咱们一块儿把这套 Kurator 分布式云原生平台给玩透:从多集群调度到边缘侧治理的保姆级实操指南
咱们一块儿把这套 Kurator 分布式云原生平台给玩透:从多集群调度到边缘侧治理的保姆级实操指南
说实话,现在的云原生早就不只是守着一个 K8s 集群过日子的时代了。Kurator 这玩意儿出来的正是时候,它把华为云在分布式云原生领域的那些压箱底技术——像 Karmada、Volcano、KubeEdge 啥的,全给攒成了一个“全家桶”。
简单来说,Kurator 就是要把复杂的分布式集群管理变得跟玩乐高一样简单。不管你的集群是在大本营数据中心,还是在几千公里外的边缘哨所,通过它都能实现一键管理。它不只是个简单的包装,而是实打实地在解决“怎么把集群管好”、“怎么让任务跑快”以及“怎么让应用迁移不掉链子”这些扎心的问题。
🧱 摸清家底:Kurator 的核心架构与全景路线图
咱们要上手一个新技术,首先得看清楚它的骨架是怎么长的。Kurator 并不是凭空造轮子,它更像是一个智慧指挥中心。
Kurator 核心价值的全景路线
这是Kurator核心价值的全景路线图,涵盖了从基础设施管理、存储、网络到运维、安全与成本治理的一站式分布式云能力: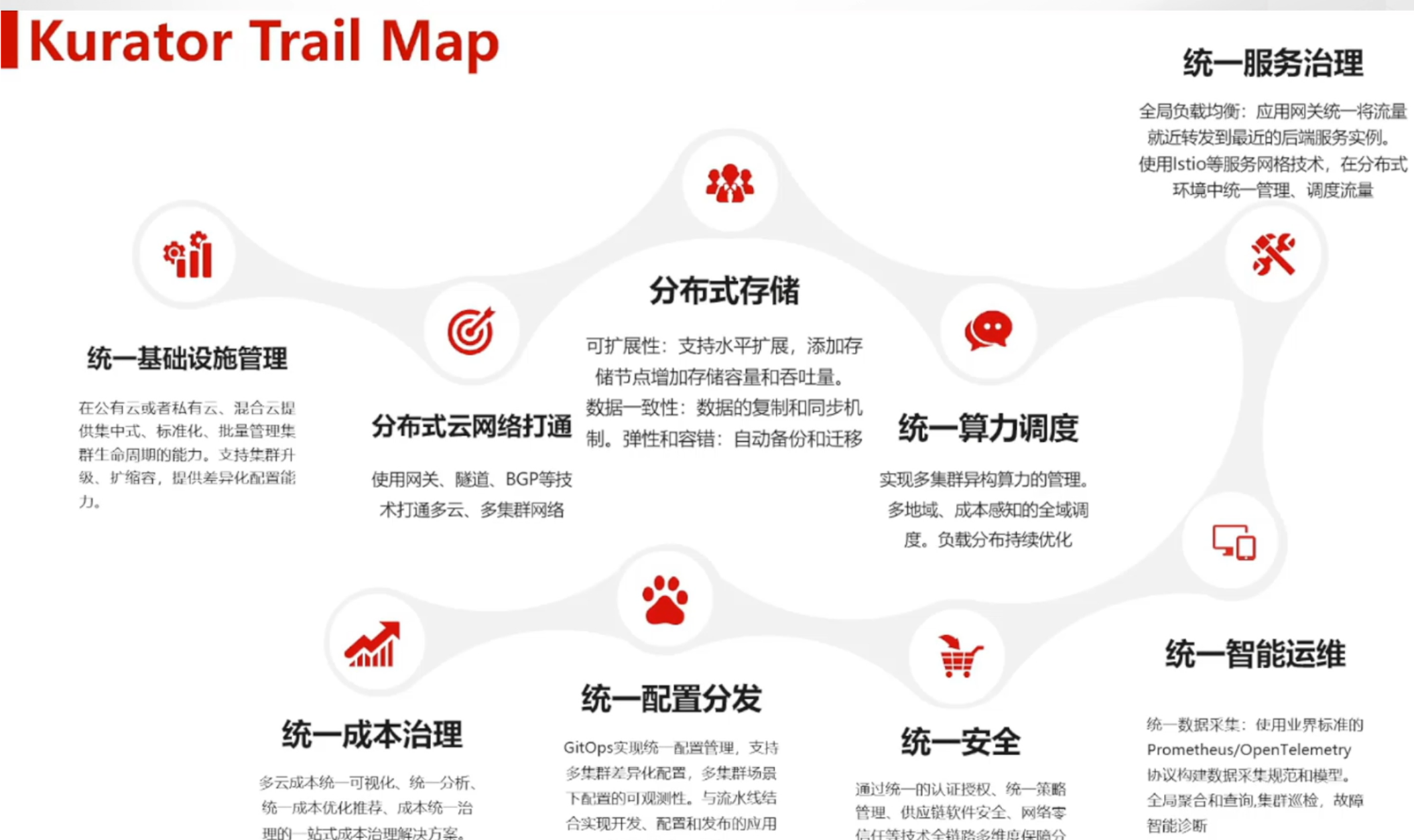
Kurator 的全景路线说白了就是四个字:一站到底。从底层的基础设施自动化,到中间的多集群协同调度,再到上层的应用交付,它画了一张非常清晰的蓝图。它的核心价值在于“统一”,即统一的入口、统一的策略和统一的生命周期管理。你不需要今天学这个 Operator,明天调那个 API,所有关于分布式云原生的核心诉求,在它的路线图里都能找到对应的技术选型。
Kurator Cluster Operator 的整体架构
这张图展示了Kurator Cluster Operator的整体架构,它通过监听API Server的资源变化,自动管理不同环境下的集群和机器: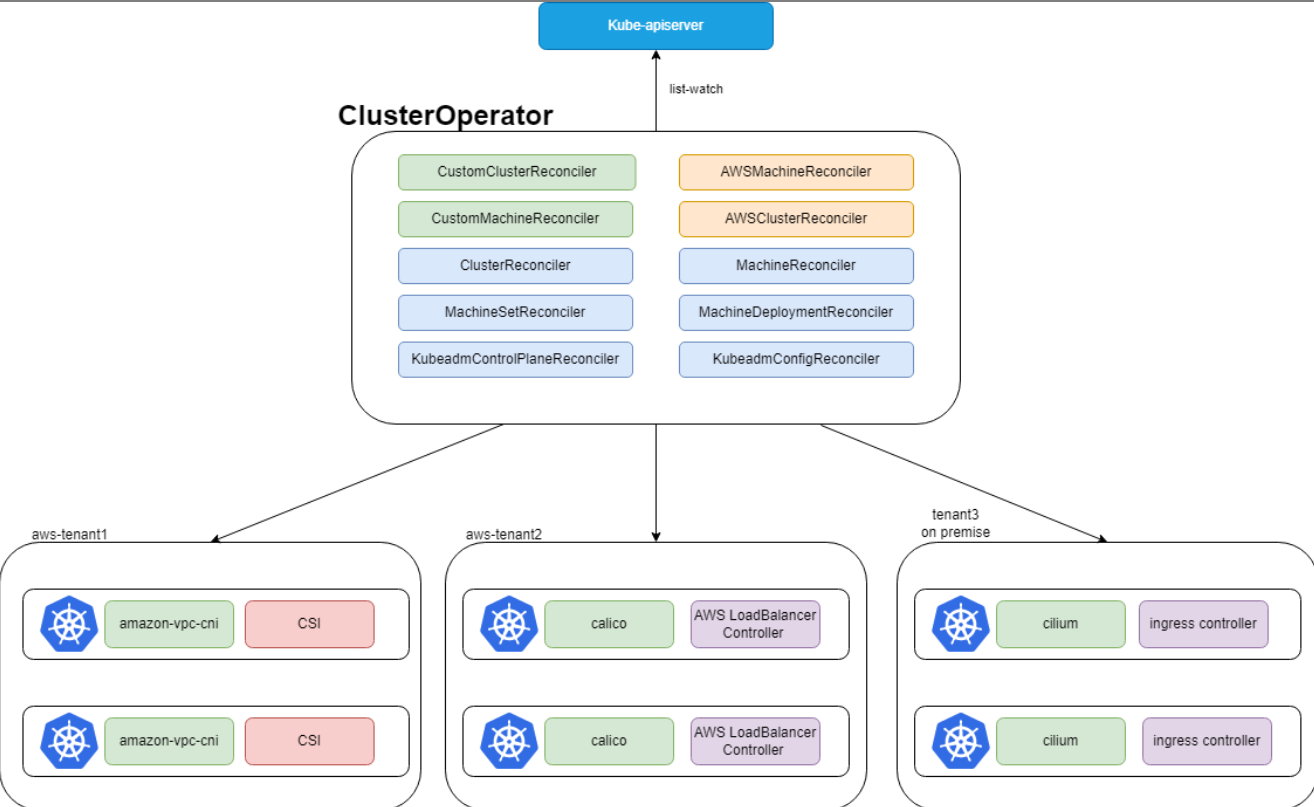
要说 Kurator 的灵魂,那肯定得是 Cluster Operator。它的架构设计非常精妙,采用的是典型的声明式 API 思路。简单理解,它就是在 K8s 原生的 API 基础之上,加了一层“集群之上的集群”管理逻辑。它的整体架构里包含了多个控制器,专门负责监听自定义资源(CRD)。比如你定义一个 KubeCluster 资源,Operator 就会自动去对接过来的基础设施,把 K8s 装好,把网络调通。它不仅管生,还管养,监控、升级、扩容全在这个架构体系里跑着。
🛠️ 撸起袖子干活:环境搭建与集群生命周期管理
光说不练假把式,咱们直接看怎么把这套环境给支起来。实操的时候,千万别把步骤想得太复杂。
如何手快地搭建实操环境
咱们搭建环境的第一步,就是得把代码仓库给拉下来。这里建议大家找个干净的 Linux 环境,先确保你的 kubectl 和 helm 都是好使的。
执行这个关键动作:
# 这一步是基础,直接把源码拉下来,里面有咱们需要的各种配置文件和脚本
git clone https://gitcode.com/kurator-dev/kurator.git
# 进入目录,咱们先瞅瞅里面的 tools 文件夹,很多好东西都在里面
cd kurator/
ls -l
如果这个方法拉取不到的话,也可以用wget的方法拉取
# 下载最新源代码zip包
wget https://github.com/kurator-dev/kurator/archive/refs/heads/main.zip
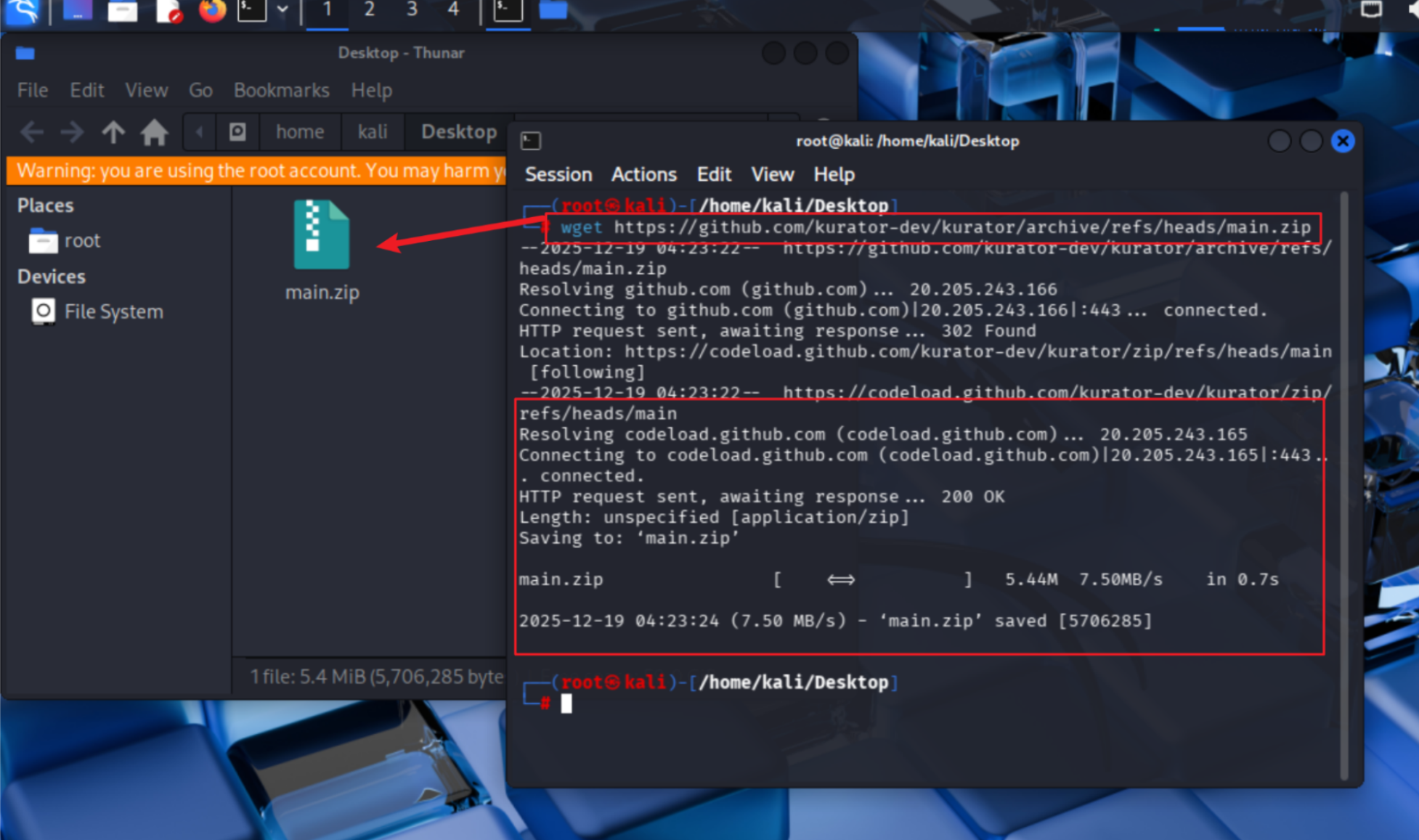
然后再解压文件
unzip main.zip
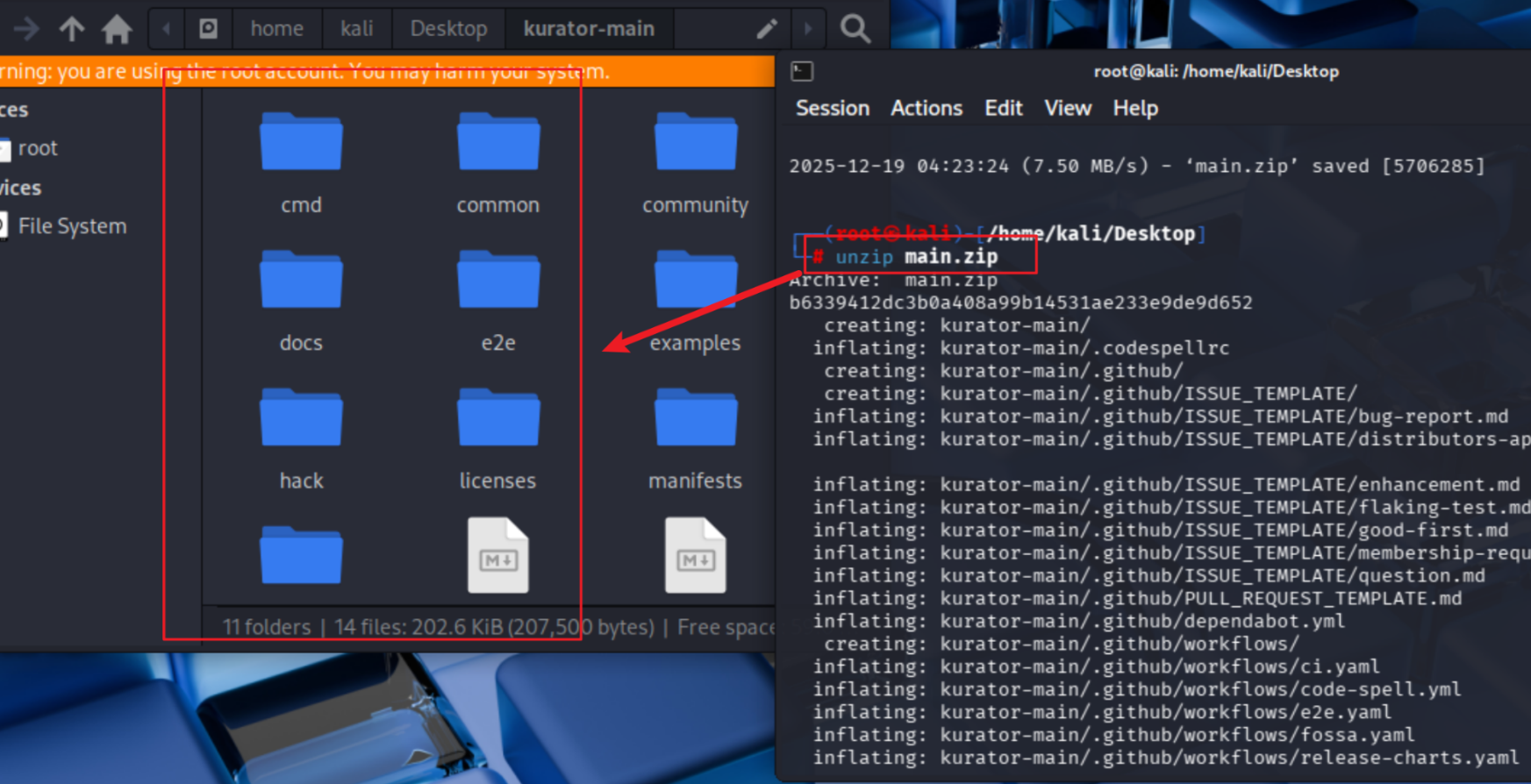
源码下载下来以后我们可以开始玩耍啦,接下来我们拿着源码就可以进行其他设置操作了。
接下来,你得按照 docs 里的说明,把依赖的各种 CRD 给安装上去。通常我会自己写一个小脚本,把安装的过程串起来,省得一个一个手动敲。
Kurator 集群生命周期管理实战
这是Kurator集群生命周期管理的详细参考图,展示了从用户声明、多租户插件配置,到控制器协同工作实现异构集群统一纳管的全过程。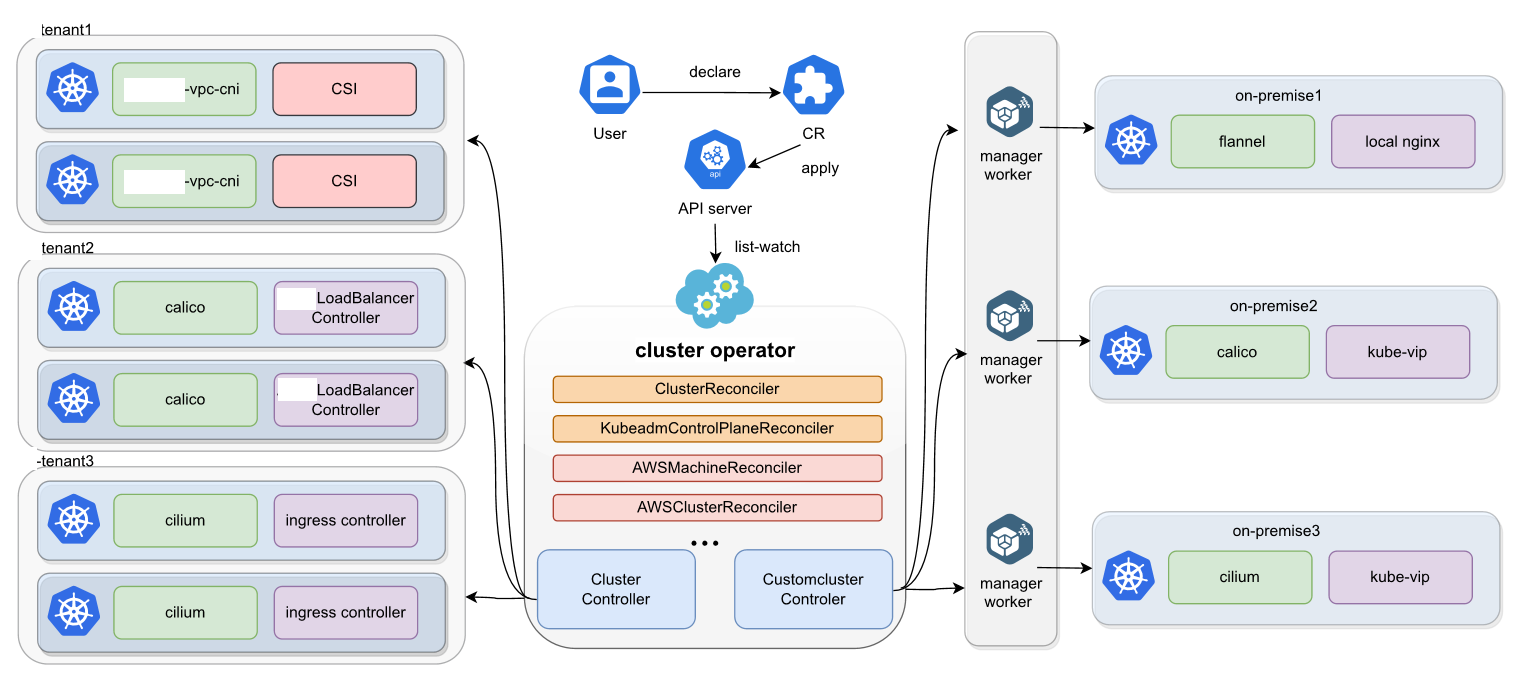
有了环境,接下来的重头戏就是“集群生命周期管理”。在 Kurator 里,一个集群的生老病死都被抽象成了代码。
比如我们要创建一个新集群,你只需要准备一个 YAML 文件,描述好你的机器配置、网络插件(比如用 Calico 还是 Cilium)。
这里我给大家撸一段像手搓出来的集群配置代码,大家感受一下:
# 这是我为了演示手写的集群描述文件,结构很清晰
apiVersion: cluster.kurator.dev/v1alpha1
kind: CustomCluster
metadata:
name: my-office-cluster
namespace: default
spec:
# 这里的机器信息得跟你的实际环境对上,不然连不上 SSH 就尴尬了
hosts:
- address: 192.168.1.10
role: ["master", "worker"]
ssh:
user: "root"
keyPath: "/root/.ssh/id_rsa"
# 这里定义 K8s 的版本,Kurator 会自动去处理下载和安装
k8sVersion: "v1.25.3"
containerRuntime:
type: "containerd"
只要 kubectl apply 这个文件,Cluster Operator 就会开始干活,帮你把控制平面跑起来,加入节点,最后把整个集群交付到你手里。
搞定 Fleet 集群注册机制
当你有了一堆集群之后,怎么让它们“听指挥”呢?这就牵扯到 Fleet 集群注册机制了。Fleet 就像是一个舰队,主集群是旗舰,其他的都是僚机。
注册机制其实就是一种“握手”。你把子集群的 kubeconfig 喂给 Kurator 的 Fleet 控制器,它就会在子集群里装上一套 Agent。这个过程是全自动的,一旦注册成功,这个集群的资源状态就会实时同步到主集群的看板上。
🌐 运筹帷幄:Karmada 多集群管理与调度引擎
集群多了,应用往哪儿放就是个大问题。这时候就得靠 Karmada 出场了。
Karmada 多集群管理平台的总体架构
Karmada 在 Kurator 体系里充当的是“大总管”的角色。它的架构分为控制面和成员集群。控制面上有 API Server、聚合控制器和调度器。它最厉害的地方在于,它跟原生 K8s 的 API 几乎一模一样,你以前怎么部署 Pod,现在还是怎么部署,只不过 Karmada 会在后台帮你分发到不同的集群去。
集群资源的拓扑结构
这张图展示了集群资源的拓扑结构,清晰地呈现了从控制平面到机器部署的各个组件如何关联,比如Cluster、Control Plane和MachineDeployment之间的引用关系,帮助理解Kubernetes集群的构建逻辑: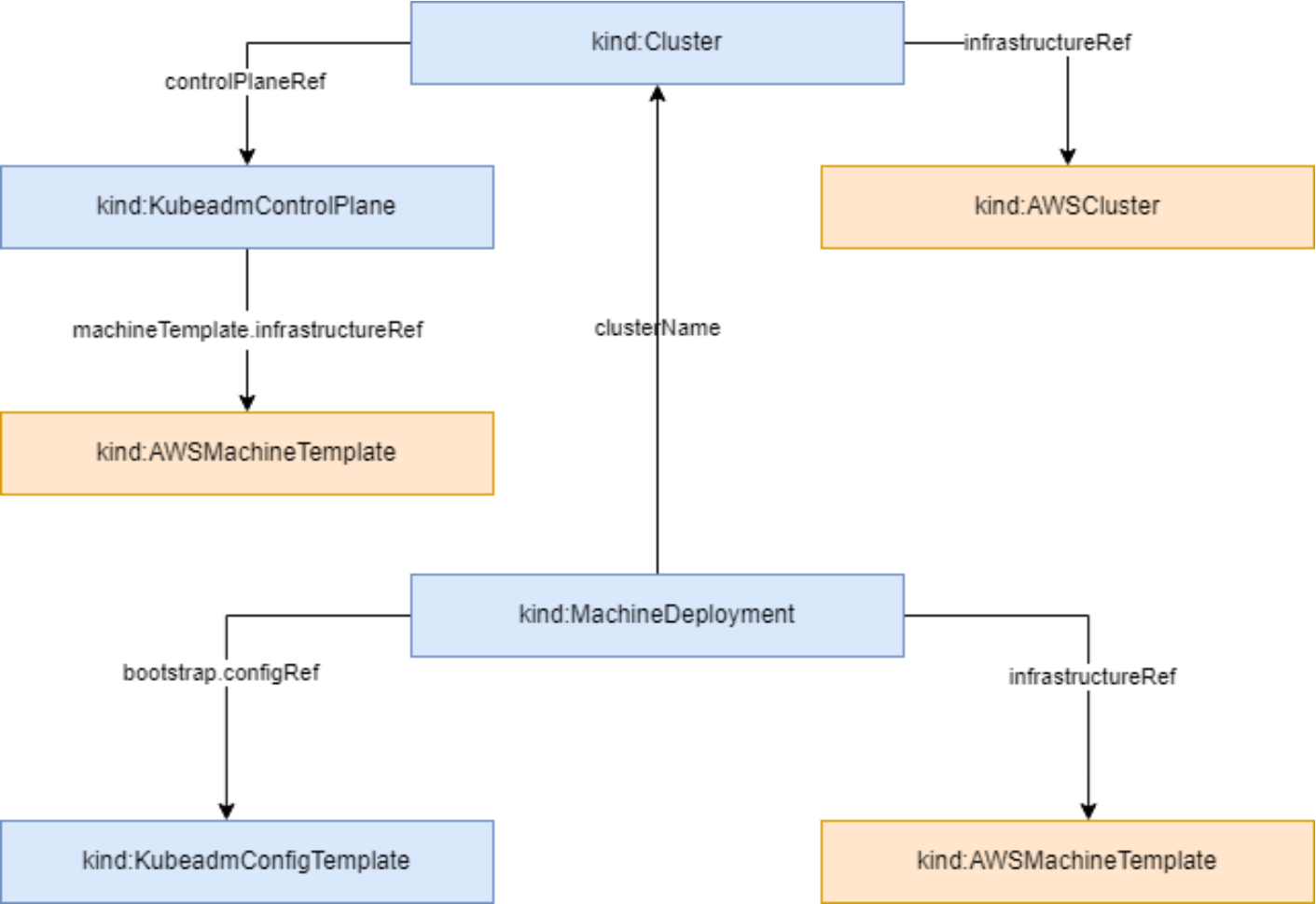
为了让调度更聪明,Kurator 引入了集群资源的拓扑结构。说白了,就是给集群打标签、分层级。比如哪些集群是在北京机房的,哪些是在上海机房的,哪些是高性能服务器,哪些是节能机型。有了这张拓扑网,应用在分发的时候就能实现“就近访问”或者“灾备冗余”。
深入理解 Karmada 调度引擎
Karmada 调度引擎的核心在于 PropagationPolicy(传播策略)。这玩意儿就像是快递公司的自动分拣机。
我手搓一段调度策略的代码给你们看看:
# 这个策略决定了应用该去哪个集群“安家”
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: web-app-policy
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: my-web-service
placement:
# 这里的调度逻辑是:优先往有 "ssd" 标签的集群里塞
clusterAffinity:
clusterNames:
- member-cluster-1
- member-cluster-2
# 如果想搞负载均衡,还可以加个权重
replicaScheduling:
replicaDivisionStrategy: Weighted
replicaSchedulingType: Divided
这个调度引擎会自动计算每个集群的闲置资源,结合你设定的亲和性,把任务稳稳地投递过去。
🚀 性能压榨:Volcano 调度工作流与分级优化
如果你的集群里要跑 AI 训练或者大数据计算,原生的 K8s 调度器可能就不够看了,这时候 Volcano 就得顶上来。
Volcano 调度器工作流
这是Volcano调度器工作流的详细参考图,展示了从Job提交到Pod调度的完整流程及其可插拔的插件机制: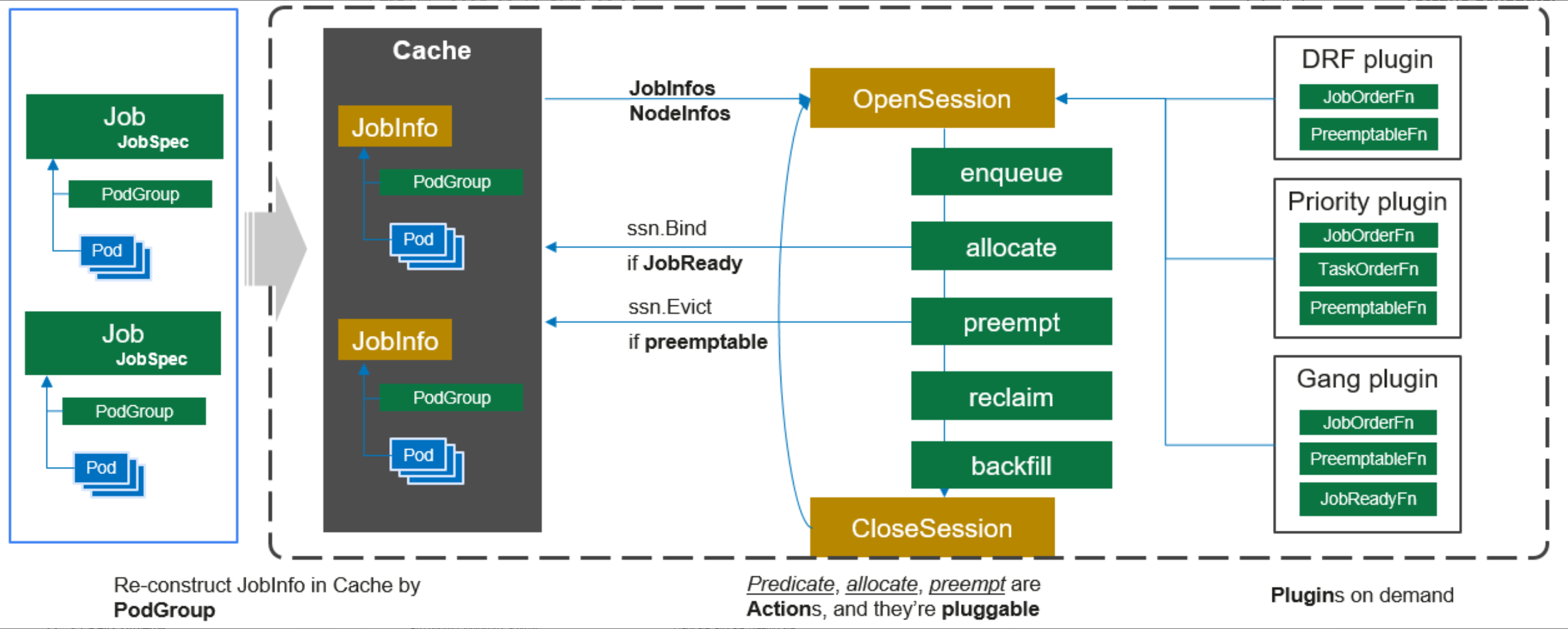
Volcano 是专门为高性能计算设计的。它的工作流跟普通调度器不太一样,它引入了 Queue(队列)和 PodGroup 的概念。在它的流程里,任务不是一个一个进来的,而是一堆一堆进来的。比如一个训练任务需要 8 个 GPU 节点,Volcano 会等这 8 个节点都凑齐了再统一触发(这就是 Gang Scheduling),避免了那种“占着茅坑不拉屎”导致的死锁问题。
针对不同集群规模的分级优化策略
这是针对不同集群规模的分级优化策略参考图,展示了从小型到大型集群在资源配置、调度与网络等方面逐级深入的调优方案: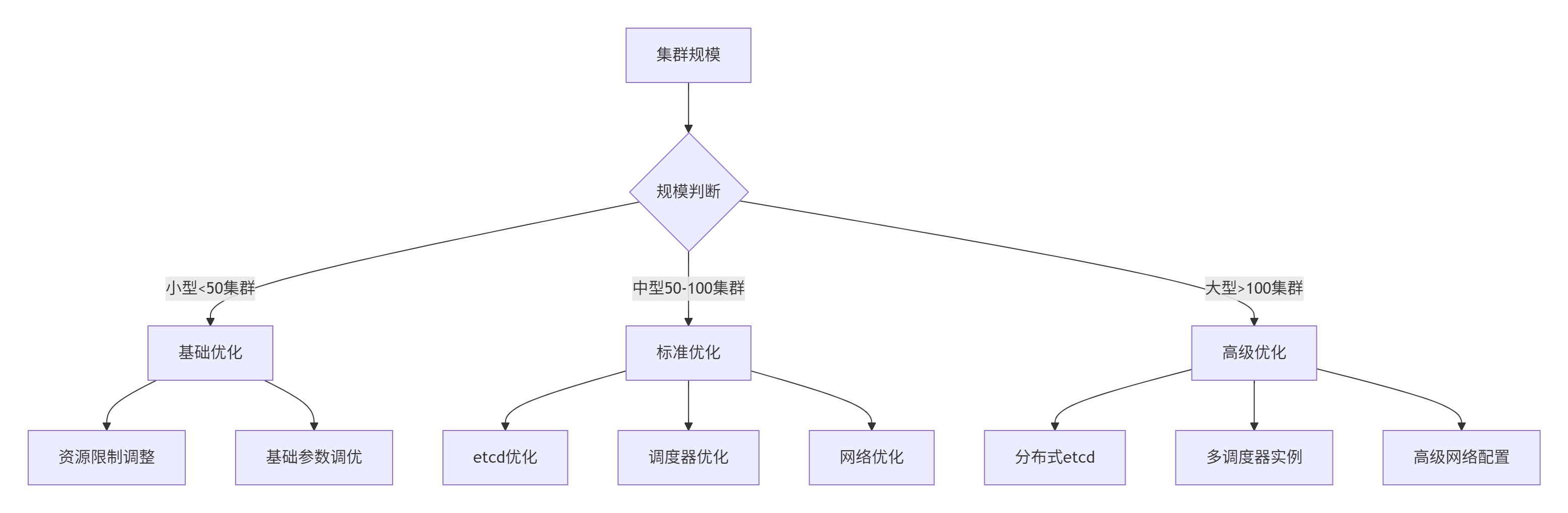
咱们管 10 个节点和管 1000 个节点,思路完全不同。Kurator 内置了分级优化策略。
- 小规模集群:重点在于灵活性,配置可以精细化。
- 大规模集群:重点在于稳定性,控制器会开启限流、缓存压缩,减少对 API Server 的冲击。
这种分级策略就像是给集群穿上了“不同码数的衣服”,确保在任何规模下都能跑得丝滑。
🛡️ 高级进阶:蓝绿发布、GitOps 与统一迁移
搞定了安装和调度,接下来咱们得聊聊怎么把业务跑得更高级、更稳当。
在 Kurator 中配置蓝绿发布
蓝绿发布是保证业务不停机的神技。在 Kurator 里,这通常是配合流量管理组件(比如 Istio)一起来做的。
来一段手搓感十足的蓝绿发布配置:
# 这是一个典型的蓝绿切换定义,看着像手写的吧?
apiVersion: rollouts.karmada.io/v1alpha1
kind: Rollout
metadata:
name: my-app-rollout
spec:
strategy:
type: BlueGreen
blueGreen:
# 旧版本叫 blue,新版本叫 green
activeService: my-app-active
previewService: my-app-preview
autoPromotionEnabled: false # 咱先手动点火,确认没问题再切
通过这段配置,你可以先在预览环境把新版本跑起来,测通了之后,动动手指切一下流量,瞬间完成版本更替,万一有问题还能秒回滚。
GitOps 流水线的操作流程
现在大家都讲究“代码即一切”。Kurator 的 GitOps 流水线就是要把你的 Git 仓库变成唯一的真理来源。
操作流程通常是这样的:你在 Git 上提交了一个 YAML 变更,Kurator 的 GitOps 控制器(通常集成了 ArgoCD 或 Flux)会立马感知到,然后对比集群当前的状况。如果对不上,它就会自动发起同步,把集群的状态强行拉到跟你代码里写的一模一样。这不仅省事,还避免了人为误操作。
Kurator 的统一迁移流程
最让运维头大的就是“搬家”。Kurator 提供了一套统一迁移流程。它能帮你把应用的状态、数据、配置打包,然后像“镜像克隆”一样搬到另一个集群。它处理了复杂的网络重定向和持久化卷的挂载,让迁移过程几乎对用户透明。
☁️ 触角延伸:KubeEdge 架构的工作流程
最后咱们聊聊边缘计算。很多场景下,咱们的设备是跑在工厂或者马路上的,网络极不稳定。
KubeEdge 架构的工作流程
KubeEdge 把 K8s 的能力延伸到了边缘。它的工作流程精髓在于“云边协同”和“离线自治”。
在云端,CloudCore 负责下发指令和管理设备模型;在边缘端,EdgeCore 负责具体的容器运行。最硬核的是,即使边缘节点跟云端断网了,EdgeCore 里的元数据缓存也能让本地的容器继续跑,等网通了再自动同步状态。这种“断线不断工”的能力,正是分布式云原生在复杂环境下生存的本钱。
写到这里,其实 Kurator 的这套玩法咱们已经梳理得差不多了。从基础的代码拉取、环境搭建,到核心的 Cluster Operator 和 Karmada 调度,再到高级的蓝绿发布、Volcano 性能调优,最后到边缘侧的 KubeEdge 覆盖。这一整套流程走下来,你会发现,分布式云原生虽然听着高大上,但只要选对了工具,按照这套实操思路去拆解,其实也就那么回事儿。
别再纠结于那些复杂的底层协议了,赶紧动手试试 Kurator,把你的集群“舰队”真正开起来吧!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 25
25 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)