Qwen3-VL模型推理流程
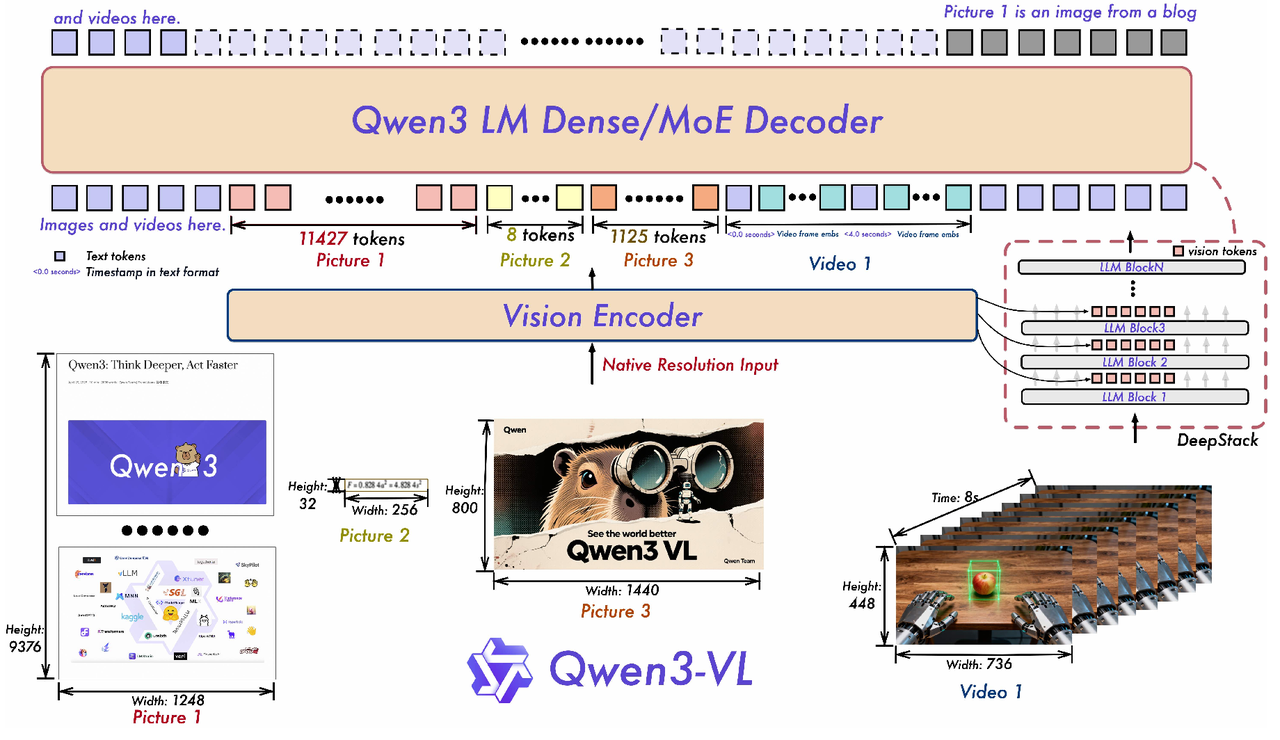
1. 数据预处理
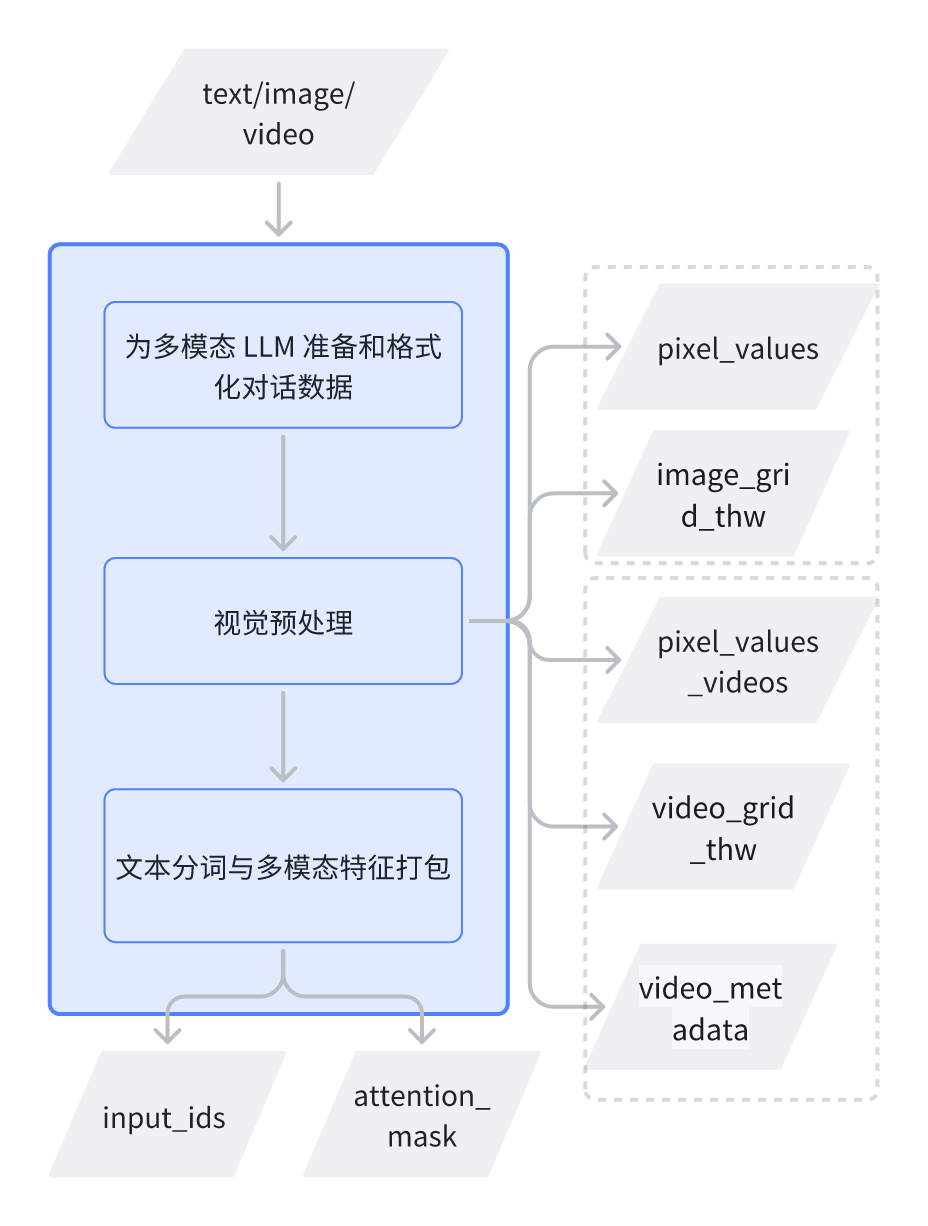
代码位置:transformers/processing_utils.py文件中apply_chat_template函数
1.1 为多模态 LLM 准备和格式化对话数据
首先遍历结构化的 conversations 列表,从每个消息中提取所有图像或视频的文件,并将其整理成输入列表;
然后将结构化对话(包含图像占位符 <|image_pad|> 等)根据预设模板,转换成模型可直接读取的、带有特殊标记的单行文本 Prompt,为下一步的特征提取和分词做准备。
将输入的message格式内容转换为prompt:
[‘<|im_start|>user\n<|vision_start|><|image_pad|><|vision_end|>Describe this image.
<|vision_start|><|video_pad|><|vision_end|><|im_end|>\n<|im_start|>assistant\n’]
1.2 视觉特征预处理
def __call__(self, images=None, text=None, videos=None, **kwargs):
# ...
# --- 图像处理 ---
if images is not None:
image_inputs = self.image_processor(images=images, ...)
image_grid_thw = image_inputs["image_grid_thw"]
else:
image_inputs = {}
image_grid_thw = None
# --- 视频处理 ---
if videos is not None:
videos_inputs = self.video_processor(videos=videos, ...)
video_grid_thw = videos_inputs["video_grid_thw"]
video_metadata = videos_inputs.pop("video_metadata") # 获取视频元数据
else:
videos_inputs = {}
video_grid_thw = None-
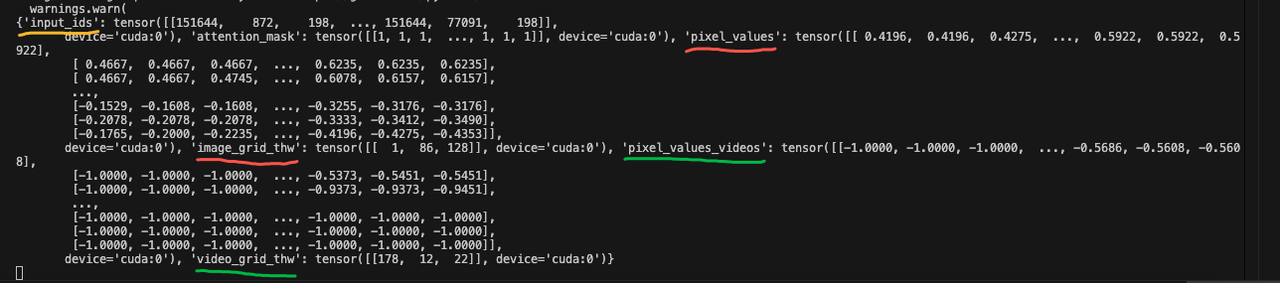
image_inputs和videos_inputs: 这两个字典里装着处理好的pixel_values等数据。
将原始图像转换为原始像素值(pixel_values)
-
image_grid_thw和video_grid_thw: 记录了每张图片/每个视频被切分成了多大的视觉patch网格(例如[[1, 42, 58]])。 -
video_metadata: 视频处理后返回的元数据,包含了采样帧的原始索引 (frames_indices) 和视频的原始帧率 (fps)。这是后续构建视频时间戳提示的关键。
图像预处理
smart_resize
将输入图片缩放至16的整数倍,保持宽高比不变。
分块
将缩放后的图片切割为 16×16 的固定大小的Patch。提取图像在“时间-高度-宽度”维度上 Patch 分布的几何元数据(grid_thw),为后续计算 Image Token 数量及进行文本占位符对齐提供了必要的空间结构信息。
| 图片分辨率 | 缩放后分辨率 | 分块数(16×16) | grid_thw shape=[1,3] |
| 512×512 | 512×512 | 32×32=1024 | [1,32,32] |
| 1024×768 | 1024×768 | 64×48=3072 | [1,64,48] |
| 2048×1024 | 2048×1024 | 128×64=8192 | [1,128,64] |
比如输入图像512*512 分为16*16 的patch 输出的grid_thw=[1, 32,32]
图像占位符扩展
计算特征合并后的视觉Token数
if image_grid_thw is not None:
merge_length = self.image_processor.merge_size**2 # merge_size=2 -> merge_length=4
index = 0
for i in range(len(text)):
while self.image_token in text[i]:
# 计算这张图片最终生成了多少个视觉令牌
num_image_tokens = image_grid_thw[index].prod() // merge_length
# 将一个 <|image_pad|> 替换成 N 个 <|placeholder|>
text[i] = text[i].replace(self.image_token, "<|placeholder|>" * num_image_tokens, 1)
index += 1
# 最后将所有 <|placeholder|> 统一换回 <|image_pad|>
text[i] = text[i].replace("<|placeholder|>", self.image_token)在视觉特征输入语言模型前,会进行空间特征合并(Merge)以压缩序列长度。合并倍率(merge_length)定义了相邻Patch的融合方式,例如将 merge_size × merge_size 个Patch合并为一个Token。
视觉Token数 = 视觉Patch总数 / (merge_size²)
示例:若
merge_size=2,则4个Patch合并为1个Token,9744个Patch最终得到9744/4 =2436个视觉Token。
原始对话文本中,图像位置由一个特殊标签(如 <|image_pad|>)占位。为了确保文本序列长度与视觉特征序列一致,将预处理序列中单个 <|image_pad|> 替换为与视觉Token数相同数量的连续标签,每个标签对应一个合并后的视觉Token。
例如,若视觉Token数为
2436,则文本中原本的<|image_pad|>被替换为2436个<|image_pad|>组成的序列。
最终:
一个 <|image_pad|> 被扩展成了一个复杂的结构,frame_seqlen 个 <|image_pad|>,为这一时间块的视觉信息预留位置
例如:
<|vision_start|>...<|image_pad|>...<|vision_end|>
<|vision_start|>...<|image_pad|>...<|vision_end|>...
视频预处理
视频采样阶段
指定总的帧数n_frames或者fps,从原始视频中均匀采样帧,计算出每个被采样的时间块在视频中的中心时间点。
-
根据 FPS 参数从原始视频中均匀采样帧
-
默认采样 2 FPS,受
min_frames=4和max_frames=768约束
视频的调整不针对帧数只针对分辨率,如果设置帧数过多,就会得到帧数很多但低清的图片。如果帧数不为偶数,会复制最后一帧,之后的切块和展平操作与图片是一样的。
每帧图像预处理
-
智能调整视频尺寸(smart_resize)
-
归一化和重塑为 patch 格式
视频占位符扩展
if video_grid_thw is not None:
# ...
for i in range(len(text)):
while self.video_token in text[i]:
metadata = video_metadata[i]
# ... (处理fps缺失的情况) ...
# 1. 计算每个采样帧的时间戳
curr_timestamp = self._calculate_timestamps(...)
video_placeholder = ""
# 2. 计算每一帧对应的视觉令牌数
frame_seqlen = video_grid_thw[index][1:].prod() // merge_length
# 3. 为视频的每一帧构建一个详细的文本描述
for frame_idx in range(video_grid_thw[index][0]): # 遍历时间维度
curr_time = curr_timestamp[frame_idx]
# 添加时间戳文本
video_placeholder += f"<{curr_time:.1f} seconds>"
# 添加帧的视觉令牌占位符,并用特殊口令包裹
video_placeholder += (
self.vision_start_token + "<|placeholder|>" * frame_seqlen + self.vision_end_token
)
# 4. 用构建好的详细描述替换原始的单个 <|video_pad|>
text[i] = text[i].replace(self.video_token, video_placeholder, 1)
index += 1
# 5. 统一换回最终的 <|video_pad|>
text[i] = text[i].replace("<|placeholder|>", self.video_token)构建详细的视频描述
这是一个循环操作,遍历grid_t 的数量构建一个文本片段。这个片段包含:
-
一个人类可读的时间戳,如 <1.5 seconds>。
-
frame_seqlen 个 <|placeholder|>,为这一时间块的视觉信息预留位置。
计算每帧令牌数:
frame_seqlen计算出视频的单个时间块会生成多少个视觉令牌。
-
用 <|vision_start|> 和 <|vision_end|> 将这些占位符包裹起来,明确标识这是一帧的范围。
替换
将原始文本中简单的 <|video_pad|> 替换为上面构建的、包含时间戳和大量占位符的复杂字符串。
最终替换
和图片处理一样,将所有 <|placeholder|> 换回 <|video_pad|>。
结果: 一个
<|video_pad|>被扩展成了一个复杂的结构 例如:
<0.2 seconds><|vision_start|>...<|video_pad|>...<|vision_end|>
<0.8 seconds><|vision_start|>...<|video_pad|>...<|vision_end|>...备注:这里图像和视频采用同样的处理方式,将图像复制一份,作为2帧的视频处理
这不仅为视频的每一帧预留了空间,还明确地将时间信息注入到了文本序列中,让模型能够理解视频的动态过程。
创新点:文本时间戳对齐机制
T-RoPE 升级,采用“时间戳-视频帧”交错输入形式,实现帧级别时间信息与视觉内容的细粒度对齐,提升视频事件定位精度。
Qwen3-VL 采用了一种更加直接和有效的方法:直接在输入中插入简单的文本标记(如 <3.8 seconds>)来表示视频帧的时间戳,而不是为每帧分配复杂的时间位置编码。
1.3 文本分词与多模态特征打包
经过上述复杂的重构后,tokenizer才真正开始工作,将这个包含了大量<|image_pad|>和<|video_pad|>的长字符串转换成input_ids。
该步骤调用分词器将包含大量图像占位符的文本字符串转换为数字形式的 Token ID 序列(如长度为 2436 的 input_ids)及对应的注意力掩码,随后进行特殊标记校验,最终将处理好的文本特征与视觉特征(image_inputs)合并,封装成模型可直接读取的对象。
输出
2. Qwen3-VL forward流程
类Qwen3VLModel(Qwen3VLPreTrainedModel)中forward代码
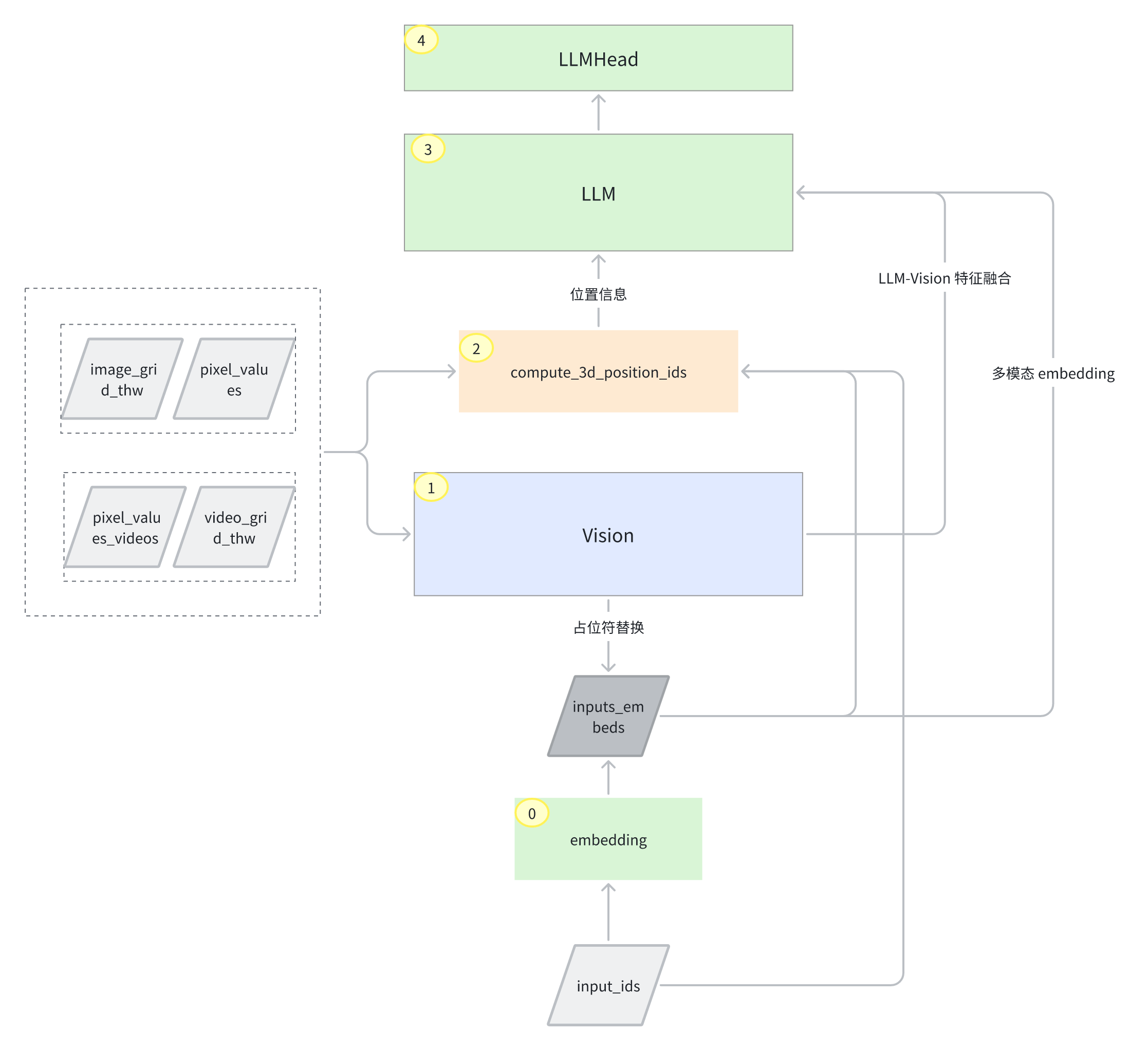
2.1 处理图像/视频输入
Qwen3-VL-2B 和4B,使用SigLIP2-Large (300M)。
1)Vision 视觉模型推理
绝对位置编码
fast_pos_embed_interpolate
pos_embeds = self.fast_pos_embed_interpolate(grid_thw)
hidden_states = hidden_states + pos_embedsfast_pos_embed_interpolate用于处理任意分辨率的输入。
视觉编码器内部维护一个可学习的绝对位置编码表 self.pos_embed,形状为 [num_base_patches, hidden_size]。
例如
Embedding(2304, 1152):2304 个位置对应一个基础网格(比如 48×48 的网格,因为 48×48=2304)每个位置编码维度为 1152(与隐藏层维度一致)。这个基础网格的大小与训练时使用的图像分辨率及 patch 尺寸相关。
-
对于任意输入图像,经过 patch 划分后得到新的网格尺寸
(h, w)(可能加上时间维t,总块数 =t * h * w)。此时需要为这t * h * w个 patch 生成位置编码,但直接索引固定表(大小 2304)是不可行的,因为h * w可能不等于 48×48。fast_pos_embed_interpolate通过双线性插值映射实现动态适配 -
对于视频或多帧输入(
t > 1),不同帧的空间位置编码是相同的(即每一帧共享同一个空间网格的编码)。因此,只需将插值得到的h × w个空间位置编码沿时间维度复制t次,即可得到总块数为t * h * w的完整位置编码序列。
旋转位置编码 (RoPE)
rot_pos_emb
position_embeddings是一个元组(cos_tensor, sin_tensor),它将被传递给每一个 Transformer Block。
rotary_pos_emb = self.rot_pos_emb(grid_thw)
seq_len, _ = hidden_states.size()
hidden_states = hidden_states.reshape(seq_len, -1)
rotary_pos_emb = rotary_pos_emb.reshape(seq_len, -1)
emb = torch.cat((rotary_pos_emb, rotary_pos_emb), dim=-1)
position_embeddings = (emb.cos(), emb.sin())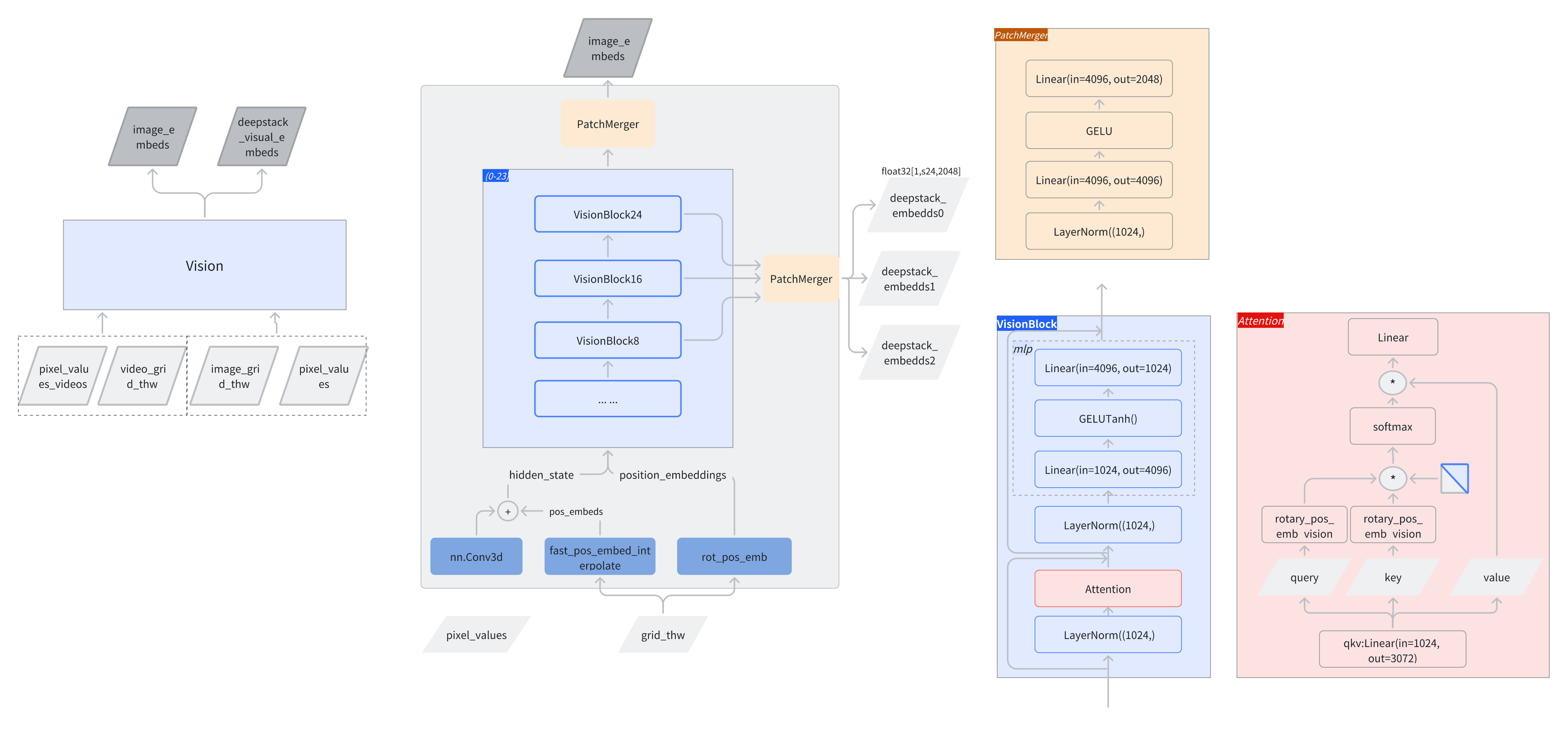
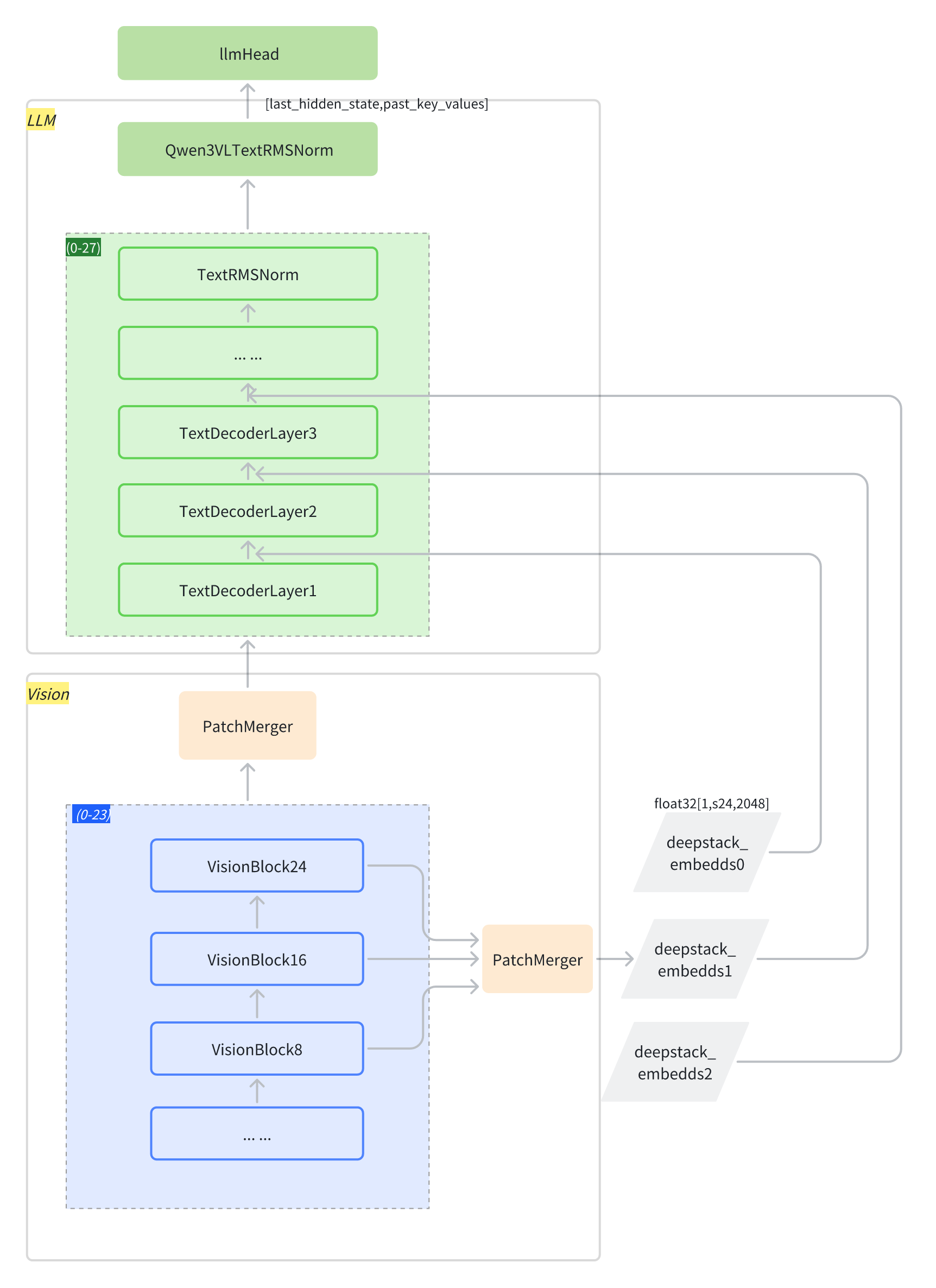
self.deepstack_merger_list和self.merger里使用的参数有一点区别
| 模块 | 归一化策略 | 适用场景 |
| deepstack_merger_list | 后归一化 (post-shuffle) | 融合不同层级的特征,保留跨层相关性 |
| merger | 前归一化 (pre-shuffle) | 合并同一层级的空间特征,保持每个 patch 的独立统计特性 |
至此,视觉部分的前向计算结束,输出是[token_num, 4096]的视觉特征hidden_states,和三个中间层特征组成的列表deepstack_feature_lists
2)占位符替换
def get_placeholder_mask(
self,
input_ids: torch.LongTensor,
inputs_embeds: torch.FloatTensor,
image_features: torch.FloatTensor | None = None,
video_features: torch.FloatTensor | None = None,):-
input_ids: 输入的 token ID 序列,形状为
(batch_size, seq_len)。 -
inputs_embeds: 输入的嵌入向量序列,形状为
(batch_size, seq_len, hidden_size),通常由input_ids经过词嵌入层得到,但可能在后续被修改(例如已部分替换为视觉特征)。 -
image_features / video_features: 由视觉编码器提取的图像或视频特征,形状通常为
(num_image_tokens, hidden_size)或(num_video_tokens, hidden_size)。这些特征将被插入到占位符位置。 -
2.2计算 3D 位置 ID
compute_3d_position_ids中函数get_rope_index
这里与Qwen2-VL的不同之处在于,每个视频帧在位置编码中被视为独立的"图像",时间维度固定为0,这是由于在是预处理的时候在文本里引入了显式的时间戳,因此不需要处理动态变化的时间维度。
get_rope_index 函数会为这个序列生成如下的3D位置ID (t, h, w):
| Token | 类型 | 逻辑位置 | get_rope_index 生成的3D位置ID (t, h, w) | 解释 |
| 请 | 文本 | 0 | (0, 0, 0) | 文本token,线性递增,三维相同 |
| 观看 | 文本 | 1 | (1, 1, 1) | |
| 视频 | 文本 | 2 | (2, 2, 2) | |
| <0.2 seconds> | 文本 | 3 | (3, 3, 3) | 时间戳被视为普通文本token |
| <vision_start> | 文本 | 4 | (4, 4, 4) | |
| (f1_0,0) | 视频帧1 | (0,0) | (5, 5, 5) | 帧1的基准偏移量为5。 t_index=0, h_index=0, w_index=0。 0+5=5 |
| (f1_0,1) | 视频帧1 | (0,1) | (5, 5, 6) | t_index=0, h_index=0, w_index=1。 t,h不变,w递增。w坐标为1+5=6 |
| <vision_end> | 文本 | 7 | (7, 7, 7) | 文本token,继续线性递增 |
| <0.8 seconds> | 文本 | 8 | (8, 8, 8) | |
| <vision_start> | 文本 | 9 | (9, 9, 9) | |
| (f2_0,0) | 视频帧2 | (0,0) | (10,10, 10) | 帧2的基准偏移量为10。 t_index=0, h_index=0, w_index=0。 0+10=10 |
| (f2_0,1) | 视频帧2 | (0,1) | (10, 10, 11) | t_index=0, h_index=0, w_index=1。 t,h不变,w递增。w坐标为1+10=11 |
| <vision_end> | 文本 | 12 | (12, 12, 12) | 文本token,继续线性递增 |
| 结束 | 文本 | 13 | (13, 13, 13) |
至此,我们得到了一个混合序列 hidden_states。这个序列中的每一个元素都是一个向量,它可能代表一个单词,也可能代表图像或视频的一个局部区域,它们在同一个向量空间中。
2.3 LLM模型推理
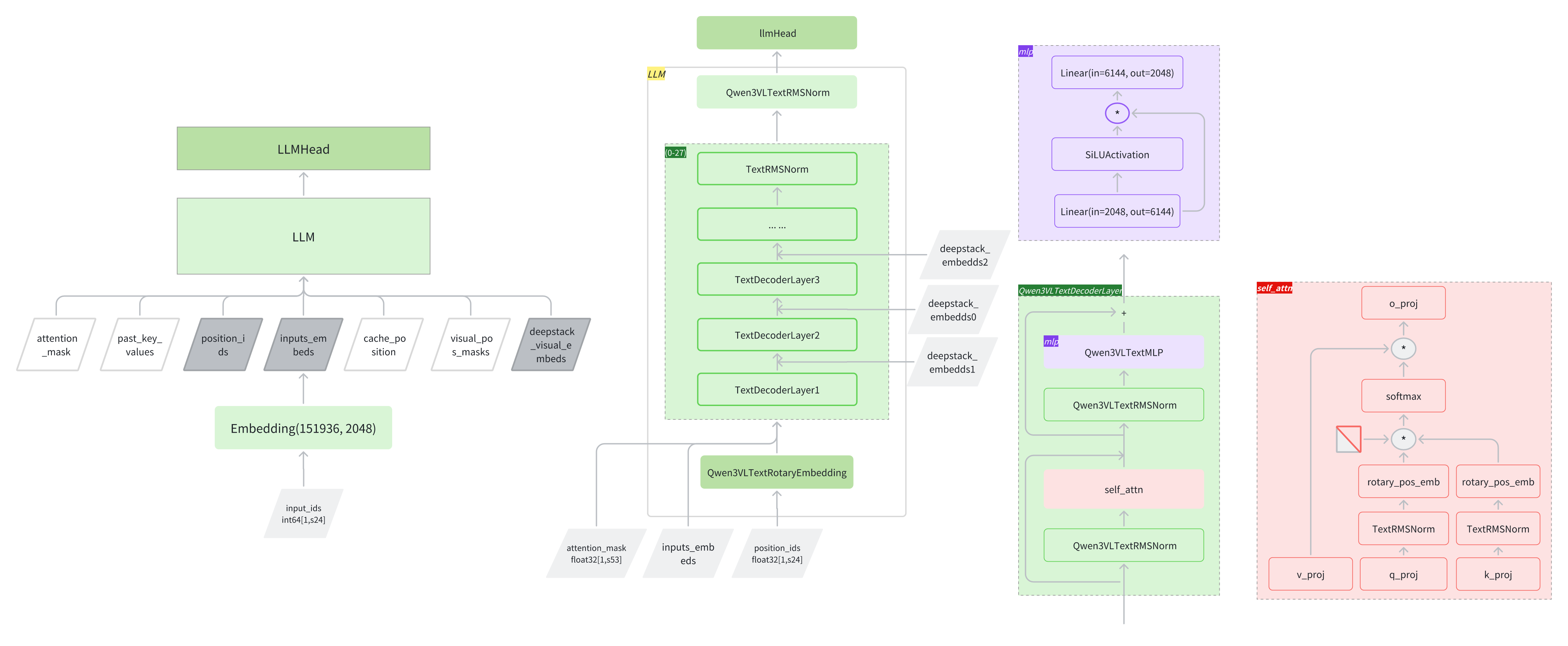
增强型交错的MRoPE
Qwen3VLTextRotaryEmbedding
创新点——MRoPE-Interleave。
原始MRoPE将特征维度按照时间(t)、高度(h)和宽度(w)的顺序分块划分,使得时间信息全部分布在高频维度上。我们在 Qwen3-VL 中采取了 t,h,w 交错分布的形式,实现对时间,高度和宽度的全频率覆盖,这样更加鲁棒的位置编码能够保证模型在图片理解能力相当的情况下,提升对长视频的理解能力;
关键的创新在apply_interleaved_mrope方法:
def apply_interleaved_mrope(self, freqs, mrope_section):
"""将3D旋转位置编码从分块布局[TTT...HHH...WWW]重组为交错布局[THTHWHTHW...TT]"""
freqs_t = freqs[0] # 以时间维度为基础
for dim, offset in enumerate((1, 2), start=1): # 处理H和W维度
length = mrope_section[dim] * 3
idx = slice(offset, length, 3) # 交错索引
freqs_t[..., idx] = freqs[dim, ..., idx] # 将H和W维度的频率交错插入
return freqs_t改进位置编码,采用时间(t)、高度(h)、宽度(w)交错分布形式,提升对长视频的理解能力。
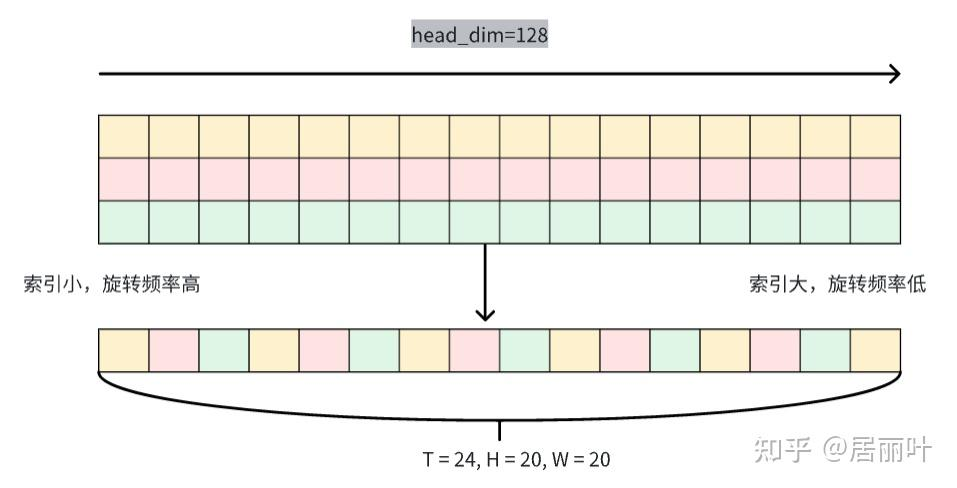
上图中黄、粉、绿分别表示T、H、W维度,T=24,H和W=20,1:4缩小,所以最后会有一个单独的时间块。
3. 模型结构
基于 MLP 的视觉-语言融合模块
创新点:将视觉特征注入 LLM 的多层中,实现更精细化的视觉理解和图文对齐精度。
Qwen3-VL 借鉴 DeepStack 的思路,将视觉 token 注入到 LLM 的多个层级中。与原始 DeepStack 方法(堆叠来自多尺度视觉输入的 token)不同,Qwen3-VL 扩展了 DeepStack,使其能够从 Vision Transformer的中间层提取视觉 token。这种设计保留了从低级到高级表示的丰富视觉信息。
具体而言,Qwen3-VL 从视觉编码器的三个不同层级选取特征。随后,专用的视觉-语言融合模块将这些多级特征投影为视觉 token,并将其直接添加到 LLM 前三层对应的隐藏状态中。
额外增加DeepStack,把vision encoder中,8、16、24三层的特征,插入到LLM中
4. 模型结构
--- 主要模块参数量对比 ---
视觉编码器 (ViT) 406.96 M
Merger 模块 (总和) 100.71 M
语言模型 (不含lm_head) 1.41 B
语言模型输出层 (lm_head) 311.16 M
语言模型 (总和) 2.03 BQwen3VLForConditionalGeneration(
(model): Qwen3VLModel(
(visual): Qwen3VLVisionModel(
(patch_embed): Qwen3VLVisionPatchEmbed(
(proj): Conv3d(3, 1024, kernel_size=(2, 16, 16), stride=(2, 16, 16))
)
(pos_embed): Embedding(2304, 1024)
(rotary_pos_emb): Qwen3VLVisionRotaryEmbedding()
(blocks): ModuleList(
(0-23): 24 x Qwen3VLVisionBlock(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Qwen3VLVisionAttention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
)
(mlp): Qwen3VLVisionMLP(
(linear_fc1): Linear(in_features=1024, out_features=4096, bias=True)
(linear_fc2): Linear(in_features=4096, out_features=1024, bias=True)
(act_fn): GELUTanh()
)
)
)
(merger): Qwen3VLVisionPatchMerger(
(norm): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(linear_fc1): Linear(in_features=4096, out_features=4096, bias=True)
(act_fn): GELU(approximate='none')
(linear_fc2): Linear(in_features=4096, out_features=2048, bias=True)
)
(deepstack_merger_list): ModuleList(
(0-2): 3 x Qwen3VLVisionPatchMerger(
(norm): LayerNorm((4096,), eps=1e-06, elementwise_affine=True)
(linear_fc1): Linear(in_features=4096, out_features=4096, bias=True)
(act_fn): GELU(approximate='none')
(linear_fc2): Linear(in_features=4096, out_features=2048, bias=True)
)
)
)
(language_model): Qwen3VLTextModel(
(embed_tokens): Embedding(151936, 2048)
(layers): ModuleList(
(0-27): 28 x Qwen3VLTextDecoderLayer(
(self_attn): Qwen3VLTextAttention(
(q_proj): Linear(in_features=2048, out_features=2048, bias=False)
(k_proj): Linear(in_features=2048, out_features=1024, bias=False)
(v_proj): Linear(in_features=2048, out_features=1024, bias=False)
(o_proj): Linear(in_features=2048, out_features=2048, bias=False)
(q_norm): Qwen3VLTextRMSNorm((128,), eps=1e-06)
(k_norm): Qwen3VLTextRMSNorm((128,), eps=1e-06)
)
(mlp): Qwen3VLTextMLP(
(gate_proj): Linear(in_features=2048, out_features=6144, bias=False)
(up_proj): Linear(in_features=2048, out_features=6144, bias=False)
(down_proj): Linear(in_features=6144, out_features=2048, bias=False)
(act_fn): SiLUActivation()
)
(input_layernorm): Qwen3VLTextRMSNorm((2048,), eps=1e-06)
(post_attention_layernorm): Qwen3VLTextRMSNorm((2048,), eps=1e-06)
)
)
(norm): Qwen3VLTextRMSNorm((2048,), eps=1e-06)
(rotary_emb): Qwen3VLTextRotaryEmbedding()
)
)
(lm_head): Linear(in_features=2048, out_features=151936, bias=False)
)5. 相关技术
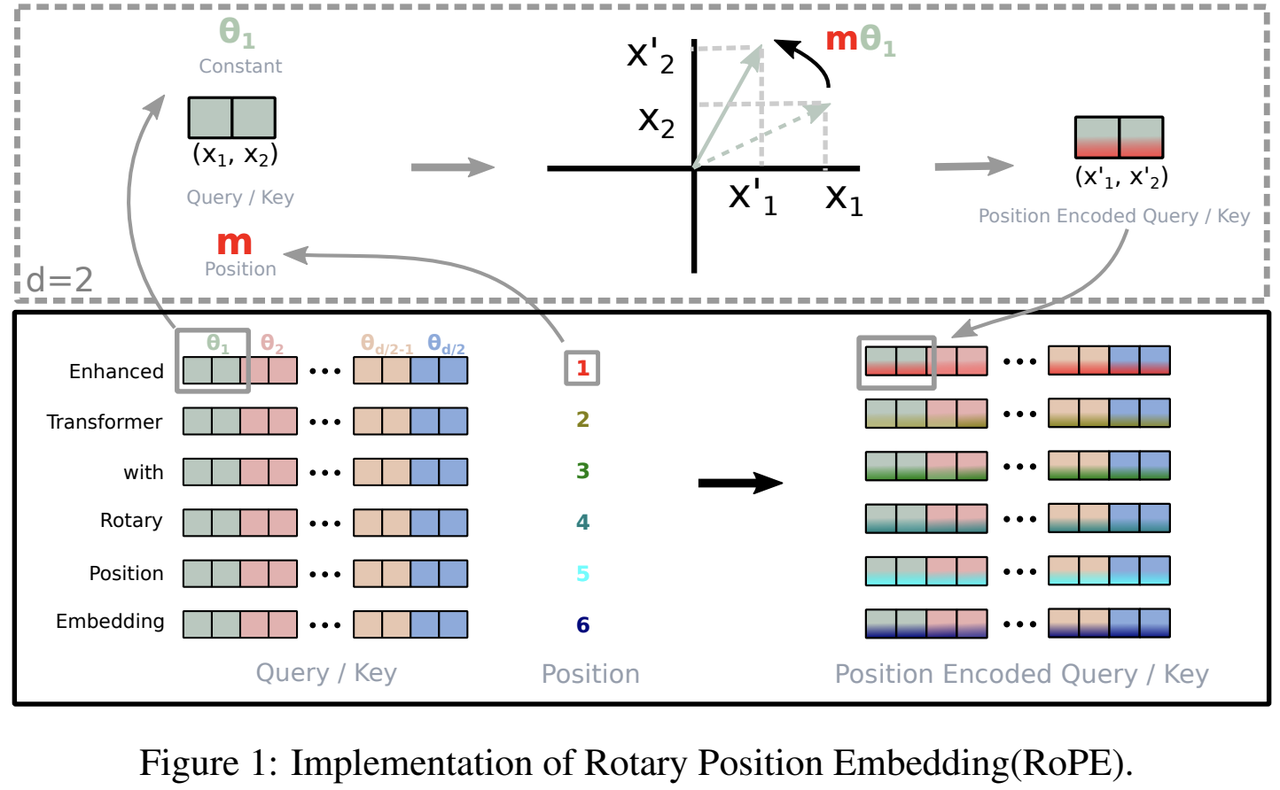
ROPE
通过旋转矩阵对一维嵌入向量进行旋转,使得旋转后的向量在计算点积时,能够自然地反映出词与词之间的相对位置关系。
MRoPE
Qwen2-VL 引入了 MRoPE 用于对多模态输入的位置信息进行建模。在其原始公式中,向量维度被划分为temporal, height, and width,每个维度被分配了不同的旋转频率。
这种划分导致了频谱不平衡,随后的研究表明这会降低模型在长视频理解基准上的性能。

-
文本这个3个维度采用同样的position_ids;
-
图像处理:时间维度ids是不变的,HW维度是不同的;
-
Video处理:时间维度ids是增加的,HW维度也是不同的;
-
不同模态的位置编码初始化:前一个模态的最大position_id + 1;
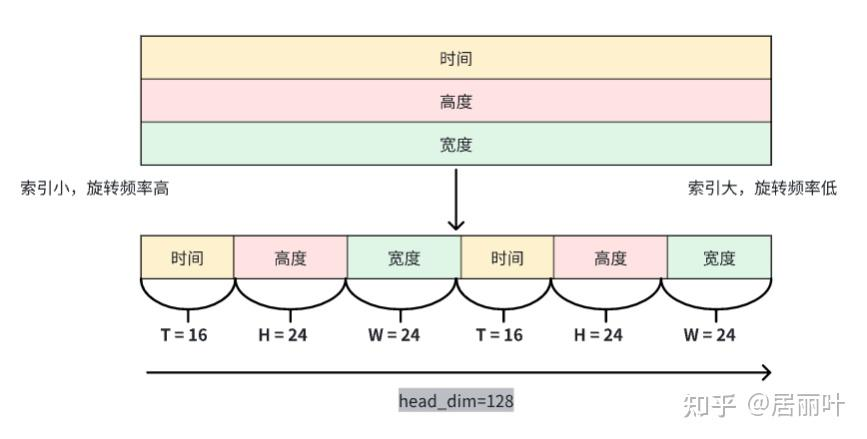
即RoPE中,表示索引,由于旋转频率随着索引增加而降低,MRoPE会导致时间维度的信息全部在高频维度上,不利于长序列的理解,会导致注意力随着时间快速衰减。
DeepStack
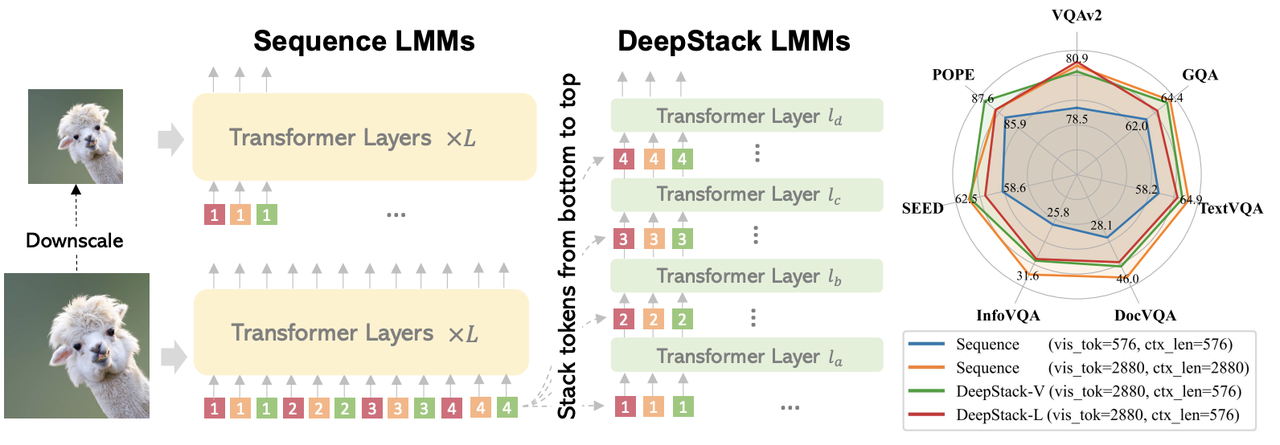
左图:传统大型多模态模型(LMMs)将所有视觉token串联成序列,用于高分辨率和低分辨率图像。
中图:论文的DeepStack LMMs将token堆叠成网格,并从下至上(11个)将其注入到第一层和中间的Transformer层中,仅使用残差连接。无需架构修改和增加上下文长度,论文的模型就能处理多倍于输入的视觉token。
右图:论文将DeepStack分别应用于Vicuna-7B(DeepStack-L)和CLIP ViT-L(DeepStack-V)。论文的模型能够处理4倍多的视觉token,并在广泛的基准测试中显著超越具有相同上下文长度的序列LMM,甚至与使用更长上下文的模型相媲美
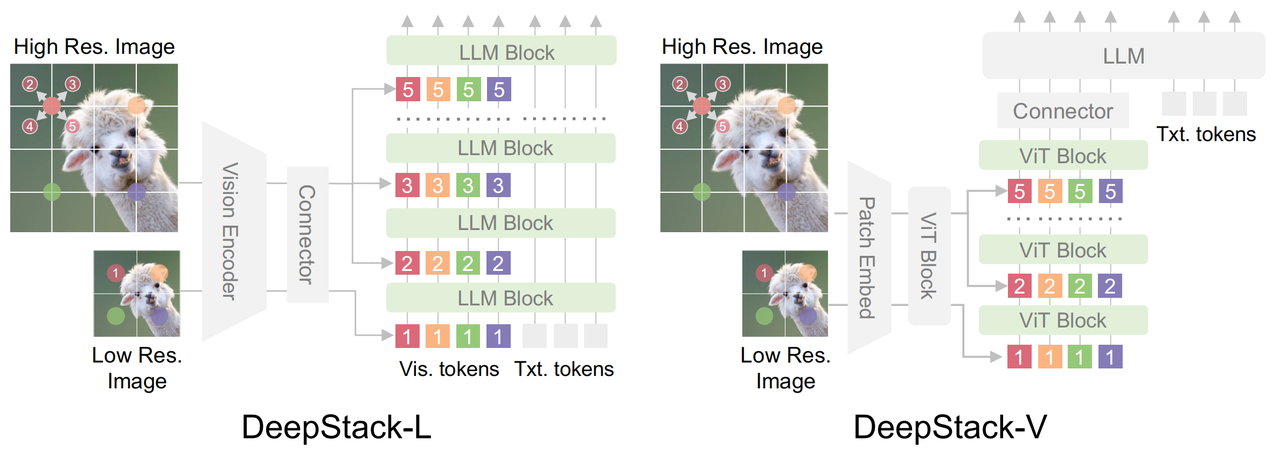
DeepStack的架构。其主要创新在于DeepStack策略,该策略将视觉token注入到不同层中。
左图:针对LLMs的DeepStack。给定一个输入图像,论文将从低分辨率版本提取的token馈送到LLM的输入层。考虑到图像的二维特性,论文从高分辨率版本提取邻域,并将其重新组织成DeepStack,然后将其馈送到LLMs的后续层。
右图:针对ViTs的DeepStack。论文采用类似的采样策略,但将视觉token馈送到视觉编码器的ViT层。
参考链接

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)