【前瞻创想】Kurator·云原生实战派:从多集群管理到智能调度的深度解析
【前瞻创想】Kurator·云原生实战派:从多集群管理到智能调度的深度解析
【前瞻创想】Kurator·云原生实战派:从多集群管理到智能调度的深度解析
摘要
在云原生技术快速演进的今天,企业面临着多云、混合云、边缘计算等复杂场景的挑战。Kurator作为一个开源的分布式云原生套件,通过深度集成Prometheus、Istio、Karmada、KubeEdge、Volcano等优秀开源项目,为企业提供了一站式的云原生解决方案。本文将从实战角度深入剖析Kurator的核心架构与关键技术,涵盖环境搭建、多集群管理、智能调度、高级发布策略、GitOps实践等多个维度,并结合实际代码示例,展现Kurator在分布式云原生领域的创新价值与未来发展方向。
一、Kurator概述与核心价值
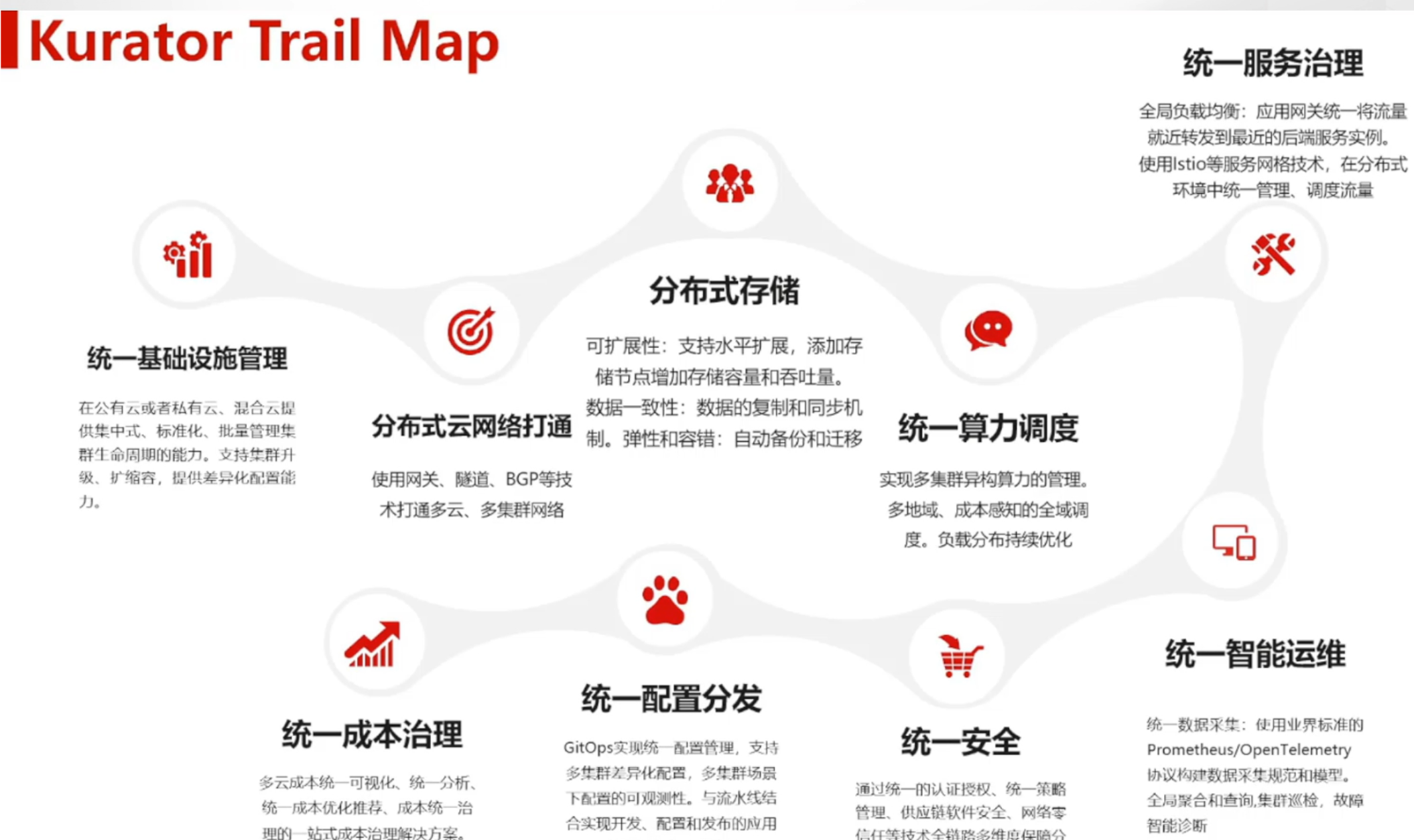
1.1 什么是Kurator
Kurator是由华为云开源的分布式云原生套件,旨在解决企业在多云、混合云、边缘计算场景下的复杂挑战。它不是简单的工具集合,而是通过深度整合多个开源项目,构建了一个完整的云原生技术栈。Kurator的核心价值在于提供统一的管理平面,让开发者能够以一致的方式管理分布在不同地理位置、不同基础设施上的集群资源。
与传统的Kubernetes集群管理工具相比,Kurator更加注重分布式场景下的协同工作能力。它通过抽象层屏蔽了底层基础设施的差异,让开发者可以专注于业务逻辑,而无需关心底层集群的具体实现细节。这种设计理念使得Kurator特别适合需要跨云部署、边缘计算支持的现代化应用架构。
1.2 内置开源项目的创新整合
Kurator的创新之处在于它不是重复造轮子,而是将现有的优秀开源项目进行深度整合和优化。例如,Karmada负责多集群调度,KubeEdge处理边缘计算,Volcano优化批处理作业,Istio提供服务网格能力,Prometheus实现监控告警。Kurator通过统一的API和配置模型,将这些项目无缝集成在一起。
这种整合方式带来了显著的优势:首先,避免了技术栈的碎片化,降低了学习和维护成本;其次,通过统一的配置管理,减少了配置冲突和不一致的风险;最后,Kurator提供了跨项目的协同能力,例如在Karmada调度集群时,可以同时考虑Volcano的队列状态和Istio的流量管理策略,实现更智能的决策。
1.3 分布式云原生的演进方向
从云原生社区的发展趋势来看,分布式云原生已经成为主流方向。传统的单集群架构已经无法满足现代应用的需求,企业需要更加灵活、可扩展的架构来应对业务挑战。Kurator代表了这一趋势的技术实现,它通过分层架构设计,支持从中心云到边缘节点的全栈管理。
未来,随着5G、物联网、AI等技术的发展,分布式云原生将向更加智能化、自动化的方向演进。Kurator作为这一领域的先行者,其架构设计和技术路线为整个行业的技术发展提供了重要参考。特别是在资源调度、服务治理、安全管控等方面,Kurator的实践经验对于构建下一代云原生基础设施具有重要价值。
二、环境搭建与基础配置
2.1 快速部署Kurator
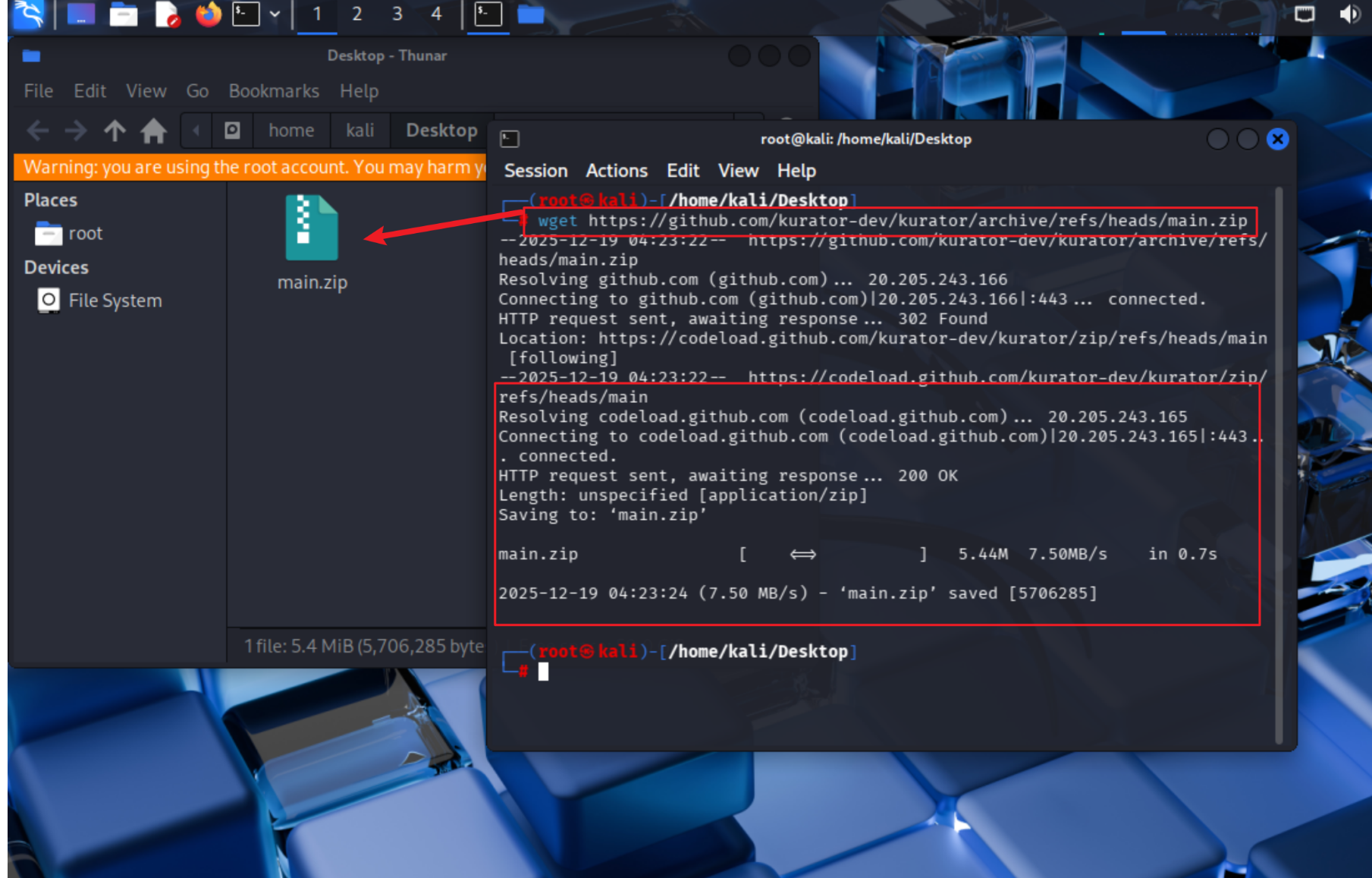
环境搭建是使用Kurator的第一步。下面我们将通过官方提供的脚本来快速部署Kurator。首先需要下载最新的源码包:
wget https://github.com/kurator-dev/kurator/archive/refs/heads/main.zip
unzip main.zip
cd kurator-main
这解压文件
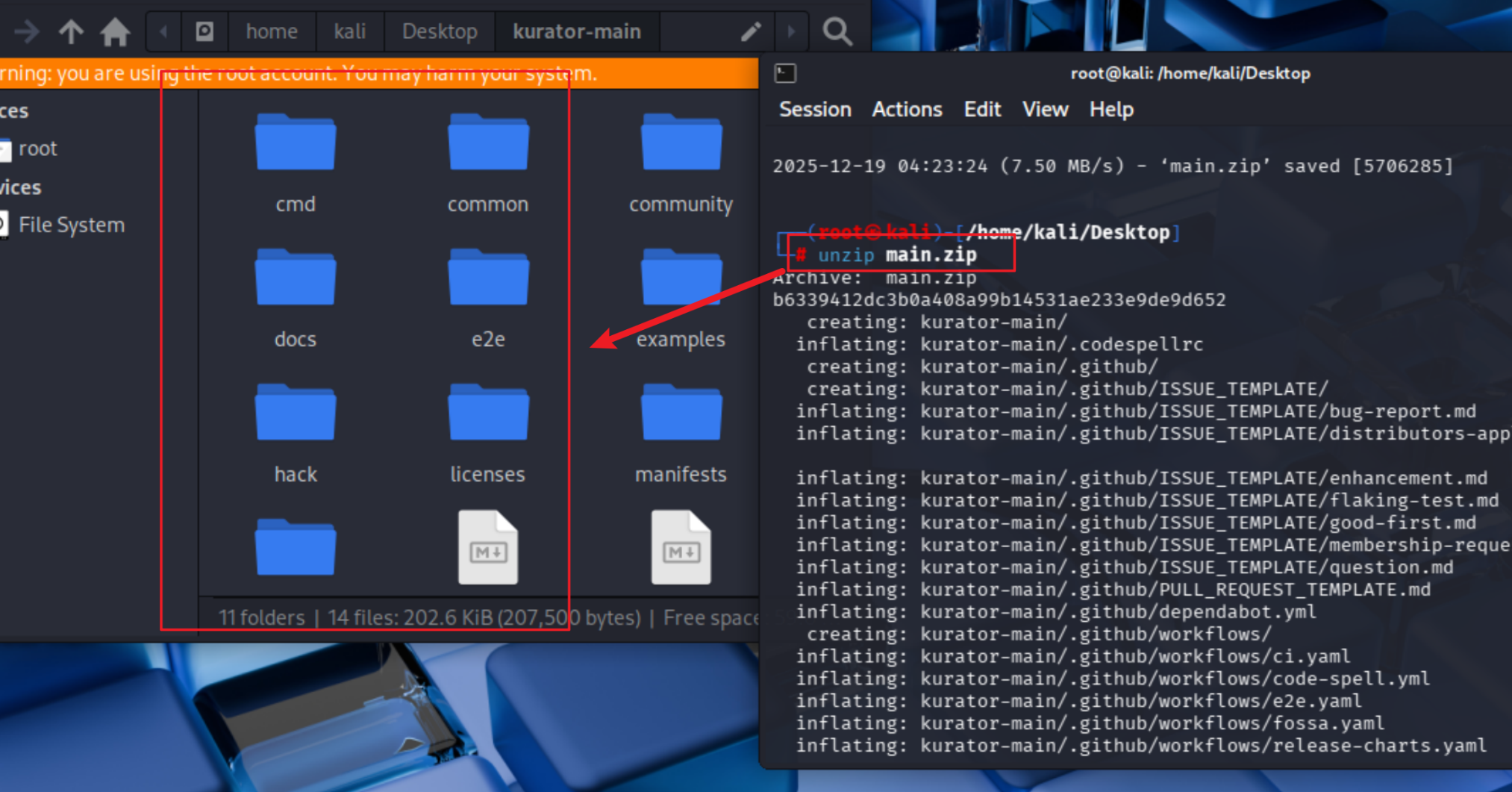
这个命令会下载Kurator的主分支代码,解压后进入源码目录。接下来,我们需要安装依赖工具。Kurator依赖于kubectl、helm等基础工具,确保这些工具已经安装在系统中。然后执行安装脚本:
./scripts/install-kurator.sh
安装脚本会自动检测系统环境,下载必要的组件,并进行初始化配置。这个过程可能需要几分钟时间,具体取决于网络状况和系统性能。安装完成后,可以通过以下命令验证安装结果:
kurator version
kubectl get pods -n kurator-system
2.2 集群初始化与验证
安装完成后,需要对Kurator进行集群初始化。Kurator支持管理多个Kubernetes集群,包括本地集群、公有云集群、边缘集群等。我们首先创建一个Fleet(舰队)来管理这些集群:
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
meta
name: my-fleet
spec:
clusters:
- name: cluster-1
kubeconfigSecret: cluster-1-kubeconfig
- name: cluster-2
kubeconfigSecret: cluster-2-kubeconfig
将上述配置保存为fleet.yaml,然后应用到集群中:
kubectl apply -f fleet.yaml
创建Fleet后,需要为每个集群配置kubeconfig。可以通过创建Secret来存储kubeconfig信息:
kubectl create secret generic cluster-1-kubeconfig --from-file=kubeconfig=./cluster1-kubeconfig.yaml -n kurator-system
kubectl create secret generic cluster-2-kubeconfig --from-file=kubeconfig=./cluster2-kubeconfig.yaml -n kurator-system
验证Fleet状态:
kubectl get fleet my-fleet -o wide
kubectl get clusters -n kurator-system
2.3 基础配置最佳实践
在生产环境中,合理的配置对于系统稳定性至关重要。Kurator提供了丰富的配置选项,以下是一些最佳实践建议:
首先,建议启用监控和日志收集功能。Kurator集成了Prometheus和Grafana,可以通过以下配置启用:
apiVersion: monitoring.kurator.dev/v1alpha1
kind: Monitoring
meta
name: prometheus
spec:
prometheusSpec:
replicas: 2
retention: 30d
grafanaSpec:
enabled: true
adminPassword: securepassword123
其次,配置网络策略以增强安全性。Kurator支持Calico、Cilium等网络插件,建议启用网络策略来限制Pod之间的通信:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
meta
name: default-deny
spec:
podSelector: {}
policyTypes:
- Ingress
- Egress
最后,设置资源配额和限制,防止资源过度使用。可以通过ResourceQuota和LimitRange来实现:
apiVersion: v1
kind: ResourceQuota
meta
name: compute-quota
spec:
hard:
requests.cpu: "10"
requests.memory: 20Gi
limits.cpu: "20"
limits.memory: 40Gi
三、多集群管理:Fleet与Karmada深度集成
3.1 Fleet架构解析
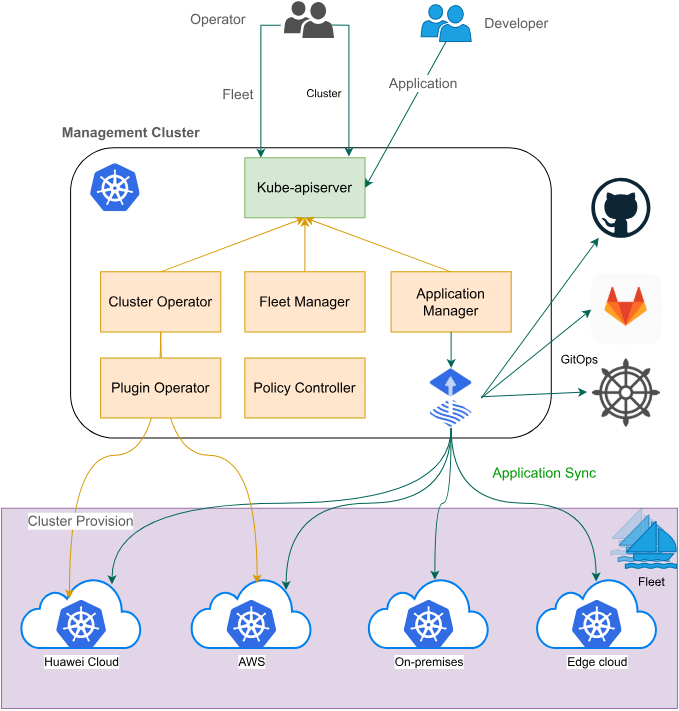
Fleet是Kurator中负责多集群管理的核心组件。它抽象了集群管理的复杂性,提供了统一的API来操作多个集群。Fleet的核心概念包括集群注册、策略分发、状态同步等。与传统的多集群管理工具相比,Fleet更加注重集群之间的协同工作能力。
Fleet的架构设计采用了控制面与数据面分离的模式。控制面运行在中心集群中,负责集群注册、策略计算、状态收集等管理工作;数据面分布在各个成员集群中,负责执行具体的策略和上报状态。这种架构设计确保了系统的可扩展性和高可用性。
Fleet还支持集群分组管理,可以将具有相同特性的集群划分为一个组,然后对组内所有集群应用相同的策略。例如,可以将生产环境的集群划分为一个组,测试环境的集群划分为另一个组,这样可以简化策略管理的复杂度。
3.2 Karmada跨集群调度实战
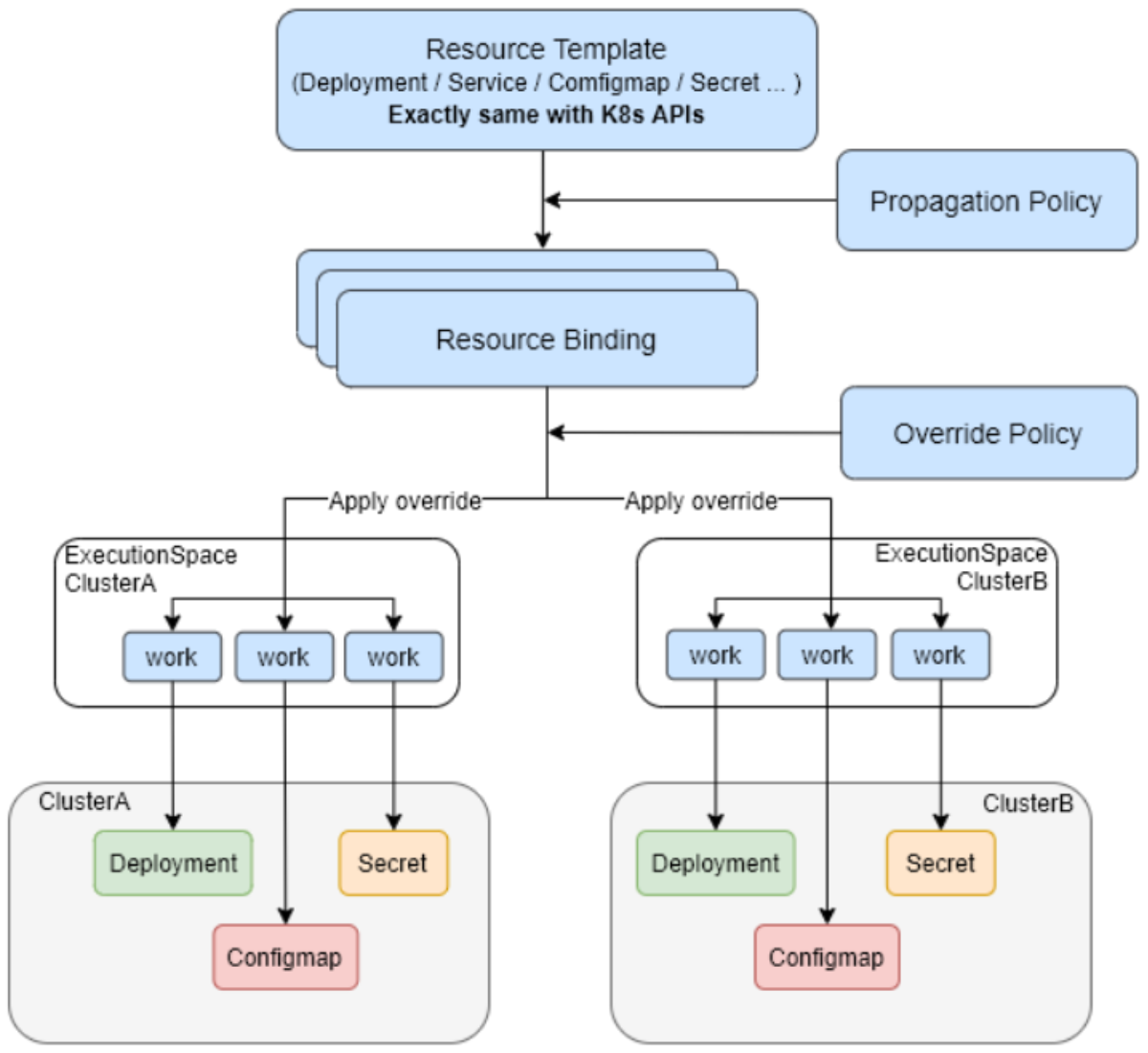
Karmada是Kurator集成的多集群调度引擎,它提供了丰富的调度策略,包括副本调度、集群亲和性、资源平衡等。下面通过一个实际例子来展示Karmada的跨集群调度能力。
首先,创建一个Deployment,并配置Karmada的PropagationPolicy来指定调度策略:
apiVersion: apps/v1
kind: Deployment
meta
name: nginx-deployment
spec:
replicas: 6
selector:
matchLabels:
app: nginx
template:
meta
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.19
ports:
- containerPort: 80
---
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
meta
name: nginx-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: nginx-deployment
placement:
clusterAffinity:
clusterNames:
- cluster-1
- cluster-2
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightList:
- targetCluster:
clusterNames:
- cluster-1
weight: 2
- targetCluster:
clusterNames:
- cluster-2
weight: 1
这个配置将6个副本按照2:1的比例分发到cluster-1和cluster-2两个集群中。应用配置后,可以通过以下命令查看调度结果:
kubectl get deployment nginx-deployment -o wide --context=cluster-1
kubectl get deployment nginx-deployment -o wide --context=cluster-2
3.3 弹性伸缩策略配置
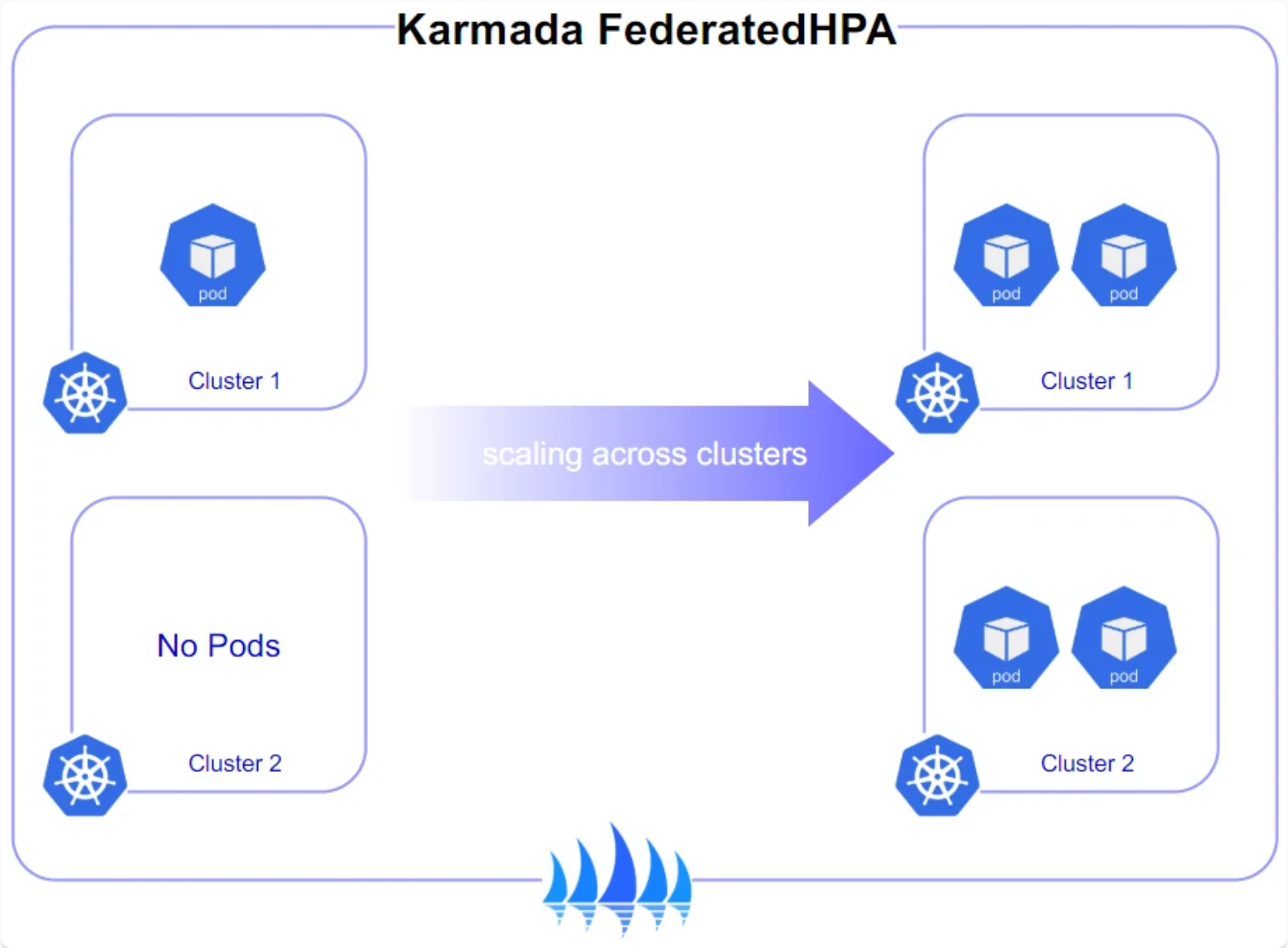
Kurator结合Karmada和HPA(Horizontal Pod Autoscaler)提供了强大的弹性伸缩能力。下面配置一个基于CPU使用率的自动伸缩策略:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
meta
name: nginx-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: nginx-deployment
minReplicas: 3
maxReplicas: 15
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
---
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
meta
name: hpa-propagation
spec:
resourceSelectors:
- apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
name: nginx-hpa
placement:
clusterAffinity:
clusterNames:
- cluster-1
- cluster-2
这个配置会根据CPU使用率自动调整副本数量,并在多个集群之间同步伸缩策略。Karmada会监控各个集群的资源使用情况,当某个集群资源不足时,会自动将负载迁移到其他集群,实现真正的跨集群弹性伸缩。
四、智能调度:Volcano在Kurator中的应用
4.1 Volcano架构剖析
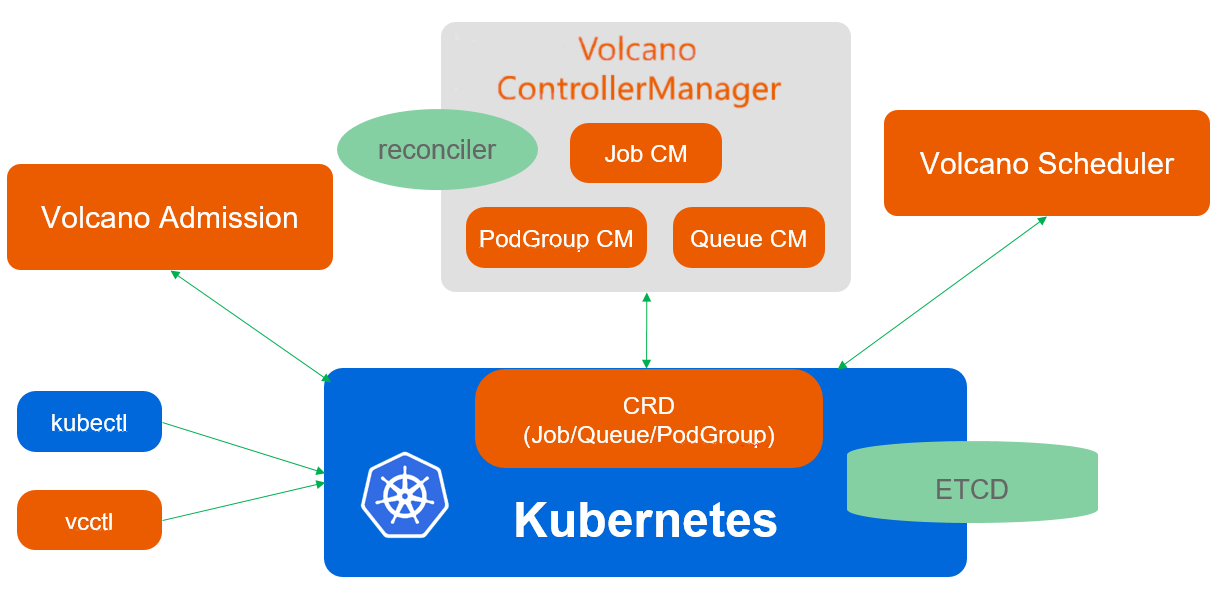
Volcano是Kurator集成的批处理作业调度器,专门为AI、大数据、HPC等计算密集型工作负载优化。与Kubernetes默认的调度器相比,Volcano提供了更丰富的调度策略,包括gang scheduling(全组调度)、priority scheduling(优先级调度)、queue management(队列管理)等。
Volcano的核心架构包括三个主要组件:Scheduler、Controller和Admission。Scheduler负责具体的调度决策,Controller管理Job和PodGroup的生命周期,Admission负责资源配额和策略校验。这种架构设计使得Volcano能够高效处理大规模批处理作业。
在Kurator中,Volcano与Karmada深度集成,实现了跨集群的批处理作业调度。当一个作业需要在多个集群上运行时,Kurator会根据各集群的资源状况、网络延迟、数据位置等因素,智能地分配作业到最优的集群上。
4.2 批量作业调度优化
下面通过一个实际例子来展示Volcano在Kurator中的应用。我们创建一个需要6个GPU的AI训练作业:
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
meta
name: ai-training-job
spec:
minAvailable: 6
schedulerName: volcano
tasks:
- replicas: 6
name: "worker"
template:
spec:
containers:
- image: tensorflow/tensorflow:2.5.0-gpu
name: tensorflow
resources:
limits:
nvidia.com/gpu: 1
command: ["python", "/app/train.py"]
restartPolicy: OnFailure
queue: "ai-queue"
这个作业使用了gang scheduling策略,要求6个worker必须同时调度成功,否则整个作业不会启动。这确保了作业的原子性,避免了部分资源被占用而导致资源浪费的问题。
在Kurator中,我们可以通过Queue来管理不同优先级的作业:
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
meta
name: ai-queue
spec:
weight: 10
capability:
cpu: "100"
memory: "500Gi"
nvidia.com/gpu: "50"
reclaimable: true
4.3 资源隔离与队列管理
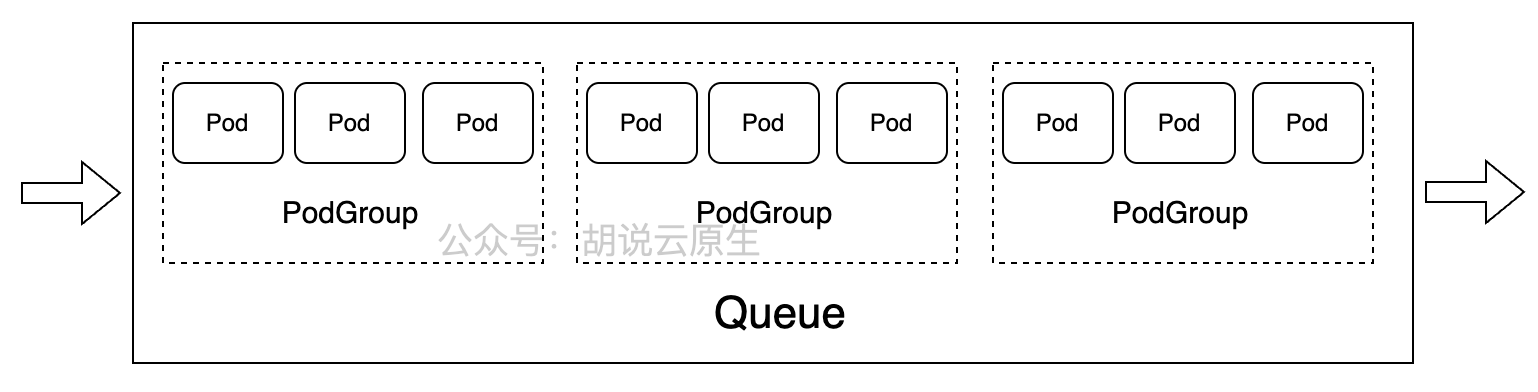
在多租户环境中,资源隔离和队列管理至关重要。Volcano提供了多种机制来实现资源隔离,包括Queue配额、PodGroup资源预留、优先级调度等。下面配置一个具有资源隔离的多租户环境:
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
metadata:
name: team-a-queue
spec:
weight: 5
capability:
cpu: "50"
memory: "200Gi"
---
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
metadata:
name: team-b-queue
spec:
weight: 3
capability:
cpu: "30"
memory: "150Gi"
通过PriorityClass可以为不同租户的作业设置不同的优先级:
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
meta
name: high-priority
value: 10000
globalDefault: false
description: "High priority jobs for critical workloads"
---
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
meta
name: critical-job
spec:
priorityClassName: high-priority
tasks:
- replicas: 1
template:
spec:
containers:
- name: critical-app
image: critical-app:latest
在Kurator中,这些配置会自动同步到所有成员集群,确保资源隔离策略在整个分布式环境中一致执行。
五、高级发布策略:金丝雀与蓝绿发布实践
5.1 金丝雀发布配置详解
金丝雀发布是一种渐进式的发布策略,通过逐步将流量切换到新版本,降低发布风险。Kurator集成了Istio作为服务网格,提供了强大的流量管理能力。下面配置一个金丝雀发布:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
meta
name: frontend
spec:
hosts:
- frontend
http:
- route:
- destination:
host: frontend
subset: v1
weight: 90
- destination:
host: frontend
subset: v2
weight: 10
---
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: frontend
spec:
host: frontend
subsets:
- name: v1
labels:
version: v1
- name: v2
labels:
version: v2
这个配置将90%的流量路由到v1版本,10%的流量路由到v2版本。通过监控v2版本的性能和错误率,可以逐步增加权重,直到完全切换到新版本。
在Kurator中,可以通过GitOps的方式管理这些配置,实现发布策略的版本控制和审计。当需要回滚时,只需将配置恢复到之前的版本即可。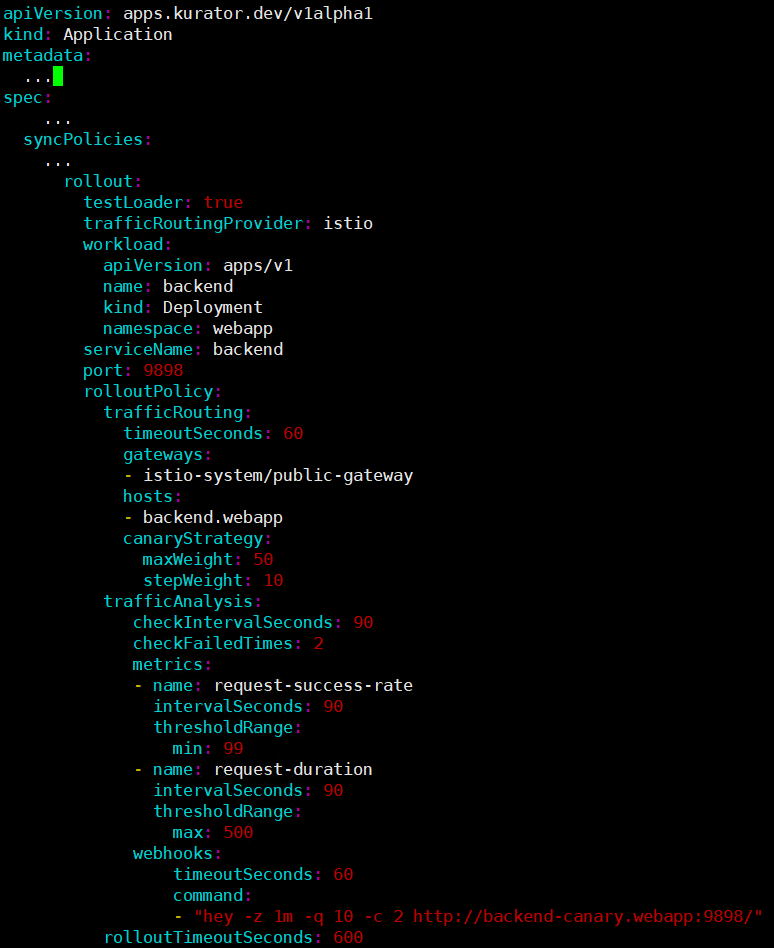
5.2 蓝绿发布实现原理
蓝绿发布通过维护两个完全相同的环境(蓝色和绿色),在发布时将流量从旧环境切换到新环境,实现零停机发布。Kurator通过Istio的流量切换能力,简化了蓝绿发布的实现。
首先,部署两个版本的服务:
apiVersion: apps/v1
kind: Deployment
meta
name: frontend-blue
spec:
replicas: 3
selector:
matchLabels:
app: frontend
version: blue
template:
meta
labels:
app: frontend
version: blue
spec:
containers:
- name: frontend
image: frontend:1.0
---
apiVersion: apps/v1
kind: Deployment
meta
name: frontend-green
spec:
replicas: 3
selector:
matchLabels:
app: frontend
version: green
template:
meta
labels:
app: frontend
version: green
spec:
containers:
- name: frontend
image: frontend:2.0
然后配置Istio的VirtualService来控制流量切换:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
meta
name: frontend
spec:
hosts:
- frontend
http:
- route:
- destination:
host: frontend
subset: blue
weight: 100
当需要切换到新版本时,只需更新VirtualService的权重配置:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
meta
name: frontend
spec:
hosts:
- frontend
http:
- route:
- destination:
host: frontend
subset: green
weight: 100
5.3 流量管理与监控集成
在高级发布策略中,监控和自动化决策至关重要。Kurator集成了Prometheus和Grafana,可以实时监控新版本的性能指标,并根据预设条件自动调整发布策略。
下面配置一个基于错误率的自动回滚策略:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
meta
name: frontend
spec:
hosts:
- frontend
http:
- route:
- destination:
host: frontend
subset: v1
weight: 90
- destination:
host: frontend
subset: v2
weight: 10
mirror:
- destination:
host: frontend
subset: v2
mirrorPercentage:
value: 100
这个配置将100%的流量镜像到v2版本,用于收集性能数据,但不影响实际用户流量。通过Prometheus监控v2版本的错误率,当错误率超过阈值时,触发自动回滚。
在Kurator中,可以通过自定义Operator来实现这种自动化逻辑,将监控数据与发布策略紧密结合,形成闭环控制系统。
六、GitOps与CI/CD:现代应用交付体系
6.1 GitOps工作流设计
GitOps是一种以Git仓库作为唯一真实源的持续交付方法。Kurator集成了FluxCD作为GitOps引擎,实现了声明式的应用交付。GitOps的核心思想是将所有配置存储在Git仓库中,通过自动化工具将配置应用到集群中,并保持集群状态与Git仓库的一致性。
Kurator的GitOps工作流包括以下几个步骤:开发人员提交代码到Git仓库,CI系统构建镜像并推送,更新Kubernetes清单文件,FluxCD检测到变更后自动同步到集群,最后通过监控系统验证部署结果。
这种工作流的优势在于:配置版本化,便于审计和回滚;自动化程度高,减少人为错误;状态一致性,确保集群状态与预期一致。
6.2 FluxCD与Helm集成
FluxCD支持多种配置格式,包括原生Kubernetes清单、Helm Charts、Kustomize等。在Kurator中,推荐使用Helm Charts来管理复杂应用,因为Helm提供了模板化、参数化和依赖管理能力。
下面配置一个HelmRelease来部署Nginx应用:
apiVersion: helm.toolkit.fluxcd.io/v2beta1
kind: HelmRelease
meta
name: nginx
namespace: default
spec:
chart:
spec:
chart: nginx
version: 9.5.2
sourceRef:
kind: HelmRepository
name: bitnami
namespace: flux-system
interval: 5m
install:
remediation:
retries: 3
upgrade:
remediation:
retries: 3
values:
service:
type: ClusterIP
replicaCount: 3
同时需要配置HelmRepository:
apiVersion: source.toolkit.fluxcd.io/v1beta1
kind: HelmRepository
meta
name: bitnami
namespace: flux-system
spec:
interval: 1h
url: https://charts.bitnami.com/bitnami
在Kurator中,这些配置会自动同步到所有成员集群,确保应用在多个集群中保持一致的状态。
6.3 持续交付流水线构建
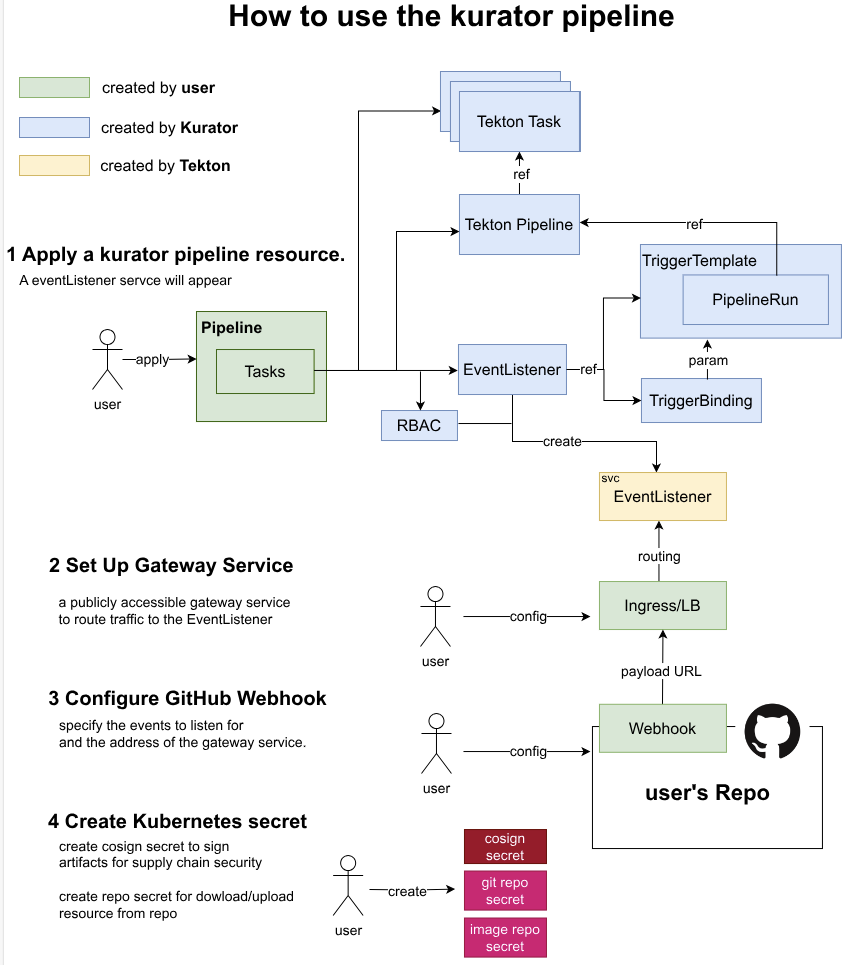
Kurator支持与Jenkins、Tekton等CI/CD工具集成,构建完整的持续交付流水线。下面是一个基于Tekton的流水线示例:
apiVersion: tekton.dev/v1beta1
kind: Pipeline
meta
name: app-pipeline
spec:
tasks:
- name: clone-repo
taskRef:
name: git-clone
params:
- name: url
value: https://github.com/example/app.git
- name: revision
value: $(params.git-revision)
- name: build-image
taskRef:
name: kaniko
params:
- name: IMAGE
value: $(params.image-repo):$(params.image-tag)
runAfter: [clone-repo]
- name: update-manifest
taskRef:
name: update-k8s-manifest
params:
- name: manifest-dir
value: k8s/manifests
- name: image
value: $(params.image-repo):$(params.image-tag)
runAfter: [build-image]
- name: deploy
taskRef:
name: flux-deploy
params:
- name: git-url
value: https://github.com/example/manifests.git
- name: git-branch
value: main
runAfter: [update-manifest]
这个流水线包含了代码克隆、镜像构建、清单更新和部署等步骤,通过Kurator的GitOps能力,实现了从代码提交到生产部署的自动化流程。
七、Kurator未来展望与技术趋势
7.1 技术演进路线
Kurator作为分布式云原生领域的前沿项目,其技术演进路线值得关注。从社区发展来看,Kurator正在向以下几个方向演进:
首先是智能化,通过引入AI和机器学习技术,实现更智能的资源调度和故障预测。例如,基于历史数据预测资源需求,自动调整集群规模;通过异常检测算法,提前发现潜在的系统故障。
其次是边缘计算的深度集成。随着5G和物联网的发展,边缘计算将成为重要的技术方向。Kurator正在加强与KubeEdge的集成,提供更好的边缘节点管理、数据同步和离线支持能力。
最后是安全性的增强。在分布式环境中,安全挑战更加复杂。Kurator正在引入零信任架构、服务网格安全策略、密钥管理等安全机制,确保整个系统的安全性。
7.2 社区生态建设
开源项目的成功离不开活跃的社区生态。Kurator社区正在快速发展,吸引了来自全球的开发者和企业用户。社区建设的重点包括:
文档和教程的完善,降低新用户的入门门槛;示例项目的丰富,展示Kurator在各种场景下的应用;开发者工具的改进,提升贡献体验;企业案例的分享,证明技术价值。
通过社区共建,Kurator正在形成一个完整的生态系统,包括核心组件、插件、工具、最佳实践等,为用户提供全方位的支持。
7.3 企业级应用建议
对于企业用户,采用Kurator需要考虑多个方面。首先是技术评估,需要根据业务需求评估Kurator是否适合当前的技术栈和业务场景。其次是团队能力建设,云原生技术栈较为复杂,需要培养具备相关技能的团队。
在实施策略上,建议采用渐进式的方式。可以从非核心业务开始试点,验证技术方案和团队能力;然后逐步扩展到核心业务,同时建立完善的监控、告警和应急响应机制。
最后,积极参与社区建设。通过贡献代码、文档、案例等方式,不仅可以获得技术支持,还可以影响技术发展方向,确保开源项目能够满足企业的需求。
结语
Kurator作为分布式云原生套件的代表,通过深度整合多个优秀开源项目,为企业提供了完整的云原生解决方案。从多集群管理到智能调度,从高级发布策略到GitOps实践,Kurator展现了云原生技术的强大能力。随着技术的不断发展,Kurator将在分布式云原生领域发挥更加重要的作用,推动企业数字化转型的深入发展。作为云原生从业者,我们应该持续关注Kurator的发展,积极参与社区建设,共同推动云原生技术的进步。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 17
17 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)