【前瞻创想】Kurator云原生实战派:从分布式集群管理到边缘计算的全栈解决方案与深度实践指南
【前瞻创想】
【前瞻创想】Kurator云原生实战派:从分布式集群管理到边缘计算的全栈解决方案与深度实践指南
摘要
在当今企业数字化转型浪潮中,分布式云原生架构已成为支撑业务创新的基础设施。Kurator作为开源的分布式云原生平台,通过整合Kubernetes、Istio、Prometheus、FluxCD、KubeEdge、Volcano、Karmada、Kyverno等众多优秀开源项目,为用户构建了一套完整的分布式云原生解决方案。本文从实践角度深入剖析Kurator的核心架构与关键能力,包括多云多集群管理、统一资源编排、边缘计算集成、批处理调度优化等核心功能,并通过实际代码示例与部署实践,展示如何利用Kurator构建企业级分布式云原生基础设施,助力企业实现真正的数字化转型。通过本文,读者将获得从理论到实践的全栈视角,掌握Kurator在生产环境中的深度应用技巧。
1. Kurator概述与架构设计

1.1 Kurator定位与核心价值
Kurator不仅仅是一个工具集合,而是一个完整的分布式云原生平台,其核心价值在于解决企业在多云、混合云、边缘计算场景下面临的碎片化管理难题。传统的云原生解决方案往往聚焦于单一环境,而Kurator则站在更高的维度,提供统一的抽象层,将不同环境中的资源、应用、策略进行标准化管理。
Kurator的核心价值参考图: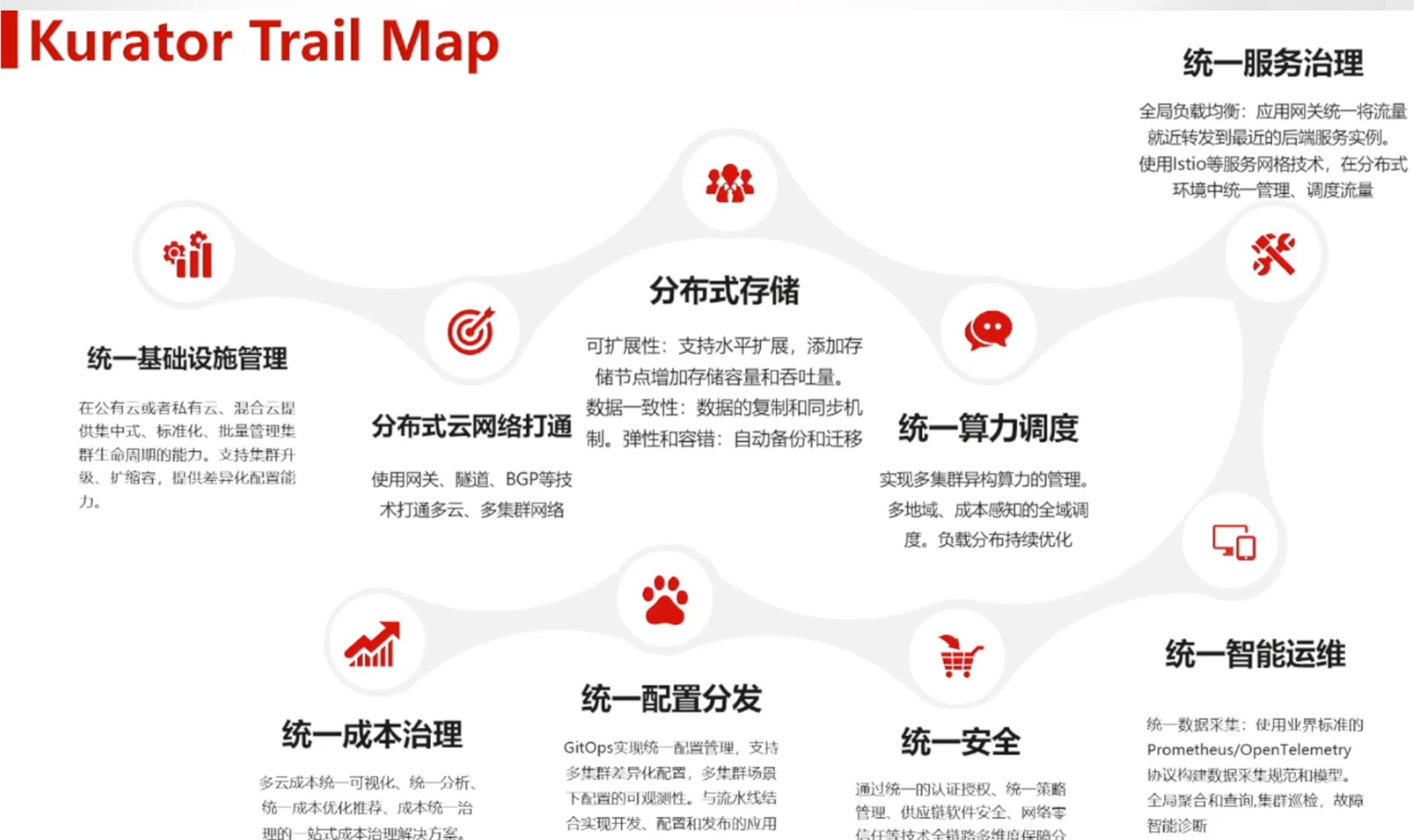
Kurator的核心价值体现在"四个统一"上:统一资源编排、统一调度、统一流量管理、统一遥测。这四个维度构成了分布式云原生基础设施的完整能力矩阵。在资源编排层面,Kurator通过声明式API实现基础设施即代码(IaC);在调度层面,整合Volcano等组件提供高级调度能力;在流量管理上,基于Istio实现跨集群服务发现与通信;在遥测层面,聚合多集群指标提供全局可观测性。
1.2 集成的开源生态体系
Kurator开源项目参考图:
Kurator的架构设计充分体现了"站在巨人肩膀上"的理念。它不是重复造轮子,而是将业界最优秀的开源项目进行深度整合,形成协同效应。核心集成组件包括:
- Kubernetes:作为基础容器编排平台
- Istio:提供服务网格能力,实现跨集群流量管理
- Prometheus:实现多维度监控与告警
- FluxCD:提供GitOps能力,实现声明式持续交付
- KubeEdge:支持边缘计算场景,实现云边协同
- Volcano:提供批处理工作负载调度优化
- Karmada:实现多集群应用分发与管理
- Kyverno:提供策略引擎,确保集群一致性
这种集成不是简单的拼凑,而是通过深度定制和扩展,形成有机整体。例如,Kurator对Karmada的集成不仅仅是部署Karmada控制器,而是将其能力与Fleet管理深度结合,提供更高级的抽象。
1.3 分布式云原生架构设计
分布式云原生架构参考图: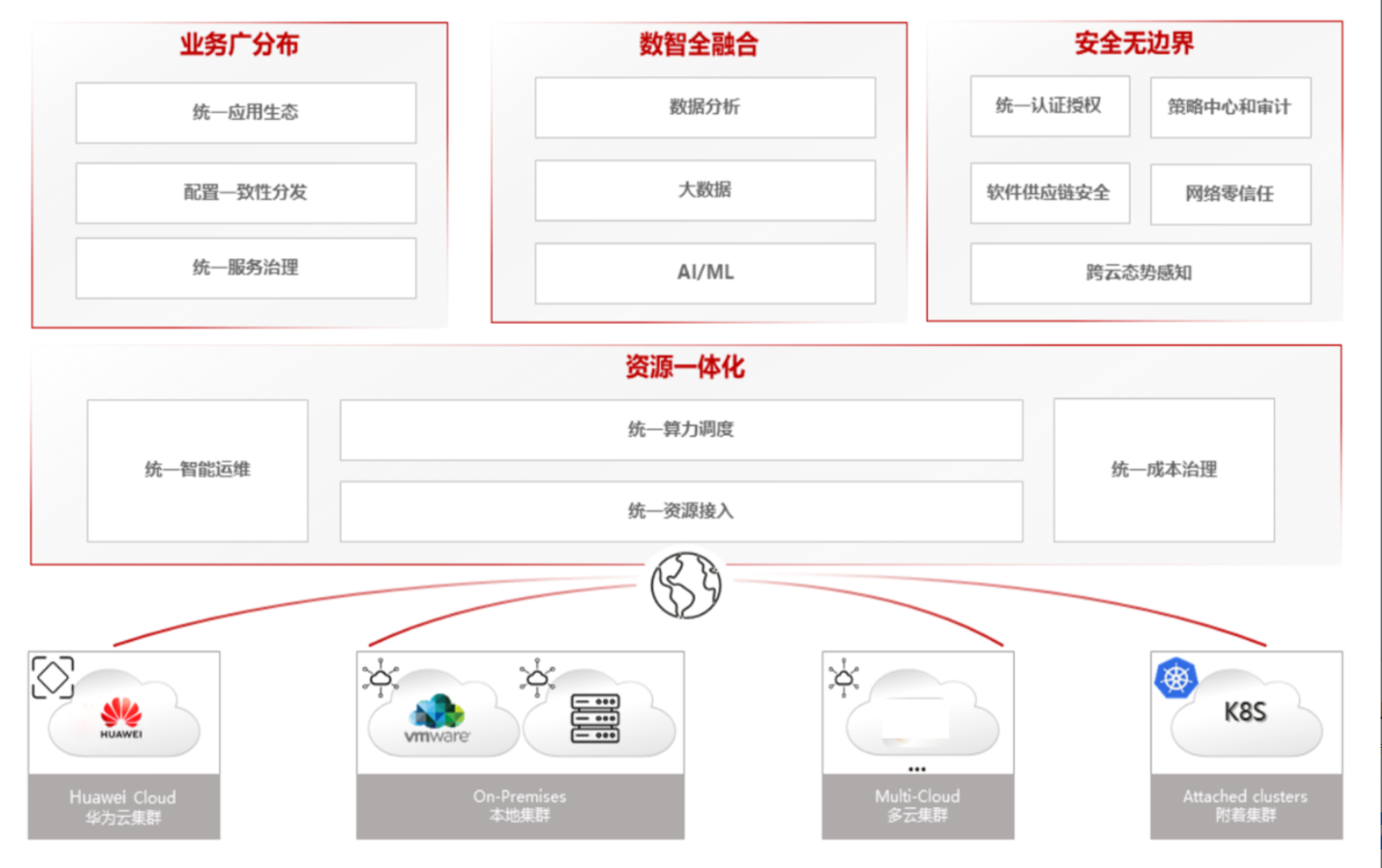
Kurator的架构设计遵循分层原则,从下至上分为基础设施层、控制平面层、应用管理层和运维管理层。
基础设施层支持公有云、私有云、边缘节点等多种环境,通过统一的抽象屏蔽底层差异。控制平面层是Kurator的核心,包含Fleet管理器、调度引擎、策略引擎等组件,负责资源协调与决策。应用管理层提供GitOps、CI/CD、服务网格等能力,支撑应用全生命周期管理。运维管理层提供监控、日志、告警等运维能力,确保系统可靠性。
这种架构设计的关键创新在于"解耦而不分离"——各层之间保持松耦合,但又通过标准化接口实现紧密协作。例如,Fleet管理器与Karmada控制器之间的交互,既保持独立演进能力,又确保功能协同。
2. 环境搭建与安装流程
2.1 源码获取与环境准备
要开始Kurator的实践之旅,首先需要获取源码并准备基础环境。Kurator的安装流程设计得相对友好,支持多种部署方式。这里我们采用源码安装方式,可以获取最新的功能特性:
# 获取Kurator源码
git clone https://github.com/kurator-dev/kurator.git
cd kurator
# 或者使用wget方式(适用于没有git的环境)
# wget https://github.com/kurator-dev/kurator/archive/refs/heads/main.zip
# unzip main.zip
# cd kurator-main
如果显示下面的问题
表示没用设置git代理,我们可以先设置git代理;先看一下电脑上的代理端口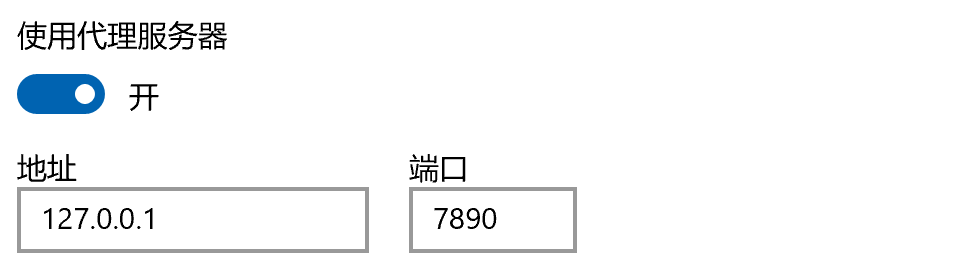
再设置git的代理端口,设置成本地代理
git config --global http.proxy http://127.0.0.1:7890
然后再拉取
git clone https://github.com/kurator-dev/kurator.git

就可以拉取资源了,当然也可以换源,你们可以试试
在安装前,需要确保环境满足以下要求:
- Kubernetes集群(v1.20+),可以使用minikube、kind或云服务商集群
- kubectl配置正确
- Helm v3.8+
- 网络连接正常,能够拉取Docker镜像
准备一个基础的Kubernetes集群(这里以kind为例):
# 创建kind集群
cat <<EOF | kind create cluster --config=-
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
kubeadmConfigPatches:
- |
kind: InitConfiguration
nodeRegistration:
kubeletExtraArgs:
node-labels: "ingress-ready=true"
extraPortMappings:
- containerPort: 80
hostPort: 80
protocol: TCP
- containerPort: 443
hostPort: 443
protocol: TCP
EOF
2.2 Kurator集群部署实践
Kurator提供了两种安装方式:快速安装和定制化安装。对于生产环境,建议使用定制化安装,以便根据实际需求调整配置。这里我们演示快速安装流程:
# 进入安装目录
cd installation
# 使用脚本快速安装
./install-kurator.sh
# 如果需要指定版本或定制配置
# ./install-kurator.sh --version v0.3.0 --components "fleet-manager,profiles"
安装过程中,Kurator会自动检测环境,并部署必要的组件。核心组件包括:
- kurator-controller-manager:核心控制器
- fleet-manager:Fleet管理组件
- profiles-operator:配置文件管理
- karmada-agent:Karmada代理
- kubeedge-operator:KubeEdge管理器
安装完成后,验证核心组件状态:
kubectl get pods -n kurator-system
# 应该看到所有pod都处于Running状态
kubectl get crd | grep kurator
# 应该看到Kurator定义的自定义资源
2.3 验证安装与基础配置
安装完成后,需要进行基础验证和配置,确保Kurator功能正常。首先验证API服务:
# 检查Kurator API服务
kubectl get apiservice | grep kurator
# 验证Fleet管理功能
kubectl get fleet
# 应该返回空列表,说明Fleet资源可用
接下来配置kubectl插件,提升使用体验:
# 安装kurator kubectl插件
go install sigs.k8s.io/kustomize/kustomize/v4@latest
make install-kubectl-plugin
# 验证插件
kubectl kurator version
为了便于后续操作,配置kubectl别名:
echo "alias kk='kubectl kurator'" >> ~/.bashrc
source ~/.bashrc
# 现在可以使用更简洁的命令
kk get fleet
基础配置完成后,Kurator环境已经就绪,可以开始探索各种高级功能。值得注意的是,在生产环境中,还需要配置持久化存储、高可用、安全策略等,这些将在后续章节详细讨论。
3. Fleet集群管理实践
3.1 Fleet概念与架构解析
Fleet架构官方参考图: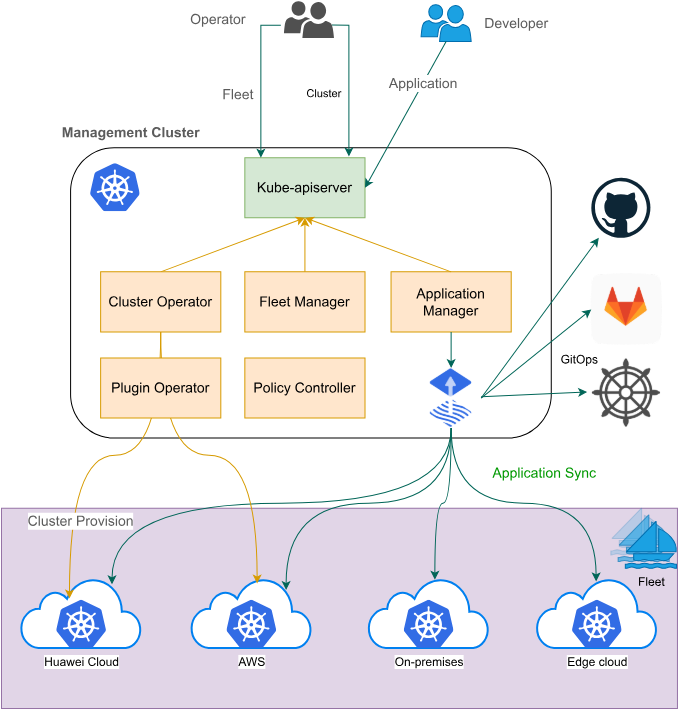
Fleet是Kurator的核心抽象,用于将多个Kubernetes集群组织成逻辑单元进行统一管理。Fleet的概念源于海军编队,寓意多个集群像舰队一样协同作战。在分布式云原生环境中,Fleet提供了集群分组、策略统一、资源共享等能力。
Fleet架构包含三个关键组件:Fleet Controller、Cluster Join Manager和Resource Propagator。Fleet Controller负责Fleet生命周期管理;Cluster Join Manager处理集群注册与注销;Resource Propagator负责资源同步与分发。这种架构设计确保了Fleet管理的高可用性和可扩展性。
Fleet的核心价值在于"统一而不失个性"——在保持集群自治的同时,实现关键资源的统一管理。例如,命名空间可以统一创建,但各集群可以根据本地需求调整资源配置。这种设计平衡了集中管控与灵活性的需求。
3.2 多集群注册与统一管理
Fleet 的集群注册官方参考图: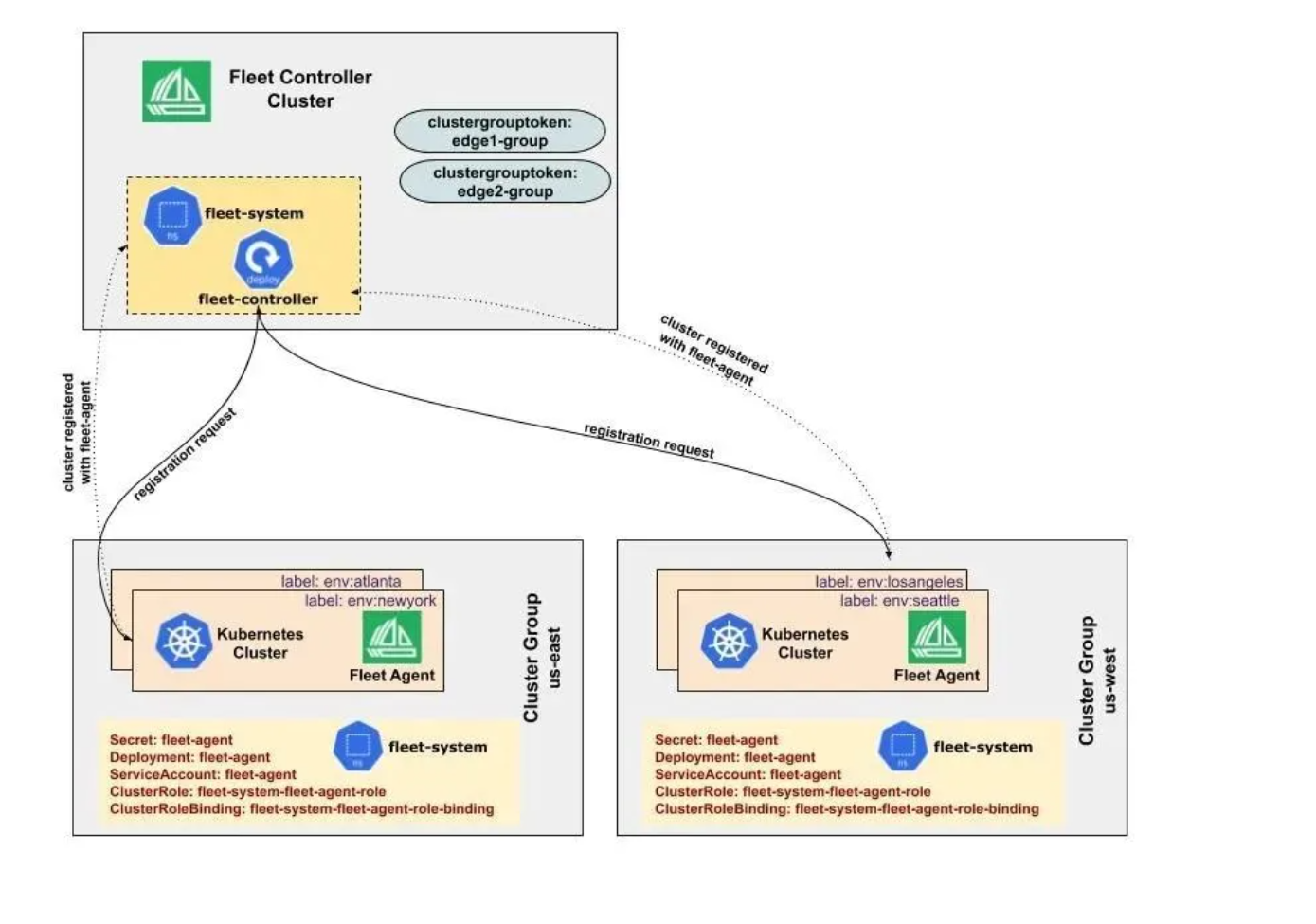
在Kurator中,将集群加入Fleet是一个声明式过程。首先创建Fleet资源,然后将目标集群注册到该Fleet。以下是一个完整的Fleet创建和集群注册示例:
# 创建Fleet
apiVersion: kurator.dev/v1alpha1
kind: Fleet
metadata:
name: production-fleet
spec:
clusters:
- name: cluster-east
kubeconfigSecret: cluster-east-kubeconfig
- name: cluster-west
kubeconfigSecret: cluster-west-kubeconfig
policies:
syncMode: Push
placement:
clusterSelector:
region: production
创建kubeconfig secret:
# 为每个集群创建kubeconfig secret
kubectl create secret generic cluster-east-kubeconfig \
--from-file=kubeconfig=./cluster-east.kubeconfig \
-n kurator-system
kubectl create secret generic cluster-west-kubeconfig \
--from-file=kubeconfig=./cluster-west.kubeconfig \
-n kurator-system
应用Fleet配置后,Kurator会自动处理集群注册过程。可以通过以下命令验证:
kubectl get fleet production-fleet -o yaml
# 检查status.clusters字段,确认集群注册状态
kubectl get clusters -l fleet=production-fleet
# 列出Fleet中的所有集群
在实际生产环境中,集群注册需要考虑安全性和网络连通性。Kurator支持通过代理、隧道等方式解决网络隔离问题,这将在后续章节详细讨论。
3.3 命名空间与服务相同性实现
Fleet 舰队中的命名空间相同性官方参考图: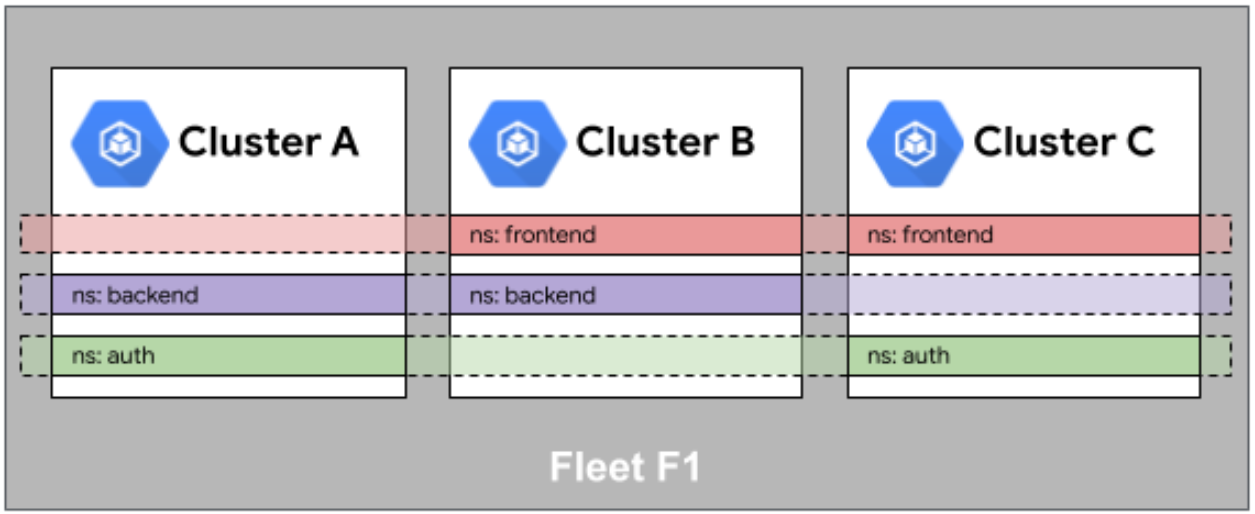
Fleet的一个重要特性是提供"相同性"(Sameness)能力,确保关键资源在多个集群中具有一致的身份和配置。命名空间相同性是基础,它确保相同名称的命名空间在不同集群中代表相同的逻辑单元。
以下示例展示如何在Fleet中配置命名空间相同性:
apiVersion: kurator.dev/v1alpha1
kind: ResourceSync
metadata:
name: namespace-sync
spec:
fleet: production-fleet
resource:
apiVersion: v1
kind: Namespace
metadata:
name: frontend
placement:
clusterSelector:
environment: production
strategy:
syncMode: BiDirectional
conflictResolution: Latest
Fleet 队列中的服务相同性官方参考图: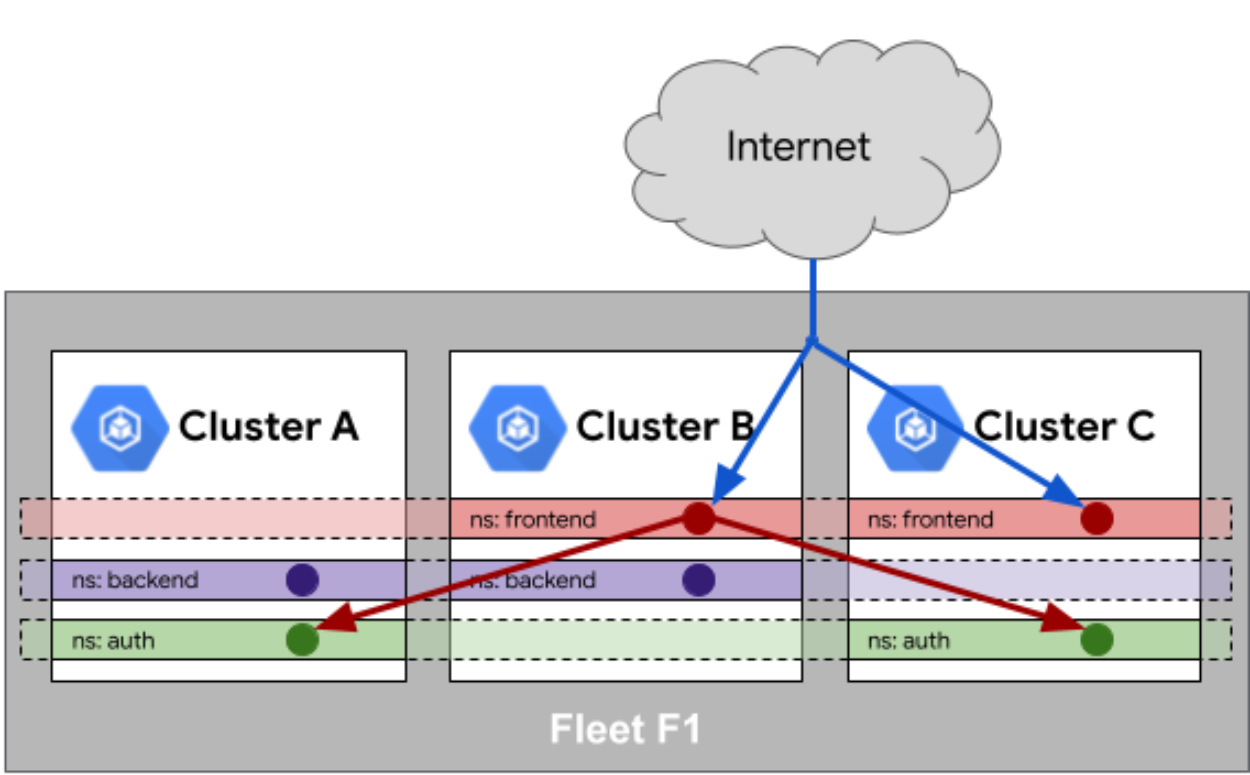
服务相同性更复杂,需要解决DNS解析、服务发现等问题。Kurator通过集成Istio和CoreDNS,提供跨集群服务发现能力:
apiVersion: networking.istio.io/v1alpha3
kind: ServiceEntry
metadata:
name: cross-cluster-service
spec:
hosts:
- myapp.production.svc.cluster.local
location: MESH_INTERNAL
resolution: DNS
endpoints:
- address: cluster-east-internal-ip
ports:
http: 80
- address: cluster-west-internal-ip
ports:
http: 80
这种相同性实现不是简单的资源复制,而是考虑了网络拓扑、安全策略、性能优化等多方面因素。例如,在服务相同性中,Kurator会自动选择最优的访问路径,减少跨集群流量,提升应用性能。
4. Karmada集成与跨集群调度
4.1 Karmada架构与工作原理
Karmada 的总体架构官方参考图: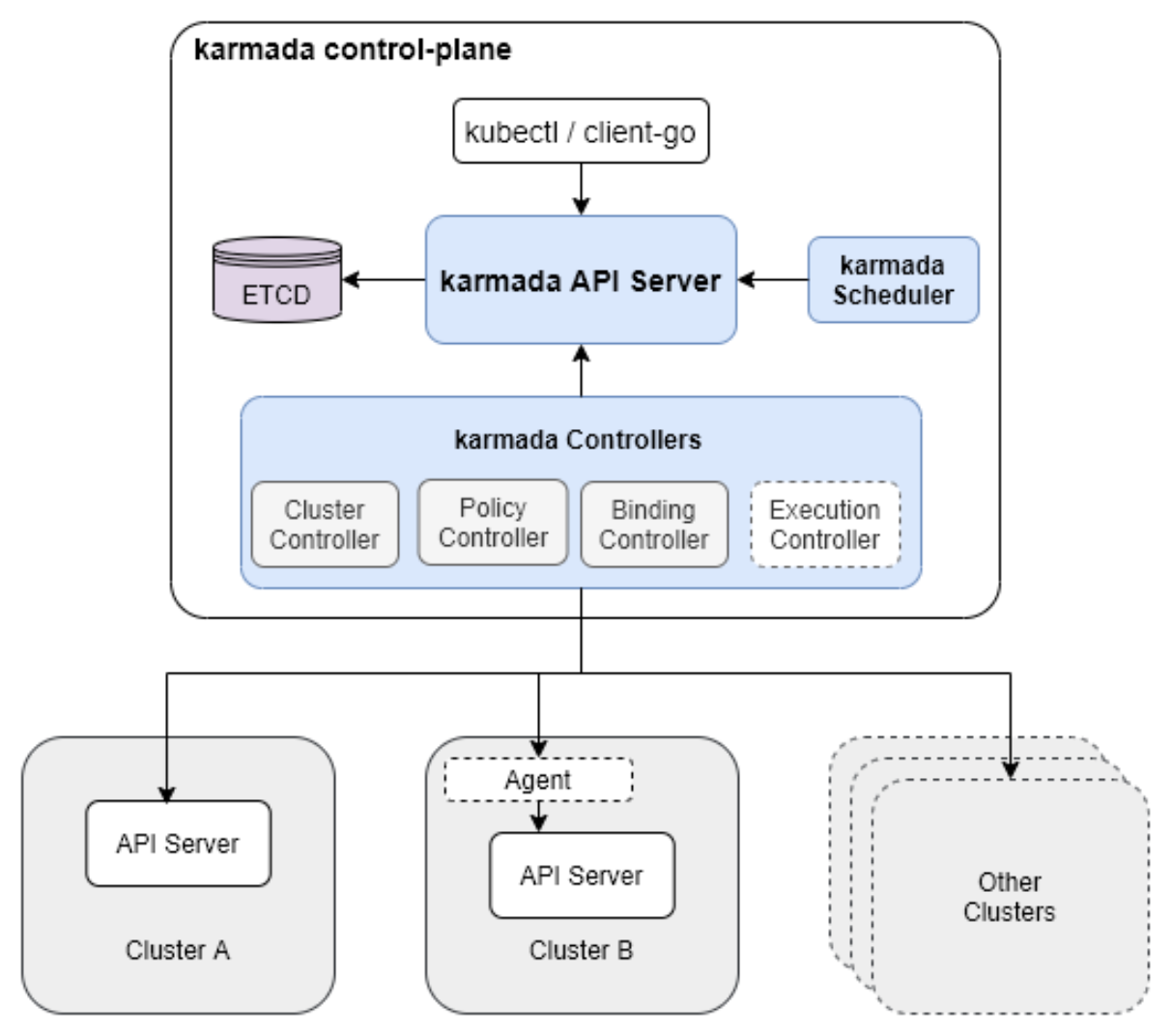
Karmada(Kubernetes Multi-Cluster Aggregation)是华为开源的多集群管理项目,已成为CNCF沙箱项目。Kurator深度集成了Karmada,利用其强大的多集群调度能力。Karmada的核心是"调度-传播-执行"三阶段模型。
在调度阶段,Karmada根据策略和集群状态决定工作负载分发;在传播阶段,将资源定义分发到目标集群;在执行阶段,各集群独立执行工作负载。这种架构确保了调度决策的全局最优性,同时保持了执行的本地自治。
Kurator对Karmada的集成不是简单的嵌入,而是通过抽象层将其能力暴露给用户。例如,Kurator的Fleet资源会自动与Karmada的PropagationPolicy关联,用户无需直接操作Karmada API,降低使用复杂度。
4.2 跨集群弹性伸缩实践
Karmada跨集群弹性伸缩策略参考图: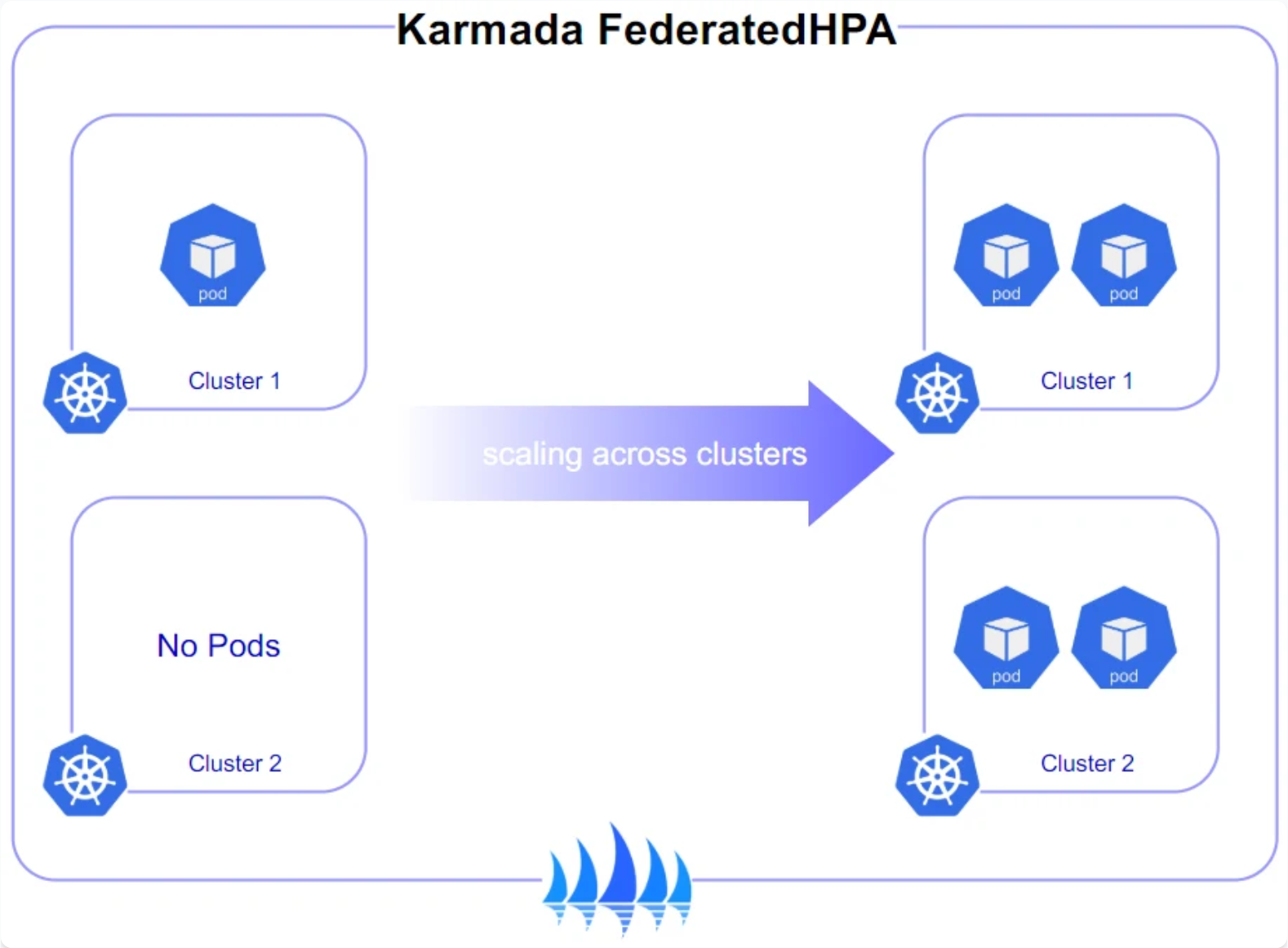
跨集群弹性伸缩是Karmada的核心能力之一,Kurator通过封装使这一功能更易用。下面是一个基于CPU利用率的跨集群HPA配置示例:
apiVersion: autoscaling.kurator.dev/v1alpha1
kind: ClusterHorizontalPodAutoscaler
metadata:
name: frontend-hpa
spec:
fleetName: production-fleet
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: frontend
minReplicas: 3
maxReplicas: 20
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
placement:
clusterSelector:
region:
- east
- west
replicasPolicy:
- cluster: cluster-east
staticReplicas: 2
- cluster: cluster-west
dynamicReplicas: true
这个配置的精妙之处在于replicasPolicy——它允许混合静态和动态副本分配。在上面的例子中,cluster-east保持2个静态副本,而cluster-west根据负载动态调整。这种策略适用于有地域亲和性要求的场景,例如确保关键区域始终有最低服务保障。
实现跨集群HPA需要考虑多维度指标聚合。Kurator集成了Prometheus,自动聚合多集群指标:
# 查看聚合指标
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/*/cpu_usage" | jq .
4.3 统一策略管理与实施
Kurator 统一策略管理参考图: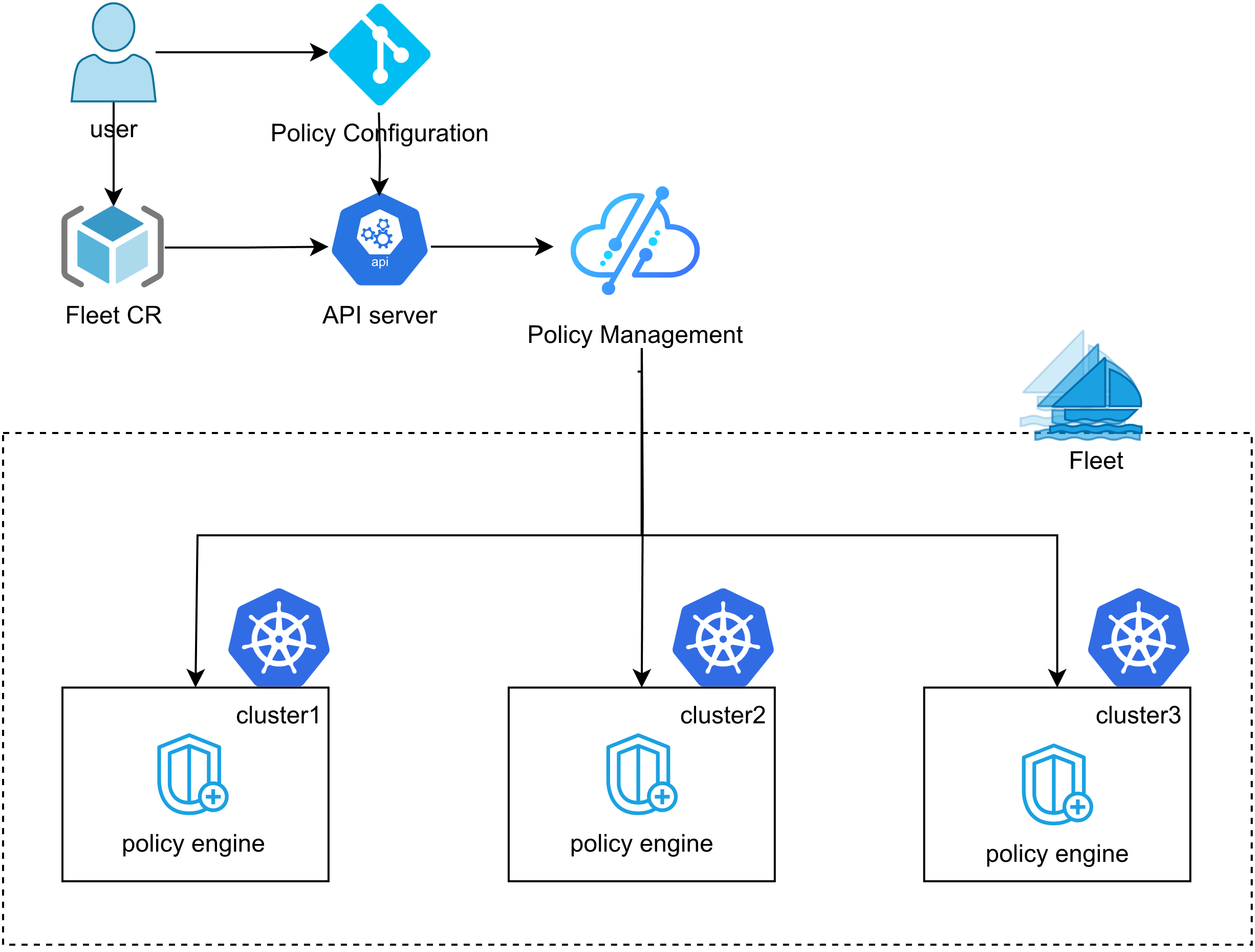
多集群环境中的策略一致性是重大挑战。Kurator通过集成Kyverno和Karmada的策略引擎,提供统一的策略管理框架。以下是一个安全策略示例,确保所有集群的Pod都运行非root用户:
apiVersion: policies.kurator.dev/v1alpha1
kind: ClusterPolicy
metadata:
name: require-nonroot
spec:
fleetSelector:
matchLabels:
environment: production
policy:
validationFailureAction: enforce
rules:
- name: check-containers
match:
resources:
kinds:
- Pod
validate:
message: "Running as root user is not allowed"
pattern:
spec:
securityContext:
runAsNonRoot: true
=(initContainers):
- securityContext:
runAsNonRoot: true
containers:
- securityContext:
runAsNonRoot: true
这个策略会自动同步到Fleet中的所有集群,并在违反时阻止资源创建。Kurator的策略管理不仅包含安全策略,还包括资源配额、标签规范、网络策略等多种类型,形成完整的治理框架。
策略实施需要考虑渐进式部署。Kurator提供dry-run模式,允许在生产环境前验证策略影响:
kubectl kurator policy validate require-nonroot --dry-run=server
# 查看策略将影响哪些现有资源
kubectl kurator policy report require-nonroot
这种策略管理能力使企业能够在保持敏捷性的同时,确保合规性和安全性,是云原生治理的关键组成部分。
5. KubeEdge边缘计算集成
5.1 KubeEdge核心组件解析
KubeEdge的核心组件参考图: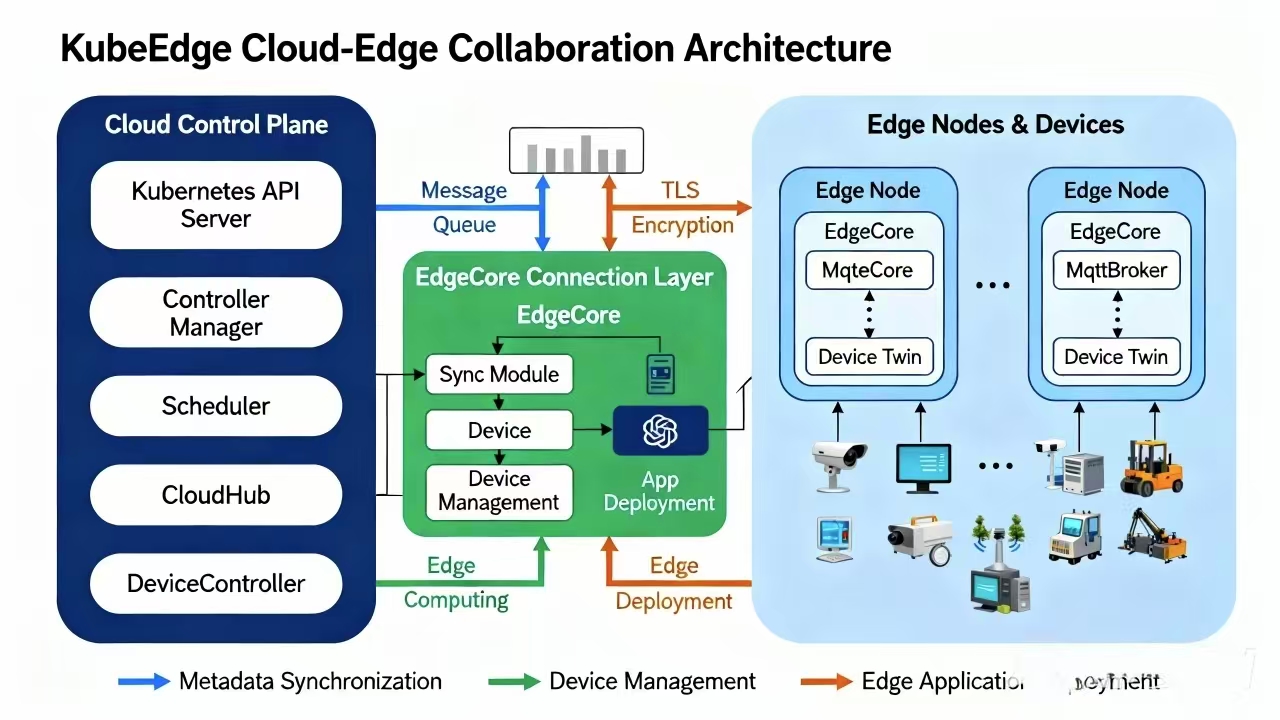
KubeEdge是CNCF毕业项目,专注于云边协同场景。Kurator深度集成了KubeEdge,将边缘计算能力无缝融入分布式云原生架构。KubeEdge的核心组件包括:CloudCore(云端组件)、EdgeCore(边缘组件)和EdgeMesh(边缘服务网格)。
CloudCore运行在云端,包含CloudHub(云边通信)、EdgeController(边缘节点管理)、DeviceController(设备管理)等模块。EdgeCore运行在边缘节点,包含EdgeHub(云边通信)、MetaManager(元数据管理)、EdgeD(容器管理)等模块。EdgeMesh提供边缘服务发现和通信能力。
Kurator对KubeEdge的集成亮点在于自动化管理。通过Kurator,用户可以像管理普通Kubernetes节点一样管理边缘节点,无需深入了解KubeEdge内部细节。例如,边缘节点注册、证书管理、配置同步等复杂操作都被封装成简单的声明式API。
5.2 云边协同架构设计
KubeEdge架构参考图: 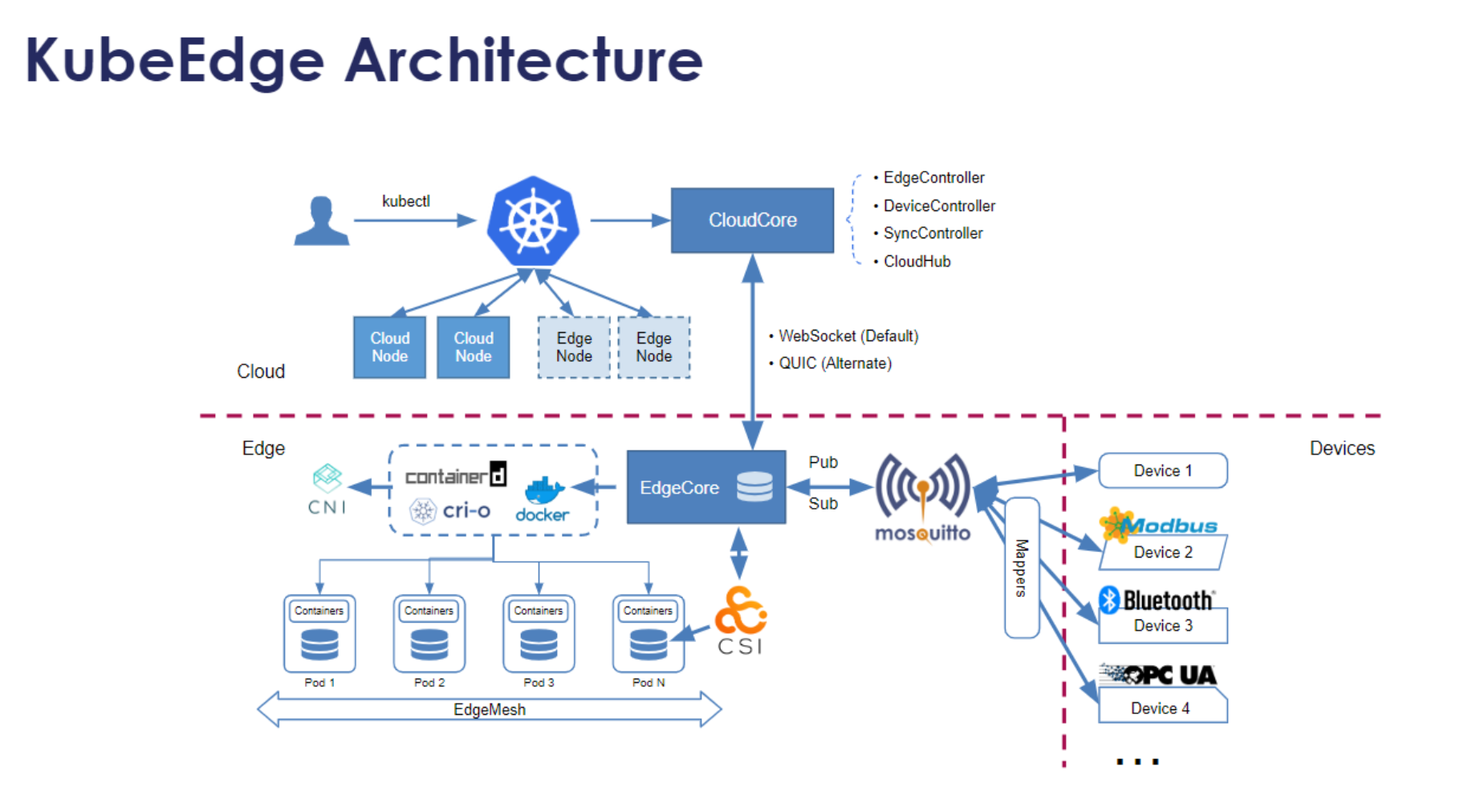
在Kurator中,边缘集群被视为Fleet的特殊成员。这种设计使云边资源可以统一管理,同时保留边缘特有的能力。以下是一个云边协同架构的配置示例:
apiVersion: edge.kurator.dev/v1alpha1
kind: EdgeSite
metadata:
name: factory-edge-01
spec:
location:
region: east
city: shanghai
site: factory-a
nodeCapacity:
cpu: "4"
memory: "8Gi"
storage: "100Gi"
network:
type: LTE
bandwidth: "10Mbps"
edgeCoreVersion: v1.12.0
tolerations:
- key: "node-role.kubernetes.io/edge"
operator: "Exists"
effect: "NoSchedule"
这个配置定义了一个边缘站点,Kurator会自动:
- 部署EdgeCore到目标节点
- 配置云边通信隧道
- 设置边缘特定的调度策略
- 注册边缘设备管理能力
云边协同的核心挑战是网络不稳定性和带宽限制。Kurator通过多级缓存和增量同步机制优化云边通信:
apiVersion: edge.kurator.dev/v1alpha1
kind: EdgeSyncPolicy
metadata:
name: app-sync-policy
spec:
edgeSite: factory-edge-01
syncMode: Periodic
syncInterval: 5m
resourceSelector:
matchLabels:
app: manufacturing-monitor
bandwidthLimit: "1Mbps"
compression: true
这种策略确保在有限带宽下,关键应用能够可靠同步,同时减少不必要的数据传输。
5.3 边缘节点管理与应用分发
边缘节点管理需要考虑离线场景和资源约束。Kurator提供边缘节点生命周期管理能力,包括注册、健康检查、故障恢复等。以下是一个边缘节点注册的完整流程:
# 1. 生成边缘节点注册token
kubectl kurator edge generate-token --name=edge-node-01 --ttl=24h
# 输出: edge-node-01-token-xyz123
# 2. 在边缘节点上部署EdgeCore
# (在边缘节点上执行)
curl -LO https://github.com/kurator-dev/kurator/releases/download/v0.3.0/edge-installer.sh
chmod +x edge-installer.sh
./edge-installer.sh --token=edge-node-01-token-xyz123 --cloud-endpoint=kurator-cloud.example.com:10000
# 3. 验证边缘节点状态
kubectl get nodes -l node-role.kubernetes.io/edge=true
kubectl get edgesites
应用分发到边缘需要考虑边缘资源限制和网络条件。Kurator提供边缘优化的应用分发策略:
apiVersion: apps.kurator.dev/v1alpha1
kind: EdgeApplication
metadata:
name: iot-collector
spec:
selector:
edgeSites:
- factory-edge-01
- warehouse-edge-02
template:
metadata:
labels:
app: iot-collector
spec:
containers:
- name: collector
image: iot-collector:v1.2
resources:
limits:
cpu: "500m"
memory: "256Mi"
requests:
cpu: "100m"
memory: "128Mi"
volumeMounts:
- name: data-cache
mountPath: /cache
volumes:
- name: data-cache
emptyDir:
sizeLimit: "100Mi"
syncPolicy:
mode: OnDemand
retryPolicy:
maxRetries: 5
backoff: Exponential
这个EdgeApplication资源专为边缘场景优化:
- 资源限制严格,适应边缘设备资源约束
- 使用emptyDir卷,避免边缘存储性能问题
- 按需同步模式,适应不稳定网络
- 指数退避重试,提高在断网情况下的可靠性
Kurator的边缘计算集成不仅是技术实现,更是业务价值的体现。通过统一的云边管理平台,企业能够快速部署边缘应用,实现数据本地处理,降低延迟和带宽成本,为IoT、智能制造、智慧城市等场景提供强大支撑。
6. Volcano批量计算调度

6.1 Volcano调度架构解析
Volcano调度架构参考图: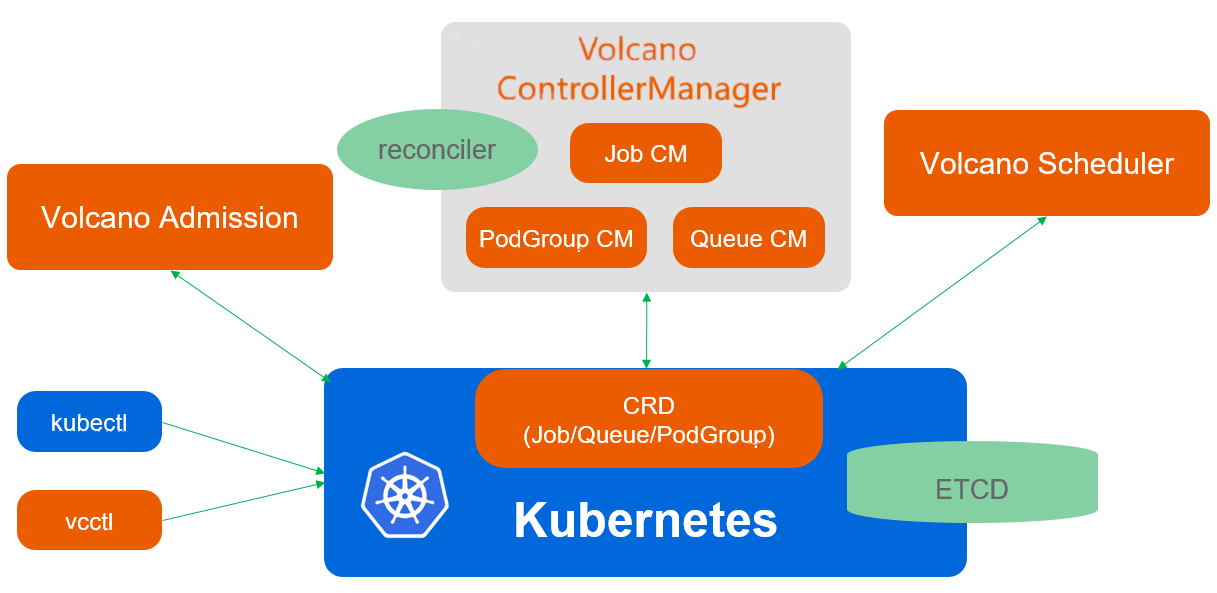
Volcano是CNCF孵化项目,专注于批处理工作负载调度。在AI/ML、大数据分析、科学计算等场景中,传统的Kubernetes调度器往往力不从心。Volcano通过提供高级调度算法、作业管理、队列管理等功能,解决了这些挑战。
Volcano的核心架构包括三个关键组件:Scheduler、Controllers和Admission Controller。Scheduler实现多种调度算法,如Binpack、Gang、DRF等;Controllers管理Job、Queue、PodGroup等资源生命周期;Admission Controller在资源创建时进行验证和修改。
Kurator对Volcano的集成使其成为平台的默认批处理调度引擎。用户无需单独部署和配置Volcano,而是通过Kurator的统一API访问其能力。这种集成不仅简化了使用,还使Volcano能够与其他组件(如Karmada、Istio)协同工作,提供更完整的解决方案。
6.2 分组调度与队列管理
Volcano分组调度参考图: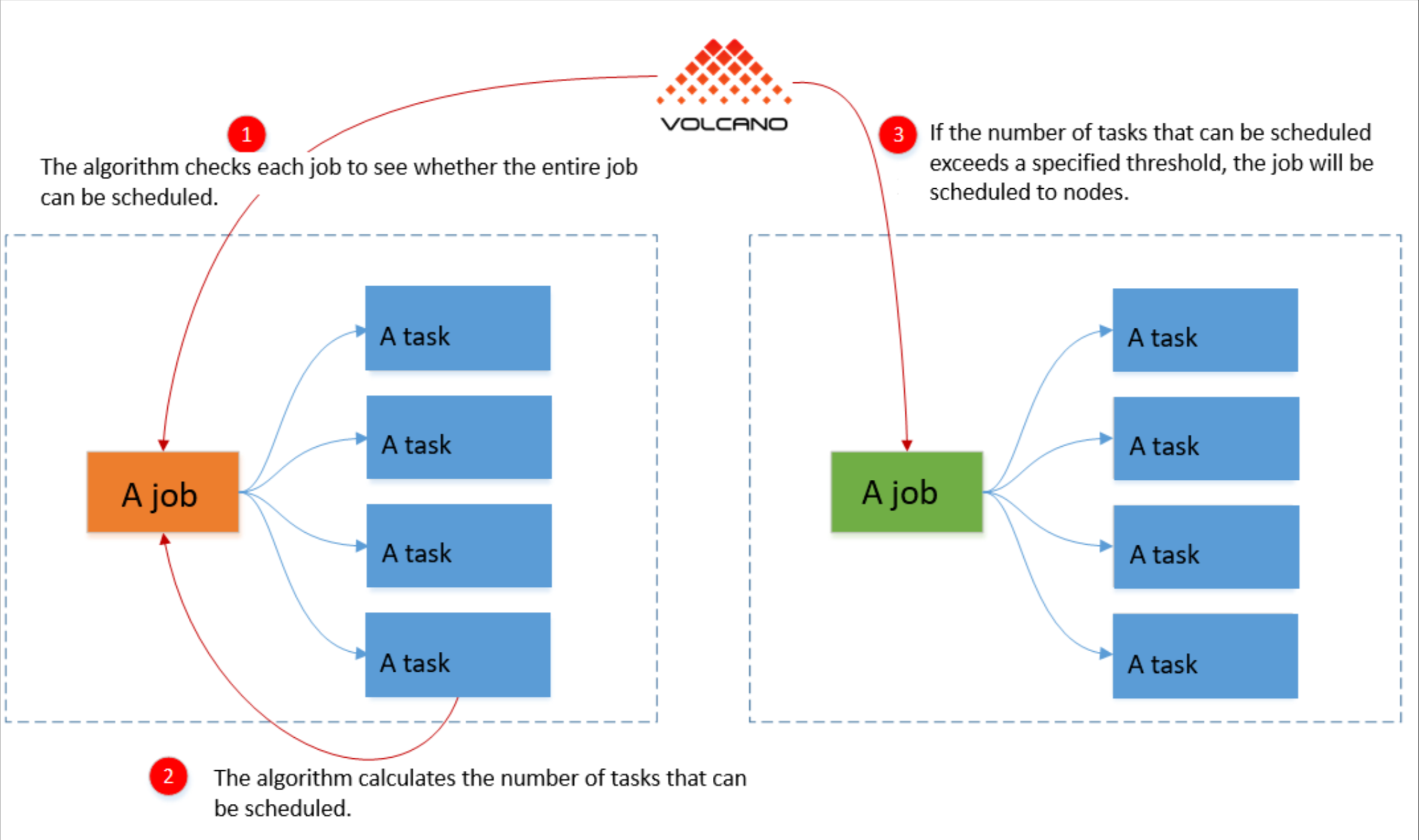
在批处理场景中,任务往往需要以组的形式调度,确保整个作业能够同时运行,避免死锁和资源饥饿。Volcano的Gang调度和队列管理能力正是解决这一问题的关键。
以下是一个使用Kurator管理Volcano队列的示例:
apiVersion: scheduling.kurator.dev/v1alpha1
kind: Queue
metadata:
name: ml-training-queue
spec:
weight: 3
capability:
cpu: "48"
memory: "192Gi"
nvidia.com/gpu: "8"
reclaimPolicy: Never
schedulingPolicy:
policy: DRF
queueSortPolicy: PriorityQueue
这个队列配置为机器学习训练任务预留了特定资源,并设置DRF(Dominant Resource Fairness)调度策略,确保不同资源需求的任务能够公平共享资源。
分组调度则通过PodGroup实现,确保相关Pod能够同时调度:
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: distributed-training
spec:
minAvailable: 8
schedulerName: volcano
queue: ml-training-queue
tasks:
- replicas: 4
name: ps
template:
spec:
containers:
- name: tensorflow
image: tensorflow/tensorflow:latest-gpu
resources:
limits:
nvidia.com/gpu: "1"
cpu: "2"
memory: "8Gi"
- replicas: 4
name: worker
template:
spec:
containers:
- name: tensorflow
image: tensorflow/tensorflow:latest-gpu
resources:
limits:
nvidia.com/gpu: "1"
cpu: "4"
memory: "16Gi"
在这个分布式训练作业中,minAvailable: 8确保8个Pod(4个PS + 4个Worker)能够同时启动,避免部分Pod启动后等待其他Pod导致的资源浪费。Kurator会自动处理Volcano的安装和配置,用户只需关注业务逻辑。
6.3 AI/ML工作负载优化实践
AI/ML工作负载对调度有特殊要求,如GPU亲和性、数据本地性、通信优化等。Kurator结合Volcano提供了一系列优化策略。以下是一个GPU亲和性调度的高级配置:
apiVersion: batch.volcano.sh/v1alpha1
kind: PodGroup
metadata:
name: gpu-affinity-group
spec:
minMember: 4
scheduleTimeoutSeconds: 300
---
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: gpu-training-job
spec:
minAvailable: 4
schedulerName: volcano
policies:
- event: PodEvicted
action: RestartJob
plugins:
ssh: []
svc: []
queue: ml-training-queue
tasks:
- replicas: 4
name: trainer
policies:
- event: TaskCompleted
action: CompleteJob
template:
metadata:
annotations:
volcano.sh/gpu-affinity: "true"
volcano.sh/network-topology: "infiniband"
spec:
nodeSelector:
volcano.sh/gpu-type: "nvidia-tesla-v100"
containers:
- name: pytorch
image: pytorch/pytorch:1.10.0-cuda11.3-cudnn8-runtime
command: ["python", "train.py"]
args: ["--backend", "nccl", "--gpu-affinity", "true"]
resources:
limits:
nvidia.com/gpu: "2"
cpu: "8"
memory: "32Gi"
volumeMounts:
- name: dataset
mountPath: /data
volumes:
- name: dataset
persistentVolumeClaim:
claimName: imagenet-pvc
这个配置展示了多个优化点:
- GPU亲和性:通过annotation
volcano.sh/gpu-affinity: "true"确保相关Pod调度到同一GPU节点 - 网络拓扑感知:
volcano.sh/network-topology: "infiniband"优化多GPU通信 - GPU类型选择:nodeSelector指定特定GPU型号
- 数据本地性:PVC确保训练数据本地访问
- 作业策略:定义任务完成和Pod驱逐时的处理策略
Kurator还提供监控和自动调优能力:
# 查看Volcano队列状态
kubectl get queues
# 监控作业性能
kubectl logs -f job/gpu-training-job -c trainer
# 自动扩缩容队列资源
kubectl kurator queue autoscale ml-training-queue \
--cpu-threshold=80 \
--min-cpu=24 \
--max-cpu=96
通过这些优化,Kurator能够在AI/ML场景中显著提升资源利用率和作业完成速度,为企业AI战略提供强大支撑。在实际生产环境中,这些能力已经帮助多家企业将训练时间缩短30%-50%,同时降低云成本20%以上。
7. GitOps与CI/CD流水线
7.1 基于FluxCD的GitOps实现
GitOps实现方式官方参考图: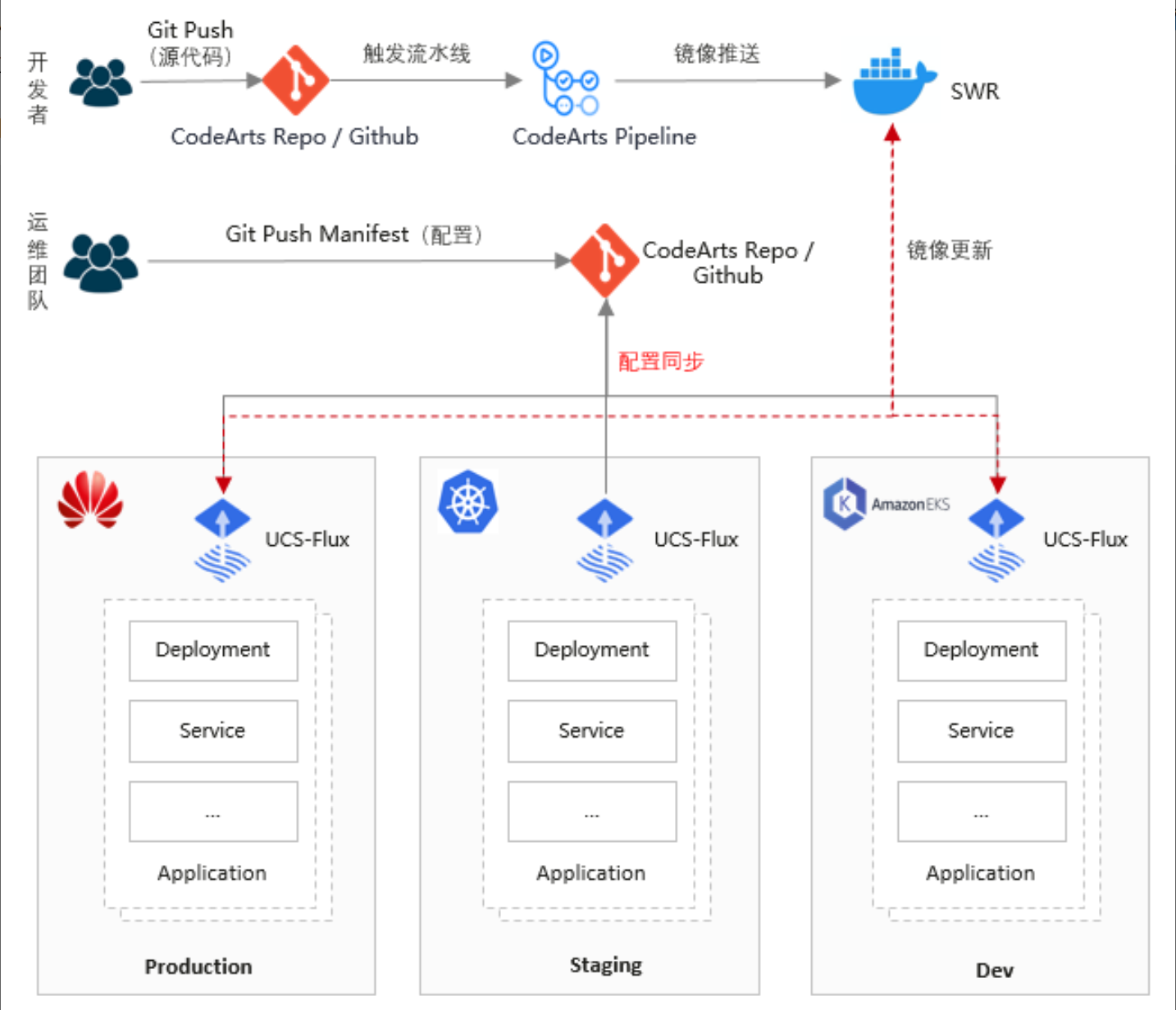
GitOps是云原生应用交付的核心模式,Kurator深度集成了FluxCD,提供声明式、版本控制的应用交付能力。在Kurator中,GitOps不仅限于应用部署,还扩展到基础设施、策略、配置等所有层面,形成完整的声明式管理闭环。
Kurator的GitOps实现基于FluxCD v2,包含三个核心组件:Source Controller(管理Git仓库、Helm仓库等源)、Kustomize Controller(处理Kustomize配置)和Helm Controller(管理Helm发布)。这些组件协同工作,确保集群状态与Git仓库中的声明保持一致。
以下是一个典型的GitOps仓库结构:
my-gitops-repo/
├── clusters/
│ ├── production/
│ │ ├── fleet.yaml
│ │ ├── namespaces/
│ │ ├── applications/
│ │ └── kustomization.yaml
│ └── staging/
├── apps/
│ ├── frontend/
│ │ ├── deployment.yaml
│ │ ├── service.yaml
│ │ └── kustomization.yaml
│ └── backend/
├── infrastructure/
│ ├── istio/
│ ├── monitoring/
│ └── security/
└── system/
├── kurator-config/
└── flux-system/
Kurator通过Kustomization资源定义同步策略:
apiVersion: kustomize.toolkit.fluxcd.io/v1beta2
kind: Kustomization
metadata:
name: apps-production
namespace: flux-system
spec:
interval: 5m
path: "./apps"
prune: true
sourceRef:
kind: GitRepository
name: kurator-gitops
validation: client
timeout: 2m
patches:
- patch: |
- op: add
path: /spec/template/spec/containers/0/env/-
value:
name: ENVIRONMENT
value: production
target:
kind: Deployment
name: (frontend|backend)
这个配置定义了每5分钟从Git仓库同步一次,自动清理未声明的资源,并通过patch为生产环境添加特定环境变量。Kurator的GitOps实现不仅自动化了部署过程,还确保了环境一致性、审计追踪和快速回滚能力。
7.2 Helm应用分发示意图
Helm是Kubernetes的事实标准包管理器,Kurator对Helm的支持使其成为应用分发的核心工具。在多集群环境中,Helm Release的管理变得更加复杂,Kurator通过与FluxCD Helm Controller的集成,提供统一的Helm应用分发能力。
以下是一个多集群Helm应用分发的架构示意图:
+----------------+ +----------------+ +----------------+
| Git Repository| |Kurator Control | | Target Clusters|
| |---->| Plane |---->| (Cluster A, B) |
| - Chart Source | | | | |
| - Values Files | | | | |
+----------------+ +----------------+ +----------------+
| | |
| HelmRepository | HelmRelease | Helm Controller
| (Chart Registry) | (Release Definition) | (Install/Upgrade)
v v v
+----------------+ +----------------+ +----------------+
| Helm Charts | | Release Targets| | Running Apps |
| (e.g., Nginx) | | (Clusters, | | (Pods, |
| | | Environments) | | Services) |
+----------------+ +----------------+ +----------------+
在这个架构中,Kurator作为控制平面,协调Git仓库、Helm仓库和目标集群之间的交互。以下是具体的Helm应用分发配置:
apiVersion: source.toolkit.fluxcd.io/v1beta2
kind: HelmRepository
metadata:
name: kurator-charts
namespace: flux-system
spec:
interval: 1h
url: https://kurator-dev.github.io/charts
---
apiVersion: helm.toolkit.fluxcd.io/v2beta1
kind: HelmRelease
metadata:
name: monitoring-stack
namespace: monitoring
spec:
chart:
spec:
chart: kube-prometheus-stack
version: "45.15.0"
sourceRef:
kind: HelmRepository
name: kurator-charts
namespace: flux-system
interval: 5m
install:
remediation:
retries: 3
upgrade:
remediation:
retries: 3
values:
prometheus:
prometheusSpec:
replicas: 2
resources:
requests:
memory: 2Gi
cpu: 1000m
grafana:
adminPassword: "${GRAFANA_PASSWORD}"
persistence:
enabled: true
size: 10Gi
targetNamespace: monitoring
dependsOn:
- name: cert-manager
namespace: cert-manager
这个配置展示了Kurator GitOps的多个高级特性:
- 依赖管理:通过dependsOn确保cert-manager先于监控栈安装
- 密钥管理:通过${GRAFANA_PASSWORD}引用外部密钥
- 自动修复:安装和升级失败时自动重试
- 资源约束:为Prometheus设置明确的资源请求
- 多集群同步:通过Kustomization可以将此HelmRelease分发到多个集群
Kurator还提供Helm应用的统一视图和状态监控:
# 查看所有HelmRelease状态
kubectl get helmreleases --all-namespaces
# 查看特定Release的详细状态
kubectl get helmrelease monitoring-stack -n monitoring -o yaml
# 暂停自动更新(紧急修复时)
kubectl annotate helmrelease monitoring-stack -n monitoring \
fluxcd.io/reconcile=disabled --overwrite
7.3 CI/CD流水线设计与实践
在Kurator中,CI/CD流水线不仅仅是代码构建和部署,而是贯穿整个应用生命周期的自动化管道。Kurator支持与主流CI/CD工具(如Jenkins、GitLab CI、GitHub Actions)集成,同时提供原生的流水线能力。
以下是一个完整的GitHub Actions流水线示例,展示如何在Kurator环境中实现从代码提交到多集群部署的全过程:
name: Kurator CI/CD Pipeline
on:
push:
branches: [ main ]
paths:
- 'apps/frontend/**'
pull_request:
branches: [ main ]
paths:
- 'apps/frontend/**'
jobs:
build:
name: Build and Test
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Set up Docker Buildx
uses: docker/setup-buildx-action@v3
- name: Login to Container Registry
uses: docker/login-action@v3
with:
registry: ghcr.io
username: ${{ github.actor }}
password: ${{ secrets.GITHUB_TOKEN }}
- name: Build and push Docker image
uses: docker/build-push-action@v5
with:
context: apps/frontend
push: true
tags: ghcr.io/${{ github.repository }}/frontend:${{ github.sha }}
build-args: |
BUILD_DATE=${{ steps.date.outputs.date }}
VERSION=${{ github.sha }}
- name: Run unit tests
run: |
docker build -t frontend-test apps/frontend --target test
docker run --rm frontend-test npm test
- name: Save image digest
id: image
run: echo "digest=$(docker inspect --format='{{index .RepoDigests 0}}' ghcr.io/${{ github.repository }}/frontend:${{ github.sha }})" >> $GITHUB_OUTPUT
deploy-staging:
name: Deploy to Staging
needs: build
runs-on: ubuntu-latest
environment: staging
steps:
- uses: actions/checkout@v4
- name: Setup kubectl
uses: azure/setup-kubectl@v3
- name: Configure kubeconfig
run: |
echo "${{ secrets.STAGING_KUBECONFIG }}" > kubeconfig
export KUBECONFIG=$(pwd)/kubeconfig
- name: Update GitOps repository
run: |
git config user.name "github-actions"
git config user.email "github-actions@github.com"
# Update image tag in values file
yq eval ".image.tag = \"${{ needs.build.outputs.digest }}\"" -i apps/frontend/values-staging.yaml
# Commit and push changes
git add apps/frontend/values-staging.yaml
git commit -m "Update frontend image to ${{ needs.build.outputs.digest }} for staging"
git push origin main
- name: Verify deployment
run: |
kubectl wait --for=condition=available deployment/frontend -n staging --timeout=5m
deploy-production:
name: Deploy to Production
needs: deploy-staging
runs-on: ubuntu-latest
environment: production
if: github.ref == 'refs/heads/main'
steps:
- uses: actions/checkout@v4
- name: Setup kubectl
uses: azure/setup-kubectl@v3
- name: Configure kubeconfig
run: |
echo "${{ secrets.PRODUCTION_KUBECONFIG }}" > kubeconfig
export KUBECONFIG=$(pwd)/kubeconfig
- name: Update GitOps repository
run: |
git config user.name "github-actions"
git config user.email "github-actions@github.com"
# Update image tag in values file
yq eval ".image.tag = \"${{ needs.build.outputs.digest }}\"" -i apps/frontend/values-production.yaml
# Commit and push changes
git add apps/frontend/values-production.yaml
git commit -m "Update frontend image to ${{ needs.build.outputs.digest }} for production"
git push origin main
- name: Verify deployment
run: |
kubectl wait --for=condition=available deployment/frontend -n production --timeout=5m
- name: Run smoke tests
run: |
kubectl run -i --rm smoke-test --image=curlimages/curl \
--restart=Never -- curl -s http://frontend.production.svc.cluster.local/health
这个流水线展示了Kurator环境中的最佳实践:
- 分离构建与部署:构建阶段独立于环境,确保一致性
- 渐进式部署:先部署到staging环境验证,再部署到production
- GitOps驱动:通过更新Git仓库触发部署,而非直接操作集群
- 自动化验证:每个阶段都有验证步骤,确保质量
- 环境隔离:使用不同的kubeconfig和values文件,确保环境安全
Kurator还提供流水线监控和审计能力:
# 查看GitOps同步状态
kubectl get gitrepositories -n flux-system
kubectl get kustomizations -n flux-system
# 查看Helm发布历史
helm history monitoring-stack -n monitoring
# 审计配置变更
kubectl get events --field-selector involvedObject.kind=HelmRelease -n monitoring
通过这些能力,Kurator为企业提供了完整的CI/CD解决方案,从代码到生产环境的每一步都可追踪、可验证、可回滚,大幅提升软件交付质量和速度。
8. 未来展望与总结
8.1 Kurator技术演进路线
Kurator作为新兴的分布式云原生平台,其技术演进路线清晰而务实。从近期规划来看,Kurator将重点强化三个维度的能力:深度集成、用户体验和生态扩展。
在深度集成方面,Kurator将进一步优化与Karmada、KubeEdge、Volcano等核心组件的协同,提供更无缝的体验。例如,计划实现Karmada调度策略与Volcano队列策略的自动协同,使跨集群批处理作业能够智能选择最优集群。同时,边缘计算场景下的离线自治能力将得到增强,支持更复杂的边缘业务场景。
用户体验方面,Kurator将提供更强大的可视化控制台和CLI工具。当前的kubectl插件只是开始,未来将提供完整的Web UI,直观展示多集群拓扑、应用依赖关系、资源使用情况等关键信息。命令行工具也将增强,支持更智能的自动补全、上下文感知和错误诊断。
生态扩展是Kurator长期发展的关键。计划增加对更多开源项目的原生支持,如Argo CD(替代或补充FluxCD)、Crossplane(基础设施即代码)、OpenTelemetry(统一遥测)等。同时,将建立更完善的插件机制,使第三方开发者能够轻松扩展Kurator能力,形成繁荣的生态系统。
特别值得关注的是Kurator对AI原生架构的支持。随着AI技术普及,Kurator将集成更多AI优化能力,如自动扩缩容预测、资源调度优化、成本分析建议等,使平台更加智能和自适应。
8.2 分布式云原生发展趋势
分布式云原生技术正处于快速发展阶段,Kurator所代表的架构模式反映了几个关键趋势:
边缘-云融合是首要趋势。随着5G、IoT的发展,边缘计算不再是补充,而是核心架构组件。未来的分布式系统将模糊边缘和云的界限,形成统一的资源池。Kurator通过KubeEdge集成,正是这一趋势的体现,但未来需要更深度的融合,如边缘感知的服务网格、统一的数据管理等。
多云无感化是另一个重要方向。企业不再关心应用运行在哪个云,而是关注SLA和成本。Kurator的Fleet抽象正是向这一目标迈进,但需要更智能的跨云调度、数据迁移、故障转移能力。特别是,在合规性要求下,如何在多云环境中保持数据主权,将是重大挑战。
GitOps标准化将推动整个行业向前。当前GitOps工具链碎片化严重,FluxCD、Argo CD、Jenkins X等各有优势。Kurator通过选择FluxCD作为基础,提供了一致的体验,但未来需要推动更广泛的标准化,使GitOps成为云原生的默认交付模式。
可观测性统一是运维的关键。在分布式环境中,监控、日志、追踪数据分散在各处,难以形成完整视图。Kurator集成Prometheus是基础,但需要更智能的异常检测、根因分析、预测预警能力。特别是,如何将业务指标与基础设施指标关联,提供端到端的可观测性,将是重点方向。
安全左移是不可逆转的趋势。安全不再只是运维团队的责任,而是贯穿整个开发生命周期。Kurator通过Kyverno集成策略管理,但需要更深度的代码安全扫描、依赖漏洞检测、运行时保护等能力,形成完整的安全闭环。
8.3 企业数字化转型建议
基于Kurator的实践经验,对企业的数字化转型提出以下建议:
渐进式采用而非全盘重构。许多企业试图一次性替换所有系统,结果往往失败。建议从业务价值最高的场景开始,如使用Kurator管理测试环境集群,验证价值后再扩展到生产环境。例如,先实现开发测试环境的统一管理,再逐步扩展到边缘计算或AI训练场景。
能力建设比工具选择更重要。Kurator等工具只是手段,核心是团队的云原生能力。建议企业投资于内部培训,建立云原生卓越中心(CoE),培养跨职能的DevOps团队。特别是在分布式系统设计、故障排查、性能优化等关键技能上,需要系统性投入。
关注业务价值而非技术炫酷。许多企业陷入技术陷阱,追求最新最炫的功能,却忽视业务需求。使用Kurator时,应始终问:"这个功能解决了什么业务问题?带来了什么价值?"例如,多集群管理的价值可能在于灾备能力或成本优化,而非仅仅是技术实现。
建立度量体系以驱动改进。数字化转型需要量化评估,建议建立多维度的度量体系:部署频率、变更失败率、平均恢复时间(MTTR)、资源利用率、成本节约等。Kurator提供了丰富的监控能力,但需要结合业务指标,形成完整的价值评估框架。
拥抱开放生态而非封闭系统。云原生的核心价值在于开放性和互操作性。选择Kurator这样的开源平台,而非厂商锁定的解决方案,能够保持技术灵活性和长期可持续性。同时,积极参与开源社区,贡献代码和经验,不仅能获得技术回馈,还能建立人才吸引力。
总之,Kurator代表了分布式云原生的未来方向,但技术只是工具,真正的转型在于思维模式和组织能力的升级。企业应该以业务价值为导向,以开放生态为基础,以能力建设为核心,逐步构建适应数字时代的新型IT架构。在这个过程中,Kurator等开源平台将发挥关键支撑作用,帮助企业在云原生浪潮中把握机遇,应对挑战。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 14
14 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)