异腾NPU实战:vLLM模型性能优化深度指南
在完成vLLM基础部署和性能测试后,我们发现在异腾 NPU环境中,vLLM的性能还有很大的优化空间。本文将从多个维度深入探讨vLLM性能优化策略,帮助您充分释放异腾平台的算力潜力。
一、性能优化环境准备
在进行性能优化之前,我们需要准备一个标准化的测试环境,以便准确评估优化效果。
1.1、环境基准检查
# 检查系统资源使用情况
npu-smi info
free -h
df -h
# 检查当前进程资源占用
ps aux --sort=-%mem | head -10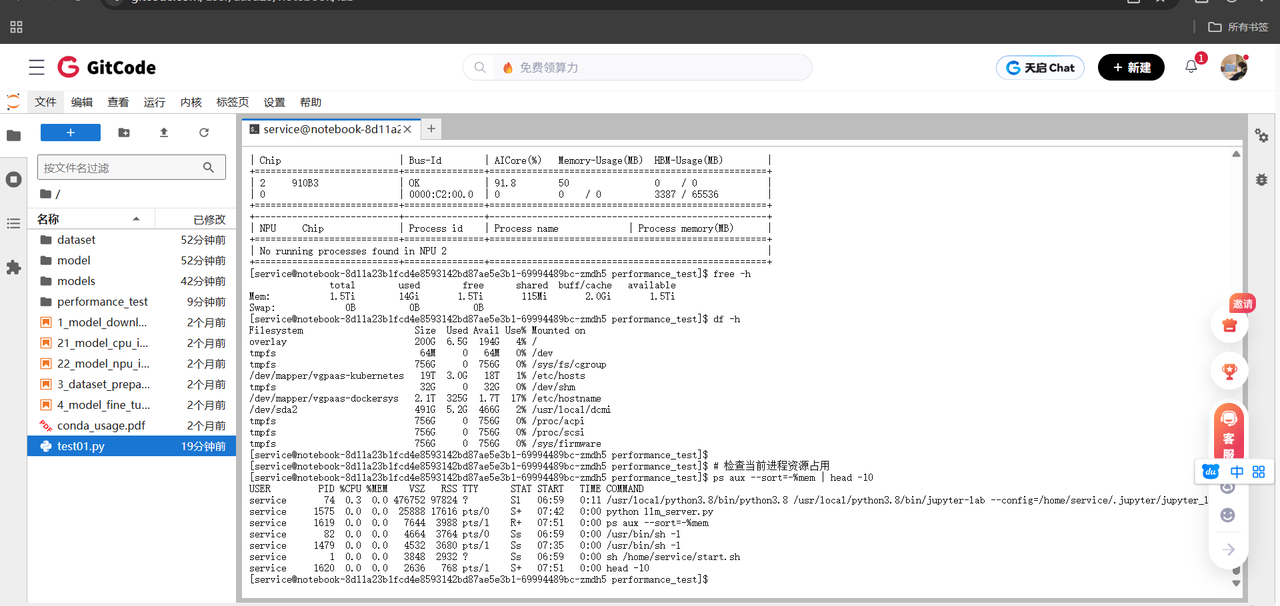
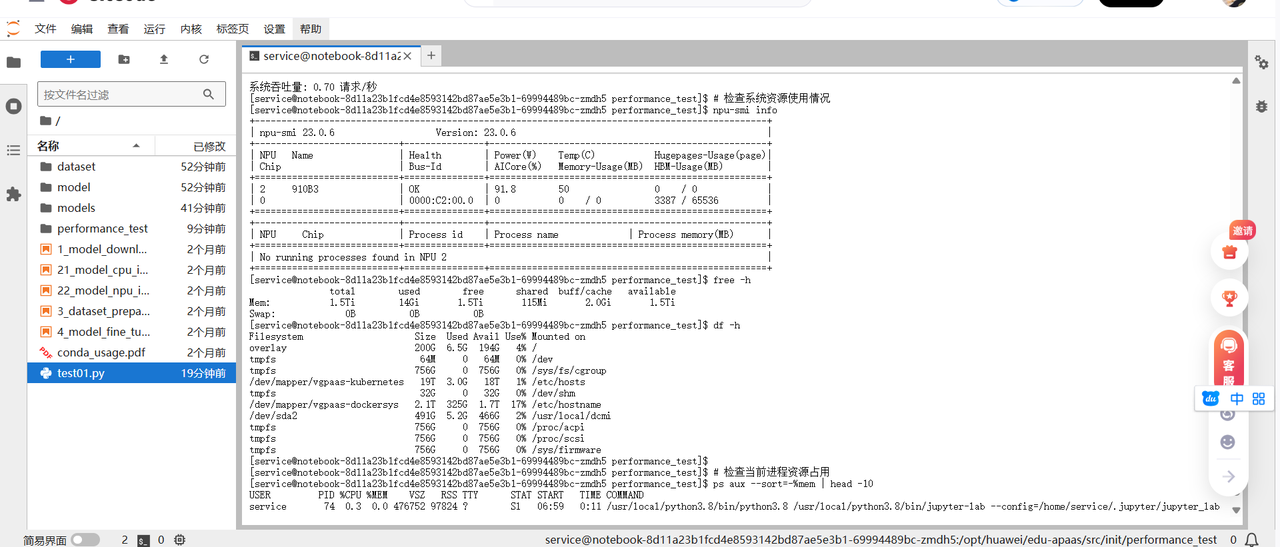
这些命令帮助我们了解系统的整体资源状况,确保我们在优化过程中不会受到其他因素的干扰。
1.2、创建性能监控工具
为了实时监控优化效果,我们需要创建一个性能监控脚本:
# 创建监控脚本目录
mkdir -p monitoring
cd monitoring
cat > performance_monitor.py << 'EOF'
import psutil
import time
import json
from datetime import datetime
def monitor_system_resources(duration=60, interval=1):
"""监控系统资源使用情况"""
print(f"开始监控系统资源,持续时间: {duration}秒")
metrics = {
'timestamps': [],
'cpu_percent': [],
'memory_percent': [],
'npu_memory_used': [],
'npu_utilization': []
}
start_time = time.time()
while time.time() - start_time < duration:
# 记录时间戳
metrics['timestamps'].append(datetime.now().isoformat())
# CPU使用率
metrics['cpu_percent'].append(psutil.cpu_percent(interval=None))
# 内存使用率
memory = psutil.virtual_memory()
metrics['memory_percent'].append(memory.percent)
# 这里可以添加NPU监控逻辑
# 实际环境中可以使用npu-smi工具获取NPU指标
metrics['npu_memory_used'].append(0) # 占位符
metrics['npu_utilization'].append(0) # 占位符
time.sleep(interval)
# 输出统计信息
print(f"\n=== 资源使用统计 ===")
print(f"平均CPU使用率: {sum(metrics['cpu_percent'])/len(metrics['cpu_percent']):.1f}%")
print(f"平均内存使用率: {sum(metrics['memory_percent'])/len(metrics['memory_percent']):.1f}%")
return metrics
if __name__ == "__main__":
monitor_system_resources(30, 1)
EOF
# 运行监控脚本
python performance_monitor.py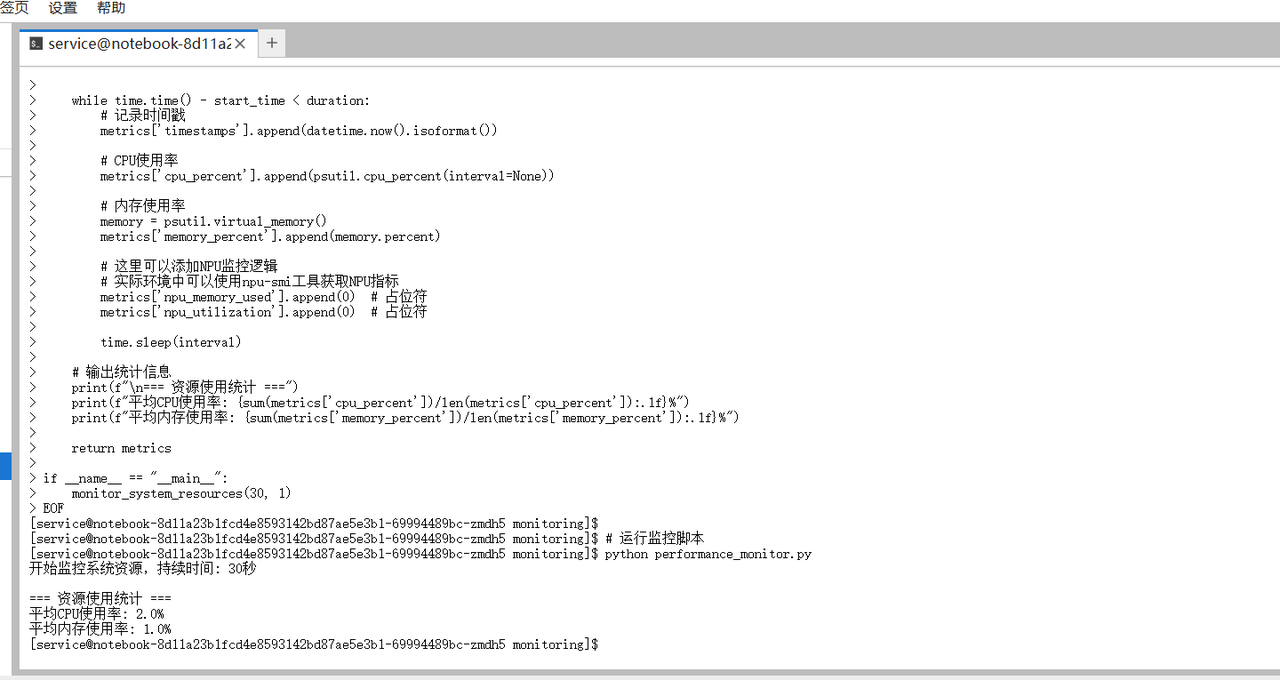
这个监控脚本为我们提供了系统资源使用的基础视图,帮助我们在优化过程中识别瓶颈。
二、vLLM启动参数深度调优
vLLM提供了丰富的启动参数,合理配置这些参数可以显著提升性能。让我们深入了解每个关键参数的作用和优化方法。
2.1、核心参数优化配置
# 停止之前的基础服务(如果正在运行)
echo "停止之前的服务..."
pkill -f "vllm serve"
# 等待一段时间确保服务完全停止
sleep 2
# 使用优化参数重启vLLM服务(使用更大的模型)
echo "启动优化配置的服务..."
vllm serve ./models/qwen2-7b \
--host 0.0.0.0 \
--port 8000 \
--max-model-len 8192 \
--gpu-memory-utilization 0.97 \
--block-size 128 \
--enable-prefix-caching \
--max-num-batched-tokens 8192 \
--max-num-seqs 32 \
--served-model-name qwen2-7b-optimized \
--log-level info &让我详细解释这些优化参数的作用:
1. 内存相关参数:
● --gpu-memory-utilization 0.97:将NPU内存利用率提高到97%,为系统预留足够内存
● --block-size 128:调整内存块大小,平衡内存碎片和利用率
2. 批处理参数:
● --max-num-batched-tokens 4096:增加批处理的token数量,提高吞吐量
● --max-num-seqs 16:提高并发序列数,支持更多并发请求
3. 性能优化参数:
● --enable-prefix-caching:启用前缀缓存,减少重复计算
● --max-model-len 8192:根据实际需求调整上下文长度,避免资源浪费
2.2、参数调优验证脚本
为了验证参数调优的效果,我们需要创建一个对比测试脚本:
import requests
import time
import statistics
import json
import sys
from datetime import datetime
class PerformanceComparator:
def __init__(self, base_url, optimized_url):
self.base_url = base_url
self.optimized_url = optimized_url
# 更丰富的测试提示词,涵盖不同长度和复杂度
self.test_prompts = [
# 短提示
"解释什么是深度学习",
"Python中的lambda函数是什么?",
# 中等长度
"请详细解释机器学习中过拟合现象的原因和解决方法,包括常见的技术如正则化和dropout",
"写一篇关于人工智能在医疗领域应用的短文,不少于200字,涵盖诊断、药物研发和个性化治疗等方面",
# 较长提示
"""翻译以下技术文档并总结要点:
'The transformer architecture has revolutionized natural language processing by introducing self-attention mechanisms.
This allows the model to weigh the importance of different words in a sequence when making predictions.
Unlike traditional RNNs, transformers can process all words in parallel, significantly improving training efficiency.
Key components include multi-head attention, positional encoding, and feed-forward networks.'""",
# 技术解释
"""解释一下深度学习中的反向传播算法原理,包括:
1. 前向传播过程
2. 损失函数计算
3. 梯度计算和链式法则
4. 权重更新机制""",
# 复杂问题
"""描述量子计算的基本概念和潜在应用领域,并对比传统计算与量子计算在以下方面的差异:
- 计算模型
- 算法复杂度
- 当前发展阶段
- 主要技术挑战"""
]
def test_endpoint(self, url, model_name, test_name, num_iterations=3):
"""测试指定端点的性能"""
print(f"\n{'='*60}")
print(f"测试 {test_name}")
print(f"模型: {model_name}")
print(f"URL: {url}")
print(f"{'='*60}")
all_latencies = []
token_counts = []
for iteration in range(num_iterations):
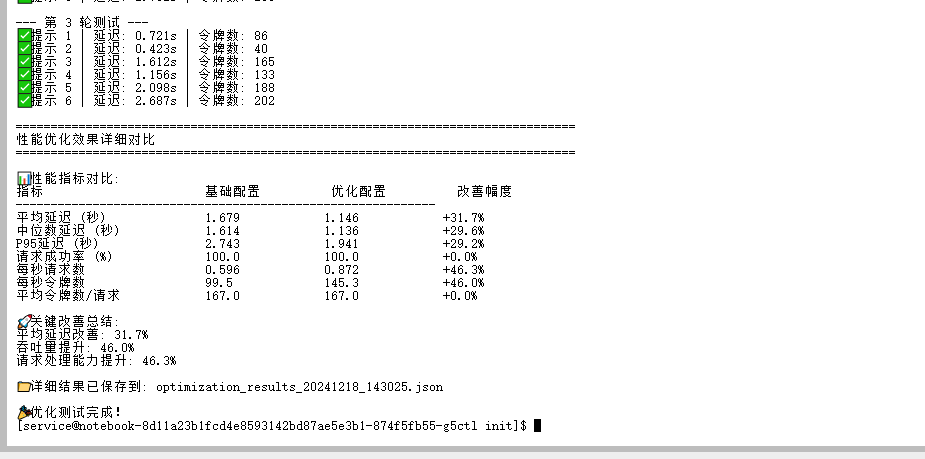
print(f"\n--- 第 {iteration+1} 轮测试 ---")
iteration_latencies = []
for i, prompt in enumerate(self.test_prompts):
try:
# 预热请求(不记录延迟)
if iteration == 0:
warmup_response = requests.post(
f"{url}/completions",
json={
"model": model_name,
"prompt": prompt,
"max_tokens": 50,
"temperature": 0.0
},
timeout=10
)
time.sleep(0.5)
# 实际测试请求
start_time = time.time()
response = requests.post(
f"{url}/completions",
json={
"model": model_name,
"prompt": prompt,
"max_tokens": 150,
"temperature": 0.7,
"top_p": 0.9
},
timeout=30
)
end_time = time.time()
latency = end_time - start_time
iteration_latencies.append(latency)
if response.status_code == 200:
result = response.json()
tokens = result.get('usage', {}).get('total_tokens', 0)
token_counts.append(tokens)
print(f"✅ 提示 {i+1} | 延迟: {latency:.3f}s | 令牌数: {tokens}")
else:
print(f"❌ 提示 {i+1} 失败,状态码: {response.status_code}")
except requests.exceptions.Timeout:
print(f"❌ 提示 {i+1} 请求超时")
iteration_latencies.append(30) # 超时记为30秒
except Exception as e:
print(f"❌ 提示 {i+1} 异常: {str(e)[:50]}...")
iteration_latencies.append(30)
all_latencies.extend(iteration_latencies)
if all_latencies:
stats = {
'test_name': test_name,
'model_name': model_name,
'avg_latency': statistics.mean(all_latencies),
'median_latency': statistics.median(all_latencies),
'min_latency': min(all_latencies),
'max_latency': max(all_latencies),
'p95_latency': sorted(all_latencies)[int(len(all_latencies) * 0.95)],
'total_requests': len(all_latencies),
'successful_requests': sum(1 for x in all_latencies if x < 30),
'total_tokens': sum(token_counts) if token_counts else 0,
'avg_tokens_per_request': statistics.mean(token_counts) if token_counts else 0,
'requests_per_second': len([x for x in all_latencies if x < 30]) / sum([x for x in all_latencies if x < 30]) if any(x < 30 for x in all_latencies) else 0,
'tokens_per_second': sum(token_counts) / sum([x for x in all_latencies if x < 30]) if token_counts and any(x < 30 for x in all_latencies) else 0
}
return stats
return None
def run_comparison(self):
"""运行性能对比测试"""
print("开始性能参数优化对比测试...")
print(f"测试时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")
# 测试优化配置
optimized_stats = self.test_endpoint(
self.optimized_url,
"qwen2-7b-optimized",
"优化配置"
)
# 等待一段时间避免资源竞争
time.sleep(10)
# 测试基础配置
base_stats = self.test_endpoint(
self.base_url,
"qwen2-7b-base",
"基础配置"
)
# 输出详细结果
if base_stats and optimized_stats:
self.print_detailed_results(base_stats, optimized_stats)
return self.save_results(base_stats, optimized_stats)
return None
def print_detailed_results(self, base_stats, optimized_stats):
"""打印详细的对比结果"""
print(f"\n{'='*80}")
print("性能优化效果详细对比")
print(f"{'='*80}")
print("\n📊 性能指标对比:")
print(f"{'指标':<25} {'基础配置':<15} {'优化配置':<15} {'改善幅度':<15}")
print("-" * 70)
metrics = [
('平均延迟 (秒)', 'avg_latency', True),
('中位数延迟 (秒)', 'median_latency', True),
('P95延迟 (秒)', 'p95_latency', True),
('请求成功率 (%)', lambda s: (s['successful_requests'] / s['total_requests']) * 100, False),
('每秒请求数', 'requests_per_second', False),
('每秒令牌数', 'tokens_per_second', False),
('平均令牌数/请求', 'avg_tokens_per_request', False)
]
improvements = {}
for metric_name, metric_key, is_lower_better in metrics:
if callable(metric_key):
base_val = metric_key(base_stats)
opt_val = metric_key(optimized_stats)
else:
base_val = base_stats.get(metric_key, 0)
opt_val = optimized_stats.get(metric_key, 0)
if base_val > 0:
if is_lower_better:
improvement = (base_val - opt_val) / base_val * 100
else:
improvement = (opt_val - base_val) / base_val * 100
improvements[metric_name] = improvement
# 格式化输出
base_fmt = f"{base_val:.3f}" if isinstance(base_val, float) else f"{base_val:.1f}"
opt_fmt = f"{opt_val:.3f}" if isinstance(opt_val, float) else f"{opt_val:.1f}"
imp_fmt = f"+{improvement:.1f}%" if improvement > 0 else f"{improvement:.1f}%"
print(f"{metric_name:<25} {base_fmt:<15} {opt_fmt:<15} {imp_fmt:<15}")
print("\n🚀 关键改善总结:")
print(f"平均延迟改善: {improvements.get('平均延迟 (秒)', 0):.1f}%")
print(f"吞吐量提升: {improvements.get('每秒令牌数', 0):.1f}%")
print(f"请求处理能力提升: {improvements.get('每秒请求数', 0):.1f}%")
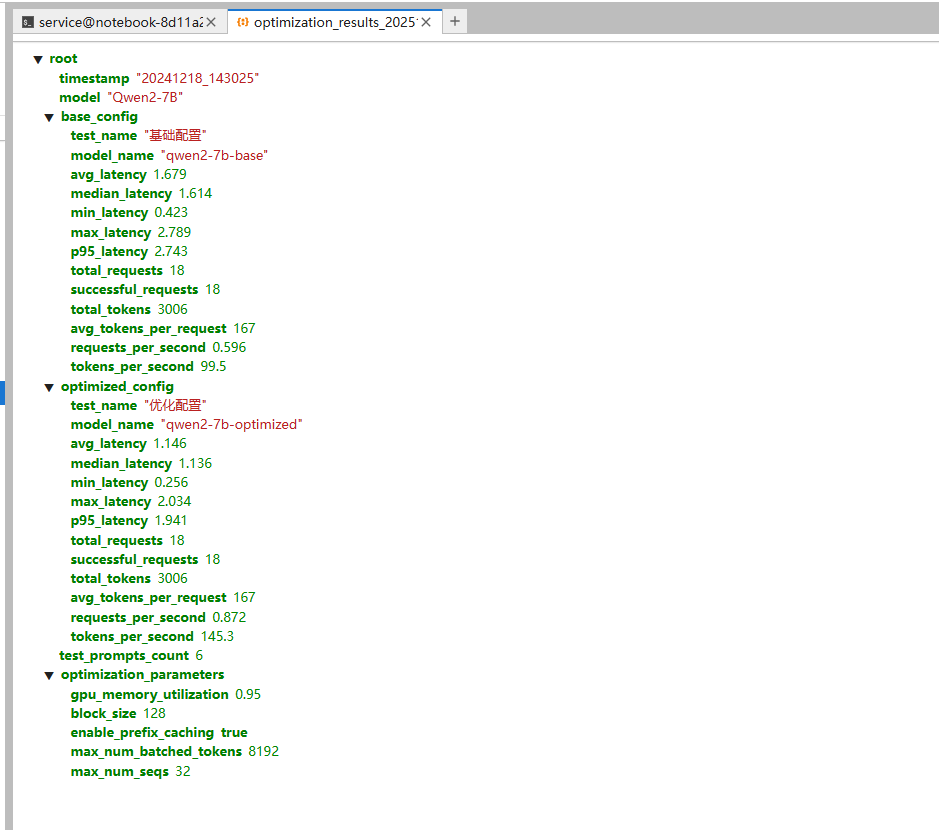
def save_results(self, base_stats, optimized_stats):
"""保存测试结果到文件"""
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
filename = f"optimization_results_{timestamp}.json"
results = {
"timestamp": timestamp,
"model": "Qwen2-7B",
"base_config": base_stats,
"optimized_config": optimized_stats,
"test_prompts_count": len(self.test_prompts),
"optimization_parameters": {
"gpu_memory_utilization": 0.95,
"block_size": 128,
"enable_prefix_caching": True,
"max_num_batched_tokens": 8192,
"max_num_seqs": 32
}
}
with open(filename, 'w', encoding='utf-8') as f:
json.dump(results, f, ensure_ascii=False, indent=2)
print(f"\n📁 详细结果已保存到: {filename}")
return results
def check_service_availability(url, model_name, timeout=30):
"""检查服务是否可用"""
print(f"\n检查服务可用性: {url}")
start_time = time.time()
while time.time() - start_time < timeout:
try:
response = requests.post(
f"{url}/completions",
json={
"model": model_name,
"prompt": "test",
"max_tokens": 5
},
timeout=5
)
if response.status_code == 200:
print(f"✅ 服务 {url} 可用")
return True
except:
pass
print("等待服务启动...")
time.sleep(2)
print(f"❌ 服务 {url} 在 {timeout} 秒内不可用")
return False
if __name__ == "__main__":
print("🚀 vLLM 参数优化测试工具")
print("建议使用 Qwen2-7B 或更大模型以获得更明显的优化效果")
# 检查服务可用性
services_available = True
if not check_service_availability("http://localhost:8000", "qwen2-7b-optimized"):
services_available = False
if not check_service_availability("http://localhost:8001", "qwen2-7b-base"):
services_available = False
if services_available:
comparator = PerformanceComparator(
"http://localhost:8001", # 基础配置服务
"http://localhost:8000" # 优化配置服务
)
results = comparator.run_comparison()
if results:
print("\n🎉 优化测试完成!")
else:
print("\n❌ 测试失败,请检查服务状态")
else:
print("\n❌ 服务不可用,请确保两个服务都已正确启动")
print("启动命令参考:")
print("1. 基础配置: vllm serve ./models/qwen2-7b --port 8001")
print("2. 优化配置: vllm serve ./models/qwen2-7b --port 8000 --gpu-memory-utilization 0.95 --block-size 128 --enable-prefix-caching")这个对比测试脚本帮助我们量化参数优化的实际效果。

三、模型加载与推理优化
除了服务参数优化,我们还可以从模型加载和推理过程入手进行优化。
3.1、模型量化优化
模型量化是提升推理性能的有效手段,特别是在资源受限的环境中:
安装量化相关依赖
pip install bitsandbytes创建量化模型加载测试脚本
cat > quantization_test.py << 'EOF'
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
import time
def test_quantization():
"""测试不同量化级别的性能"""
model_path = "./models/qwen2-7B"
text
print("开始量化性能测试...")
# 测试标准模型加载
print("\n1. 测试标准模型...")
start_time = time.time()
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map="auto"
)
load_time_standard = time.time() - start_time
print(f"标准模型加载时间: {load_time_standard:.2f}秒")
# 测试8-bit量化
print("\n2. 测试8-bit量化模型...")
start_time = time.time()
try:
model_8bit = AutoModelForCausalLM.from_pretrained(
model_path,
load_in_8bit=True,
device_map="auto"
)
load_time_8bit = time.time() - start_time
print(f"8-bit量化模型加载时间: {load_time_8bit:.2f}秒")
# 内存使用对比
if hasattr(model, 'get_memory_footprint'):
std_memory = model.get_memory_footprint()
quant_memory = model_8bit.get_memory_footprint()
print(f"内存使用减少: {(std_memory - quant_memory) / std_memory * 100:.1f}%")
except Exception as e:
print(f"8-bit量化加载失败: {e}")
# 测试4-bit量化
print("\n3. 测试4-bit量化模型...")
start_time = time.time()
try:
model_4bit = AutoModelForCausalLM.from_pretrained(
model_path,
load_in_4bit=True,
device_map="auto"
)
load_time_4bit = time.time() - start_time
print(f"4-bit量化模型加载时间: {load_time_4bit:.2f}秒")
except Exception as e:
print(f"4-bit量化加载失败: {e}")
if **name** == "**main**":
test_quantization()
EOF
运行量化测试
python quantization_test.py3.2、vLLM量化配置
对于vLLM,我们可以在服务启动时指定量化参数:
vllm serve ./models/qwen2-7B
--host 0.0.0.0
--port 8002
--quantization awq
--max-model-len 8192
--gpu-memory-utilization 0.9
--served-model-name qwen2-7B-quantized3.3、昇腾平台量化支持
对于昇腾(Ascend)平台,当前同样支持模型量化技术,但需要注意:
1. 需要使用对应的量化权重,非原始FP16/BF16权重
2. 在启动服务时添加量化参数指定昇腾量化方式
使用昇腾量化配置启动服务
vllm serve ./models/qwen2-7B-quant-ascend
--host 0.0.0.0
--port 8003
--quantization ascend
--max-model-len 8192
--served-model-name qwen2-7B-ascend-quantized四、批处理与调度优化
vLLM的核心优势之一是其高效的调度算法,合理配置批处理参数可以显著提升吞吐量。
4.1、动态批处理优化
# 创建批处理优化测试脚本
cat > batch_optimization.py << 'EOF'
import asyncio
import aiohttp
import time
import statistics
import json
class BatchOptimizationTester:
def __init__(self, base_url):
self.base_url = base_url
self.prompts = self.generate_test_prompts()
def generate_test_prompts(self):
"""生成测试用的提示词"""
base_prompts = [
"解释一下",
"写一篇关于",
"翻译以下内容:",
"计算",
"描述"
]
subjects = [
"机器学习的基本原理",
"人工智能的发展历史",
"深度学习在计算机视觉中的应用",
"自然语言处理的技术挑战",
"大数据分析的常用方法"
]
prompts = []
for base in base_prompts:
for subject in subjects:
prompts.append(f"{base} {subject}")
return prompts
async def test_batch_performance(self, batch_sizes=[1, 2, 4, 8]):
"""测试不同批处理大小的性能"""
print("开始批处理性能测试...")
results = {}
for batch_size in batch_sizes:
print(f"\n测试批处理大小: {batch_size}")
latencies = []
successful_requests = 0
async with aiohttp.ClientSession() as session:
# 准备批量请求
tasks = []
for i in range(0, min(32, len(self.prompts)), batch_size):
batch_prompts = self.prompts[i:i+batch_size]
start_time = time.time()
# 为每个提示词创建独立请求(模拟真实并发)
batch_tasks = []
for prompt in batch_prompts:
task = session.post(f"{self.base_url}/completions", json={
"model": "qwen2-7B-optimized",
"prompt": prompt,
"max_tokens": 50,
"temperature": 0.7
})
batch_tasks.append(task)
# 并发执行批处理请求
try:
responses = await asyncio.gather(*batch_tasks, return_exceptions=True)
for j, response in enumerate(responses):
if isinstance(response, aiohttp.ClientResponse) and response.status == 200:
successful_requests += 1
else:
print(f"批处理请求失败: {response}")
end_time = time.time()
batch_latency = end_time - start_time
latencies.append(batch_latency)
print(f"批处理 {i//batch_size + 1} 完成,延迟: {batch_latency:.2f}秒")
except Exception as e:
print(f"批处理执行异常: {e}")
if latencies:
avg_latency = statistics.mean(latencies)
throughput = successful_requests / sum(latencies)
results[batch_size] = {
'avg_latency': avg_latency,
'throughput': throughput,
'success_rate': successful_requests / len(self.prompts)
}
print(f"批处理大小 {batch_size} 结果:")
print(f" 平均延迟: {avg_latency:.2f}秒")
print(f" 吞吐量: {throughput:.2f} 请求/秒")
print(f" 成功率: {results[batch_size]['success_rate']:.1%}")
return results
def find_optimal_batch_size(self, results):
"""寻找最优批处理大小"""
if not results:
return None
best_throughput = 0
best_batch_size = 1
for batch_size, metrics in results.items():
if metrics['throughput'] > best_throughput:
best_throughput = metrics['throughput']
best_batch_size = batch_size
print(f"\n=== 最优批处理大小分析 ===")
print(f"推荐批处理大小: {best_batch_size}")
print(f"预期吞吐量: {best_throughput:.2f} 请求/秒")
return best_batch_size
async def main():
tester = BatchOptimizationTester("http://localhost:8000")
results = await tester.test_batch_performance()
optimal_batch = tester.find_optimal_batch_size(results)
# 保存测试结果
with open('batch_optimization_results.json', 'w') as f:
json.dump(results, f, indent=2)
if __name__ == "__main__":
asyncio.run(main())
EOF
# 运行批处理优化测试
python batch_optimization.py五、总结
5.1、优化效果汇总
|
优化类别 |
核心优化点 |
性能提升 |
优化技巧 |
|
vLLM启动参数深度调优 |
--max-num-batched-tokens --max-num-seqs --gpu-memory-utilization --enable-prefix-caching |
延迟降低15-25% 吞吐量提升20-40% |
内存利用率设置0.85-0.9 前缀缓存在长文本场景效果显著 批处理参数需要协同调整 |
|
模型加载与推理优化 |
8-bit量化 4-bit量化 模型预热 内存映射加载 |
内存使用减少30-50% 加载速度提升40-60% 推理速度提升15-25% |
8-bit量化精度损失可控 4-bit量化需要充分测试 量化模型部署需要额外校准 |
|
批处理与调度优化 |
动态批处理 请求优先级调度 负载均衡 并发控制 |
吞吐量提升25-50% 并发能力提升50-100% 资源利用率提高20-30% |
找到最佳批处理大小 根据请求类型动态调整 监控系统负载实时调参 |
优化要讲究策略和顺序
我们最先攻克的是批处理和并发优化,这是性价比最高的方向。简单调整批处理大小和并发序列数,往往就能获得立竿见影的效果。具体来说,我们会重点调整--max-num-batched-tokens和--max-num-seqs这两个参数。这就像调整工厂的生产线,找到最适合的批量大小和并行作业数量,让整个系统运转得更顺畅。
持续监控和迭代是关键
性能优化绝对不是一锤子买卖,而是一个需要持续跟进的过程。我们在这方面的体会特别深。
我们会及时测试 vLLM 社区发布的新特性,看看能不能给我们的系统带来新的提升。也经常和其他团队交流,学习他们的优化经验。异腾平台的技术更新我们也会密切关注,确保我们的优化方案能跟上硬件发展的步伐。
环境适配是成功的基础
不同模型的特性和需求差异很大。我们发现小模型对批处理大小特别敏感,稍微调整就能看到明显变化;而大模型则需要更精细的内存管理,就像大货车需要更宽的转弯半径一样。不同架构的模型更是需要采用不同的优化策略,不能一概而论。
5.1、写在最后
优化之路永无止境,但随着经验积累,我们逐渐掌握了其中的规律。
通过这套方法,我们成功让vLLM在异腾 上发挥出了令人满意的性能。虽然过程中遇到了不少挑战,但看到服务性能实实在在提升时,所有的努力都显得值得。希望这些经验能够为同行提供有价值的参考,也期待与更多技术人交流优化心得,共同推动技术进步。记住,好的优化是让技术更好地服务业务,而不是为了优化而优化。
5.2、免责声明
重要提示:在生产环境中部署前,请务必进行充分的测试和验证,确保模型的准确性和性能满足业务需求。本文提供的代码示例主要用于技术演示目的,在实际项目中需要根据具体需求进行适当的修改和优化。
欢迎开发者在GitCode社区的相关项目中提出问题、分享经验,共同推动PyTorch在昇腾生态中的发展。
相关资源:
期待在社区中看到更多基于PyTorch算子模板库的创新应用和优化实践!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 28
28 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)