探索GAPSO - CNN - BiLSTM:超越传统预测的新高度
GAPSO-CNN-BiLSTM,遗传粒子群优化算法来优化CNN-BiLSTM网络做预测,预测精度高于普通的PSO-BiLSTM。 这里把遗传算法跟粒子群优化算法结合,指的不是用遗传算法来优化PSO的参数,而是解决PSO的容易收敛到局部最优点的问题。
在数据预测的广袤领域中,模型的优化与创新始终是提升预测精度的关键。今天,咱们就来唠唠GAPSO - CNN - BiLSTM这个颇具潜力的组合,看看它是如何在预测任务中崭露头角,超越普通的PSO - BiLSTM的。
遗传粒子群优化算法(GAPSO)的奥秘
大家都知道,粒子群优化算法(PSO)虽然简单高效,但它有个令人头疼的毛病——容易收敛到局部最优点。就好比一群探险家,在寻找宝藏的过程中,很容易被眼前的小财宝吸引,而错过更珍贵的宝藏。而遗传算法,有着优秀的全局搜索能力,就像拥有更广阔视野的探险家,能在更大范围内寻找宝藏。
将两者结合,不是简单地用遗传算法来优化PSO的参数,而是为了解决PSO容易陷入局部最优的困境。具体咋做呢?遗传算法中的选择、交叉和变异操作就派上用场啦。选择操作就像是在一群“探险家”中挑选出更有潜力的,让他们有更多机会去“探索”;交叉操作则是让这些优秀的“探险家”互相交流经验,产生新的思路;变异操作则是偶尔给“探险家”来点意外之喜,让他们去探索一些原本没考虑到的地方。
CNN - BiLSTM网络基础
先看看CNN(卷积神经网络),它在处理图像、时间序列等数据时有着得天独厚的优势。CNN通过卷积层的卷积核在数据上滑动,提取数据的局部特征,就像是拿着放大镜,一点点地观察数据中的重要信息。比如在处理时间序列数据时,代码示例如下:
import tensorflow as tf
model = tf.keras.Sequential()
model.add(tf.keras.layers.Conv1D(filters = 32, kernel_size = 3, activation='relu', input_shape=(time_steps, features)))这里,我们定义了一个1D卷积层,filters = 32表示使用32个卷积核,kernel_size = 3意味着卷积核的大小为3,这些卷积核在时间序列数据上滑动,提取不同的局部特征。
GAPSO-CNN-BiLSTM,遗传粒子群优化算法来优化CNN-BiLSTM网络做预测,预测精度高于普通的PSO-BiLSTM。 这里把遗传算法跟粒子群优化算法结合,指的不是用遗传算法来优化PSO的参数,而是解决PSO的容易收敛到局部最优点的问题。
再说说BiLSTM(双向长短期记忆网络),它能够同时处理正向和反向的序列信息,对时间序列数据中的长期依赖关系捕捉能力超强。比如:
model.add(tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(units = 64)))这里我们在模型中添加了一个双向LSTM层,units = 64表示LSTM层中有64个隐藏单元,能够更好地学习时间序列数据中的复杂模式。
GAPSO优化CNN - BiLSTM
当我们把GAPSO应用到CNN - BiLSTM网络时,实际上就是利用GAPSO的全局搜索优势,去寻找CNN - BiLSTM网络中最优的参数组合。在代码实现上,可能会像下面这样:
# 假设我们已经定义好了CNN - BiLSTM模型
def fitness_function(parameters):
# 根据参数设置模型
model.set_params(parameters)
model.compile(optimizer='adam', loss='mse')
model.fit(X_train, y_train, epochs = 50, batch_size = 32, verbose = 0)
loss = model.evaluate(X_test, y_test, verbose = 0)
return loss
# 初始化GAPSO相关参数
num_particles = 50
num_dimensions = len(model.get_params())
particles = np.random.rand(num_particles, num_dimensions)
velocities = np.zeros((num_particles, num_dimensions))
pbest_positions = particles.copy()
pbest_fitness = np.array([fitness_function(p) for p in particles])
gbest_index = np.argmin(pbest_fitness)
gbest_position = pbest_positions[gbest_index]
gbest_fitness = pbest_fitness[gbest_index]
# GAPSO迭代更新
for i in range(max_iterations):
# 更新速度和位置
velocities = w * velocities + c1 * np.random.rand(num_particles, num_dimensions) * (pbest_positions - particles) + c2 * np.random.rand(num_particles, num_dimensions) * (gbest_position - particles)
particles = particles + velocities
# 应用遗传算法操作
# 选择
selected_indices = np.argsort(pbest_fitness)[:int(num_particles * selection_rate)]
selected_particles = particles[selected_indices]
# 交叉
new_particles = []
for j in range(0, len(selected_particles), 2):
parent1 = selected_particles[j]
parent2 = selected_particles[j + 1]
crossover_point = np.random.randint(1, num_dimensions - 1)
child1 = np.concatenate((parent1[:crossover_point], parent2[crossover_point:]))
child2 = np.concatenate((parent2[:crossover_point], parent1[crossover_point:]))
new_particles.append(child1)
new_particles.append(child2)
# 变异
for k in range(len(new_particles)):
if np.random.rand() < mutation_rate:
mutation_index = np.random.randint(0, num_dimensions)
new_particles[k][mutation_index] = np.random.rand()
particles = np.array(new_particles)
# 计算适应度
fitness_values = np.array([fitness_function(p) for p in particles])
improved_indices = fitness_values < pbest_fitness
pbest_positions[improved_indices] = particles[improved_indices]
pbest_fitness[improved_indices] = fitness_values[improved_indices]
current_best_index = np.argmin(pbest_fitness)
if pbest_fitness[current_best_index] < gbest_fitness:
gbest_fitness = pbest_fitness[current_best_index]
gbest_position = pbest_positions[current_best_index]
# 使用最优参数设置模型并预测
best_model = model.set_params(gbest_position)
best_model.compile(optimizer='adam', loss='mse')
best_model.fit(X_train, y_train, epochs = 50, batch_size = 32, verbose = 0)
y_pred = best_model.predict(X_test)这段代码大致展示了GAPSO优化CNN - BiLSTM的过程。首先定义了一个适应度函数fitness_function,通过模型的损失来评估参数组合的好坏。然后初始化粒子群的位置、速度等参数,在迭代过程中,不仅按照PSO的方式更新速度和位置,还应用遗传算法的选择、交叉和变异操作,不断寻找更优的参数组合,最后用找到的最优参数设置模型并进行预测。
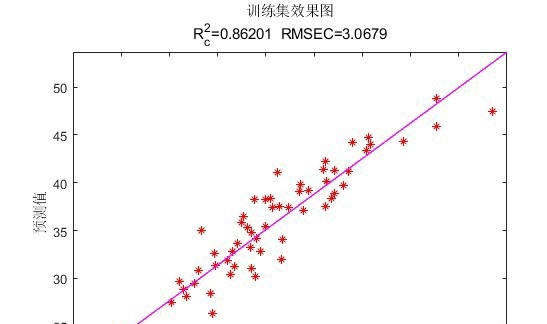
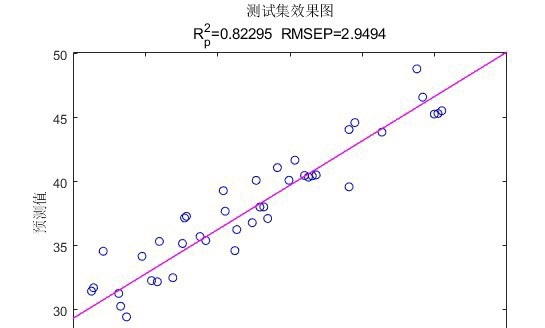
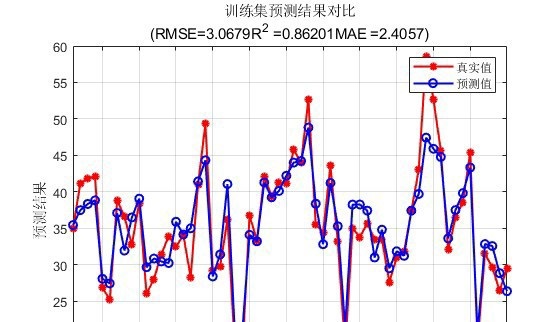
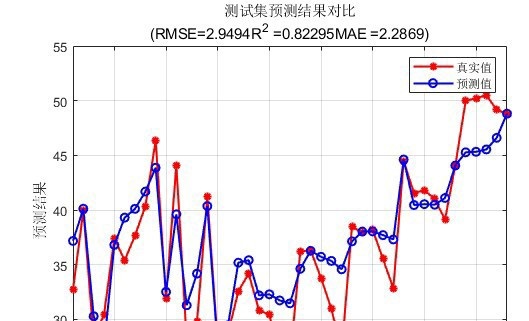
预测精度对比
实际应用中,GAPSO - CNN - BiLSTM的预测精度确实高于普通的PSO - BiLSTM。这是因为GAPSO能更有效地搜索到全局最优解,避免了CNN - BiLSTM网络陷入局部最优的参数组合。普通的PSO - BiLSTM可能会在局部最优解附近徘徊,导致模型无法发挥出最佳性能。而GAPSO - CNN - BiLSTM就像是开了“上帝视角”,能在更广阔的参数空间中找到最适合的那一组,从而提升了预测精度。
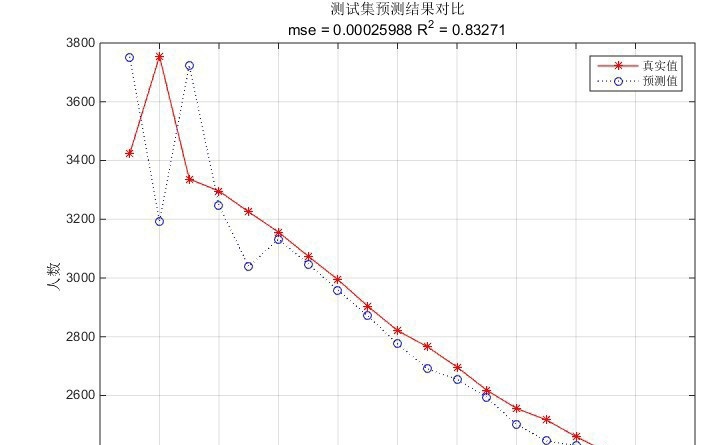
总的来说,GAPSO - CNN - BiLSTM为数据预测带来了新的思路和方法,通过巧妙结合遗传算法和粒子群优化算法的优势,让CNN - BiLSTM网络在预测任务中展现出更强大的实力。希望这篇文章能给大家在相关领域的研究和实践中带来一些启发。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)