【前瞻创想】Kurator分布式云原生平台实战:从多云管理到边缘计算的统一架构与深度实践指南
【前瞻创想】Kurator分布式云原生平台实战:从多云管理到边缘计算的统一架构与深度实践指南
【前瞻创想】Kurator分布式云原生平台实战:从多云管理到边缘计算的统一架构与深度实践指南
摘要
在数字化转型的浪潮中,企业面临着基础设施分散、应用部署复杂、运维管理困难等挑战。Kurator作为一款开源的分布式云原生平台,通过集成Kubernetes、Istio、Prometheus、FluxCD、KubeEdge、Volcano、Karmada、Kyverno等优秀开源项目,为用户提供了统一的多云、多集群管理能力。本文深入探讨Kurator的核心架构、技术优势及实践应用,从环境搭建到多集群管理,从边缘计算到批处理调度,全面解析Kurator如何帮助企业构建现代化的云原生基础设施。通过丰富的实战案例和代码示例,读者将掌握Kurator在真实场景中的部署与优化技巧,为企业的云原生转型提供有力支撑。
一、Kurator平台架构与核心价值
1.1 分布式云原生的演进与挑战
分布式云原生架构参考图: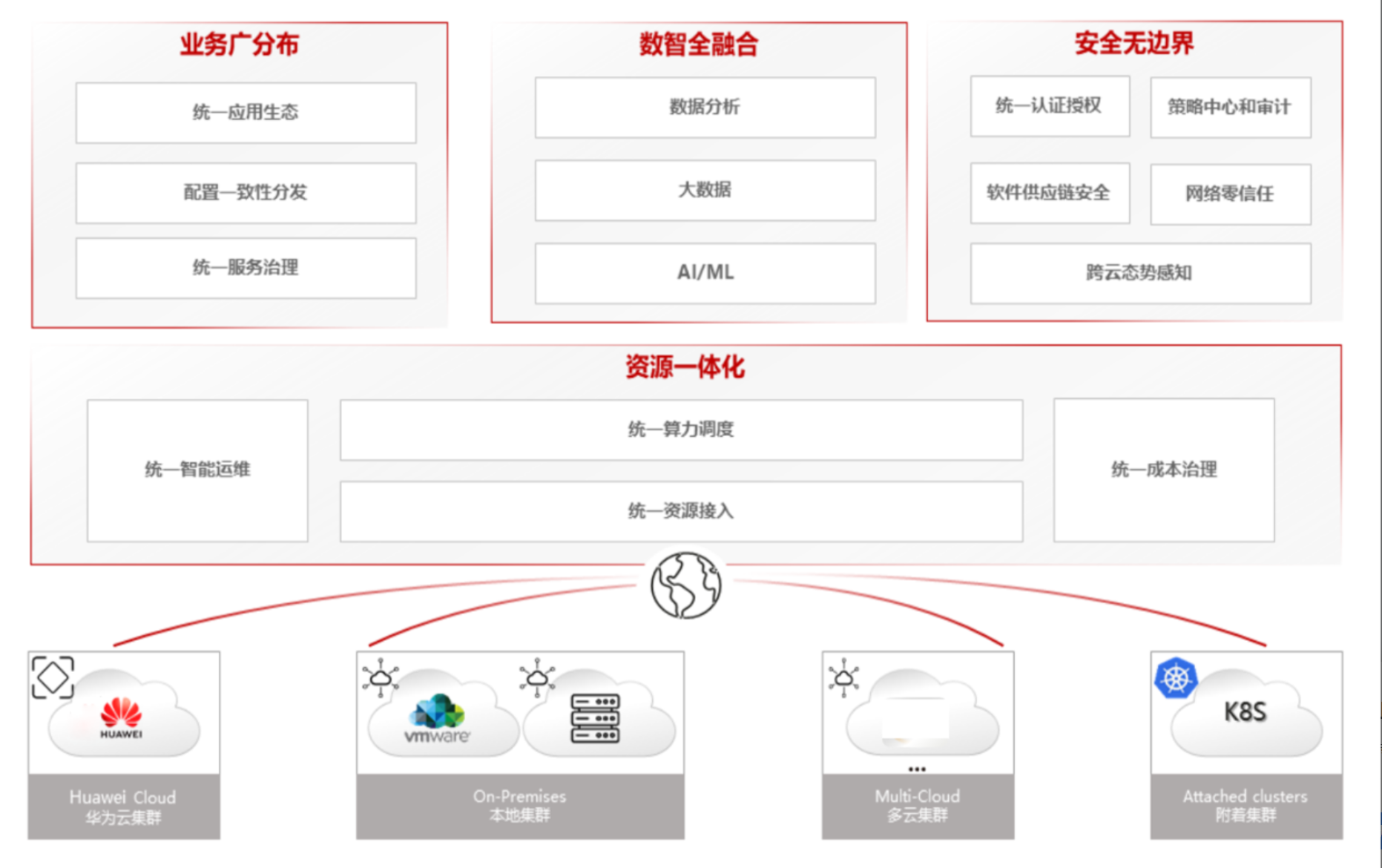
随着企业业务的全球化布局和数字化转型的深入,传统的单集群Kubernetes架构已无法满足现代应用的需求。企业通常拥有多个云环境(公有云、私有云、混合云)以及大量边缘节点,这些分散的基础设施带来了资源管理复杂、应用部署不一致、运维监控困难等问题。分布式云原生架构应运而生,旨在提供统一的管理平面,实现资源、应用、策略的全局一致性。
Kurator正是在这一背景下诞生的开源平台,它不是简单的工具集合,而是通过深度整合多个云原生项目,构建了一个完整的分布式云原生操作系统。与传统的多集群管理方案相比,Kurator更注重"统一性"和"自动化",通过声明式API和GitOps工作流,将基础设施管理提升到新的高度。
1.2 Kurator的核心架构设计
kurator架构参考图: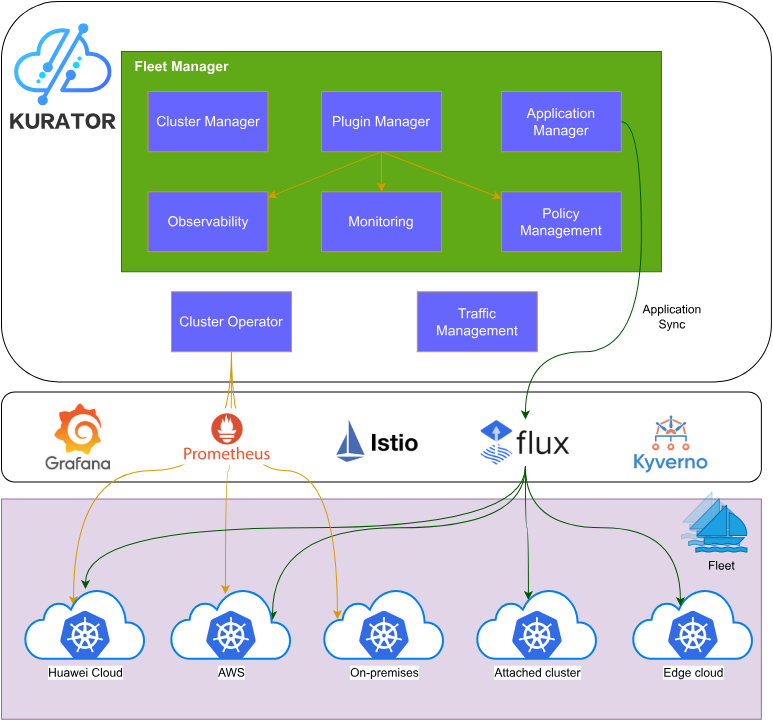
Kurator采用分层架构设计,底层是基础设施层,支持各种云平台、边缘设备和物理服务器;中间层是集群管理层,通过Fleet抽象统一管理多个Kubernetes集群;上层是应用和服务层,提供统一的流量管理、监控告警、策略执行等能力。
# Kurator架构核心组件配置示例
apiVersion: kurator.dev/v1alpha1
kind: Fleet
meta
name: production-fleet
spec:
clusters:
- name: east-region-cluster
kubeconfigSecret: east-kubeconfig
- name: west-region-cluster
kubeconfigSecret: west-kubeconfig
- name: edge-cluster-01
kubeconfigSecret: edge-kubeconfig
policies:
- name: resource-quota-policy
type: ResourceQuota
spec:
hard:
requests.cpu: "10"
requests.memory: 20Gi
这种架构设计的关键优势在于解耦了业务逻辑与基础设施细节。开发者只需关注应用本身,而运维团队可以通过统一的控制平面管理所有集群,大大降低了复杂性。
1.3 Kurator的独特价值主张
Kurator相对于其他多集群管理方案的独特之处在于其"一体化"设计理念。它不仅仅是一个管理工具,更是一个完整的云原生平台,内置了从基础设施到应用层的全栈能力:
- 统一资源编排:通过Karmada实现跨集群的应用分发和资源调度
- 统一调度策略:结合Volcano提供高级批处理调度能力
- 统一流量管理:基于Istio实现跨集群的服务发现和流量控制
- 统一监控告警:聚合Prometheus指标,提供全局视图
- 基础设施即代码:声明式管理集群、节点、网络等基础设施
这种一体化设计消除了传统方案中工具链断裂的问题,为企业提供了一个真正端到端的云原生解决方案。
二、Kurator集成的云原生技术栈深度解析
2.1 核心组件技术选型与集成策略
Kurator的成功很大程度上归功于其精心选择的技术栈。在集群管理层面,Kurator选择了Karmada作为核心,因为Karmada提供了强大的多集群调度和应用分发能力;在边缘计算领域,KubeEdge被集成进来,它解决了边缘节点资源受限、网络不稳定等挑战;对于批处理工作负载,Volcano提供了高效的作业调度和资源隔离。
# Karmada策略配置示例,展示Kurator如何利用Karmada进行跨集群调度
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
meta
name: nginx-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: nginx
placement:
clusterAffinity:
clusterNames:
- cluster-east
- cluster-west
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightList:
- targetCluster:
clusterNames:
- cluster-east
weight: 2
- targetCluster:
clusterNames:
- cluster-west
weight: 1
这种技术选型不是简单的堆砌,而是经过深思熟虑的集成。Kurator在这些项目的基础上构建了统一的API和用户体验,掩盖了底层复杂性。
2.2 GitOps与基础设施即代码的实现
GitOps是Kurator的核心理念之一。通过集成FluxCD,Kurator实现了声明式的基础设施和应用管理。所有配置都存储在Git仓库中,通过自动化流程同步到目标环境,确保了环境的一致性和可追溯性。
Kurator的GitOps实现不仅仅停留在应用部署层面,还扩展到了基础设施管理。通过Terraform和Crossplane等工具,Kurator可以管理云资源、网络配置、存储卷等基础设施组件,真正实现了"基础设施即代码"。
# FluxCD Helm应用配置示例,展示Kurator中的GitOps实践
apiVersion: source.toolkit.fluxcd.io/v1beta1
kind: HelmRepository
meta
name: kurator-charts
namespace: kurator-system
spec:
interval: 10m
url: https://kurator-dev.github.io/charts
---
apiVersion: helm.toolkit.fluxcd.io/v2beta1
kind: HelmRelease
meta
name: kurator-dashboard
namespace: kurator-system
spec:
chart:
spec:
chart: dashboard
sourceRef:
kind: HelmRepository
name: kurator-charts
version: "0.1.0"
interval: 5m
values:
service:
type: ClusterIP
resources:
limits:
cpu: 500m
memory: 512Mi
2.3 统一监控与可观测性架构
Kurator 统一监控参考图: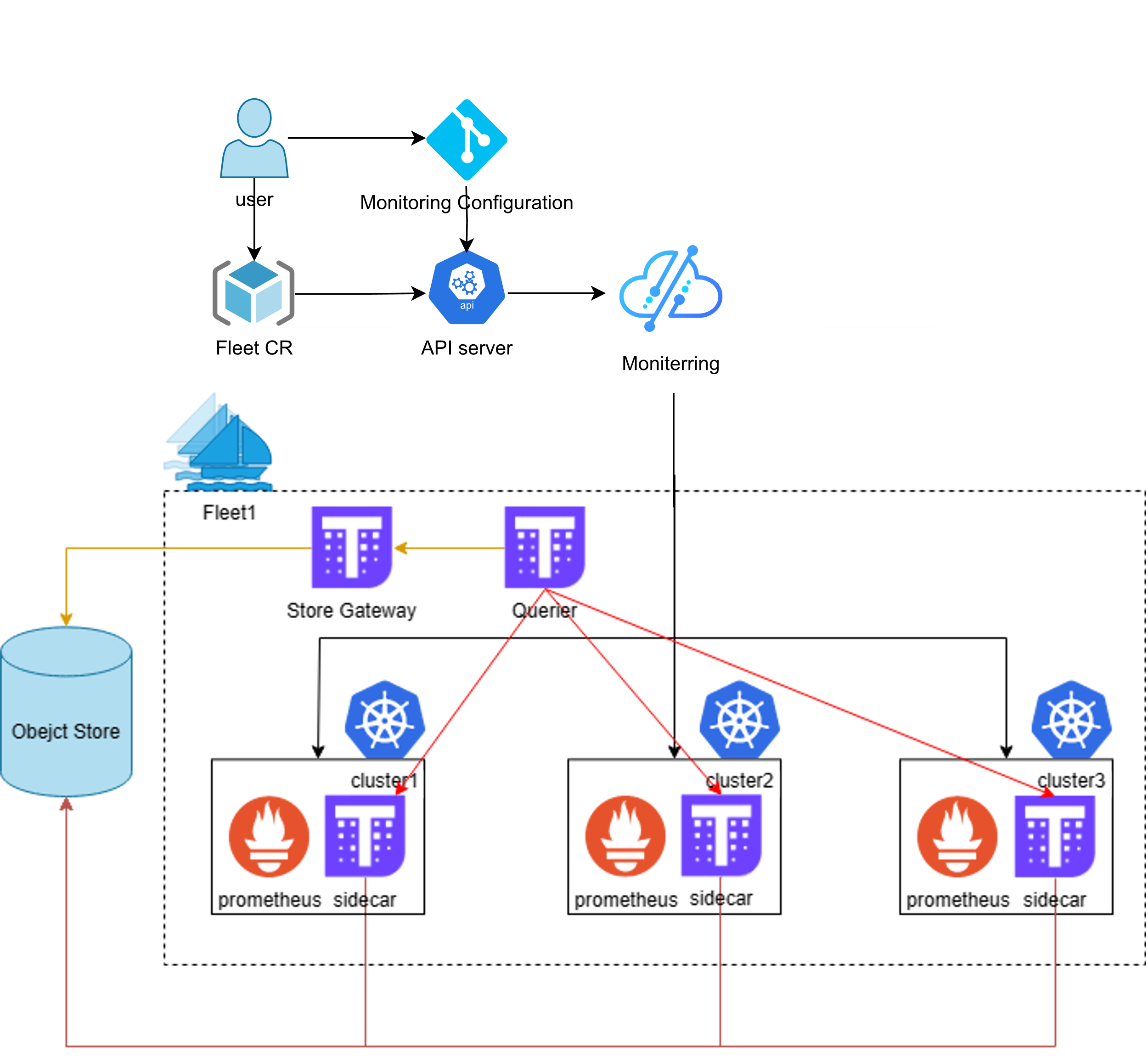
在分布式环境中,监控和可观测性至关重要。Kurator集成了Prometheus、Grafana、Jaeger等工具,构建了统一的监控体系。通过Karmada的指标聚合能力,Kurator可以从所有管理的集群中收集指标,在全局层面提供统一的监控视图。
Kurator的监控架构分为三层:数据采集层、数据处理层和展示层。在数据采集层,每个集群部署Prometheus实例收集本地指标;在数据处理层,Kurator使用Thanos或Mimir进行指标聚合和长期存储;在展示层,通过Grafana提供统一的仪表板。
# Kurator监控配置示例
apiVersion: monitoring.kurator.dev/v1alpha1
kind: Monitoring
meta
name: global-monitoring
spec:
clusters:
- name: cluster-east
prometheusURL: http://prometheus-east.kube-system.svc:9090
- name: cluster-west
prometheusURL: http://prometheus-west.kube-system.svc:9090
retention:
local: 24h
remote: 90d
alerting:
rules:
- name: high-cpu-usage
expr: sum(rate(container_cpu_usage_seconds_total[5m])) by (pod) > 0.8
for: 10m
labels:
severity: warning
annotations:
summary: High CPU usage on pod {{ $labels.pod }}
三、Kurator环境搭建与集群部署实战
3.1 环境准备与依赖安装
在开始安装Kurator之前,需要准备适当的环境。Kurator支持在Linux、macOS等操作系统上运行,需要安装Docker、kubectl、Helm等基础工具。以下是一个完整的环境准备流程:
# 安装基础依赖
sudo apt-get update
sudo apt-get install -y curl wget git docker.io kubectl
# 安装Helm
curl https://baltocdn.com/helm/signing.asc | sudo apt-key add -
sudo apt-get install apt-transport-https --yes
echo "deb https://baltocdn.com/helm/stable/debian/ all main" | sudo tee /etc/apt/sources.list.d/helm-stable-debian.list
sudo apt-get update
sudo apt-get install helm
# 克隆Kurator源码
git clone https://github.com/kurator-dev/kurator.git
cd kurator
# 或者使用wget下载
# wget https://github.com/kurator-dev/kurator/archive/refs/heads/main.zip
# unzip main.zip
# cd kurator-main
在项目地址中,可以看到可以clone到本地
https://gitcode.com/kurator-dev/kurator.git
或者我们也可以下载到本地
可以看到我们资源文件已经下载下来了
可以看到版本是0.6.0
3.2 Kurator安装流程详解
Kurator提供了多种安装方式,包括Helm Chart、kubectl apply和基于源码的构建安装。对于生产环境,推荐使用Helm Chart安装,因为它提供了更灵活的配置选项和升级路径。
# 添加Kurator Helm仓库
helm repo add kurator https://kurator-dev.github.io/charts
helm repo update
# 创建命名空间
kubectl create namespace kurator-system
# 安装Kurator核心组件
helm install kurator kurator/kurator \
--namespace kurator-system \
--set global.clusterDomain=cluster.local \
--set components.fleet.enabled=true \
--set components.karmada.enabled=true \
--set components.kubeedge.enabled=false \
--set components.volcano.enabled=true
# 验证安装
kubectl get pods -n kurator-system
安装过程中,Kurator会自动部署以下核心组件:
- Fleet Manager:负责集群注册和管理
- Karmada Controller:处理跨集群应用分发
- Volcano Controller:管理批处理作业调度
- GitOps Operator:基于FluxCD的GitOps引擎
- Dashboard:提供Web UI界面
3.3 多集群环境配置与集成
安装完成后,需要将现有的Kubernetes集群注册到Kurator中,形成一个统一的Fleet。Kurator支持多种集群注册方式,包括kubeconfig文件、服务账户令牌等。
# 生成集群注册命令
kubectl kurator cluster register --name cluster-east --context east-context
# 或者手动创建集群资源
cat <<EOF | kubectl apply -f -
apiVersion: cluster.kurator.dev/v1alpha1
kind: Cluster
meta
name: cluster-west
spec:
kubeconfigSecret: cluster-west-kubeconfig
labels:
region: west
environment: production
EOF
# 验证集群注册状态
kubectl get clusters.cluster.kurator.dev
在多集群环境中,网络连通性是关键挑战。Kurator提供了多种网络解决方案,包括隧道模式、Service Mesh集成等。对于跨公网的集群通信,建议使用隧道模式,它通过加密通道保证通信安全。
# 隧道配置示例
apiVersion: networking.kurator.dev/v1alpha1
kind: Tunnel
meta
name: cluster-east-tunnel
spec:
sourceCluster: local-cluster
targetCluster: cluster-east
type: WireGuard
wireGuard:
publicKey: "jRJ8VqQz7yVQhXQpXqXqXqXqXqXqXqXqXqXqXqXqXqY="
endpoint: "203.0.113.10:51820"
allowedIPs:
- "10.244.0.0/16"
四、Fleet多集群管理的核心机制与实践
4.1 Fleet架构与工作原理
Fleet架构官方参考图: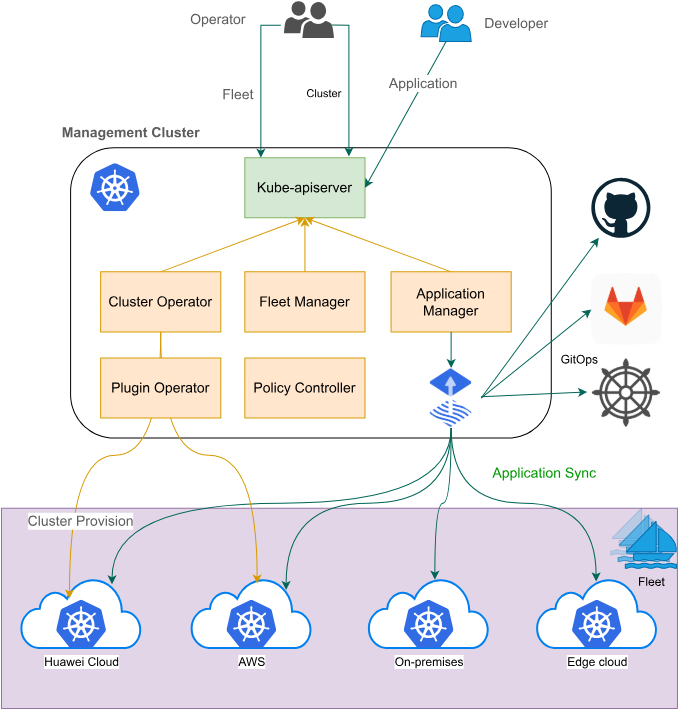
Fleet是Kurator多集群管理的核心抽象,它代表一组逻辑上相关的Kubernetes集群。Fleet的设计借鉴了Karmada的概念,但增强了与Kurator其他组件的集成。在Fleet中,集群可以按地域、环境、业务等维度进行分组,每个Fleet可以应用不同的策略和配置。
Fleet的工作流程包括:集群注册、策略同步、应用分发、状态收集等环节。当用户在Fleet级别定义一个应用时,Fleet Controller会根据策略将应用分发到目标集群,并持续监控应用状态,确保一致性。
# Fleet高级配置示例
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
metadata:
name: global-fleet
spec:
clusters:
- name: ap-southeast-1
labels:
region: ap-southeast
cloud: aws
- name: us-west-2
labels:
region: us-west
cloud: aws
- name: edge-shanghai
labels:
region: china
type: edge
placement:
policies:
- name: region-policy
rules:
- clusterSelector:
matchLabels:
region: ap-southeast
weight: 2
- clusterSelector:
matchLabels:
region: us-west
weight: 1
4.2 集群资源拓扑结构管理
集群资源拓扑结构参考图: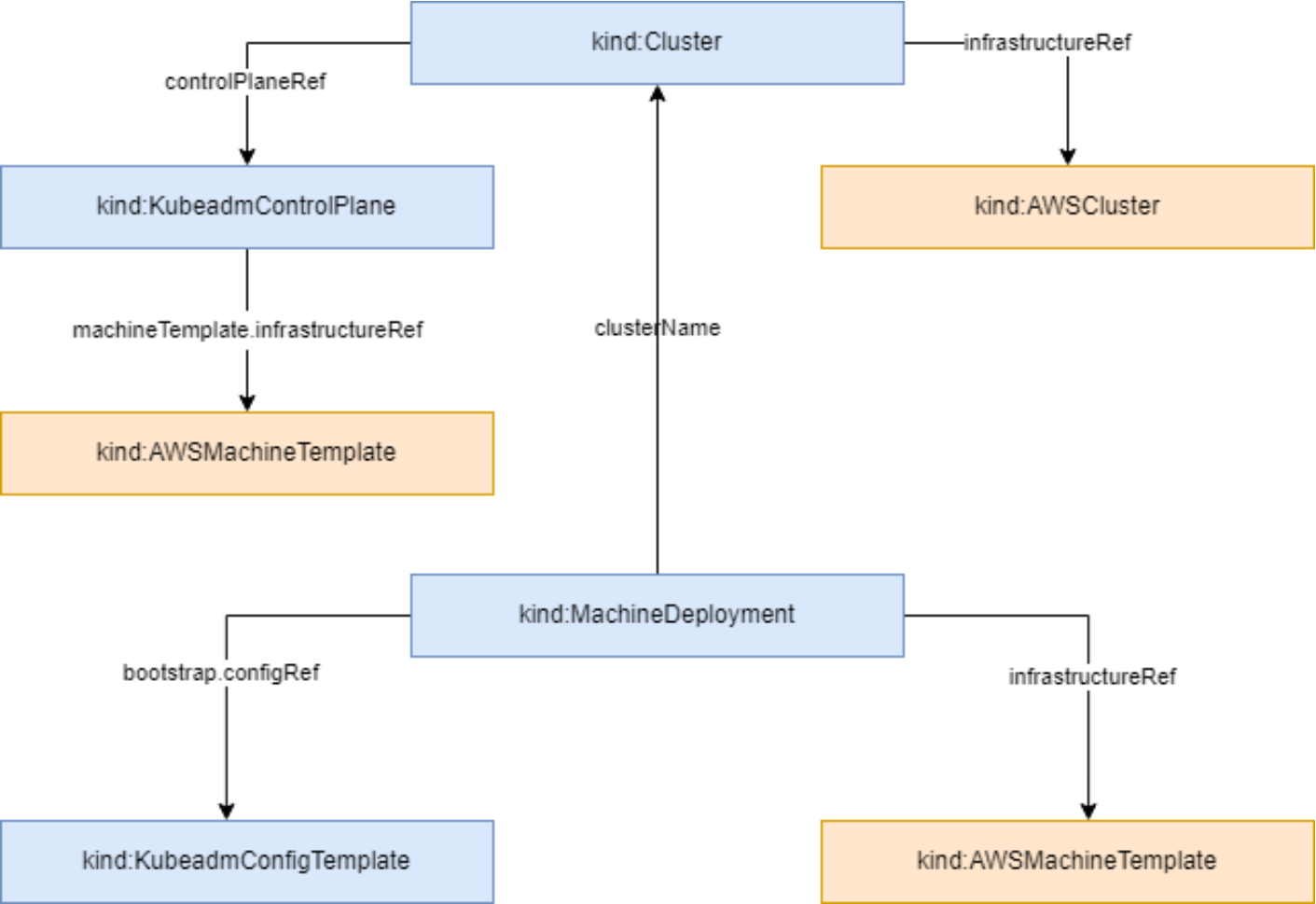
在复杂的多集群环境中,理解资源拓扑结构至关重要。Kurator提供了可视化工具和API来展示集群间的层次关系、网络拓扑和资源分布。通过资源拓扑管理,运维团队可以快速识别性能瓶颈、容量规划和故障影响范围。
Kurator的资源拓扑管理基于CRD(Custom Resource Definition)实现,允许用户定义自定义的拓扑关系。例如,可以定义数据中心、机架、服务器等物理层级,或者定义业务单元、服务层级等逻辑层级。
# 资源拓扑配置示例
apiVersion: topology.kurator.dev/v1alpha1
kind: ResourceTopology
metadata:
name: datacenter-topology
spec:
levels:
- name: region
children:
- name: zone
children:
- name: cluster
children:
- name: node
4.3 Fleet中的身份与命名空间一致性
Fleet 舰队中的命名空间相同性官方参考图: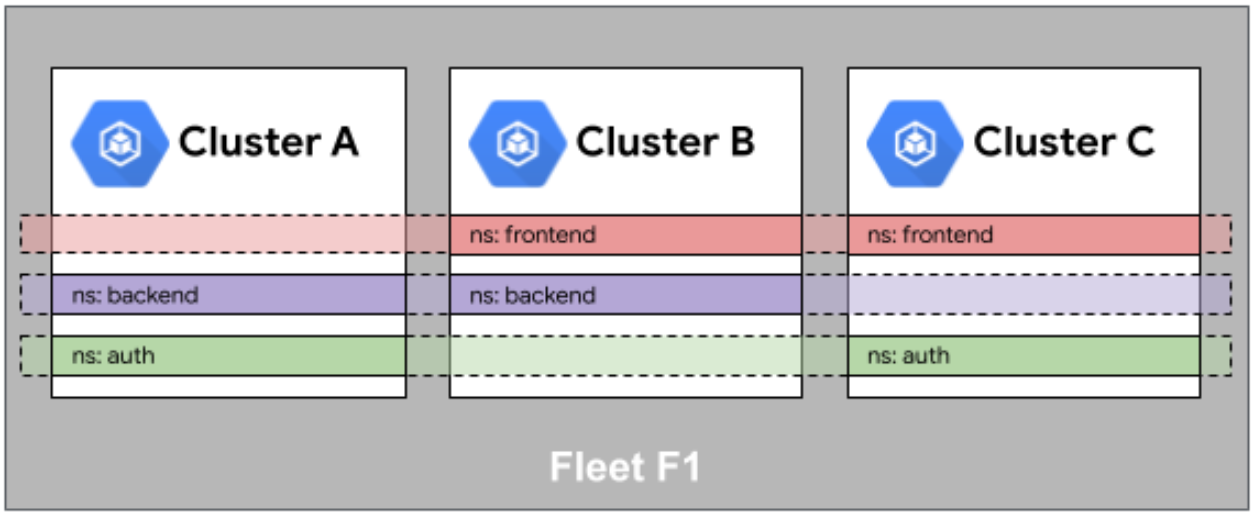
在多集群环境中,身份和命名空间的一致性是常见挑战。Kurator通过ServiceAccount、RoleBinding和命名空间策略确保跨集群的身份和权限一致性。例如,当在Fleet级别创建一个命名空间时,Kurator会自动在所有成员集群中创建相同的命名空间,并同步相关的RBAC配置。
# 命名空间同步策略示例
apiVersion: fleet.kurator.dev/v1alpha1
kind: NamespacePolicy
meta
name: dev-namespace-policy
spec:
namespace: development
placement:
clusterSelector:
matchLabels:
environment: production
rbac:
serviceAccounts:
- name: app-service-account
imagePullSecrets:
- name: registry-secret
roles:
- name: developer-role
rules:
- apiGroups: [""]
resources: ["pods", "services"]
verbs: ["get", "list", "watch"]
五、Karmada跨集群调度与弹性伸缩实践

5.1 Karmada架构与Kurator集成
Karmada 架构官方参考图: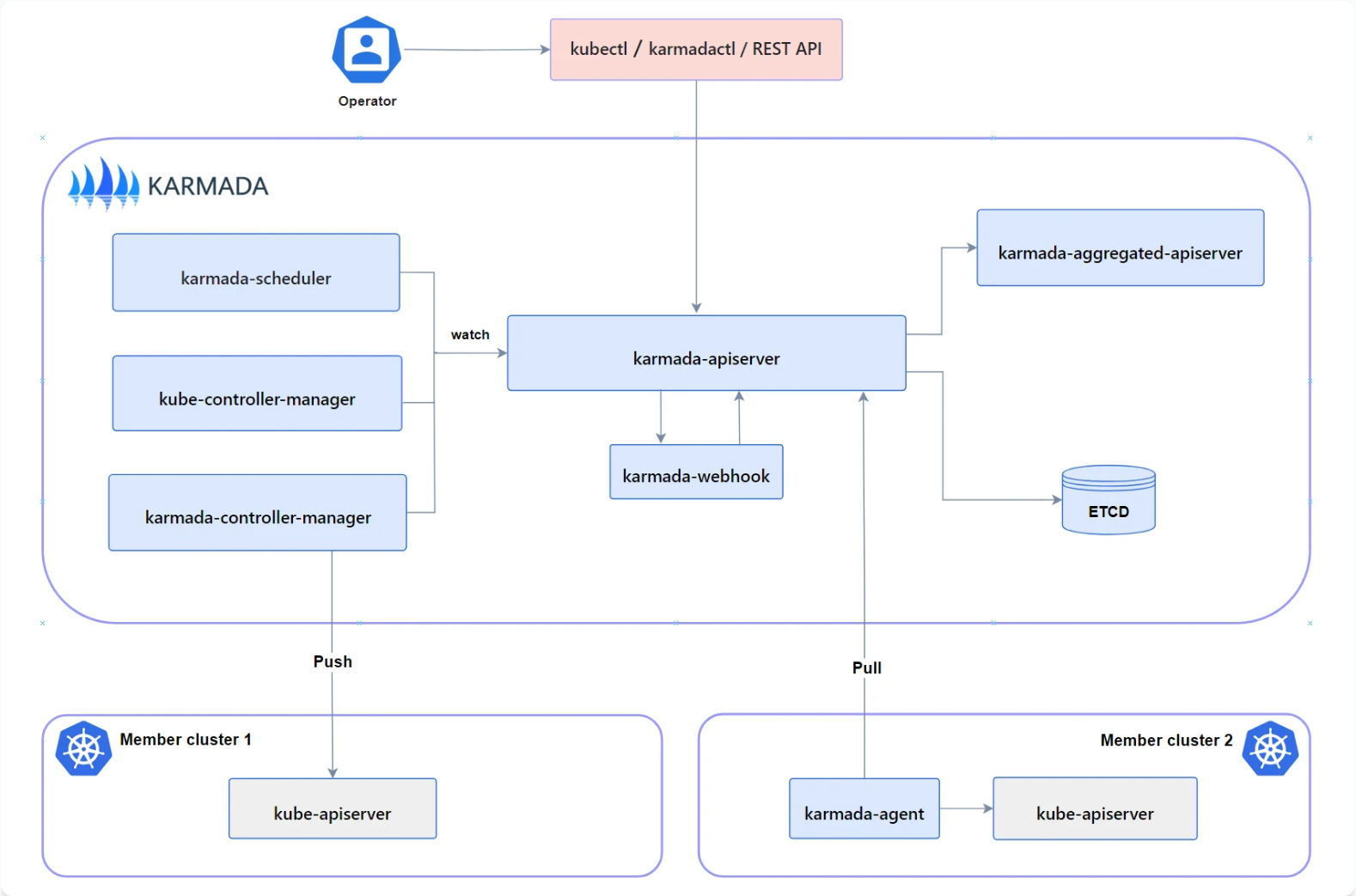
Karmada是Kurator的核心组件之一,负责跨集群的资源调度和应用分发。Karmada采用控制平面架构,包含API Server、Scheduler、Controller Manager等组件。在Kurator中,Karmada被深度集成,提供了更友好的用户界面和扩展功能。
Kurator对Karmada的增强主要体现在:统一的策略管理、与Volcano的集成、增强的监控能力等方面。通过Kurator,用户可以更容易地定义复杂的调度策略,如基于拓扑的调度、基于负载的调度等。
# Karmada高级调度策略示例
apiVersion: policy.karmada.io/v1alpha1
kind: ClusterPropagationPolicy
meta
name: high-availability-policy
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
labelSelector:
matchLabels:
app: critical-service
placement:
clusterAffinity:
clusterNames:
- cluster-east
- cluster-west
- cluster-central
spreadConstraints:
- spreadByField: cluster
maxGroups: 3
minGroups: 2
5.2 跨集群弹性伸缩策略设计
Karmada跨集群弹性伸缩策略参考图: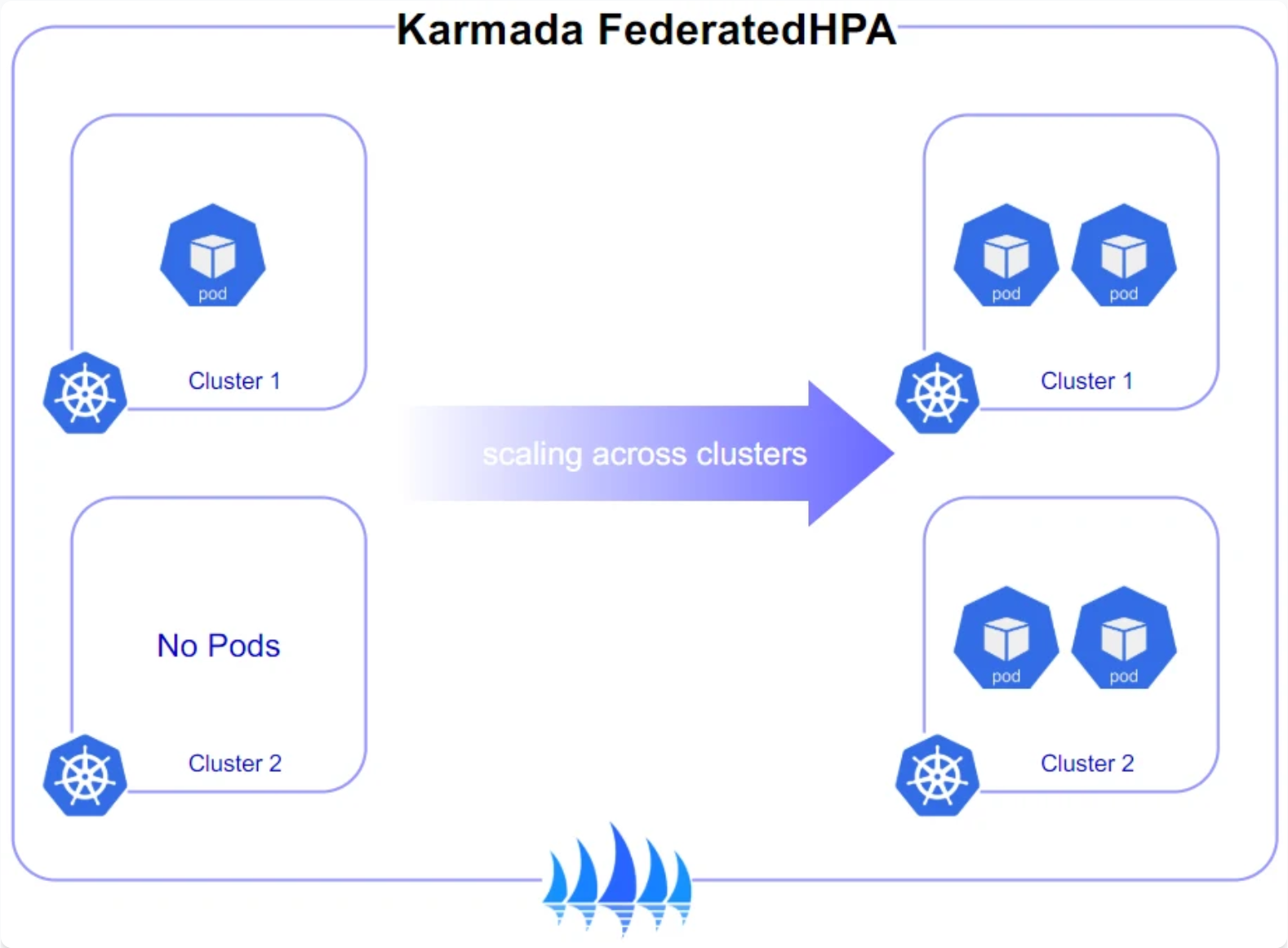
在分布式环境中,弹性伸缩变得更加复杂。Kurator结合Karmada和KEDA(Kubernetes Event-Driven Autoscaling)实现了跨集群的弹性伸缩能力。这种能力不仅考虑单个集群的负载,还考虑全局资源分布和业务需求。
例如,对于一个全球部署的电商应用,可以在不同地域的集群中设置不同的伸缩策略。在购物高峰期,自动将流量导向资源充足的集群,同时在负载较低的集群中缩减资源,优化成本。
# 跨集群HPA配置示例
apiVersion: autoscaling.kurator.dev/v1alpha1
kind: GlobalHorizontalPodAutoscaler
meta
name: global-web-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: web-server
minReplicas: 10
maxReplicas: 100
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
clusterScalingPolicy:
type: Weighted
weights:
cluster-east: 2
cluster-west: 1
cluster-central: 1
5.3 多集群故障转移与容灾策略
高可用性是分布式系统的核心要求。Kurator通过Karmada实现了智能的故障转移和容灾策略。当某个集群出现故障时,系统可以自动将应用迁移到健康的集群,确保业务连续性。
Kurator的故障转移策略包括:主动健康检查、优雅降级、数据同步等机制。通过结合Prometheus监控数据和自定义健康检查,Kurator可以准确判断集群状态,并触发相应的故障转移流程。
# 故障转移策略配置示例
apiVersion: disaster.kurator.dev/v1alpha1
kind: FailoverPolicy
meta
name: critical-service-failover
spec:
targetApplication:
apiVersion: apps/v1
kind: Deployment
name: critical-app
healthCheck:
interval: 30s
failureThreshold: 3
httpGet:
path: /health
port: 8080
failoverStrategy:
type: Automatic
priorityClusters:
- cluster-central
- cluster-east
- cluster-west
recoveryStrategy:
type: ManualApproval
timeout: 1h
六、KubeEdge边缘计算架构与Kurator集成
6.1 KubeEdge核心组件与架构解析
KubeEdge的核心组件参考图: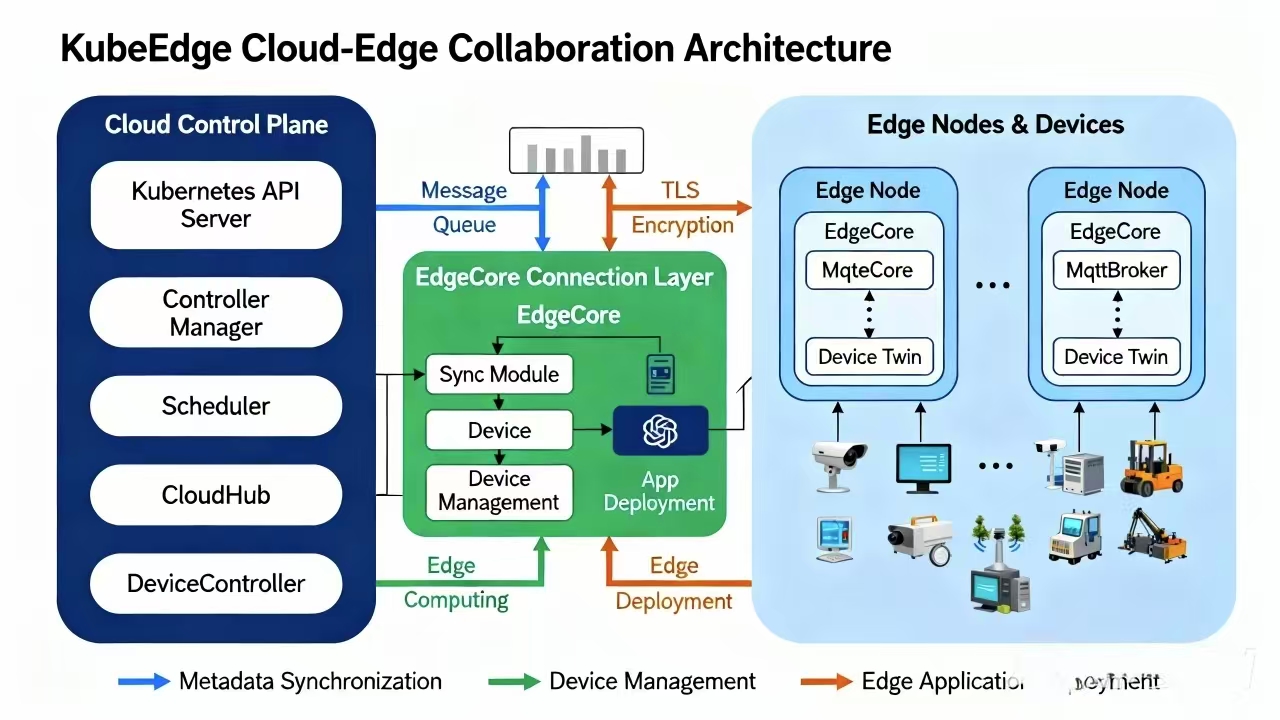
KubeEdge是Kurator集成的边缘计算框架,它将Kubernetes的能力扩展到边缘节点。KubeEdge的核心组件包括:CloudCore(云侧组件)、EdgeCore(边缘侧组件)、EdgeMesh(边缘服务网格)等。
KubeEdge架构参考图: 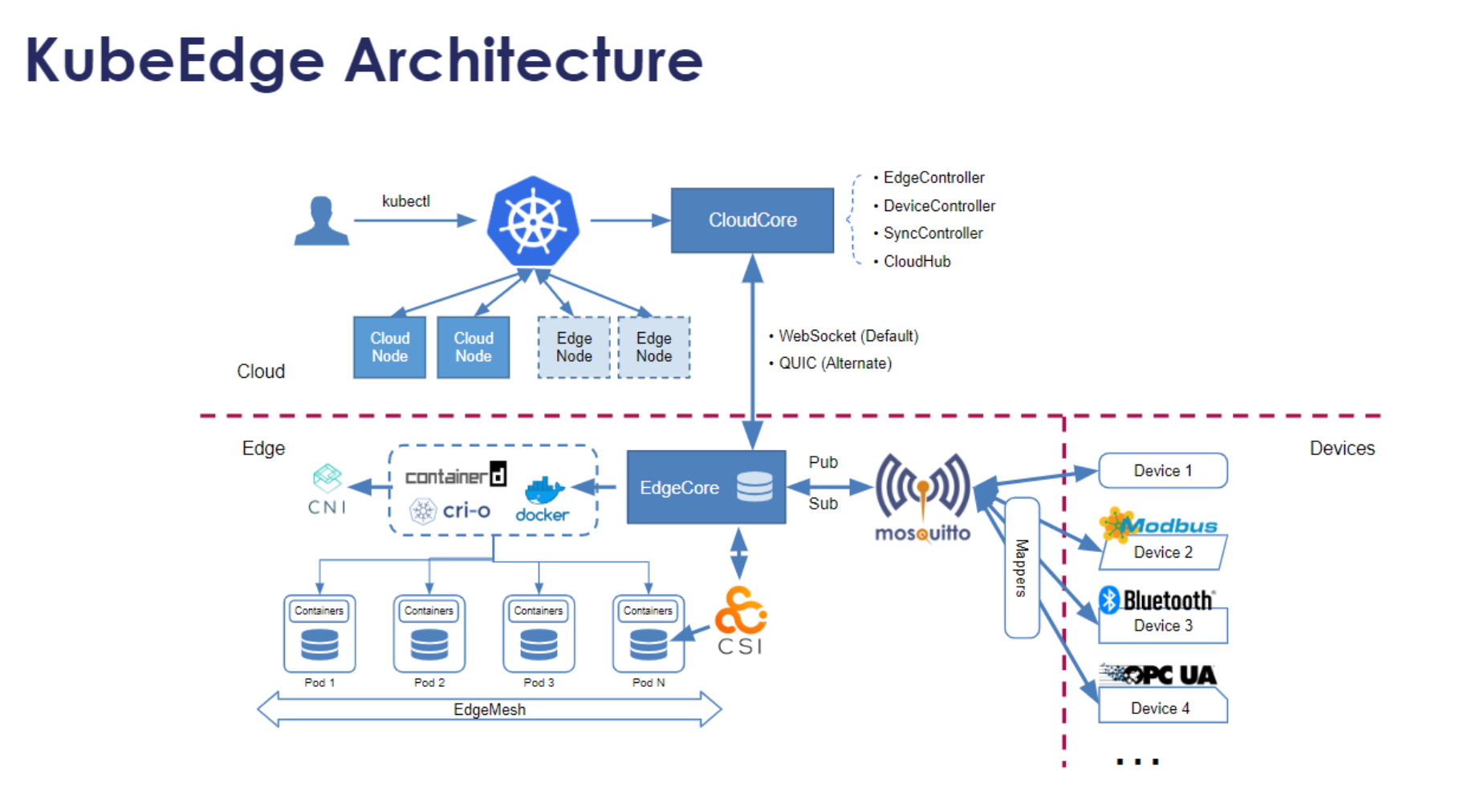
KubeEdge的架构设计充分考虑了边缘环境的特点:网络不稳定、资源受限、设备异构等。通过元数据同步、离线运行、设备管理等机制,KubeEdge确保了边缘应用的可靠运行。
在Kurator中,KubeEdge被无缝集成到Fleet管理中,边缘集群与中心集群可以统一管理,应用可以自由地在中心和边缘之间调度。
# KubeEdge边缘节点注册示例
apiVersion: edge.kurator.dev/v1alpha1
kind: EdgeNode
metadata:
name: edge-node-01
spec:
labels:
location: factory-floor
device-type: industrial-pc
taints:
- key: edge
value: "true"
effect: NoSchedule
edgeInfo:
cpu: "4"
memory: "8Gi"
storage: "100Gi"
os: "Linux"
6.2 边缘-云协同的应用部署模式
云边协同应用部署参考图: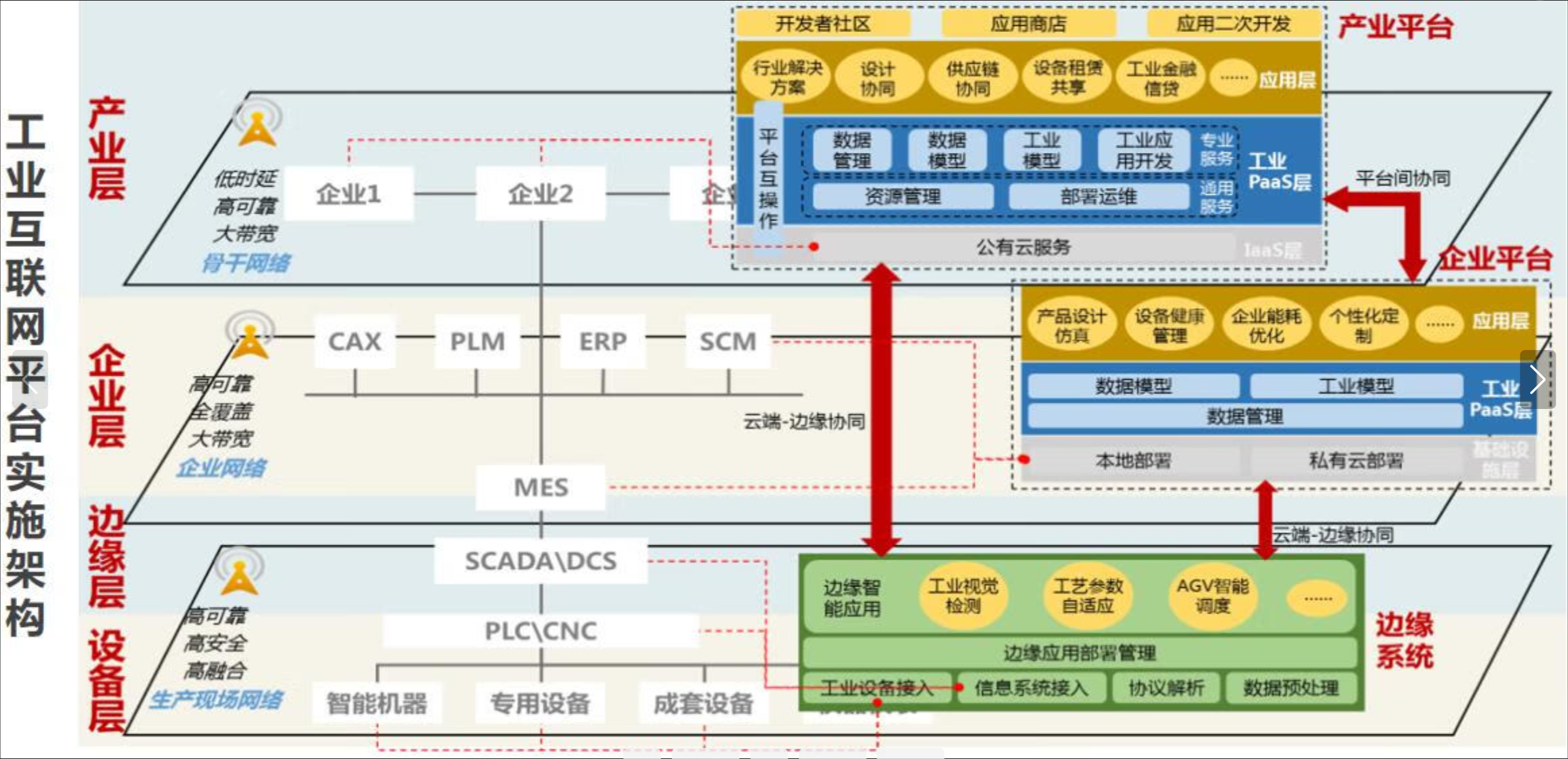
在边缘计算场景中,应用部署模式与传统云环境有很大不同。Kurator支持多种边缘-云协同部署模式:
- 中心控制,边缘执行:应用逻辑在中心定义,实际执行在边缘
- 数据就近处理:敏感数据在边缘处理,聚合结果上传到中心
- 分层AI推理:简单推理在边缘执行,复杂推理在中心执行
- 混合工作负载:批处理在中心,实时处理在边缘
Kurator通过FluxCD和Karmada的组合,实现了这些部署模式的灵活配置。开发者可以通过声明式API定义应用的部署策略,系统会自动处理复杂的同步和调度逻辑。
# 边缘应用部署策略示例
apiVersion: apps.kurator.dev/v1alpha1
kind: EdgeApplication
meta
name: factory-monitoring
spec:
selector:
matchLabels:
app: monitoring
processingMode: EdgeFirst
components:
- name: data-collector
placement: Edge
resources:
limits:
cpu: "500m"
memory: "256Mi"
- name: data-analyzer
placement: Cloud
resources:
limits:
cpu: "1"
memory: "1Gi"
dataFlow:
from: edge-node-01
to: cloud-cluster
syncInterval: 5m
6.3 边缘网络与安全挑战应对
边缘环境的网络和安全挑战比中心云环境更为复杂。Kurator通过以下机制应对这些挑战:
- 自适应连接:根据网络质量动态调整同步频率和数据量
- 离线操作:在网络中断时,边缘节点可以继续运行预定义的工作负载
- 零信任安全:基于证书的双向认证,细粒度的访问控制
- 数据加密:传输中和静态数据的端到端加密
Kurator的安全架构基于SPIFFE/SPIRE标准,为边缘节点提供统一的身份管理。每个边缘节点都有唯一的身份标识,所有通信都经过严格的身份验证和授权。
# 边缘安全策略示例
apiVersion: security.kurator.dev/v1alpha1
kind: EdgeSecurityPolicy
meta
name: factory-security
spec:
targetEdges:
- edge-node-01
- edge-node-02
authentication:
method: Certificate
rotationInterval: 24h
authorization:
policies:
- resource: "/api/sensors"
verbs: ["GET"]
users: ["operator"]
- resource: "/api/control"
verbs: ["POST"]
users: ["admin"]
networkPolicy:
ingress:
- from:
- podSelector:
matchLabels:
app: data-processor
ports:
- protocol: TCP
port: 8080
七、Volcano批处理调度在Kurator中的应用
7.1 Volcano架构与调度原理
Volcano是Kurator集成的批处理调度框架,专为AI/ML、大数据、HPC等计算密集型工作负载设计。Volcano的核心组件包括:Scheduler、Controller、Admission Controller等。
Volcano的调度算法基于多种策略:公平调度、能力调度、优先级调度等。与Kubernetes默认调度器相比,Volcano提供了更细粒度的资源管理和更智能的调度决策,特别适合处理长时间运行的批处理任务。
在Kurator中,Volcano与Karmada深度集成,实现了跨集群的批处理作业调度。用户可以定义全局的队列策略,系统会自动将作业分配到最合适的集群。
# Volcano队列配置示例
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
meta
name: ml-training-queue
spec:
weight: 1
capability:
cpu: "100"
memory: "500Gi"
reclaimable: true
reservation:
timeout: 24h
7.2 VolcanoJob与资源分组管理
VolcanoJob是Volcano的核心概念,它扩展了Kubernetes Job,提供了更强大的批处理能力。VolcanoJob支持多种任务类型:MapReduce、MPI、TensorFlow等,并提供了任务依赖、错误重试、资源隔离等高级功能。
PodGroup是Volcano的另一个重要概念,它将一组Pod视为一个调度单元,确保这些Pod能够同时调度成功,避免部分调度导致的资源浪费。在AI训练场景中,PodGroup特别有用,因为它可以确保所有训练节点同时启动,避免训练过程中的同步问题。
# VolcanoJob配置示例
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
meta
name: distributed-training
spec:
minAvailable: 8
schedulerName: volcano
tasks:
- replicas: 8
name: trainer
template:
spec:
containers:
- image: tensorflow/tensorflow:2.5.0-gpu
name: tensorflow
command: ["python", "train.py"]
resources:
limits:
nvidia.com/gpu: 1
cpu: "4"
memory: "16Gi"
nodeSelector:
node-type: gpu-node
queue: ml-training-queue
7.3 跨集群批处理作业优化策略
在分布式环境中,批处理作业的优化变得更加复杂。Kurator结合Volcano和Karmada,提供了跨集群批处理作业优化能力。这种优化不仅考虑单个集群的资源利用率,还考虑网络延迟、数据局部性、成本等因素。
例如,对于一个需要处理TB级数据的机器学习训练任务,Kurator可以自动将作业分配到数据所在的集群,减少数据传输开销。同时,根据集群的空闲资源情况,动态调整作业的并行度,最大化资源利用率。
# 跨集群批处理策略示例
apiVersion: batch.kurator.dev/v1alpha1
kind: DistributedJob
metadata:
name: global-data-processing
spec:
type: Spark
placement:
strategy: DataLocality
clusters:
- name: data-center-east
weight: 2
maxParallelism: 100
- name: data-center-west
weight: 1
maxParallelism: 50
dataSources:
- name: user-logs
location: s3://data-bucket/user-logs
preferredCluster: data-center-east
- name: product-catalog
location: s3://data-bucket/product-catalog
preferredCluster: data-center-west
optimization:
costAware: true
deadline: 2h
八、Kurator未来发展与云原生技术展望
8.1 Kurator技术路线图分析
Kurator作为新兴的分布式云原生平台,其技术路线图展现了对未来的深刻思考。从短期来看,Kurator将重点完善核心功能,提高稳定性和性能;从中期来看,将加强与CNCF项目的深度集成,扩展边缘计算和AI/ML场景支持;从长期来看,将探索Serverless架构、WebAssembly等新技术在分布式环境中的应用。
特别值得关注的是Kurator对eBPF技术的应用计划。通过eBPF,Kurator可以实现更高效的网络策略、安全监控和性能分析,这将大幅提升平台的整体性能和可观测性。
8.2 分布式云原生技术发展趋势
分布式云原生技术正朝着几个关键方向发展:
- 统一控制平面:从多集群管理向全域统一控制演进
- AI驱动的自动化:利用机器学习优化资源调度、故障预测
- 边缘智能:边缘计算与AI/ML深度融合,实现近数据处理
- 安全内生:安全能力内置于平台架构,而非外挂组件
- 绿色计算:通过智能调度降低能耗,实现可持续发展
Kurator作为开源平台,正在积极参与这些技术趋势的探索和实践。通过社区协作和开放创新,Kurator有望成为分布式云原生领域的标杆项目。
8.3 企业云原生转型建议
基于Kurator的实践经验,对企业的云原生转型提出以下建议:
- 渐进式演进:不要试图一次性重构所有系统,从非关键业务开始
- 能力培养:投资团队的云原生技能培养,建立内部专家团队
- 工具链统一:选择像Kurator这样的统一平台,避免工具碎片化
- 可观测性优先:在架构设计初期就考虑监控和日志收集
- 安全左移:将安全考虑融入开发流程,而非事后补救
Kurator开源社区提供了丰富的学习资源和最佳实践,企业可以通过参与社区活动,快速提升云原生能力。同时,Kurator的模块化设计允许企业根据自身需求选择性采用,降低了转型风险。
结语
Kurator作为分布式云原生平台的代表,展示了云原生技术在多云、边缘计算时代的巨大潜力。通过深度整合Kubernetes生态中的优秀项目,Kurator为企业提供了一个统一、高效、可扩展的云原生基础设施。本文从架构设计到实战应用,全面探讨了Kurator的核心价值和使用场景,希望为读者的云原生之旅提供有价值的参考。
随着云原生技术的不断发展,我们期待Kurator社区能够持续创新,推动分布式云原生架构的演进。对于技术从业者而言,掌握Kurator这样的平台技术,将为职业发展带来新的机遇。让我们共同拥抱云原生的未来,构建更加智能、高效、可靠的数字基础设施。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 25
25 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)