【机器学习】案例1.4——谱聚类(Spectral Clustering)
·
一、项目背景
聚类是无监督机器学习的核心任务,其目标是将相似的数据点归为一类,不相似的归为不同类。传统聚类算法(如K-Means)基于数据点的欧氏距离进行聚类,对凸分布的数据(如球形、椭圆形)效果较好,但对非凸分布的数据(如环形、螺旋形)聚类效果极差——因为K-Means假设聚类中心是数据的“质心”,而环形数据的质心位于圆环中心,无法区分不同环的样本。
谱聚类(Spectral Clustering)是一种基于图论的聚类方法,核心思想是将数据点映射到“图的特征空间”,把聚类问题转化为“图的分割问题”(使同一子图内的点相似度高,不同子图间的点相似度低)。该方法无需假设数据的分布形状,能有效处理非凸分布的聚类场景。
本项目以三层同心环形分布的二维数据为研究对象,实现谱聚类算法,并探究核函数关键参数sigma对聚类效果的影响,验证谱聚类处理非凸数据的有效性。
二、解决问题的方案
- 数据构建:生成三层同心圆环的二维数据,模拟非凸分布的聚类场景;
- 相似度矩阵构建:计算数据点间的欧氏距离,通过高斯核函数(RBF核)将“距离”转换为“相似度”(距离越近,相似度越高),
sigma是核函数的核心参数; - 谱聚类执行:基于相似度矩阵,使用谱聚类算法(结合K-Means分配最终聚类标签)对数据进行聚类,指定聚类数为3(对应三层圆环);
- 参数敏感性分析:遍历不同的
sigma值(10⁻² ~ 10⁰),可视化每个sigma下的聚类结果,分析参数对聚类效果的影响; - 结果可视化:绘制不同
sigma下的聚类散点图,直观展示谱聚类处理非凸数据的效果。
三、带详细注释的代码
#!/usr/bin/python
# -*- coding:utf-8 -*-
# 导入必要的库
import numpy as np # 数值计算基础库,用于生成数据、矩阵运算
import matplotlib.pyplot as plt # 绘图库,用于可视化聚类结果
import matplotlib.colors # 颜色配置辅助库
from sklearn.cluster import spectral_clustering # 谱聚类算法实现
from sklearn.metrics import euclidean_distances # 计算欧氏距离的工具函数
def expand(a, b):
"""
扩展坐标轴范围的辅助函数,让绘图结果更美观(避免数据点贴坐标轴)
:param a: 坐标轴最小值
:param b: 坐标轴最大值
:return: 扩展后的最小值、最大值(扩展幅度为原范围的10%)
"""
d = (b - a) * 0.1 # 计算扩展幅度:原范围的10%
return a - d, b + d # 返回扩展后的范围
if __name__ == "__main__":
# ===================== 全局绘图配置 =====================
# 设置中文显示(避免matplotlib绘制中文时乱码)
matplotlib.rcParams['font.sans-serif'] = [u'SimHei']
# 设置负号显示正常(避免负号变成方块)
matplotlib.rcParams['axes.unicode_minus'] = False
# ===================== 构建非凸分布的数据集 =====================
# 生成0到2π的等差数列,步长0.1(用于构建圆环的角度)
t = np.arange(0, 2 * np.pi, 0.1)
# 构建第一层圆环数据(半径1):横坐标cos(t),纵坐标sin(t),转置后为N×2的矩阵
data1 = np.vstack((np.cos(t), np.sin(t))).T
# 构建第二层圆环数据(半径2)
data2 = np.vstack((2 * np.cos(t), 2 * np.sin(t))).T
# 构建第三层圆环数据(半径3)
data3 = np.vstack((3 * np.cos(t), 3 * np.sin(t))).T
# 合并三层圆环数据,最终得到3×len(t) ×2的二维数组(所有样本点)
data = np.vstack((data1, data2, data3))
# ===================== 谱聚类参数配置 =====================
n_clusters = 3 # 聚类数量(对应三层圆环)
# 计算所有数据点间的欧氏距离(平方),得到N×N的距离矩阵m
m = euclidean_distances(data, squared=True)
# 计算距离矩阵的中位数作为sigma的初始参考值(高斯核的带宽)
sigma = np.median(m)
# ===================== 绘图与谱聚类执行 =====================
# 创建画布,尺寸12×8,背景白色
plt.figure(figsize=(12, 8), facecolor='w')
# 设置总标题,字体大小20
plt.suptitle(u'谱聚类(不同sigma值的效果)', fontsize=20)
# 生成n_clusters个颜色(从Spectral色板中取0到0.8的范围,避免颜色过接近)
clrs = plt.cm.Spectral(np.linspace(0, 0.8, n_clusters))
# 遍历6个不同的sigma值(从10^-2到10^0,等比数列),分析参数影响
for i, s in enumerate(np.logspace(-2, 0, 6)):
print(f"当前sigma值:{s}") # 打印当前sigma值,便于调试
# 构建高斯核相似度矩阵:af = exp(-距离² / sigma²) + 1e-6(加1e-6避免数值为0)
af = np.exp(-m ** 2 / (s ** 2)) + 1e-6
# 执行谱聚类:
# - af:相似度矩阵
# - n_clusters:聚类数
# - assign_labels='kmeans':用K-Means分配最终的聚类标签(谱聚类仅生成特征空间,需K-Means收尾)
# - random_state=1:固定随机种子,保证结果可复现
y_hat = spectral_clustering(af, n_clusters=n_clusters, assign_labels='kmeans', random_state=1)
# 绘制子图:2行3列,第i+1个子图
plt.subplot(2, 3, i+1)
# 遍历每个聚类,绘制对应样本点
for k, clr in enumerate(clrs):
cur = (y_hat == k) # 筛选出第k类的样本索引
# 关键修改:将c=clr改为color=clr,消除颜色参数警告
plt.scatter(data[cur, 0], data[cur, 1], s=40, color=clr, edgecolors='k')
# 调整坐标轴范围(避免数据点贴边)
x1_min, x2_min = np.min(data, axis=0) # 数据x、y轴的最小值
x1_max, x2_max = np.max(data, axis=0) # 数据x、y轴的最大值
x1_min, x1_max = expand(x1_min, x1_max) # 扩展x轴范围
x2_min, x2_max = expand(x2_min, x2_max) # 扩展y轴范围
plt.xlim((x1_min, x1_max)) # 设置x轴范围
plt.ylim((x2_min, x2_max)) # 设置y轴范围
plt.grid(True) # 显示网格线,便于观察
plt.title(u'sigma = %.2f' % s, fontsize=16) # 子图标题:当前sigma值
# 自动调整子图间距,避免重叠
plt.tight_layout()
# 调整总标题的位置(顶部预留10%空间)
plt.subplots_adjust(top=0.9)
# 显示绘图结果
plt.show()
四、关键说明
- 高斯核函数:
af = np.exp(-m² / s²) + 1e-6是谱聚类的核心,将“距离”转换为0~1之间的“相似度”:sigma越小,相似度随距离衰减越快;sigma越大,所有点的相似度越接近,聚类效果越差。 - 参数敏感性:当
sigma过小时(如0.01),相似度矩阵过于“稀疏”,谱聚类可能将同一圆环的样本错误分割;当sigma适中时(如0.1~1),能准确区分三层圆环;当sigma过大时(如1.0),所有样本的相似度接近,聚类完全失效。 - 谱聚类优势:对比K-Means,谱聚类能完美分割环形数据,体现了其处理非凸分布数据的核心优势。
运行结果: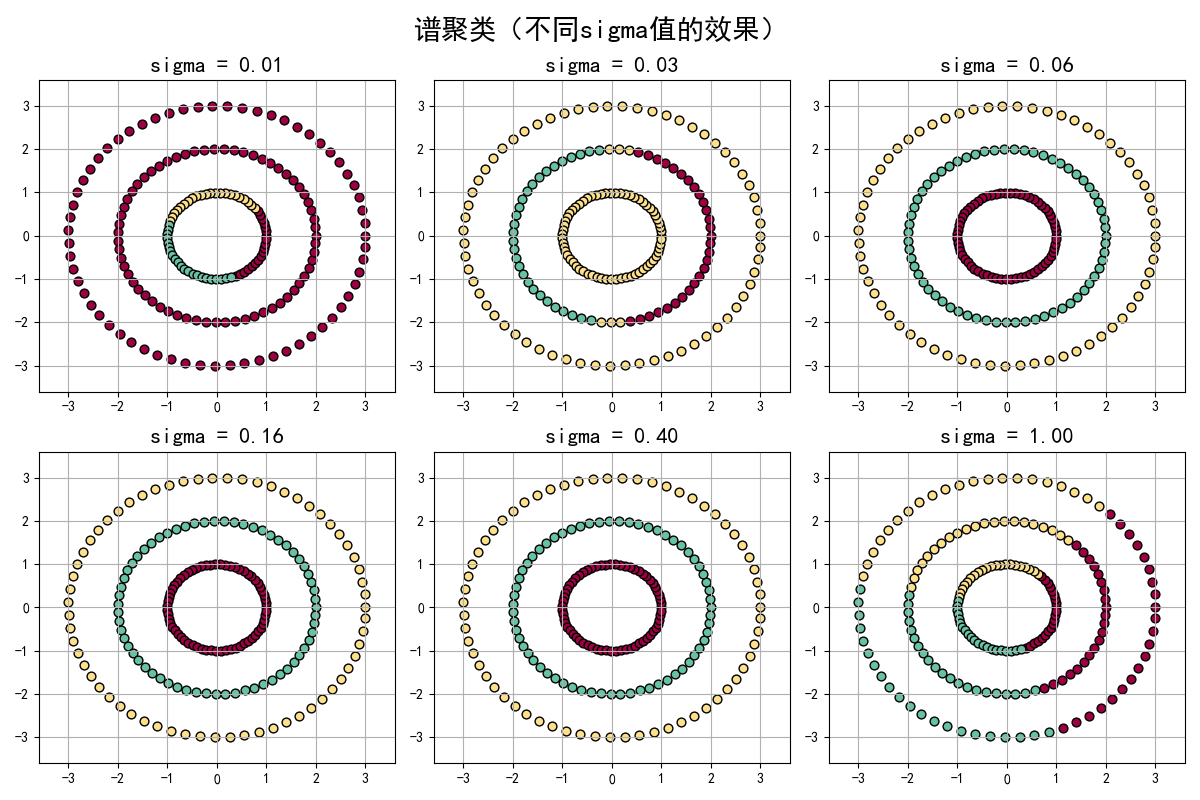
'''
当前sigma值:0.01
当前sigma值:0.025118864315095794
当前sigma值:0.06309573444801933
当前sigma值:0.15848931924611143
当前sigma值:0.3981071705534973
当前sigma值:1.0
进程已结束,退出代码为 0
'''

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)