Kubernetes 调度器
调度器概念
调度器作为单独的程序运行,启动后一直坚挺 APIServer,获取 PodSpec.NodeName 为空的 Pod,对每个 Pod 都会创建一个 Binding,表面该 Pod 应放在哪个节点上
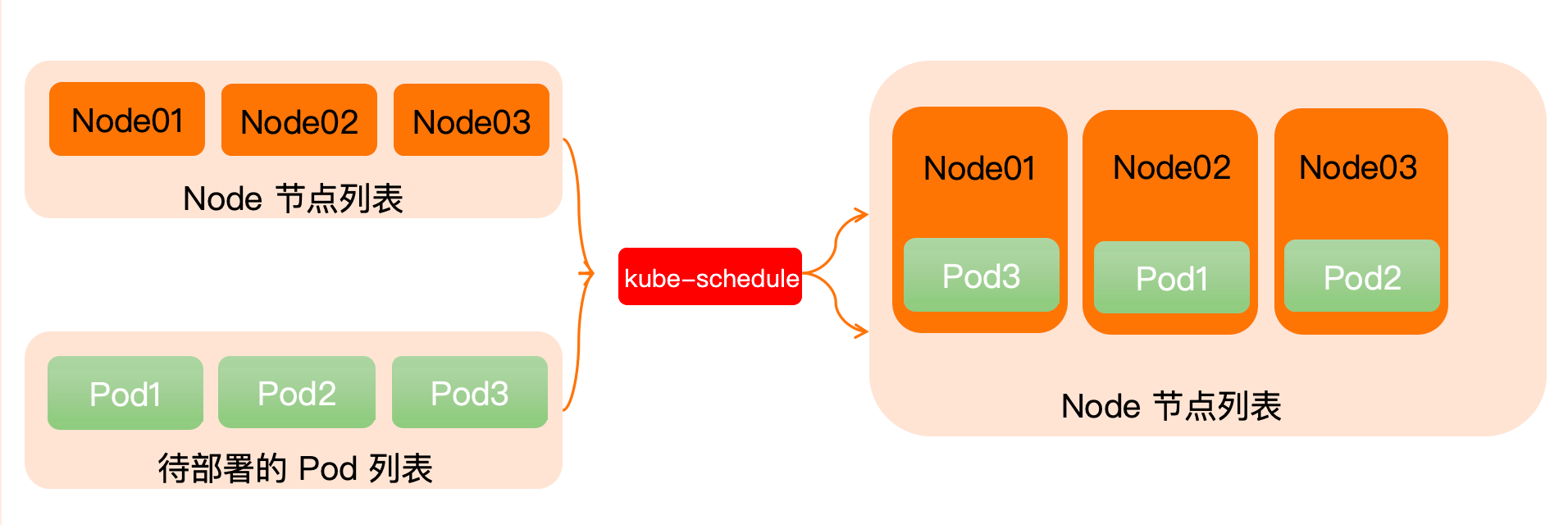
自定义调度器
调度器可以自定义,通过:spec.schedulername 参数指定调度器名字,可以为 Pod 选择用哪个调度器
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp
labels:
app: myapp
spec:
replicas: 1
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
schedulerName: my-scheduler
containers:
- name: myapp
image: docker.xuanyuan.run/nginx:alpine
运行后 pod 会是 pending 状态
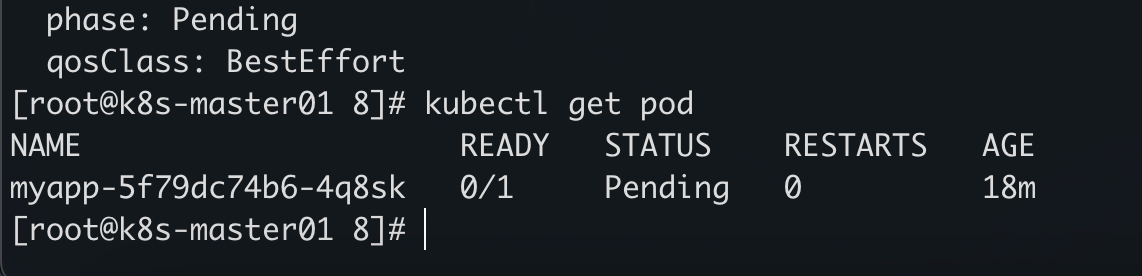
因为调度器指定的my-scheduler,而我们没有这个调度器,所有没有调度器去调度这个 pod,所以就是pending 状态了
创建一个基于 shell 的自定义调度器
yum install -y epel-release jq
#!/bin/bash
SERVER='localhost:8001'
while true; do
# 找到 schedulerName 为 my-scheduler 且未绑定 Node 的 Pod
for PODNAME in $(kubectl --server $SERVER get pods -o json \
| jq '.items[]
| select(.spec.schedulerName == "my-scheduler")
| select(.spec.nodeName == null)
| .metadata.name' | tr -d '"')
do
# 获取所有 Node 列表
NODES=($(kubectl --server $SERVER get nodes -o json \
| jq '.items[].metadata.name' | tr -d '"'))
NUMNODES=${#NODES[@]}
CHOSEN=${NODES[$((RANDOM % NUMNODES))]}
# 发送 Binding 对象
curl -s \
-H "Content-Type: application/json" \
-X POST \
-d '{
"apiVersion": "v1",
"kind": "Binding",
"metadata": { "name": "'$PODNAME'" },
"target": {
"apiVersion": "v1",
"kind": "Node",
"name": "'$CHOSEN'"
}
}' \
http://$SERVER/api/v1/namespaces/default/pods/$PODNAME/binding/
echo "Assigned $PODNAME to $CHOSEN"
done
sleep 1
done
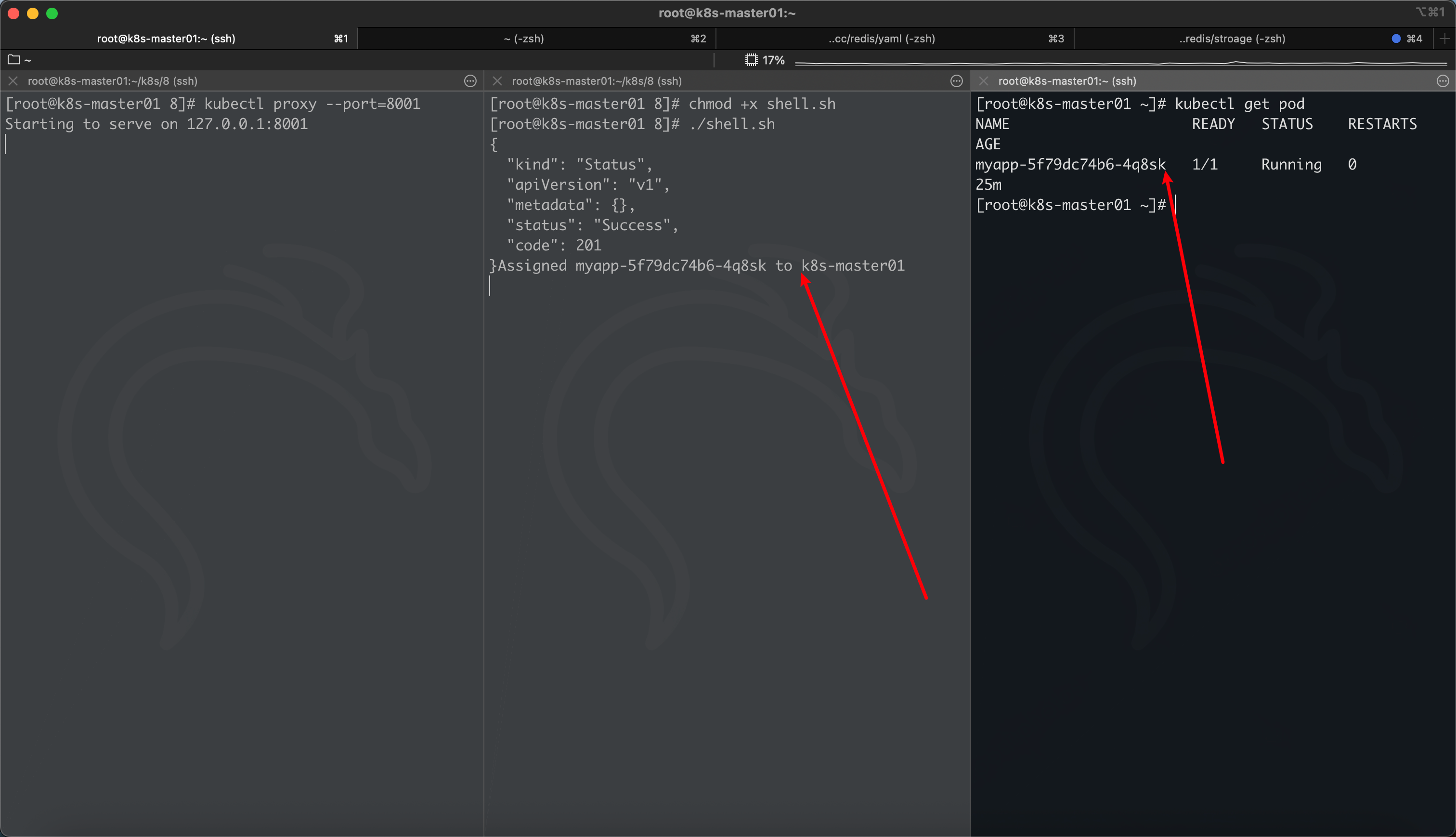
调度过程
调度器是可以自定义的,但是一般不会这样做,因为官方的调度器很完善,通过多个阶段来匹配调度,所以直接用官方的就好了。
过滤阶段
可以理解为StatefulSet 的预选/优选
过滤不能运行该 Pod 的 Node
- PodFitsResources: 节点资源大于 Pod 的请求的资源
- PodFitsHost:Pod 如果指定了 Node,那就用指定的
- PodFitsHostPorts:节点上已经使用的端口和 Pod 期望的 port 是否冲突
- PodSelectorMatches:过滤和 pod 指定的 label 不匹配的节点
- NoDiskConflict:已经挂载的卷和 Pod 指定的不能冲突
- …
打分阶段
- LeastRequestedPriority:倾向空闲资源多的节点
- BalancedAllocation:cpu/内存都均衡的
- ImageLocality:如果节点上有本地镜像的
- …
绑定阶段
调度器执行
老版本
POST /api/v1/namespaces/{ns}/pods/{name}/binding
新版本
PATCH /api/v1/namespaces/{namespace}/pods/{name}
告诉 APiServer,这个 pod 应该绑定在哪个 Node 上
随后,APiServer 会把
Pod.Spec.NodeName = <NodeName>
进行更新,这是老版本的绑定阶段,大概在v1.15 前,新版本的会直接使用 PATCH 方式进行更新 NodeName,不单独创建 Binding 对象,这是一个优化,可以理解为,不用创建 Binding 对象到 etcd 数据库里,直接操作修改,操作更少,效率更高。
亲和性
节点亲和性,k8s 官方的调度器有自己的调度方案,通过过滤、打分,然后调度,但是有时候我就想这个 pod1 跑在 node1 上甚至 master 上,人的权限总归是大于机器的,所以就有了亲和性这个东西
pod.spec.nodeAffinity
- preferredDuringSchedulingIgnoredDuringExecution:软性策略
你希望pod放在node1,但是一些其它原因导致不行,那就算了,调度器会进行预选优选选一个node运行pod
- requiredDuringSchedulingIgnoredDuringExecution:硬性策略
你希望pod放在node1,但是一些其它原因导致不行,那也不行,必须放在node1上,不然就别运行了
node 亲和性
软策略
affinity:亲和性策略
preferredDuringSchedulingIgnoredDuringExecution:软策略
weight:权重,访问 1-100
preference:亲和类型,或者说偏好
matchExpressions:对应亲和类型,类型为匹配运算
然后是匹配 key 等于什么
operator:In 包含
除了 In 还有这些
matchLabels:只支持等值匹配(key=value)
matchExpressions:用来进行 更复杂的 label 匹配
- In:值在列表中
- NotIn:值不在列表中
- Exists:存在该 key
- DoesNotExist:不存在该 key
包含什么,包含values 是 test 的
这里匹配的是节点的标签
节点标签
kubectl get node --show-labels
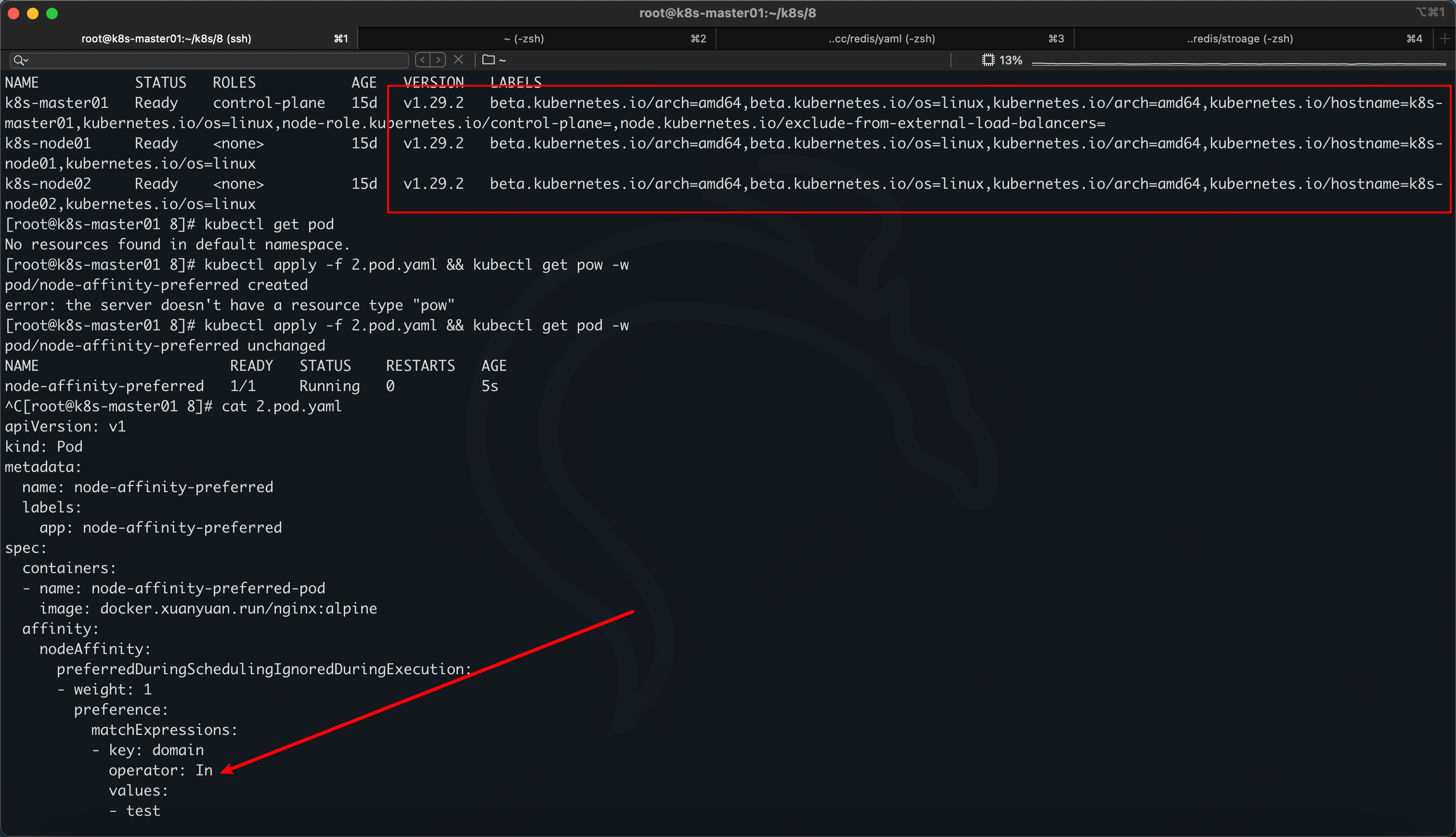
apiVersion: v1
kind: Pod
metadata:
name: node-affinity-preferred
labels:
app: node-affinity-preferred
spec:
containers:
- name: node-affinity-preferred-pod
image: docker.xuanyuan.run/nginx:alpine
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: domain
operator: In
values:
- test
指定了软策略,但是 node 没有符合条件的,那就算了,但也不是随便哪个 node 都行,都要进行调度的预选/优选,所以即使没有匹配,Pod 也 running 了
场景:
- 跨机房部署服务时,尽量用本地机房,减少延迟
- 一些 node 是机械硬盘,一些事固态,优先固态的
- 镜像本地化加速启动,优先本地
- …
硬策略
apiVersion: v1
kind: Pod
metadata:
name: node-affinity-required
labels:
app: node-affinity-required
spec:
containers:
- name: node-affinity-required-pod
image: docker.xuanyuan.run/nginx:alpine
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- k8s-node02
因为是硬策略,选了 kubernetes.io/hostname,一定包含k8s-node02 的才运行,所以最后 pod 落在了k8s-node02 node 上
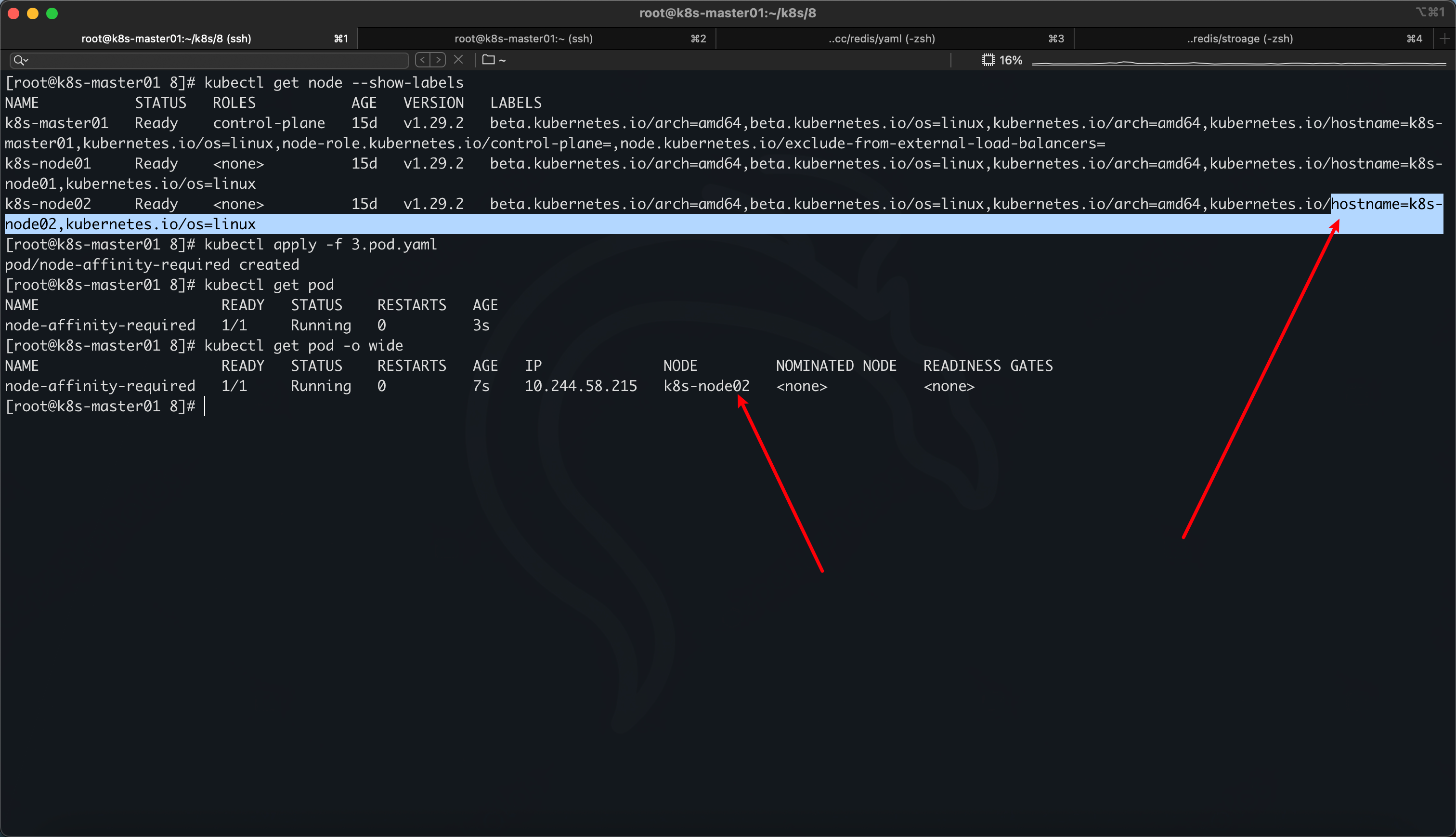
场景
- 一些业务可能依赖 GPU,但不是所有都有高性能显卡,有显卡的才能跑
- 安全性与合规,跨数据中心的业务场景,比如中国《——》新加坡的一个集群,国内产生的数据需要放置在本地,不允许出境。
- …
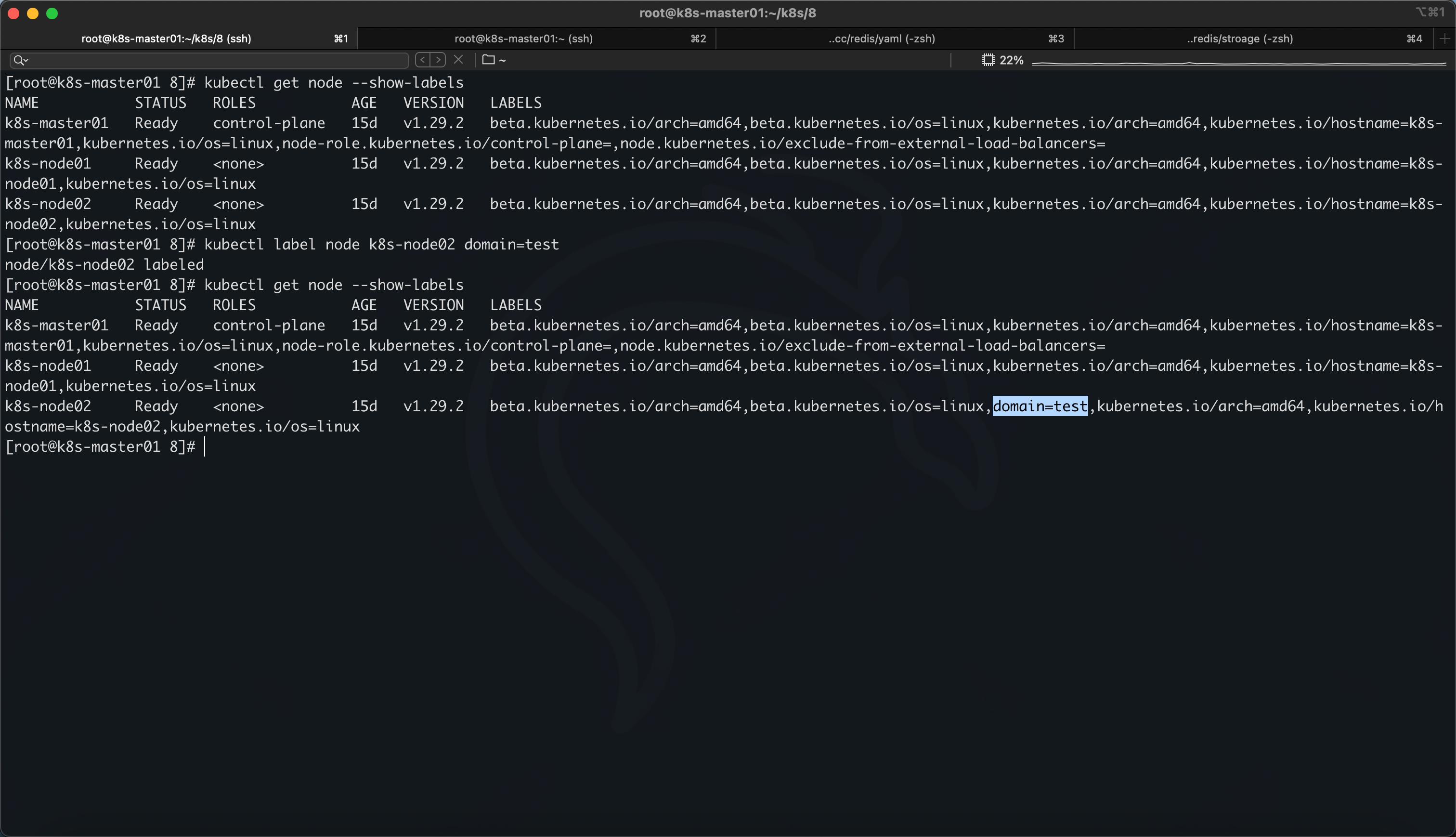
添加 node 的标签
kubectl label node k8s-node02 domain=test
Pod 亲和性
其实跟 node 亲和性是一个概念,但是 pod 有反亲和性,node 没有
亲和性
pod.spec.podAffinity
反亲和性
pod.spec.podAntiAffinity
preferredDuringSchedulingIgnoredDuringExecution:软策略
requiredDuringSchedulinglgnoredDuringExecution:硬策略
topologykey
topologykey:拓扑域(指定 Pod 调度或分布约束的作用范围)
- kubernetes.io/hostname:单节点
- 按节点计算 Pod 的亲和/反亲和
- 设置反亲和:
- 比如有一个 redis 集群场景,运行 3 个副本,是反亲和性的 Pod 策略,topologykey:kubernetes.io/hostname,调度器打分时,会尽量选择不同节点部署 Pod 副本,同样如果是软的就是尽量,如果是硬的就是必须。
- 意义:避免单节点故障导致的集群不可用
- 设置亲和:
- 有一个 Web 服务器与本地缓存服务的场景。Web 服务器 Pod 需要和本地的缓存服务 Pod 部署在同一节点上,以便通过本地通信(如 localhost 或共享内存)获得极低的访问延迟。同,软就是尽量,硬就是必须。
- 意义:性能优化,业务延迟最低
- topology.kubernetes.io/zone:区级别
- 区级别,一般对应华东、华北这种区域
- 设置反亲和
- 一个 Mysql 主从集群,把主和从部署到不同区域,实现高可用。软尽量、硬必须。
- 意义:跨区域实现高可用,避免单个区域故障导致不可用
- 设置亲和
- 一个 Web 应用和它的 Redis,分布式部署,配置亲和让它们离得最近,用户访问 web,因为没有配置亲和,redis 在成都,需要缓存时会从上海 web《——》成都 redis ,这样做肯定会提高延迟,设置区域级亲和,让上海的 web 调度到上海的 redis。
- 意义:降低延迟
- topology.kubernetes.io/region:域级别
- 域级别,一般对应欧洲、亚洲这种区域
- 同上。因为没有接触到这个级别,所有我也不知道:)
关于区级标签和域级标签,比较抽象
一般如果是云上,云供应商会打上区域标签,如果是本地自建,需要自己打标签,以代表它们的区域。
比如这样,看了这个图应该好理解些了
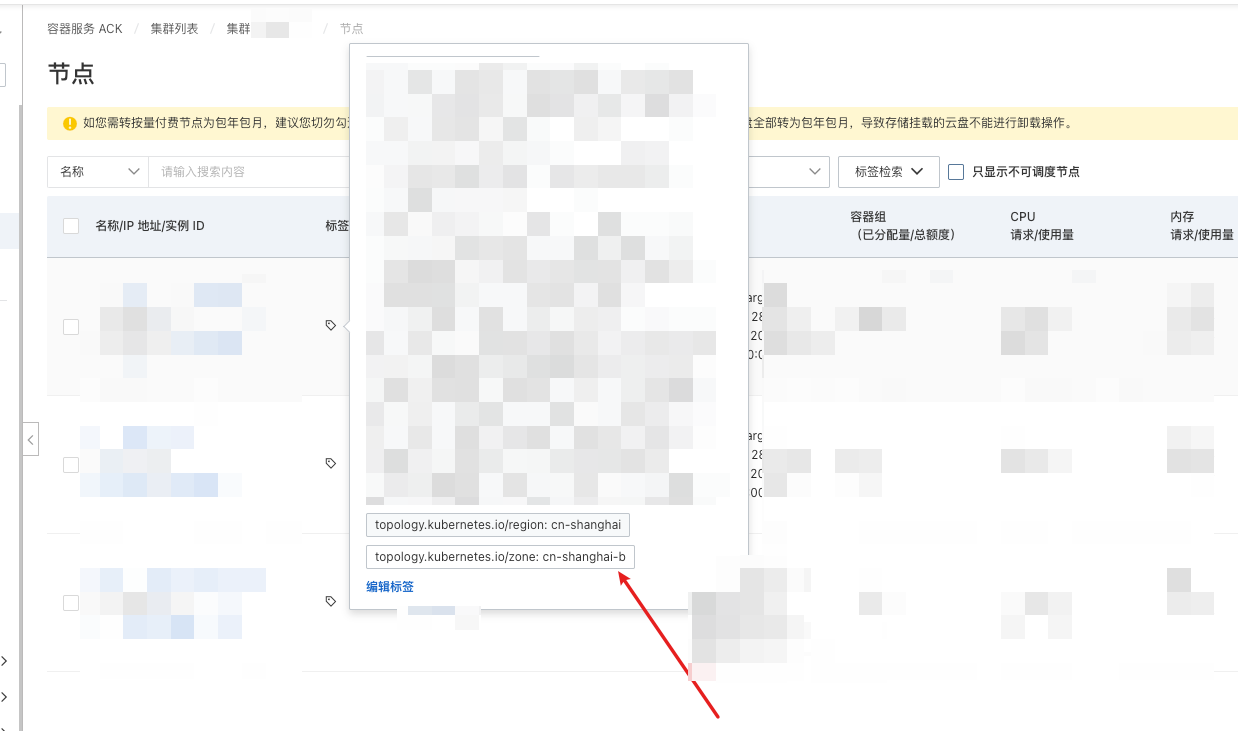
软策略
podAffinityTerm 在 pod 里
topologyKey: kubernetes.io/hostname 为单节点
apiVersion: v1
kind: Pod
metadata:
name: pod-aff-prefer
labels:
app: pod-aff
spec:
containers:
- name: myapp
image: docker.xuanyuan.run/nginx:alpine
affinity:
podAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- pod-1
topologyKey: kubernetes.io/hostname
硬策略
apiVersion: v1
kind: Pod
metadata:
name: pod-aff-req
labels:
app: pod-aff-req
spec:
containers:
- name: pod-aff-req-c
image: docker.xuanyuan.run/nginx:alpine
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- pod-1
topologyKey: kubernetes.io/hostname
不满足 Pending

Pod 反亲和性
反亲和软策略
如果有 Pod 有 app=pod-aff 这些标签,那就不在那一台 Node 上运行,但又同时,我这个 pod 又有pod-aff 这个标签
apiVersion: v1
kind: Pod
metadata:
name: pod-antiaff-prefer
labels:
app: pod-aff
spec:
containers:
- name: myapp
image: docker.xuanyuan.run/nginx:alpine
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- pod-aff
topologyKey: kubernetes.io/hostname
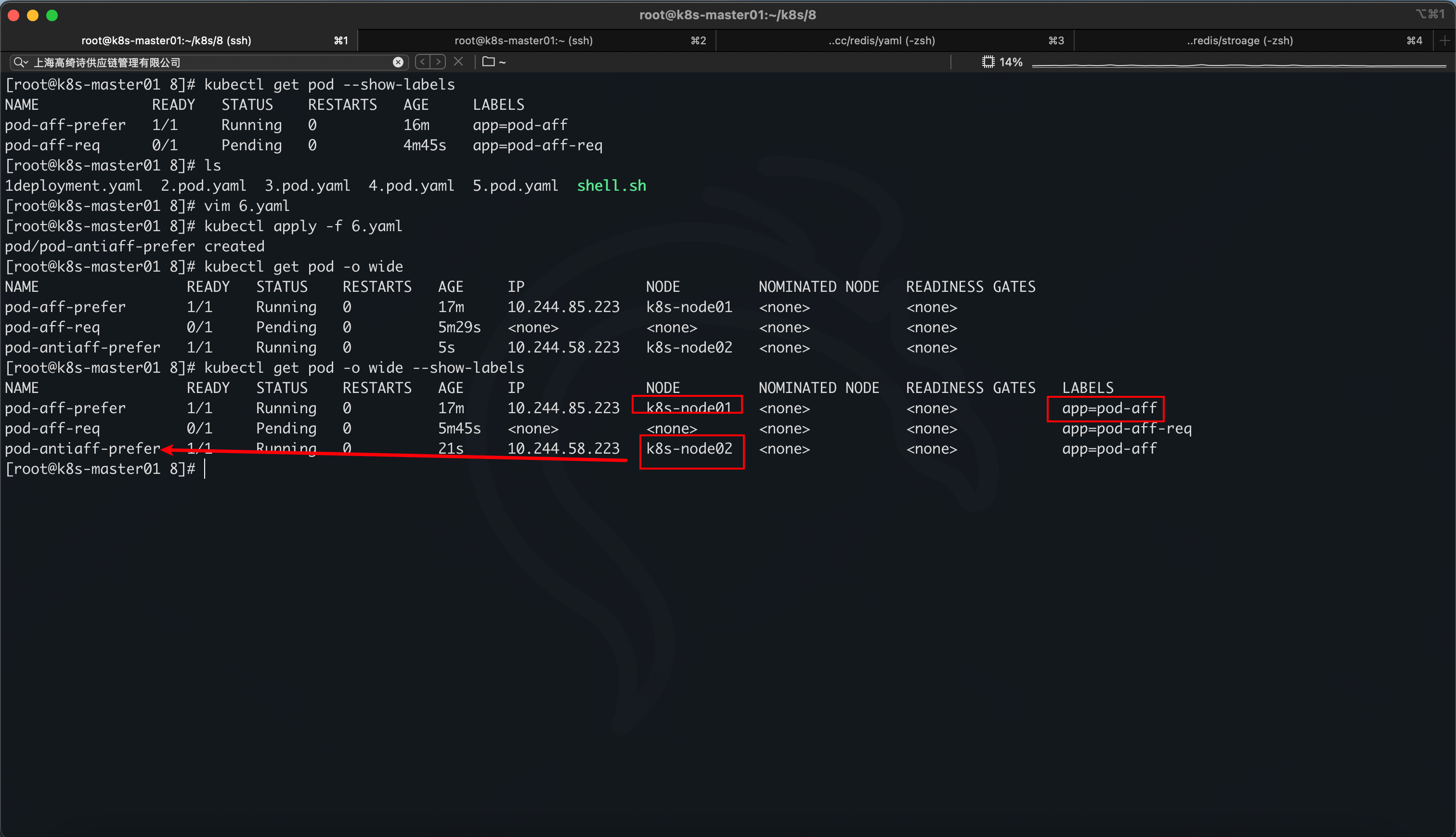
总结
| 调度策略 | 匹配对象 | 操作符 | 是否依赖拓扑域(topologyKey) | 调度目标 |
|---|---|---|---|---|
| nodeAffinity | Node(节点标签) | In、NotIn、Exists、DoesNotExist、Gt、Lt | 否 | 将 Pod 调度到符合特定 Node 标签的节点(或避免某些节点) |
| podAffinity | Pod(Pod 标签) | In、NotIn、Exists、DoesNotExist | 是(必须指定 topologyKey) | 将 Pod 调度到与目标 Pod 同一拓扑域 的节点上 |
| podAntiAffinity | Pod(Pod 标签) | In、NotIn、Exists、DoesNotExist | 是(必须指定 topologyKey) | 将 Pod 调度到与目标 Pod 不同拓扑域 的节点上 |
污点和容忍
污点 Taint
容忍 Toleration
亲和性是 正向选择,打上标签后,调度器根据标签调度
污点和容忍是 反向隔离",需要时打标签,默认无污点
| 对比项 | 亲和/反亲和 | 污点/容忍 |
|---|---|---|
| 调度机制 | 正向筛选 | 反向隔离 |
| 是否必须打标签 | Pod 或 Node 都需要标签 | 按需使用,默认无污点 |
| 控制方式 | “我想去哪” | “我不能去哪(除非容忍)” |
| 默认行为 | 不指定就都能调度 | 不加污点 → 所有 Pod 都能去 |
| 应用场景 | 定位节点、性能优化、副本分布 | 保护节点、专用节点、隔离节点 |
污点(Taint)和容忍(Toleration)是成对使用的调度控制机制:
- 污点加在 Node 上,用于“排斥”没有相应容忍的 Pod。一个节点可以有多个污点,每个污点都会阻止未容忍该污点的 Pod 被调度到该节点。
- 容忍加在 Pod 上,用于“允许”该 Pod 调度到带有特定污点的节点。

污点
key=value:effect
每个污点有一个 key 和一个 value 作为污点标签,value 可为空
策略
- NoSchedule:表示不会调度 Pod 到具有污点的 Node 上
- PreferNoSchedule:尽量避免调度 Pod 到有污点 Node 上
- NoExecute:不会调度 Pod 到具有污点的 Node,且将已存在的 Pod 驱赶出去
master 上默认会有一个污点,所以我们的 Pod 从来没有部署到 master 上
master 其实是一个概念,指定的一台主机为 master,并且将主机名命为 master(方便管理,主机名并不能决定它就是 master),在这台叫 master 的主机上部署 k8s,他就成了真的 master 了,上面运行了kube-apiserver、etcd 等容器,所以他就是 master,如果我们在另一台 node 上也运行 apiserver、etcd 等容器,那这台叫 node 的节点也可以成为 master,并且在配置了 kube config 配置文件,有 kubectl 工具的话也可以调用下面的其它 node,所以有 kubectl get node 这种命令,没有 get master 这种命令
污点的 key 叫:node-role.kubernetes.io/control-plane
value 为空,所以这里没写
策略为NoSchedule表示不会调度 Pod 到具有污点的 Node 上,所以删除它,就会有 pod 被调度到 master 这台主机上了
查询污点可以通过查询 node 的详细信息看到
kubectl describe node k8s-master01
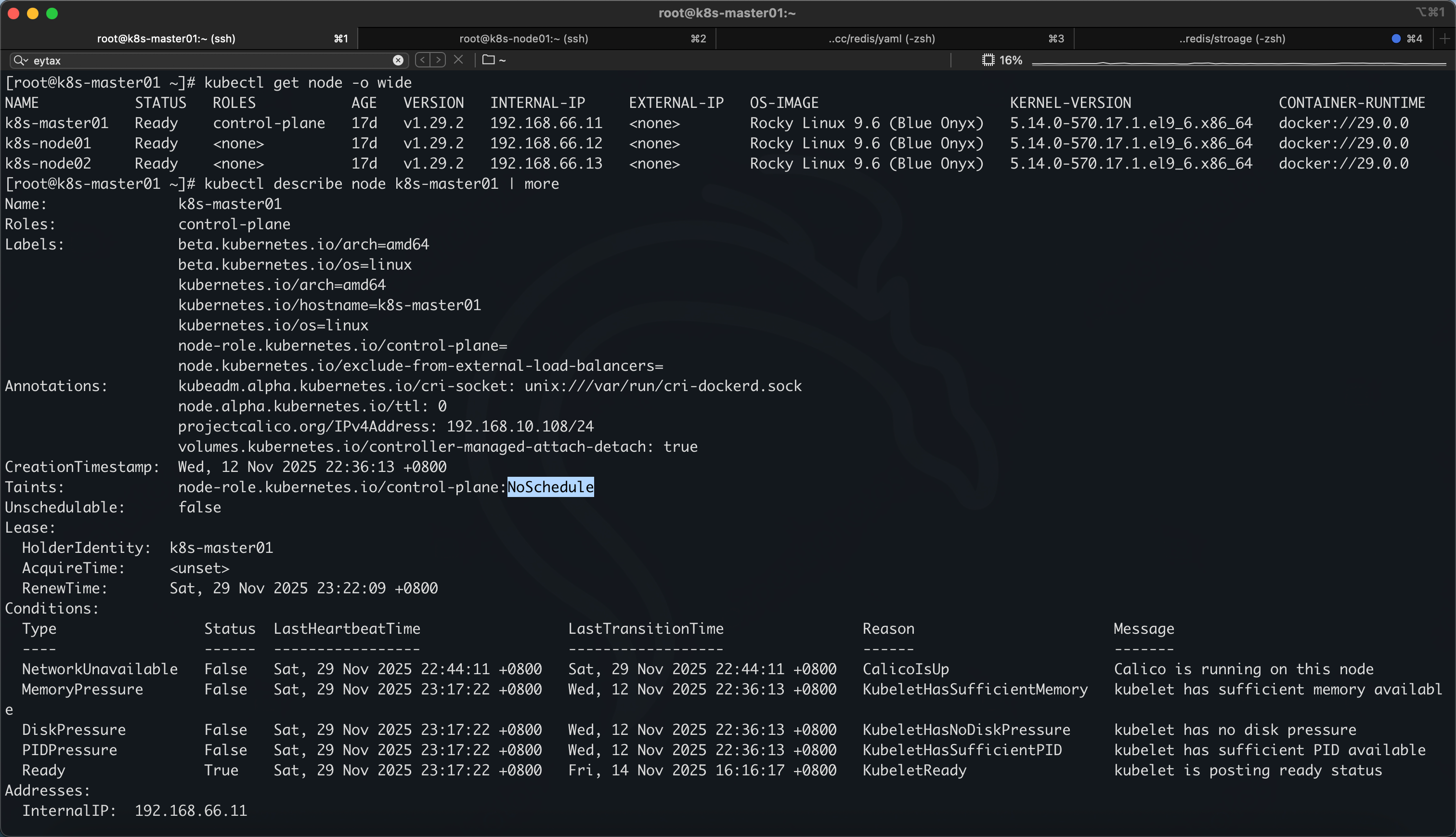
设置污点与移除污点
kubectl taint node k8s-master01 key=value:NoSchedule
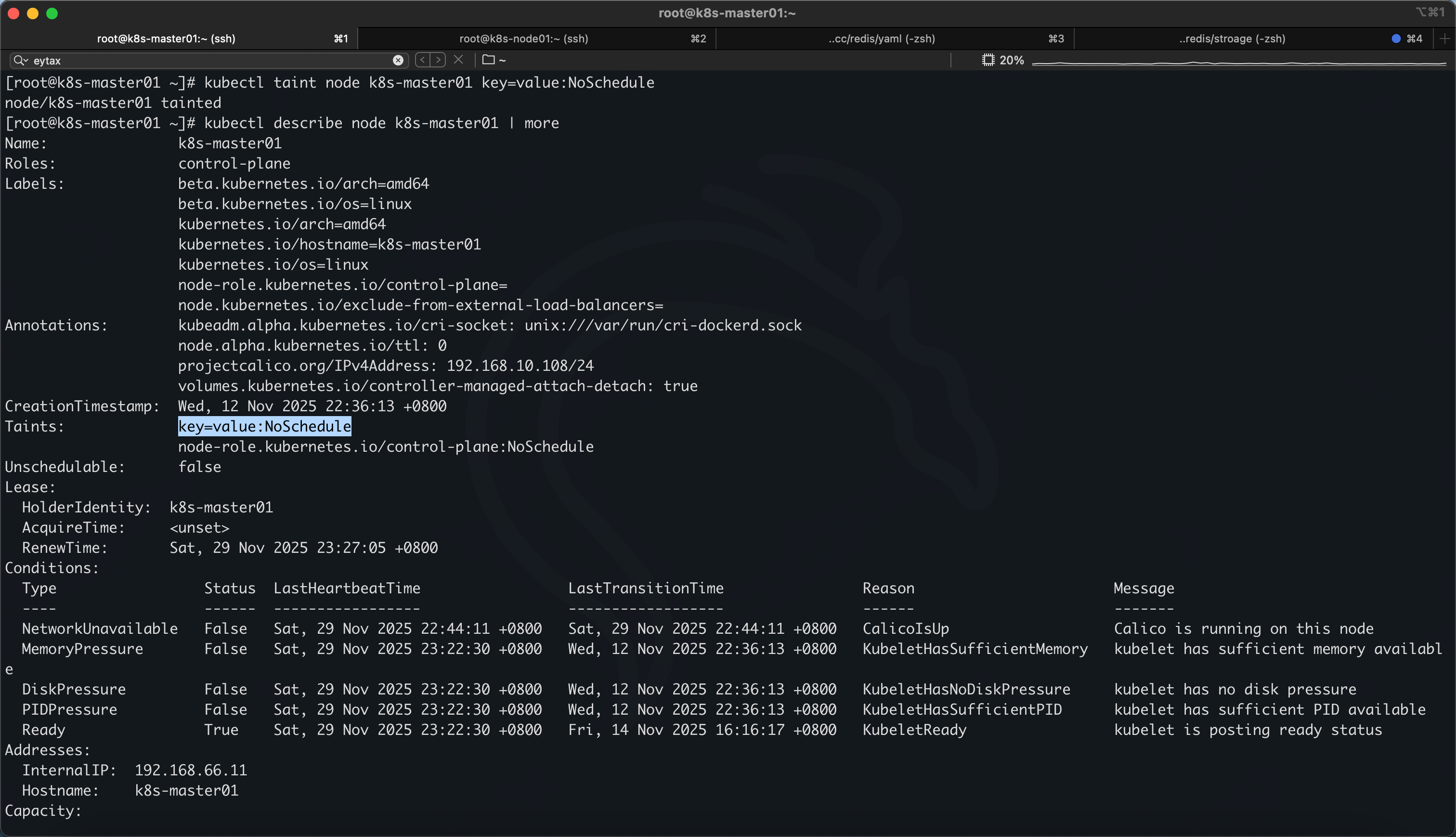
移除污点
在设置的命令上加一个减号就是移除
kubectl taint node k8s-master01 key=value:NoSchedule-
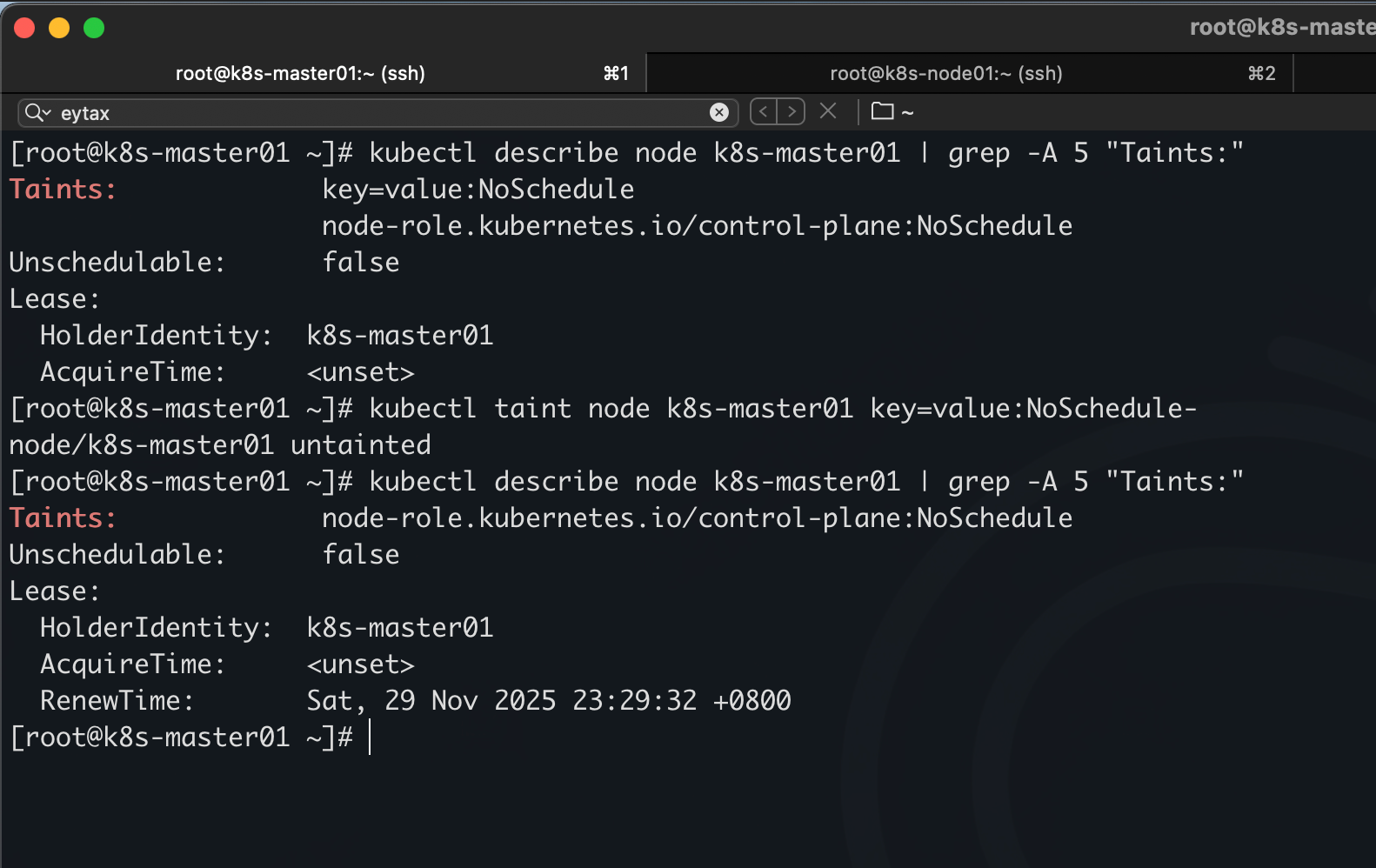
注意,如果有些为空的污点,不会显示,但是在删除的时候需要加上等于
比如污点查询出来是这个
node-role.kubernetes.io/control-plane:NoSchedule
删除的时候需要加上=
node-role.kubernetes.io/control-plane=:NoSchedule-
容忍
master 默认上不运行 pod 的,但是这些因为是 master 的核心组件,它们配置了容忍,所以可以在 master 上运行
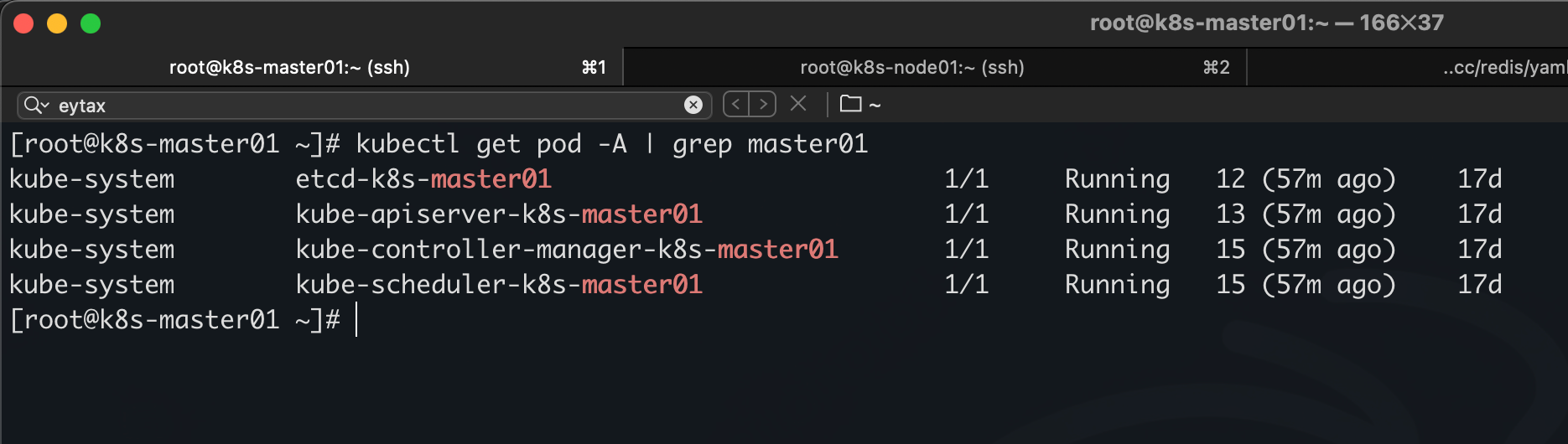
比如 etcd

设置了污点的 node 将根据污点的策略产生互斥,而通过配置 Pod 的容忍,那就可以调度了
配置容忍
operator 匹配方式
- Equal:精确匹配 key 和 value
- Exists:只要存在 key 就容忍,所以可以不写 value,如果都不写,代表容忍所有污点
精确匹配,key:value
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
只匹配 key
- key: "key2"
operator: "Exists"
effect: "NoSchedule"
都不匹配,全部容忍
tolerations:
- operator: "Exists"
如果有多 master 场景,或者资源很紧张,但是也没办法加 node, 在资源利用和稳定性中取个中间值比较合理,比如
将 master01配置为PreferNoSchedule(尽可能不调度 Pod )
kubectl taint node k8s-master01 node-role.kubernetes.io/control-plane=:PreferNoSchedule
固定节点调度
跳过调度器的预选/优选、亲和、污点这种策略,根据配置文件在指定的 pod 上运行 pod,场景:node2 上有高性能 GPU 用于 AI 训练,其它 node 上没有,通过直接指定就可以运行在 node2 上了,即使是 master 也行。
nodename
nodeName: k8s-node01 指定运行的 node
apiVersion: apps/v1
kind: Deployment
metadata:
name: nodename-test
spec:
replicas: 7
selector:
matchLabels:
app: nodename
template:
metadata:
labels:
app: nodename
spec:
nodeName: k8s-node01
containers:
- name: myweb
image: docker.xuanyuan.run/nginx:alpine
ports:
- containerPort: 80
nodeselect
指定运行 node,通过标签来指定
设置了一个 Pod 的标签:key=app,value=nodeselect,跟调度没关系,只是标识这个 pod 的标签
nodeSelector 节点选择器
- type: nodeselect
代表只会调度到有type: nodeselect 这个标签的节点上运行
apiVersion: apps/v1
kind: Deployment
metadata:
name: nodeselect-test
spec:
replicas: 2
selector:
matchLabels:
app: nodeselect
template:
metadata:
labels:
app: nodeselect
spec:
nodeSelector:
type: nodeselect
containers:
- name: myweb
image: docker.xuanyuan.run/nginx:alpine
ports:
- containerPort: 80
添加 node 的标签
kubectl label node k8s-node01 type=nodeselect

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 38
38 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)