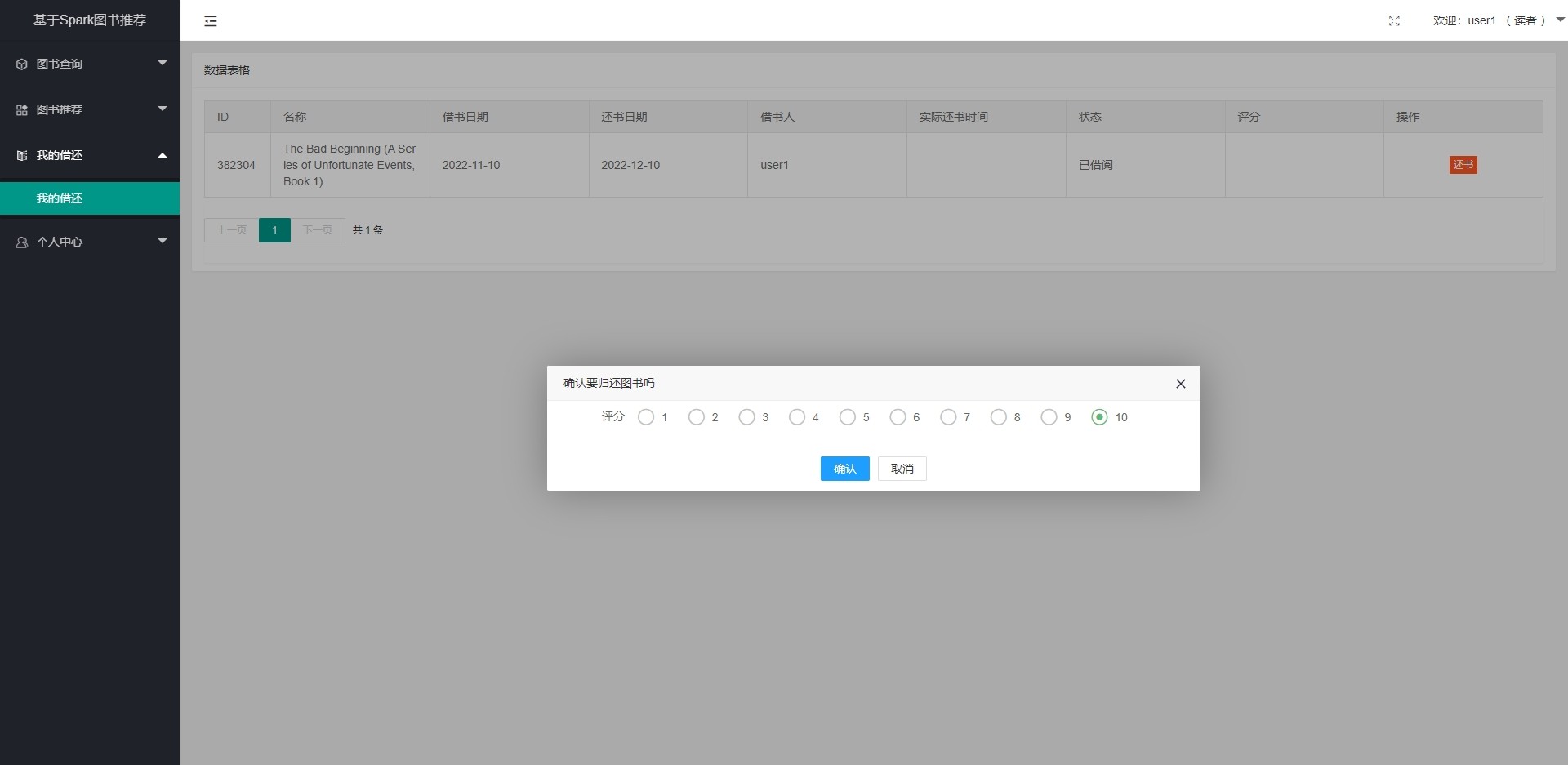
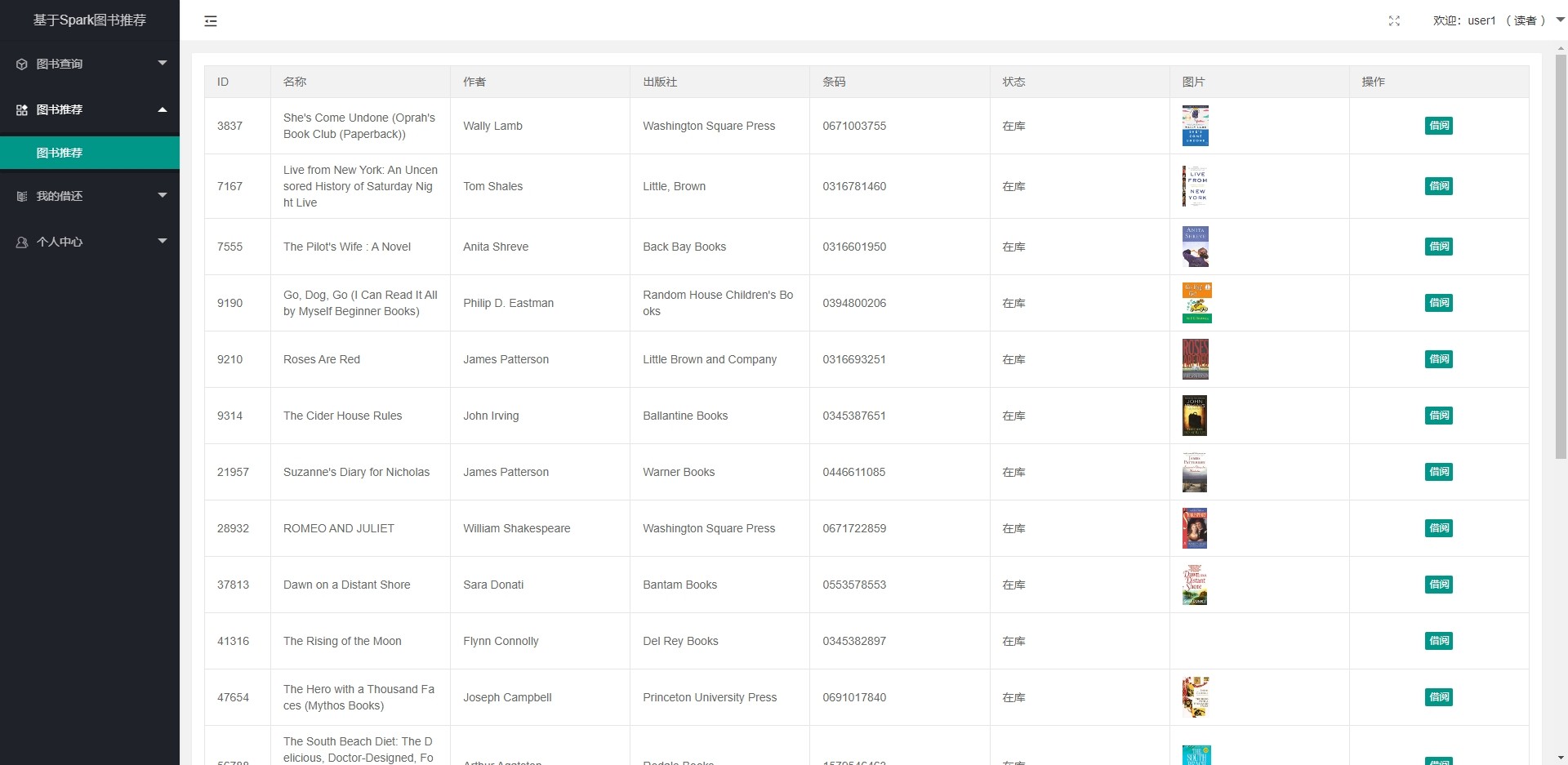
基于spark的图书推荐系统 基于大数据的图书推荐 基于模型的协同过滤图书推荐系统 矩阵分解 ...
基于spark的图书推荐系统 基于大数据的图书推荐 基于模型的协同过滤图书推荐系统 矩阵分解 ALS推荐(最小二乘法) 数据源:BookCrossing (BX) 数据集由 Cai-Nicolas Ziegler 在 Humankind Systems 首席技术官 Ron Hornbaker 的善意许可下从 Book-Crossing 社区进行为期 4 周的爬行(2004 年 8 月 / 9 月)收集。 它包含 278,858 名用户(匿名但具有人口统计信息),对 271,379 本书提供 1,149,780 个评分(显式/隐式)。 推荐流程: (1)数据清洗:过滤重复的数据,比如同个书编的书籍信息,评分为0分的不合理信息,将清洗后的数据保存到mysql数据库中 (2)模型训练:从mysql数据库中读取评分数据,通过spark构建模型后填充数据进行模型训练,模型训练后可以保存模型到本地,当有新数据时再重新训练,这个过程可以用采用本地启动spark进行运算也可以将任务提交到spark集群上运算(前提时已搭建好spark集群) (3)数据推荐:为每个用户推荐20本书,并将推荐结果保存到数据库中 (4)通过springboot搭建一个图书借阅系统展示数据,当新用户在平台借书后归还图书则会增加数据集,触发计算则会有新的推荐结果。
当图书推荐系统撞上Spark:从数据清洗到实时推荐的全栈实战
最近在折腾图书推荐系统,发现BookCrossing数据集真是个宝藏——27万用户、百万级评分量级,足够让推荐算法喝一壶了。不过原始数据就像没分类的图书馆,得先来个大扫除:
import pandas as pd
from sqlalchemy import create_engine
raw_data = pd.read_csv('BX-Book-Ratings.csv', encoding='latin1')
# 过滤零分评价(可能存在误操作)
cleaned = raw_data[raw_data['Book-Rating'] > 0]
# ISBN去重(同一本书可能有多个版本)
cleaned = cleaned.drop_duplicates(subset=['ISBN'], keep='first')
# 写入MySQL
engine = create_engine('mysql+pymysql://user:pass@localhost/book_rec')
cleaned.to_sql('clean_ratings', engine, if_exists='replace', index=False)这里有个坑:BookCrossing的ISBN字段居然存在非标准编码,得用正则过滤^[0-9X-]{13}$才能避免后续计算翻车。处理完数据后,Spark该上场表演了。
让评分数据飞一会儿
Spark MLlib的ALS(交替最小二乘法)是处理隐式反馈的利器,但参数调优得像煮拉面一样讲究火候:
val ratings = spark.read.format("jdbc")
.option("url", "jdbc:mysql://localhost/book_rec")
.option("dbtable", "clean_ratings")
.load()
.select($"User-ID", $"ISBN", $"Book-Rating".cast("float"))
// 冷启动处理:给新用户塞热门书
val als = new ALS()
.setRank(50) // 潜在因子维度
.setMaxIter(15) // 别超过20,边际效应明显
.setRegParam(0.01) // 正则化防止过拟合
.setColdStartStrategy("drop")
.setNonnegative(true)
val model = als.fit(ratings)
model.save("hdfs:///models/book_als")这里rank参数就像相机的ISO值——太小捕捉不到特征,太大会让计算量爆炸。实践中可以先用model.recommendForAllUsers(20)试推,观察推荐多样性再调整。
基于spark的图书推荐系统 基于大数据的图书推荐 基于模型的协同过滤图书推荐系统 矩阵分解 ALS推荐(最小二乘法) 数据源:BookCrossing (BX) 数据集由 Cai-Nicolas Ziegler 在 Humankind Systems 首席技术官 Ron Hornbaker 的善意许可下从 Book-Crossing 社区进行为期 4 周的爬行(2004 年 8 月 / 9 月)收集。 它包含 278,858 名用户(匿名但具有人口统计信息),对 271,379 本书提供 1,149,780 个评分(显式/隐式)。 推荐流程: (1)数据清洗:过滤重复的数据,比如同个书编的书籍信息,评分为0分的不合理信息,将清洗后的数据保存到mysql数据库中 (2)模型训练:从mysql数据库中读取评分数据,通过spark构建模型后填充数据进行模型训练,模型训练后可以保存模型到本地,当有新数据时再重新训练,这个过程可以用采用本地启动spark进行运算也可以将任务提交到spark集群上运算(前提时已搭建好spark集群) (3)数据推荐:为每个用户推荐20本书,并将推荐结果保存到数据库中 (4)通过springboot搭建一个图书借阅系统展示数据,当新用户在平台借书后归还图书则会增加数据集,触发计算则会有新的推荐结果。
推荐结果落地实战

生成推荐列表后,得考虑存储效率。用MySQL的JSON字段存推荐书单,比传统关系表节省70%空间:
// Spark写入推荐结果
val recommendations = model.recommendForAllUsers(20)
.select($"User-ID",
to_json($"recommendations").alias("recommended_books"))
recommendations.write
.format("jdbc")
.option("url", "jdbc:mysql://localhost/book_rec")
.option("dbtable", "user_recommendations")
.mode("overwrite")
.save()当SpringBoot遇见推荐更新
前端用SpringBoot搭个借阅系统,重点在于触发机制设计——新用户借阅3本书后立即触发ALS增量训练:
// 借阅事件监听器
@EventListener
public void handleBorrowEvent(BorrowEvent event) {
userService.checkBorrowCount(event.getUserId());
if(shouldRetrain()) {
sparkLauncher.submit(new ALSRetrainTask());
}
}
// 增量训练技巧:合并新旧评分
spark.sql("CREATE TEMP VIEW merged_ratings AS
SELECT * FROM mysql_ratings
UNION ALL
SELECT * FROM new_ratings")这套系统最爽的点在于:用户还书时看到的推荐书单已经根据TA的借阅记录动态更新。不过要小心集群资源分配——曾经因为没设executor内存上限,训练任务直接把Spark集群搞OOM了...
最后留个思考题:当用户对《三体》的评分同时出现在科幻类和哲学类时,潜在因子要怎么解释?或许这就是推荐系统的魅力——算法黑盒里藏着无数个星辰宇宙。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 0
0 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)