【前瞻创想】从单集群到分布式云原生:Kurator平台架构解析与多集群协同实战指南
【前瞻创想】从单集群到分布式云原生:Kurator平台架构解析与多集群协同实战指南
【前瞻创想】从单集群到分布式云原生:Kurator平台架构解析与多集群协同实战指南

摘要
随着企业数字化转型深入,传统的单集群Kubernetes架构已难以满足复杂的业务需求。本文深入剖析Kurator这一开源分布式云原生平台,通过理论结合实践的方式,详解其在多云、边缘计算场景下的创新应用。文章从环境搭建入手,深入探讨Fleet集群管理、Karmada跨集群调度、KubeEdge边缘协同、Volcano批量调度、GitOps自动化等核心能力,并通过代码实例展示关键功能实现,为企业构建现代化云原生基础设施提供专业指导。最后,结合社区参与经验,对分布式云原生技术未来发展方向提出前瞻性建议。
一、Kurator概述与分布式云原生演进
1.1 从单集群到分布式云原生的必然演进
在云原生技术发展的早期阶段,单集群Kubernetes架构能够满足大部分应用场景。然而,随着业务复杂度提升、数据合规要求严格、用户体验要求提高,单一集群架构的局限性日益突出:资源隔离不足、地理位置分散导致的延迟问题、多环境一致性难以保障等。
分布式云原生架构应运而生,它打破了传统集群边界,将计算能力延伸至边缘、多云甚至混合环境。Kurator正是这一演进过程中的重要产物,它不是简单的技术堆叠,而是通过深度整合多个优秀开源项目,构建出统一的控制平面,实现跨集群、跨地域、跨边界的资源协同。
1.2 Kurator架构设计与核心能力
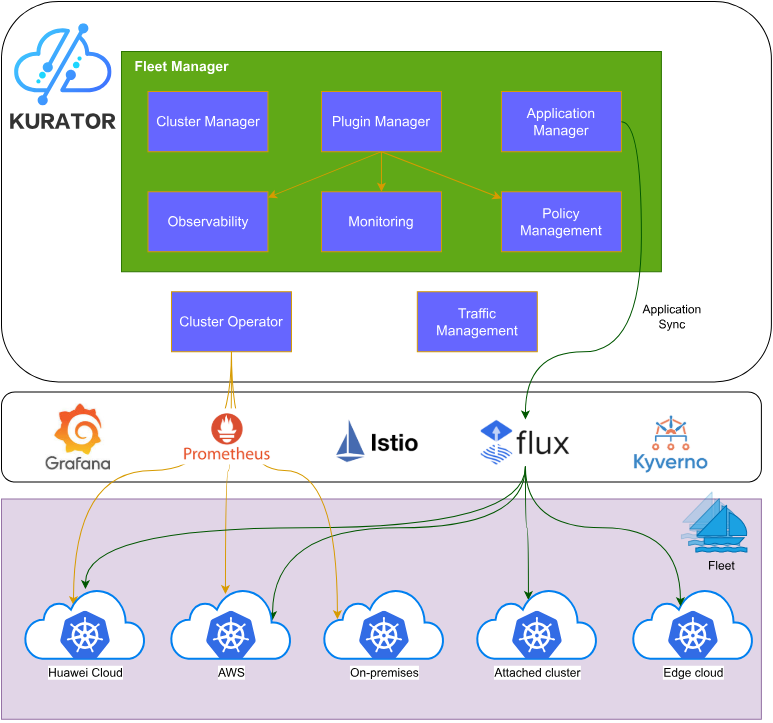
Kurator站在众多优秀开源项目的"肩膀"上,包括Kubernetes、Istio、Prometheus、FluxCD、KubeEdge、Volcano、Karmada、Kyverno等。其架构设计遵循"统一编排、分散执行"的原则,核心能力包括:
- 多云、边缘云、边缘-边缘协同:打破传统边界,实现资源的全局最优分配
- 统一资源编排:通过声明式API,实现跨集群资源的一致管理
- 统一调度系统:集成Volcano等调度器,支持AI/ML、批处理等高性能计算场景
- 统一流量管理:基于Istio服务网格,实现跨集群服务发现与流量治理
- 统一遥测系统:聚合多集群监控指标,提供全局可观测性
- 基础设施即代码:通过GitOps方式管理集群、节点、VPC等基础设施
这种架构设计使Kurator既能满足企业级应用的复杂需求,又能保持开源生态的灵活性和可扩展性。
1.3 Kurator在企业数字化转型中的战略价值
企业数字化转型不仅是技术升级,更是业务模式的重构。Kurator通过提供统一的分布式云原生平台,帮助企业实现:
- 降低运维复杂性:统一管理多云、混合云、边缘环境,减少运维负担
- 提升资源利用率:通过智能调度,最大化硬件投资回报
- 加速应用交付:GitOps工作流支持快速、可靠的软件交付
- 增强业务连续性:跨集群容灾能力保障核心业务不间断
- 满足合规要求:数据本地化、计算能力就近部署,符合各地法规
二、Kurator环境搭建与安装实践
2.1 环境准备与前置依赖
在搭建Kurator环境前,需要准备以下基础环境:
- 支持Kubernetes 1.20+的集群(建议至少3个节点)
- Helm 3.8+
- kubectl 1.20+
- Git 2.0+
- 至少8GB内存、4核CPU的机器作为管理节点
网络环境需要确保:
- 集群节点间网络互通
- 能够访问Docker Hub、GitHub等外部资源
- 各节点时间同步(建议配置NTP服务)
# 检查基础环境
kubectl version --client --short
helm version --short
git --version
2.2 基于源码的Kurator构建与部署
Kurator提供了灵活的部署方式,这里我们采用源码构建方式,既能深入了解项目结构,又能体验最新功能特性。
# 克隆Kurator源码仓库
git clone https://github.com/kurator-dev/kurator.git
# 或者使用wget下载
# wget https://github.com/kurator-dev/kurator/archive/refs/heads/main.zip
cd kurator
# 查看项目结构
tree -L 2
# .
# ├── Makefile
# ├── README.md
# ├── charts
# ├── cmd
# ├── deploy
# ├── docs
# ├── examples
# ├── hack
# ├── manifests
# ├── pkg
# ├── scripts
# └── test
克隆下来以后可以再看看源码文件
构建Kurator需要Go 1.18+环境,项目提供了Makefile简化构建流程:
# 构建Kurator二进制
make build
# 构建Docker镜像(可选)
make docker-build
# 部署Kurator核心组件
make deploy
2.3 安装验证与基础配置
安装完成后,需要验证各组件是否正常运行:
# 检查Kurator相关Pod状态
kubectl get pods -n kurator-system
# 预期输出示例
# NAME READY STATUS RESTARTS AGE
# kurator-controller-manager-0 2/2 Running 0 5m
# kurator-fleet-manager-5d7df9b897-2jklm 1/1 Running 0 5m
# kurator-karmada-manager-76c9d557d4-8fhkl 1/1 Running 0 5m
# kurator-volcano-manager-6b9f548d55-4xvnp 1/1 Running 0 5m
配置kubectl上下文,便于后续操作:
# 获取Kurator配置
kubectl config set-context --current --namespace=kurator-system
# 验证Kurator CRD是否安装成功
kubectl get crd | grep kurator
三、多集群管理核心-Fleet架构深度解析
Fleet核心架构图,如图所示: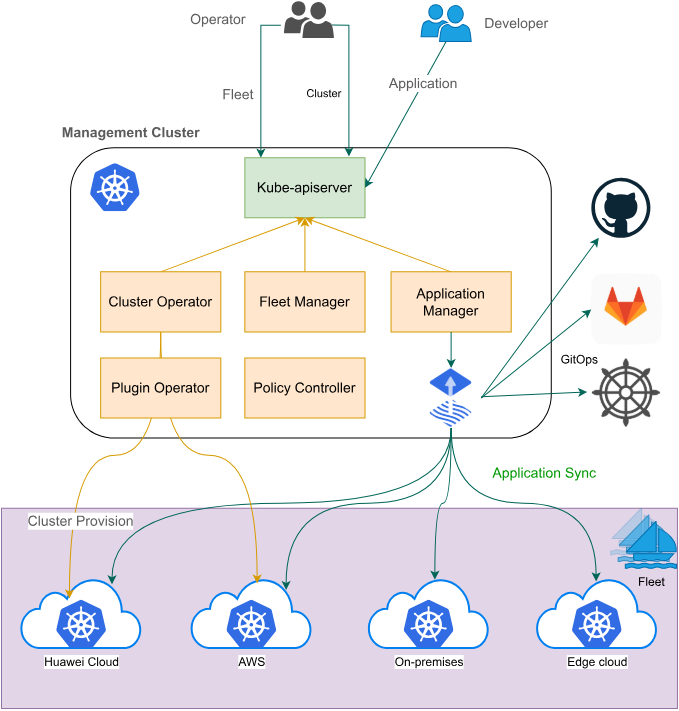
3.1 Fleet的设计哲学与核心概念
Fleet是Kurator中多集群管理的核心抽象,它将多个Kubernetes集群组织成一个逻辑单元,实现统一管理。Fleet的设计理念源于"舰队管理"的类比:单个船只(集群)难以应对复杂海洋(业务环境)的挑战,而舰队(Fleet)可以通过协同作战,发挥整体优势。
Fleet核心概念包括:
- MemberCluster:加入Fleet的集群成员
- ClusterResource:定义在Fleet级别管理的资源
- Policy:跨集群的一致性策略
- ResourceBinding:资源在集群间的绑定关系
3.2 集群注册与生命周期管理
Kurator集群生命周期管理如图所示: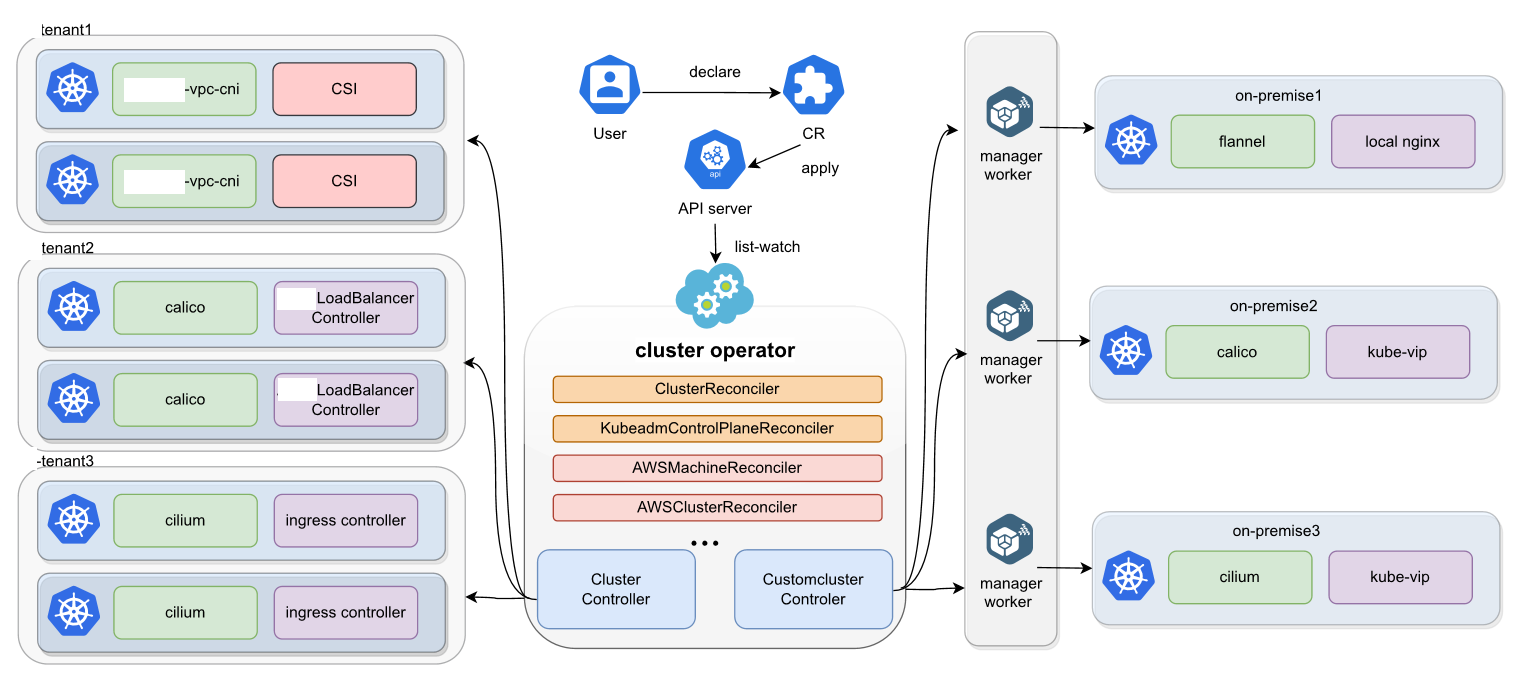
将集群加入Fleet是多集群管理的第一步。Kurator提供了多种注册方式,包括kubeconfig导入、集群代理注册等:
# cluster-registration.yaml
apiVersion: fleet.kurator.dev/v1alpha1
kind: Cluster
meta
name: member-cluster-1
spec:
kubeconfigSecret:
name: member-cluster-1-kubeconfig
namespace: kurator-system
syncMode: Push # 同步模式:Push或Pull
集群生命周期管理涵盖创建、更新、删除等操作,Kurator通过控制器模式实现自动化管理:
// 伪代码:集群生命周期管理控制器
func (c *ClusterController) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
cluster := &fleetv1alpha1.Cluster{}
if err := c.Get(ctx, req.NamespacedName, cluster); err != nil {
return ctrl.Result{}, client.IgnoreNotFound(err)
}
// 处理集群注册
if cluster.Status.Phase == "" {
return c.handleRegistration(ctx, cluster)
}
// 处理集群健康检查
if time.Since(cluster.Status.LastHeartbeatTime.Time) > cluster.Spec.HeartbeatInterval {
return c.handleHealthCheck(ctx, cluster)
}
// 处理集群注销
if !cluster.DeletionTimestamp.IsZero() {
return c.handleDeregistration(ctx, cluster)
}
return ctrl.Result{RequeueAfter: 5 * time.Minute}, nil
}
3.3 跨集群资源同步与一致性保障
Fleet的核心价值在于跨集群资源同步,Kurator通过声明式API实现这一目标:
# namespace-propagation.yaml
apiVersion: fleet.kurator.dev/v1alpha1
kind: NamespacePropagation
meta
name: shared-namespace
spec:
name: shared-ns
placement:
clusterSelector:
matchLabels:
environment: production
template:
meta
labels:
kurator.dev/managed-by: fleet
spec: {}
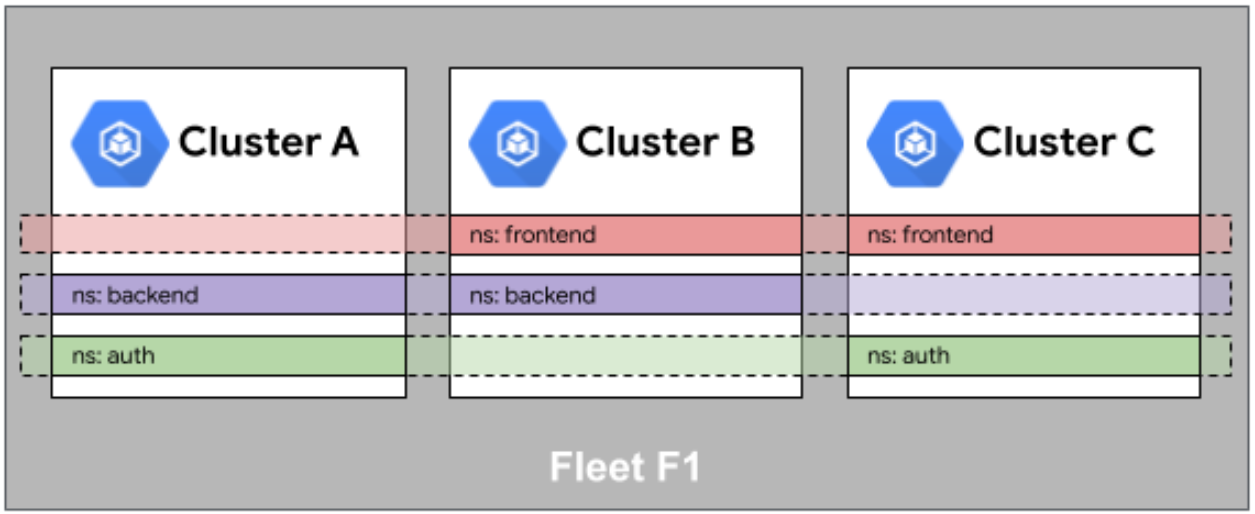
Kurator支持三种级别的相同性(Sameness):
-
命名空间相同性:确保特定命名空间在所有集群中一致存在
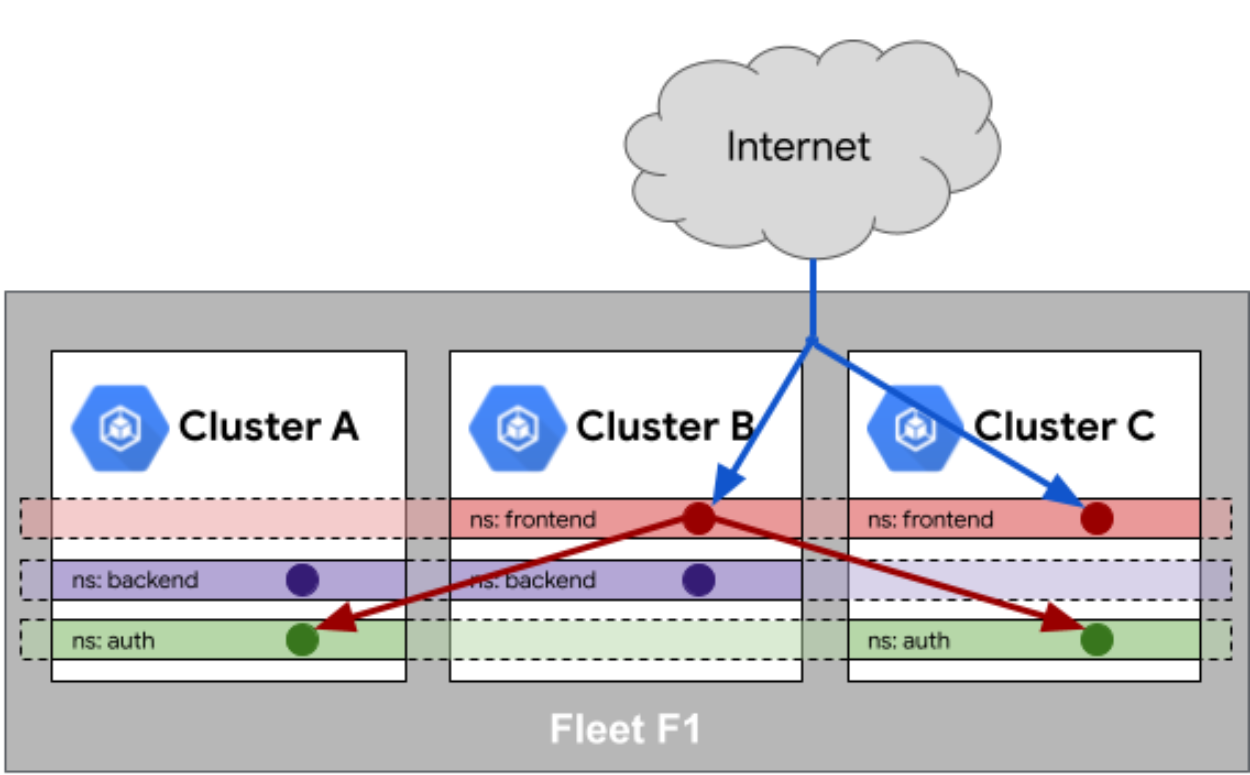
-
服务相同性:保证服务在跨集群环境下的可发现性
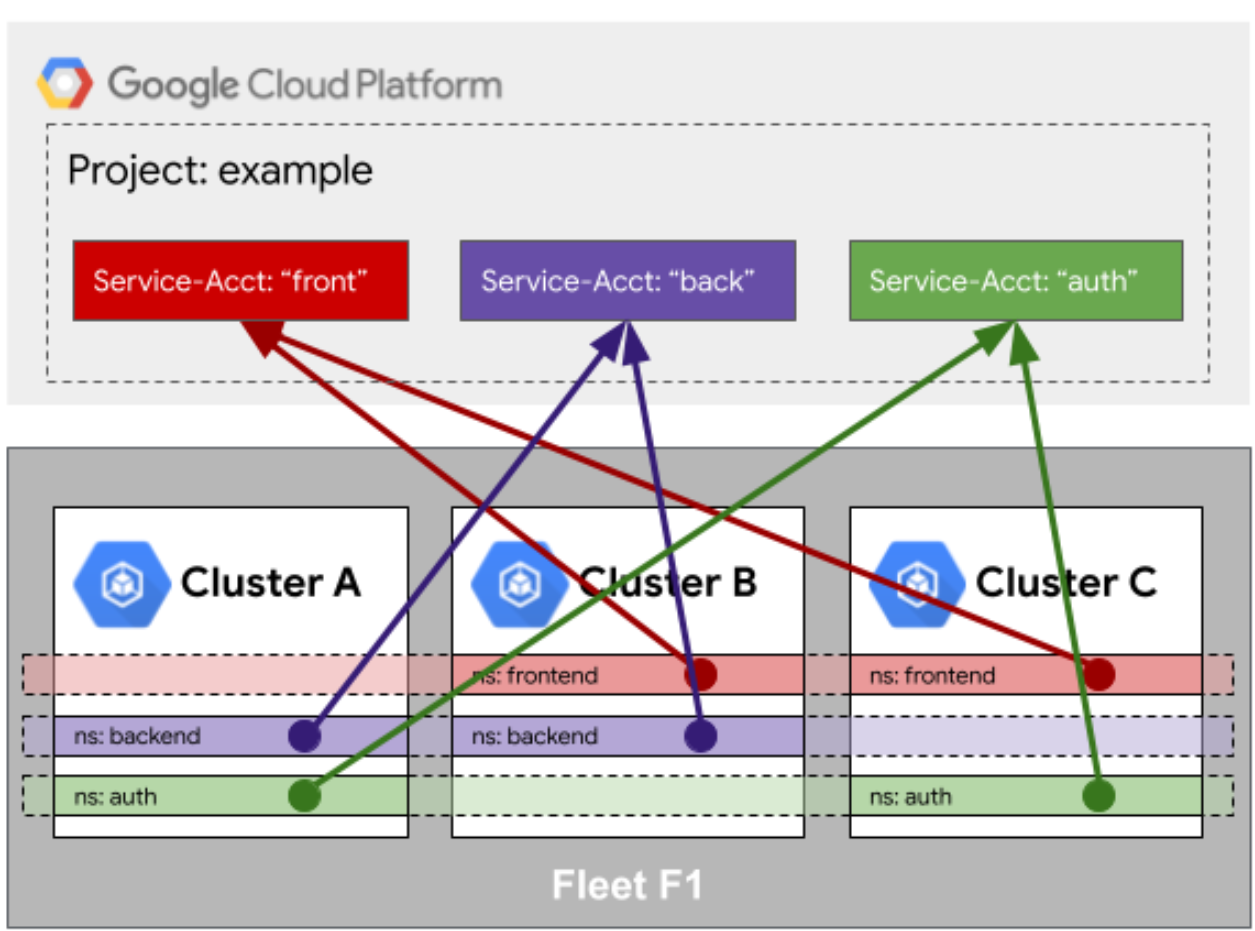
-
身份相同性:统一ServiceAccount和RBAC策略,实现跨集群访问控制
# 验证命名空间同步状态
kubectl get namespacepropagation shared-namespace -o yaml
四、Karmada在Kurator中的集成与应用实践

4.1 Karmada架构与多集群调度原理
Karmada架构如图所示: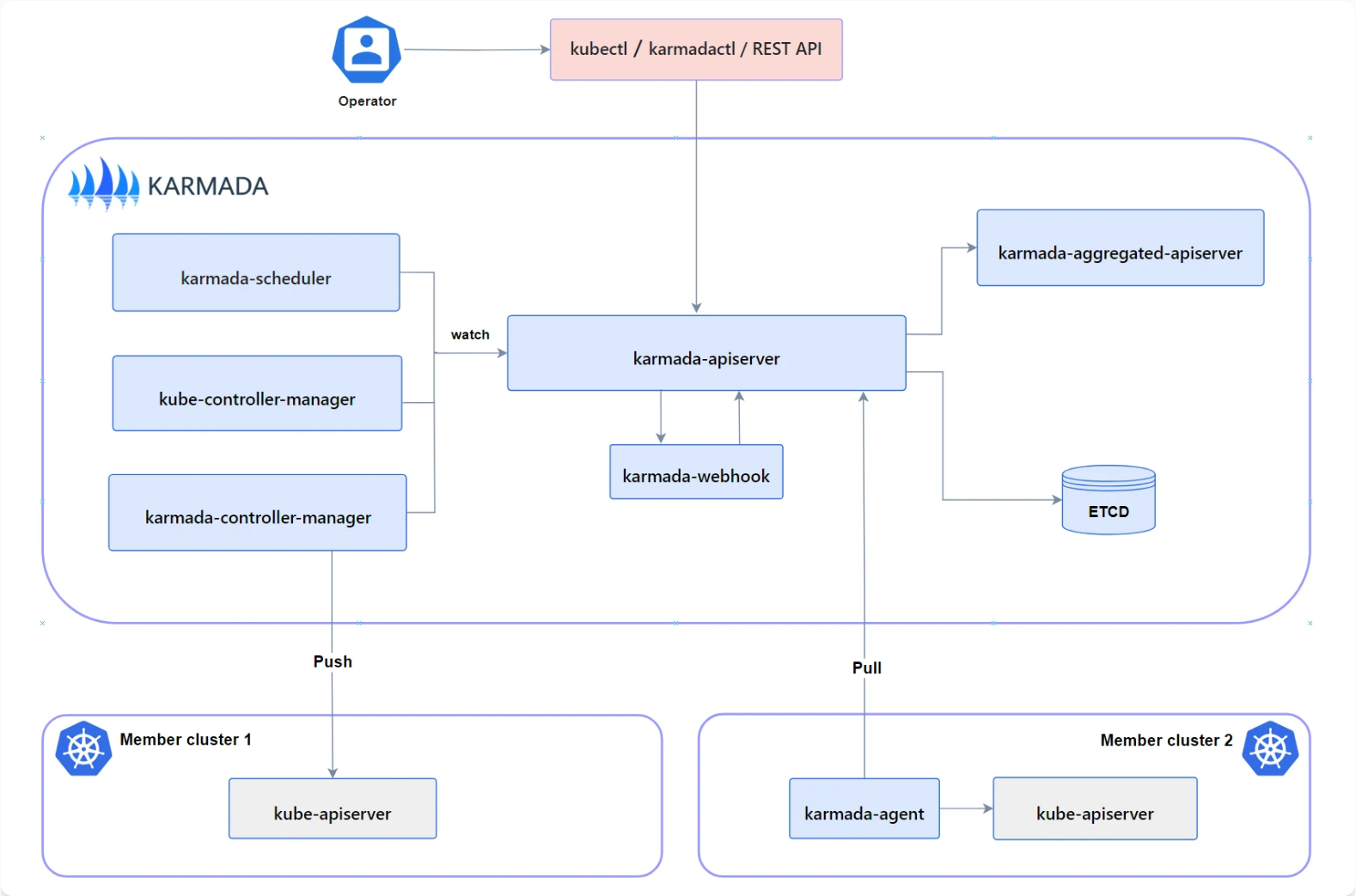
Karmada是CNCF孵化的多集群调度项目,Kurator将其深度集成,提供高级调度能力。Karmada的核心架构包括:
- karmada-control-plane:控制平面,包含API Server、etcd等
- karmada-scheduler:集群调度器,决定工作负载部署位置
- karmada-controller-manager:资源传播控制器
- karmada-agent:成员集群代理,执行具体操作
Karmada调度策略支持多种算法:
- 副本调度(Replica Scheduling)
- 集群故障域感知(Failure Domain Aware)
- 集群亲和性/反亲和性(Cluster Affinity/Anti-affinity)
- 动态权重调度(Dynamic Weighted Scheduling)
4.2 基于Karmada的跨集群弹性伸缩实践
Kurator扩展了Karmada的弹性能力,实现跨集群自动伸缩。下面是一个跨集群HPA的配置示例:
# cross-cluster-hpa.yaml
apiVersion: autoscaling.karmada.io/v1alpha1
kind: PropagationPolicy
meta
name: hpa-propagation
spec:
resourceSelectors:
- apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
name: frontend-hpa
placement:
clusterAffinity:
clusterNames:
- cluster-1
- cluster-2
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightList:
- targetCluster:
clusterNames:
- cluster-1
weight: 2
- targetCluster:
clusterNames:
- cluster-2
weight: 1
Kurator对Karmada的增强包括:
- 智能流量感知伸缩:结合Istio遥测数据,基于实际流量进行伸缩决策
- 成本优化策略:在多云环境下,优先选择成本较低的云提供商
- 地理位置感知:根据用户分布,就近部署应用实例
4.3 Karmada策略引擎在Kurator中的优化
Kurator对Karmada策略引擎进行了多项优化,以适应企业级场景:
- 策略继承与覆盖:
// 伪代码:策略继承与覆盖逻辑
func resolvePolicyOverrides(basePolicy, clusterPolicy *karmada.Policy) *karmada.Policy {
resolved := basePolicy.DeepCopy()
// 覆盖副本数
if clusterPolicy.Replicas != nil {
resolved.Replicas = clusterPolicy.Replicas
}
// 合并标签选择器
if clusterPolicy.ClusterAffinity != nil {
resolved.ClusterAffinity = mergeAffinities(basePolicy.ClusterAffinity, clusterPolicy.ClusterAffinity)
}
// 覆盖资源限制
if clusterPolicy.ResourceRequirements != nil {
resolved.ResourceRequirements = clusterPolicy.ResourceRequirements
}
return resolved
}
- 策略版本控制:通过GitOps方式管理策略变更,支持回滚和审计
- 策略模拟与验证:在应用策略前,模拟其影响,避免误操作
五、边缘计算与KubeEdge协同实践
5.1 边缘计算挑战与KubeEdge架构
边缘计算面临独特挑战:网络不稳定、资源受限、安全风险高、管理复杂。KubeEdge通过扩展Kubernetes API,将容器管理能力延伸至边缘:
- CloudCore:云端组件,连接Kubernetes API Server
- EdgeCore:边缘节点代理,管理容器运行时
- EdgeMesh:轻量级服务网格,支持边缘服务发现
- DeviceTwin:设备管理,提供统一设备抽象
Kuruator与KubeEdge集成,实现云边协同调度、统一应用分发等能力。
5.2 Kurator与KubeEdge集成方案
Kurator通过自定义资源定义(CRD)和控制器,实现与KubeEdge的深度集成:
# edge-application.yaml
apiVersion: apps.kurator.dev/v1alpha1
kind: EdgeApplication
meta
name: edge-ai-inference
spec:
selector:
app: ai-inference
template:
metadata:
labels:
app: ai-inference
spec:
containers:
- name: inference
image: edge-ai-inference:latest
resources:
limits:
cpu: 2
memory: 4Gi
nvidia.com/gpu: 1 # GPU资源需求
placement:
edgeClusters:
- name: factory-edge-cluster
nodeSelector:
edge-type: industrial
- name: retail-edge-cluster
nodeSelector:
edge-type: commercial
syncPolicy:
type: CloudToEdge # 同步方向
interval: 5m # 同步间隔
集成架构图如下:
+----------------+ +------------------+ +-----------------+
| Kurator | | KubeEdge | | Edge Node |
| Control Plane |<----->| CloudCore |<----->| EdgeCore |
| (Multi-cluster)| API | (Cloud Side) | Edge | (Edge Side) |
+----------------+ +------------------+ +-----------------+
^ ^ ^
| | |
v v v
+----------------+ +------------------+ +-----------------+
| Git Repository | | Edge Device CRDs | | Edge Containers |
| (GitOps Source)| | (DeviceTwin) | | (EdgeMesh) |
+----------------+ +------------------+ +-----------------+
5.3 云边协同场景下的AI推理应用部署
在智能制造场景中,AI视觉检测需要低延迟和数据隐私保障。Kurator与KubeEdge协同,实现云训练、边缘推理的架构:
- 模型训练:在云端Kubernetes集群训练AI模型
- 模型分发:通过GitOps将训练好的模型推送到边缘
- 边缘推理:在边缘节点执行推理,结果汇总到云端
- 反馈优化:异常样本上传云端,持续优化模型
# 创建边缘应用
kubectl apply -f edge-ai-inference.yaml
# 监控边缘应用状态
kubectl get edgeapp edge-ai-inference -o wide
# 查看边缘节点资源使用
kubectl get nodes -l edge-node=true -o wide
Kurator的统一控制平面使云边协同变得简单,开发者无需关注底层基础设施差异,专注于业务逻辑实现。
六、GitOps实践与CI/CD流水线构建
Kurator流水线架构图,如图所示: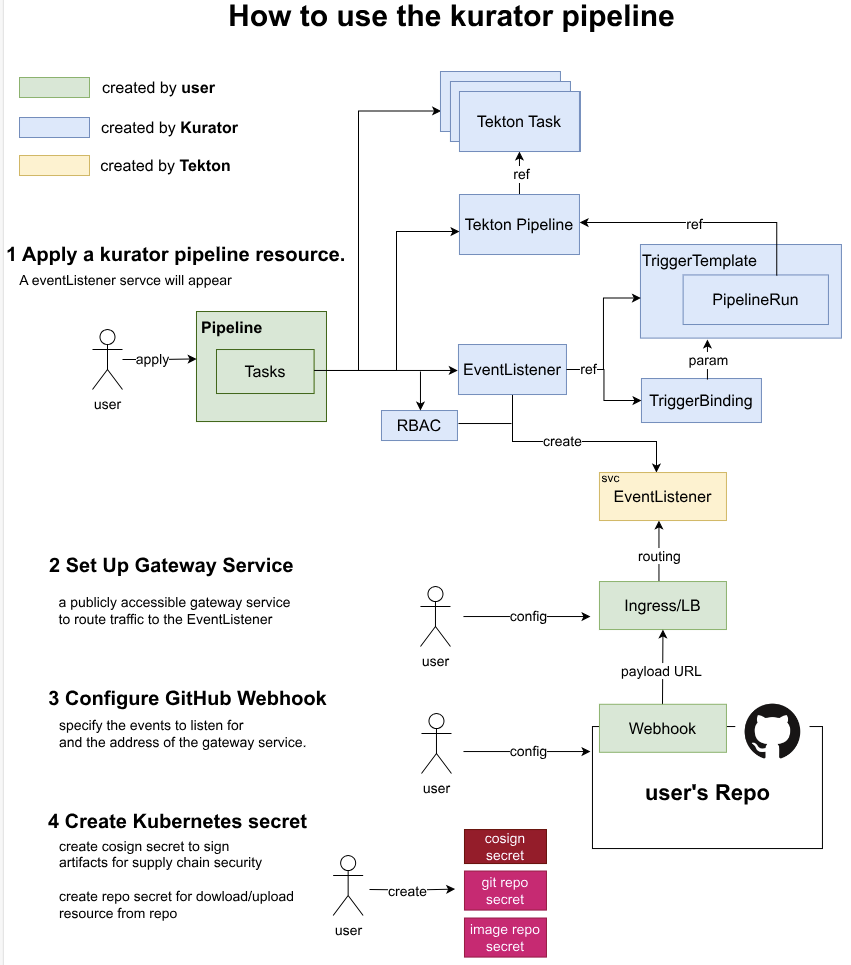
6.1 GitOps理念在Kurator中的实现
GitOps是云原生应用管理的核心理念,Kurator基于FluxCD实现声明式基础设施管理。核心原则包括:
- 声明式配置:所有基础设施和应用配置存储在Git仓库
- 自动化同步:系统自动检测Git变更并应用到集群
- 版本控制:配置变更可追踪、可回滚
- 审计合规:所有变更留有审计记录
Kurator扩展了标准GitOps模式,支持多集群、多环境配置:
# gitops-repo.yaml
apiVersion: source.toolkit.fluxcd.io/v1beta1
kind: GitRepository
meta
name: kurator-apps
namespace: flux-system
spec:
interval: 1m
url: https://github.com/your-org/kurator-apps
ref:
branch: main
secretRef:
name: git-auth
---
apiVersion: kustomize.toolkit.fluxcd.io/v1beta2
kind: Kustomization
meta
name: apps-production
namespace: flux-system
spec:
interval: 5m
path: "./environments/production"
prune: true
sourceRef:
kind: GitRepository
name: kurator-apps
postBuild:
substitute:
ENV: production
REGION: ap-southeast-1
6.2 基于FluxCD的Helm应用管理
Kurator深度集成FluxCD Helm控制器,简化Helm Chart管理:
# helm-release.yaml
apiVersion: helm.toolkit.fluxcd.io/v2beta1
kind: HelmRelease
metadata:
name: prometheus-stack
namespace: monitoring
spec:
chart:
spec:
chart: kube-prometheus-stack
version: "45.0.8"
sourceRef:
kind: HelmRepository
name: prometheus-community
namespace: flux-system
interval: 5m
install:
remediation:
retries: 3
upgrade:
remediation:
retries: 3
values:
prometheus:
prometheusSpec:
replicas: 2
retention: 15d
grafana:
enabled: true
adminPassword: "changeme"
persistence:
enabled: true
size: 10Gi
FluxCD Helm控制器工作流程:
- 从HelmRepository获取Chart版本
- 渲染Chart模板,应用values覆盖
- 在目标命名空间创建或更新Helm Release
- 监控Release状态,自动修复失败部署
6.3 Kurator CI/CD流水线设计与优化
Kurator提供完整的CI/CD解决方案,结合Jenkins、Tekton或Argo Workflows:
# kurator-pipeline.yaml
apiVersion: tekton.dev/v1beta1
kind: Pipeline
meta
name: kurator-app-pipeline
spec:
tasks:
- name: git-clone
taskRef:
name: git-clone
workspaces:
- name: source
workspace: shared-workspace
- name: build-image
taskRef:
name: kaniko
runAfter: [git-clone]
workspaces:
- name: source
workspace: shared-workspace
params:
- name: IMAGE
value: $(params.image-repo)/$(params.app-name):$(params.git-sha)
- name: deploy-to-staging
taskRef:
name: kubectl-deploy
runAfter: [build-image]
params:
- name: MANIFEST_PATH
value: deploy/staging/
- name: IMAGE_TAG
value: $(params.git-sha)
- name: run-tests
taskRef:
name: integration-tests
runAfter: [deploy-to-staging]
- name: promote-to-production
taskRef:
name: kurator-promote
runAfter: [run-tests]
when:
- input: $(tasks.run-tests.results.passed)
operator: in
values: ["true"]
params:
- name: SOURCE_ENV
value: staging
- name: TARGET_ENV
value: production
Kurator流水线的关键优化:
- 环境一致性:通过相同的Helm Chart和Kustomize配置,确保多环境一致性
- 安全合规:集成Kyverno策略,在部署前验证资源合规性
- 可观测性:集成交互式部署仪表板,实时显示流水线状态
- 成本优化:在非生产环境自动伸缩资源,降低测试成本
七、统一调度与资源管理-Volcano深度应用
7.1 Volcano调度架构与核心概念
Volcano是CNCF孵化的批处理调度框架,专为AI/ML、大数据、HPC等场景设计。其架构包括:
- Volcano Scheduler:基于多级调度策略的核心调度器
- Queue Controller:管理作业队列和资源配额
- Job Controller:管理VolcanoJob生命周期
- PodGroup Controller:管理Pod组协同调度
核心概念:
- Queue:资源池,定义可用资源总量
- PodGroup:协同调度的Pod集合,保证原子性
- VolcanoJob:批处理作业抽象,支持多种任务模式
- PriorityClass:作业优先级,支持抢占式调度
7.2 PodGroup、Queue与VolcanoJob协同工作
Kurator将Volcano深度集成,优化资源利用率:
# volcano-resources.yaml
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
meta
name: ai-training-queue
spec:
weight: 50
capability:
cpu: "100"
memory: 500Gi
nvidia.com/gpu: "20"
---
apiVersion: scheduling.volcano.sh/v1beta1
kind: PodGroup
metadata:
name: distributed-training
spec:
minMember: 8 # 最小成员数,低于此数不调度
minTaskMember:
- name: ps # 参数服务器
minMember: 2
- name: worker # 训练工作节点
minMember: 6
---
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
meta
name: image-classification-training
spec:
minAvailable: 8
schedulerName: volcano
queue: ai-training-queue
tasks:
- replicas: 2
name: ps
template:
spec:
containers:
- name: tensorflow
image: tensorflow/tensorflow:2.10.0-gpu
command: ["python", "/opt/train.py", "--role=ps"]
nodeSelector:
node-type: gpu
- replicas: 6
name: worker
template:
spec:
containers:
- name: tensorflow
image: tensorflow/tensorflow:2.10.0-gpu
command: ["python", "/opt/train.py", "--role=worker"]
nodeSelector:
node-type: gpu
7.3 Kurator中Volcano调度策略优化
Kurator针对多集群环境,优化了Volcano调度策略:
- 跨集群队列管理:统一管理多集群资源配额
// 伪代码:跨集群队列资源分配
func (q *CrossClusterQueue) AllocateResources(clusters map[string]*ClusterResource) {
totalResources := q.GetTotalResources()
clusterWeights := q.GetClusterWeights()
for clusterName, cluster := range clusters {
weight := clusterWeights[clusterName]
allocated := totalResources.Multiply(weight)
// 申请集群资源
if err := cluster.Allocate(allocated); err != nil {
// 降级策略:从其他集群借用资源
q.applyFailoverAllocation(clusterName, allocated)
}
}
}
- 异构硬件感知:自动识别GPU、TPU、FPGA等加速器
- 抢占与回收:高优先级作业可抢占低优先级资源,空闲资源自动回收
- 弹性扩展:队列满载时自动触发集群扩缩容
八、Kurator未来发展方向与社区生态建设
8.1 技术演进路线图
Kurator正处于快速发展阶段,未来技术路线包括:
- 边缘AI融合:深度集成TensorFlow Lite、PyTorch Mobile等边缘推理框架
- 服务网格增强:扩展Istio多集群功能,支持更精细的流量治理
- 安全增强:集成SPIFFE/SPIRE,实现零信任架构
- 成本优化:提供多云成本分析与优化建议
- 开发者体验:改进CLI工具,提供更直观的交互式界面
8.2 社区建设与贡献指南
Kurator作为开源项目,欢迎各方参与贡献:
- 代码贡献:遵循CONTRIBUTING.md指南,提交PR前运行测试
- 文档完善:改进英文/中文文档,添加更多实践案例
- 问题反馈:通过GitHub Issues报告bug或提出建议
- 社区活动:参与月度社区会议,分享实践经验
# 克隆仓库准备贡献
git clone https://github.com/kurator-dev/kurator.git
cd kurator
# 设置开发环境
make setup-dev
# 运行测试
make test
# 构建本地镜像
make docker-build IMG=your-dockerhub/kurator-controller:dev
8.3 企业落地实践建议与展望
基于多个企业落地经验,建议采用分阶段策略:
-
评估阶段(1-2个月):
- 梳理现有应用架构,识别适合多集群部署的应用
- 评估网络、安全、合规要求
- 制定POC验证计划
-
试点阶段(2-3个月):
- 选择1-2个非核心应用进行试点
- 建立DevOps工具链,培训团队
- 验证关键场景:多集群部署、故障转移等
-
推广阶段(3-6个月):
- 逐步迁移更多应用
- 建立治理规范和最佳实践
- 与现有监控、安全体系集成
-
优化阶段(持续):
- 基于运行数据持续优化架构
- 参与社区贡献,反馈需求
- 探索AI运维、自动优化等高级能力
分布式云原生是未来5-10年技术演进的重要方向。Kurator作为这一领域的创新者,将通过开源协作,持续推动企业数字化转型,实现"基础设施无感,业务敏捷创新"的愿景。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 19
19 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)