【前瞻创想】Kurator分布式云原生平台实战:构建多云、边缘协同的现代化基础设施
【前瞻创想】Kurator分布式云原生平台实战:构建多云、边缘协同的现代化基础设施
【前瞻创想】Kurator分布式云原生平台实战:构建多云、边缘协同的现代化基础设施
摘要
在当今分布式计算时代,企业面临着多云、混合云和边缘计算的复杂挑战。Kurator作为一款开源的分布式云原生平台,通过整合Kubernetes、Istio、Prometheus、FluxCD、KubeEdge、Volcano、Karmada、Kyverno等优秀开源项目,为企业提供了一站式解决方案。本文深入探讨Kurator的核心架构与创新优势,从环境搭建到多集群管理,从边缘计算集成到批处理调度优化,通过丰富的实战案例和深度技术剖析,帮助读者掌握如何利用Kurator构建统一、高效、弹性的云原生基础设施,加速企业数字化转型进程。
1. Kurator平台概述与核心价值
1.1 分布式云原生时代的挑战与机遇
随着企业数字化转型的深入,传统的单集群Kubernetes架构已无法满足日益复杂的业务需求。多云部署、边缘计算、混合云架构成为新常态,但同时也带来了运维复杂性高、资源利用率低、应用一致性难保证等挑战。Kurator应运而生,通过整合业界领先的开源项目,构建了一个统一的分布式云原生平台,让企业能够专注于业务创新而非基础设施管理。
Kurator的核心价值在于"统一"二字:统一资源编排、统一调度策略、统一流量管理、统一监控告警、统一安全策略。这种统一不是简单的功能堆砌,而是通过深度整合各组件,形成协同效应,实现1+1>2的效果。例如,在多集群场景下,Kurator不仅提供了集群注册和管理能力,更实现了跨集群的服务发现、身份认证和策略同步,大大简化了多云架构的复杂性。
1.2 Kurator技术架构全景图
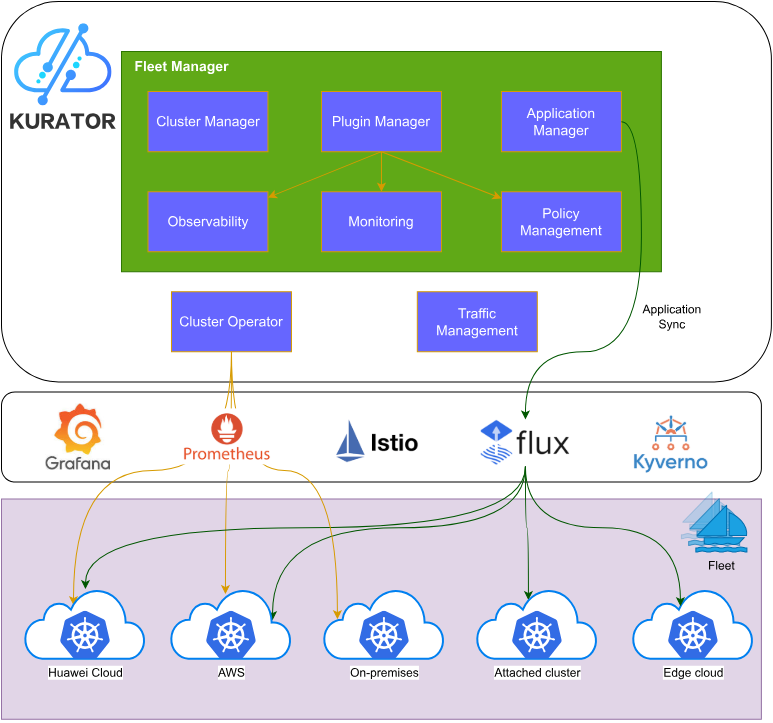
Kurator站在众多优秀开源项目的肩膀上,构建了一个层次分明、功能完备的技术栈。底层是基础设施层,支持公有云、私有云、边缘节点等多种环境;中间是核心平台层,包括Karmada负责多集群管理、KubeEdge处理边缘计算、Volcano优化批处理调度、Istio提供服务网格能力;上层是运维管理层,通过FluxCD实现GitOps、通过Prometheus实现统一监控、通过Kyverno实现策略管理。
# Kurator架构组件关系示例
apiVersion: kurator.dev/v1alpha1
kind: ClusterFleet
metadata:
name: production-fleet
spec:
clusters:
- name: cloud-cluster-1
kubeconfigSecret: cloud-cluster-1-kubeconfig
roles: [cloud]
- name: edge-cluster-1
kubeconfigSecret: edge-cluster-1-kubeconfig
roles: [edge]
policies:
scheduling:
strategy: Spread
security:
enforce: true
这种架构设计充分体现了"基础设施即代码"的理念,所有配置都可通过声明式API进行管理,确保了环境的一致性和可复现性。同时,Kurator采用了松耦合的微服务架构,各组件可独立升级和扩展,保证了系统的灵活性和可维护性。
1.3 Kurator与传统云原生方案对比优势
相比传统的云原生解决方案,Kurator具有显著优势。传统方案通常需要企业自行集成多个开源项目,不仅技术门槛高,而且各组件间的协同性差,容易形成"烟囱式"架构。Kurator则提供了开箱即用的集成体验,通过统一的控制平面和API,大大降低了使用门槛。
此外,Kurator特别注重实际生产环境中的痛点解决。例如,在边缘计算场景下,传统方案往往难以处理网络不稳定、资源受限等问题,而Kurator通过集成KubeEdge,提供了边缘自治、消息可靠传输、设备管理等能力;在AI/大数据工作负载场景下,传统Kubernetes调度器难以满足复杂调度需求,Kurator通过Volcano提供了队列管理、抢占调度、拓扑感知等高级功能。
Kurator的另一个独特优势是其社区驱动的开发模式。作为CNCF生态系统的重要成员,Kurator积极与各开源项目社区合作,确保技术的前瞻性和兼容性。这种开放合作的模式,使得Kurator能够快速响应市场需求,持续创新。
2. 环境搭建与Kurator安装实践
2.1 前置条件与环境准备
在安装Kurator之前,需要确保满足以下前置条件:一个可用的Kubernetes集群(版本1.20+)、足够的计算资源(建议至少4核8G内存)、kubectl命令行工具、helm包管理器,以及网络访问权限。对于生产环境,还需要考虑高可用架构、持久化存储、证书管理等高级配置。
环境准备阶段,建议使用云厂商提供的托管Kubernetes服务(如EKS、ACK、GKE等)或自建高可用集群。同时,需要规划好网络架构,确保各组件间的网络连通性,特别是边缘节点与中心集群之间的通信。安全方面,应配置RBAC权限、网络策略和TLS加密,确保系统安全性。
# 检查环境依赖
kubectl version --client --short
helm version --short
docker --version
2.2 Kurator源码获取与安装流程
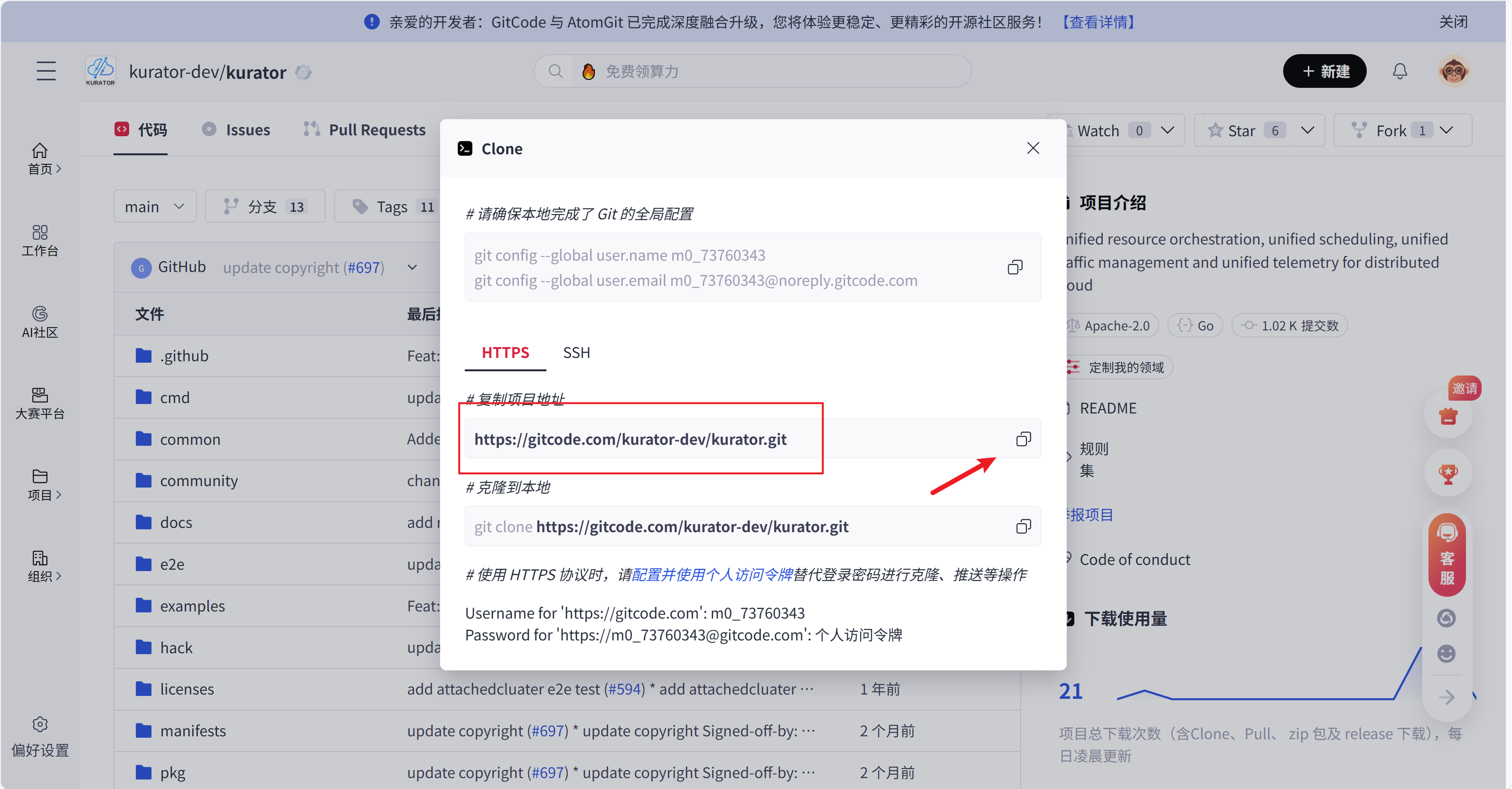
Kurator的安装非常简便,可以通过源码或Helm Chart两种方式。源码安装提供了最大的灵活性和可定制性,适合开发者和高级用户。以下是使用git clone命令获取源码的标准流程:
在项目地址中,可以看到可以clone到本地
https://gitcode.com/kurator-dev/kurator.git
或者我们也可以下载到本地
可以看到我们资源文件已经下载下来了
安装过程中,Kurator会自动检测环境并配置相应的组件。对于生产环境,建议使用Helm Chart安装,可以通过values.yaml文件自定义配置参数,如镜像仓库、资源限制、网络设置等。安装完成后,可以通过kubectl get pods -n kurator-system命令验证各组件运行状态。
2.3 多集群环境配置与验证
Kurator的核心价值在于多集群管理,因此安装完成后需要配置多个集群。首先,需要准备各个集群的kubeconfig文件,然后通过Kurator CLI或API进行集群注册。注册过程包括集群元数据采集、证书交换、网络连通性测试等步骤。
# 注册新集群到Kurator fleet
kurator fleet register --name=cluster-east-1 \
--kubeconfig=/path/to/cluster-east-1.kubeconfig \
--role=cloud
kurator fleet register --name=edge-node-1 \
--kubeconfig=/path/to/edge-node-1.kubeconfig \
--role=edge
配置完成后,需要进行全面验证,包括:跨集群服务发现测试、应用部署同步验证、监控指标聚合检查、策略同步一致性验证等。可以使用Kurator提供的诊断工具kurator diagnose进行自动化检查,或者通过自定义脚本进行深度验证。对于边缘场景,还需要特别关注离线工作能力、数据同步延迟等指标。
3. Fleet多集群管理深度实践
3.1 Fleet架构与核心概念解析
Fleet架构官方参考图: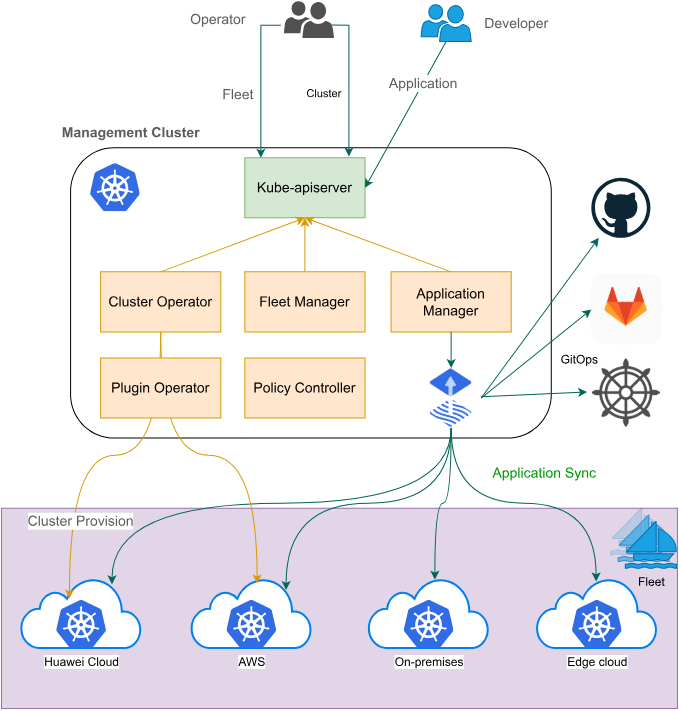
Fleet是Kurator多集群管理的核心组件,它抽象了多集群操作的复杂性,提供了统一的管理界面。Fleet的核心概念包括:集群组(ClusterGroup)、策略(Policy)、同步规则(SyncRule)、资源拓扑(ResourceTopology)。集群组是逻辑上的集群集合,可以根据地域、环境、业务等维度进行划分;策略定义了跨集群的统一规则,如安全策略、调度策略、监控策略;同步规则控制资源配置的同步行为;资源拓扑描述了资源在多集群间的分布关系。
Fleet采用控制器模式实现,通过监视自定义资源的变化,自动触发相应的操作。例如,当创建一个新的SyncRule时,Fleet控制器会解析规则内容,生成相应的Kubernetes资源,并分发到目标集群。这种设计保证了声明式API的最终一致性,即使在网络分区或集群故障的情况下,也能保证配置的正确同步。
3.2 跨集群服务相同性实现
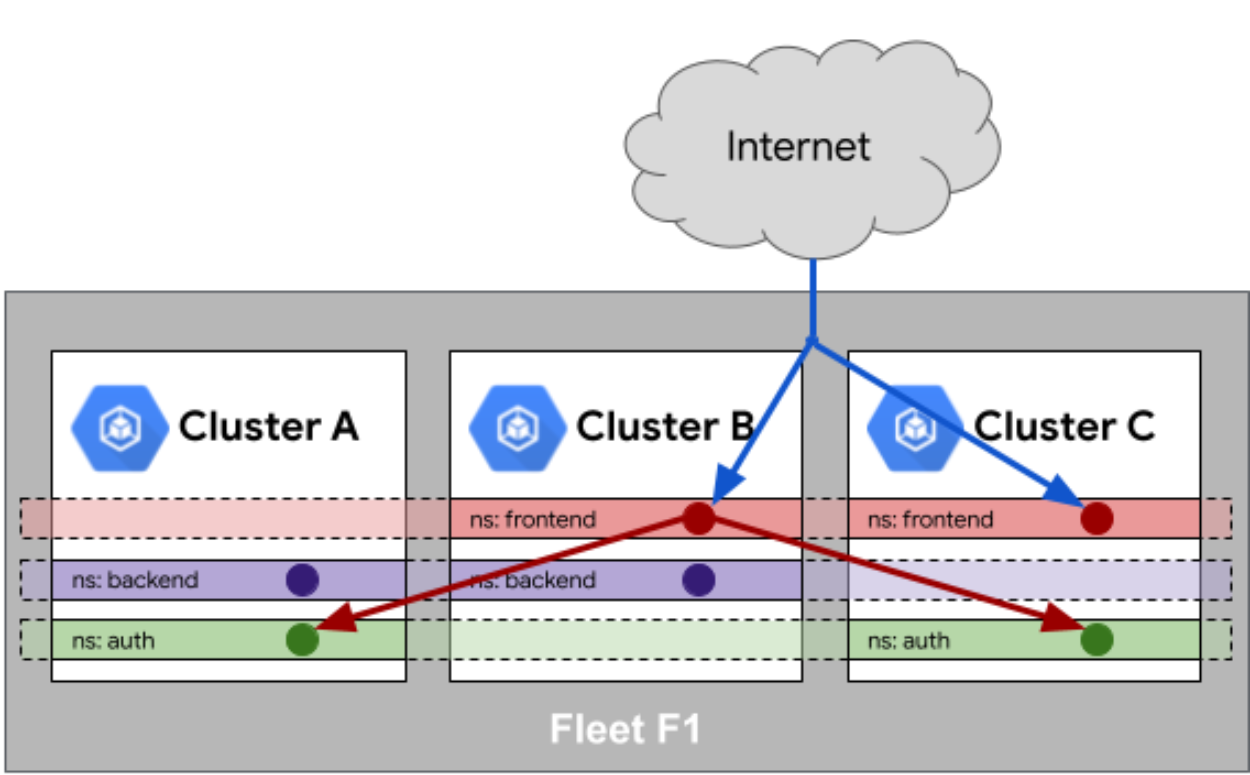
在多集群环境下,服务相同性(Service Sameness)是实现无缝服务发现和调用的关键。Kurator通过Fleet实现了三种级别的服务相同性:DNS相同性、服务IP相同性、端口相同性。DNS相同性确保服务在不同集群中具有相同的DNS名称;服务IP相同性保证服务在不同集群中使用相同的ClusterIP;端口相同性确保服务暴露的端口一致。
# Fleet中的服务相同性配置示例
apiVersion: fleet.kurator.dev/v1alpha1
kind: ServiceSameness
meta
name: global-frontend
spec:
selector:
app: frontend
clusters:
- name: cluster-east
- name: cluster-west
topologyPolicy: PreferSameCluster
failoverPolicy: Automatic
实现服务相同性的技术挑战在于网络连通性和DNS解析。Kurator通过集成Istio多集群服务网格,解决了跨集群的服务发现和流量管理问题。在边缘场景下,还结合KubeEdge的EdgeMesh组件,实现了边缘节点间的服务发现,即使在网络不稳定的情况下,也能保证服务的可用性。
3.3 Fleet策略引擎与统一治理
Fleet策略引擎是Kurator统一治理的核心,它允许管理员定义跨集群的统一策略,包括资源配额、安全策略、标签策略等。策略引擎基于Kyverno实现,支持复杂的条件判断、上下文感知和动态生成。例如,可以定义一个策略:所有生产环境的Pod必须包含特定标签,且不能使用latest镜像标签。
# Fleet策略示例:强制安全上下文
apiVersion: policies.kurator.dev/v1alpha1
kind: ClusterPolicy
meta
name: require-security-context
spec:
rules:
- name: check-container-security-context
match:
resources:
kinds: [Pod]
namespaces: ["production-*"]
validate:
message: "Containers must have security context defined"
pattern:
spec:
securityContext:
runAsNonRoot: true
runAsUser: "> 1000"
策略引擎的执行模式包括审计模式(Audit)和执行模式(Enforce),在审计模式下只记录违规但不阻止操作,适合策略试点阶段;在执行模式下会阻止违规操作,适合生产环境。策略引擎还提供了详细的报告和可视化,帮助管理员了解策略执行情况和合规状态。
4. Karmada集成与跨集群调度优化

4.1 Karmada架构与Kurator集成
Karmada 架构参考图:
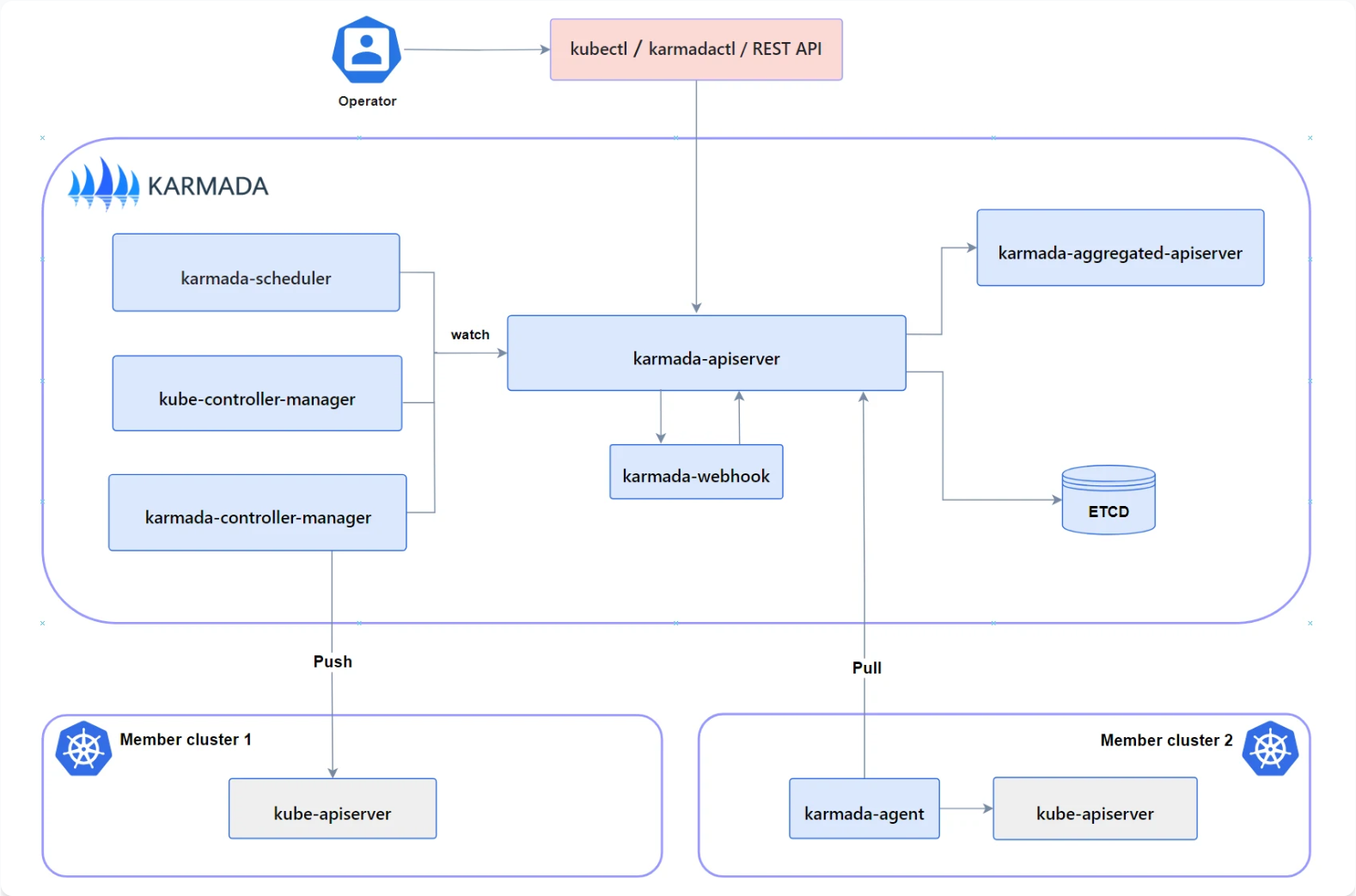
Karmada是CNCF孵化项目,专注于Kubernetes原生多集群管理。Kurator深度集成了Karmada,利用其强大的调度能力和策略框架,实现了更智能的跨集群资源分布。Karmada的核心组件包括:karmada-control-plane、karmada-scheduler、karmada-controller-manager等。Kurator通过扩展这些组件,增加了边缘感知、成本优化、亲和性调度等能力。
karmada集成实践参考图: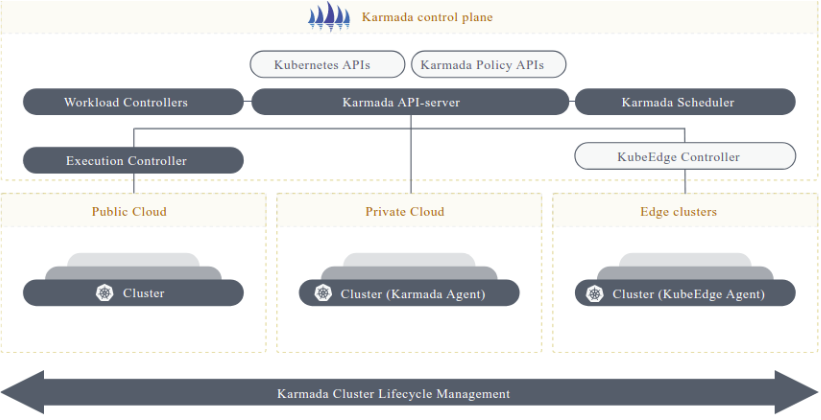
集成Karmada后,Kurator支持多种调度策略:复制调度(ReplicaScheduling)将工作负载复制到多个集群;分散调度(Descheduler)将工作负载分散到不同集群以提高可用性;聚合调度(AggregatedScheduling)将工作负载聚合到特定集群以优化资源利用率。这些策略可以根据业务需求动态调整,无需修改应用代码。
4.2 跨集群弹性伸缩实践
Karmada跨集群弹性伸缩参考图: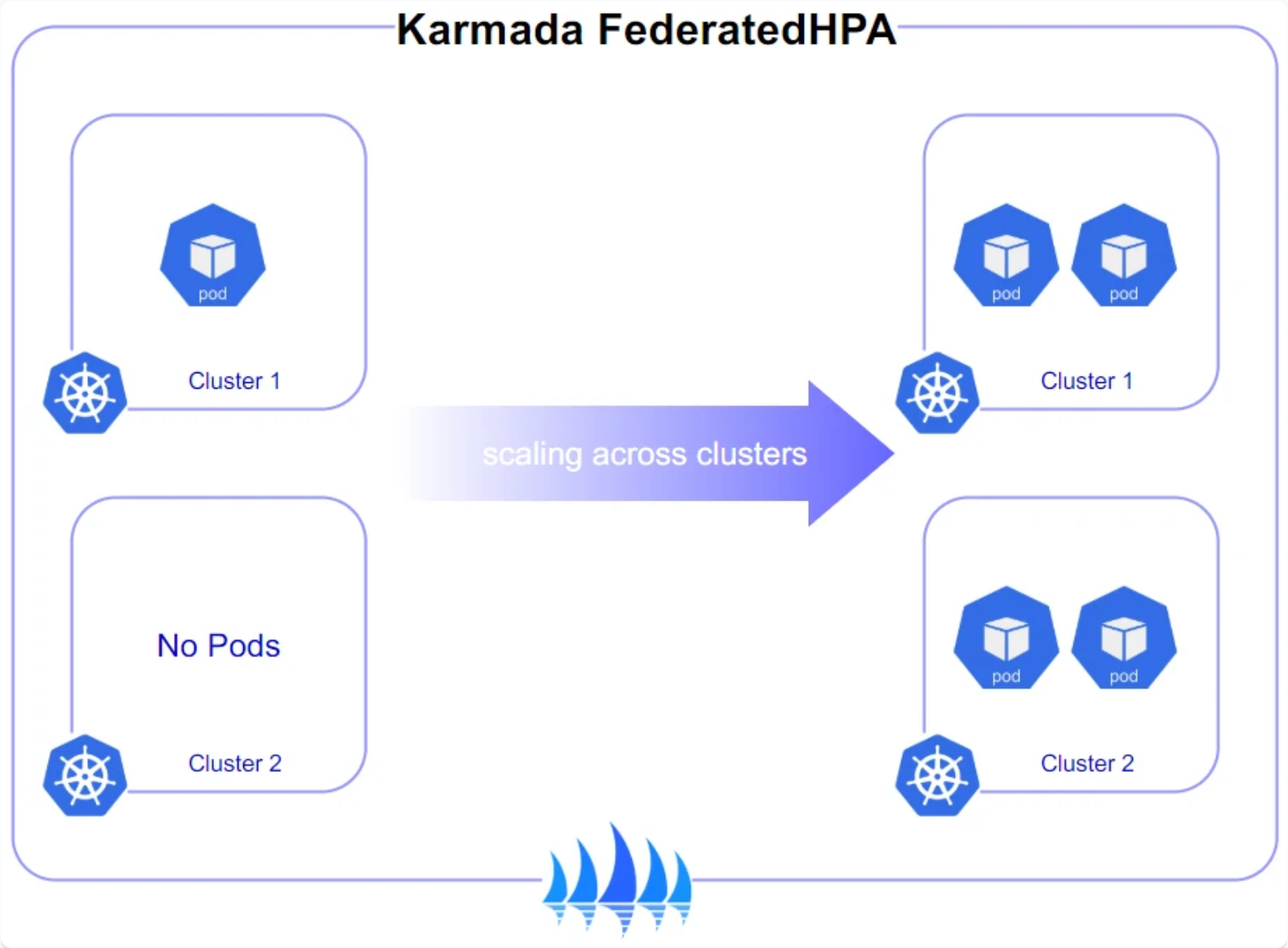
跨集群弹性伸缩是Kurator结合Karmada的重要特性,它超越了传统单集群HPA的限制,实现了全局资源视图下的智能扩缩容。当单个集群资源不足时,系统会自动将工作负载迁移到资源充足的集群,而非简单地拒绝调度。
# Karmada跨集群HPA配置示例
apiVersion: autoscaling.kurator.dev/v1alpha1
kind: ClusterHorizontalPodAutoscaler
meta
name: global-web-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: web-server
minReplicas: 3
maxReplicas: 20
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
clusterScaling:
strategy: Balanced
constraints:
maxClusterReplicas: 10
minHealthyClusters: 2
实现跨集群弹性伸缩的技术难点在于指标聚合和决策一致性。Kurator通过Prometheus联邦集群,实现了多集群指标的统一采集和查询;通过Karmada的调度框架,实现了基于全局状态的扩缩容决策。此外,还引入了预测性扩缩容机制,基于历史负载模式预测未来需求,提前进行资源准备,避免突发流量导致的性能下降。
4.3 资源拓扑感知调度
集群资源拓扑结构参考图: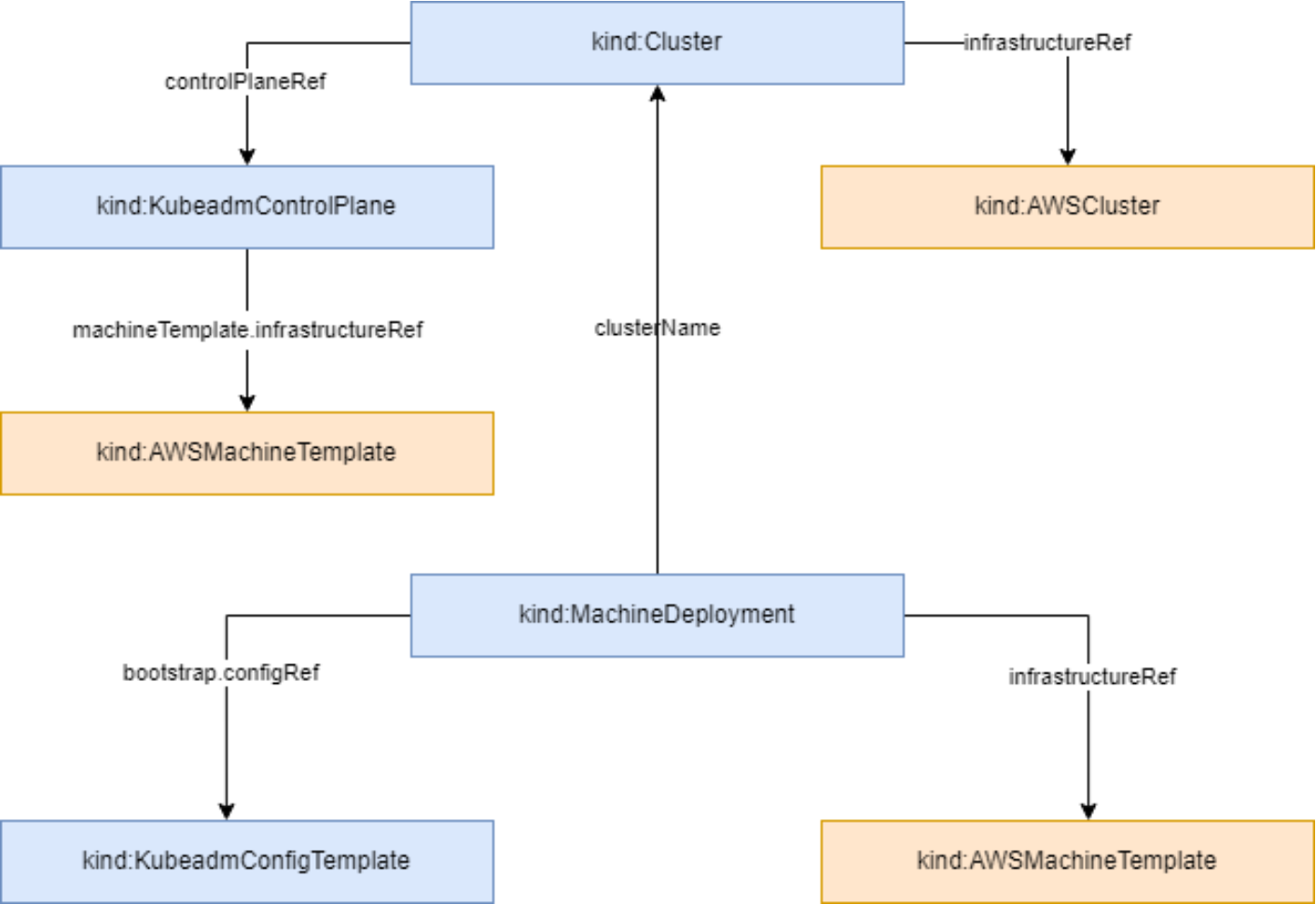
在分布式环境中,网络延迟、带宽成本、数据局部性等因素对应用性能有重大影响。Kurator通过Karmada实现了资源拓扑感知调度,根据应用的拓扑需求(如数据亲和性、地理位置、网络质量等),智能选择最优集群。
资源拓扑感知调度的核心是拓扑模型,它描述了集群间的网络关系、资源容量、成本因素等。Kurator支持自定义拓扑指标,如通过Prometheus采集的网络延迟、通过云厂商API获取的跨区域流量成本、通过自定义探测获取的应用响应时间等。调度器会综合这些指标,计算每个集群的"拓扑得分",选择最优集群部署工作负载。
# 查看集群拓扑关系
kurator topology view --clusters=cluster-east,cluster-west,edge-node-1
# 输出示例:
# cluster-east <-> cluster-west: latency=15ms, bandwidth=1Gbps
# cluster-east <-> edge-node-1: latency=45ms, bandwidth=100Mbps
# cluster-west <-> edge-node-1: latency=60ms, bandwidth=50Mbps
这种拓扑感知能力特别适合有严格SLA要求的应用,如实时音视频处理、金融交易系统、IoT数据处理等。通过将工作负载调度到最优位置,可以显著降低延迟、提高吞吐量、减少运营成本。
5. KubeEdge边缘计算深度集成

5.1 KubeEdge架构与核心组件
KubeEdge架构参考图: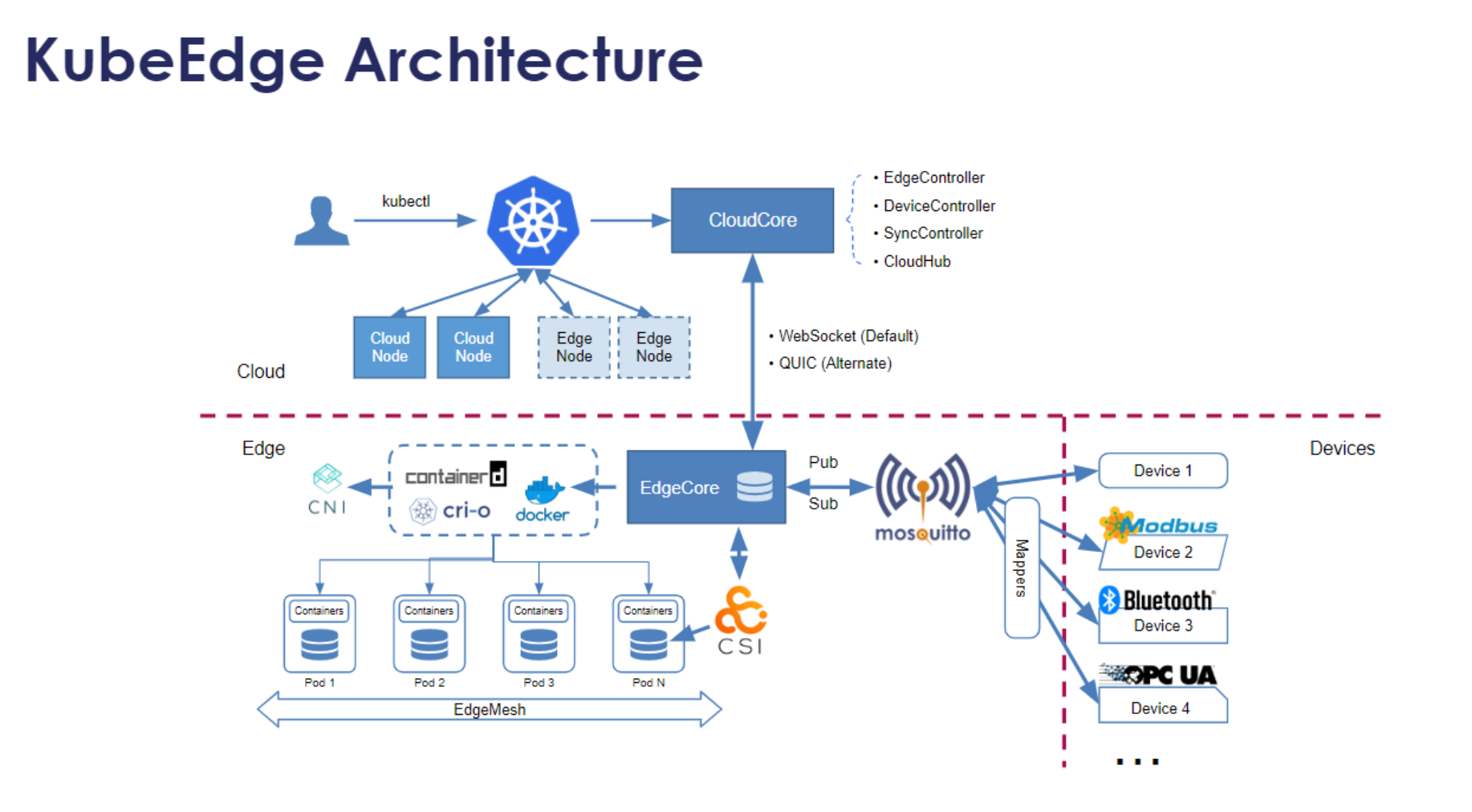
KubeEdge的核心组件参考图: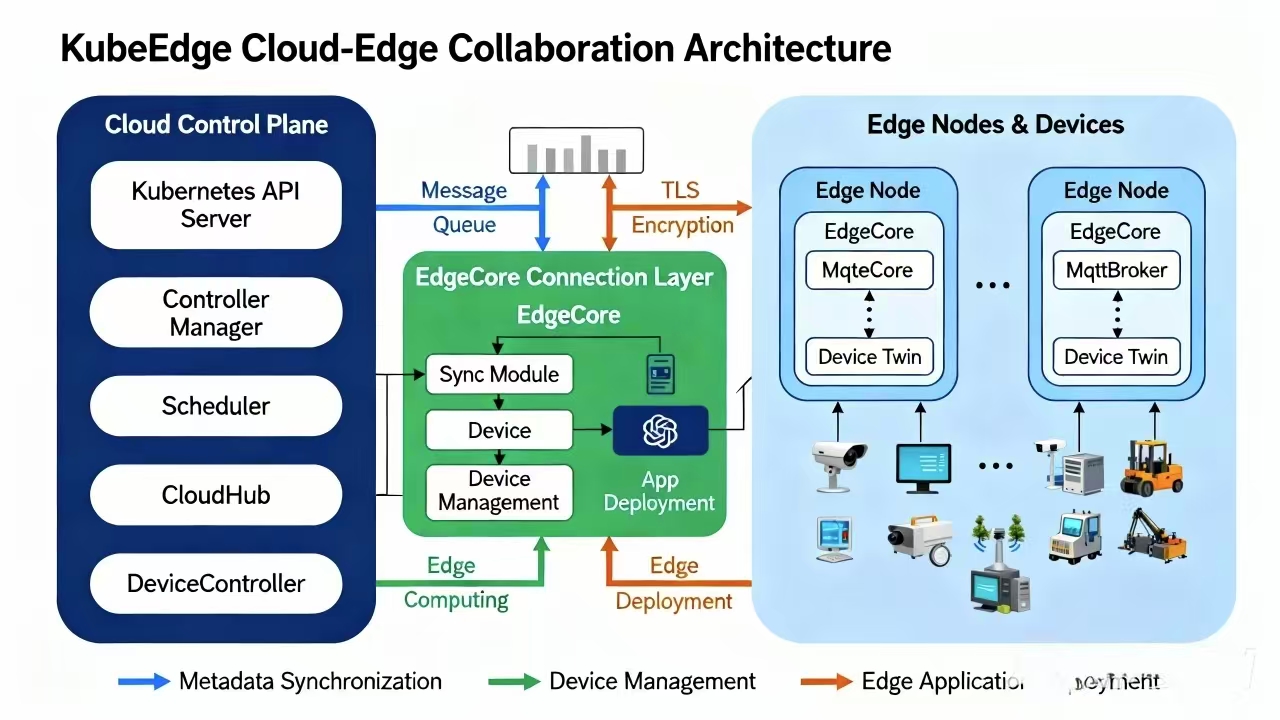
KubeEdge是CNCF毕业项目,专注于Kubernetes原生边缘计算。Kurator集成了KubeEdge,将云原生能力扩展到边缘场景。KubeEdge的核心组件包括:CloudCore(云端组件)、EdgeCore(边缘组件)、EdgeMesh(服务网格)、DeviceTwin(设备孪生)等。CloudCore运行在云端,负责与Kubernetes API Server通信;EdgeCore运行在边缘节点,提供边缘自治能力;EdgeMesh实现边缘节点间的服务发现;DeviceTwin管理物理设备的数字孪生。
Kurator通过扩展KubeEdge,增加了边缘集群管理、边缘应用分发、边缘监控告警等功能。特别值得一提的是,Kurator实现了边缘集群的Fleet管理,使得边缘集群可以像普通Kubernetes集群一样,纳入统一的管理平台,享受一致的运维体验。
5.2 边缘自治与离线工作模式
在网络不稳定或完全断开的情况下,边缘节点需要具备自治能力,保证关键业务连续运行。Kurator通过KubeEdge实现了多层次的边缘自治:元数据自治(缓存Kubernetes对象)、应用自治(本地运行Pod)、数据自治(本地存储和处理)、策略自治(本地执行策略)。
# 边缘自治策略配置示例
apiVersion: edge.kurator.dev/v1alpha1
kind: EdgeAutonomyPolicy
meta
name: critical-services-autonomy
spec:
selector:
app: critical-service
clusters:
- role: edge
autonomyLevel: High
offlineTTL: 72h
localStorage:
enabled: true
retention: 24h
实现边缘自治的关键技术是元数据同步和冲突解决。Kurator采用CRDT(Conflict-free Replicated Data Types)算法,确保在网络分区恢复后,能够自动合并冲突,保持数据一致性。此外,还提供了手动干预接口,允许管理员在极端情况下,强制同步或回滚。
5.3 边缘-云协同计算模式
边缘-云协同计算是Kurator边缘集成的高级特性,它将计算任务在边缘和云之间智能分配,充分发挥各自优势。边缘负责实时处理(如视频分析、传感器数据过滤),云负责批量处理(如模型训练、大数据分析)。Kurator通过统一的调度框架,实现了任务的自动拆分和分配。
协同计算的核心是任务图(Task Graph)概念,它描述了任务间的依赖关系和数据流向。Kurator调度器会根据任务特性(如实时性要求、计算复杂度、数据大小)、资源状况(如边缘节点负载、网络带宽)、成本因素(如云资源价格、流量费用),优化任务分配方案。
# 边缘-云协同计算任务示例
from kurator.edge import EdgeTask, CloudTask, TaskGraph
# 定义任务图
task_graph = TaskGraph("video-analytics")
edge_task = EdgeTask("frame-extraction",
image="edge-frame-extractor:1.0",
resources={"cpu": "1", "memory": "512Mi"})
cloud_task = CloudTask("object-detection",
image="cloud-object-detector:2.0",
resources={"cpu": "4", "memory": "8Gi", "gpu": "1"})
# 设置任务依赖
task_graph.add_dependency(edge_task, cloud_task, data_type="video-frames",
max_latency=1.0) # 1秒延迟要求
# 提交任务图
kurator_client.submit_task_graph(task_graph)
这种协同计算模式特别适合智能城市、工业互联网、车联网等场景,在保证实时性的同时,充分利用云端的强大算力,实现性能和成本的最佳平衡。
6. Volcano批处理调度与资源优化
6.1 Volcano架构与Kurator集成
Volcano调度架构参考图: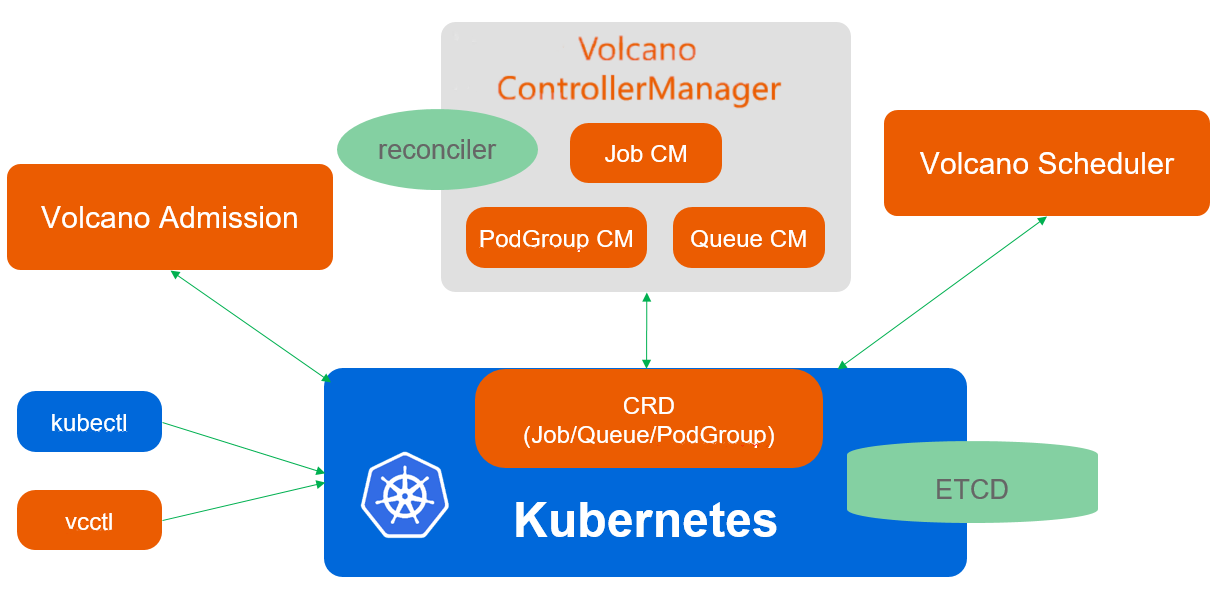
Volcano是CNCF沙箱项目,专注于Kubernetes批处理工作负载调度。Kurator深度集成了Volcano,为AI训练、大数据处理、科学计算等场景提供了高级调度能力。Volcano的核心组件包括:volcano-scheduler(调度器)、volcano-controller-manager(控制器)、volcano-admission(准入控制)等。调度器是核心,它实现了多种高级调度算法;控制器管理Volcano自定义资源;准入控制验证资源请求的合法性。
Kurator通过扩展Volcano,增加了多集群感知能力,使得批处理作业可以在多个集群间智能分布。特别是结合Karmada,实现了跨集群的队列管理和资源共享,大幅提高了资源利用率和作业吞吐量。
6.2 VolcanoJob与队列管理实践
VolcanoJob是Volcano的核心资源类型,它扩展了Kubernetes Job,增加了高级调度特性。Kurator增强了VolcanoJob,支持任务依赖、数据位置感知、抢占调度等功能。队列管理是另一个重要特性,它允许管理员定义多个队列,为不同团队或项目分配资源配额,实现多租户资源共享。
# VolcanoJob配置示例
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
meta
name: distributed-training
spec:
minAvailable: 8
schedulerName: volcano
queue: ai-training
tasks:
- replicas: 4
name: ps
template:
spec:
containers:
- image: tensorflow/tensorflow:2.8.0-gpu
name: ps
resources:
limits:
nvidia.com/gpu: 1
- replicas: 4
name: worker
template:
spec:
containers:
- image: tensorflow/tensorflow:2.8.0-gpu
name: worker
resources:
limits:
nvidia.com/gpu: 1
plugins:
ssh: []
env: []
svc: []
队列管理的核心是公平调度(Fair Sharing)和抢占机制(Preemption)。Kurator实现了层次化队列,支持队列内公平分配、队列间优先级调度、跨队列资源借用等功能。当高优先级作业等待时,系统会自动抢占低优先级作业的资源,保证关键业务的及时执行。
6.3 分组调度与拓扑感知优化
Volcano分组调度参考图: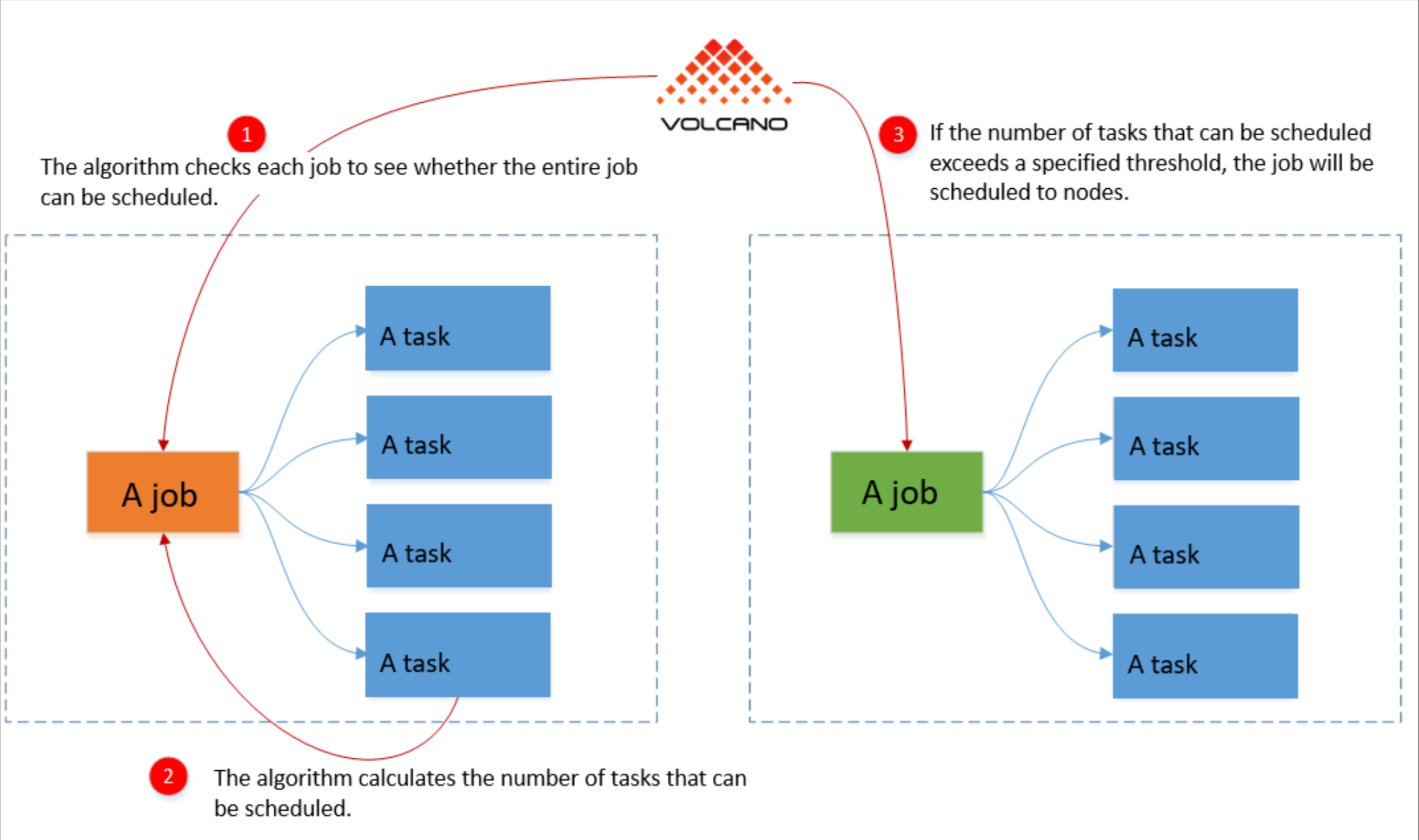
分组调度(PodGroup)是Volcano的核心创新,它将一组Pod视为一个调度单元,只有所有Pod都能被调度时,才会真正创建它们。这种"all-or-nothing"的调度策略,特别适合MPI、Spark等需要所有任务同时启动的分布式计算框架。
Kurator扩展了分组调度,增加了拓扑感知能力。它考虑了多种拓扑因素:节点拓扑(同一物理机、同一机架)、网络拓扑(同一交换机、同一可用区)、存储拓扑(同一存储卷、同一存储类型)。通过拓扑感知调度,可以显著减少跨节点通信开销,提高应用性能。
# 查看Volcano调度器拓扑感知状态
kurator volcano topology --queue=ai-training
# 输出示例:
# Queue: ai-training
# Cluster Topology:
# Region: us-east-1
# Zone: us-east-1a (3 nodes, 12 GPUs)
# Zone: us-east-1b (2 nodes, 8 GPUs)
# Region: us-west-2
# Zone: us-west-2a (4 nodes, 16 GPUs)
# Placement Policy: IntraZone
拓扑感知调度的实现基于Kubernetes拓扑标签和自定义拓扑域。Kurator调度器会分析任务的通信模式(通过历史监控数据或静态配置),计算最优的拓扑分布方案。例如,对于AllReduce通信模式的AI训练任务,会尽量将所有Pod调度到同一机架;对于MapReduce模式的大数据作业,会优先考虑数据局部性,减少数据传输开销。
7. GitOps与CI/CD流水线集成
7.1 GitOps实现方式与架构
GitOps实现方式参考图: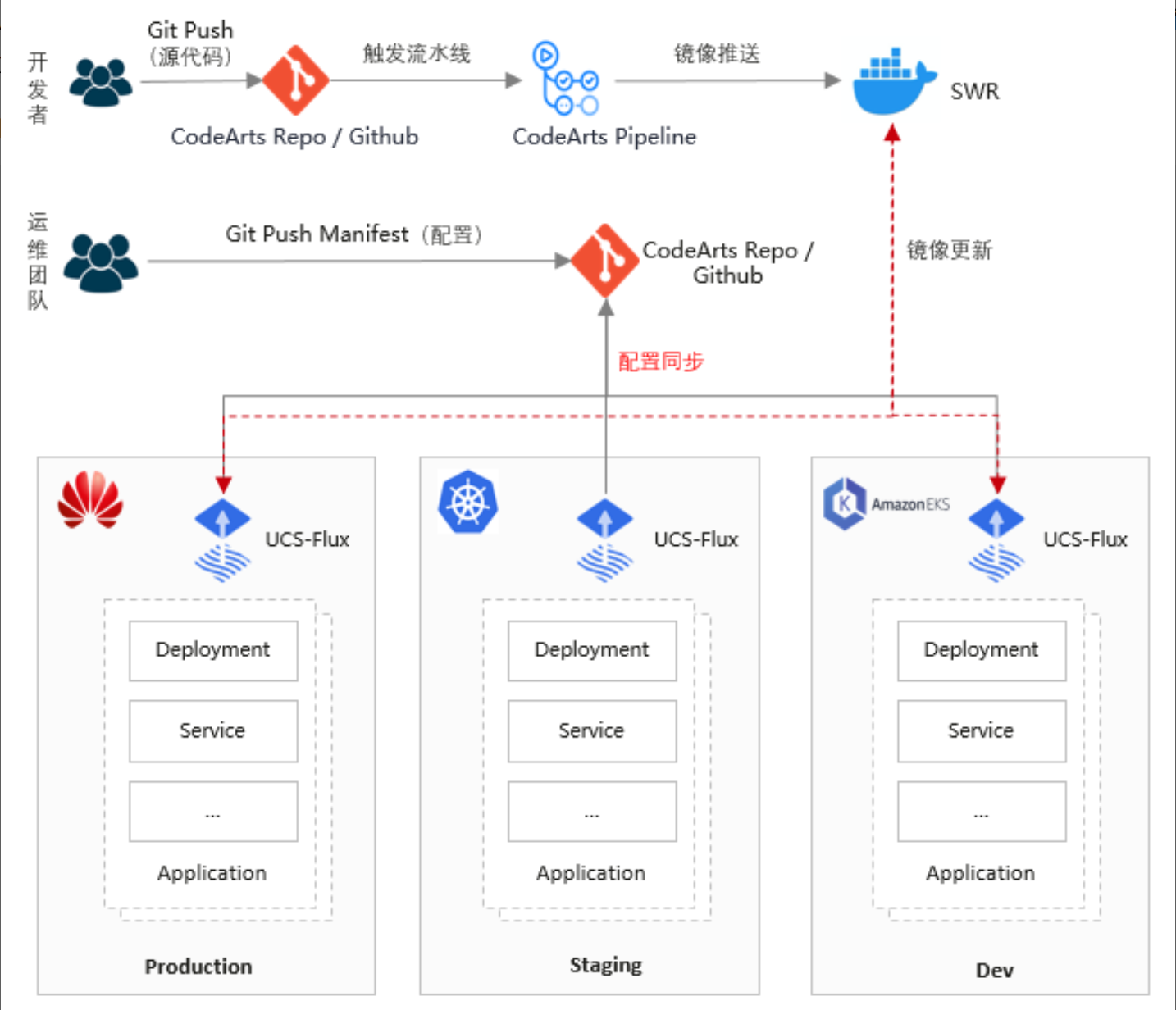
GitOps是云原生时代的运维范式,它将Git作为唯一事实来源,通过声明式配置和自动化同步,实现基础设施和应用的持续交付。Kurator通过集成FluxCD,实现了完整的GitOps能力,支持多集群、多环境的配置管理。
Kurator的GitOps架构包含三个核心组件:源控制器(Source Controller)负责监控Git仓库变化;Kustomize控制器(Kustomize Controller)负责解析和生成Kubernetes资源;Helm控制器(Helm Controller)负责管理Helm发布。这些组件通过事件驱动架构协同工作,确保系统状态与Git仓库中的声明保持最终一致。
# GitOps仓库结构示例
├── clusters
│ ├── production
│ │ ├── fleet.yaml
│ │ ├── karmada-policy.yaml
│ │ └── volcano-queue.yaml
│ └── staging
│ ├── fleet.yaml
│ └── ...
├── apps
│ ├── frontend
│ │ ├── base
│ │ ├── overlays
│ │ │ ├── production
│ │ │ └── staging
│ │ └── kustomization.yaml
│ └── backend
└── infrastructure
├── monitoring
├── logging
└── security
Kurator的GitOps实现特别强调安全性和审计性。所有配置变更都需要通过Pull Request流程,经过代码审查和自动化测试后才能合并。系统会自动记录每次同步的详细日志,包括变更内容、操作人员、时间戳等,满足合规性要求。
7.2 FluxCD Helm应用管理实践
Helm是Kubernetes的应用包管理器,Kurator通过FluxCD深度集成了Helm,实现了Helm Chart的自动化部署和升级。与传统Helm命令行相比,Kurator的GitOps方式具有明显优势:版本控制、变更审计、回滚能力、多环境管理。
# FluxCD HelmRelease配置示例
apiVersion: helm.toolkit.fluxcd.io/v2beta1
kind: HelmRelease
meta
name: kurator-dashboard
namespace: kurator-system
spec:
chart:
spec:
chart: kurator-dashboard
version: "1.2.3"
sourceRef:
kind: HelmRepository
name: kurator-charts
namespace: flux-system
interval: 1h
install:
remediation:
retries: 3
upgrade:
remediation:
retries: 3
strategy: rollback
values:
replicaCount: 2
service:
type: ClusterIP
resources:
requests:
memory: 256Mi
cpu: 100m
limits:
memory: 512Mi
cpu: 500m
在实践中,Kurator推荐使用多级Helm覆盖(Multi-stage Helm Overlays)模式:基础Chart定义通用配置,环境特定覆盖(Environment-specific Overlays)定义差异化配置,集群特定覆盖(Cluster-specific Overlays)定义集群特定参数。这种模式既保证了配置复用,又满足了环境差异需求。
7.3 Kurator CI/CD流水线设计
Kurator的CI/CD流水线采用分层架构,包括:代码层(应用代码、基础设施代码)、构建层(镜像构建、包构建)、测试层(单元测试、集成测试)、部署层(多环境部署、金丝雀发布)、验证层(健康检查、性能测试)、监控层(指标采集、告警通知)。
流水线的核心是质量门禁(Quality Gates),它定义了各阶段的通过标准。例如,在部署到生产环境前,必须通过安全扫描、性能基准测试、配置合规性检查等门禁。Kurator通过集成Tekton、Argo Events等工具,实现了高度自动化的流水线,同时保留了人工干预接口,确保关键决策的可控性。
# Kurator流水线触发示例
kurator pipeline run --app=frontend --environment=production --version=1.2.3
# 输出:
# Pipeline frontend-prod-1.2.3 started
# Stage 1/6: Code Scan - PASSED
# Stage 2/6: Build & Test - PASSED
# Stage 3/6: Security Scan - PASSED
# Stage 4/6: Staging Deployment - PASSED
# Stage 5/6: Performance Test - PASSED
# Stage 6/6: Production Deployment - IN_PROGRESS
这种流水线设计特别适合大规模分布式系统,它将复杂的部署过程分解为可管理的阶段,每个阶段都有明确的成功标准和失败处理策略。通过流水线的可视化和状态跟踪,团队可以快速定位问题,加速交付过程。
8. 未来展望与总结思考
8.1 Kurator技术路线图
Kurator作为新兴的分布式云原生平台,其技术路线图聚焦于三个方向:边缘智能、AI原生、零信任安全。边缘智能方面,将增强边缘自治能力,支持更复杂的边缘工作负载(如实时AI推理、边缘函数计算);AI原生方面,将深度集成AI框架,提供端到端的MLOps能力,从数据准备到模型部署;零信任安全方面,将实现全栈安全策略,从网络层到应用层,从静态配置到运行时保护。
特别值得关注的是Kurator的Serverless边缘计算愿景。通过结合Knative和KubeEdge,Kurator计划实现"边缘函数"能力,允许开发者编写简单的函数代码,系统自动处理调度、扩展、冷启动等复杂问题。这种模式将极大降低边缘应用开发门槛,加速边缘创新。
8.2 企业落地挑战与应对策略
尽管Kurator技术先进,但在企业落地过程中仍面临诸多挑战:技术栈复杂度高、人才短缺、遗留系统集成困难、组织文化变革阻力等。成功落地需要系统性的策略:分阶段实施(从非核心业务开始)、能力建设(培训、认证、社区参与)、架构治理(标准、规范、最佳实践)、度量驱动(ROI分析、价值证明)。
特别重要的是建立跨职能团队(Platform Team),负责Kurator平台的建设、运维和推广。这个团队应该包含基础设施专家、应用开发者、安全专家、运维工程师等多角色,共同推动平台演进。同时,需要建立清晰的平台契约(Platform Contract),明确定义平台提供的能力、SLA承诺、自助服务接口等,促进平台与业务的协同。
8.3 分布式云原生未来趋势
展望未来,分布式云原生将呈现三大趋势:异构计算融合(CPU、GPU、FPGA、AI加速器的统一调度)、无服务器化(Serverless架构成为主流)、自治运维(AIOps实现自我修复、自我优化)。Kurator作为开源平台,将在这些趋势中扮演关键角色,通过开放标准和社区协作,推动技术演进。
对于技术从业者,需要持续学习新技能:云原生基础(Kubernetes、Service Mesh)、分布式系统原理(一致性、容错、分区)、领域特定知识(AI/ML、大数据、IoT)。同时,软技能同样重要:跨团队协作、业务价值理解、变革管理能力。只有技术和业务深度融合,才能真正释放分布式云原生的价值。
在数字化转型的浪潮中,Kurator不仅是一个技术平台,更是一种新的思维方式。它让我们重新思考如何构建弹性、智能、高效的分布式系统,如何应对复杂性和不确定性,如何在速度和稳定性之间取得平衡。随着技术的不断成熟和生态的日益繁荣,Kurator必将为更多企业带来创新动力,推动云原生进入下一个发展阶段。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 17
17 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)