【前瞻创想】Kurator·云原生实战派:构建下一代分布式云原生统一平面的深度探索与实践
【前瞻创想】Kurator·云原生实战派:构建下一代分布式云原生统一平面的深度探索与实践
【前瞻创想】Kurator·云原生实战派:构建下一代分布式云原生统一平面的深度探索与实践
摘要
在云原生技术多集群、分布式部署成为主流范式的今天,管理复杂度呈指数级增长。Kurator,作为一个开源的分布式云原生套件,应运而生。它并非重复造轮子,而是以“连接器”和“增强器”的定位,将 Karmada、KubeEdge、Istio、Volcano、FluxCD 等顶尖开源项目无缝集成,构建了一个统一的分布式云原生平台。本文将从实战角度出发,深度解读 Kurator 的设计哲学与核心架构,并通过一个从零开始的完整实践案例,演示如何利用 Kurator 的 Fleet(舰队)概念统一纳管异构集群、利用 Volcano 实现跨集群的先进调度、借助 Istio 打造统一的服务网格,最终通过 GitOps 实现应用在多云多集群间的自动化交付。文章不仅展示操作步骤,更将深入分析其背后的工作原理、优势与适用场景,并对 Kurator 及分布式云原生的未来发展方向提出专业思考。
一、Kurator 前瞻解读:生于开源,高于集成
Kurator开源项目如图所示:
1.1 核心理念:统一平面的价值主张
Kurator 的诞生直击当前云原生生态的痛点:碎片化。一个典型的生产环境可能包含中心 K8s 集群、边缘 KubeEdge 节点池、不同公有云上的托管集群,甚至混合了虚拟机和裸机。管理者需要分别处理集群生命周期、应用分发、服务治理、监控日志等,工具链割裂,运维成本高昂。
Kurator 提出了“统一舰队(Unified Fleet)”的顶层设计。它将地理位置分散、架构各异的 Kubernetes 集群抽象为一个逻辑上的“舰队”进行统一管理。在这个平面下,你无需关心应用具体运行在哪个集群的哪个节点,而是声明期望的状态(如“部署 5 个副本,其中 3 个在边缘,2 个在中心,并保证跨地域高可用”),由 Kurator 及其集成的组件协同完成资源的调度、分发与治理。
1.2 集成创新:顶尖项目的“粘合剂”

Kurator 的核心竞争力在于其优秀的集成能力:
- 多云/多集群编排层:以 Karmada 为基石,提供强大的多集群工作负载编排与故障转移能力。Kurator 进一步简化了其配置,并通过自定义资源定义(CRD)提供了更上层的抽象。
- 边缘计算层:无缝集成 KubeEdge,将云原生能力延伸至网络不稳定、资源受限的边缘环境,实现了边缘节点的自治与云边协同。
- 智能调度层:集成 Volcano,为批量计算、AI训练等任务提供基于队列、优先级、公平共享等高级调度策略,并扩展至跨集群场景。
- 服务网格层:集成 Istio,为整个舰队提供统一的服务发现、流量治理、安全策略和可观测性,屏蔽底层集群边界。
- GitOps 持续交付层:原生支持 FluxCD,以 Git 作为单一可信源,自动化实现应用在庞大舰队中的安全、可追溯的部署与升级。
Kurator 的创新在于,它通过一套统一的 API 和 CLI 工具,将这些组件有机组合,让“1+1>2”,解决了用户在自行集成时面临的版本兼容、网络连通、配置同步等巨大挑战。
二、实战起航:构建你的第一个 Kurator 舰队
2.1 环境搭建与 Kurator 安装
实践是检验真理的唯一标准。让我们从零开始,搭建一个包含一个中心集群和一个模拟边缘集群的 Kurator 舰队。
首先,准备两个 Kubernetes 集群(可以使用 Kind 快速创建)。在作为管理集群的节点上,执行以下命令安装 Kurator CLI 及核心组件:
git clone https://github.com/kurator-dev/kurator.git
clone资源
如果显示下面的问题
表示没用设置git代理,我们可以先设置git代理;先看一下电脑上的代理端口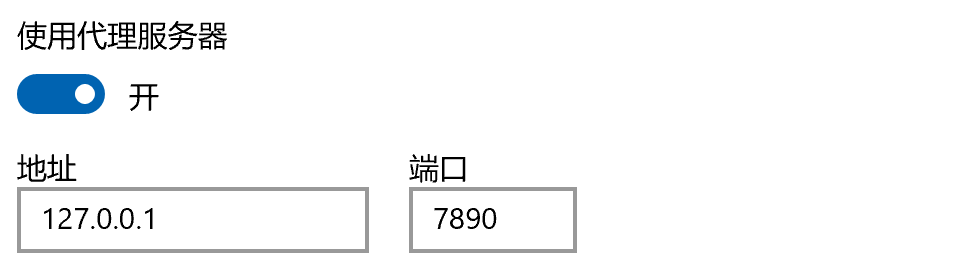
再设置git的代理端口,设置成本地代理,也可以设置一下git的源,换成其他的即可
git config --global http.proxy http://127.0.0.1:7890
安装脚本会部署 Kurator 的 Operator、自定义资源控制器等。验证安装:
kubectl get pods -n kurator-system
应看到所有 Pod 均处于 Running 状态。
2.2 集群生命周期管理:纳管异构成员
Kurator 通过 Cluster 和 AttachedCluster 等 CRD 来管理舰队成员。我们将中心集群作为“主集群”(Host Cluster),并将另一个集群作为“附属集群”加入舰队。
创建 AttachedCluster 资源描述文件 edge-cluster.yaml:
apiVersion: cluster.kurator.dev/v1alpha1
kind: AttachedCluster
metadata:
name: edge-cluster-01
namespace: default
spec:
kubeconfig:
secretRef:
name: edge-cluster-kubeconfig-secret # 预先创建,包含目标集群的 kubeconfig
plugins:
- type: karmada
- type: volcano
应用该配置后,Kurator 将自动在目标集群中安装必要的组件(如 Karmada Agent),并将其注册到舰队中。这个过程充分体现了 Kurator 在集群资源拓扑结构构建上的自动化能力,用户只需关心“加入”的意图,无需手动部署复杂的连接组件。
集群资源拓扑结构如图所示: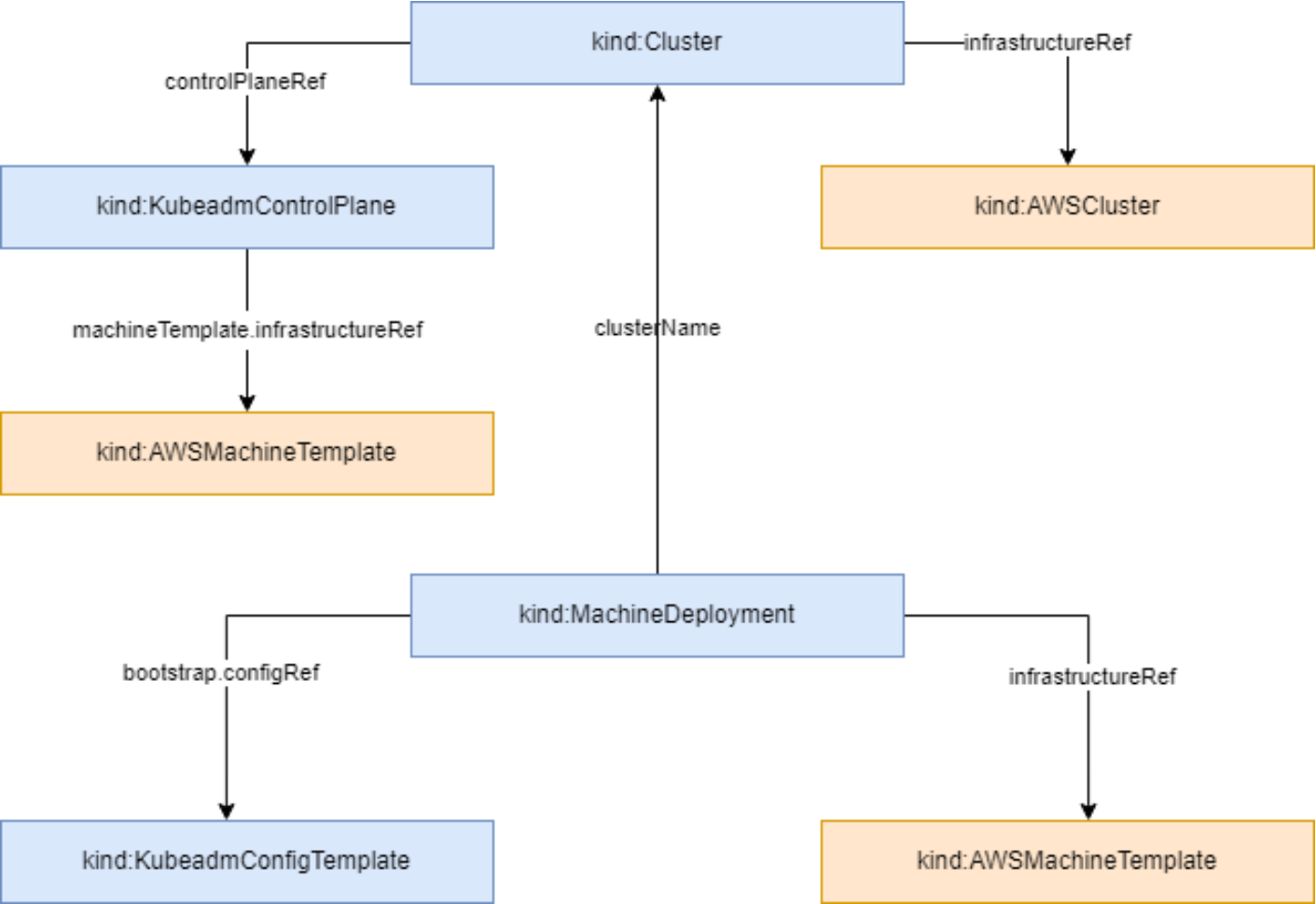
三、舰队核心:Fleet 抽象与多集群应用分发
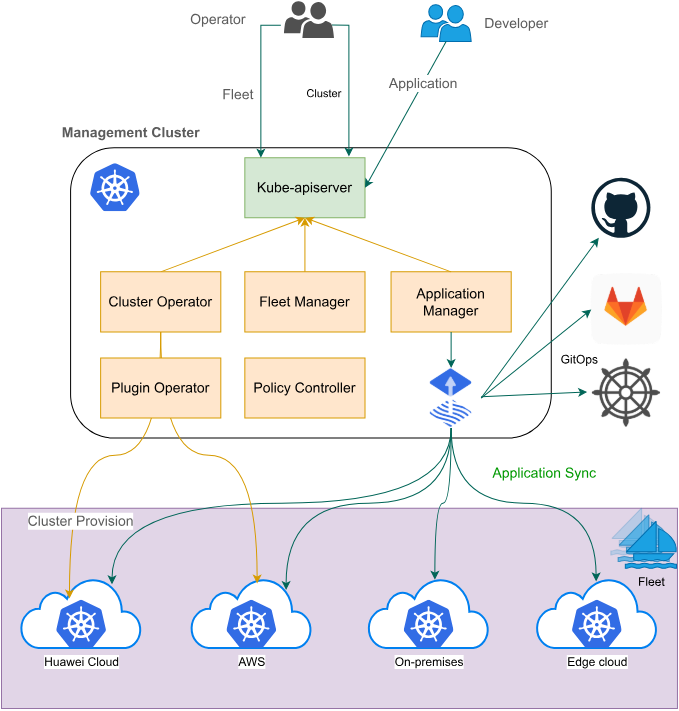
3.1 Fleet 模型:命名空间与身份的联邦
Fleet 是 Kurator 中最核心的抽象。一个 Fleet 定义了一组集群,并在这些集群上建立了一系列共享策略和身份。
Fleet 舰队中的命名空间相同性是第一个关键特性。当你在 Fleet 级别创建一个命名空间时,Kurator 会确保该命名空间在所有成员集群中被同步创建。这为跨集群应用部署提供了统一的资源边界。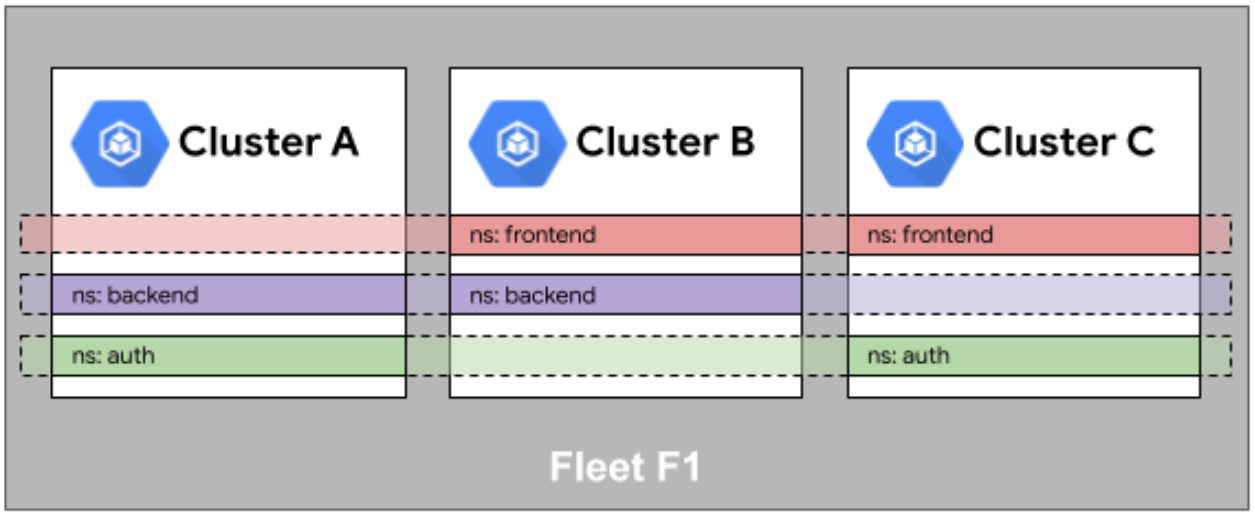
Fleet 队列中的身份相同性则更为强大。它通过集成 Karmada 的“ServiceAccount 传播”等机制,确保在 Fleet 中定义的 ServiceAccount 及其绑定的 RBAC 权限在所有集群中一致。这使得应用 Pod 无论调度到哪个集群,都能以相同的身份访问 API Server 或其它服务,极大简化了跨集群的安全策略管理。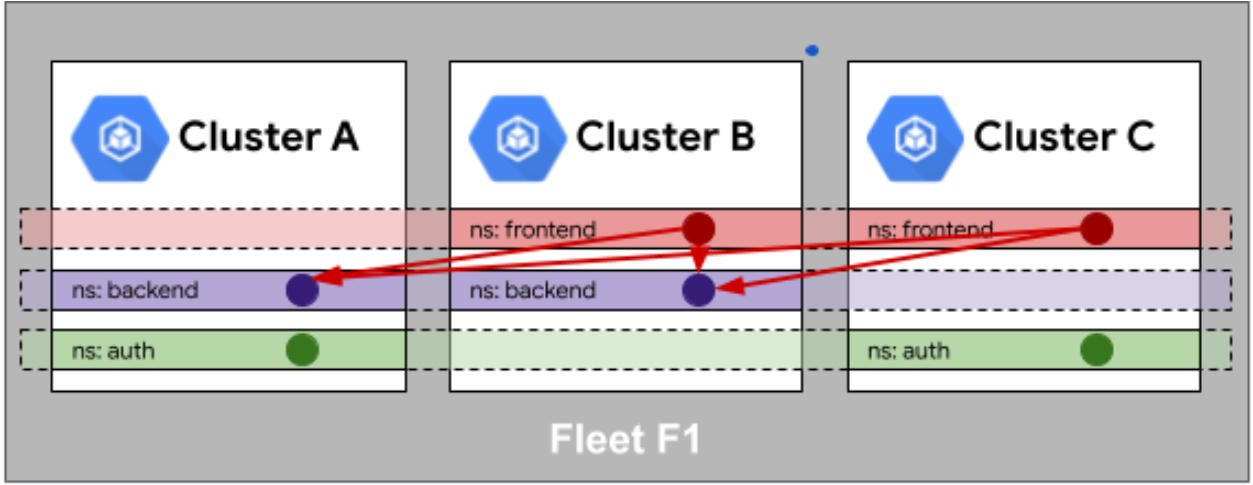
3.2 跨集群应用部署实践
下面,我们在名为 global-fleet 的舰队中,部署一个简单的 Nginx 应用,并利用 Karmada 的传播策略将其分发到中心集群和边缘集群。
首先,创建 Fleet:
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
metadata:
name: global-fleet
spec:
clusters:
- name: host-cluster # 管理集群自身
- name: edge-cluster-01
template:
namespace: global-apps
接着,定义一个 FleetApplication(Kurator 对应用的高级抽象):
apiVersion: application.kurator.dev/v1alpha1
kind: FleetApplication
metadata:
name: nginx-global
namespace: global-apps
spec:
fleet: global-fleet
workloadTemplate:
deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 2
selector: ...
template: ...
placement:
clusterAffinity:
clusterNames:
- host-cluster
- edge-cluster-01
spreadConstraints:
- maxGroups: 1
minGroups: 1
spreadByField: cluster
应用此配置后,Kurator 会调用底层的 Karmada,将 Deployment 转化为 PropagationPolicy 和 Work,并最终在指定的两个集群中各创建一个 Nginx Pod。通过 kubectl get kubectl get work -n kurator-system 可以观察到分发任务的状态。这个过程清晰展示了 Kurator 分发流程:将用户友好的高级 API,翻译成底层多集群编排引擎的执行指令。
四、调度增强:集成 Volcano 实现批量任务跨集群调度
4.1 Volcano 架构与 Kurator 的集成
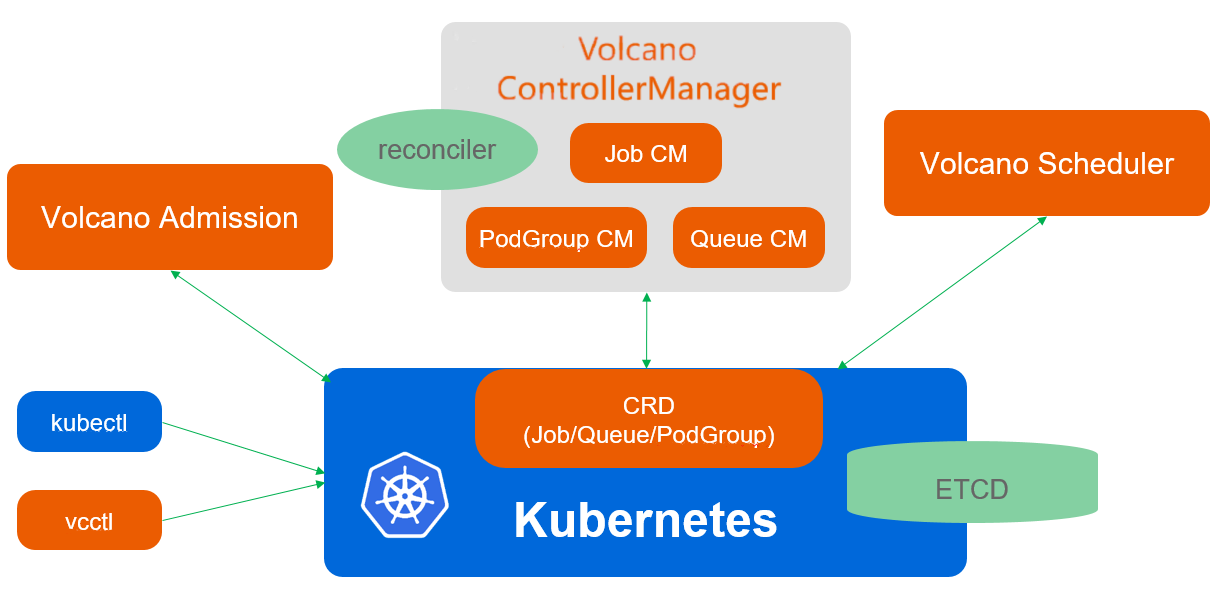
原生 Kubernetes 调度器主要针对长时运行服务,对 AI/ML、大数据处理等批量作业支持不足。Volcano 通过引入 PodGroup、Queue、Job 等概念,提供了作业级调度、公平共享、优先级抢占等高级特性。
VolcanoJob和Queue、PodGroup 如图所示: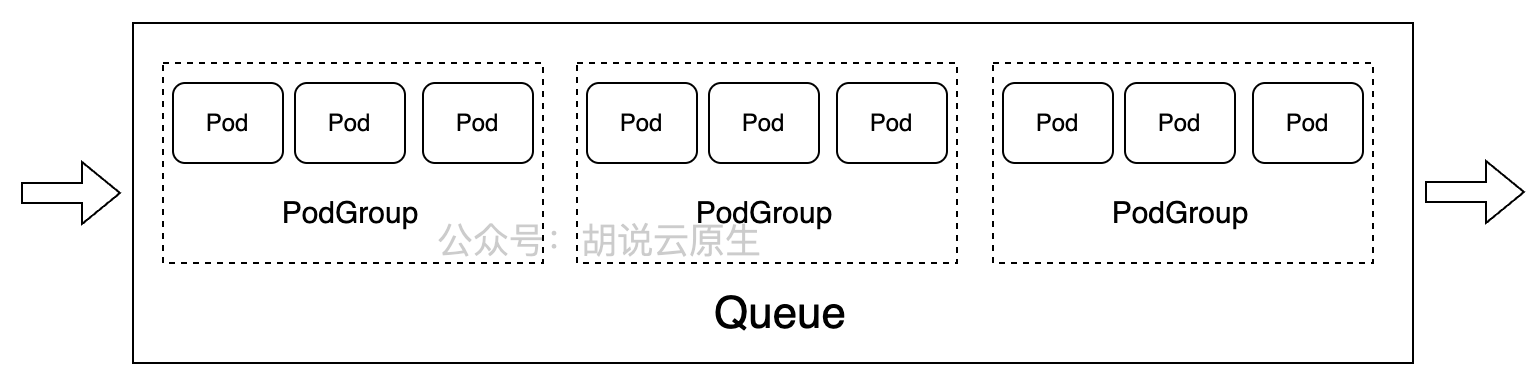
Kurator 将 Volcano 的调度能力从单集群扩展到了整个舰队。它允许你定义一个 FleetQueue,该队列下的所有 VolcanoJob 可以共享跨集群的配额和优先级。调度器会综合考虑各集群的资源利用率、作业优先级、数据 locality(如果集成了)等因素,做出最优的跨集群调度决策。
4.2 跨集群 AI 训练任务实战
假设我们有一个分布式 TensorFlow 训练任务(一个 Chief Worker 和多个 PS Worker),需要大量计算资源。我们通过 Kurator 将其提交到舰队队列中。
首先,创建一个 FleetQueue:
apiVersion: scheduling.kurator.dev/v1alpha1
kind: FleetQueue
metadata:
name: ai-training-queue
spec:
fleet: global-fleet
weight: 1.0 # 队列权重
reclaimable: true
然后,提交一个 VolcanoJob(Kurator 已为其提供 Fleet 级别的 CRD):
apiVersion: batch.kurator.dev/v1alpha1
kind: FleetVolcanoJob
metadata:
name: distributed-tf-job
spec:
fleet: global-fleet
queue: ai-training-queue
minMember: 4 # 最少需要4个Pod同时调度成功,作业才会开始
jobTemplate:
spec:
tasks:
- name: chief
replicas: 1
template: ... # Chief Pod 模板
- name: ps
replicas: 3
template: ... # PS Pod 模板
policies:
- event: PodEvicted
action: RestartJob
当这个 Job 被创建时,Kurator 与 Volcano 的协同调度器开始工作。它会将 PodGroup 的概念作用于整个舰队,确保只有在足够的资源(可能分布在多个集群)被同时预留时,作业的 Pod 才会被批量创建。这有效避免了因资源碎片化导致的大作业“饿死”问题,实现了跨集群的弹性伸缩和资源高效利用。
五、服务治理:基于 Istio 的统一服务网格
Istio服务网格如图所示: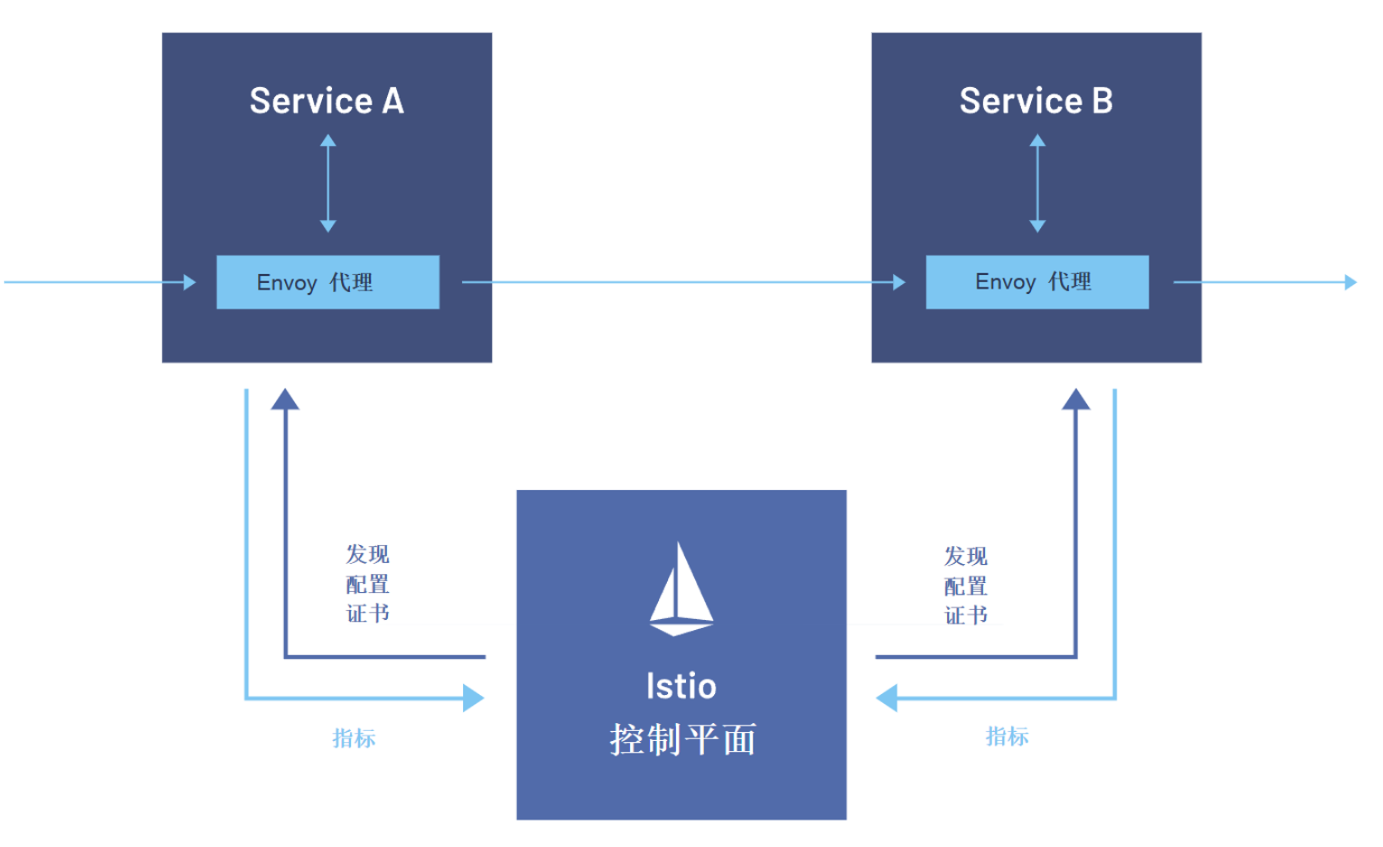
5.1 跨集群服务网格的挑战与方案
在多个集群间打通服务网格是另一个难题。传统的做法是在每个集群独立安装 Istio,然后通过东西向网关(East-West Gateway)手动配置复杂的服务发现和流量路由。
Kurator 通过 FleetMesh CRD 自动化了这一过程。它会在 Fleet 的每个成员集群中安装和配置 Istio,并自动建立集群间的双向 TLS 隧道,将分散的多个 Istio 控制平面逻辑上连接成一个“超级网格”。
5.2 实现跨集群金丝雀发布
借助 FleetMesh,我们可以轻松实现跨集群的金丝雀发布。假设我们的 nginx 服务 v1 版本运行在两个集群,现在要将 v2 版本先发布到边缘集群进行灰度测试。
- 配置 FleetMesh:Kurator 自动完成网格搭建。
- 定义目的地规则和虚拟服务:在 Fleet 级别(或主集群)创建 Istio 资源配置,利用 Istio 的
subset和DestinationRule,将流量按比例或按特定头信息路由到不同集群的不同版本。
# 这是一个简化的示例,在 Kurator 管理下,这些配置可能通过更高层的 API 或 GitOps 下发
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: nginx-vs
namespace: global-apps
spec:
hosts:
- nginx.global-apps.svc.cluster.local
http:
- match:
- headers:
region:
exact: "edge"
route:
- destination:
host: nginx.global-apps.svc.cluster.local
subset: v2
- route: # 默认路由到 v1
- destination:
host: nginx.global-apps.svc.cluster.local
subset: v1
来自“edge”区域的流量会被导向 v2 版本,其他流量则仍使用 v1。Kurator 确保了这套复杂的 Istio 配置被正确同步到所有相关集群的 Istio 控制平面中。网络连通性排查和隧道维护等脏活累活都由 Kurator 完成,用户只需关注业务级的流量规则。
六、GitOps 之道:以 FluxCD 实现舰队级持续交付
6.1 Kurator CI/CD 的结构
Kurator 倡导 GitOps 作为舰队应用管理的核心模式。其 CI/CD 结构清晰:
- Git 仓库作为唯一可信源:所有集群的期望状态(Fleet、应用、配置)均以声明式 YAML 形式存储在 Git 中。
- FluxCD 作为协调引擎:Kurator 在管理集群中部署了 FluxCD,并为其配置了监视 Fleet 所有集群状态的能力。
- Kurator 作为策略与分发中转:FluxCD 监测到 Git 仓库变化,将新的 Kurator CRD(如
FleetApplication)应用到管理集群。Kurator 控制器再将这些高级资源翻译成底层组件(Karmada、原生 K8s)的配置,并分发执行。
6.2 全自动流水线示例
一个完整的 Kurator流水线 可以这样设计:
- 开发者推送代码到应用仓库,触发 CI 构建镜像并推送至 Registry,同时更新 Helm Chart 版本。
- 运维人员(或 CI 系统)更新 配置仓库 中对应
FleetApplication的 Helm Chart 版本字段并提交。 - FluxCD 检测到配置仓库的变更,将新的
FleetApplication拉取到管理集群。 - Kurator 控制器处理该对象,通过 Karmada 将新版本的 Helm Release 部署到 Fleet 中指定的集群。
- FleetMesh 确保新版本服务被平滑纳入网格,可按预设的灰度策略接收流量。
整个流程无需人工登录任何集群执行 kubectl 命令,实现了端到端的自动化、可审计的持续交付。
七、未来展望与专业思考
7.1 Kurator 未来发展方向
基于当前架构和社区动态,Kurator 可能在以下方向深化:
- 更智能的调度策略:集成更多的集群度量指标(成本、碳排放、实时带宽),结合机器学习实现预测性调度和自动优化。
- 无服务器(Serverless)集成:将 Knative 或 OpenFunction 等 Serverless 框架纳入 Fleet 管理范畴,提供统一的 FaaS 平台。
- 安全沙箱与机密计算:深度集成 Kata Containers 或 Confidential Containers,为舰队中的敏感工作负载提供更强的隔离和安全保障。
- 多租户与自服务门户:在强大的技术底层之上,构建面向企业内部多团队的自服务控制台,降低使用门槛。
7.2 对分布式云原生技术的建议
- 标准先行:希望 Kurator 等领先项目能更积极地参与 K8s 多集群 SIG、CNCF 网络与服务网格等标准化工作,推动跨云管理接口的事实标准形成,避免新的生态锁定。
- 可观测性统一:分布式系统的调试极其困难。未来应进一步加强将舰队中所有集群、所有组件(调度器、网格、边缘)的 metrics、logs、traces 统一聚合、关联分析的能力,这可能意味着与 OpenTelemetry 等项目的更深层次集成。
- 聚焦价值场景:技术最终服务于业务。社区应持续挖掘和深耕如全球应用交付、混合云容灾、边缘 AI 推理、跨云大数据处理等高价值场景,并提炼出最佳实践,让技术红利更快落地。
结语
Kurator 以其“集成而非替代”的务实理念,为我们描绘了分布式云原生管理的清晰蓝图。它通过 Fleet 这一精巧的抽象,将异构基础设施归一化处理;通过深度集成业界翘楚,将复杂的技术栈平民化应用。本文的实践之旅,仅揭开了其强大能力的冰山一角。随着社区的不断壮大和技术的持续演进,Kurator 有望成为连接云、边、端,驾驭分布式云原生浪潮的关键舵手。对于每一位云原生实践者而言,现在正是深入了解并参与其中的最佳时机。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)