上关于可扩展性的准确率(%)。]
6.5 大局部轮次
在FL中,较大的局部轮次(Local Epochs)可以减少总的通信迭代次数,但增加了大多数方法每次迭代的计算开销。使用较大的局部轮次,FedCP仍然可以保持其优势,如表6所示。大多数方法在局部轮次变大时性能变差,因为更多的局部训练加剧了客户端模型之间的差异,这不利于服务器的聚合。例如,当局部轮次数从5增加到40时,FedRoD的准确率下降了2.16%。
[表6:在默认实际设置下的Cifar10在使用较大局部轮次时的准确率(%)。]
6.6 客户端意外掉线
由于网络连接质量的变化,某些客户端可能在一次迭代中意外(随机)掉线,并在另一次迭代中重新活跃,这在移动环境中经常发生。我们比较了当部分客户端意外掉线时pFL方法的性能,如表7所示。我们没有使用常数 ρ\rhoρ,而是在每次迭代中在一个给定范围内随机选择一个 ρ\rhoρ 值。ρ\rhoρ 的范围越大,设置越不稳定。它通过随机的掉线率模拟了一个更加实际的场景,而不是SOTA方法中在所有迭代中都设置固定掉线率的场景。
在不稳定的设置中,大多数pFL方法的准确率都会下降。与表7中 ρ=1\rho=1ρ=1 的情况相比,pFedMe和FedPHP的准确率分别下降了最多6.65%和9.80%。部分方法(如FedRep和FedRoD)在更大的 ρ\rhoρ 范围内表现更差。当 ρ∈[0.1,1]\rho \in [0.1, 1]ρ∈[0.1,1] 时,Per-FedAvg、pFedMe、Ditto和FedRoD的标准差大于1%,这意味着它们的性能在随机 ρ\rhoρ 下是不稳定的。由于CPN能自动分离特征信息,FedCP可以适应不断变化的环境,从而在这些不稳定的设置中依然保持优势和稳定的性能。
[表7:当客户端意外掉线时,在Cifar100 (N=50,β=0.1N=50, \beta=0.1N=50,β=0.1) 上的准确率(%)。]
7 超参数 λ\lambdaλ 的影响
为了引导学习到的特征适应冻结的全局头部,我们使用超参数 λ\lambdaλ 来控制MMD损失的重要性,该损失对齐个性化特征提取器和全局特征提取器的输出。λ\lambdaλ 越大,这两个输出就越接近。
[表8:在三种实际设置下,在Tiny-ImageNet上使用4层CNN的准确率(%)。]
从表8可以看出,随着 λ\lambdaλ 的增加,准确率先上升后下降,这在三种具有不同统计异质程度的设置中是相似的。通过为 λ\lambdaλ 设定一个适当的值,个性化特征提取器可以从局部数据中学习信息,同时引导输出特征去拟合冻结的全局头部。当 λ\lambdaλ 的值过大(例如 λ=50\lambda=50λ=50)时,个性化特征提取器几乎无法从局部数据中学习。相反,它倾向于输出与冻结的全局特征提取器相似的结果。为了在异质性更强的设置(例如 β=0.01\beta=0.01β=0.01)中更多地关注局部数据,FedCP需要一个相对较小的 λ\lambdaλ,因为在这种情况下全局信息的作用没那么关键。
8 策略研究
我们在图5中展示了训练样本的策略变化以及推理期间所有测试样本的生成策略。为了清晰起见,我们在每个客户端上收集所有特定样本的 sis_isi,并对它们求平均值以得到 sˉi\bar{s}_isˉi。然后我们进一步对 sˉi\bar{s}_isˉi 中的元素求平均值以生成一个标量,该标量称为个性化识别率(PIR):PIRi:=1K∑kKsˉik,i∈[N]\text{PIR}_i := \frac{1}{K} \sum_k^K \bar{s}_i^k, i \in [N]PIRi:=K1∑kKsˉik,i∈[N],其中 sˉik\bar{s}_i^ksˉik 是策略 sˉi\bar{s}_isˉi 中的第 kkk 个元素。
[图5:在默认实际设置的Tiny-ImageNet上,PIR和 sis_isi 分布的可视化。蓝色和橙色分别代表使用4层CNN和ResNet-18时的图表。我们绘制了训练样本的PIR变化曲线。最好在彩色模式下查看。]
当使用具有不同特征提取能力的各种主干网络时,PIR的变化和 sis_isi 的分布在策略上都会有所不同。如图5(a)所示,在客户端#0上,在使用4层CNN时,PIR在前20次迭代中从0.50的初始值增加到0.58左右,并保持几乎不变。然而,当使用ResNet-18时,PIR先下降,然后迅速上升到0.61左右,这意味着在ResNet-18中提取的特征在早期迭代中包含了更多的全局特征信息,而我们的CPN可以在所有的FL迭代中自动捕捉这一动态特性。在图5(b)中,sis_isi 的取值范围在不同客户端之间有所不同,因为它们包含不同的样本。例如,客户端#10的 sis_isi 范围是所有客户端中最大的。尽管对于不同的样本,策略各不相同,但在使用同一种主干网络时,客户端之间 sis_isi 的均值是相似的,如图5(b)所示。在推理过程中,sis_isi 的值都大于0.5,这意味着在这些场景中,客户端上学习到的特征包含的个性化特征信息多于全局特征信息。
9 结论
我们提出了一种联邦条件策略(FedCP)方法,该方法为每个样本生成一个策略,将其特征分离为全局特征信息和个性化特征信息,然后分别通过全局头部和个性化头部进行处理。FedCP在各种设置下都比十一个SOTA方法高出多达6.69%,并且具有出色的隐私保护能力。此外,当某些客户端意外掉线时,FedCP也保持了出色的性能。
附录
A 收敛性分析
回想我们的目标是
{W1,…,WN}=argminG(F1,…,FN),(9) \{W_1,\ldots,W_N\} = \arg\min \mathcal{G}(\mathcal{F}_1,\ldots,\mathcal{F}_N), \quad (9) {W1,…,WN}=argminG(F1,…,FN),(9)
其中 Fi,∀i∈[N]\mathcal{F}_i, \forall i \in [N]Fi,∀i∈[N] 是局部损失,且 G(F1,…,FN)=∑i=1NniFi\mathcal{G}(\mathcal{F}_1,\ldots,\mathcal{F}_N) = \sum_{i=1}^N n_i \mathcal{F}_iG(F1,…,FN)=∑i=1NniFi。在训练阶段,G\mathcal{G}G 的值就是FedCP的训练损失。为了研究FedCP的收敛性,我们将局部学习后使用训练好的个性化模型计算得到的损失表示为 lossaftloss_{aft}lossaft,将局部学习前使用初始化的个性化模型计算得到的损失表示为 lossbefloss_{bef}lossbef。除了损失值之外,我们还评估了相应的测试准确率,这是通过对每个客户端在各自本地测试数据集上的所有个性化模型的准确率求平均得到的。
为了从经验上分析FedCP的收敛性,我们绘制了使用ResNet-18时FedCP的训练损失曲线和测试准确率曲线,如图6所示。在默认实际设置下的Tiny-ImageNet上,lossaftloss_{aft}lossaft 在74次迭代后变得接近 lossbefloss_{bef}lossbef,并且两者同时达到最小值。换句话说,FedCP在训练约74次迭代后收敛。随着训练损失的减少,测试准确率随之增加。如图5正文部分所示,由于策略的更新,在使用ResNet-18时,损失曲线和准确率曲线在第56次迭代之前都存在波动。

[图6:在默认实际设置的Tiny-ImageNet上使用ResNet-18时的训练损失曲线和测试准确率曲线。红色的圆圈和绿色的方块分别代表局部学习前和局部学习后评估的结果。最好在彩色模式下查看。]
B 隐私保护能力
这里,参照传统的FL方法FedCG,我们考虑一个半诚实的场景,即服务器遵循FL协议,但可能通过梯度深度泄漏(DLG)攻击利用客户端的模型更新来恢复受害者客户端的原始数据。在本文的基线方法中,就服务器与客户端之间的信息传输而言可分为两类。类别1中的方法共享整个主干模型中的参数,例如FedAvg、FedProx、Per-FedAvg、pFedMe、Ditto、FedRoD、FedFomo和FedPHP。类别2中的方法仅共享特征提取器中的参数,例如FedPer和FedRep。不失一般性,我们选择每个类别中最著名的方法作为代表性的基线方法:针对类别1的FedAvg和针对类别2的FedPer。同样参照FedCG,我们在表9中提供了实验结果,以通过峰值信噪比(PSNR)来评估FedCP与代表性基线方法的隐私保护能力。较低的PSNR值表明其具有更好的隐私保护能力。表9中的结果展示了FedCP的优越性。
[表9:在默认实际设置下Cifar100的PSNR。]
C 条件策略网络设计
默认情况下,我们的CPN包含一个全连接(FC)层和一个层归一化(LN)层,随后加上ReLU激活函数。在这里,我们通过改变FC层数、归一化层和激活函数来研究不同设计对CPN有效性的影响,如表10所示。由于中间输出 ai∈RK×2a_i \in \mathbb{R}^{K \times 2}ai∈RK×2 有两组,对于组归一化(GN),我们将组数设置为2。我们仅在FedCP的基础上更改所考虑的组件。带下划线的准确率结果高于FedCP的准确率。
[表10:在默认实际设置下,Tiny-ImageNet上使用不同CPN时的准确率(%)。]
表10中的结果表明,我们可以通过为CPN使用其他架构来进一步提升FedCP。增加更多的FC层来处理输入提高了ResNet-18的测试准确率,但导致4层CNN略微下降。为拥有1个FC、2个FC、3个FC和4个FC的FedCP引入的额外参数分别为0.527M(百万)、0.790M、1.052M和1.315M。然而,额外的FC层在每次迭代中引入的额外计算成本不值得那微小的准确率提升。对于归一化层,将LN替换为批归一化(BN)能使4层CNN的测试准确率提高0.64%。然而,对于同样包含BN层的ResNet-18,准确率却降低了约0.48%。与对整个 aia_iai 进行归一化的LN相似,GN分别对 ai,1a_{i,1}ai,1 和 ai,2a_{i,2}ai,2 进行归一化。然而,对于4层CNN和ResNet-18,在使用GN层时测试准确率都有所下降。对于激活函数,使用tanh只会增加4层CNN的准确率,而对于这两种主干网络,使用sigmoid都比使用ReLU提升了性能,因为属于 (0,1)(0, 1)(0,1) 的输出更适合用于输出策略。
D 超参数设置
我们使用网格搜索来寻找最佳的 λ\lambdaλ。具体来说,我们在以下搜索空间中执行网格搜索:
- λ\lambdaλ: 0, 0.1, 1, 5, 10
在本文中,对于4层CNN我们设定 λ=5\lambda = 5λ=5,对于ResNet-18和fastText,我们分别设定 λ=1\lambda = 1λ=1。
E 数据分布可视化
这里,我们在图像和文本任务中展示数据分布(包括训练和测试数据)的可视化。
[图7:在不同的 β\betaβ 下,实际设置中Tiny-ImageNet上所有客户端的数据分布。圆的大小代表样本的数量。]



[图8:在客户端数量分别为10、30、50和100的实际设置中,Cifar100上所有客户端的数据分布。]
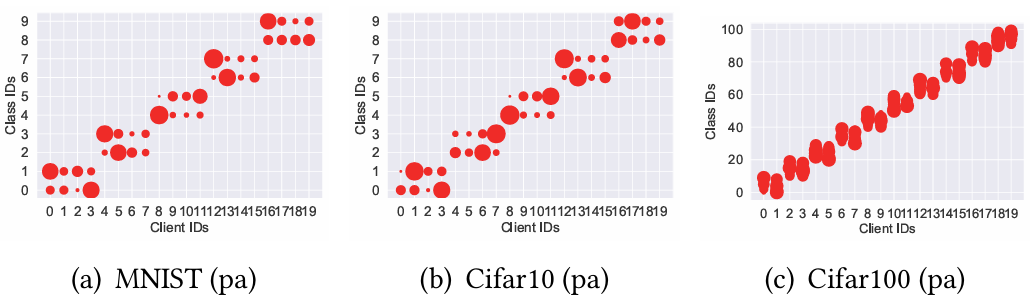
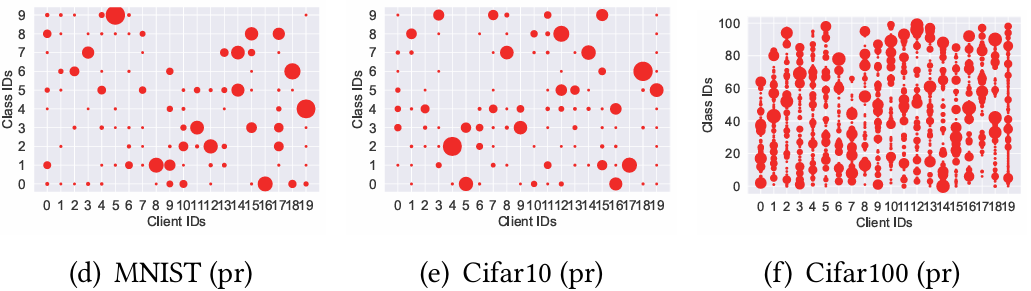
[图9:在病态(pa)设置和默认实际(pr)设置中所有客户端的数据分布。]
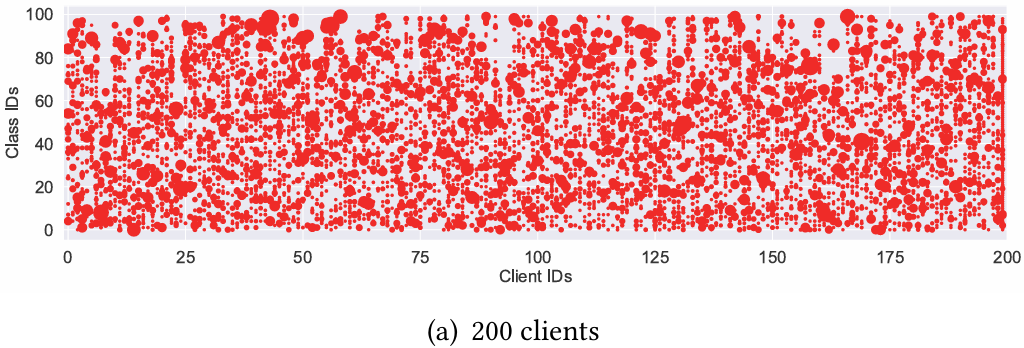
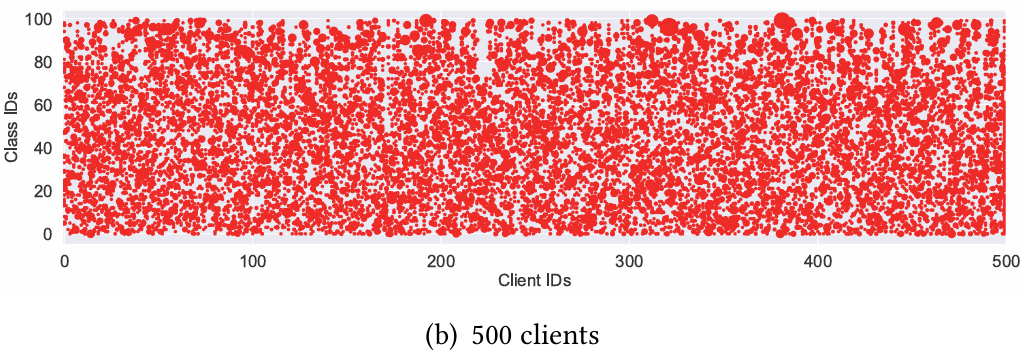
[图10:在默认实际设置下,包含200和500个客户端的Cifar100上所有客户端的数据分布。]
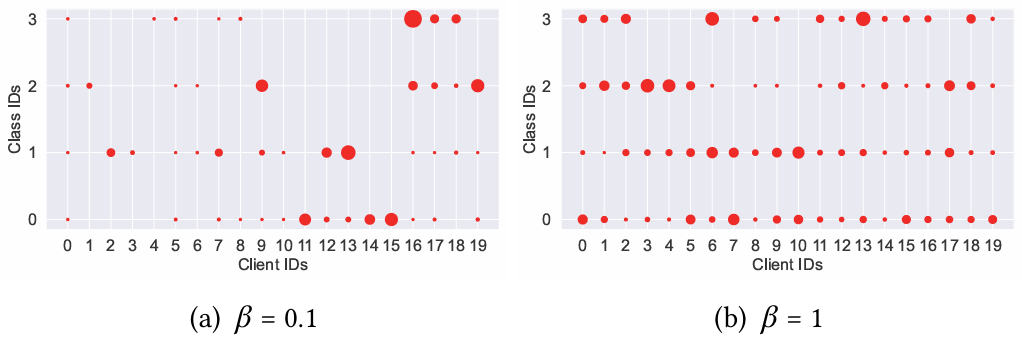
[图11:在两种异质设置下,AG News上所有客户端的数据分布。]

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 20
20 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)