从零开始写Qwen3(三)-KVCache
概述
在上一章中,我们搭建了一个Qwen3模型并且进行推理,但推理速度较慢,而且随着输出变长越来越慢,在GPU上还好,较短的输出还感受不出来,CPU上超过20个token就能明显感受到越来越慢
推理速度慢的速度后面后手写算子解决,现在先解决这个越来越慢的问题,按现在的速度完全无法生成长文
自回归过程
大部分大语言模型都基于自回归,根据之前的输入得到下一个词元的输出的分布,然后采样得到下一个词元,拼接得到下一个输入
x i ∼ f ( X i ∣ X 0 : i − 1 ) = F ( x 0 : i − 1 ) x_i \sim f(X_i | X_{0:i-1})=F(x_{0:i-1}) xi∼f(Xi∣X0:i−1)=F(x0:i−1)
如果 F F F 的计算复杂度和 x x x 的长度成正比,则整体的计算复杂度就是 O ( N 2 ) O(N^2) O(N2),当N较长时会导致耗时难以接受,更何况自注意力的计算是 O ( N 2 ) O(N^2) O(N2)的
但是如果 F ( [ x 0 : i − 1 , x i ] ) F([x_{0:i-1},x_i]) F([x0:i−1,xi])中所有 x j , j < i x_j,j<i xj,j<i 的计算都和 x i x_i xi 无关,此时就可以使用缓存
F ( [ x 0 : i − 1 , x i ] ) = F ( x i ∣ x 0 : i − 1 ) F([x_{0:i-1},x_i])=F(x_i|x_{0:i-1}) F([x0:i−1,xi])=F(xi∣x0:i−1)
其中所有由 x 0 : i − 1 x_{0:i-1} x0:i−1 产生的中间结果都缓存着,不用重算,只有由 x i x_i xi 产生的才新计算
因果遮罩
自回归模式可以用于推理,但不适用于训练,首先一开始的时候长度较短,训练就会有很大浪费,而且不同句子长度不同导致难以统一
训练时期已经有完整的句子了,可以将其利用起来,不是只取最后一个输出,而是每个输出都拿来利用,比如第i个位置的输出,可以认为是给定前i个输入的结果
但是这样隐藏着一个问题:预测第i个位置输出时是否可以看到i以后的数据,对于自回归方式输出来说是不行的,因为实际推理时是不知道后面的结果,只能一个个输出
为了和推理时期保持一致,同时保持高效训练,就出现了因果遮罩。因果遮罩就是要让i的输入只依赖i之前的数据,不能使用i之后的数据,具体来说就是应用在自注意力乘出来的那个自注意力权重,让它变成一个下三角矩阵,这样输出就只依赖之前的输入
A ∗ = [ Q 1 K 1 ⊤ / D − inf … − inf Q 2 K 1 ⊤ / D Q 2 K 2 ⊤ / D … − inf ⋮ ⋮ ⋱ ⋮ Q n K 1 ⊤ / D Q n K 2 ⊤ / D … Q n K n ⊤ / D ] \mathbf{A}^*= \begin{bmatrix} \mathbf{Q}_1 \mathbf{K}_1^\top /\sqrt{D}& -\inf & \dots & -\inf \\ \mathbf{Q}_2 \mathbf{K}_1^\top /\sqrt{D} & \mathbf{Q}_2 \mathbf{K}_2^\top /\sqrt{D} & \dots & -\inf\\ \vdots & \vdots & \ddots & \vdots \\ \mathbf{Q}_n \mathbf{K}_1^\top /\sqrt{D} & \mathbf{Q}_n \mathbf{K}_2^\top /\sqrt{D} & \dots & \mathbf{Q}_n\mathbf{K}_n^\top /\sqrt{D} \end{bmatrix} A∗= Q1K1⊤/DQ2K1⊤/D⋮QnK1⊤/D−infQ2K2⊤/D⋮QnK2⊤/D……⋱…−inf−inf⋮QnKn⊤/D
这样经过 softmax 后变成
A = [ 1 0 … 0 e A 21 ∗ / S 2 e A 22 ∗ / S 2 … 0 ⋮ ⋮ ⋱ ⋮ e A n 1 ∗ / S n e A n 2 ∗ / S n … e A n n ∗ / S n ] \mathbf{A}= \begin{bmatrix} 1 & 0 & \dots & 0 \\ e^{A^*_{21}}/S_2 & e^{A^*_{22}}/S_2 & \dots & 0\\ \vdots & \vdots & \ddots & \vdots \\ e^{A_{n1}^*}/S_n & e^{A_{n2}^*}/S_n & \dots & e^{A_{nn}^*}/S_n \end{bmatrix} A=
1eA21∗/S2⋮eAn1∗/Sn0eA22∗/S2⋮eAn2∗/Sn……⋱…00⋮eAnn∗/Sn
得到输出结果
O = [ 1 0 … 0 e A 21 ∗ / S 2 e A 22 ∗ / S 2 … 0 ⋮ ⋮ ⋱ ⋮ e A n 1 ∗ / S n e A n 2 ∗ / S n … e A n n ∗ / S n ] [ V 1 V 2 ⋮ V n ] = [ V 1 ( e A 21 ∗ V 2 + e A 22 ∗ V 2 ) / S 2 ⋮ ∑ i n e A n i ∗ V i / S n ] \mathbf{O}=\begin{bmatrix} 1 & 0 & \dots & 0 \\ e^{A^*_{21}}/S_2 & e^{A^*_{22}}/S_2 & \dots & 0\\ \vdots & \vdots & \ddots & \vdots \\ e^{A_{n1}^*}/S_n & e^{A_{n2}^*}/S_n & \dots & e^{A_{nn}^*}/S_n \end{bmatrix} \begin{bmatrix}V_1\\V_2\\\vdots\\V_n \end{bmatrix} = \begin{bmatrix} V_1 \\ (e^{A^*_{21}}V_2 +e^{A^*_{22}}V_2 )/S_2\\\vdots\\ \sum_i^n e^{A^*_{ni}}V_i /S_n \end{bmatrix} O=
1eA21∗/S2⋮eAn1∗/Sn0eA22∗/S2⋮eAn2∗/Sn……⋱…00⋮eAnn∗/Sn
V1V2⋮Vn
=
V1(eA21∗V2+eA22∗V2)/S2⋮∑ineAni∗Vi/Sn
KV缓存
实际上,上面的矩阵乘法可以分块
O = [ A : i − 1 , : i − 1 ∣ 0 A i , : i − 1 ∣ A i , i ] [ V : i − 1 V i ] = [ A : i − 1 , : i − 1 V : i − 1 A i , : V ] \mathbf{O}= \begin{bmatrix} \mathbf{A}_{:i-1,:i-1}& \vert & \mathbf{0} \\ \hline \mathbf{A}_{i,:i-1} &\vert & \mathbf{A}_{i,i} \end{bmatrix} \begin{bmatrix} \mathbf{V}_{:i-1}\\ \hline \mathbf{V}_i\end{bmatrix}= \begin{bmatrix} \mathbf{A}_{:i-1,:i-1}\mathbf{V}_{:i-1}\\ \hline \mathbf{A}_{i,:} \mathbf{V} \end{bmatrix} O=[A:i−1,:i−1Ai,:i−1∣∣0Ai,i][V:i−1Vi]=[A:i−1,:i−1V:i−1Ai,:V]
上半部分是和 Q i , K i , V i Q_i,K_i,V_i Qi,Ki,Vi完全无关的,可以直接缓存,实际上这个注意力矩阵都不用算了,只用算下半部分,这个下半部分的 i ≥ j i\ge j i≥j是恒成立的,连遮罩也不用做了
这样注意力从 O ( N 2 ) O(N^2) O(N2) 变成了 O ( N ) O(N) O(N),不过付出了 O ( N ) O(N) O(N) 的空间复杂度,从此大模型的瓶颈从计算耗时移到了KVCache的显存限制和读取显存的耗时
实现
在模型整体的输入中除了x外再增加一个context,里面包含一个KVCache类
在自注意力获取qkv的时候调用
def forward(self, x, context: ModelContext):
input_shape = x.shape[:-1]
hidden_shape = (*input_shape, -1, self.config.head_dim)
q = self.q_norm(self.q_proj(x).view(hidden_shape).transpose(1, 2))
k = self.k_norm(self.k_proj(x).view(hidden_shape).transpose(1, 2))
v = self.v_proj(x).view(hidden_shape).transpose(1, 2)
q = self.rope(q, context)
k = self.rope(k, context)
if context.use_cache:
k,v = context.kv_cache.update(k, v, self.layer_idx, context.cache_position)
o = (
self.gqa(q, k, v)
.transpose(1, 2)
.reshape(*input_shape, -1)
)
o = self.o_proj(o)
return o
此时整个模型只用输入最新的x,而不用整个传入历史数据,即这里的 x.shape[1]==1,q的长度也是1,但kv的长度需要是N,这也就是缓存为什么叫KV缓存,q不需要缓存,因为q总是最新的
最简单的KVCache就是推理开始时每层生成两个空的张量,然后不断拼接kv,但这样频繁拼接本身也是很耗时的,改进就是预分配,在启动时就分配最大长度的张量,然后每次写入和读取对应位置,但这样固定分配会造成空间浪费和内存碎片,vLLM的核心PageAttention就是解决这个问题的
预填充阶段
因为KV缓存,解码器模型的推理就分成了预填充和解码两个节点,用户第一次输入提示词到生成第一个响应的这个阶段就是预填充,从第一个词元开始解码阶段。
预填充阶段和解码有着这样的不同:
- 预填充的输入是一次性来一大堆,比如提示词可以很长,而解码一次产生一个
- 预填充一次就能拿到所有输入,而解码后面生成的数据依赖前面的数据
不管预填充还是解码,因果遮罩一直都是开启的,虽然解码阶段因果遮罩不用加
预填充的这个阶段是没有缓存可用的,必须计算整个 N 2 N^2 N2 ,如果提示词很长消耗时间还是很长,并且需要产生一个 N 2 N^2 N2 的注意力矩阵,这对显存也是很大压力。解决这个问题有几个方法:
- 前缀匹配缓存,如果之前输入了某段提示词,在另一个对话中又输入一遍,这段提示词的KV可以直接拿来用,即使不是完整匹配也不要紧,只匹配前缀就取前缀的缓存,只计算后面不同部分即可。不过这里需要注意,跨用户前缀缓存有隐私泄漏风险,需要小心
- 解决注意力矩阵巨大的问题,可以使用分块矩阵乘法,比如FlashAttention,可以让额外(注意力矩阵如果不输出则是中间的、额外的内存开支)内存开支从 O ( N 2 ) O(N^2) O(N2) 变成常数,不仅可以用于预填充,解码阶段也能使用
多轮对话场景
多轮对话时,每一轮对话都会把之前的所有输入和响应全部拼接到一起(可能过长,需要压缩),然后一起加到本轮输入前面,可以看 前一章中那个提示词模板,实际上多轮对话会合成一段提示词交给大模型的
如果时间间隔较短,上一轮的KV缓存还在,那只需要把用户新增的部分进行预填充,历史对话直接从缓存中读取;但如果间隔较长,比如时隔一个月继续上个话题,那服务器肯定不会接着缓存,只能重新算一遍
编码器模型
因果遮罩本来是训练时防止和推理时产生偏差而引入的手段,结果却成为了能大幅提升推理速度的根本原因,如果没有因果遮罩KVCache就无法成立,因为位置为i-1的o可能会因为位置为位置为i的新输入发生变化,每次推理原有的缓存都会更新,缓存就没有意义了
编码器模型就没有这个遮罩,它不仅可以看到前面的信息,还能看到后面的信息,比如BERT,B就是双向,E就是编码器。编码器无法利用KV缓存,但它并不需要,因为它拿到了所有信息,并不需要一个一个输出结果,而是一次推理输出全部结果,它主要用于输出不会作为新输入的情况,比如机器翻译、文本分类等
实验
实验报告
在GTX3060,WSL上执行 Qwen3-0.6B,用前一章实现的模型进行推理,结果如下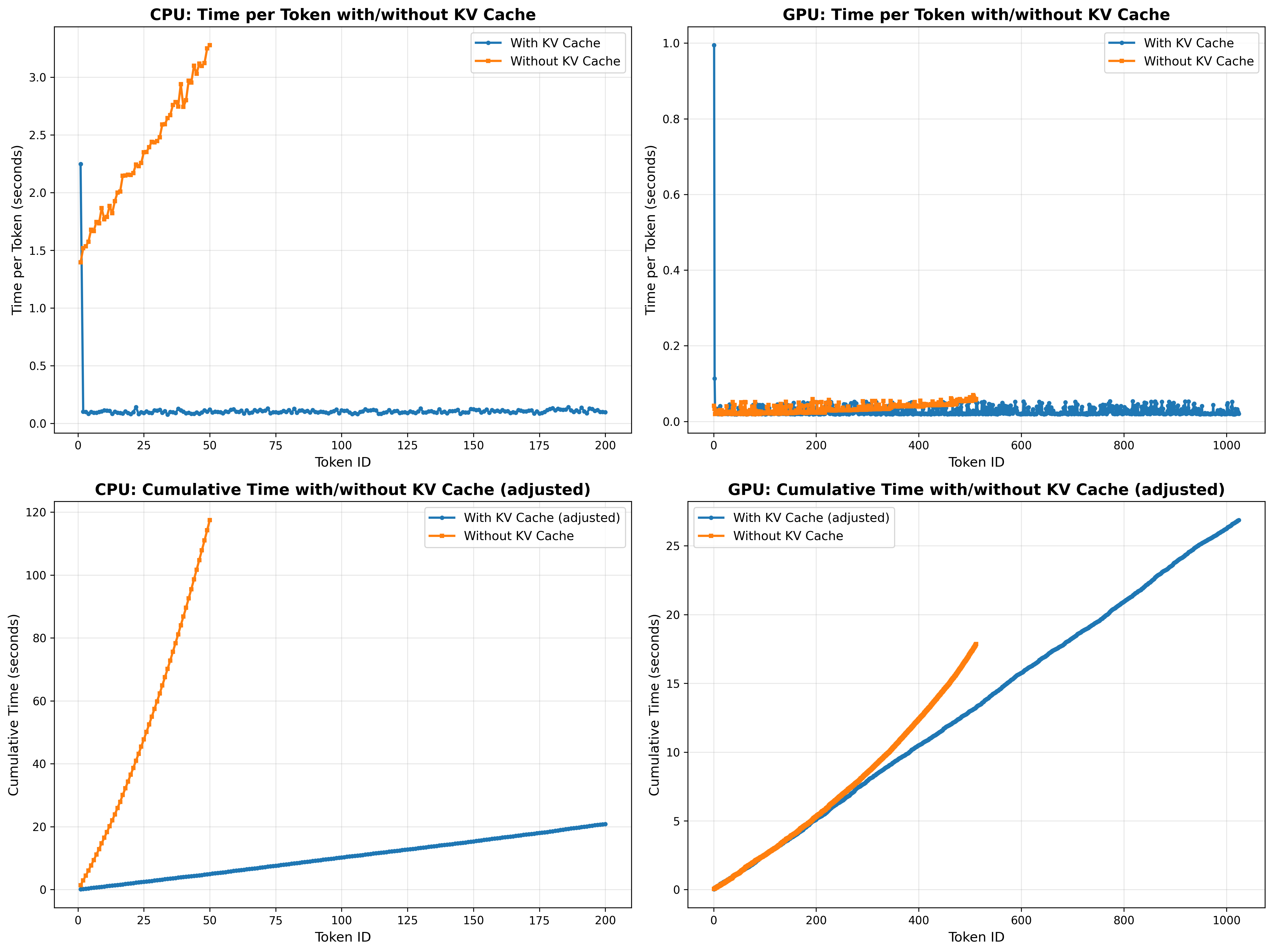
从图中看出,带有缓存的总耗时近乎线性,没有缓存的平均耗时随着长度增长而增长

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)