【前瞻创想】Kurator·云原生实战派:构建分布式云原生新范式
【前瞻创想】Kurator·云原生实战派:构建分布式云原生新范式
【前瞻创想】Kurator·云原生实战派:构建分布式云原生新范式

摘要
在数字化转型浪潮下,企业面临着多云、混合云和边缘计算的复杂环境挑战。Kurator作为开源分布式云原生平台,站在Kubernetes、Istio、Prometheus、FluxCD、KubeEdge、Volcano、Karmada、Kyverno等优秀开源项目的肩膀上,为用户提供统一的分布式云原生基础设施。本文深入解读Kurator的核心架构,通过实战案例展示其在多集群管理、边缘计算、批处理调度等场景的应用价值,分享环境搭建、Fleet管理、Karmada集成、KubeEdge边缘协同等关键技术实践,探讨分布式云原生技术的发展方向,为云原生技术爱好者和企业架构师提供实用参考。
1. Kurator架构与核心价值
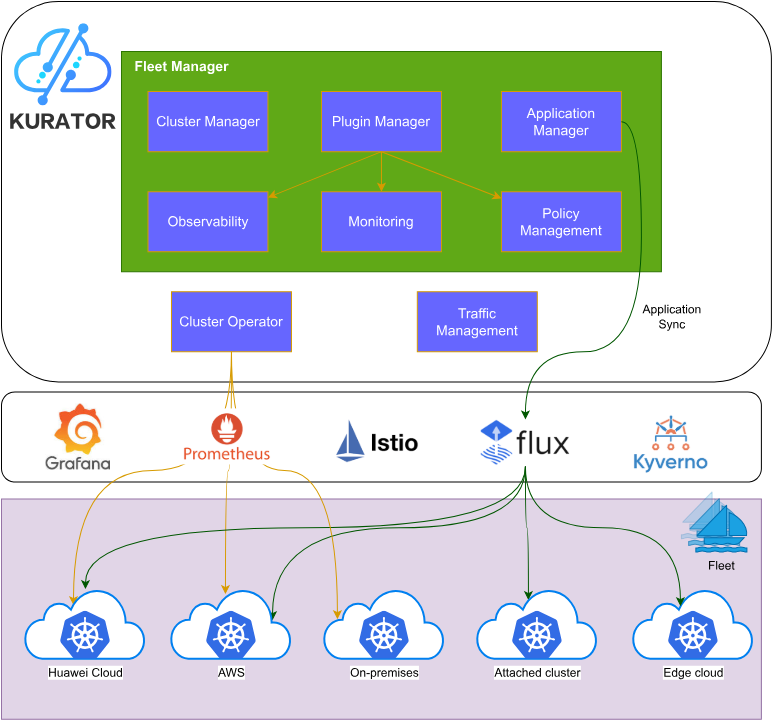
1.1 分布式云原生的挑战与机遇
当今企业IT架构正经历从单体应用到微服务、从数据中心到多云环境的深刻变革。传统云原生解决方案在面对跨地域、跨云厂商、边缘节点等复杂场景时,往往面临资源管理分散、应用部署不一致、运维复杂度高等问题。分布式云原生应运而生,旨在构建统一的资源视图、一致的应用体验和简化的运维流程。
1.2 Kurator核心架构解析
Kurator采用分层架构设计,底层依托Kubernetes作为容器编排基础,中间层集成了Istio、Prometheus、Karmada等云原生组件,上层通过Fleet概念实现多集群统一管理。其核心创新在于"Infrastructure-as-Code"理念的深度实践,通过声明式API实现集群、节点、VPC等基础设施的统一管理,无论这些资源位于公有云、私有云还是边缘环境。
1.3 与传统云原生平台的差异化优势
相比传统云原生平台,Kurator的独特价值体现在:统一的多云/边缘协同能力、开箱即用的云原生套件集成、声明式的基础设施管理、以及强大的GitOps支持。这些特性使企业能够快速构建符合自身业务需求的分布式云原生基础设施,而非受限于单一厂商的技术栈。
2. 环境搭建与基础配置
2.1 源码获取与环境准备
首先,我们需要获取Kurator的源代码。执行以下命令克隆官方仓库:
git clone https://github.com/kurator-dev/kurator.git
cd kurator
结果如下图:
在开始安装前,确保您的环境满足以下要求:
- Kubernetes集群(v1.20+)
- Helm(v3.8+)
- kubectl(与集群版本兼容)
- 至少8GB内存和4核CPU的节点资源
2.2 Kurator组件安装与配置
Kurator采用模块化设计,可以根据需求选择安装组件。使用Helm安装Kurator核心组件:
# 添加Kurator Helm仓库
helm repo add kurator https://kurator-dev.github.io/kurator/charts
helm repo update
# 安装Kurator控制平面
helm install kurator kurator/kurator \
--namespace kurator-system \
--create-namespace \
--set global.clusterDomain=cluster.local
对于开发环境,也可以使用源码中的脚本进行快速部署:
# 使用源码中的脚本安装
./scripts/install-kurator.sh
2.3 验证安装与基础功能测试
安装完成后,验证Kurator组件运行状态:
kubectl get pods -n kurator-system
预期看到controller-manager、scheduler、api-server等核心组件正常运行。接下来,创建一个简单的Fleet资源测试基础功能:
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
meta
name: test-fleet
spec:
clusters:
- name: member1
kubeconfigSecretRef:
name: member1-kubeconfig
namespace: kurator-system
通过上述步骤,我们完成了Kurator基础环境的搭建,为后续深入实践奠定了基础。
3. Fleet多集群管理实践
3.1 Fleet概念与架构设计
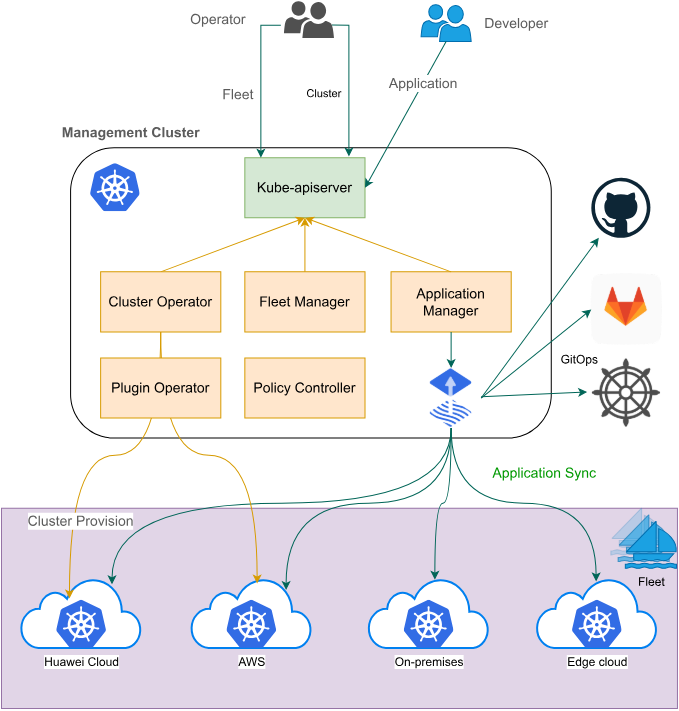
Fleet是Kurator的核心抽象概念,它代表一组逻辑上相关联的Kubernetes集群。Fleet架构设计解决了多集群环境下的资源碎片化问题,通过统一的控制平面实现跨集群的应用部署、策略同步和服务发现。Fleet支持三种主要模式:主从模式、对等模式和层级模式,适应不同的业务场景需求。
3.2 多集群注册与管理
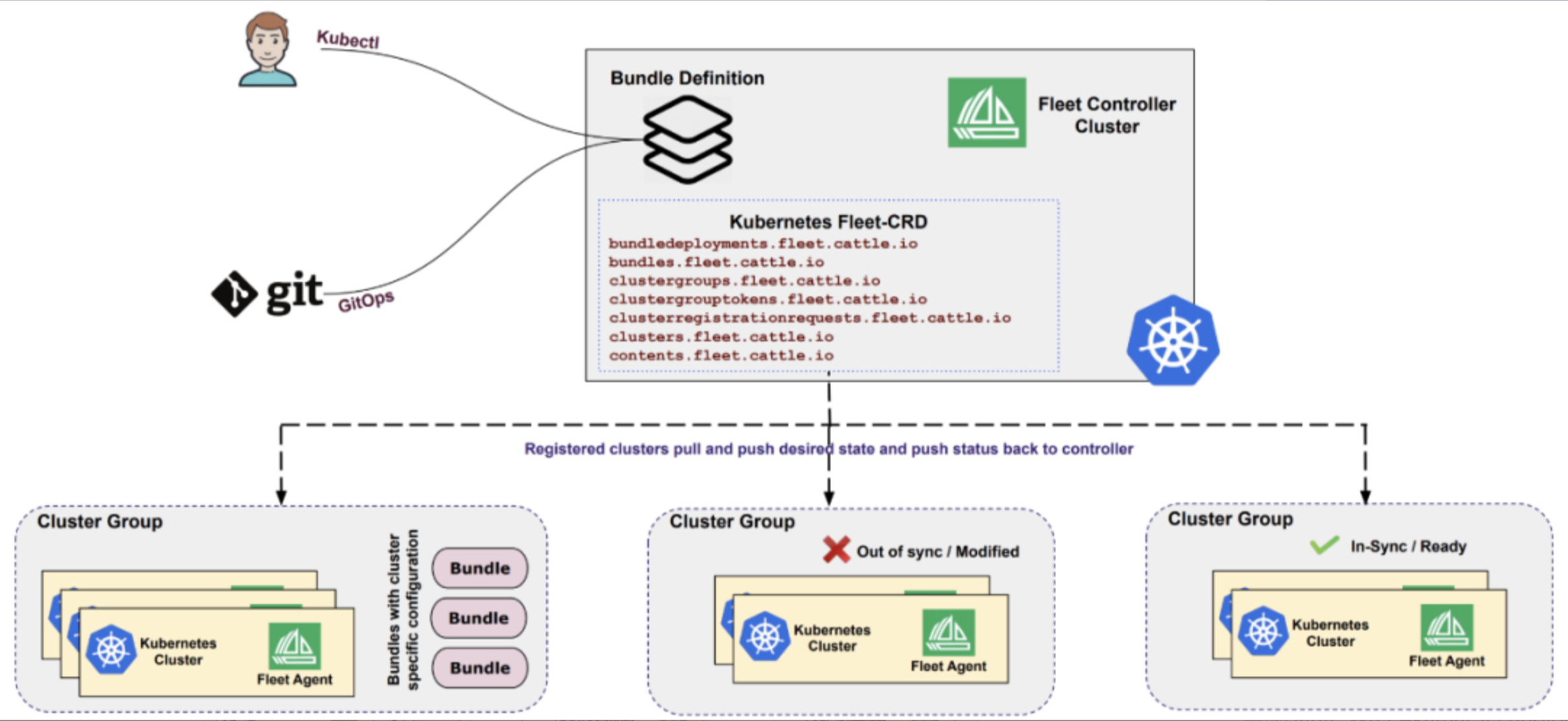
在Kurator中,将集群加入Fleet的过程称为"注册"。以下是注册一个新集群到Fleet的示例:
# 准备目标集群的kubeconfig
kubectl config view --minify --flatten > member-cluster-kubeconfig
# 创建Secret存储kubeconfig
kubectl create secret generic member1-kubeconfig \
--from-file=kubeconfig=member-cluster-kubeconfig \
-n kurator-system
# 更新Fleet配置,添加新集群
kubectl apply -f - <<EOF
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
meta
name: production-fleet
spec:
clusters:
- name: member1
kubeconfigSecretRef:
name: member1-kubeconfig
namespace: kurator-system
- name: member2
kubeconfigSecretRef:
name: member2-kubeconfig
namespace: kurator-system
EOF
3.3 统一资源编排与策略同步
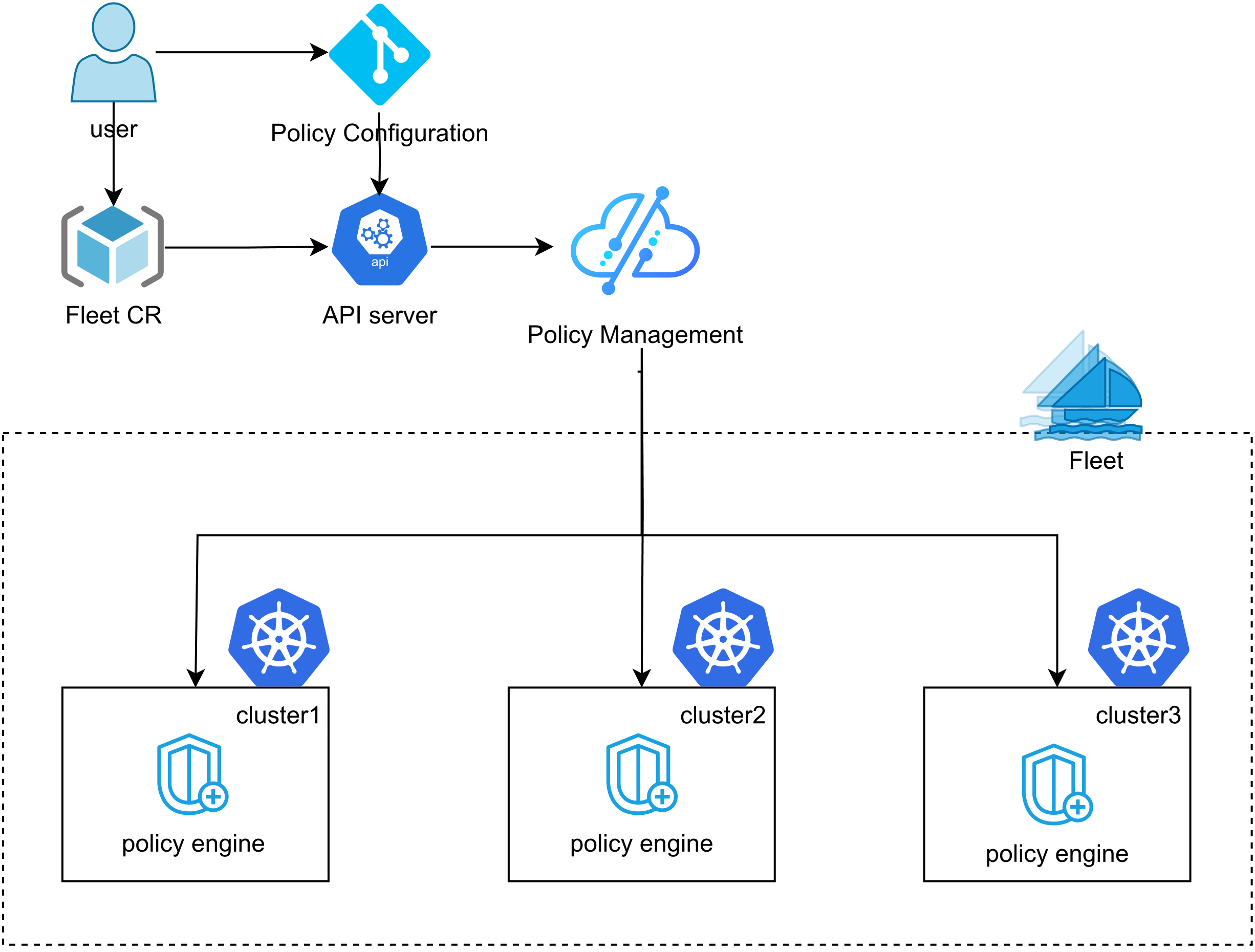
Kurator的统一资源编排能力允许用户在Fleet级别定义资源,自动同步到所有成员集群。例如,定义一个命名空间策略:
apiVersion: policy.kurator.dev/v1alpha1
kind: NamespacePolicy
meta
name: common-namespaces
spec:
fleetSelector:
matchLabels:
environment: production
namespaceTemplates:
- meta
name: monitoring
spec: {}
- meta
name: logging
spec: {}
通过这种方式,可以在所有生产环境集群中自动创建一致的命名空间结构,确保环境一致性。
3.4 跨集群服务发现与通信
Kurator集成了Karmada的服务发现机制,实现跨集群的服务通信。以下配置示例展示了如何启用跨集群服务发现:
apiVersion: service.kurator.dev/v1alpha1
kind: ServiceExport
meta
name: frontend
namespace: default
spec:
fleetSelector:
matchLabels:
environment: production
当ServiceExport资源创建后,Kurator会自动在所有匹配的集群中导出该服务,并通过DNS实现跨集群服务发现。
4. Karmada集成与跨集群调度
4.1 Karmada核心能力解析
Karmada作为CNCF沙箱项目,专注于Kubernetes多集群和多云管理。其核心能力包括:跨集群调度、多集群服务发现、策略传播和故障转移。Kurator深度集成Karmada,将其作为多集群调度的核心引擎,提供统一的调度策略API。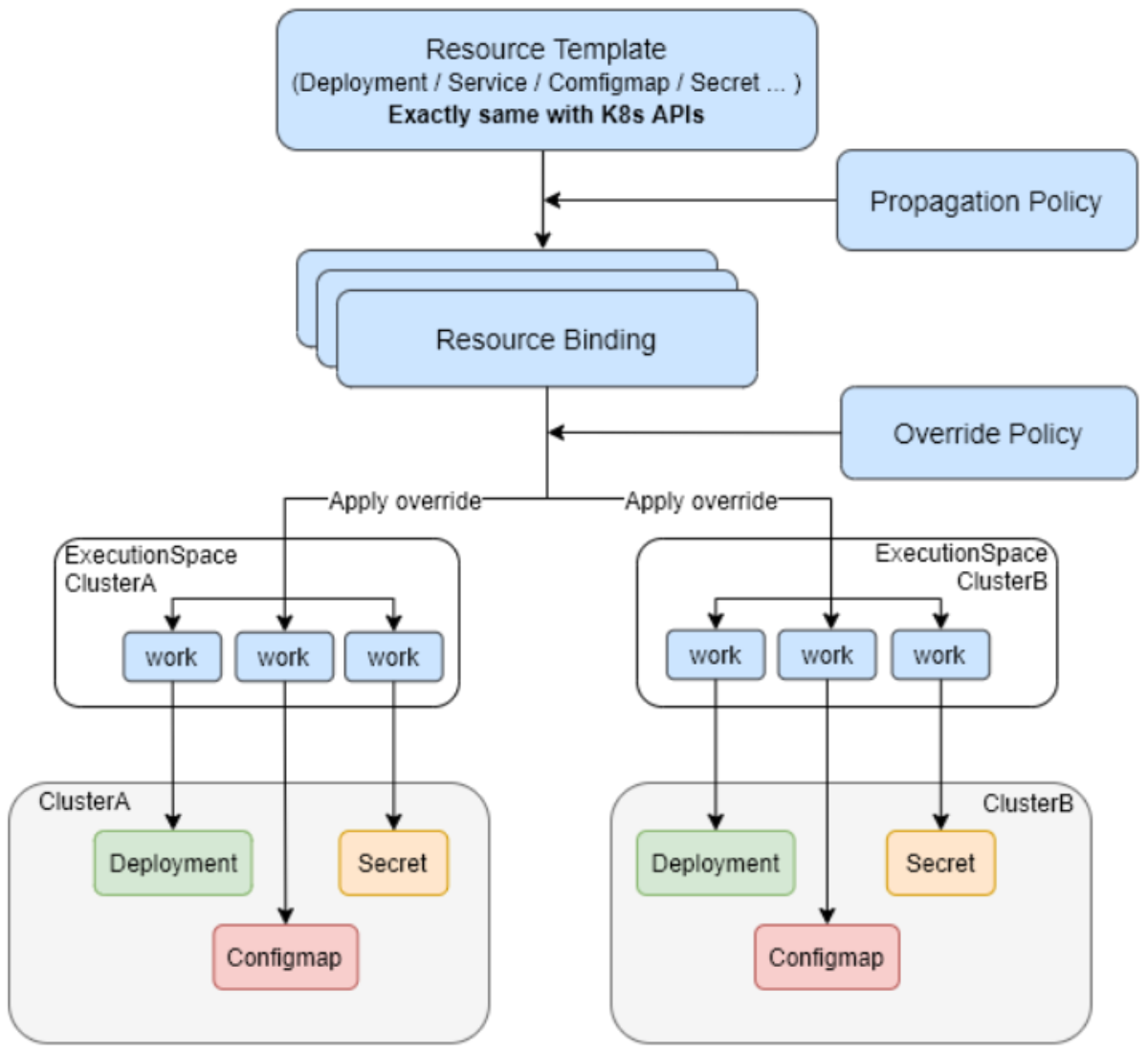
4.2 Kurator与Karmada深度集成
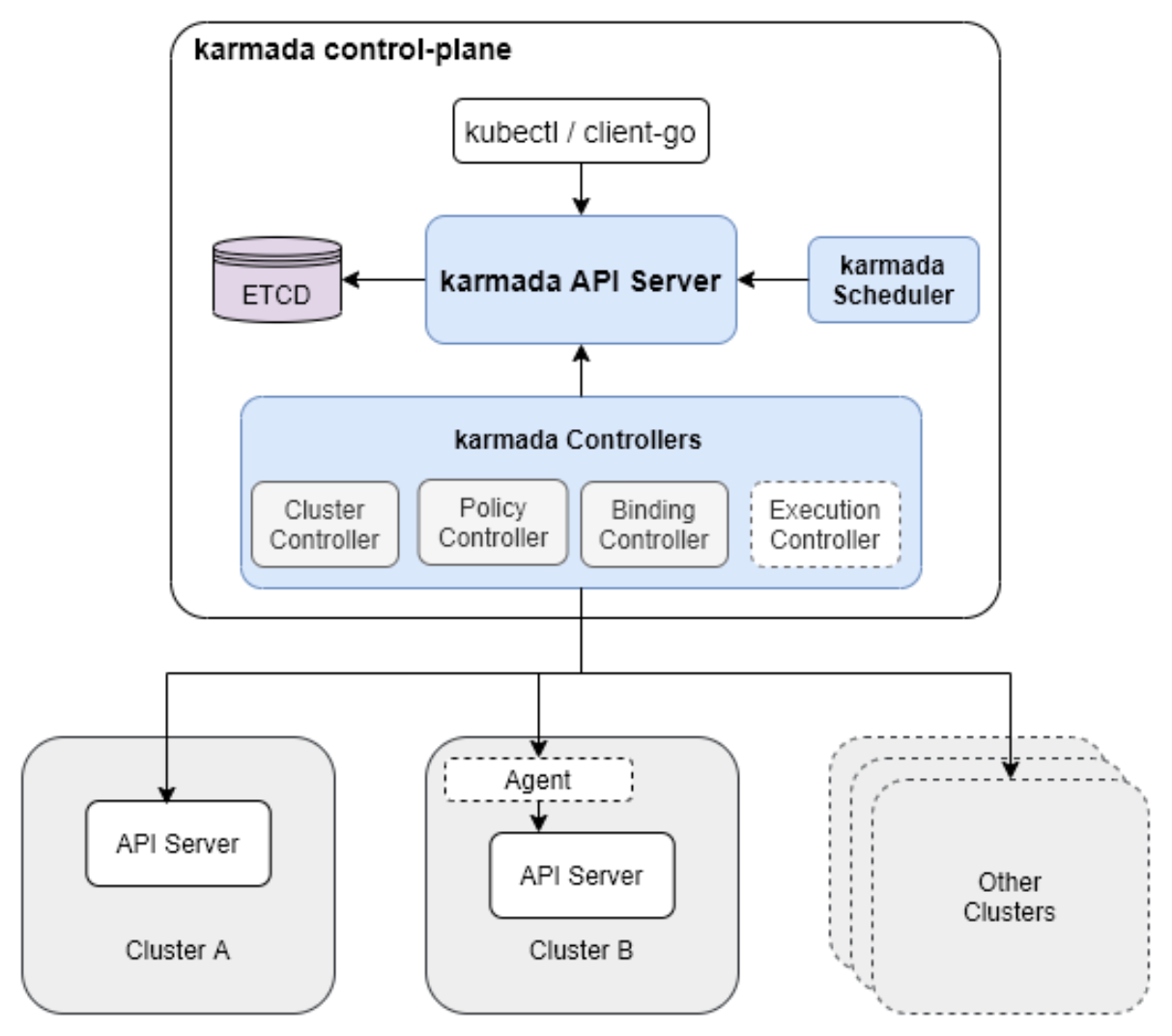
在Kurator架构中,Karmada被封装为一个可插拔组件,通过统一的API暴露其能力。以下代码展示了如何在Kurator中配置Karmada调度策略:
apiVersion: scheduling.kurator.dev/v1alpha1
kind: ClusterSchedulingPolicy
metadata:
name: spread-by-region
spec:
placement:
clusterAffinity:
clusterNames:
- cluster-east
- cluster-west
spreadConstraints:
- spreadBy: region
maxGroups: 2
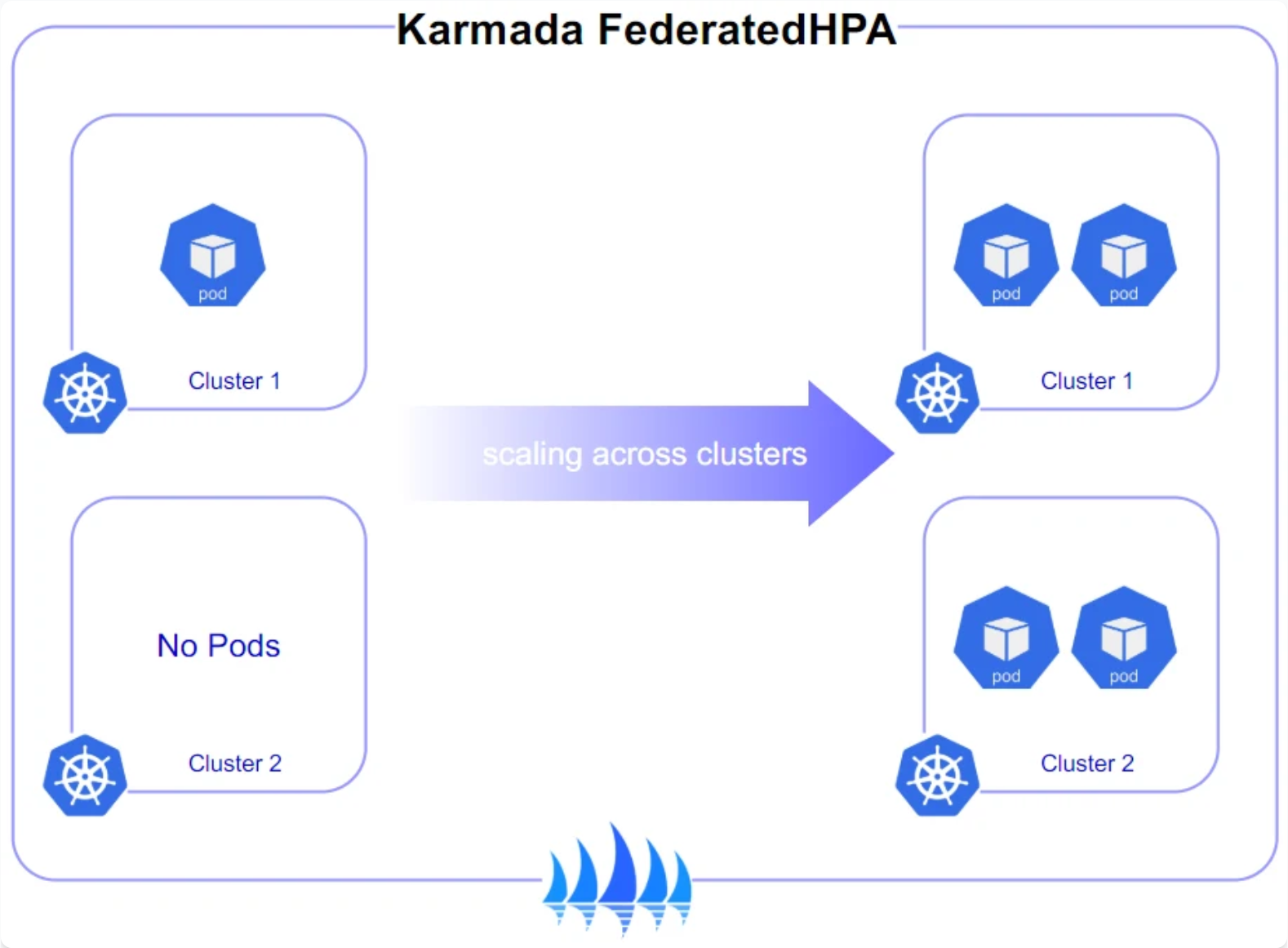
4.3 跨集群弹性伸缩实践
基于Karmada的弹性伸缩能力,Kurator实现了跨集群的自动扩缩容。以下是一个跨集群HPA配置示例:
apiVersion: autoscaling.kurator.dev/v1alpha1
kind: FederatedHPA
metadata:
name: frontend-hpa
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: frontend
minReplicas: 3
maxReplicas: 20
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
schedulerPolicy:
placement:
clusterNames:
- cluster-prod-1
- cluster-prod-2
该配置会根据CPU使用率在两个生产集群间动态分配Pod,实现真正的跨集群弹性能力。
4.4 多云负载均衡策略
在多云环境下,Kurator结合Karmada提供了智能的负载均衡策略。以下配置演示了如何根据集群能力分配工作负载:
apiVersion: scheduling.kurator.dev/v1alpha1
kind: WorkloadDistributionPolicy
meta
name: ai-workload-distribution
spec:
workloadSelector:
matchLabels:
app: ai-inference
distributionStrategy:
type: Weighted
weights:
cluster-gpu-1: 60
cluster-gpu-2: 40
fallbackStrategy:
type: Failover
targetClusters:
- cluster-gpu-3
这种策略确保AI推理工作负载优先分配到GPU资源充足的集群,当主集群资源不足时,自动切换到备用集群。
5. KubeEdge边缘计算能力整合
5.1 边缘计算架构挑战
在这里插入图片描述
边缘计算面临网络不稳定、资源受限、管理复杂等挑战。传统云原生架构在边缘场景中往往表现不佳,需要专门的边缘优化方案。Kurator通过集成KubeEdge,为边缘场景提供了完整的解决方案。
5.2 Kurator边缘云协同方案
Kurator的边缘云协同架构包含三个层次:云端控制平面、边缘管理平面和边缘节点。通过统一的API,用户可以在中心位置管理分布在全球的边缘节点,实现应用的边缘部署和数据同步。
5.3 边缘节点管理与应用分发
在Kurator中注册边缘集群与注册普通集群类似,但需要额外配置边缘特定参数:
apiVersion: edge.kurator.dev/v1alpha1
kind: EdgeCluster
meta
name: factory-edge-1
spec:
kubeconfigSecretRef:
name: factory-edge-1-kubeconfig
edgeNodeSelector:
matchLabels:
location: factory
syncPolicy:
mode: CloudToEdge
interval: 5m
该配置实现了从云端到边缘的单向同步,适合边缘设备资源有限的场景。
5.4 边缘到云的数据同步优化
对于需要将边缘数据同步到云端的场景,Kurator提供了优化的数据同步机制:
apiVersion: edge.kurator.dev/v1alpha1
kind: EdgeDataSync
metadata:
name: sensor-data-sync
spec:
source:
cluster: factory-edge-1
path: /data/sensors
destination:
cluster: cloud-central
path: /data/warehouse
syncMode: Differential
bandwidthLimit: 10Mbps
compression: true
通过差分同步和带宽限制,该配置在保证数据一致性的同时,最大限度减少网络带宽消耗,特别适合卫星链路等受限网络环境。
6. Volcano批处理调度优化

6.1 传统Kubernetes调度局限
标准Kubernetes调度器在面对AI/ML训练、大数据分析等批处理工作负载时,存在队列管理不足、抢占策略有限、拓扑感知能力弱等问题。Volcano作为CNCF孵化项目,专注于批处理和弹性工作负载调度,弥补了这些不足。
6.2 Volcano调度架构与优势
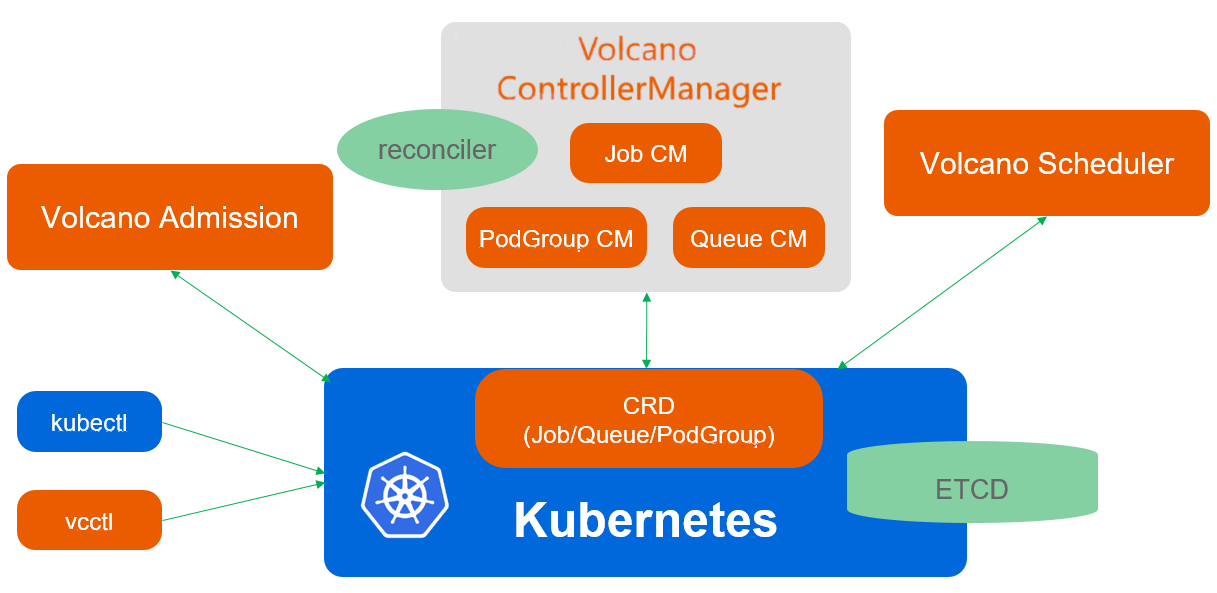
Volcano引入了队列、Pod组、抢占策略等高级调度概念。在Kurator中,Volcano被深度集成,提供统一的批处理调度API。其核心优势包括:高效的作业队列管理、支持Gang调度、多种抢占策略、拓扑感知调度等。
6.3 AI/ML工作负载调度实践
以下配置展示了如何在Kurator中为AI训练作业配置Volcano调度器:
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
meta
name: ai-training-job
spec:
minAvailable: 8
schedulerName: volcano
tasks:
- replicas: 8
name: worker
template:
spec:
containers:
- image: ai-training-image:latest
name: worker
resources:
limits:
nvidia.com/gpu: 1
volumeMounts:
- mountPath: /data
name: shared-data
volumes:
- name: shared-data
persistentVolumeClaim:
claimName: training-data-pvc
queue: high-priority
policies:
- event: PodEvicted
action: RestartJob
该配置确保所有训练Pod同时启动(Gang调度),并分配到具有GPU资源的节点,最大化训练效率。
6.4 资源利用率优化策略
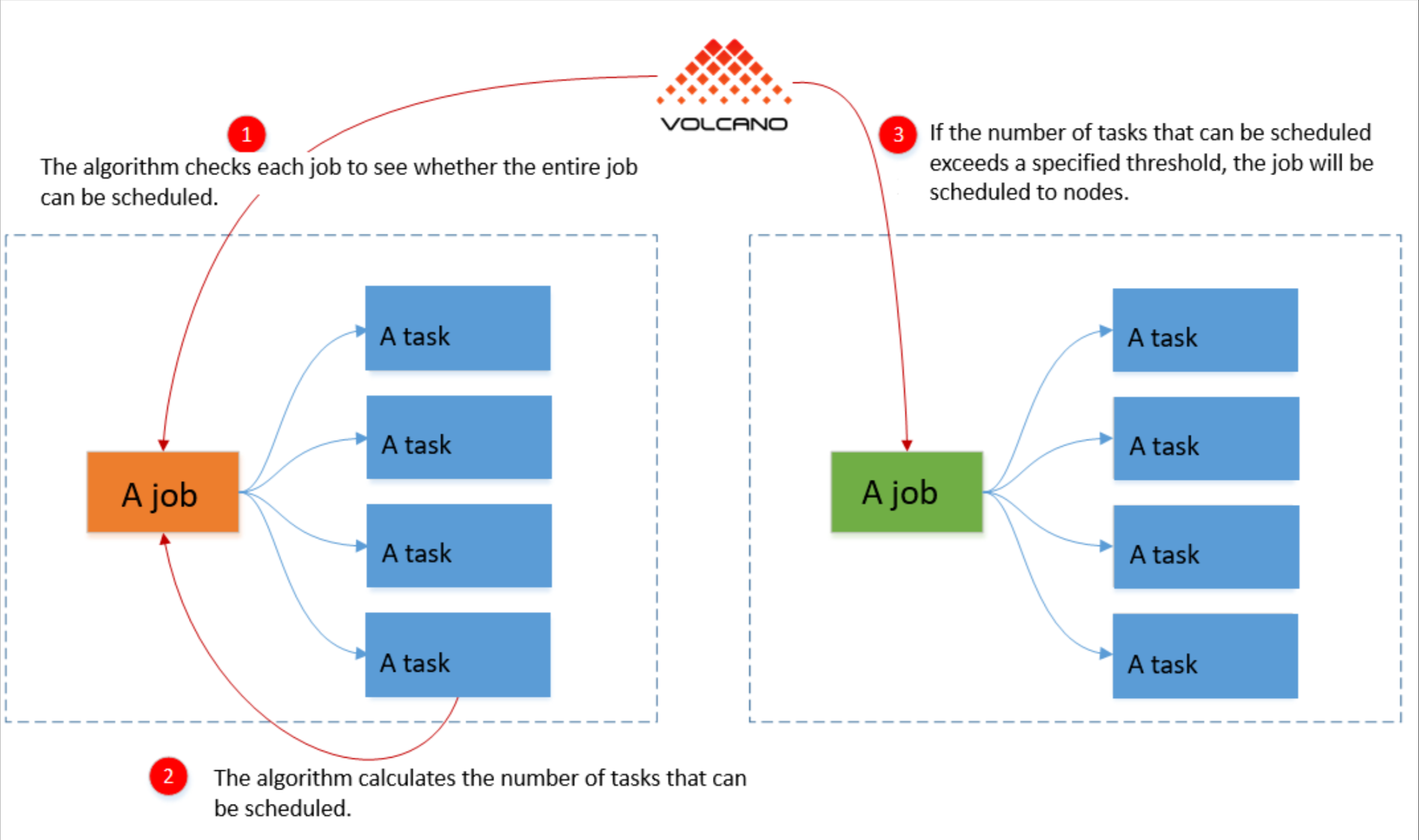
Volcano的资源优化能力在Kurator中得到了充分发挥。以下配置演示了如何实现混合工作负载的资源优化:
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
meta
name: production-queue
spec:
weight: 10
reclaimable: true
reservation:
hard:
cpu: "64"
memory: 256Gi
capability:
min:
cpu: "32"
memory: 128Gi
max:
cpu: "128"
memory: 512Gi
通过队列预留和弹性容量,该配置确保关键业务有稳定的资源保障,同时在资源空闲时可被其他工作负载临时使用,提高整体资源利用率。
7. GitOps与CI/CD流水线实践
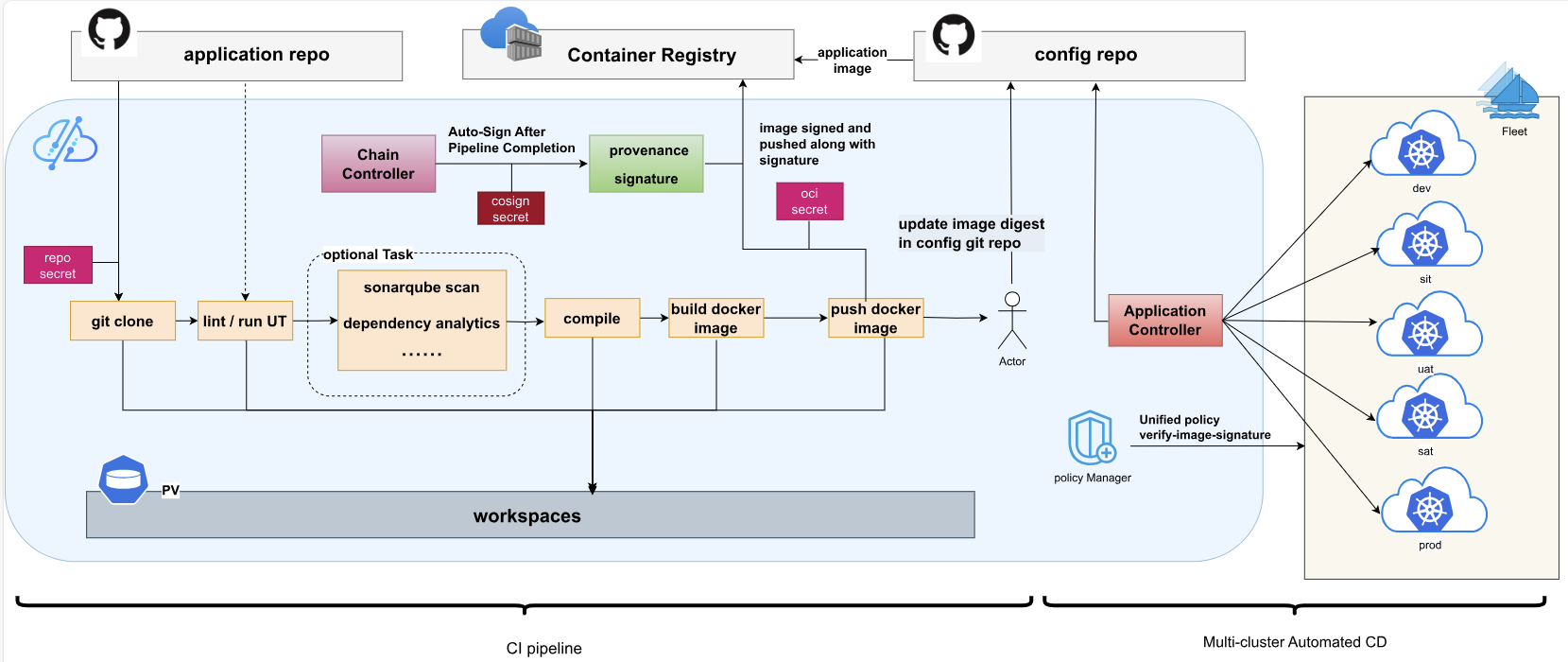
7.1 GitOps理念在Kurator中的实现
Kurator通过集成FluxCD实现了纯正的GitOps实践。在GitOps模式下,所有集群状态都通过Git仓库中的声明式配置进行定义和管理。Kurator扩展了这一理念,支持多集群环境下的GitOps,实现"一个仓库,多集群同步"。
7.2 FluxCD集成与应用同步
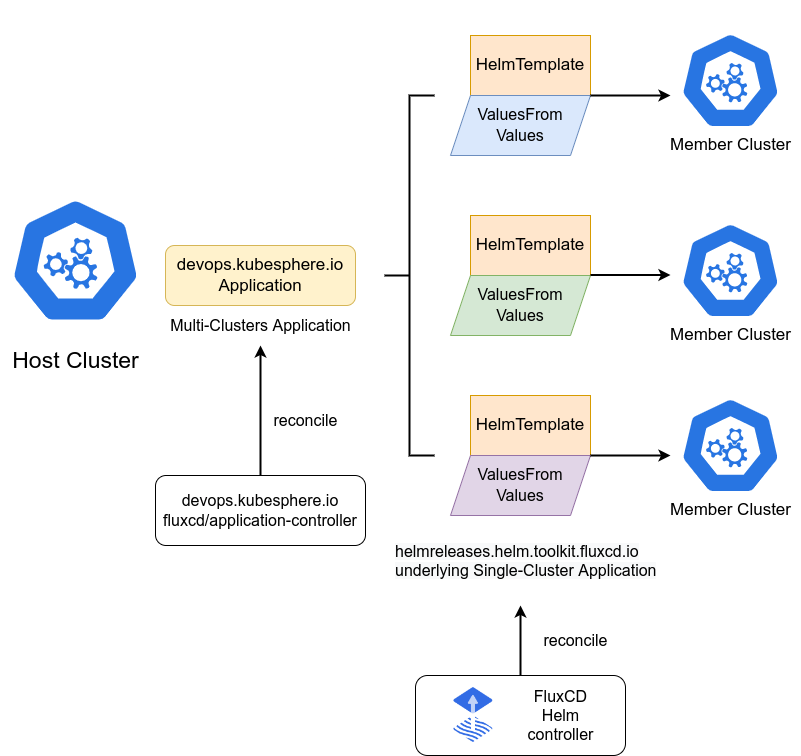
以下配置展示了如何在Kurator中设置FluxCD进行多集群应用同步:
apiVersion: gitops.kurator.dev/v1alpha1
kind: GitRepository
meta
name: application-repo
spec:
url: https://github.com/organization/application-manifests
ref:
branch: main
secretRef:
name: git-credentials
---
apiVersion: gitops.kurator.dev/v1alpha1
kind: Kustomization
meta
name: production-apps
spec:
gitRepositoryRef:
name: application-repo
namespace: kurator-system
path: "./environments/production"
prune: true
validation: client
timeout: 2m
fleetSelector:
matchLabels:
environment: production
该配置会自动将Git仓库中生产环境的配置同步到所有标记为"production"的集群,实现配置的一致性。
7.3 多环境部署策略配置
Kurator支持复杂的多环境部署策略,包括金丝雀发布和蓝绿发布。以下是一个金丝雀发布配置示例:
apiVersion: traffic.kurator.dev/v1alpha1
kind: CanaryRelease
meta
name: frontend-canary
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: frontend
fleetSelector:
matchLabels:
environment: production
steps:
- weight: 10
pause: 1h
metrics:
- name: error-rate
threshold: 0.1%
interval: 5m
- weight: 50
pause: 2h
- weight: 100
该配置逐步将流量从旧版本转移到新版本,并在每个阶段监控错误率,确保发布过程的安全性。
8. Kurator未来发展方向

8.1 开源生态建设
Kurator将继续深化与CNCF项目生态的集成,特别是与新兴的边缘计算、服务网格和安全项目合作。我们计划建立更完善的插件体系,允许社区贡献者轻松集成新的云原生组件,打造开放、可扩展的分布式云原生平台。
8.2 企业级特性增强
针对企业用户需求,Kurator将重点增强以下企业级特性:多租户支持与资源配额管理、审计日志与合规性报告、灾难恢复与备份策略、细粒度的RBAC控制。这些特性将使Kurator更好地满足金融、医疗等高度监管行业的需求。
8.3 社区贡献与协作模式
Kurator采用开放的社区治理模式,鼓励多样化贡献。我们正在完善贡献者阶梯计划,从文档改进到核心代码贡献,为不同技能水平的参与者提供清晰的成长路径。同时,建立更高效的issue triage和PR review机制,加速社区协作创新。
8.4 分布式云原生技术趋势
展望未来,分布式云原生将朝着更智能化、自动化、安全化的方向发展。Kurator将探索AI驱动的资源优化、零信任安全架构、跨云服务网格等前沿领域,帮助企业构建真正弹性的分布式应用。我们相信,通过社区共同努力,Kurator将成为连接云、边缘和终端的分布式云原生基础设施的核心枢纽。
结语
Kurator作为分布式云原生平台,不仅整合了Kubernetes生态的优秀开源项目,更通过创新的架构设计和统一的API抽象,为企业提供了构建分布式云原生基础设施的完整解决方案。从多集群管理到边缘计算,从批处理调度到GitOps实践,Kurator展现了分布式云原生的强大潜力。随着技术的不断演进和社区的持续贡献,Kurator将继续引领分布式云原生的发展方向,助力企业实现真正的数字化转型。作为云原生技术从业者,我们应当积极拥抱这一变革,深入理解其原理,勇于实践创新,共同推动云原生技术生态的繁荣发展。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 19
19 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)