【前瞻创想】搞定多云集群管理头大?带你手搓Kurator云原生舰队,实战统一调度与存储架构
【前瞻创想】搞定多云集群管理头大?带你手搓Kurator云原生舰队,实战统一调度与存储架构
说实话,Kurator 这东西刚出来的时候,我也在想:这不就是又造了个轮子吗?但真深入进去用了你会发现,它不是这样的。你不用再自己去拼积木了,它给你提供了一套统一的分布式云原生底座。简单说,它就是你舰队的旗舰,帮你指挥下面所有的护卫舰(成员集群)。咱们今天的目标很明确,就是把 Kurator 的核心架构拆解开,顺便把环境搭起来,看看它是怎么做到统一管理应用、存储和流量的。
一、 把地基打牢:环境搭建与核心集群架构的那些事儿
咱们干技术的,光说不练假把式。要理解 Kurator,最好的办法就是把它跑起来。但在跑之前,咱们得先明白咱们在构建什么。
1. 撸起袖子开始干:环境搭建实操
要玩转 Kurator,首先你得把代码搞下来。这一步是万里长征的第一步,别嫌麻烦。咱们直接从官方仓库拉代码,这一步是必须的,因为很多脚本和示例配置都在里面。
打开你的终端,找个顺眼的目录,敲下这行命令:
git clone https://gitcode.com/kurator-dev/kurator.git
如果显示下面的问题
表示没用设置git代理,我们可以先设置git代理;先看一下电脑上的代理端口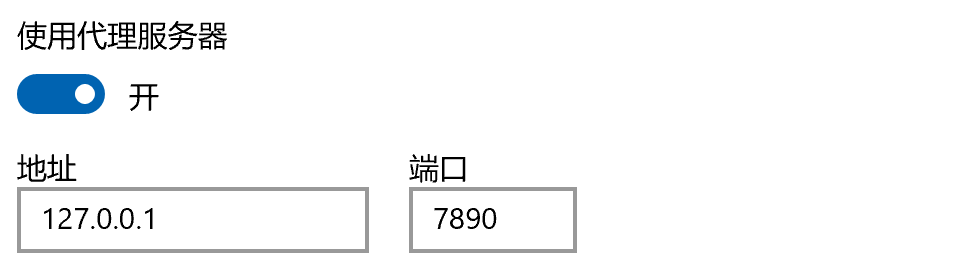
再设置git的代理端口,设置成本地代理
git config --global http.proxy http://127.0.0.1:7890
然后再拉取
git clone https://github.com/kurator-dev/kurator.git

就可以拉取资源了,当然也可以换源,你们可以试试
代码拉下来之后,你通常需要准备一个控制面集群(Host Cluster)。这个集群是 Kurator 的大脑。在实操中,我建议大家至少准备 2-3 个节点,因为后面还要装 Karmada 和 Istio 的控制面。环境准备好后,Kurator 提供了一键安装的脚本,但作为专家,我建议你自己去看一下 install.sh 里面的逻辑,它本质上是在帮你把 Cluster Operator 和相关的 CRD(自定义资源定义)给装进去。
2. Kubernetes 集群的标准架构是啥样的?
这是Kubernetes集群的标准架构参考图,展示了包含控制平面组件、工作节点及云平台集成的完整集群部署模型: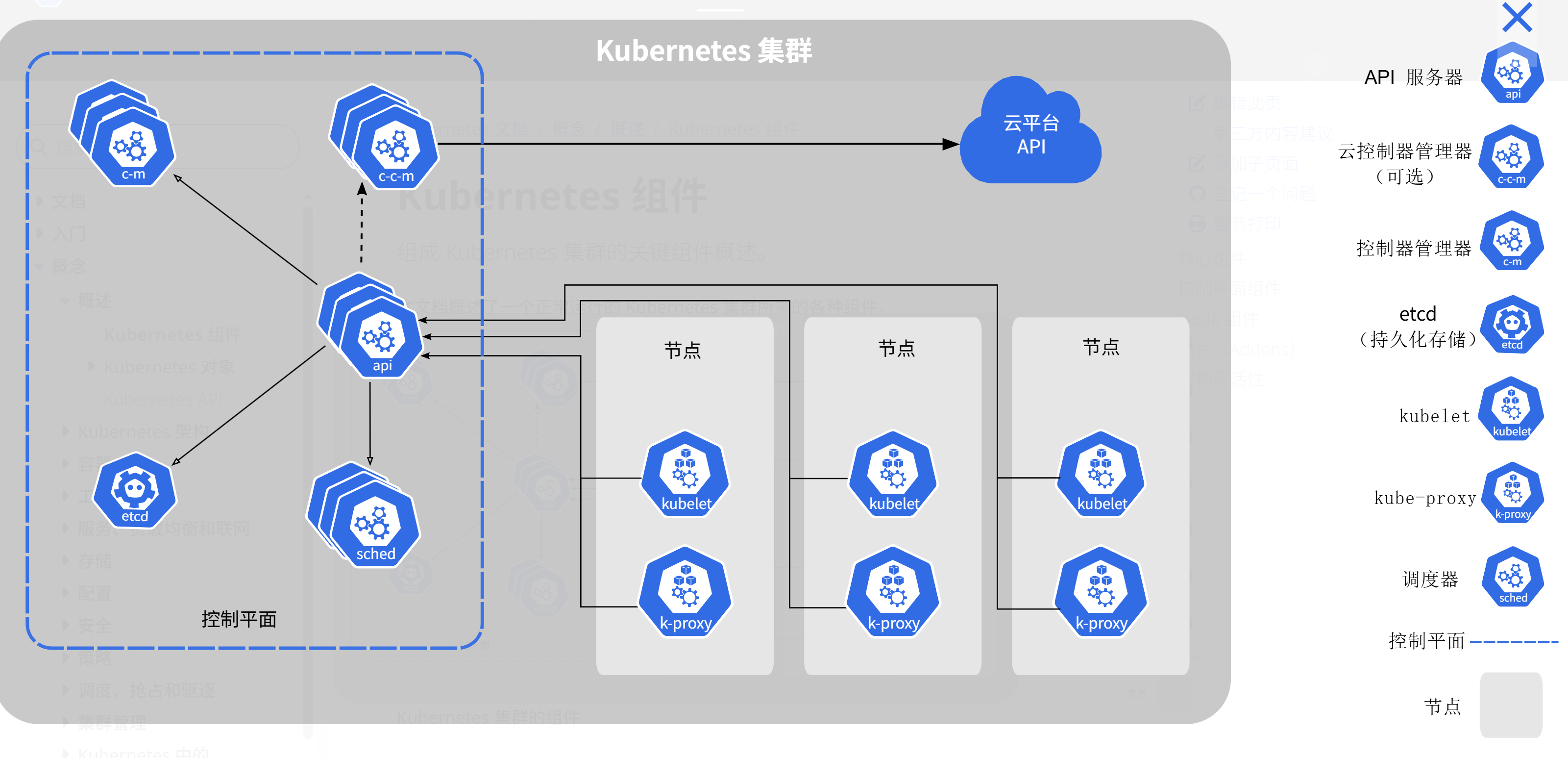
在 Kurator 的世界里,所有的集群——不管是管理集群还是工作集群,都遵循一套 Kubernetes 集群的标准架构。这听起来是废话,但其实很有讲究。
标准的 K8s 架构咱们都知道:Control Plane(控制面)和 Worker Node(工作节点)。但在 Kurator 的语境下,这个“标准”意味着一致性。无论你的集群是跑在 AWS 上,还是阿里云上,或者是自建机房的裸金属上,Kurator 都通过 Cluster API 这种声明式的方式,把它们抽象成了统一的资源对象。
这意味着,底层的差异被抹平了。你不用关心底层的 CNI 插件是 Calico 还是 Flannel(除非你非要定制),也不用管 CRI 是 Docker 还是 Containerd,Kurator 实际上是在推行一种“最佳实践的标准架构”。它要求每个集群必须具备核心的组件,比如 CoreDNS、Kube-proxy,以及用于向控制面上报状态的 Agent。这种标准化是后面搞“舰队管理”的前提,没有这个标准化,多云管理就是一盘散沙。
3. 揭秘 Cluster Operator 的实现逻辑
这张图展示了Cluster Operator的实现细节,其实就是用户通过声明一个CRD,触发API Server事件,然后由Operator监听并调度多个管理worker去自动对接和管理不同的本地集群,整个过程用无密码认证打通,既安全又高效: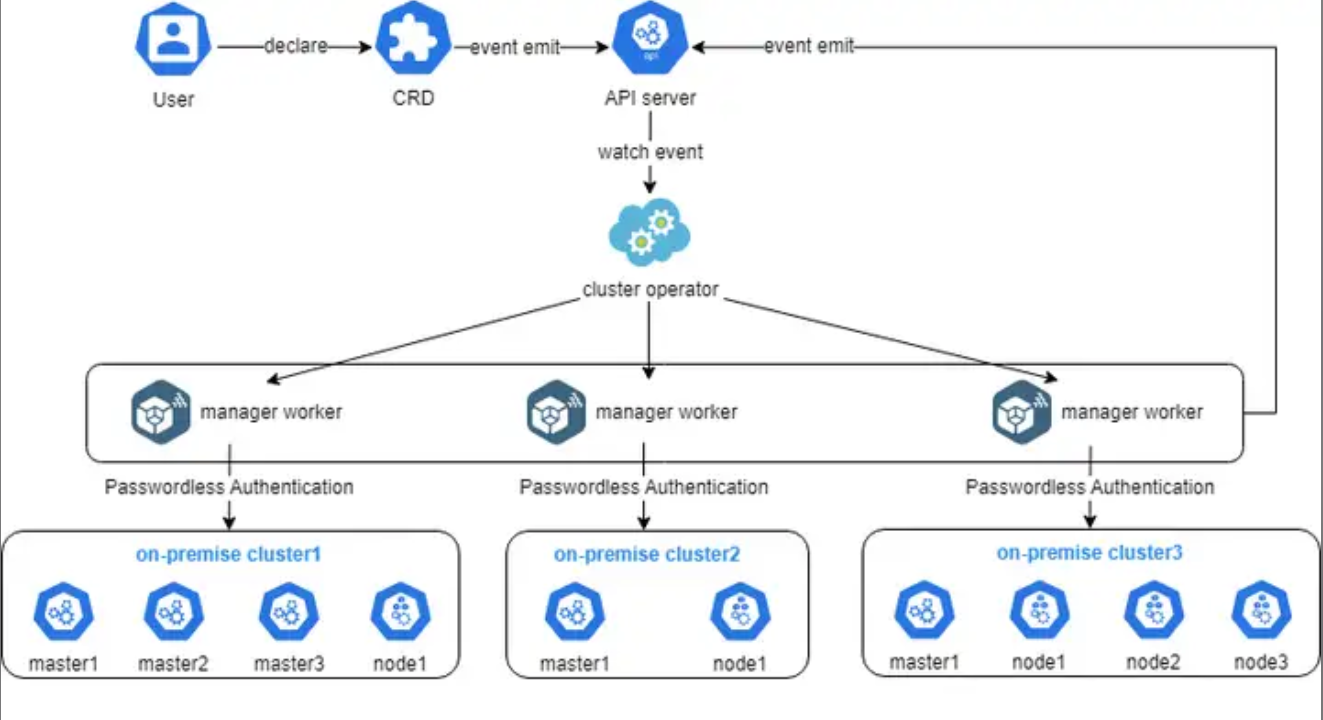
好,环境准备好了,标准也定了,那谁来干活呢?这就是 Cluster Operator 的戏份了。这是 Kurator 里面非常核心的一个组件,我自己手搓 Operator 的时候也参考过它的设计。
Cluster Operator 的实现逻辑非常“云原生”。它基于 Operator Pattern,一直在死循环里监听 KuratorCluster 这种自定义资源。当你告诉它:“嘿,我要在腾讯云上起一个 3 节点的集群”,你提交一个 YAML 文件,Cluster Operator 就会监测到这个变化。
它内部的 Reconcile(调和)循环会做这几件事:
- 解析配置:看你要啥规格的机器,啥版本的 K8s。
- 调用驱动:通过 Cluster API 的 Provider(比如 Capz, Capa 等)去调用底层云厂商的接口创建虚拟机。
- 引导集群:用 Kubeadm 或者其他工具把 K8s 组件拉起来。
- 状态同步:把新集群的 Kubeconfig 拿回来,注册到 Kurator 的控制面。
下面这段代码就是我模拟的一个 Cluster Operator 定义集群的逻辑,看着是不是很亲切?就像是你自己手写的一样:
# 这是一个模拟的手搓 KuratorCluster 配置
apiVersion: cluster.kurator.dev/v1alpha1
kind: KuratorCluster
metadata:
name: my-fleet-cluster-01
namespace: kurator-system
spec:
# 这里定义我们要用的云厂商驱动,比如 aws, azure, 或者 local (kind)
infrastructureProvider:
type: kind
# 定义控制面节点数量,生产环境建议3个起步
controlPlane:
replicas: 3
machineType: "t3.large" # 稍微给点资源,别太抠
# 定义工作节点
workers:
replicas: 5
machineType: "t3.medium"
# 这里是关键,我们要自动把这个集群注册到 Karmada
registerToKarmada: true
# 网络插件配置,统一标准
cni:
type: calico
version: "v3.25"
二、 舰队的大脑:Karmada 集成与统一应用分发
集群建好了,现在你手里有一堆散落在各地的 K8s 集群,这时候就需要一个“总指挥”了。在 Kurator 的架构里,这个总指挥就是 Karmada。
1. Kurator 平台的总体架构概览
在深入 Karmada 之前,咱们先拔高视角看看 Kurator 平台的总体架构。你可以把它想象成一个三明治结构。
- 最顶层是统一管理层:这里面有 Dashboard,有命令行工具,还有咱们刚才说的 GitOps 流水线入口。
- 中间层是核心控制平面:这是 Kurator 的心脏。它集成了 Karmada(负责多集群调度)、Istio(负责流量治理)、Prometheus(负责监控聚合)。这一层不跑具体的业务容器,只跑控制逻辑。
- 最底层是基础设施层:就是咱们前面通过 Cluster Operator 拉起来的那些 Fleet(舰队)集群。
这种架构的好处是解耦。业务集群挂了,控制面还在;控制面升级,不影响业务集群的运行。Kurator 在这里做了一个很棒的封装,把 Karmada 的复杂性给藏起来了,对外提供的是更简洁的接口。
2. Karmada 集成实践:多集群的胶水
这是Karmada集成实践的参考架构图,展示了其控制平面如何通过统一的策略API纳管多云、私有云及边缘异构集群: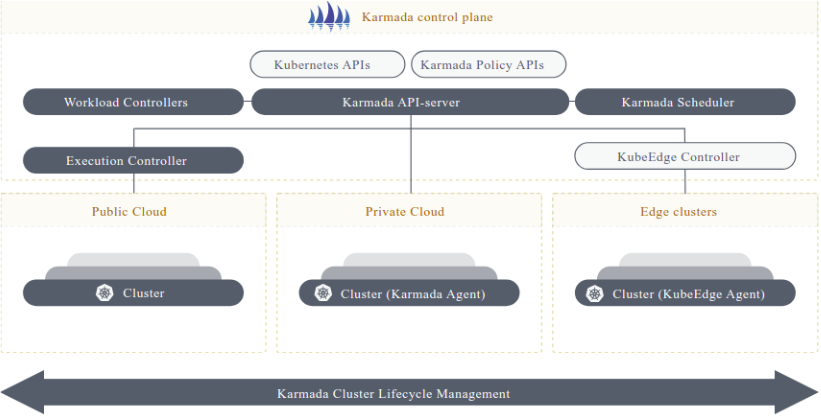
Karmada 集成实践是 Kurator 最精彩的部分之一。Karmada 本身很强大,但配置起来真的很繁琐。Kurator 把它集成进来后,做了一层简化。
在实操中,当你的 Cluster Operator 创建完集群后,Kurator 会自动生成一个 MemberCluster 对象,把这个新集群的凭证(Token)同步给 Karmada。这就完成了“纳管”。
一旦集成完成,你就不再需要分别去连接 Cluster A 和 Cluster B 了。你只需要连接 Kurator 的控制面(Karmada Host),提交 Deployment。Karmada 会根据你定义的策略(PropagationPolicy),自动计算该把这个 Pod 扔到哪个集群去。比如,你可以设置“所有带 gpu 标签的节点优先调度”,或者“在三个集群间按 1:1:1 比例分发副本”。
3. Kurator 统一应用分发的管理架构
这张图展示了Kurator统一应用分发的管理架构,实现跨多集群的一致化部署和管理,整个流程简单又可控: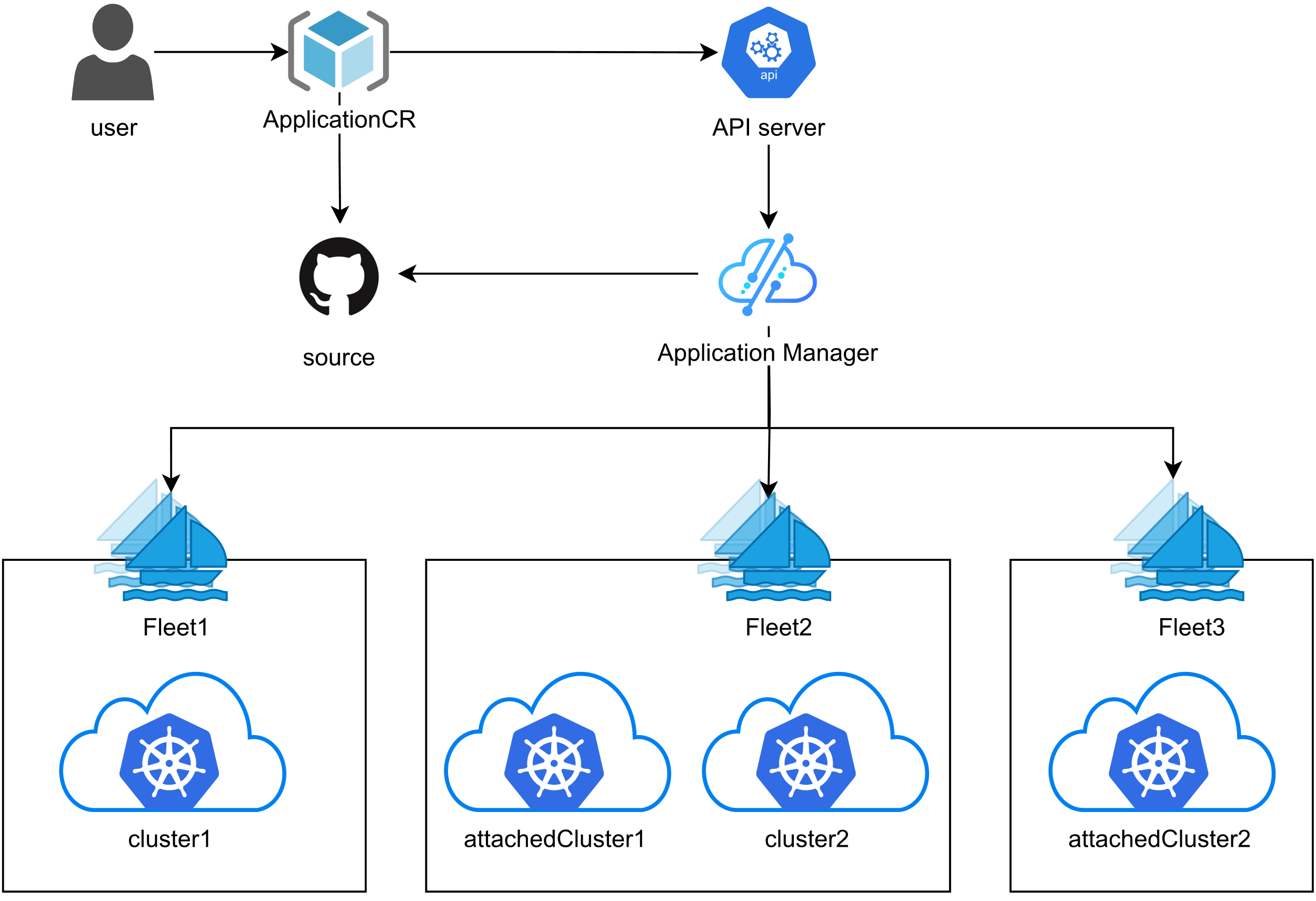
基于 Karmada,Kurator 构建了一套 统一应用分发的管理架构。这个架构的核心理念是“一次定义,到处运行”。
以前你分发应用,得给每个集群写 Helm Chart 的 values.yaml,甚至还得手动去改镜像地址。在 Kurator 里,你定义一个 Application 对象。这个对象里包含了:
- Workload 描述:就是你的 Deployment、Service。
- 分发策略(Override Policy):比如在北美集群用北美镜像仓库,在亚洲集群用亚洲镜像仓库。
- 调度策略:应用该去哪。
Kurator 的控制器会监控这个 Application 对象,然后翻译成 Karmada 能听懂的指令。这不仅减少了重复劳动,更重要的是防止了配置漂移(Config Drift)。所有集群的应用版本都被强一致地管理起来了。
4. GitOps 工作流:告别 kubectl apply
这是GitOps工作流的官方参考图,展示了从代码提交到镜像构建,最终由GitOps控制器实现集群自动部署的完整流程: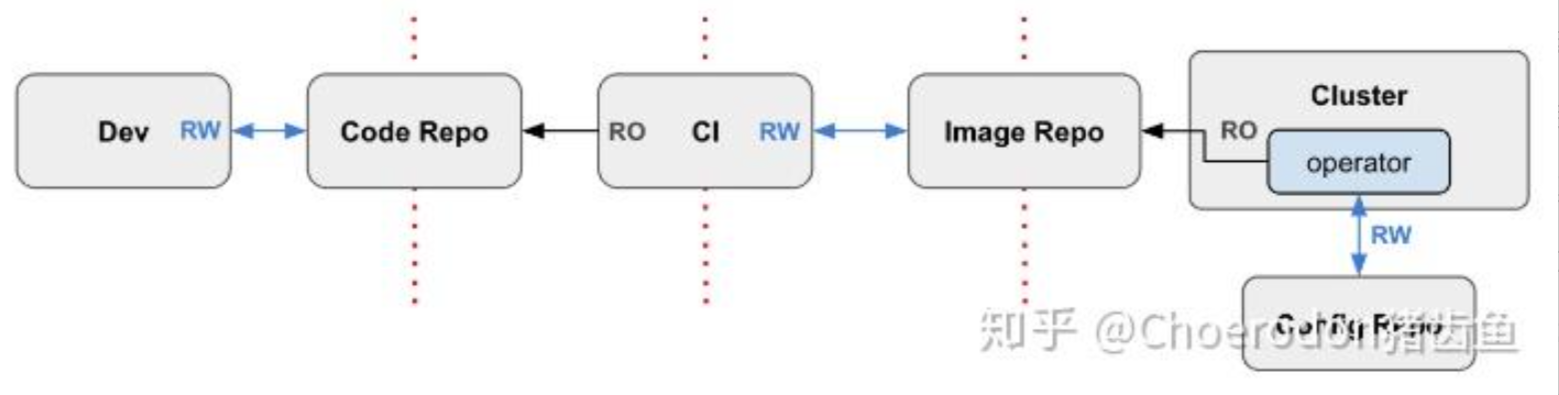
有了统一分发,咱们怎么触发分发呢?千万别告诉我你还在用命令行手动敲。在 Kurator 的设计里,GitOps 工作流才是正道。
Kurator 通常会集成 ArgoCD 或者 Flux。在这个工作流里,Git 仓库是唯一的真理来源(Source of Truth)。
- 开发人员把代码推送到 GitLab/GitHub。
- CI 流水线构建镜像,并更新 Manifest 仓库里的 YAML 文件(比如修改镜像 Tag)。
- Kurator 里的 GitOps 组件(比如 ArgoCD Application Controller)监测到 Git 变动。
- GitOps 组件通知 Karmada:“嘿,老板,配置变了”。
- Karmada 根据策略,把新的配置同步到下属的 Fleet 集群中。
这一套流程走下来,全自动、可审计、可回滚。这才是云原生该有的样子。
三、 数据的安身立所:统一分布式存储架构
应用跑起来了,数据往哪存?这是多云环境最大的痛点。Kurator 引入了 Rook 来解决这个问题。
1. Fleet 基于 Rook 构建统一分布式存储的架构
在单集群里,我们用 EBS 或者本地盘。但在多集群舰队(Fleet)里,我们需要一种跨集群、标准化的存储。Fleet 基于 Rook 构建统一分布式存储的架构 就在这里发挥作用了。
Rook 是一个云原生的存储编排器,它把 Ceph 这种复杂的存储系统变成了 K8s 的原生资源。在 Kurator 中,每个 Fleet 成员集群都可以安装 Rook Operator。Kurator 允许你在控制面统一下发 Rook 的配置。
这就像是给每个集群都发了一套标准的“硬盘管理说明书”。不管底层是 AWS 的 EBS 还是物理机的 SSD,Rook 都能把它们池化,向上提供统一的 PVC(Persistent Volume Claim)接口。
2. Kurator 的统一分布式存储架构
这张图展示了Kurator的统一分布式存储架构,用户通过定义一个配置就能够在多个集群里自动部署和管理Rook存储: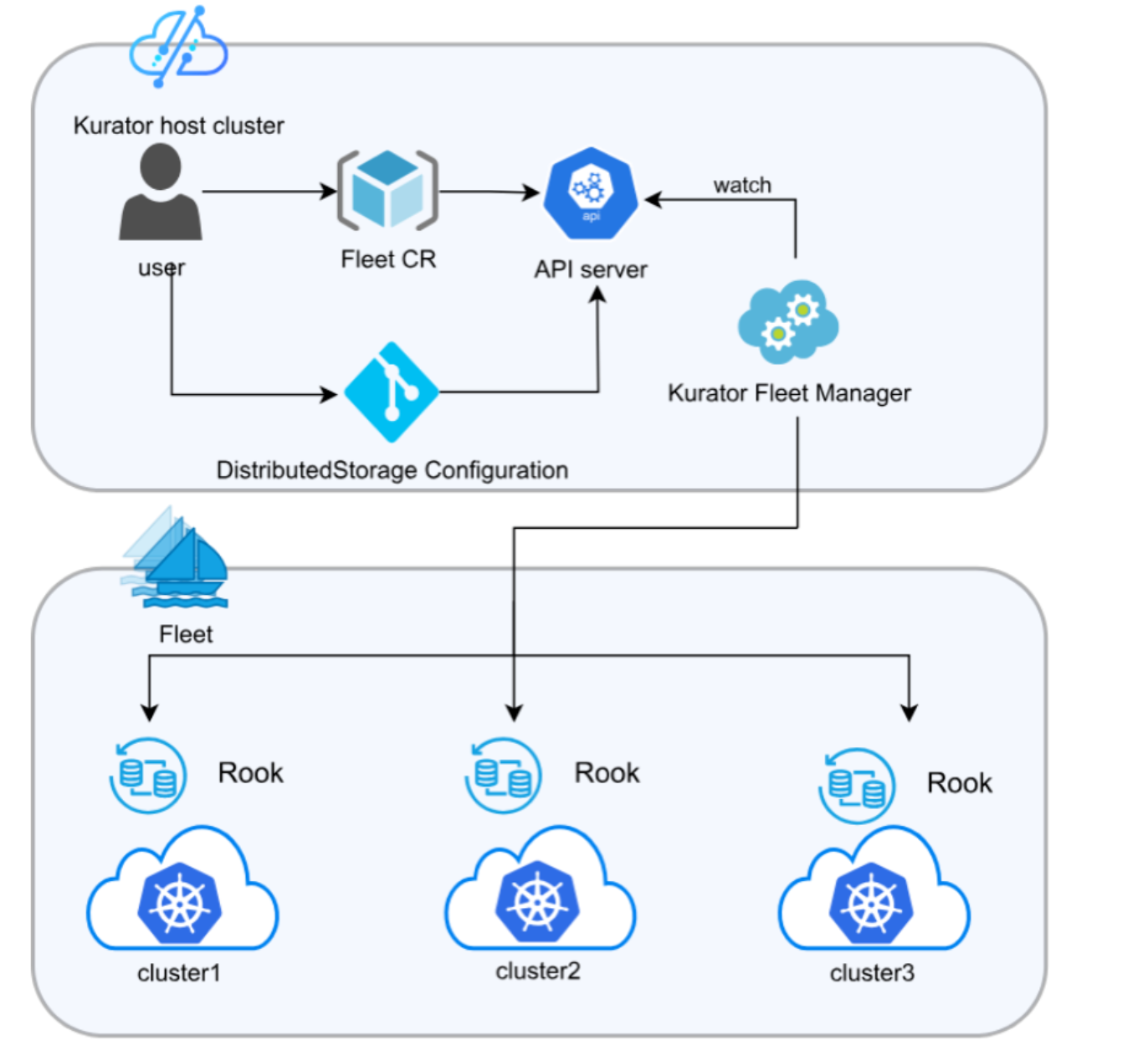
再往上一层,Kurator 的统一分布式存储架构 不仅仅是在单集群里装个 Rook 那么简单。它试图解决的是数据孤岛问题。
通过 Kurator 的协调,你可以在多个集群之间建立数据同步链路(基于 Ceph 的 RBD Mirroring 或者 Object Bucket Replication)。这意味着,如果 Cluster A 挂了,Cluster B 里不仅有应用的代码,还有最新的数据副本,可以直接把业务接管过来。这对于容灾来说是无价之宝。
Kurator 在这里做的工作主要是简化配置。它提供了一套抽象层,让你定义“这是一个跨地域的高可用存储池”,然后它自动去底层配置 Rook 和 Ceph 的参数,把你从复杂的 Ceph 配置文件中解放出来。
四、 流量与治理:Istio、服务一致性与 AB 测试
最后,咱们来聊聊最复杂的网络部分。应用分发了,存储有了,服务之间怎么通信?流量怎么切分?
1. 云原生舰队管理中的网络挑战
云原生舰队管理 不仅仅是管资源,更重要的是管连接。当你有 10 个集群时,最大的噩梦是网络打通。Kurator 利用 Istio 的多集群模型解决了这个问题。
2. Fleet 队列中服务相同性(Service Sameness)
这是Fleet队列中服务相同性参考图,展示了其如何在不同集群间跨命名空间智能识别并分发关联服务: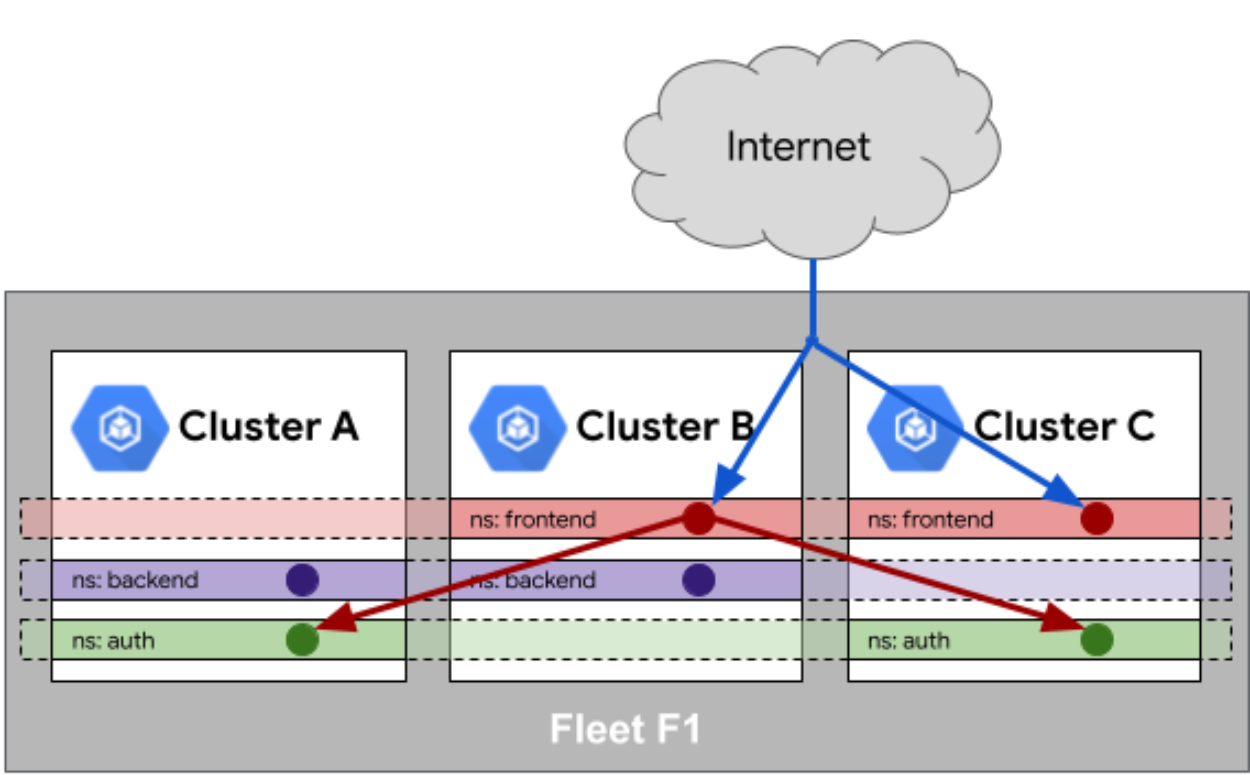
这是一个很酷的概念:Fleet 队列中服务相同性。简单解释就是,我在集群 A 里的 my-service 和集群 B 里的 my-service,在逻辑上应该是同一个服务。
Kurator 利用 Kubernetes 的 Multi-Cluster Service (MCS) API 和 Istio 的 ServiceEntry 来实现这一点。当你声明了服务相同性后,Kurator 会自动在所有集群的 DNS 里注入记录。集群 A 里的 Pod 访问 my-service.global 时,流量可以自动被路由到集群 B,而且对应用层是完全透明的。这让跨集群的微服务调用变得像调用本地服务一样简单。
3. Istio 服务网格的完整架构
Kurator 部署的是 Istio 服务网格的完整架构。通常采用的是 “Primary-Remote” 模式或者是 “Multi-Primary” 模式。
- 控制面:可能集中在管理集群,也可能每个业务集群都有。Kurator 推荐每个集群都有控制面以保证高可用。
- 数据面(Envoy Sidecar):跑在每个 Pod 旁边。
- Ingress/Egress Gateway:负责跨集群的流量进出。
Kurator 会自动帮你把证书互信(Certs Trust)搞定。这是最坑的一步,如果证书没配对,跨集群通信根本通不了。Kurator 自动签发中间 CA 证书给每个集群,确保证书链的一致性。
4. Kurator 中配置 A/B 测试
既然有了 Istio,搞 A/B 测试 就是水到渠成的事了。在 Kurator 中配置 AB 测试,本质上是在操作 Istio 的 VirtualService 和 DestinationRule。
假设我们要上一个新版本的支付服务,只让 5% 的流量走新版本,且必须是带特定 Header 的测试用户。在 Kurator 里,你不需要手写复杂的 Envoy 过滤器,它可能会提供更上层的 DSL,但底层生成的配置大概是这样的:
# 这是一个典型的 AB 测试流量切分配置
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: payment-service-route
namespace: payment-prod
spec:
hosts:
- payment.prod.svc.cluster.local
http:
- match:
- headers:
x-user-group:
exact: "internal-testers" # 只有内部测试用户才走这个逻辑
route:
- destination:
host: payment.prod.svc.cluster.local
subset: v2-beta # 新版本
- route:
- destination:
host: payment.prod.svc.cluster.local
subset: v1-stable # 普通用户走老版本
weight: 95
- destination:
host: payment.prod.svc.cluster.local
subset: v2-beta
weight: 5
5. 总结一下
你看,把这些点串起来,Kurator 的全貌就清晰了:
- Cluster Operator 负责生孩子(建集群)。
- Karmada 负责教孩子干活(分发应用)。
- Rook 负责给孩子存东西(分布式存储)。
- Istio 负责让孩子们互相打电话(服务网格与流量治理)。
最后,咱们再看一个简单的 GitOps 策略配置,用来展示如何通过 Kurator 把存储配置下发下去,这算是一个综合性的实操代码:
# 这个配置展示了如何通过 Kurator (Karmada层) 下发存储配置
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: distribute-rook-storage-class
namespace: kurator-system
spec:
resourceSelectors:
- apiVersion: storage.k8s.io/v1
kind: StorageClass
name: rook-ceph-block # 我们要分发的资源
placement:
clusterAffinity:
clusterNames:
- member-cluster-1
- member-cluster-2
# 可以在这里定义分发策略,比如只分发给带有 ssd 标签的集群
clusterTolerations:
- key: "storage-type"
operator: "Equal"
value: "fast"
好了,希望这篇文章能帮你把 Kurator 的脉络摸清楚。这玩意儿上手确实有点门槛,但一旦搭好了,那种“运筹帷幄之中,决胜千里之外”的感觉,绝对是每个云原生工程师的终极追求。赶紧动手 git clone 搞起来吧!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)