还在手动撸集群?快来看看这套 Kurator 云边一体化野路子,从此告别加班调参的苦日子!
还在手动撸集群?快来看看这套 Kurator 云边一体化野路子,从此告别加班调参的苦日子!
嘿,兄弟们,又见面了。
怎么把手里那堆乱七八糟的 Kubernetes 集群、边缘节点、还有跑得半死不活的 AI 任务给统一管起来。
说实话,这两年云原生圈子有点卷不动了,大家都在搞多云、搞边缘。但是你真上手就会发现:K8s 原生那一套在跨集群和边缘场景下,简直就是“灾难现场”。网络不通、调度不准、监控数据割裂……这坑我都替大家踩遍了。直到我碰到了 Kurator。
简单说,Kurator 这玩意儿就是一个“集成怪兽”。它不是重新造轮子,而是把 Karmada(多云编排)、KubeEdge(边缘计算)、Volcano(批量计算)、Istio(服务网格)这些顶级开源项目给“缝”在了一起,搓成了一个开箱即用的分布式云原生平台。它解决的痛点就一个:别让运维再当“表哥表姐”去手动维护几百个节点的配置了,咱们要的是统一视图、统一治理。
好了,废话不多说,保温杯里的枸杞水泡好,咱们直接开整。
一、 先把场子搭起来:环境准备与源码初探
老规矩,光说不练假把式。很多技术文上来就画图,画得天花乱坠,一到部署就报错。咱们今天反其道而行之,先把环境搞定,有了手感再聊架构。
要玩转 Kurator,你得准备一台像样的 Linux 机器(建议 Ubuntu 20.04+),Docker 和 Go 环境(建议 Go 1.20+)是必须要有的。别问我为什么 Docker 版本低了不行,问就是“依赖地狱”。
我们要做的第一件事,不是去下二进制包,而是直接把源码拉下来。为什么?因为 Kurator 更新贼快,看源码不仅能学到架构,关键是里面的 examples 目录才是真正的“宝藏库”,比官方文档更新得都及时。
如图这是kurator的gitCode站内资源
点击项目中可以看到如下的源码文件内容
到这一步我们下载源码就分成方便啦
如果我们有git环境就可以直接用命令clone到本地
如果没有的话也可以直接下载zip包
下载下来解压缩就能得到源码文件啦
如下是源码文件
拉下来之后,你会发现它的目录结构非常清晰。重点关注 pkg/ 下面的逻辑,那是核心。
环境搭建这块,我多啰嗦一句“避坑指南”:如果你是在国内的云主机上跑,千!万!别!忘!了!配置镜像加速器。Kurator 底层会拉取很多 K8s 的基础镜像,如果网络卡住,你会发现安装脚本一直在重试,那种绝望感懂的都懂。
Kurator 提供了非常方便的 CLI 工具,但我建议初期咱们先用 Helm 或者它自带的安装脚本来部署 Control Plane,这样你能清楚地看到它到底在你的集群里塞了哪些 CRD(自定义资源定义)。相信我,搞清楚 CRD,你就搞懂了 Kurator 的一半。
二、 掌控全局:Fleet 核心架构与统一监控体系
环境搭好了,咱们得聊聊怎么“管”。
在 Kurator 的世界观里,Fleet(舰队) 是个核心概念。你别把它想得太复杂,它其实就是一组集群的集合。
1. Fleet 的核心架构与整体设计
这是Fleet的核心架构图,展示了其如何基于Bundle定义和集群分组实现多集群应用的分发、同步与状态追踪: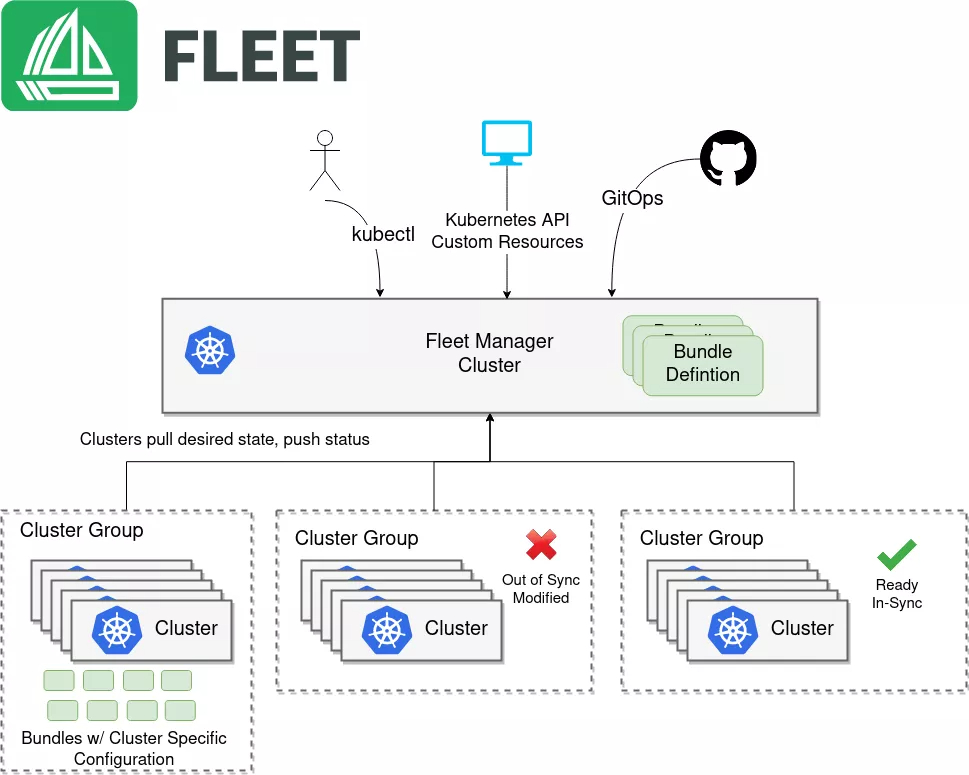
Fleet 的设计初衷是为了解决“配置漂移”的问题。以前我们管 10 个集群,得切 10 次 kubeconfig,在这个集群改了 nginx 配置,忘了那个集群,最后上线直接炸锅。
Kurator 的 Fleet 架构基于 Karmada 进行了深度封装。它的整体架构可以看作是一个“大脑(Host Cluster)”带着一堆“小弟(Member Clusters)”。
- 控制面(Control Plane):这是大脑。Kurator 在这里运行 API Server、Scheduler 和 Controller Manager。当你向控制面提交一个 Deployment 时,你并不是直接发给某个具体的集群,而是发给 Fleet。
- 资源解释器(Resource Interpreter):这是个很有意思的组件。它负责“翻译”。因为不同的集群可能有不同的资源结构或版本,解释器能确保你的配置下发下去是合法的。
- 传播策略(Propagation Policy):这是 Fleet 的灵魂。你可以定义:“把这个应用部署到所有带
region: hangzhou标签的集群,并且每个集群副本数按权重分配”。
这种架构最爽的一点是,它把多云管理变得像管理单机一样。你不需要关心底层是阿里云、AWS 还是你自己机房的裸金属,只要它连进了 Fleet,就是你的资源池。
2. Kurator 的统一监控体系
集群管起来了,要是瞎子可不行。Kurator 的监控体系是我觉得做得最贴心的地方之一。
以前做多集群监控,要在每个集群装 Prometheus,然后搞 Thanos 或者 VictoriaMetrics 做联邦,配置繁琐到令人发指。Kurator 搞了一套基于 Prometheus Federation 的自动化监控栈。
它利用 Fleet 的能力,自动在 Member Cluster 里注入监控 Agent(其实就是 Prometheus Agent 模式或者轻量级采集器)。这些 Agent 会自动发现本地的指标,然后通过加密通道“上报”给 Host Cluster 的统一存储网关。
避坑心得:在配置监控的时候,一定要注意指标的基数(Cardinality)。如果你的边缘节点有成千上万个,且每个 Pod 都有几十个自定义标签,统一汇聚后存储压力会巨大。建议在 Kurator 的配置里,开启指标过滤(Allowlist/Denylist),只上传核心指标(如 CPU、内存、网络、关键业务 QPS),别的留在本地查。
这张图展示了Kurator的统一监控架构,通过集中式配置和自动同步,把多个集群的监控数据汇聚到一起,实现跨集群的统一观测和管理,让运维更省心、排查问题也更快: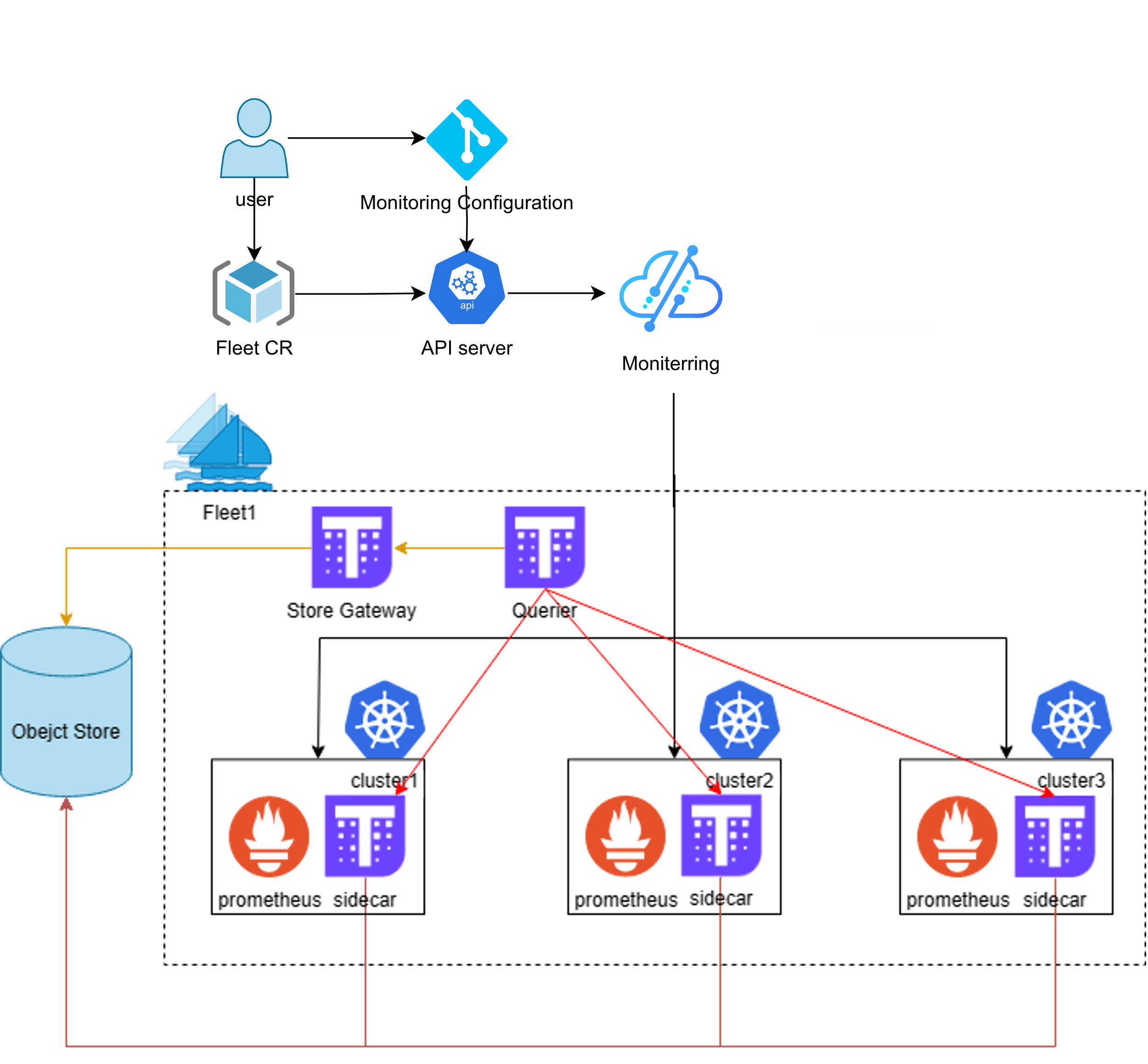
三、 决战边缘:KubeEdge 深度拆解与云边协同
既然咱们的主题是“云边协同”,那 KubeEdge 这个大杀器必须得讲透。Kurator 默认集成了 KubeEdge,让它成为了管理边缘节点的标准姿势。
1. KubeEdge 的详细架构拆解
这是KubeEdge的详细架构参考图,展示了云端核心组件、边缘节点及其与设备之间的完整管理、通信与应用部署链路: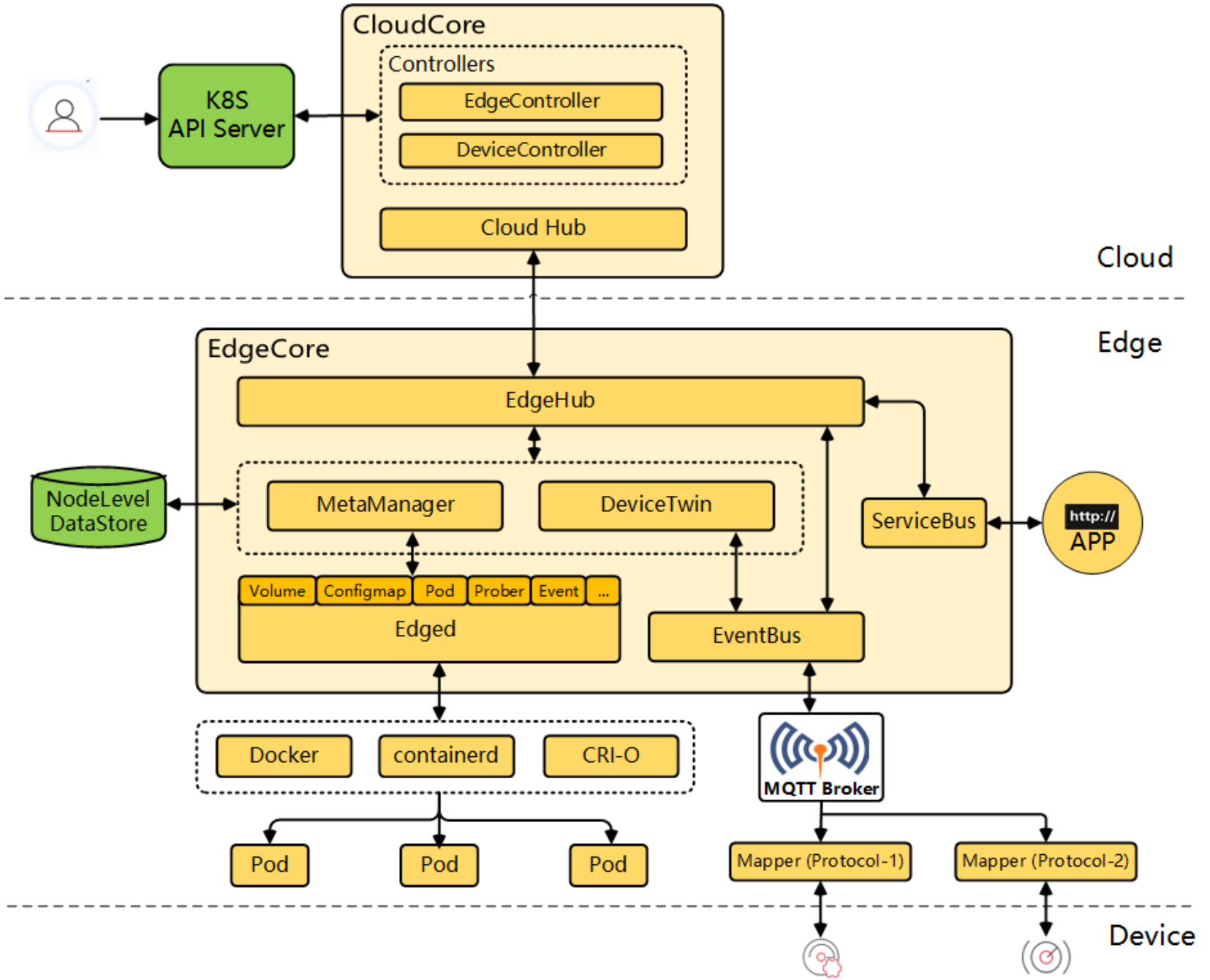
很多兄弟觉得 KubeEdge 神秘,其实拆开了看,它就是把 K8s 的 Kubelet 给“魔改”了,并且加了个超牛的“隧道”。
KubeEdge 的架构分两头:CloudCore(云端)和 EdgeCore(边缘端)。
- CloudCore:部署在 Kurator 的控制面集群里。它拦截了 K8s API Server 的请求。比如你
kubectl get nodes,如果请求的是边缘节点,CloudCore 就会接管。它通过 WebSocket 维持着与边缘节点的长连接。 - EdgeCore:跑在树莓派、工控机或者边缘网关上。它是个轻量级的 Agent。
- EdgeHub:负责跟云端通信,支持断网重连。这个非常关键,边缘网络抖动是常态,EdgeHub 会把没发出去的消息存在本地 SQLite 数据库里,网好了再发。
- Edged:这是 Kubelet 的精简版,负责管理 Pod 的生命周期。
- EventBus:这就厉害了,它支持 MQTT 协议。这意味着你的传感器数据可以直接通过 MQTT 发给 EventBus,然后映射成 K8s 的 CRD,云端立马就能看见。
2. 云边协同应用的部署架构
在 Kurator 里部署云边应用,那叫一个“丝滑”。你不需要单独去操作 KubeEdge,直接用 Kurator 的 API 定义应用。
Kurator 设计了一种差异化配置的能力。比如,你的后端服务跑在云端(高性能机器),而数据采集服务跑在边缘端(低功耗机器)。你可以用一个 Application 描述文件搞定。
下面这段代码,展示了如何用 Kurator(底层基于 Karmada 策略)定义一个分发策略,把采集服务专门“钉”在边缘节点上。这比你手动去写 NodeAffinity 优雅多了。
# 这是一个典型的 PropagationPolicy 示例
# 目的:将边缘采集服务精确分发到标签为 'edge-zone: factory-a' 的节点组
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: edge-collector-policy
namespace: manufacturing-app
spec:
# 资源定位:我们要分发哪个 Deployment
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: sensor-collector-v1 # 你的应用名字
placement:
# 集群亲和性:选择加入了 Fleet 的边缘集群
clusterAffinity:
clusterNames:
- edge-cluster-shanghai
# 副本调度策略
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightPreference:
staticWeightList:
- targetCluster:
clusterName: edge-cluster-shanghai
weight: 1 # 这里的权重可以控制流量或副本比例
# 这是一个关键点:差异化配置 (Override)
# 边缘节点的镜像仓库可能和云端不一样,或者需要挂载特殊的 HostPath
# Kurator 允许你在此处直接 Patch,而不用改原始 Deployment
# experimentalOverrides:
# - ... (这里可以写具体的 JSON Patch)
实操心得:在云边协同场景下,最头疼的是镜像拉取。边缘节点往往在一个私网环境,拉不到 Docker Hub。我的建议是:利用 Kurator 的镜像预热功能,或者在边缘侧搭建一个 Registry Mirror,配置在 EdgeCore 的配置里。别让网络成为压死边缘节点的最后一根稻草。
四、 算力榨干:Volcano 调度与 CI/CD 自动化
集群有了,边缘也通了,接下来该聊聊怎么让机器“跑满”。这年头,GPU 那么贵,要是利用率只有 20%,老板得杀人。
1. Volcano 的实际应用场景及其调度架构深度解析
这是Volcano的应用场景参考图,展示了它如何作为统一调度平台,支撑AI训练、大数据及科学计算等多种分布式工作负载: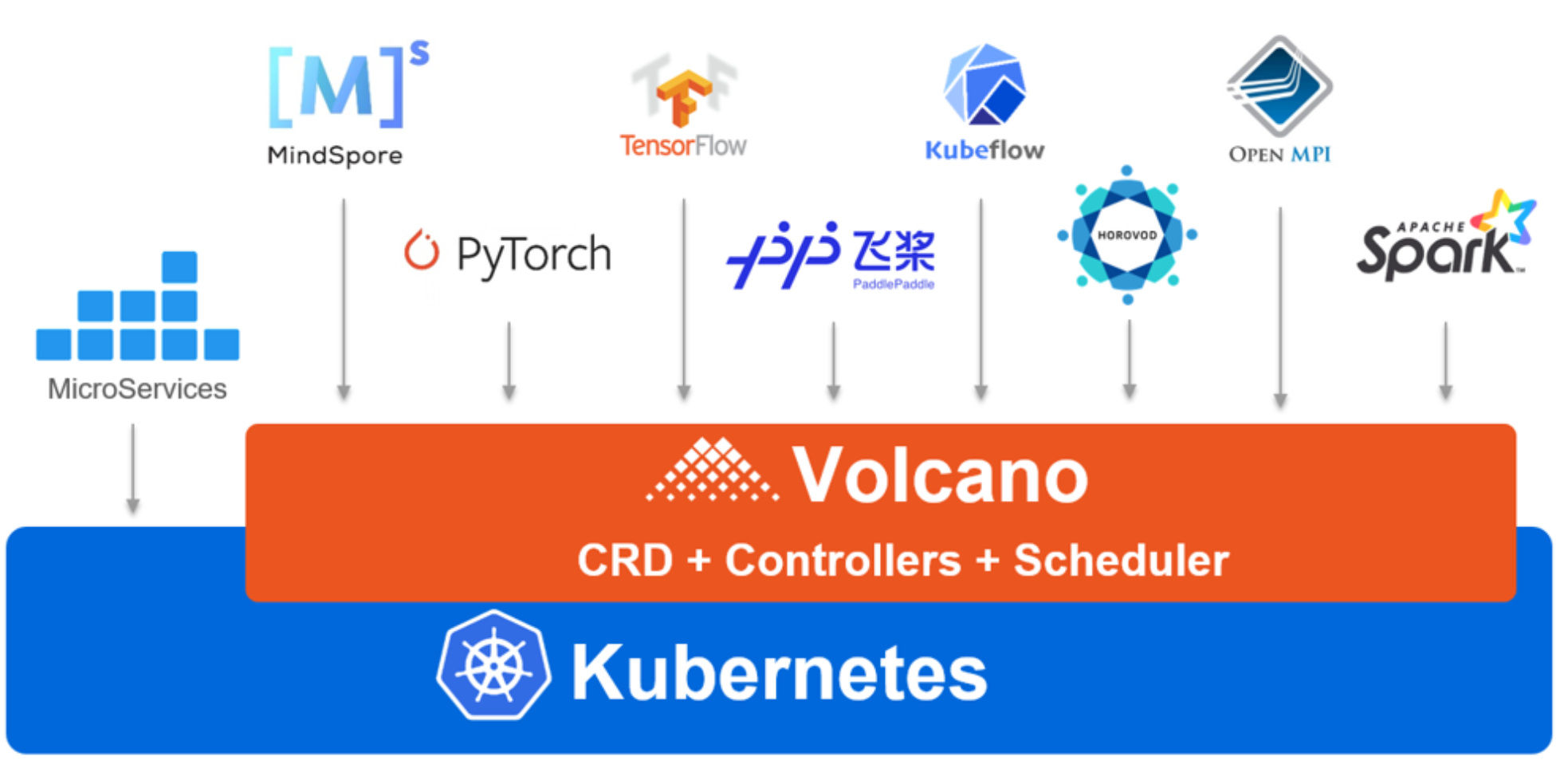
Kurator 集成了 Volcano,这是专门为高性能计算(HPC)和 AI 训练任务生的。
K8s 原生的调度器是“一个一个”调度的,这对于 AI 任务(比如 TensorFlow 的 Parameter Server 模式)来说是个坑。如果资源只够起 Worker,不够起 PS,那 Worker 起来了也是白等,浪费资源。
Volcano 的核心架构在于 Batch Scheduling(批量调度) 和 Queue(队列)。
- Gang Scheduling(帮派调度):这是 Volcano 的杀手锏。它奉行“要上一起上,不够别硬挤”的原则。一个 AI 任务需要的 10 个 Pod,要么同时拿到资源运行,要么都在队列里等着。这完美解决了死锁和资源碎片问题。
- Plugins 架构:Volcano 的调度逻辑全是插件化的。
drf(主导资源公平)、binpack(装箱算法)、proportion(队列比例)。
在 Kurator 中,你可以为不同的业务线创建不同的 Queue。比如,“数据科学组”一个队列,“线上推理组”一个队列,通过权重控制资源抢占。
下面这个 Job 定义,展示了如何用 Volcano 运行一个简单的批处理任务,注意看 minAvailable 字段,这就是 Gang Scheduling 的开关。
# Volcano Job 示例:这是一个必须同时起 3 个副本才能运行的任务
# 场景:分布式数据清洗,少一个节点都会导致数据不一致
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: data-scrubbing-job
namespace: bigdata
spec:
# 调度插件配置,这里启用了 gang 插件
schedulerName: volcano
minAvailable: 3 # 划重点:至少要有 3 个 Pod 资源就绪,才会开始调度
queue: data-science-queue # 指定该任务跑在哪个队列里
tasks:
- name: scrubber
replicas: 3
template:
spec:
containers:
- image: internal-repo/scrubber:v2.5
name: scrubber
command: ["/bin/sh", "-c", "python scrub.py --shard-index $VK_TASK_INDEX"]
resources:
requests:
cpu: "500m"
memory: "1Gi"
restartPolicy: OnFailure
2. Kurator CI/CD 的完整自动化流程
这张图展示了Kurator CI/CD的完整流程,从代码拉取、编译、安全扫描、镜像构建和签名,再到多环境自动部署,整个过程高度自动化,既保证了交付效率,又兼顾了安全性和可追溯性: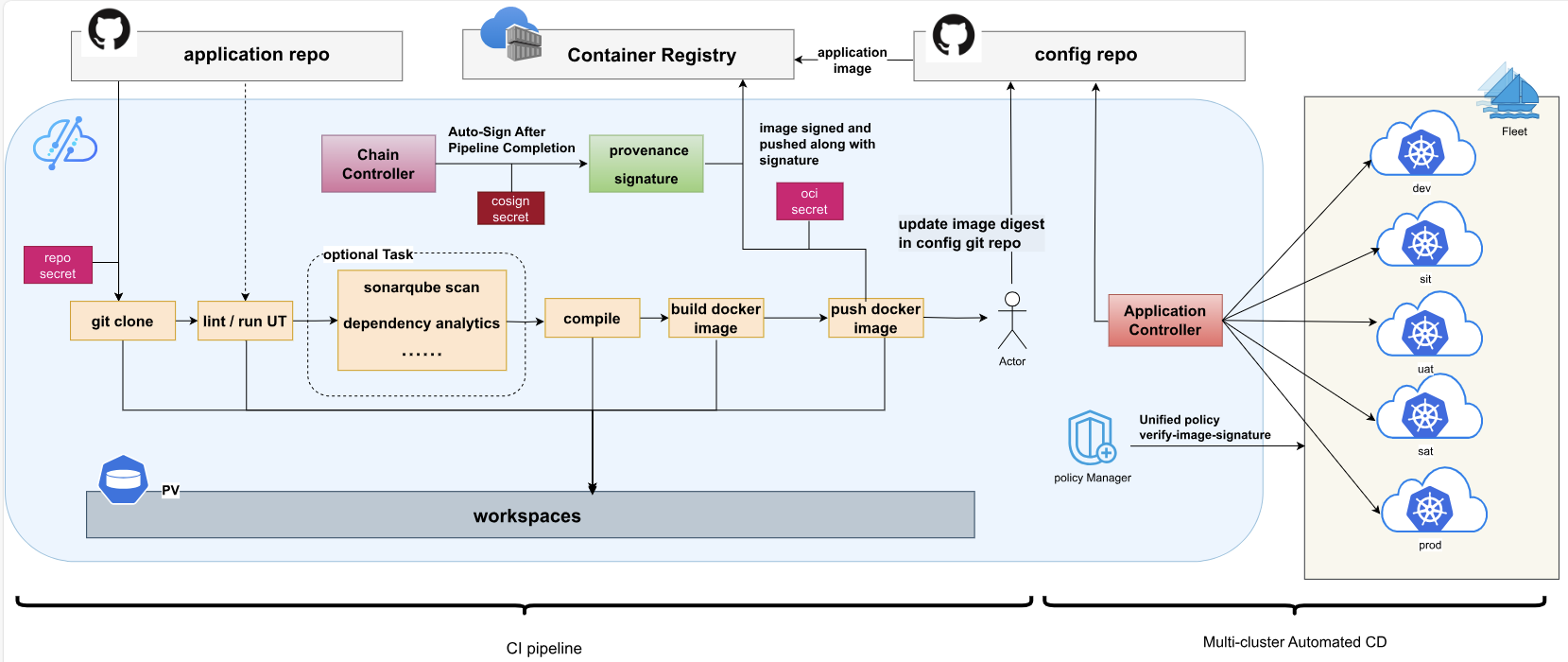
光有调度不够,还得有流水线。Kurator 的 CI/CD 不仅仅是 Jenkins 那么简单,它更倾向于 GitOps。
Kurator 内部整合了 Argo CD 或者 Flux(取决于你的配置选择)。整个自动化流程是这样的:
- 代码提交:开发老哥 push 代码到 GitLab。
- 镜像构建:触发 Jenkins/GitLab CI 构建 Docker 镜像,推送到 Harbor。
- 配置更新:CI 脚本自动修改 Git 仓库里的 Helm Chart 版本号。
- 自动同步:Kurator 的 GitOps 组件检测到仓库变动,自动将变更“拉取”到 Fleet 控制面。
- 多集群分发:Fleet 根据传播策略,把新版本的应用推送到北京、上海、广州的边缘集群。
这个过程完全不需要人工干预 kubectl。
五、 稳如老狗:Kurator Rollout 的功能实现架构
文章最后,咱们聊聊怎么“不炸库”。上线最怕什么?怕全量发布直接崩全网。
Kurator Rollout 模块就是为了解决这个问题。它基于 Argo Rollouts 进行了适配。它支持蓝绿发布(Blue-Green)和金丝雀发布(Canary)。
Kurator Rollout 的实现逻辑
它的核心原理是流量加权。它会控制 Service Mesh(如 Istio)或者 Ingress Controller(如 Nginx),精确地控制多少流量去新版本。
比如,我想先切 5% 的流量给新版本,跑 1 小时,如果没有 5xx 报错,自动加到 20%,最后全量。如果中间错误率飙升,立马回滚。
这在边缘场景尤其重要。你不可能派人去几千个边缘节点手动回滚。
下面这段代码,展示了如何定义一个带有“分析能力”的金丝雀发布策略。
# Kurator Rollout 策略示例
# 这是一个带有自动化指标分析的金丝雀发布
apiVersion: argoproj.io/v1alpha1
kind: Rollout
metadata:
name: api-gateway-rollout
spec:
replicas: 10
strategy:
canary:
# 流量切分步骤
steps:
- setWeight: 5 # 第一阶段:切 5% 流量
- pause: {duration: 10m} # 观察 10 分钟
- analysis: # 这里是核心:调用分析模板检查 Prometheus 指标
templates:
- templateName: success-rate-check # 预定义的检查成功率的模板
args:
- name: service-name
value: api-gateway
- setWeight: 50 # 如果分析通过,切到 50%
- pause: {duration: 30m}
- setWeight: 100 # 全量
selector:
matchLabels:
app: api-gateway
template:
metadata:
labels:
app: api-gateway
spec:
containers:
- name: gateway
image: my-registry/gateway:v3.0.1 # 新版本镜像
写在最后
兄弟们,写了这么多,其实就想传达一个观点:云原生到了今天,单打独斗的时代已经过去了。
Kurator 并不完美,它也有坑,文档有时也跟不上代码更新。但它的思路是对的——把业界最牛的开源项目整合起来,给咱们提供一个统一的“操作台”。
对于咱们这些在一线搬砖的工程师来说,掌握 Kurator 这种架构层面的工具,比单纯会写几个 K8s yaml 要有价值得多。它是你从“运维小哥”进阶到“平台架构师”的一把梯子。
好了,文章就到这。如果你在 git clone 之后遇到了什么奇葩报错,或者在配置 Fleet 的时候卡住了,欢迎在评论区或者社区群里吼一声。咱们技术人,主打的就是一个互助。
别愣着了,赶紧去试试吧,把你的集群“盘”得圆润一点!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 15
15 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)