【前瞻创想】别再被多集群搞崩心态了!手把手带你用Kurator一站式搞定云原生底座,从搭建到调度全流程实战复盘
【前瞻创想】别再被多集群搞崩心态了!手把手带你用Kurator一站式搞定云原生底座,从搭建到调度全流程实战复盘
咱们开篇先唠两句心里话。以前我也觉得,自己写脚本管几个集群不挺好吗?直到集群数量上了两位数,还要做跨云容灾和边缘计算的时候,我才发现自己太天真了。Kurator这玩意儿,最吸引我的其实是它那个“统一”的劲儿——统一的生命周期管理、统一的各种Operator整合。它不是重新造轮子,而是把轮子装成了一辆跑车。下面我就带大家看看这辆车怎么开。
一、 开局一把梭:环境搭建与集群生命周期管理
想玩转Kurator,第一步肯定是得把环境搭起来。很多人在这里就卡壳,其实没那么复杂。咱们不需要去各种官网找散件,直接用Kurator的一键式安装逻辑。
1. 极简环境搭建指南
说实话,官方文档有时候写得太细反而找不到重点。我自己在内网环境搭过好几次,总结下来核心就那么几步。首先,你得有一台哪怕是虚拟机的Linux机器,Docker得装好吧?K8s环境如果你不想折腾,Kind搞一个也行。
最关键的一步,把源码拉下来。别去瞎找别的源,直接用这个,速度和稳定性都还可以.可以看到这是项目的gitCode源码
我们可以拉取下来
git clone https://github.com/kurator-dev/kurator.git
源码文件如下,接下来就可以使用了
可以注意到,这个命令kurator version可以看到版本号
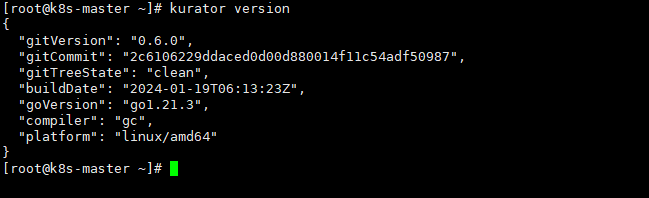
拉下来之后,重点看那个 Makefile,里面藏着很多快捷命令。搭建的核心在于把 kurator-controller-manager 跑起来,它是一切的大脑。
2. Kurator集群生命周期管理
这是Kurator集群生命周期管理的详细参考图,展示了从用户声明、多租户插件配置,到控制器协同工作实现异构集群统一纳管的全过程。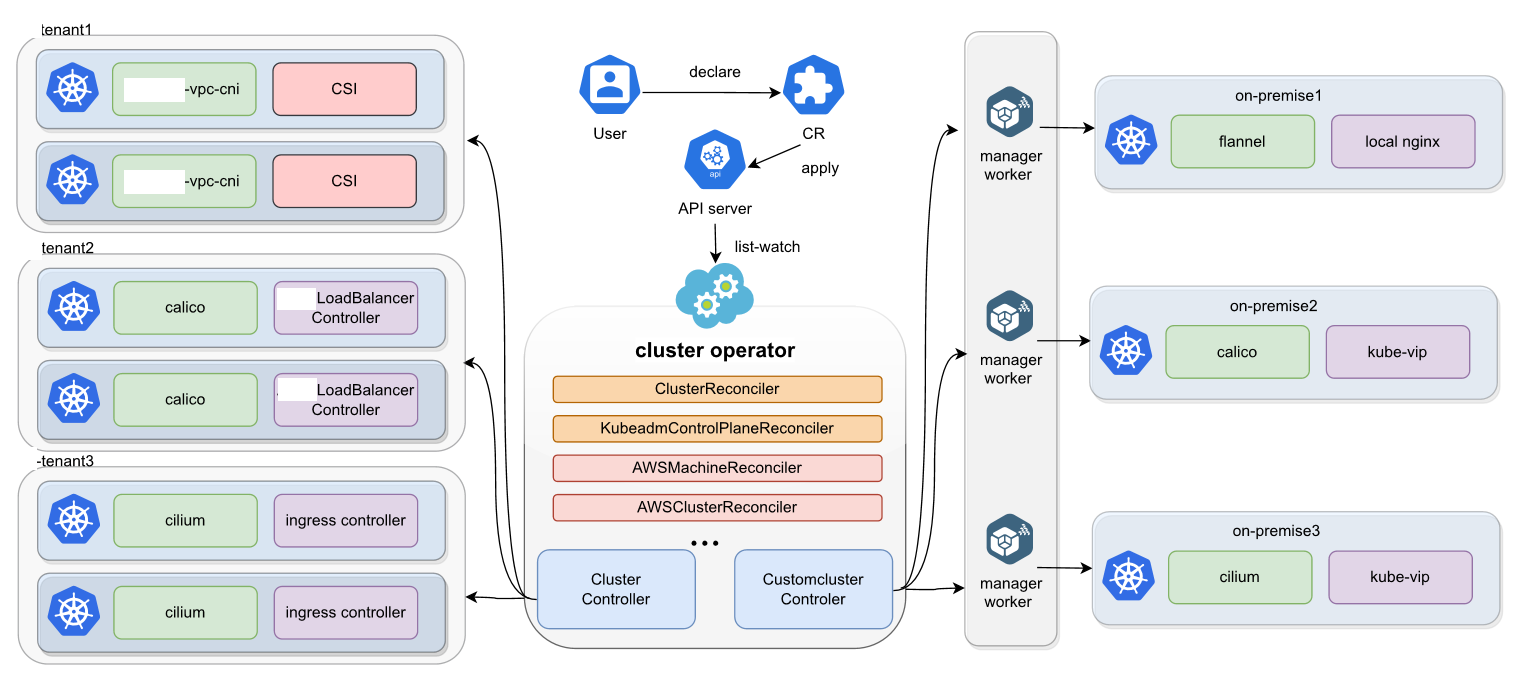
环境弄好后,咱们得聊聊“生孩子”的事儿——也就是集群生命周期管理。以前我们建集群,Terraform写一套,Ansible写一套,乱得很。Kurator引入了一套统一的API。
它能在你现有的基础设施上(比如AWS、阿里云或者本地Bare Metal)直接Provisioning集群。它的逻辑是“声明式”的。你告诉它:“我要一个3主3从的集群,版本1.28”,它就给你变出来。它底层其实封装了Cluster API,但屏蔽了那些复杂的细节。最爽的是,它把集群的升级、扩容、销毁都变成了一个CRD对象的修改,改完YAML,Controller自动干活,这才是云原生该有的样子。
3. 集群资源的拓扑结构
这张图展示了集群资源的拓扑结构,清晰地呈现了从控制平面到机器部署的各个组件如何关联,比如Cluster、Control Plane和MachineDeployment之间的引用关系,帮助理解Kubernetes集群的构建逻辑: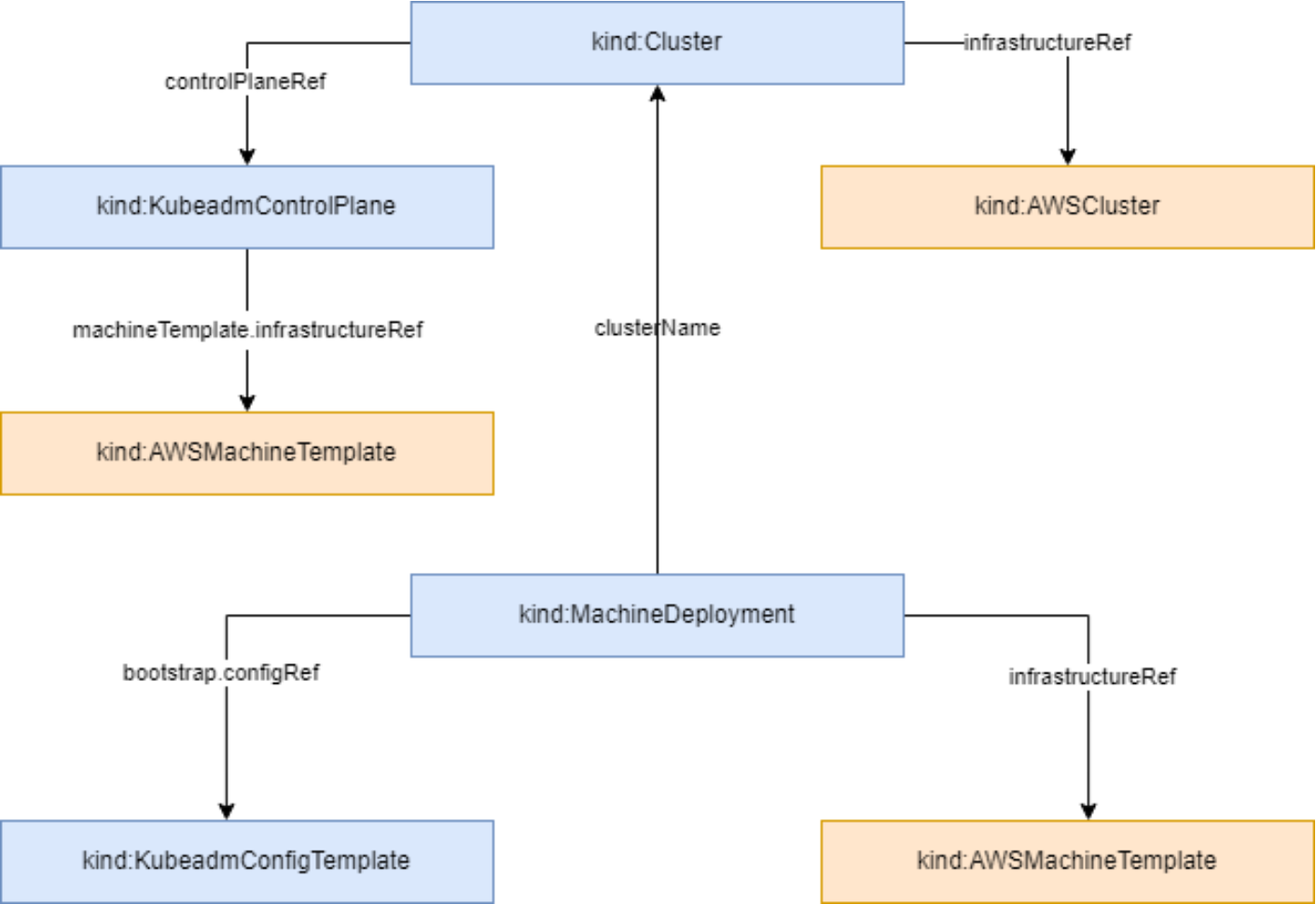
集群建好了,长啥样?这就涉及到集群资源的拓扑结构。在Kurator的视图里,资源不是扁平的,而是有层级的。它会自动识别你的节点所在的Zone、Region,构建出一个立体的拓扑图。这对于后面的调度至关重要。比如,你有一个业务必须跨可用区高可用,Kurator读取到的拓扑结构就能告诉调度器:“嘿,这两个副本别塞在一个机架上。”这种拓扑感知能力,是它区别于普通脚本管理的核心。
二、 核心大脑拆解:Karmada架构与Kurator Operator
底座有了,咱们得看看这里面到底是谁在指挥。这部分稍微硬核一点,但弄懂了你就是组里的架构师。
1. Kurator Cluster Operator的整体架构
这张图展示了Kurator Cluster Operator的整体架构,它通过监听API Server的资源变化,自动管理不同环境下的集群和机器: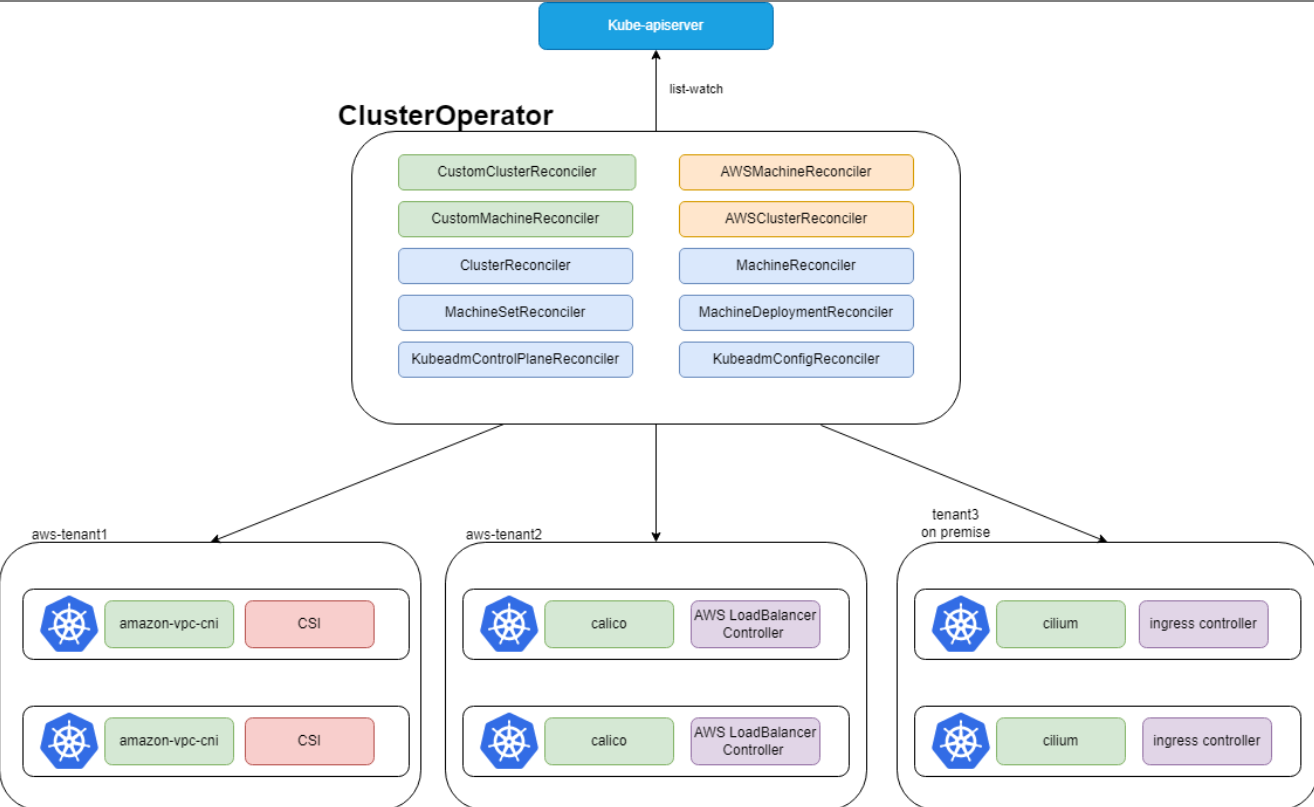
这个Operator是Kurator的亲儿子。它的架构设计非常精妙,主要由三个部分组成:API Server、Controller Manager和各个插件的Adaptor。
简单来说,Cluster Operator 就像个包工头。你发个指令说“我要安装Prometheus监控套件”,它不会自己去下Helm包,而是去调用内部集成的组件管理器。它维护着一个状态机,时刻监控着子集群里组件的健康状态。如果某个组件挂了,它会尝试自动重启或者告警。它的架构核心在于“解耦”,底层的K8s版本变了,Operator不用大改,只需要更新一下对应的Driver就行。
2. Karmada多集群管理平台的总体架构
这是Karmada多集群管理平台的总体架构图,展示了其控制平面如何通过各类控制器实现策略分发与跨集群资源协同: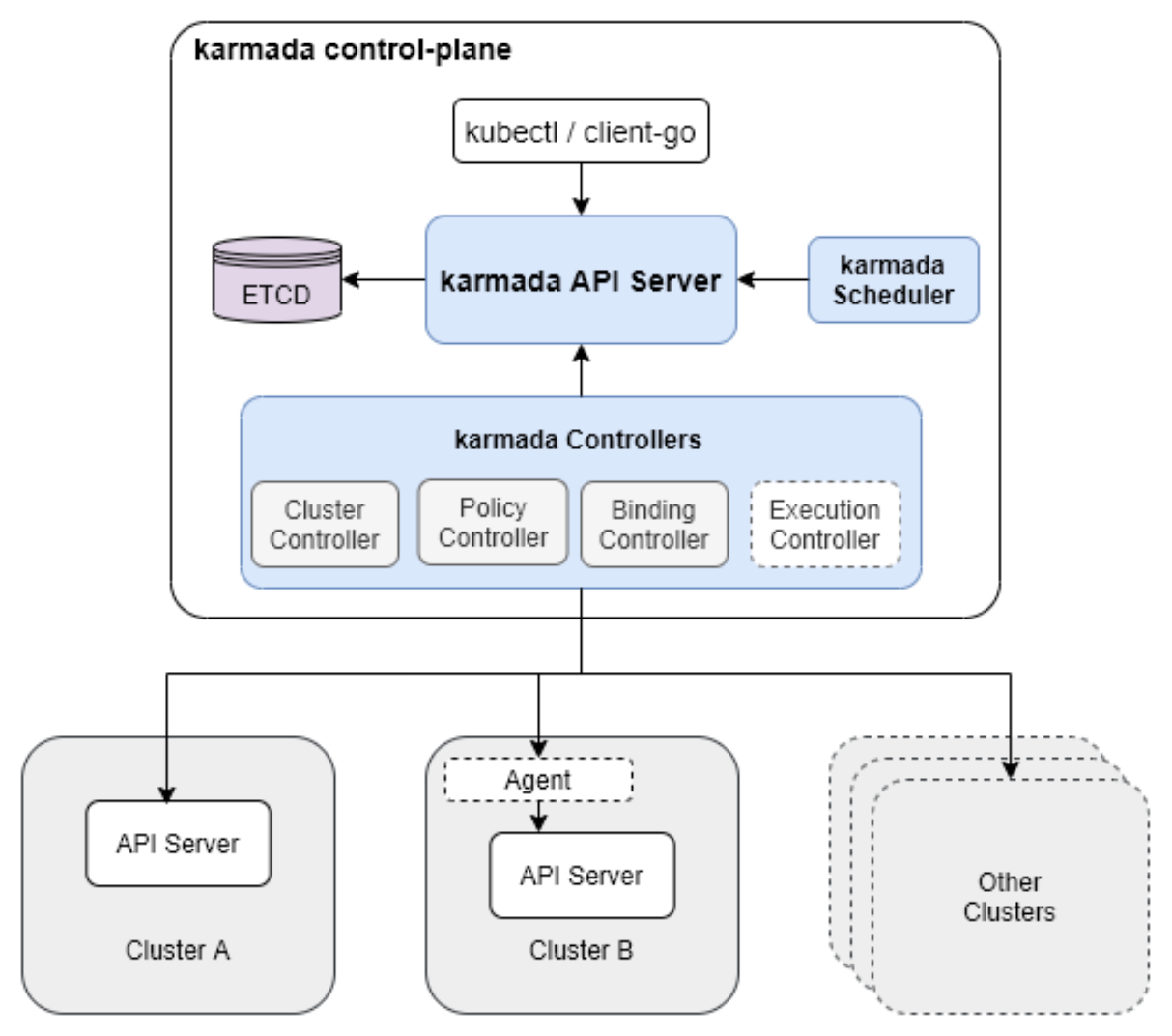
Kurator的多集群能力,其实很大程度上是站在Karmada肩膀上的。Karmada的架构大家得熟悉,经典的控制面(Control Plane)和数据面(Data Plane)分离。
- Karmada API Server:你跟它说话的地方,兼容K8s原生API。
- Karmada Controller Manager:负责把你的资源清单(Manifest)转换成不同集群能懂的语言。
- Karmada Scheduler:这个是核心,咱们后面细说。
在Kurator里,Karmada被无缝集成进去了。你甚至感觉不到它的存在,但其实你每一次跨集群发应用,都是Karmada在后面默默扛下了所有。
3. Kurator核心价值的全景路线
聊到架构,不得不提Kurator的核心价值全景路线。我研究了他们的Roadmap,发现野心很大。从最底层的多云/混合云基础设施屏蔽,到中间层的统一应用分发与治理,再到最上层的AI与边缘计算赋能,这是一条非常清晰的路线。
现在的版本,重点在于“统一”。统一的监控、统一的日志、统一的策略。未来我看它会往“智能化”走,比如根据成本自动调度Pod去便宜的云节点,这才是我们这种穷鬼公司最需要的功能啊!
三、 流量与任务的指挥棒:调度引擎与GitOps流水线
集群多了,应用怎么发?流量怎么走?任务怎么排?这一章节咱们聊聊实操中最高频的场景。
1. Karmada调度引擎与Volcano调度器工作流
这里有两个调度器,别搞混了。
Karmada调度引擎管的是“宏观”。比如你有一个Deployment,要分发到北京、上海、广州三个集群。Karmada的调度器会根据你定义的策略(比如地域亲和性、集群剩余资源)来决定哪个集群分多少个Pod。它支持动态权重,非常灵活。
Volcano调度器工作流管的是“微观”,特别是针对AI和大数据任务。在Kurator里集成Volcano后,工作流是这样的:
一个批处理作业提交上来 -> Volcano通过Queue机制排队 -> 根据Gang Scheduling(帮派调度)策略,判断资源够不够 -> 够了一起起,不够都不起,防止死锁。
看一段我平时用的Volcano Job配置,这是手写的,大家感受下那种“All or Nothing”的配置感:
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: training-job-demo
spec:
minAvailable: 3 # 重点看这,不到3个资源咱们就不开工
schedulerName: volcano
tasks:
- replicas: 3
name: "tensorflow-worker"
template:
spec:
containers:
- image: my-repo/tf-gpu:v2.1
name: worker
# 资源限制一定要写准,不然调度器算不准
resources:
requests:
cpu: "4"
memory: "8Gi"
restartPolicy: OnFailure
2. GitOps流水线的操作流程
这是GitOps流水线的操作流程图,展示了从代码变更、镜像构建到配置更新与生产环境自动部署的完整工作流。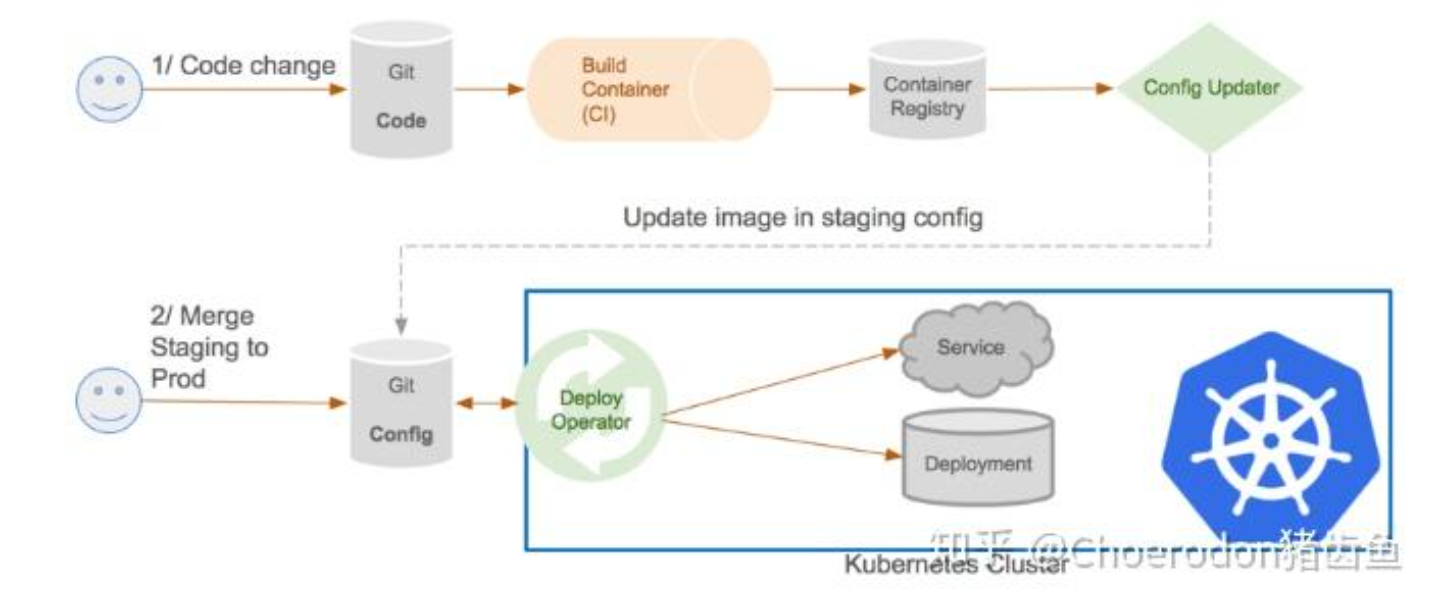
现在谁还没个GitOps啊?在Kurator里,GitOps流水线是打通开发和运维的桥梁。通常我们会结合ArgoCD或者Flux。
流程是这样的:
开发人员把代码推到Git -> CI流水线打镜像 -> 更新Git仓库里的Manifest文件(比如Helm Values) -> Kurator监测到Git变动 -> 自动同步到管理平面 -> 这里的关键点来了,Kurator会根据之前定义的Fleet集群注册机制,识别出这套配置该发给哪一组集群。
3. Fleet集群注册机制
这是Fleet集群注册机制的官方示意图,展示了中央控制器如何通过令牌统一纳管边缘及多区域集群: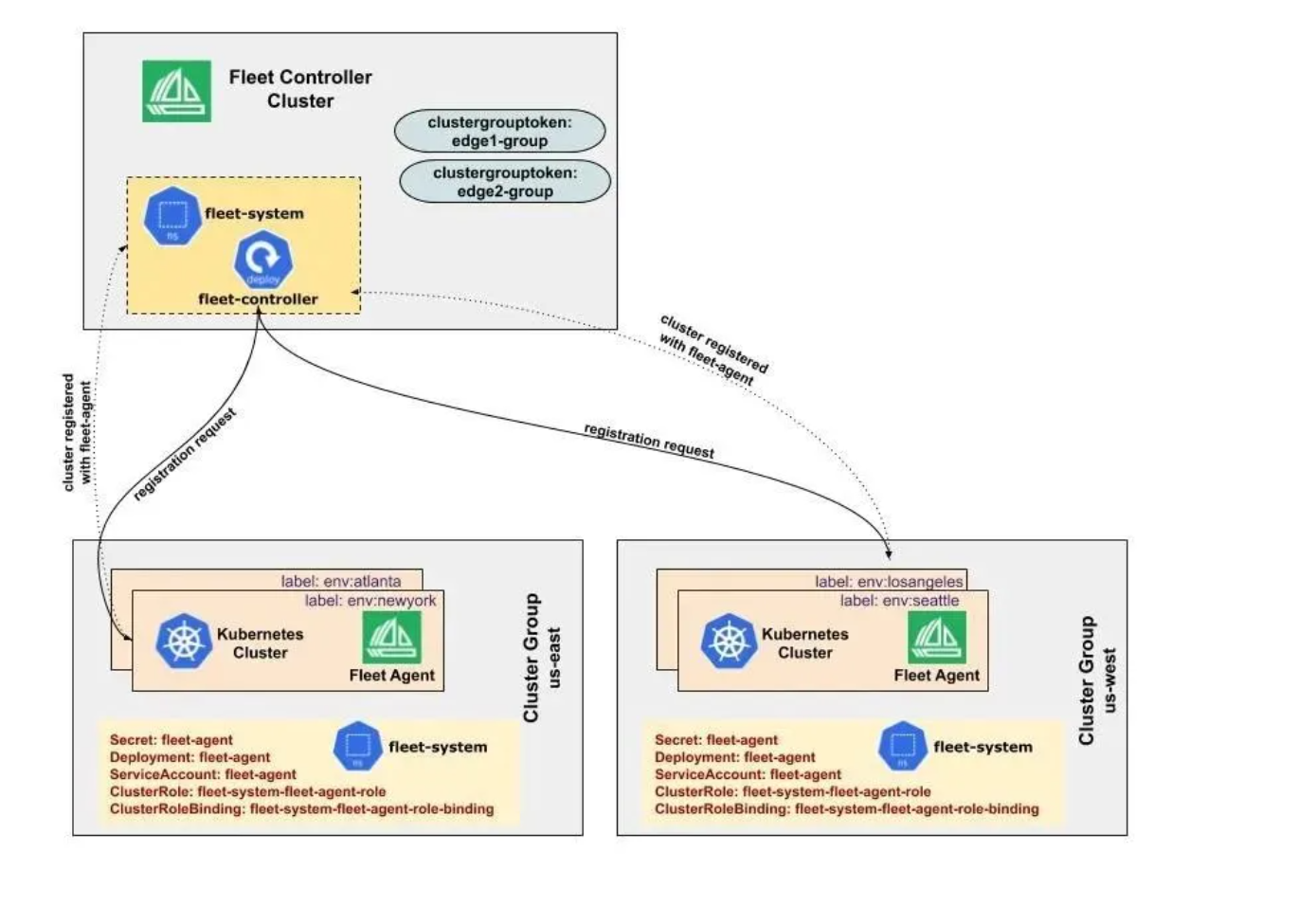
这就接上了。Fleet机制就是给集群“打标签、分组”。新集群加入时,通过Agent向控制面注册。比如这台机器打上 env: production, region: cn-north。GitOps流水线在同步时,只认标签。这样你就在Git里改一行代码,几十个生产环境的集群就全同步了,效率高得吓人,当然,要是配错了,炸得也挺壮观。
四、 进阶玩法:边缘计算、迁移与蓝绿发布
这部分属于高阶选手的领域了。如果你能把这块玩溜,涨薪是迟早的事。
1. KubeEdge架构的工作流程
这是KubeEdge架构的工作流程参考图,展示了云端控制器如何通过CloudHub与边缘节点通信,实现应用下发和设备管理的完整协同链路: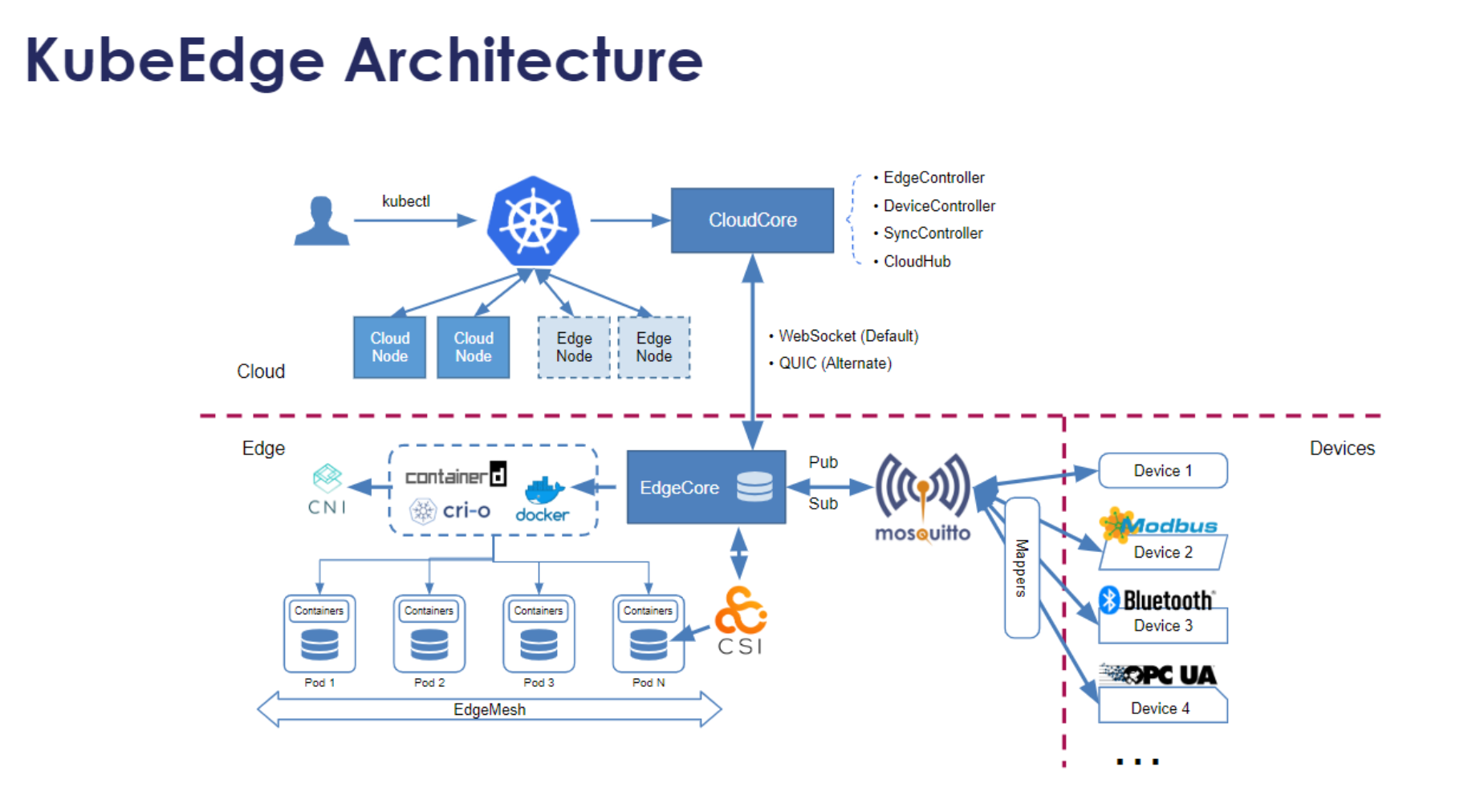
Kurator对边缘计算的支持主要靠KubeEdge。它的工作流程非常适合那种网络不稳定的环境(比如工厂、甚至卫星上)。
核心在于云边协同。云端有CloudCore,监听K8s事件;边缘端有EdgeCore,负责跑容器。流程是:你在Kurator控制面下发一个Pod -> CloudCore拦截到 -> 存到本地消息队列 -> 等边缘节点上线或者心跳正常时,通过WebSocket下发给EdgeCore -> EdgeCore拉起容器。哪怕中间断网了,EdgeCore也能维持本地业务运行,等网好了再同步状态。这就叫“离线自治”。
2. Kurator的统一迁移流程与分级优化策略
很多公司已有老集群,怎么搬到Kurator上来?Kurator提供了一套统一迁移流程。
不是暴力甚至停机迁移,而是“纳管”。先在老集群装Agent,注册到Kurator,然后逐步接管控制权。最后才是数据卷的迁移。
针对不同规模的集群,Kurator有分级优化策略。
- 小规模(<10节点):精简组件,把非必要的监控采集频率调低,省资源。
- 中规模(10-100节点):开启标准的HA高可用,Etcd分片。
- 大规模(100+节点):这时候就要做调度层面的优化了,开启批量调度,关闭不必要的事件透传,防止API Server被打爆。
3. Kurator中配置蓝绿发布
最后讲讲怎么稳稳地上线。蓝绿发布在Kurator里是通过通过流量切分实现的,通常配合Istio或者Ingress Controller。
你需要定义两个版本的Service。在Kurator里,你可以写一个Rollout策略。
逻辑是:先起新版本(绿),健康检查通过后,修改Ingress的权重,把5%的流量切过去。观察错误率,没问题就切到50%,最后100%。
这是一个手搓的Istio VirtualService配置片段,Kurator可以把它封装成更高级的策略对象:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: my-app-route
spec:
hosts:
- my-app.com
http:
- route:
- destination:
host: my-app-v1 # 蓝环境,旧的稳的一批
subset: v1
weight: 80
- destination:
host: my-app-v2 # 绿环境,新的,先放点流量试试水
subset: v2
weight: 20
五、 总结
写了这么多,其实就想告诉大家,Kurator不是什么神秘的黑科技,它就是把我们平时手动做的那些繁琐、易错的跨集群操作,变成了一套标准化的流程。
从Git clone搭建环境开始,到利用Karmada做大脑,用Volcano排任务,用KubeEdge管边缘,最后通过GitOps和蓝绿发布保证业务上线。这一套打下来,云原生底座才算是真的“稳”了。
兄弟们,技术这东西,光看没用,还是得动手。把上面那个Git地址拉下来,自己在虚拟机里跑一遍,遇到的坑踩一遍,你就出师了。有问题随时在社区群里喊我,咱们下次接着聊!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)