【前瞻创想】从理论到实践:深入解析Kurator分布式云原生平台架构与企业级应用落地指南
【前瞻创想】从理论到实践:深入解析Kurator分布式云原生平台架构与企业级应用落地指南
【前瞻创想】从理论到实践:深入解析Kurator分布式云原生平台架构与企业级应用落地指南

摘要
本文深入剖析Kurator这一开源分布式云原生平台,从架构设计到企业级实践全面解读。文章首先介绍Kurator的核心价值与组件生态,包括Karmada、KubeEdge、Volcano等关键开源项目的集成优势;随后详细演示环境搭建与安装流程,提供从零到一的实战指导;继而深入探讨GitOps、多集群调度、服务治理等核心场景的实现细节,结合真实代码示例展示技术深度;最后展望分布式云原生技术发展趋势,为企业数字化转型提供专业建议。通过理论与实践相结合的方式,帮助读者全面掌握Kurator平台的核心能力与应用价值,为构建现代化分布式云原生基础设施提供参考。
1. Kurator云原生平台概览与核心价值
1.1 分布式云原生的时代背景与技术挑战
随着企业数字化转型深入,传统的单集群云原生架构已无法满足业务发展需求。多云、混合云、边缘计算等场景的兴起,带来了资源分散、管理复杂、服务割裂等挑战。特别是在金融、制造、零售等行业,业务需要在中心云、区域云、边缘节点之间无缝协同,这对云原生技术提出了更高要求。
分布式云原生平台应运而生,它需要解决的核心问题包括:如何统一管理异构基础设施,如何实现应用的跨集群部署与调度,如何保障多环境下的服务连续性,以及如何简化运维复杂度。这些挑战催生了像Kurator这样的新一代云原生平台,它通过整合多个优秀的开源项目,构建了完整的分布式云原生解决方案。
1.2 Kurator架构设计与技术栈整合
Kurator架构参考图: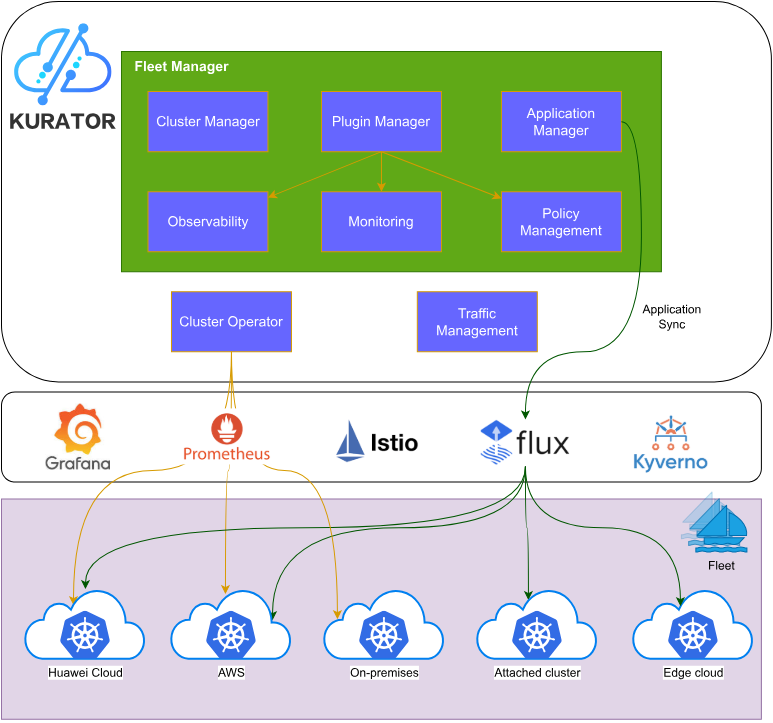
Kurator是一个站在巨人肩膀上的分布式云原生平台,它深度集成了Kubernetes、Istio、Prometheus、FluxCD、KubeEdge、Volcano、Karmada、Kyverno等云原生领域最优秀的开源项目。这种整合不是简单的拼凑,而是通过精心设计的架构,将这些组件的能力无缝融合,形成1+1>2的效果。
从架构层面看,Kurator采用分层设计思想:基础设施层负责多云、多集群、边缘节点的统一纳管;资源调度层提供统一的调度策略与弹性伸缩能力;应用管理层实现GitOps驱动的应用分发与同步;服务治理层确保跨集群的服务发现与通信;观测层提供统一的监控、日志、追踪能力。这种层次化的架构设计,使得Kurator能够灵活应对各种复杂场景。
1.3 Kurator的核心价值与差异化优势
Kurator的核心价值如图所示:
相比传统的云原生平台,Kurator具有显著的差异化优势。首先,它真正实现了"基础设施即代码"的理念,通过声明式API管理集群、节点、VPC等基础设施资源,大大降低了运维复杂度。其次,Kurator提供了开箱即用的能力,一键安装完整的云原生软件栈,加速企业上云进程。
更重要的是,Kurator解决了分布式环境下的"一致性"问题。通过Fleet概念,它实现了集群注册与注销、应用定制化同步、命名空间/服务账户/服务的相同性、跨集群服务发现、聚合监控指标、统一策略管理等关键能力。这些能力在企业级应用中至关重要,能够确保业务在复杂环境中稳定运行。
2. Kurator核心组件深度剖析
2.1 Fleet多集群管理架构设计
Fleet架构官网参考图: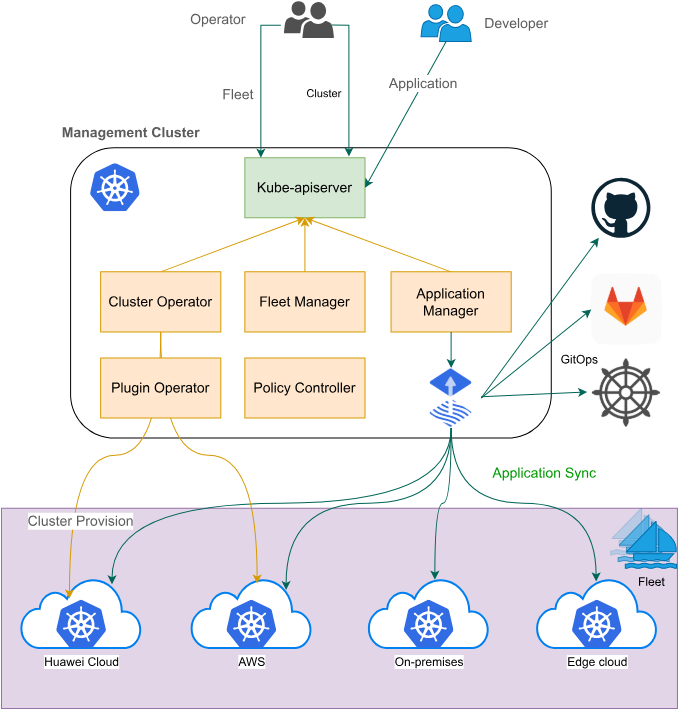
Fleet是Kurator的核心抽象,代表一组协同工作的Kubernetes集群。Fleet架构设计的关键在于如何实现集群的统一管理与资源的协同调度。在Fleet中,每个集群保持自治性,同时又能参与全局资源调度和服务治理。
Fleet架构包含三个核心组件:Fleet Controller负责集群生命周期管理;Resource Syncer实现跨集群资源配置同步;Service Mesh Integration提供跨集群服务发现。这种设计使得Fleet既能保持集群的独立性,又能实现资源的全局优化。例如,当一个应用需要部署到多个集群时,Fleet Controller会根据策略自动选择目标集群,Resource Syncer确保配置一致性,Service Mesh Integration则确保服务能够跨集群调用。
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
meta
name: production-fleet
spec:
clusters:
- name: cluster-east
kubeconfigSecret: cluster-east-kubeconfig
- name: cluster-west
kubeconfigSecret: cluster-west-kubeconfig
placement:
clusterSelector:
region: production
strategy: spread
2.2 Karmada跨集群调度与弹性伸缩实践
Karmada 的总体架构参考图: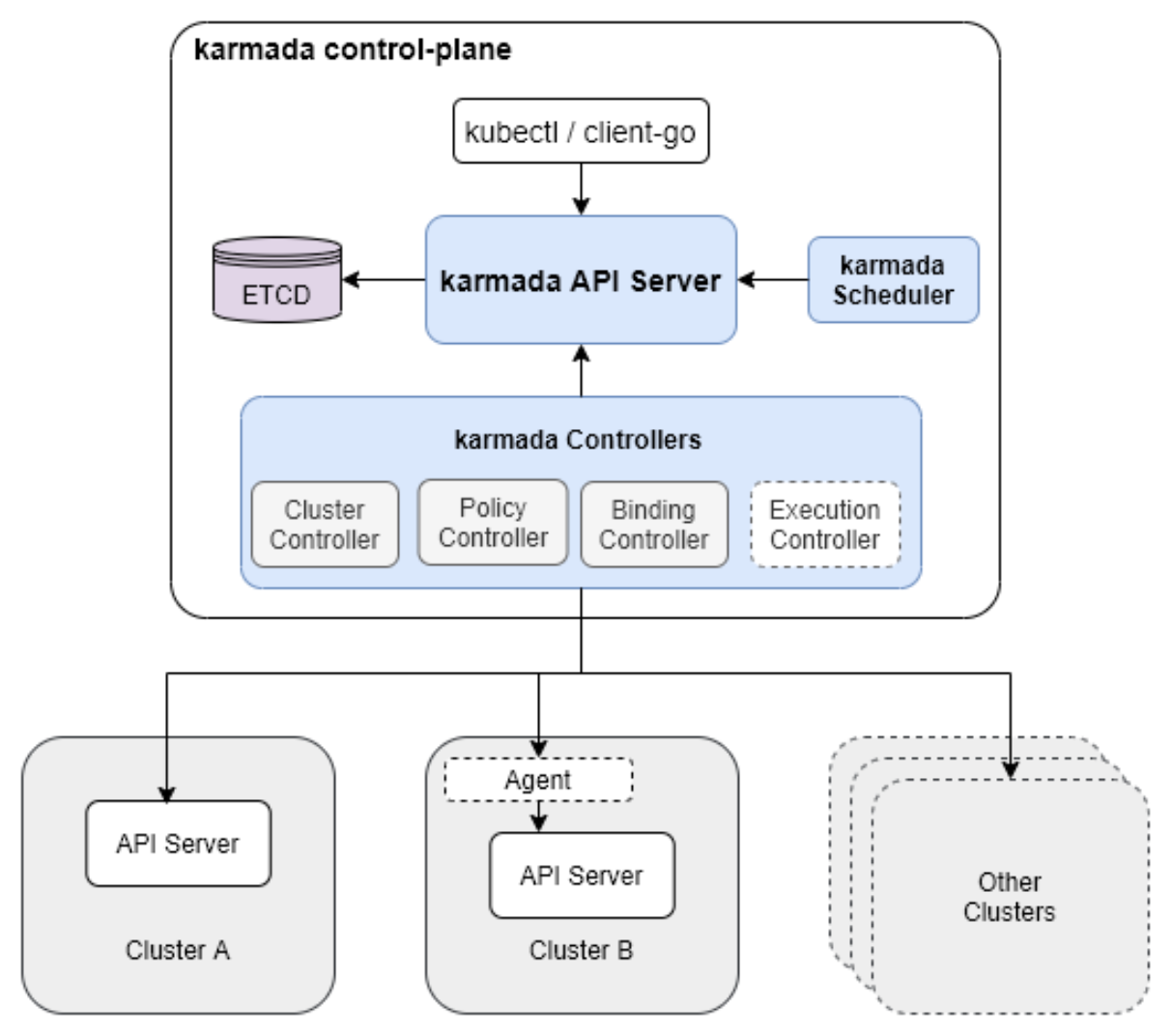
Karmada是Kurator集成的关键组件,专注于多集群应用调度。它通过Propagator、Scheduler、Executor三个核心组件实现应用的跨集群分发。在Kurator中,Karmada的能力被进一步增强,支持更复杂的调度策略和弹性伸缩场景。
跨集群弹性伸缩是Karmada的核心价值之一。当单一集群资源不足时,Karmada能够自动将工作负载迁移到其他集群,确保应用的高可用性。这种能力在大促、突发事件等场景下尤为重要。Karmada的弹性伸缩不仅考虑CPU、内存等基础资源,还支持基于自定义指标的智能调度,如业务量、响应时间等。
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: nginx
placement:
clusterAffinity:
clusterNames:
- cluster-east
- cluster-west
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightList:
- targetCluster:
clusterNames:
- cluster-east
weight: 2
- targetCluster:
clusterNames:
- cluster-west
weight: 1
2.3 KubeEdge边缘计算架构与核心组件
KubeEdge架构官网参考图: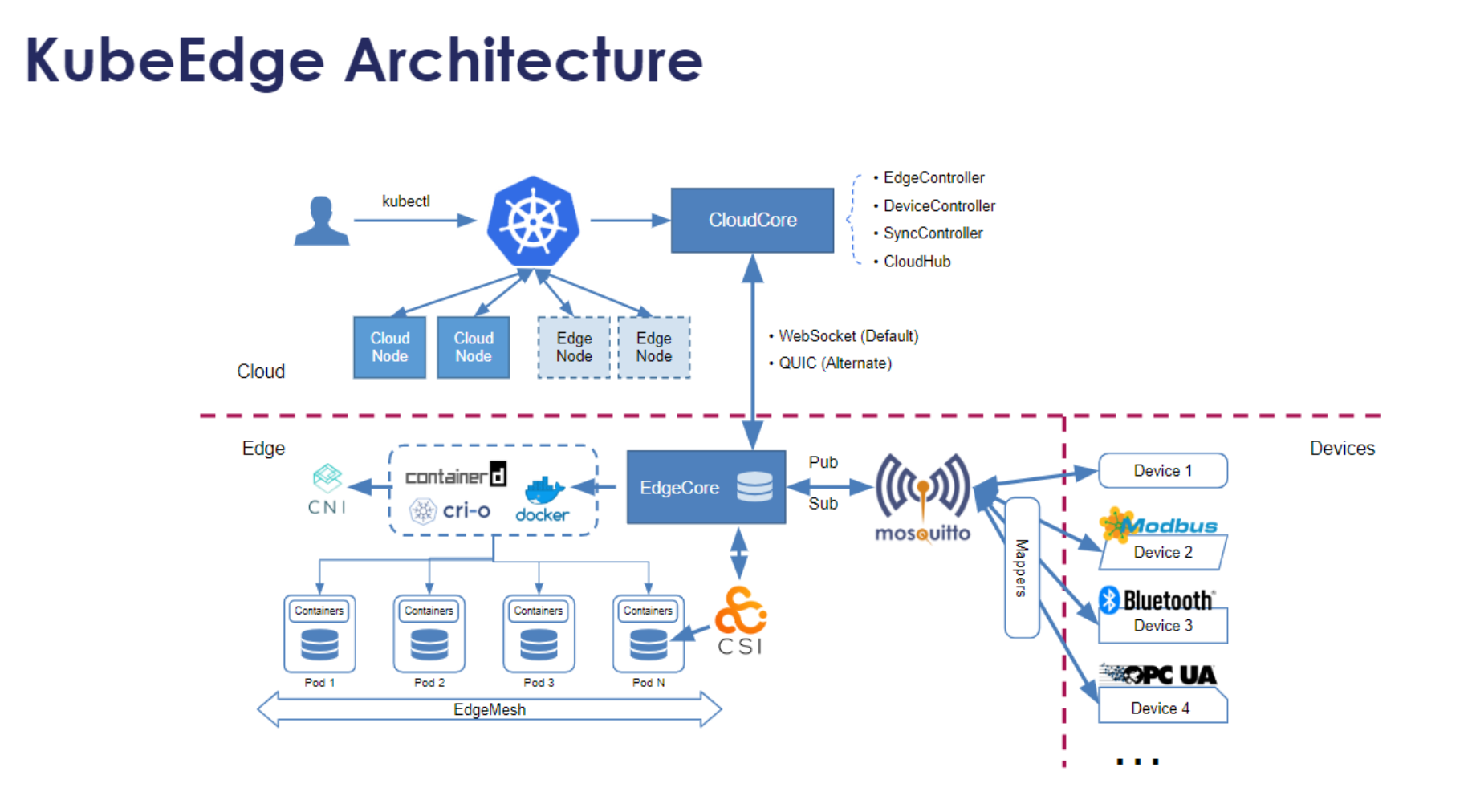 KubeEdge的核心组件参考图:
KubeEdge的核心组件参考图: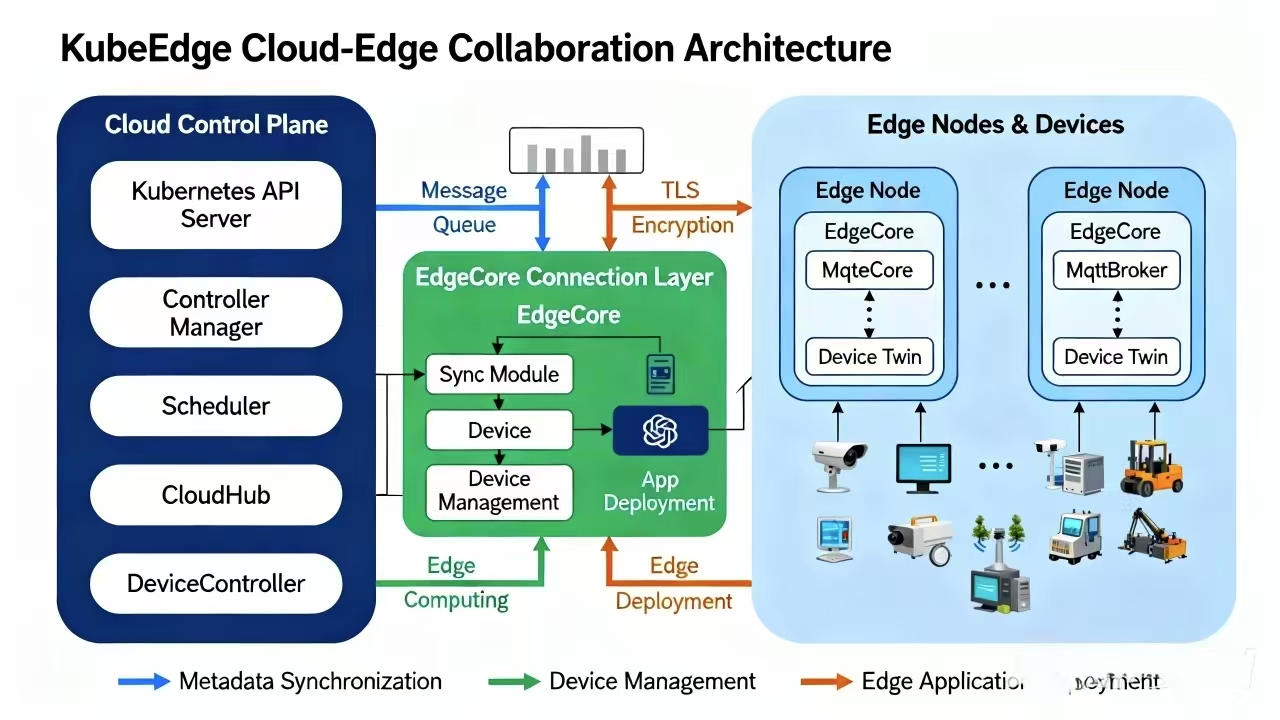
KubeEdge为Kurator提供了强大的边缘计算能力,它将Kubernetes的能力延伸到边缘节点,解决了边缘场景下的网络不稳定、资源受限等挑战。KubeEdge的核心架构包括CloudCore(云端组件)和EdgeCore(边缘组件),通过WebSocket和Quic协议实现可靠通信。
在Kurator中,KubeEdge的集成不仅仅是技术实现,更是业务场景的创新。例如,在智能制造场景中,Kurator可以统一管理工厂内的边缘设备和云端资源,实现数据的本地处理和云端分析。KubeEdge的Device CRD为边缘设备提供了标准化管理接口,而EdgeMesh则解决了边缘节点间的服务发现与通信问题。
# 在Kurator中部署KubeEdge边缘节点
kubectl apply -f - <<EOF
apiVersion: edge.kurator.dev/v1alpha1
kind: EdgeNode
meta
name: factory-edge-01
spec:
clusterName: production-fleet
labels:
location: factory-floor
type: industrial
edgeCoreVersion: v1.12.0
runtimeType: docker
nodeIP: 192.168.1.100
EOF
3. 环境搭建与Kurator安装实战
3.1 前置环境准备与依赖检查
在安装Kurator之前,需要确保环境满足基本要求。首先,需要一个运行中的Kubernetes集群(版本1.20+),建议使用至少3节点的集群以获得最佳体验。其次,需要安装基本工具链,包括kubectl、helm、git等。最后,需要确保网络连通性,特别是能够访问GitHub和Docker Hub。
环境检查是安装成功的关键步骤。需要验证kubectl配置是否正确,helm版本是否兼容,以及集群资源是否充足。特别是在生产环境中,还需要考虑存储类、网络插件、安全策略等因素。Kurator提供了详细的检查清单,帮助用户快速识别潜在问题。
# 环境检查脚本
echo "检查kubectl版本..."
kubectl version --client --short
echo "检查helm版本..."
helm version --short
echo "检查集群节点状态..."
kubectl get nodes
echo "检查存储类..."
kubectl get storageclass
echo "检查网络插件..."
kubectl get pods -n kube-system | grep -E 'calico|flannel|cilium'
3.2 源码编译与安装流程详解
Kurator提供了灵活的安装方式,既可以从源码编译,也可以使用预构建的镜像。对于开发者和高级用户,从源码编译能够获得最新的功能和定制能力。以下是详细的源码安装流程:
到项目地址中,可以看到可以clone到本地
https://gitcode.com/kurator-dev/kurator.git
或者我们也可以下载到本地
可以看到我们资源文件已经下载下来了
编译完成后,需要配置Kurator的安装参数。Kurator使用Helm Chart进行部署,可以通过values.yaml文件定制配置。关键配置包括:集群网络CIDR、存储类、镜像仓库、认证方式等。在生产环境中,建议使用私有镜像仓库和TLS加密通信。
# values.yaml 示例
global:
imageRegistry: docker.io/kurator
imagePullSecrets:
- name: registry-secret
fleet:
enabled: true
replicas: 3
resources:
requests:
memory: 256Mi
cpu: 100m
limits:
memory: 512Mi
cpu: 500m
karmada:
enabled: true
scheduler:
replicas: 2
kubeedge:
enabled: false # 按需启用
3.3 集群初始化与基础配置验证
安装完成后,需要进行集群初始化和基础配置验证。首先,创建Fleet资源,将现有集群注册到Kurator管理平面。然后,部署测试应用,验证多集群调度和服务发现功能。最后,配置监控和告警,确保系统可观测性。
验证步骤应该包括:检查所有Pod状态、验证跨集群服务调用、测试应用分发能力、确认监控数据采集等。这些验证不仅确保安装成功,也为后续的高级功能使用奠定基础。在企业环境中,建议编写自动化验证脚本,集成到CI/CD流水线中。
# 初始化Fleet
kubectl apply -f examples/fleet.yaml
# 验证Fleet状态
kubectl get fleet
kubectl get clusters.fleet.kurator.dev
# 部署测试应用
kubectl apply -f examples/nginx-deployment.yaml
kubectl apply -f examples/nginx-service.yaml
# 验证跨集群服务
kubectl exec -it nginx-pod -- curl http://nginx-service.production-fleet.svc.cluster.local
4. GitOps在Kurator中的实践与创新
4.1 FluxCD在Kurator中的集成与应用
FluxCD Helm 应用的示意图: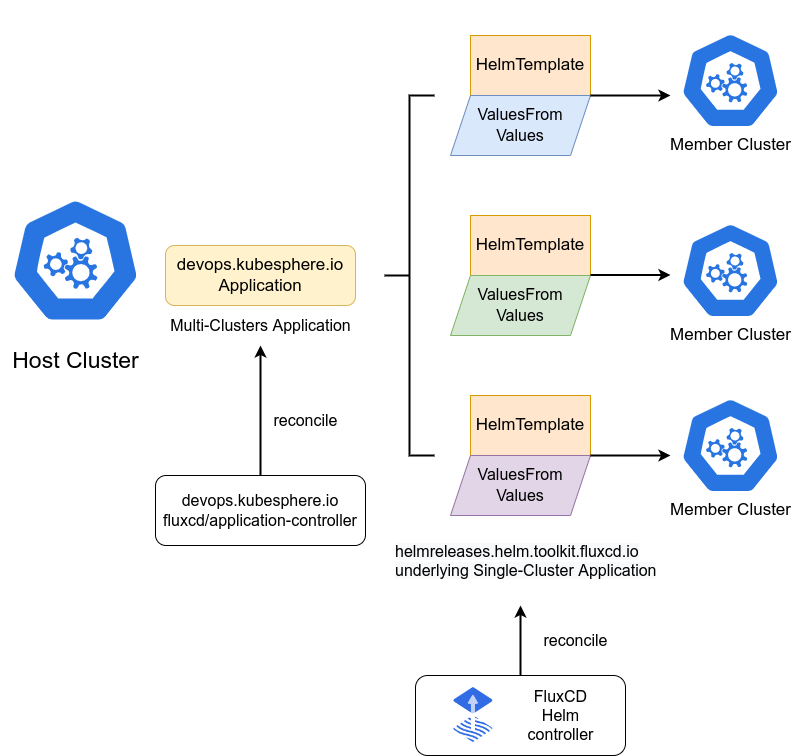
GitOps是现代云原生应用管理的核心范式,Kurator深度集成了FluxCD作为其GitOps引擎。FluxCD提供了Kustomize控制器、Helm控制器、源控制器等核心组件,实现了从Git仓库到Kubernetes集群的自动化同步。在Kurator中,FluxCD的能力被扩展到多集群场景,支持跨集群的配置同步和版本控制。
Kurator对FluxCD的增强主要体现在三个方面:首先是多集群感知能力,能够根据集群标签自动选择目标集群;其次是策略驱动的同步机制,支持灰度发布、金丝雀发布等高级部署策略;最后是安全增强,提供签名验证、加密存储等安全特性。这些增强使得FluxCD在企业级场景中更加可靠和灵活。
apiVersion: source.toolkit.fluxcd.io/v1beta1
kind: GitRepository
meta
name: kurator-apps
namespace: flux-system
spec:
interval: 1m0s
url: https://github.com/your-org/kurator-apps
ref:
branch: main
secretRef:
name: git-auth
---
apiVersion: kustomize.toolkit.fluxcd.io/v1beta1
kind: Kustomization
meta
name: apps
namespace: flux-system
spec:
interval: 5m0s
path: "./clusters/production"
prune: true
sourceRef:
kind: GitRepository
name: kurator-apps
targetNamespace: production
wait: true
timeout: 2m0s
4.2 多集群GitOps工作流设计
GitOps工作流参考图:
在多集群环境中,GitOps工作流需要考虑更多复杂性。Kurator提供了创新的多集群GitOps模式,通过分层的Git仓库结构实现环境隔离和版本控制。典型的仓库结构包括:基础设施层(定义集群配置)、平台层(定义中间件和服务)、应用层(定义业务应用)。
每个层次都有独立的同步策略和权限控制。例如,基础设施层的变更需要严格的审批流程,而应用层可以采用更敏捷的发布节奏。Kurator通过Fleet资源抽象,将Git仓库中的配置映射到具体集群,实现了"一次定义,多处运行"的能力。这种设计既保证了环境一致性,又提供了必要的灵活性。
# 多集群Git仓库结构示例
kurator-apps/
├── clusters/
│ ├── production/
│ │ ├── fleet.yaml
│ │ ├── karmada-policy.yaml
│ │ └── kustomization.yaml
│ ├── staging/
│ │ ├── fleet.yaml
│ │ └── kustomization.yaml
│ └── development/
│ ├── fleet.yaml
│ └── kustomization.yaml
├── infrastructure/
│ ├── clusters/
│ │ ├── production.yaml
│ │ └── staging.yaml
│ └── nodes/
│ ├── edge-nodes.yaml
│ └── cloud-nodes.yaml
└── applications/
├── frontend/
│ ├── base/
│ ├── overlays/
│ │ ├── production/
│ │ ├── staging/
│ │ └── development/
│ └── kustomization.yaml
└── backend/
├── base/
├── overlays/
│ ├── production/
│ ├── staging/
│ └── development/
└── kustomization.yaml
4.3 Helm应用在多环境下的分发与同步
Helm是Kubernetes应用包管理的事实标准,Kurator通过FluxCD Helm控制器实现了Helm应用的多集群分发。与单集群场景不同,多集群Helm部署需要考虑环境差异、版本一致性、回滚策略等问题。Kurator提供了环境感知的HelmRelease资源,能够根据集群标签自动应用不同的配置。
在实践中,我们发现Helm应用的多集群管理需要解决几个关键问题:首先是Chart版本控制,需要确保所有集群使用相同版本的Chart;其次是值文件管理,不同环境需要不同的配置值;最后是生命周期管理,需要协调多个集群的升级和回滚操作。Kurator通过声明式的API和自动化的工作流,有效解决了这些问题。
apiVersion: helm.toolkit.fluxcd.io/v2beta1
kind: HelmRelease
meta
name: prometheus
namespace: monitoring
spec:
chart:
spec:
chart: prometheus
version: "15.5.2"
sourceRef:
kind: HelmRepository
name: prometheus-community
namespace: flux-system
interval: 5m
install:
remediation:
retries: 3
upgrade:
remediation:
retries: 3
values:
server:
persistentVolume:
enabled: true
storageClass: "standard"
alertmanager:
enabled: true
# 集群特定配置
targetClusters:
- name: production-fleet
clusterSelector:
environment: production
values:
server:
resources:
requests:
memory: 2Gi
cpu: 1000m
limits:
memory: 4Gi
cpu: 2000m
- name: staging-fleet
clusterSelector:
environment: staging
values:
server:
resources:
requests:
memory: 1Gi
cpu: 500m
limits:
memory: 2Gi
cpu: 1000m
5. 统一调度与资源管理深度实践
5.1 Volcano调度架构与工作流分析
Volcano调度架构官方参考图: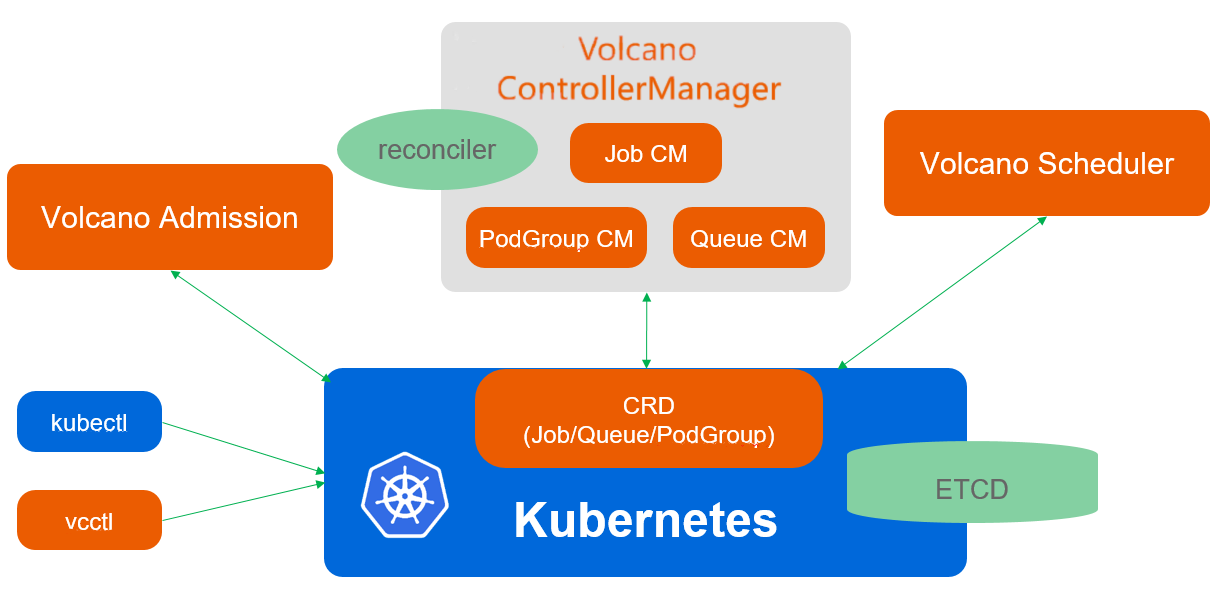
Volcano是Kurator集成的批处理调度器,专注于AI、大数据、HPC等计算密集型工作负载。与Kubernetes默认调度器不同,Volcano提供了任务队列、分组调度、拓扑感知等高级调度能力。在Kurator中,Volcano与Karmada深度集成,实现了跨集群的批处理任务调度。
Volcano的架构核心是Scheduler Framework,它通过插件机制支持多种调度策略。关键插件包括:Queue插件管理任务队列,Binpack插件优化资源利用率,DRF插件实现公平调度。在AI训练场景中,Volcano能够将GPU密集型任务调度到具有GPU资源的集群,同时考虑网络带宽、存储性能等因素。
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
meta
name: gpu-queue
spec:
weight: 1
capability:
cpu: "64"
memory: "256Gi"
nvidia.com/gpu: "8"
reclaimable: true
---
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
meta
name: tensorflow-training
spec:
minAvailable: 4
schedulerName: volcano
queue: gpu-queue
tasks:
- replicas: 4
name: worker
template:
spec:
containers:
- image: tensorflow/tensorflow:latest-gpu
name: tensorflow
resources:
limits:
nvidia.com/gpu: 1
cpu: "8"
memory: "32Gi"
command: ["python", "/app/train.py"]
nodeSelector:
node-type: gpu
5.2 PodGroup与Queue资源调度策略
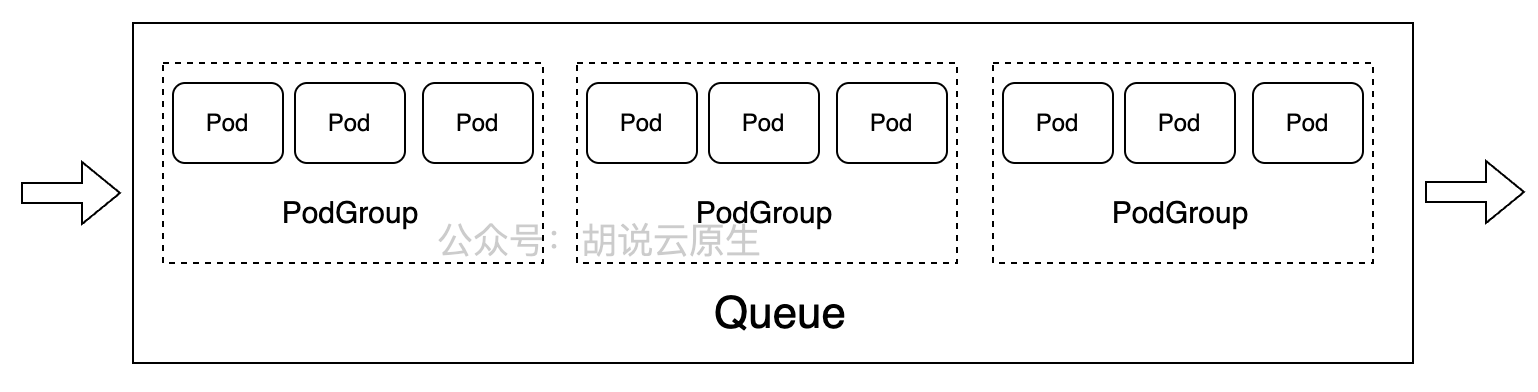
PodGroup和Queue是Volcano的核心概念,它们解决了Kubernetes原生调度器在批处理场景下的局限性。PodGroup定义了一组需要同时调度的Pod,确保它们要么全部成功调度,要么全部失败。Queue则提供了多租户资源隔离和优先级调度能力。
在Kurator中,PodGroup与Queue的结合使用能够实现复杂的调度场景。例如,在机器学习训练中,一个训练任务可能需要多个GPU节点协同工作,通过PodGroup确保所有训练节点同时可用;通过Queue实现不同团队之间的资源配额管理,避免资源争抢。这种设计特别适合科研机构、AI实验室等需要共享计算资源的场景。
# 查看Queue状态
kubectl get queues.scheduling.volcano.sh
# 查看PodGroup状态
kubectl get podgroups.scheduling.volcano.sh
# 查看Volcano调度事件
kubectl logs -f -l app=volcano-scheduler -n volcano-system
# 动态调整Queue资源配额
kubectl patch queue.scheduling.volcano.sh/gpu-queue -p '{"spec":{"capability":{"nvidia.com/gpu":"16"}}}' --type=merge
5.3 跨集群弹性伸缩与资源优化
Karmada跨集群弹性伸缩 参考图: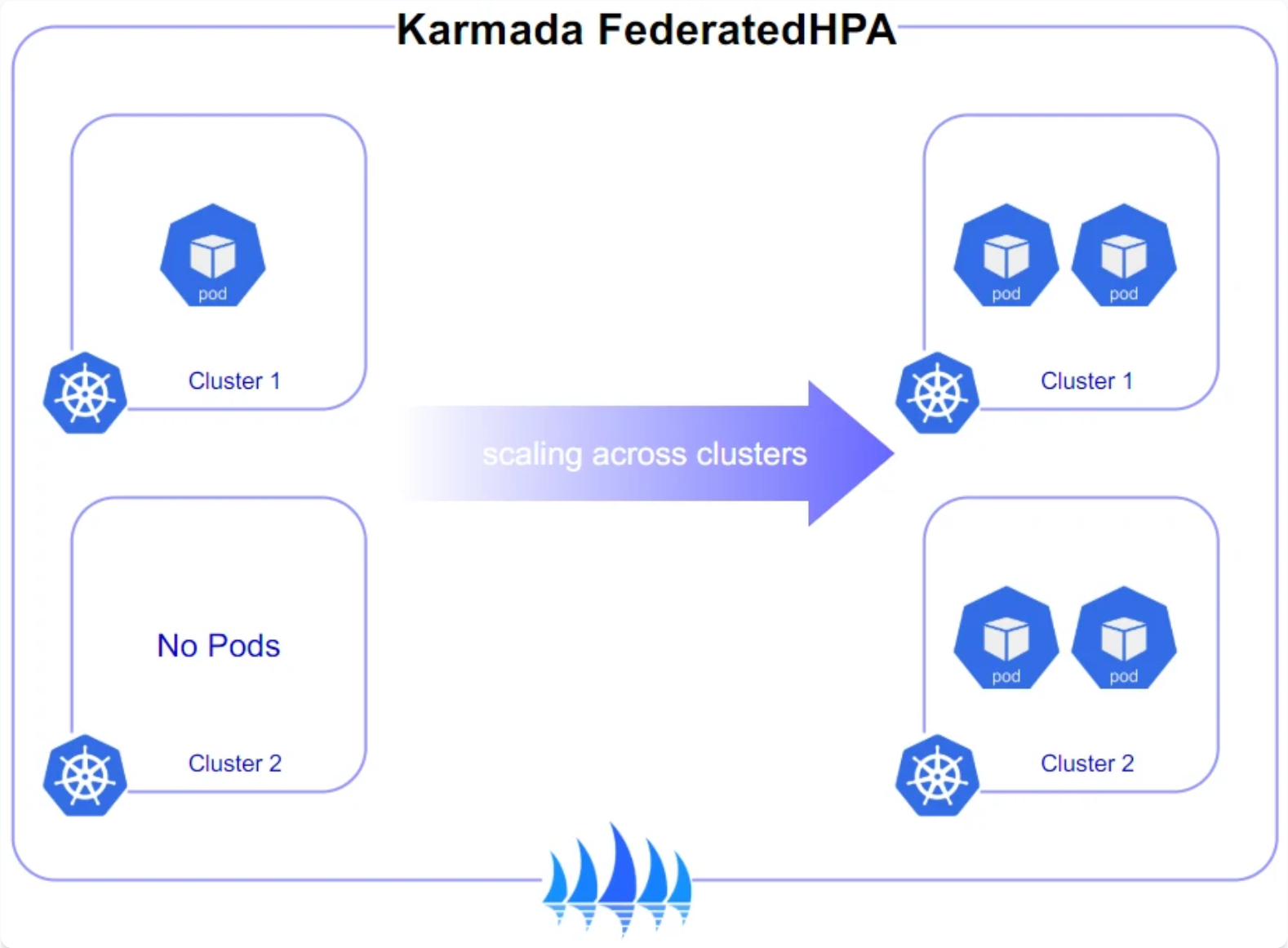
跨集群弹性伸缩是Kurator的核心能力之一,它结合了Karmada的集群调度和Volcano的任务调度,实现了多维度的资源优化。当单一集群资源不足时,系统可以自动将工作负载迁移到其他集群;当任务队列积压时,可以动态扩展计算资源。
在实践中,我们设计了一套智能弹性伸缩策略,综合考虑资源利用率、任务优先级、成本因素等。例如,在夜间低峰期,可以将计算密集型任务调度到成本较低的区域;在白天高峰期,优先保证高优先级任务的资源需求。这种策略不仅提高了资源利用率,还显著降低了运营成本。
apiVersion: autoscaling.karmada.io/v1alpha1
kind: ClusterPropagationPolicy
meta
name: auto-scaling-policy
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: inference-service
placement:
clusterAffinity:
clusterNames:
- cluster-east
- cluster-west
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
autoScaling:
enabled: true
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
- type: Custom
custom:
name: request-latency
target:
type: Value
value: 100 # milliseconds
cooldownPeriod: 300 # seconds
scaleUpLimit: 200% # maximum scale up percentage
scaleDownLimit: 50% # maximum scale down percentage
6. 多集群服务治理与网络连通性
6.1 Fleet集群间服务发现机制
在多集群环境中,服务发现是最大的挑战之一。Kurator通过集成Istio和Karmada,实现了跨集群的服务发现与通信。核心机制是通过ServiceExport和ServiceImport资源,将服务暴露到Fleet级别,使得不同集群中的服务能够相互发现和调用。
服务发现机制的设计需要考虑几个关键因素:首先是服务版本管理,不同集群可能运行不同版本的服务;其次是流量控制,需要根据延迟、负载等因素智能路由;最后是安全策略,确保跨集群调用的安全性。Kurator通过声明式的API和自动化的配置同步,简化了这些复杂性。
apiVersion: multicluster.x-k8s.io/v1alpha1
kind: ServiceExport
meta
name: frontend
namespace: production
spec:
selector:
app: frontend
---
apiVersion: multicluster.x-k8s.io/v1alpha1
kind: ServiceImport
metadata:
name: frontend
namespace: production
spec:
type: ClusterSetIP
ports:
- port: 80
protocol: TCP
sessionAffinity: None
sessionAffinityConfig: null
ips:
- 10.100.1.10 # cluster-east IP
- 10.100.2.10 # cluster-west IP
6.2 Istio多集群服务网格集成
lstio服务网格参考图: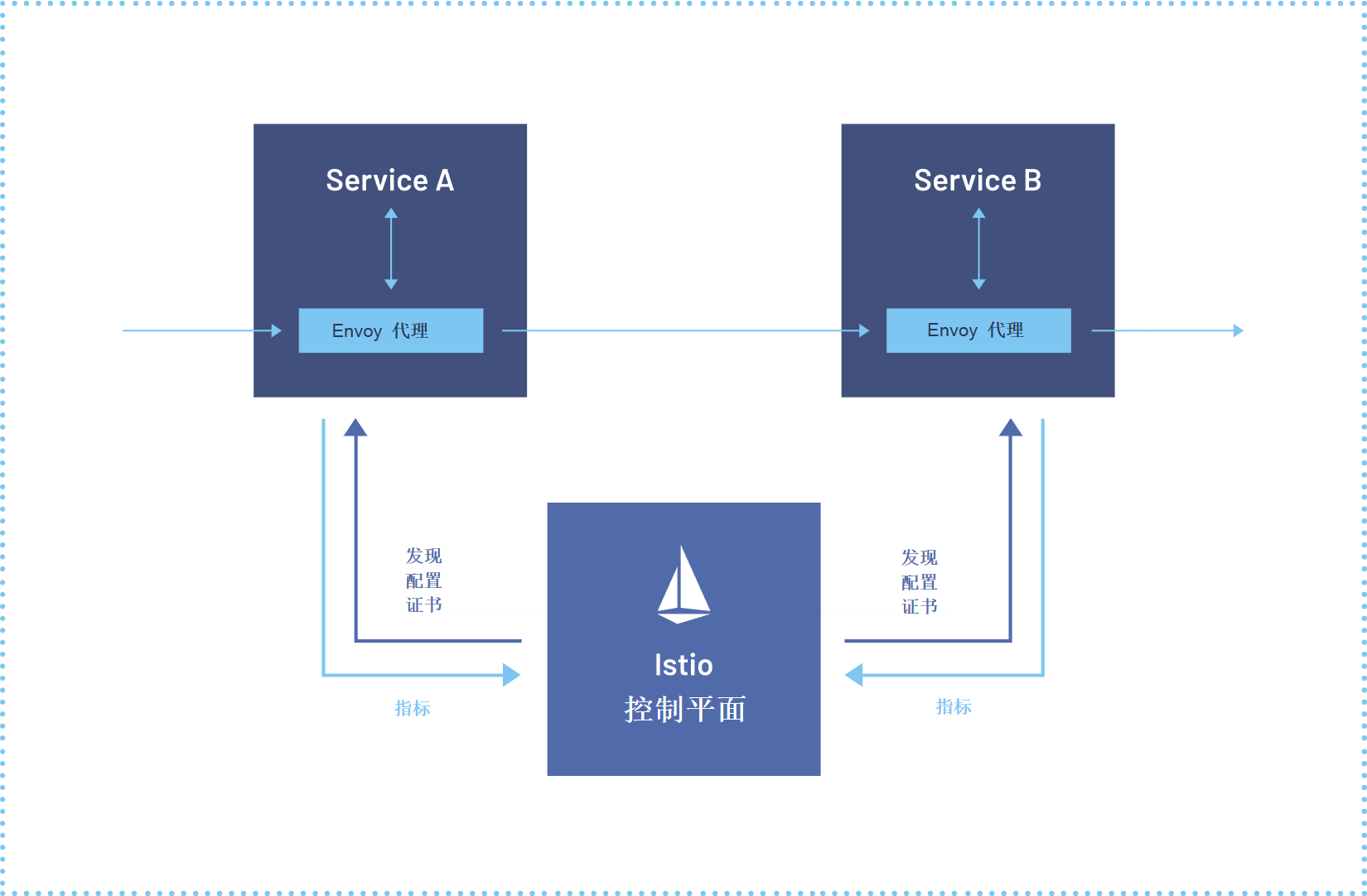
Istio是Kurator集成的服务网格解决方案,它提供了流量管理、安全、可观测性等核心能力。在多集群场景中,Istio通过控制平面共享和数据平面分离的架构,实现了跨集群的服务治理。Kurator对Istio的集成进行了优化,支持多控制平面和单控制平面两种部署模式。
在生产实践中,我们发现单控制平面模式更适合大多数企业场景,它简化了管理复杂度,同时提供了足够的灵活性。Kurator通过自动化工具,简化了Istio在多集群环境中的部署和配置,包括证书管理、网关配置、策略同步等。这种集成使得企业能够快速实现微服务治理,而无需深入Istio的复杂细节。
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
meta
name: frontend-route
namespace: production
spec:
hosts:
- frontend.production.svc.cluster.local
gateways:
- istio-system/ingress-gateway
http:
- route:
- destination:
host: frontend.production.svc.cluster.local
subset: v1
weight: 90
- destination:
host: frontend.production.svc.cluster.local
subset: v2
weight: 10
---
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: frontend-dr
namespace: production
spec:
host: frontend.production.svc.cluster.local
subsets:
- name: v1
labels:
version: v1
- name: v2
labels:
version: v2
trafficPolicy:
loadBalancer:
simple: ROUND_ROBIN
connectionPool:
tcp:
maxConnections: 100
http:
http1MaxPendingRequests: 100
maxRequestsPerConnection: 10
6.3 网络连通性排查与隧道技术实践
网络连通性排查 参考图: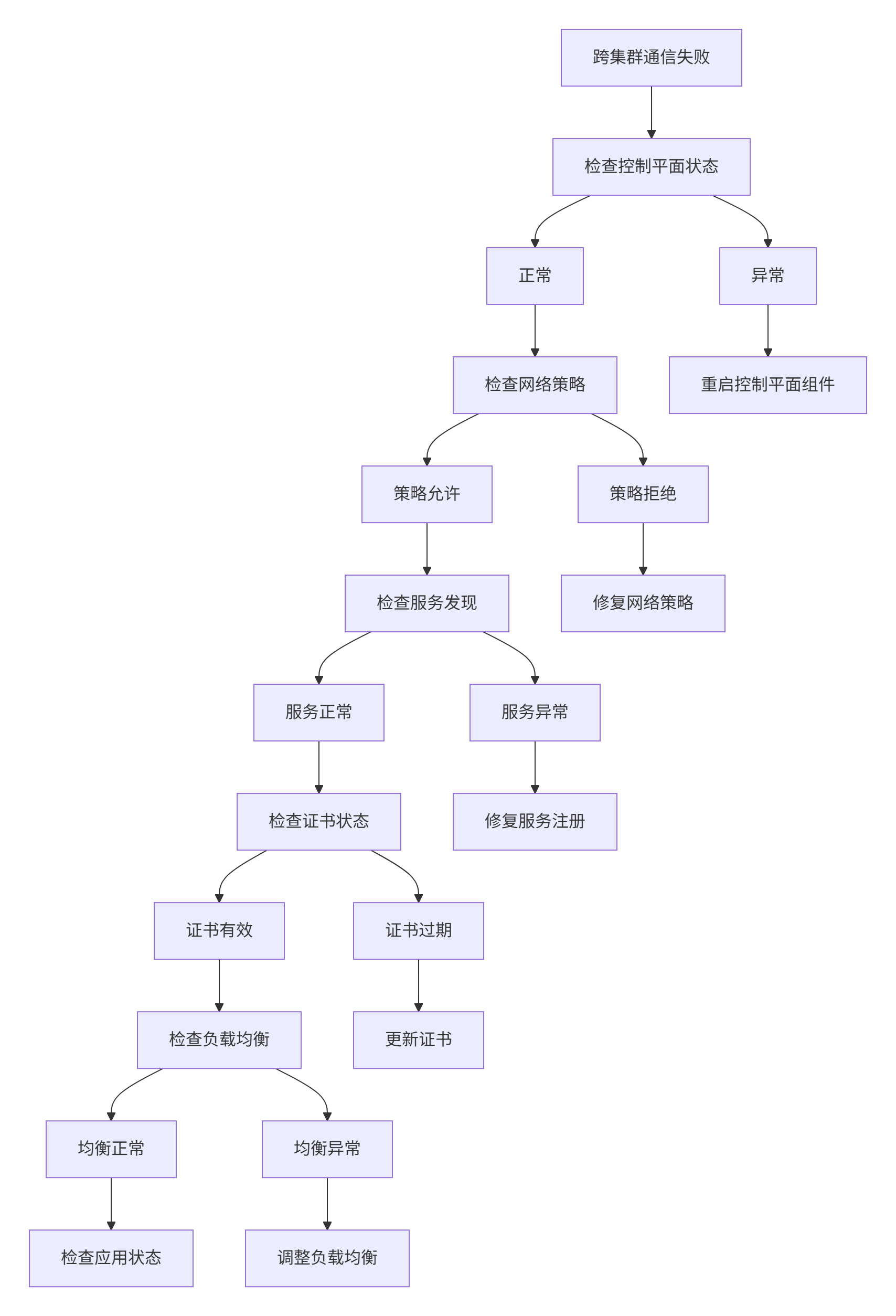
隧道机制参考图: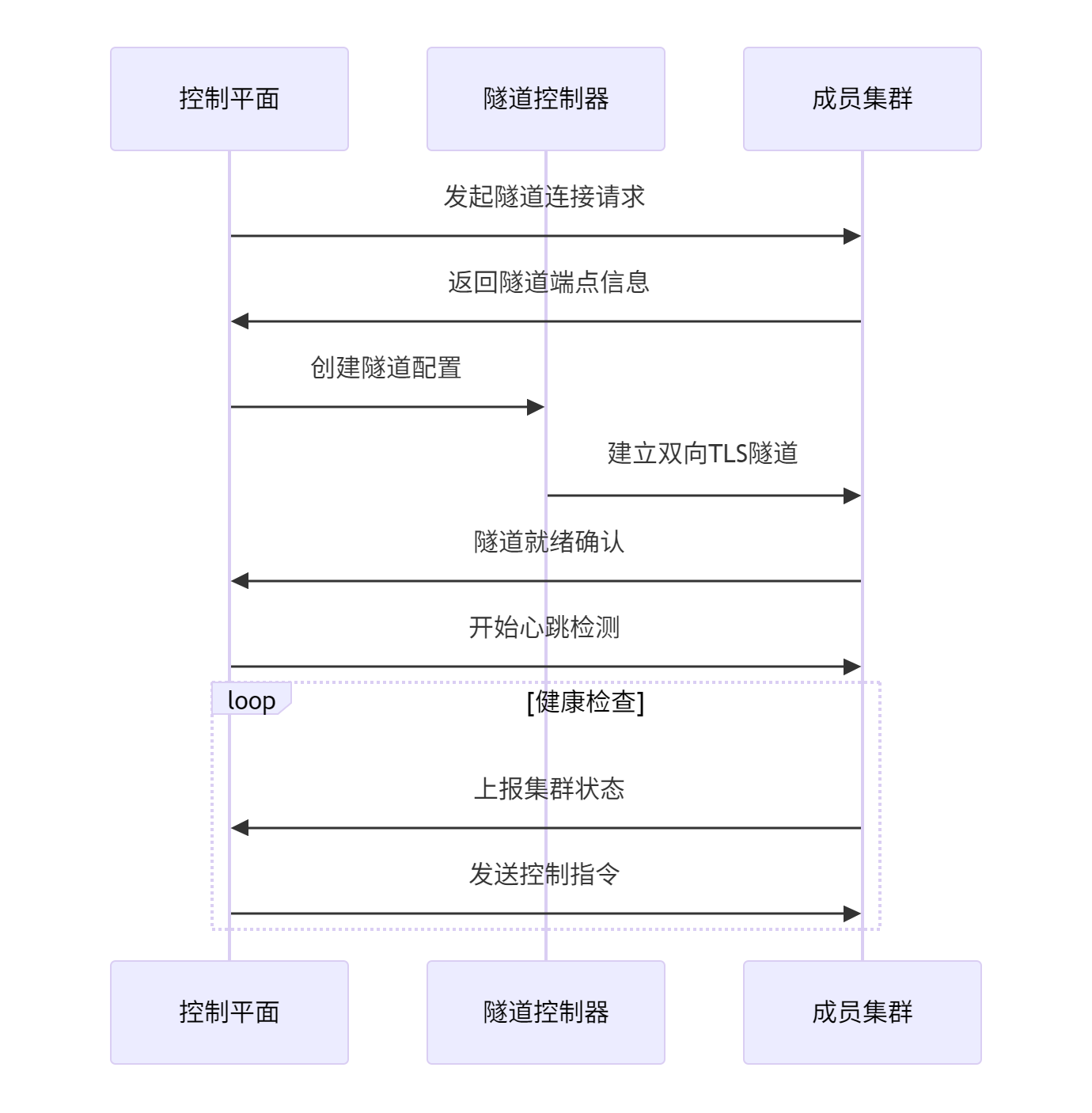
在多集群和边缘计算场景中,网络连通性是最大的挑战之一。Kurator提供了多种网络解决方案,包括隧道技术、Service Mesh、Network Policy等。当遇到网络问题时,需要系统的排查方法和工具。
我们总结了一套网络排查的最佳实践:首先验证基础连通性(ping、traceroute),然后检查服务发现(DNS解析、Service端点),接着分析流量路径(iptables规则、网络策略),最后深入协议层面(TCP抓包、TLS握手)。Kurator集成了多种网络诊断工具,如kube-trace、istioctl analyze等,大大简化了排查过程。
# 网络连通性排查命令集
# 1. 基础连通性检查
kubectl exec -it pod-in-cluster-east -- ping cluster-west-gateway
# 2. 服务发现检查
kubectl exec -it pod-in-cluster-east -- nslookup frontend.production.svc.cluster.local
# 3. 端点检查
kubectl get endpoints frontend -n production
# 4. 网络策略检查
kubectl get networkpolicies -n production
# 5. Istio流量检查
istioctl analyze -n production
istioctl proxy-config clusters pod-in-cluster-east -n production
# 6. 抓包分析
kubectl exec -it pod-in-cluster-east -- tcpdump -i any -w /tmp/capture.pcap host frontend.production.svc.cluster.local
kubectl cp pod-in-cluster-east:/tmp/capture.pcap ./capture.pcap
7. Kurator CI/CD流水线设计与实现
7.1 基础设施即代码(IaC)在Kurator中的应用
基础设施即代码(IaC)是Kurator的核心理念之一,它通过声明式API管理集群、节点、网络等基础设施资源。在Kurator中,IaC不仅限于Kubernetes资源,还扩展到云供应商资源、边缘设备、网络设备等。这种统一的管理方式,使得基础设施变更可以像应用代码一样进行版本控制、代码审查、自动化测试。
Kurator提供了丰富的CRD(Custom Resource Definition)来描述基础设施,如Cluster、NodePool、NetworkPolicy等。这些CRD与GitOps工作流无缝集成,实现了基础设施的自动化部署和变更管理。在企业实践中,我们发现IaC显著提高了基础设施管理的可靠性和效率,减少了人为错误。
apiVersion: infrastructure.kurator.dev/v1alpha1
kind: Cluster
meta
name: production-cluster
spec:
provider: aws
region: us-west-2
version: "1.25"
nodePools:
- name: system-pool
instanceType: m5.xlarge
replicas: 3
labels:
node-role.kubernetes.io/control-plane: ""
- name: worker-pool
instanceType: c5.2xlarge
replicas: 10
labels:
workload-type: compute-intensive
network:
vpcCIDR: "10.0.0.0/16"
serviceCIDR: "10.96.0.0/12"
podCIDR: "10.244.0.0/16"
addons:
- name: istio
version: "1.16"
- name: prometheus
version: "2.40"
7.2 多环境自动化部署流水线构建
在企业级应用中,通常需要维护开发、测试、预发布、生产等多个环境。Kurator通过Fleet和GitOps的结合,实现了多环境的自动化部署流水线。核心思想是通过环境标签和集群选择器,将Git仓库中的配置自动同步到目标环境。
流水线设计需要考虑几个关键点:首先是环境隔离,确保生产环境不会受到开发环境的影响;其次是变更审批,关键环境的变更需要人工审批;最后是回滚机制,当部署失败时能够快速回退。Kurator通过策略引擎和事件驱动架构,实现了灵活的流水线控制。
# .github/workflows/deployment.yaml
name: Kurator Deployment Pipeline
on:
push:
branches: [ main ]
paths:
- 'applications/**'
pull_request:
branches: [ main ]
paths:
- 'applications/**'
jobs:
validate:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Set up Kustomize
uses: imranismail/setup-kustomize@v1
with:
kustomize-version: "4.5"
- name: Validate manifests
run: |
kustomize build applications/overlays/development | kubectl apply --dry-run=client -f -
kustomize build applications/overlays/staging | kubectl apply --dry-run=client -f -
kustomize build applications/overlays/production | kubectl apply --dry-run=client -f -
deploy-development:
needs: validate
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Deploy to development
run: |
kubectl apply -f applications/overlays/development
env:
KUBECONFIG: ${{ secrets.DEV_KUBECONFIG }}
deploy-staging:
needs: deploy-development
runs-on: ubuntu-latest
environment: staging
steps:
- uses: actions/checkout@v3
- name: Deploy to staging
run: |
kubectl apply -f applications/overlays/staging
env:
KUBECONFIG: ${{ secrets.STAGING_KUBECONFIG }}
deploy-production:
needs: deploy-staging
runs-on: ubuntu-latest
environment: production
steps:
- uses: actions/checkout@v3
- name: Deploy to production
run: |
kubectl apply -f applications/overlays/production
env:
KUBECONFIG: ${{ secrets.PROD_KUBECONFIG }}
7.3 安全策略与合规性检查集成
安全是云原生平台的核心关切,Kurator通过集成Kyverno、OPA等策略引擎,实现了全面的安全策略管理。在CI/CD流水线中,安全策略检查是必不可少的环节,包括镜像扫描、配置审计、权限验证等。
Kurator的安全策略分为几个层次:基础设施安全(网络策略、节点安全)、应用安全(容器安全、镜像签名)、数据安全(加密存储、访问控制)。在流水线中,我们集成了多种安全工具,如Trivy(镜像扫描)、kube-bench(CIS基准检查)、kube-score(最佳实践检查),确保每个变更都符合安全标准。
apiVersion: kyverno.io/v1
kind: ClusterPolicy
meta
name: require-pod-security
spec:
validationFailureAction: enforce
rules:
- name: check-root-user
match:
resources:
kinds:
- Pod
validate:
message: "Root user is not allowed. Set runAsNonRoot to true."
pattern:
spec:
securityContext:
runAsNonRoot: true
- name: check-privileged
match:
resources:
kinds:
- Pod
validate:
message: "Privileged containers are not allowed."
pattern:
spec:
containers:
- securityContext:
privileged: false
- name: require-image-signature
match:
resources:
kinds:
- Pod
validate:
message: "Container images must be signed."
pattern:
spec:
containers:
- image: "*"
initContainers:
- image: "*"
conditions:
- key: "{{ images.containers.*.signature_verified }}"
operator: Equals
value: true
8. Kurator未来展望与技术演进
8.1 分布式云原生技术发展趋势
随着5G、物联网、边缘计算的快速发展,分布式云原生技术正在进入新的发展阶段。未来的趋势包括:边缘智能的普及,将AI推理能力下沉到边缘节点;多云管理的标准化,通过统一API管理不同云供应商的资源;服务网格的演进,从流量管理向全面的服务治理发展;以及安全架构的重构,从边界防御向零信任架构转变。
Kurator作为分布式云原生平台,需要紧跟这些趋势,持续创新。特别是在边缘AI、多云成本优化、安全合规等方面,还有很大的发展空间。社区应该加强与CNCF项目、云供应商、行业标准组织的合作,共同推动技术进步。
8.2 Kurator社区生态与开源贡献
开源是Kurator的生命线,社区生态的健康发展至关重要。目前,Kurator已经吸引了来自全球的开发者和用户,贡献包括代码提交、文档改进、案例分享等。未来,社区需要在几个方面加强建设:首先是降低贡献门槛,提供更好的开发者体验;其次是建立完善的治理模型,确保决策透明和公平;最后是加强行业合作,推动在金融、制造、能源等关键行业的落地。
作为开发者,参与开源社区不仅是技术提升的机会,也是职业发展的重要途径。我们鼓励读者从简单的文档改进开始,逐步参与到核心功能开发中。每个贡献都很重要,无论是修复一个bug,还是提出一个新功能建议。
8.3 企业级分布式云原生架构实践建议
基于Kurator的实践经验,我们为企业提供几条关键建议:首先是采用渐进式演进策略,从单集群开始,逐步扩展到多集群、边缘节点;其次是建立完善的治理流程,包括变更管理、权限控制、审计追踪;最后是注重人才培养,建设具备云原生技能的团队。
在技术选型上,建议企业根据自身业务特点选择合适的组件组合。例如,金融行业可能更关注安全和合规,需要加强策略引擎和审计功能;制造行业可能更关注边缘计算能力,需要优化KubeEdge的集成。Kurator的模块化设计,使得企业能够按需选择和定制。
总之,分布式云原生是企业数字化转型的必由之路,Kurator作为这一领域的创新平台,为企业提供了完整的技术解决方案。通过理论与实践的结合,我们相信企业能够构建更加敏捷、可靠、高效的云原生基础设施,为业务创新提供强大支撑。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)