【前瞻创想】多集群管理太头大?Kurator 实战全攻略:手把手带你玩转 Fleet、云边协同与自动化发布!
【前瞻创想】多集群管理太头大?Kurator 实战全攻略:手把手带你玩转 Fleet、云边协同与自动化发布!
关于 Kurator 的碎碎念
Kurator 就像是一个超级大脑,把散落在各地的 K8s 集群给捏成一个整体。它把分布式云原生的各种牛掰功能,比如多集群管理、批量调度、云边协同、自动化发布全给整合到一起了。今天我就带大家像“手搓”零件一样,把这一整套架构给理顺,看看它到底是怎么帮我们“偷懒”的。
一、 别废话,先起环境:从代码仓库到集群就绪
搞技术最忌讳的就是“纸上谈兵”。咱们第一步先把 Kurator 的代码仓库搞下来,这就像是盖房子先得有图纸和地基。
1.1 拉取核心仓库与环境初始化
咱们直接从 GitCode 镜像站拉取最新的 Kurator 代码。这一步是所有实操的起点,里面的 artifacts 目录下藏着不少好宝贝,比如安装脚本和各类 CRD 模板。
# 别犹豫,一行命令直接拉下来
git clone https://gitcode.com/kurator-dev/kurator.git
# 进到目录里看看,这可是咱们待会要“手搓”的战场
cd kurator
ls -F
# 通常我们需要检查一下当前的 kubectl 环境,确保你是对准了那个“主控集群”
# 这里的脚本是我们为了方便本地测试手写的简单检测逻辑
if kubectl cluster-info > /dev/null 2>&1; then
echo "集群状态在线,准备起飞!"
else
echo "兄弟,先检查下你的 KUBECONFIG 或者集群还活着没?"
exit 1
fi
既然要玩,那没项目怎么玩嘛,所以我们第一步先来把项目下载到本地,这一步非常简单,可以直接下载或者clone
我们本地若没有安装Git插件的,那我们直接就下载zip即可。当然,我们这里直接选择通过git远程克隆吧,会高级一些~~
接着,我们输入clone 指令。
git clone https://gitcode.com/kurator-dev/kurator.git
clone之后,我们便成功拿到了完整的Kurator项目源码:
1.2 基础工具链的准备
Kurator 依赖一些基础的 CRD,比如 Cluster API。在搭建环境时,我们需要确保主控集群(Hub)已经安装了相关的 Controller。这就像是你指挥部的电台得先调好频。
1.3 环境搭建的避坑指南
实操过程中,很多兄弟容易死在网络上。由于我们要管理多个集群,建议在环境搭建初期就规划好各个集群的内网 CIDR,别等到后面路由冲突了才拍大腿。
二、 指挥官的视角:Fleet 架构与统一监控的“透视眼”
集群多了,怎么管?Kurator 给出的方案叫 Fleet(舰队)。这个名字起得特别传神,你就是那个站在母舰上的指挥官。
2.1 Fleet 架构:不仅仅是聚合那么简单
这是Fleet架构的官方示意图,展示了其跨云、混合云和边缘的统一应用分发与管理平台: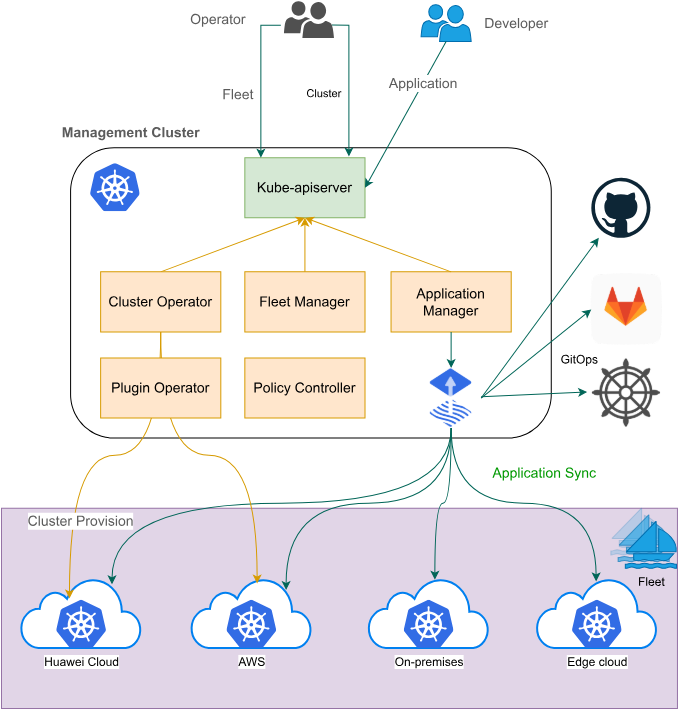
Fleet 架构的核心逻辑是“一处定义,到处运行”。它通过一组控制器来监听 Hub 集群里的 CRD 变化,然后把意志下达到各个分舰队(子集群)。
-
资源映射:你在 Hub 集群里定义一个
Fleet资源,它会自动识别哪些子集群属于这个舰队。 -
控制回路:它是基于 Cluster API 构建的,意味着它具备了生命周期管理的能力。你可以通过 Fleet 直接让某个子集群升个级,或者加两个节点。
2.2 Fleet 的核心架构:剥开洋葱看里层
如果往深了看,Fleet 的核心架构包含了一个极其关键的组件:Cluster Manager。它负责维护与各个 Spoke(子集群)的连接。
-
状态同步:它不是实时地去做强一致性同步,而是通过最终一致性模型。哪怕某个子集群断网了,等网通了,Fleet 依然能把它纠正回来。
-
策略下发:你可以定义
Policy,比如规定这个 Fleet 里的所有集群必须安装某个特定的安全组件。
这是Fleet的核心架构图,展示了其如何基于Bundle定义和集群分组实现多集群应用的分发、同步与状态追踪: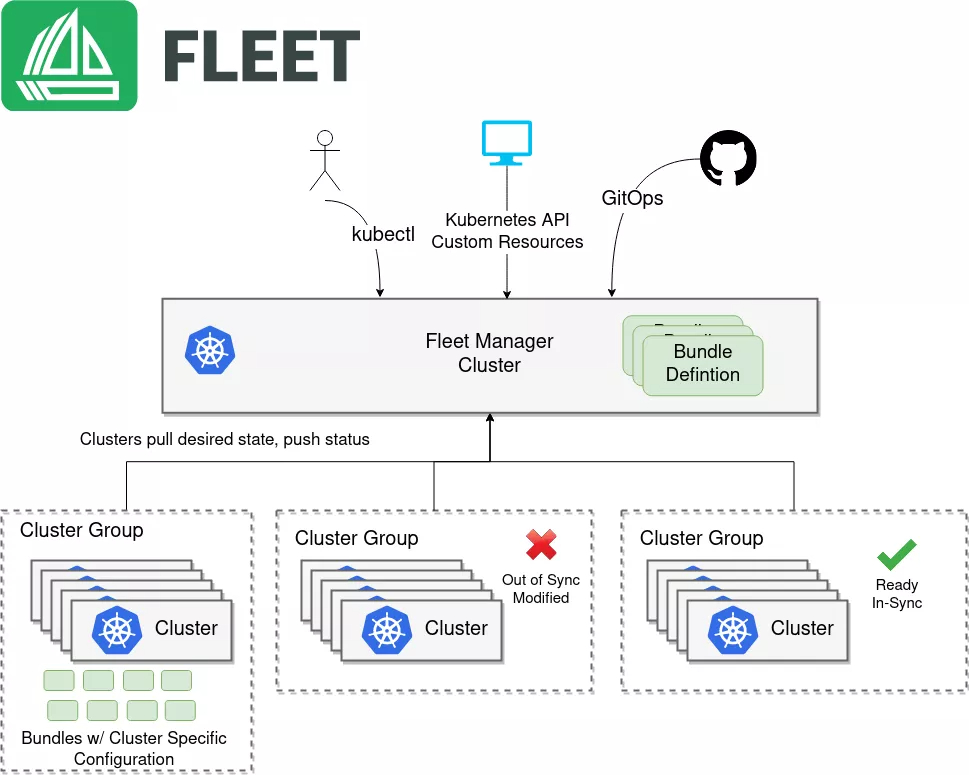
2.3 Kurator 的统一监控架构:拒绝切屏,一站式搞定
这张图展示了Kurator的统一监控架构,通过集中式配置和自动同步,把多个集群的监控数据汇聚到一起,实现跨集群的统一观测和管理,让运维更省心、排查问题也更快: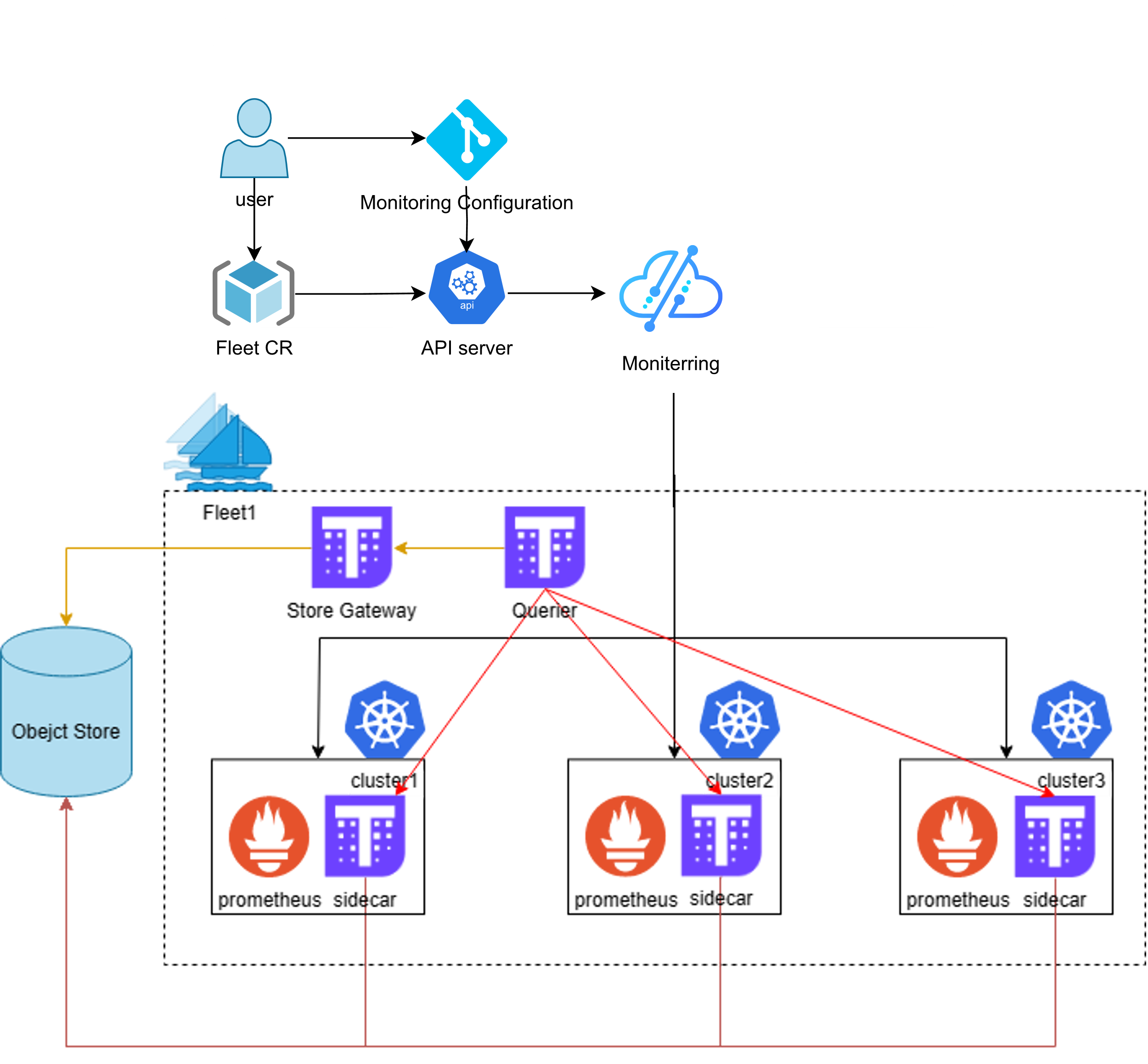
管集群最痛苦的就是看监控,50 个集群难道要开 50 个 Grafana 窗口?Kurator 的统一监控架构采用了 Prometheus 联邦机制 结合 Thanos/VictoriaMetrics 的思路。
-
数据汇聚:每个子集群跑一个轻量级的监控采样,然后通过公网或专线安全隧道,把关键指标推送到 Hub 集群。
-
全局视图:我们在 Hub 端手撸一个全局的仪表盘,就能一眼看穿整个舰队的健康状况。这不仅是数据的堆砌,更是通过 Fleet 的标签体系,实现了按维度(比如按地区、按业务线)的监控聚合。
三、 深入无人区:KubeEdge 详细架构与云边协同部署
很多时候,咱们的 Pod 不光跑在机房里,还得跑在工厂的网关或者路口的摄像头旁边。这时候就需要 KubeEdge 出来主持大局了。
3.1 KubeEdge 的详细架构:云边之间的秘密通道
这是KubeEdge的详细架构参考图,展示了云端核心组件、边缘节点及其与设备之间的完整管理、通信与应用部署链路: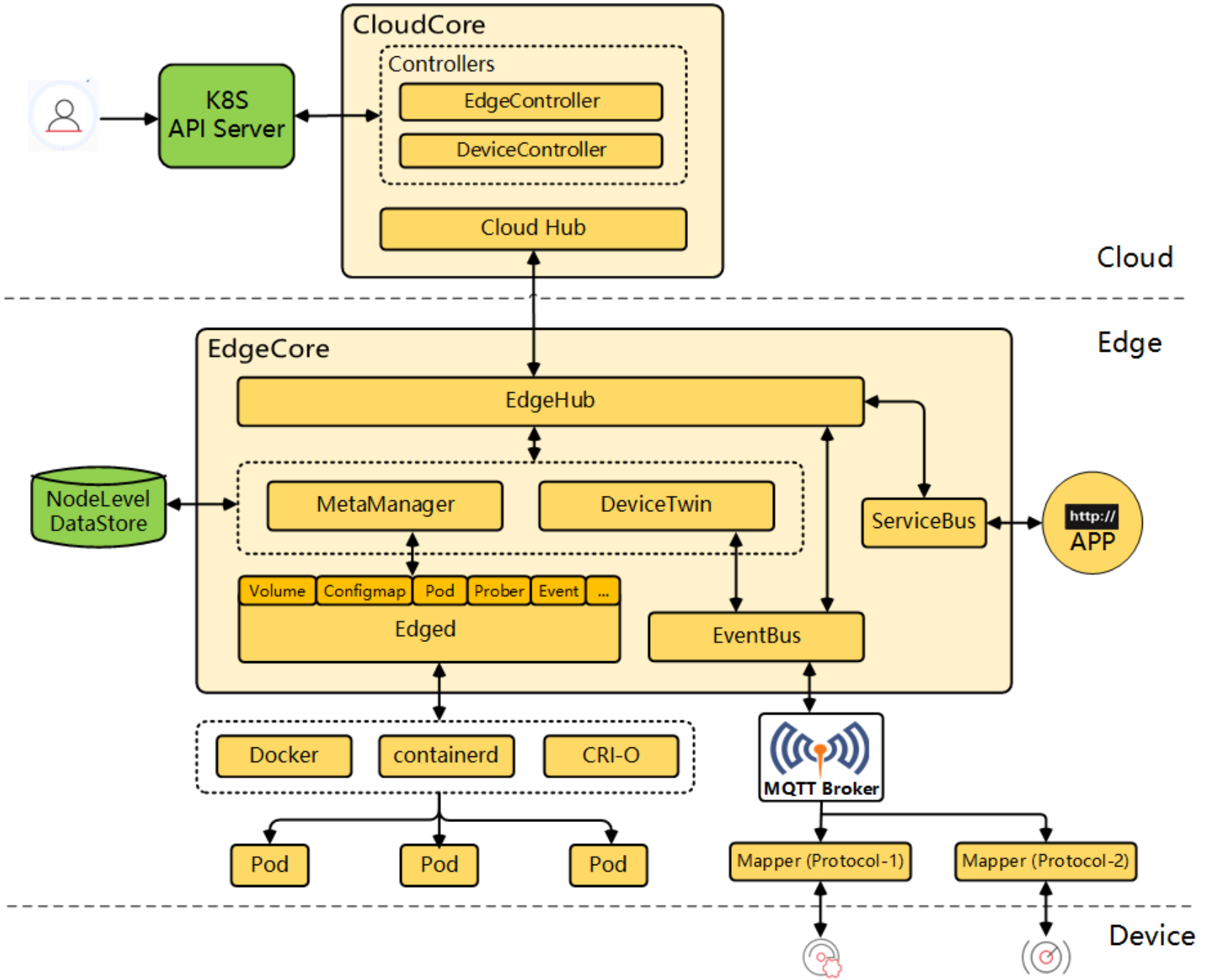
KubeEdge 是对 K8s 的一种“极限拉伸”。它的详细架构分为两个大块:CloudCore 和 EdgeCore。
-
CloudCore(云端大脑):它负责跟 K8s 的 API Server 打交道。最核心的是
EdgeController,它把 K8s 的资源变更转换成消息,通过 WebSocket 或者 QUIC 协议发给边缘。 -
EdgeCore(边缘心脏):这玩意儿运行在边缘节点上。里面有个
MetaManager,它非常关键,负责本地数据的持久化。万一云端和边缘断了网,边缘的容器还能靠本地的缓存继续跑,这就是我们常说的“离线自治”。
3.2 云边协同应用的部署架构:像调优本地一样调优边缘
在 Kurator 里的实操文里,云边协同的部署架构其实是一个“逻辑上一致,物理上分离”的过程。
-
节点亲和性:我们通过给边缘节点打标签,利用 K8s 原生的调度策略把任务精准投送。
-
流量闭环:Kurator 优化了边缘网络,使得同一边缘区域内的 Pod 互相访问不需要绕道云端,大大降低了延迟。
这张图展示了云边协同应用的部署架构,从设备层到边缘层、企业层再到产业平台,层层联动,实现工业数据在本地和云端的高效协同处理,支持智能制造和数字化转型: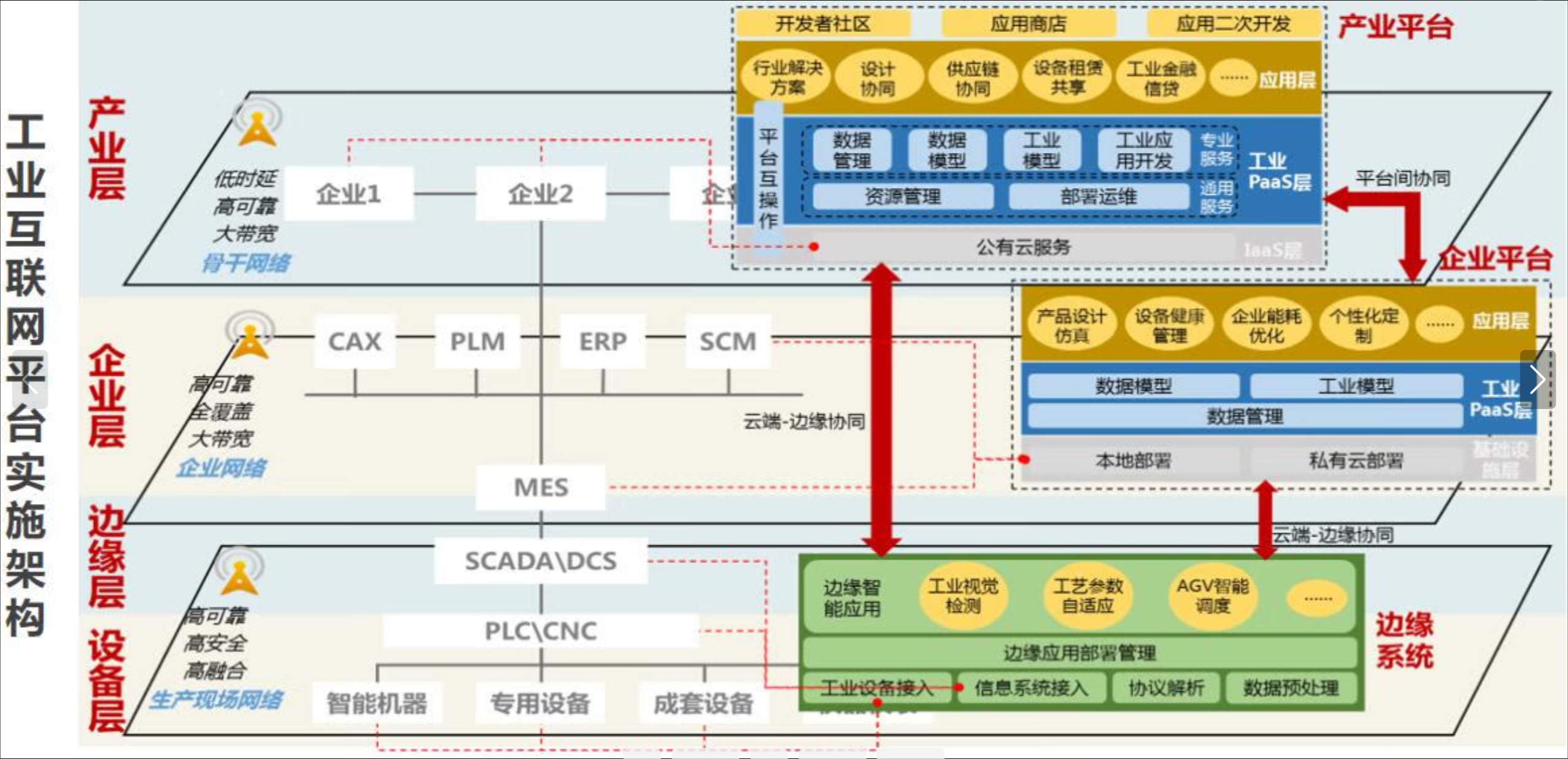
3.3 实际操作中的设备管理
别忘了,边缘端往往还有很多传感器和工业设备。KubeEdge 的架构里定义了 Device API,你可以手写一个 Device 模板,把家里的温湿度计也抽象成 K8s 的一个资源,这才是真正的云原生设备管理。
四、 高性能调度的艺术:Volcano 调度架构与应用场景
如果你在集群里跑 AI 训练或者是基因测序,你会发现原生的 K8s 调度器有点“捉襟见肘”。这时候 Volcano(火山)就要喷发了。
4.1 Volcano 调度架构:打破“一个一个来”的陈旧逻辑
传统的 K8s 调度是 Pod-by-Pod 的。Volcano 的调度架构引入了 Session(会话) 的概念。
-
批量调度(Gang Scheduling):这是它的拿手好戏。比如一个 AI 训练任务需要 4 个 Pod 同时干活,如果集群只剩下 3 个坑,Volcano 会选择一个都不起,而不是起 3 个在那干等浪费资源。
-
多插件机制:它的架构极其灵活,支持缓存、队列、抢占等多种插件。你可以根据自己的业务手搓一套调度算法插件。
4.2 Volcano 的应用场景:不仅仅是 AI
在实战中,Volcano 简直是大数据处理的神器。
-
AI 训练:大规模分布式训练,要求 Pod 之间极高的同步性。
-
大数据计算:比如跑 Spark 或者 Flink 任务,Volcano 能根据队列的优先级动态调整资源分配。
-
生命科学:那些极其耗计算资源的基因对比任务,用 Volcano 管起来能节省 30% 以上的计算时间。
为了让大家感受一下 Volcano 的魅力,咱们手搓一个简单的 PodGroup 资源定义。这是 Volcano 识别“一伙 Pod”的关键:
# 这是一个手写的 PodGroup 示例,告诉 Volcano 这一批 Pod 必须同生死共患难
apiVersion: scheduling.volcano.sh/v1beta1
kind: PodGroup
metadata:
name: kurator-ai-training-group
spec:
# 最小启动 Pod 数,达不到这个数,谁也别想开工
minMember: 4
queue: default
priorityClassName: high-priority
五、 自动化发布的终极闭环:CI/CD 完整流程与 Rollout 架构
代码写完了,环境也稳了,最后一步就是怎么把业务平滑地推上去。Kurator 把 CI/CD 和 Rollout 玩出了花。
5.1 Kurator CI/CD 的完整流程:从 Git 到全网生效
在 Kurator 的世界观里,CI/CD 是一个连贯的动作:
-
代码提交:程序员推代码。
-
构建镜像:流水线自动触发,镜像被打上版本号推送到私有仓库。
-
多集群感知:Kurator 的 CD 模块(通常集成 ArgoCD 这种思想)感知到镜像变化。
-
分发到 Fleet:Fleet 按照预设的策略,把更新指令像电波一样发给全球的子集群。
5.2 Kurator Rollout 功能的架构:发布不心慌的保障
Rollout 架构其实是加在 Deployment 之上的一层“保险丝”。
-
灰度发布:它不会一下把旧版本全删掉。它会先起一小部分新版本。
-
监控联动:这是最骚的操作。它会自动盯着咱们前面提到的“统一监控架构”。如果新版本上线后报错率飙升,Rollout 架构会自动触发回滚,根本不用你半夜爬起来操作。
5.3 生产环境下的“手搓”发布策略
实操中,我们通常会定义一个 Rollout 对象。这里面包含了我们对业务平滑过渡的所有理解。
# 这是一个贴合生产实战的 Kurator Rollout 配置片段
apiVersion: rollouts.k8s.io/v1alpha1
kind: Rollout
metadata:
name: business-app-rollout
spec:
# 咱们的策略是金丝雀发布(Canary)
strategy:
canary:
steps:
- setWeight: 20 # 先给 20% 的流量试试水
- pause: {duration: 10m} # 观察 10 分钟,没问题再继续
- setWeight: 50
- pause: {duration: 5m}
- setWeight: 100
# 这里引用我们要发布的业务应用
workloadRef:
apiVersion: apps/v1
kind: Deployment
name: main-api-server
写在最后
呼!洋洋洒洒说了这么多,咱们总算是把 Kurator 的核心点都给连起来了。从最开始用 git clone 准备环境,到通过 Fleet 架构指挥整个集群舰队;从云边协同把手伸向边缘,到利用 Volcano 压榨每一分算力,最后用 CI/CD 和 Rollout 实现自动化的华丽收尾。
搞云原生,最怕的就是守着一堆文档看,而不动手操作。Kurator 给了我们一个非常好的整合平台,让我们不用再去东拼西凑。如果你现在正面临多集群管理的焦头烂额,或者边缘端业务的一团乱麻,听我的,把代码拉下来,按我这篇实操文的思路“手搓”一遍,你会有全新的发现。
大家在玩 Kurator 的时候,如果碰到什么奇怪的报错,或者在 Fleet 调度上有什么独特的骚操作,欢迎评论区里聊聊。咱们云原生这条路,一个人走得快,一群人走得远!加油,打工人!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 27
27 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)