【前瞻创想】搞定分布式集群管理:手把手带你用 Kurator 打造一站式云原生舰队,从基础环境搭建到 GitOps 与分布式存储实战全流程
【前瞻创想】搞定分布式集群管理:手把手带你用 Kurator 打造一站式云原生舰队,从基础环境搭建到 GitOps 与分布式存储实战全流程
说起现在的云原生开发,大家最头疼的可能早就不是怎么写个 Dockerfile 或者编排个 Pod 了,而是怎么管好手里那一堆散落在各处的 Kubernetes 集群。以前咱们可能就盯着一两个集群使劲薅,现在动不动就是多云、边缘计算、混合云,这种“集群大爆发”的场面,要是没个好工具,光是日常运维就能让人头大三圈。
这时候 Kurator 就派上用场了。简单来说,Kurator 就是要把这些零散的 Kubernetes 集群给“编队”,弄成一个整齐划一的“云原生舰队”。它不是简单地把集群堆在一起,而是从底层的基础设施自动化,到中间的存储、网络,再到上层的应用分发和流量治理,全给包圆了。接下来,我就以一个老兵的视角,带大家实操一遍,看看怎么用 Kurator 玩转这套先进的架构。
一、 Kurator 平台到底长啥样?咱们先从它的总体架构聊起 🏗️
要想用好一个东西,得先知道它骨子里是怎么长的。Kurator 的设计理念其实很明确,就是“统一”和“标准化”。
1. 揭秘 Kurator 平台的总体架构
这张Kurator架构图挺清晰的,Kurator 架构分为 Fleet Manager 统一管理集群、插件、应用与策略,Operator 负责流量与同步,底层集成多云与观测组件: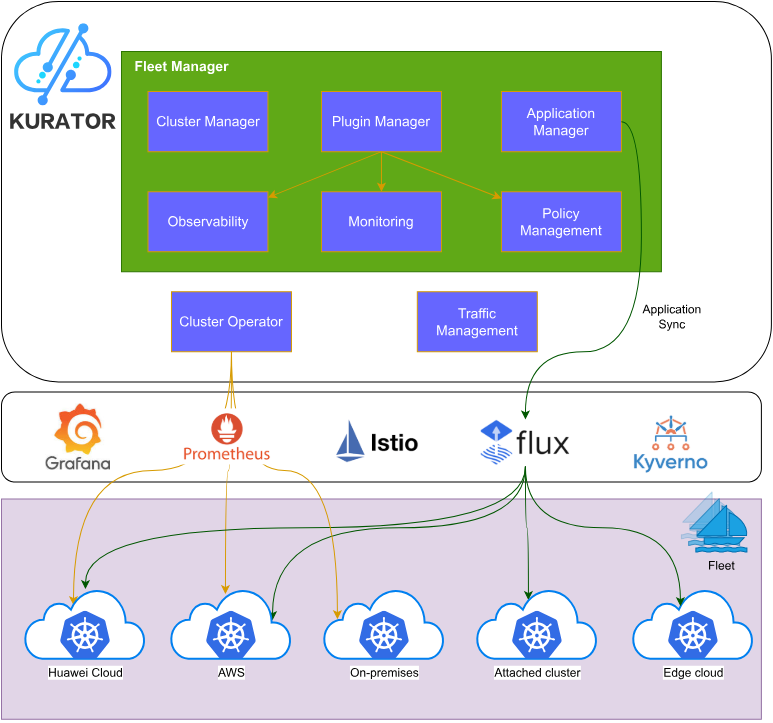
Kurator 并不是要在 Kubernetes 之上再造一个完全陌生的系统,它是站在巨人的肩膀上,整合了业内最顶尖的项目。它的核心思想是把分散的集群抽象成一个“Fleet”(舰队)的概念。在 Kurator 的总体架构里,它通过一套统一的控制平面,向下管理成百上千个不同环境下的集群。不管是公有云上的托管集群,还是你自己用物理机搭的私有集群,在 Kurator 眼里都是舰队里的一个成员。它通过 Cluster Operator 来负责集群的生命周期,通过 Karmada 负责跨集群的应用调度,再配合 GitOps 搞定自动化部署。这种层层递进的架构,保证了无论你的业务规模怎么扩充,管理逻辑都是一套,不会乱。
2. 聊聊那些稳如老狗的 Kubernetes 集群标准架构
这是Kubernetes集群的标准架构参考图,展示了包含控制平面组件、工作节点及云平台集成的完整集群部署模型: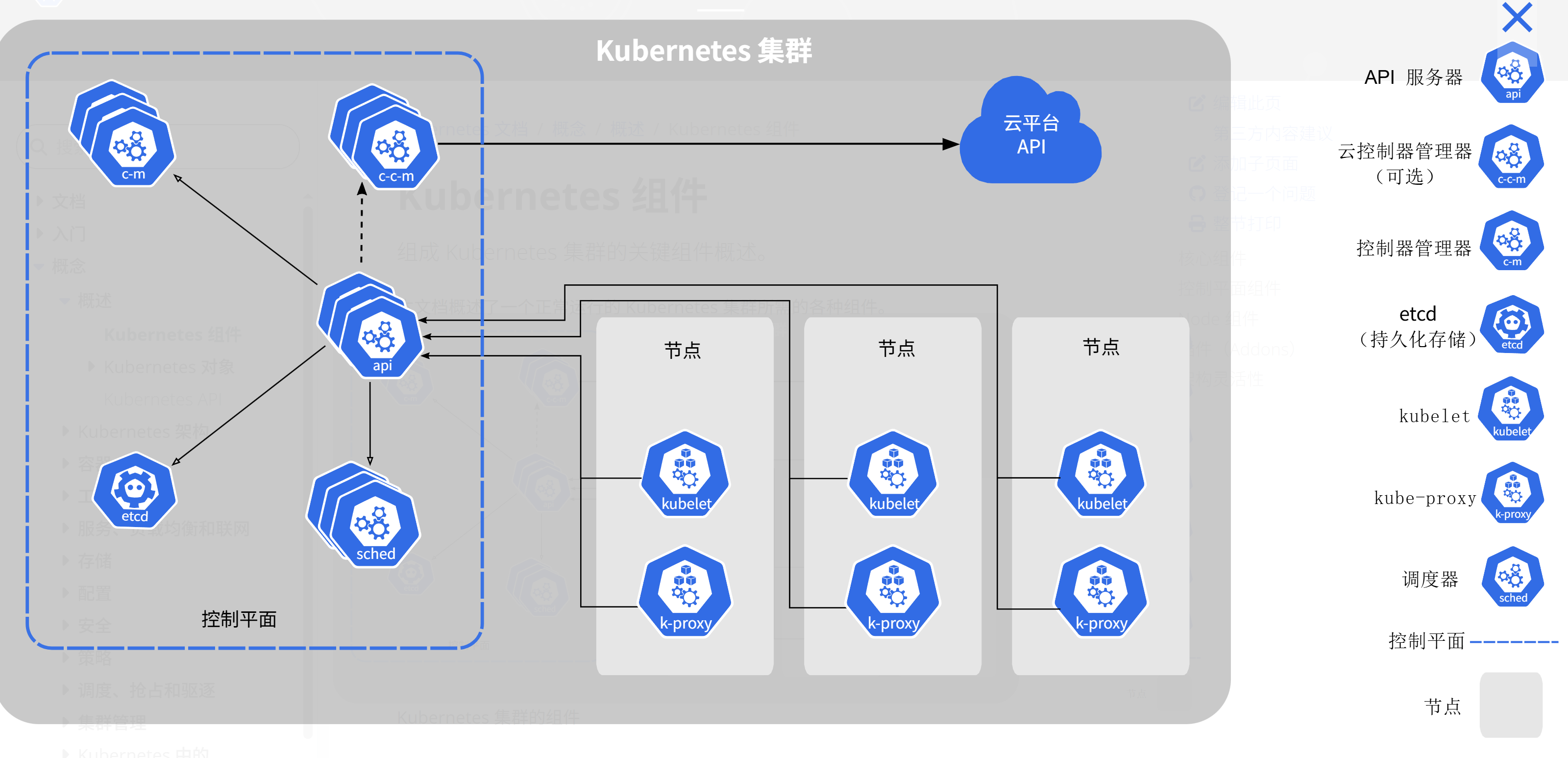
在 Kurator 的世界里,每一个加入舰队的集群都遵循一种“标准架构”。我们不再推崇那种野路子搭出来的集群,因为不好管。Kurator 提倡的是通过 Cluster API(CAPI)来定义的集群,这也就是我们常说的 Kubernetes 集群的标准架构。这意味着每个集群都有清晰的角色定义:控制节点干控制节点的活,工作节点老老实实跑业务,而且这些节点的扩容、缩容、升级,全部都变成了一种声明式的配置。你只需要告诉 Kurator 你想要个什么样的集群,剩下的事情,比如怎么装组件、怎么配置网络,都由底层的自动化逻辑去搞定。
二、 实战开始!咱们先把环境给搭起来,看看怎么上手 🛠️
聊完了虚的架构,咱们直接上硬菜。搞技术嘛,不亲手摸摸代码总觉得心里不踏实。
1. 手把手教你搭建环境:代码拉取与基础配置
首先,咱们得把 Kurator 的家当给搬回来。
当然,感兴趣的同学,可以将项目下载下来体验一下:
然后我们找到Kurator的https地址,通过git将其拉取到本地:
分别执行下面两条命令:
# 复制项目地址
https://gitcode.com/kurator-dev/kurator.git
# 克隆到本地
git clone https://gitcode.com/kurator-dev/kurator.git
实际克隆项目演示效果可以看到如下图: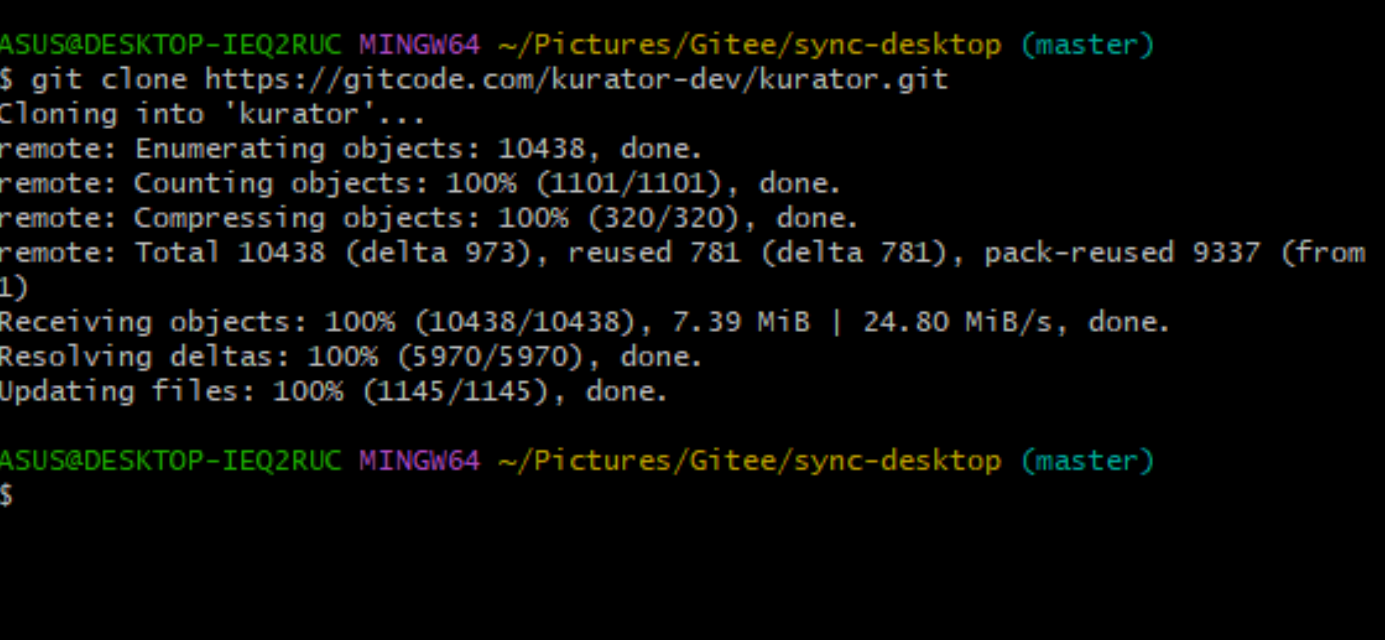
如下展示的便是完整的项目源码啦:
下载完成后,我们便可以进行项目部署及实战演练了。
这行命令执行完,你就已经拿到了 Kurator 的核心代码。接下来,你需要根据你的环境(比如是本地 Minikube 还是云上的 K8s)去修改配置文件。
2. Cluster Operator 的实现逻辑:集群是怎么自动跑起来的
这张图展示了Cluster Operator的实现细节,其实就是用户通过声明一个CRD,触发API Server事件,然后由Operator监听并调度多个管理worker去自动对接和管理不同的本地集群,整个过程用无密码认证打通,既安全又高效: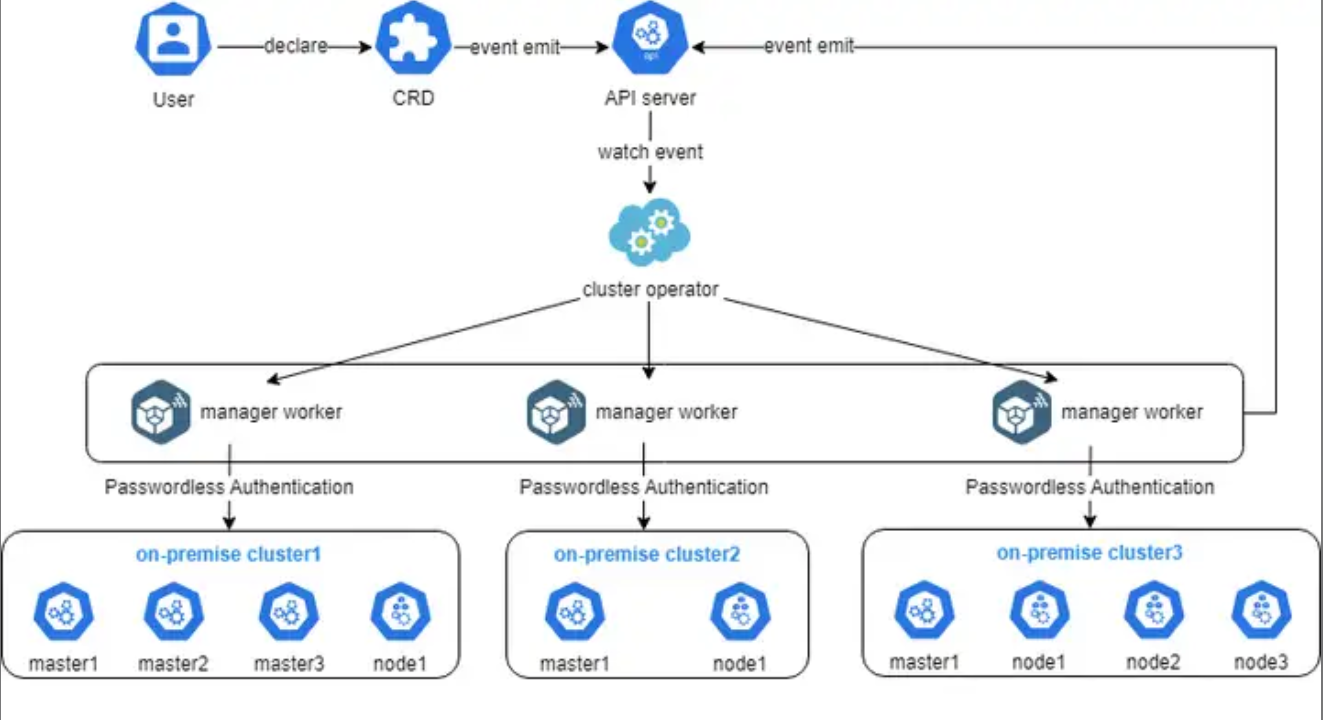
环境拉下来后,最核心的一个组件就是 Cluster Operator。你可以把它理解为一个“超级管家”。在传统的玩法里,你要加个节点,得手动 SSH 过去装包、加 Token。但在 Kurator 里,Cluster Operator 的实现是基于声明式 API 的。
简单来说,当你在管理集群里提交一个描述“目标集群”的 YAML 文件时,Cluster Operator 就会捕捉到这个信号。它会去调用底层的云厂商驱动或者 Baremetal 驱动,自动去刷镜像、配网络。如果在这个过程中,某个节点挂了,Operator 发现实际状态和你的 YAML 写的“期望状态”不一致,它会自动触发修复逻辑。这种“自愈”的能力,就是 Cluster Operator 最迷人的地方。
三、 所谓的“云原生舰队”是怎么管的?Karmada 又是怎么集成的? 🚢
有了集群,咱们就得聊聊怎么把它们组织起来。这就涉及到了“舰队管理”的概念。
1. 云原生舰队管理:告别碎片化的集群操作
当你手里有 10 个集群的时候,如果你还是一个一个集群去敲 kubectl apply,那效率太低了。云原生舰队管理的核心,就是把这些集群逻辑上编成一个组。在 Kurator 里,你可以定义一个 Fleet 对象,把上海、北京、甚至海外的集群都划到一个 Fleet 里。这样,当你需要下发一个全网通用的基础配置(比如安全策略)时,你只需要对着 Fleet 发指令,Kurator 就会像指挥官一样,把命令传达给所有的属下。
2. Karmada 集成实践:让多集群管理变得像单集群一样简单
这是Karmada集成实践的参考架构图,展示了其控制平面如何通过统一的策略API纳管多云、私有云及边缘异构集群: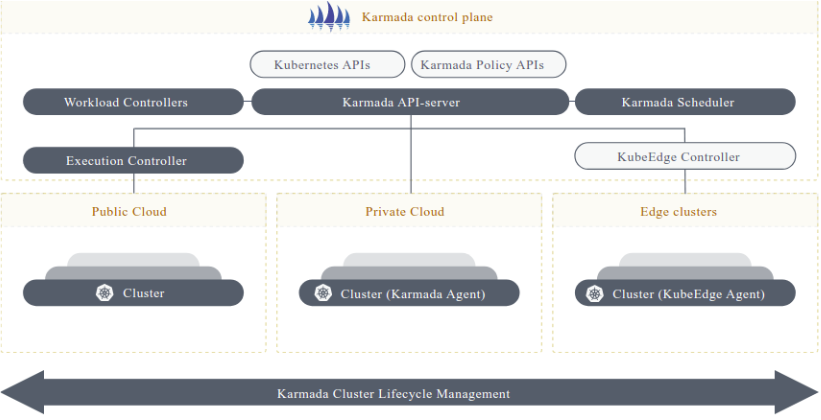
说到多集群,绕不开的一个大牛项目就是 Karmada。Kurator 聪明的地方在于,它直接把 Karmada 给集成进来了。在实践中,Karmada 扮演的是“超级调度员”的角色。
我们可以来看看,如果是咱们“手搓”一个 Karmada 风格的应用分发配置,它大概长这个样子(这只是个示意逻辑,说明应用是怎么分发的):
# 这是一个典型的应用分发策略,决定应用去哪个集群
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: my-app-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: my-web-server
placement:
clusterAffinity:
# 这里指定分发到带有 "env=prod" 标签的所有舰队成员集群中
labelSelector:
matchLabels:
env: prod
通过这种方式,你只需要在控制面写好 Policy,Karmada 就会帮你盯死那些子集群,确保应用稳稳地跑在上面。
四、 应用分发与自动化:GitOps 工作流和多集群分发管理架构 🚀
管理好了集群,接下来就是怎么优雅地发布应用了。
1. Kurator 统一应用分发的管理架构:应用是怎么精准投送的
这张图展示了Kurator统一应用分发的管理架构,实现跨多集群的一致化部署和管理,整个流程简单又可控: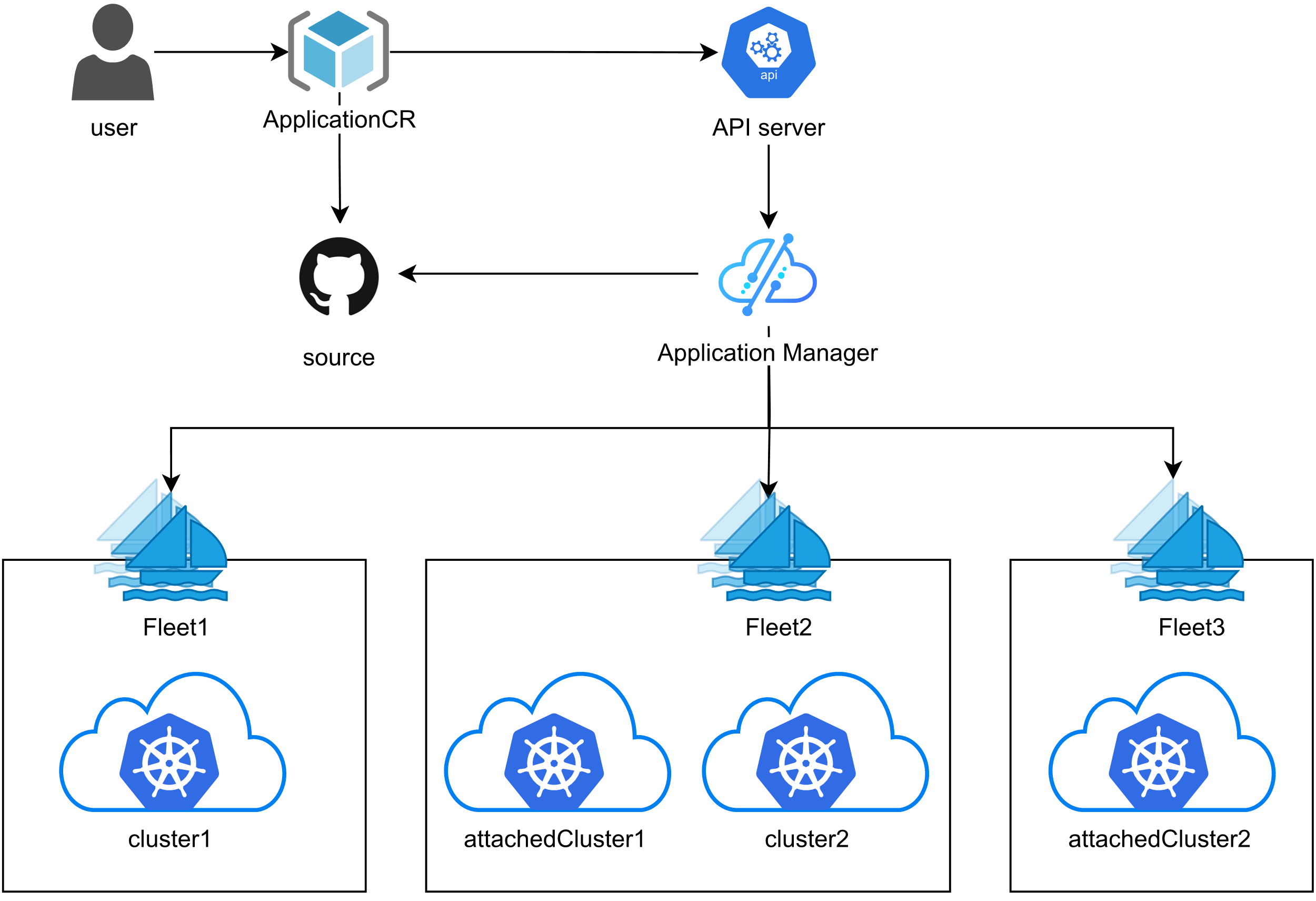
Kurator 建立了一套统一的应用分发管理架构。这套架构解决了“应用从哪来、到哪去、怎么去”的问题。它支持多种源,比如 Helm 仓库、S3 存储桶或者 Git 仓库。当你的应用打包好之后,Kurator 的分发控制器会根据预设的策略,把镜像镜像和配置文件投送到目标集群。最关键的是,这个过程是“版本化”和“可追溯”的。
2. 玩转 GitOps 工作流:代码提交即部署
现在的流行趋势是 GitOps。简单说,就是 Git 仓库里存的是什么,集群里跑的就是什么。在 Kurator 中,GitOps 工作流被集成得非常丝滑。你把 Kubernetes 的 Manifest 往 Git 仓库一推,Kurator 里的 GitOps 组件(通常是集成了 Flux 或者 ArgoCD 的能力)就会感知到代码变了。它会自动拉取最新的配置,然后在 Fleet 里的各个集群执行更新。这样,运维人员甚至不需要接触 kubectl,只需要审核代码合并(PR)就行了。
3. 聊聊 Fleet 队列中服务相同性:为什么同步这么重要
这是Fleet队列中服务相同性参考图,展示了其如何在不同集群间跨命名空间智能识别并分发关联服务: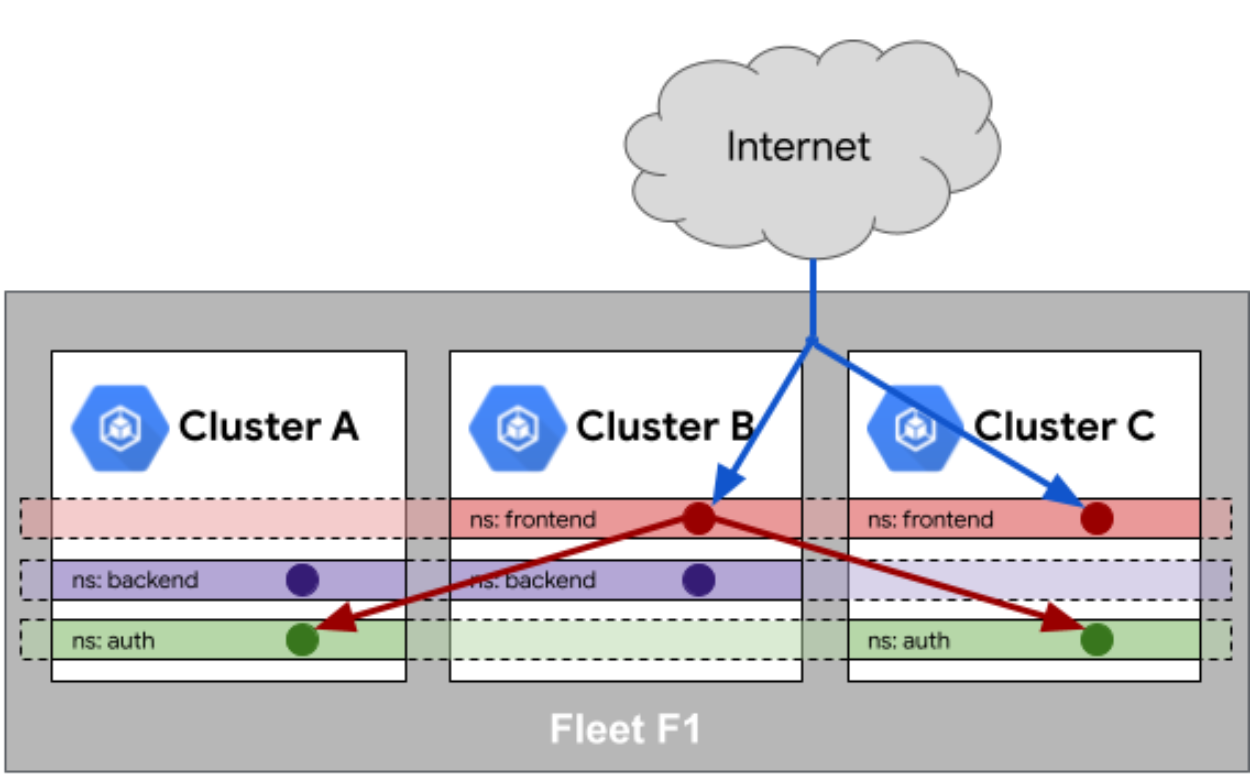
在多集群环境下,有一个坑很多人会踩,就是“环境漂移”。比如 A 集群里的服务是 v1 版本,B 集群因为网络闪断没更新成功,留在了 v0.9。Kurator 强调 Fleet 队列中的服务相同性,就是为了解决这个问题。通过持续的调和机制,它会强制要求舰队里属于同一逻辑组的服务保持版本、配置甚至环境变量的完全一致。只有保证了这种相同性,你的负载均衡和全局流量调度才有意义,否则用户访问到哪个集群全靠运气,排查问题时简直是灾难。
五、 存储与流量的高级进阶:从 Rook 存储到 Istio 灰度发布 🛡️
最后咱们聊聊两个硬骨头:存储和网络流量。
1. Kurator 的统一分布式存储架构:基于 Rook 搞定 Fleet 存储
这张图展示了Kurator的统一分布式存储架构,用户通过定义一个配置就能够在多个集群里自动部署和管理Rook存储: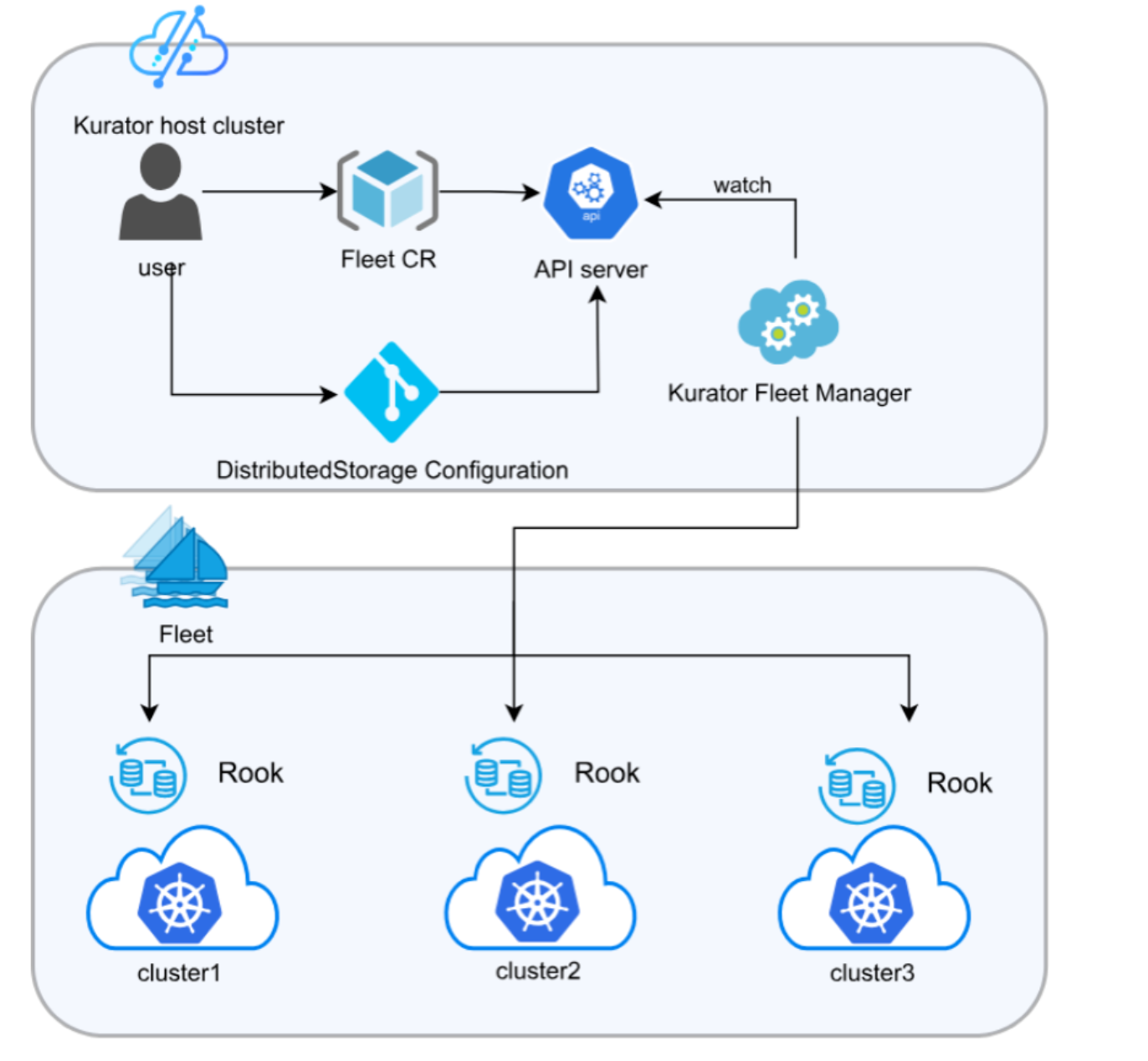
很多多集群方案只管计算,不管存储,结果数据同步成了大问题。Kurator 的统一分布式存储架构非常有特色,它深度集成了 Rook。Rook 实际上是 Ceph 在 Kubernetes 上的 Operator。
通过 Fleet 基于 Rook 构建统一分布式存储的架构,Kurator 可以在整个舰队范围内提供一种“逻辑上统一”的存储池。无论你的数据物理上是在哪个节点,上层应用看到的都是标准化的 PV(持久卷)。这大大简化了有状态应用(比如数据库)在多集群间的迁移和容灾。
2. Istio 服务网格的完整架构:怎么在多集群里做流量治理
当你的应用跨集群部署后,服务之间的通信(East-West traffic)就变得复杂了。Kurator 引入了 Istio 服务网格的完整架构。它不仅在一个集群里跑 Mesh,还要把网格扩展到整个舰队。通过部署一个多集群模式的 Istio 控制平面,所有集群的服务都纳入一个统一的信任域。这意味着集群 A 的服务可以直接通过服务名访问集群 B 的服务,而且中间的加密(mTLS)、可观测性全都是现成的。
3. Kurator 中配置 A/B 测试:手把手教你做流量切分
有了 Istio 之后,最爽的就是做流量实验。比如我们要给新版本做一个 AB 测试,在 Kurator 里你可以非常方便地配置。咱们来“手搓”一个 Istio 的虚拟服务配置,看看它是怎么实现 10% 流量给新版本的:
# 配置流量切分,这在多集群环境下做 A/B 测试非常实用
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: my-app-vservice
spec:
hosts:
- my-app.prod.svc.cluster.local
http:
- route:
- destination:
host: my-app.prod.svc.cluster.local
subset: v1
weight: 90 # 90% 的老流量继续走稳定版
- destination:
host: my-app.prod.svc.cluster.local
subset: v2
weight: 10 # 10% 的“小白鼠”流量去新版本测试
这种配置在 Kurator 统一管理下,可以迅速下发到所有相关的集群。你只需要在管理端改一下数字,全网的流量比例就会瞬时跟着变。
总结一下
到这里,咱们把 Kurator 的核心能力基本都盘了一遍。从最基础的 git clone 开始搭建环境,到利用 Cluster Operator 自动化造集群,再到通过 Karmada 和 GitOps 实现应用的“一键下发”,最后用 Rook 和 Istio 搞定存储与流量的高级玩法。
说实话,云原生这条路,集群只会越来越多,环境只会越来越杂。Kurator 给我们提供了一套很棒的思路:别试图去手动维护每一个孤岛,而是要把它们打造成一支纪律严明的舰队。如果你现在正被多集群管理搞得焦头烂额,不妨按我上面说的步骤,动手拉下代码试试看。毕竟,实践才是检验技术的唯一标准!
怎么样,看完之后是不是对手里的集群管理有了新的想法?其实多集群并不可怕,关键是要有“舰队思维”。如果你在搭建或者配置 GitOps 过程中遇到了什么坑,欢迎随时找我交流,咱们一起把这些“铁甲舰”开得更稳!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 15
15 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)