告别繁琐的多云管理:Kurator 实战指南,带你手把手撸明白云边协同与分布式调度架构
告别繁琐的多云管理:Kurator 实战指南,带你手把手撸明白云边协同与分布式调度架构
说起 Kurator,如果你还在把它当成一个简单的 Kubernetes 插件,那就真的有点小看它了。简单来说,Kurator 是华为云开源的一套分布式云平台,它核心解决的就是“多集群焦虑”。现在大家手里的集群越来越多,有的在公有云,有的在私有云,还有的在边缘端,怎么把这些散落各地的“孤岛”连成一片,还能像管一个集群那样简单?这就是 Kurator 存在的意义。它不是在重新发明轮子,而是把业内最顶尖的工具(像 Karmada、KubeEdge、Volcano 这些)打包整合,形成了一个开箱即用的“云原生全家桶”。
先聊聊这套“全家桶”的大脑:Fleet 架构到底是怎么管集群的? 🧠
我们在用 Kurator 的时候,第一个接触的概念肯定就是 Fleet。你可以把它理解成一个“集群舰队”。
Fleet 的核心架构逻辑
这是Fleet的核心架构图,展示了其如何基于Bundle定义和集群分组实现多集群应用的分发、同步与状态追踪: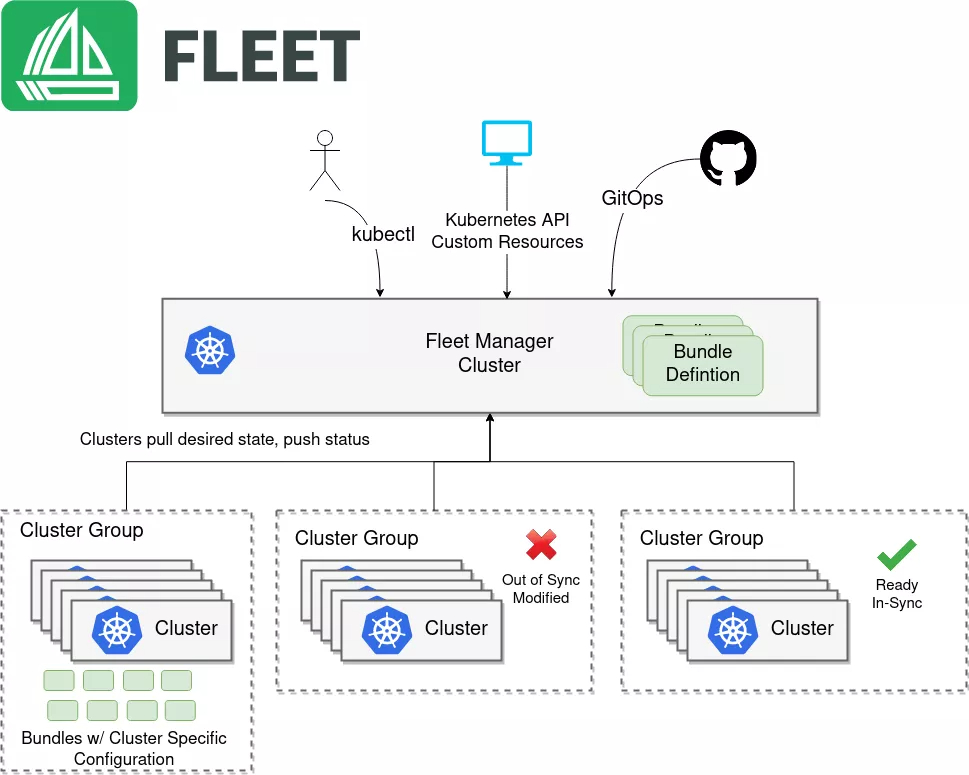
Fleet 的核心其实是一个“中心控制面”的思想。在 Fleet 的视角里,它把所有的集群分成了两种角色:一个是 Hub(主控集群),另一个是 Member(成员集群)。Hub 集群里跑着 Kurator 的控制器,它就像个调度中心,负责维护整个舰队的状态。所有的配置、策略、分发指令都是从 Hub 发出来的。它的好处在于,你不需要去每一个成员集群里反复敲命令,只要在 Hub 上定义好“我想要什么”,Fleet 就会自动同步到下面的各个集群。
Fleet 架构下的资源下发
这里的 Fleet 架构其实借鉴了分布式治理的精髓。它通过 CRD(自定义资源)定义了一套“舰队规范”。当你把一个新集群加入 Fleet 时,Kurator 会在 Hub 上生成一个对应的映射。无论你的成员集群是在北京、上海,还是远在海外的机房,Fleet 都能通过统一的通道把资源包投递过去。这种架构保证了高度的隔离性,哪怕某个成员集群断连了,也不会影响到 Hub 对其他集群的操作,等网络恢复了,状态会自动同步,这就是分布式架构的韧性。
环境动手搭起来:别只看文档,咱们得把代码拉下来跑跑看 🛠️
说一千道一万,不如亲自上手跑一下。我们要研究 Kurator,最直接的办法就是把它的源码仓库拉下来,研究一下它的构建逻辑和初始化脚本。
源码获取与环境准备
咱们先在本地或者开发机上找个干净的目录。这里咱们直接用 Git 把项目克隆下来。这个步骤是所有实操的起点,别跳过。
当然,感兴趣的同学,可以将项目下载下来体验一下:
然后我们找到Kurator的https地址,通过git将其拉取到本地:
分别执行下面两条命令:
# 复制项目地址
https://gitcode.com/kurator-dev/kurator.git
# 克隆到本地
git clone https://gitcode.com/kurator-dev/kurator.git
实际克隆项目演示效果可以看到如下图:
如下展示的便是完整的项目源码啦:
下载完成后,我们便可以进行项目部署及实战演练了。
手搓一个本地初始化脚本
虽然官方有各种自动化工具,但我建议初学者可以尝试自己写个简单的 Shell 来理解它的初始化过程。比如我们要检查本地环境是否满足 Kind 集群的安装要求,可以这么写:
#!/bin/bash
# 这是一个非常基础的环境检查和初始化模拟脚本
# 目的是为了确保我们在跑 Kurator 之前,本地的 K8s 环境是稳的
set -e
PROJECT_DIR=$(pwd)
echo "当前工作目录: $PROJECT_DIR"
# 检查一下 docker 还在不在,这是基础中的基础
if ! command -v docker &> /dev/null; then
echo "错误: 没找着 Docker,请先安装它。"
exit 1
fi
# 模拟 Kurator 的部分初始化逻辑,检查并创建本地 bin 目录
mkdir -p ./bin
echo "正在准备构建依赖..."
# 假设我们需要手动编译一个简单的 controller 辅助工具
# 这里模拟一个手搓的编译过程
# go build -o ./bin/kurator-helper ./cmd/helper/main.go
echo "环境自检完成,可以开始下一步的 Fleet 加入操作了。"
让应用稳稳降落:深入 Kurator Rollout 的滚动更新逻辑 🚀
应用部署上去了,最怕的就是更新时出问题。Kurator Rollout 功能就是专门干这个的,它是多集群环境下的“降落伞”。
Kurator Rollout 功能的架构分析
这是Kurator Rollout功能的架构图,展示了如何基于Git仓库和策略控制器,通过Flagger在多个集群中实现灰度发布: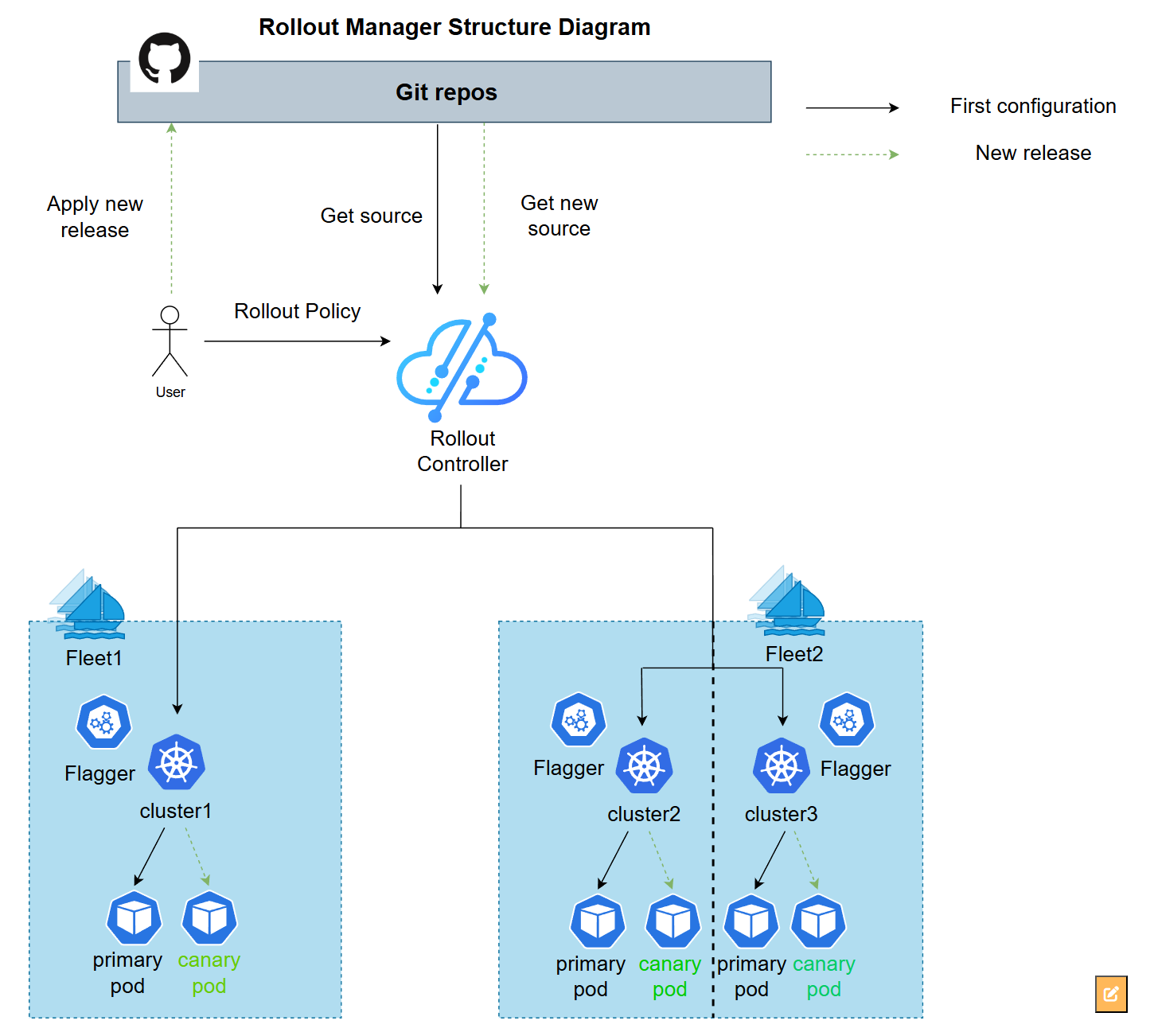
这个 Rollout 模块其实是站在了 Argo Rollouts 等优秀项目的肩膀上,但它更强调“跨集群协同”。它的架构主要由 Rollout Controller 和 Traffic Manager 组成。Controller 负责盯着你的 Deployment 或者自定义的资源,一旦发现版本变了,它不会立刻全量替换,而是启动一套灰度策略。
灰度发布与流量切换
在多集群场景下,Rollout 架构最厉害的地方在于它可以实现“集群间的逐步发布”。比如你有一百个集群,你可以设置先发布其中的 10%,观察监控指标。如果报错率上升,Rollout 架构会自动触发回滚。它通过与 Service Mesh(如 Istio)或者 Ingress Controller 联动,精准控制切往新版本的流量百分比。这种架构把风险控制在了极小的范围内。
云边一体化实操:用 KubeEdge 把手伸到边缘端 🌐
现在的业务不只是跑在中心云,很多时候需要跑在厂房、加油站或者自动驾驶汽车上。这就是云边协同的场景。
KubeEdge 的详细架构拆解
这是KubeEdge的详细架构参考图,展示了云端核心组件、边缘节点及其与设备之间的完整管理、通信与应用部署链路: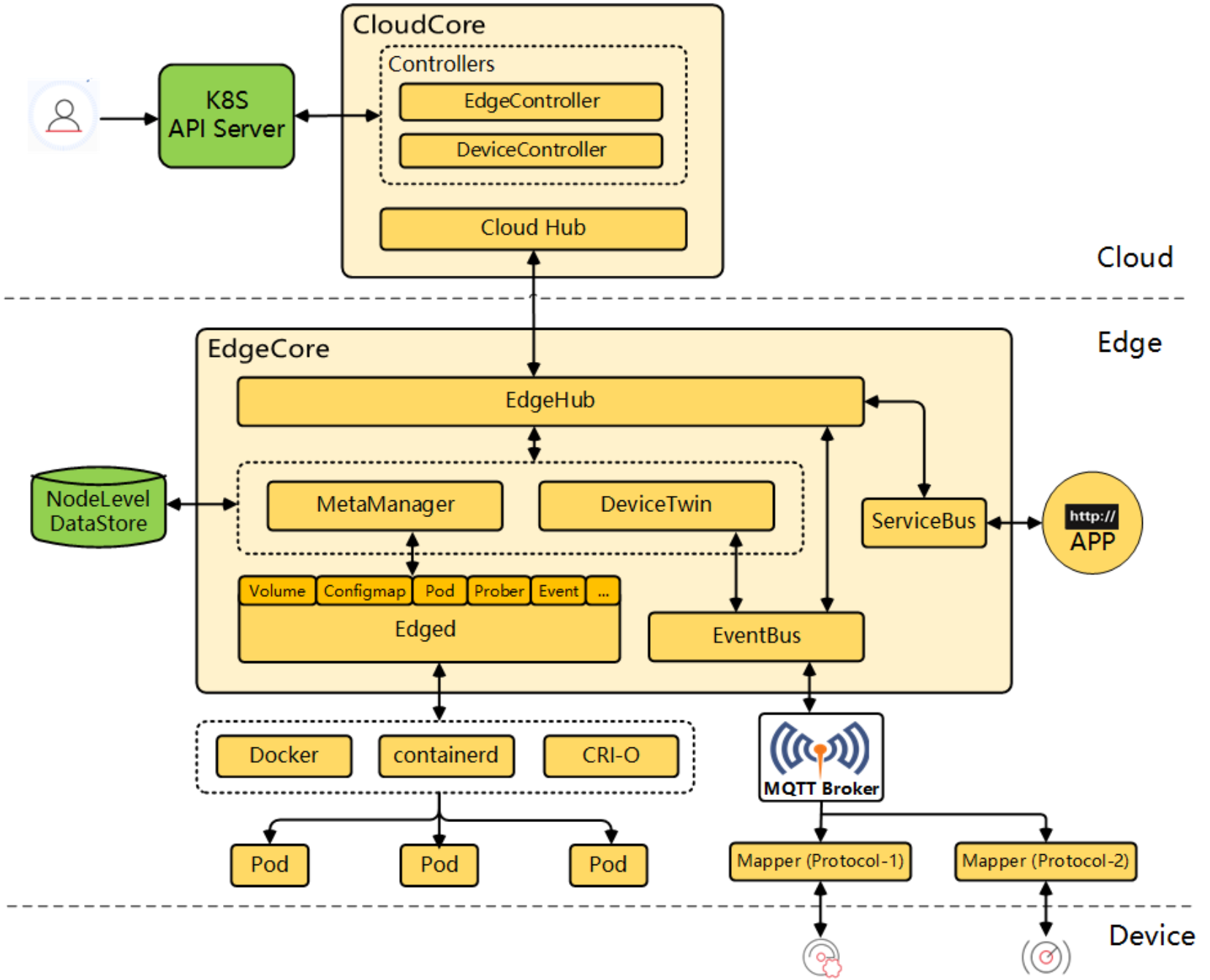
Kurator 深度集成了 KubeEdge。KubeEdge 的架构分为 CloudSide(云端) 和 EdgeSide(边缘端)。
- CloudSide:有个叫 CloudCore 的东西,它负责把 K8s 的 API 转换成边缘端能听懂的轻量级协议。
- EdgeSide:有个 EdgeCore,里面包含了 Edged(精简版 kubelet)、MetaManager(元数据管理)和 Beehive(消息框架)。
最核心的逻辑是:即便边缘端和云端断网了(这在边缘场景太常见了),边缘端的容器依然能照常运行,因为 MetaManager 会在本地持久化一份状态。
云边协同应用的部署架构
这张图展示了云边协同应用的部署架构,从设备层到边缘层、企业层再到产业平台,层层联动,实现工业数据在本地和云端的高效协同处理,支持智能制造和数字化转型: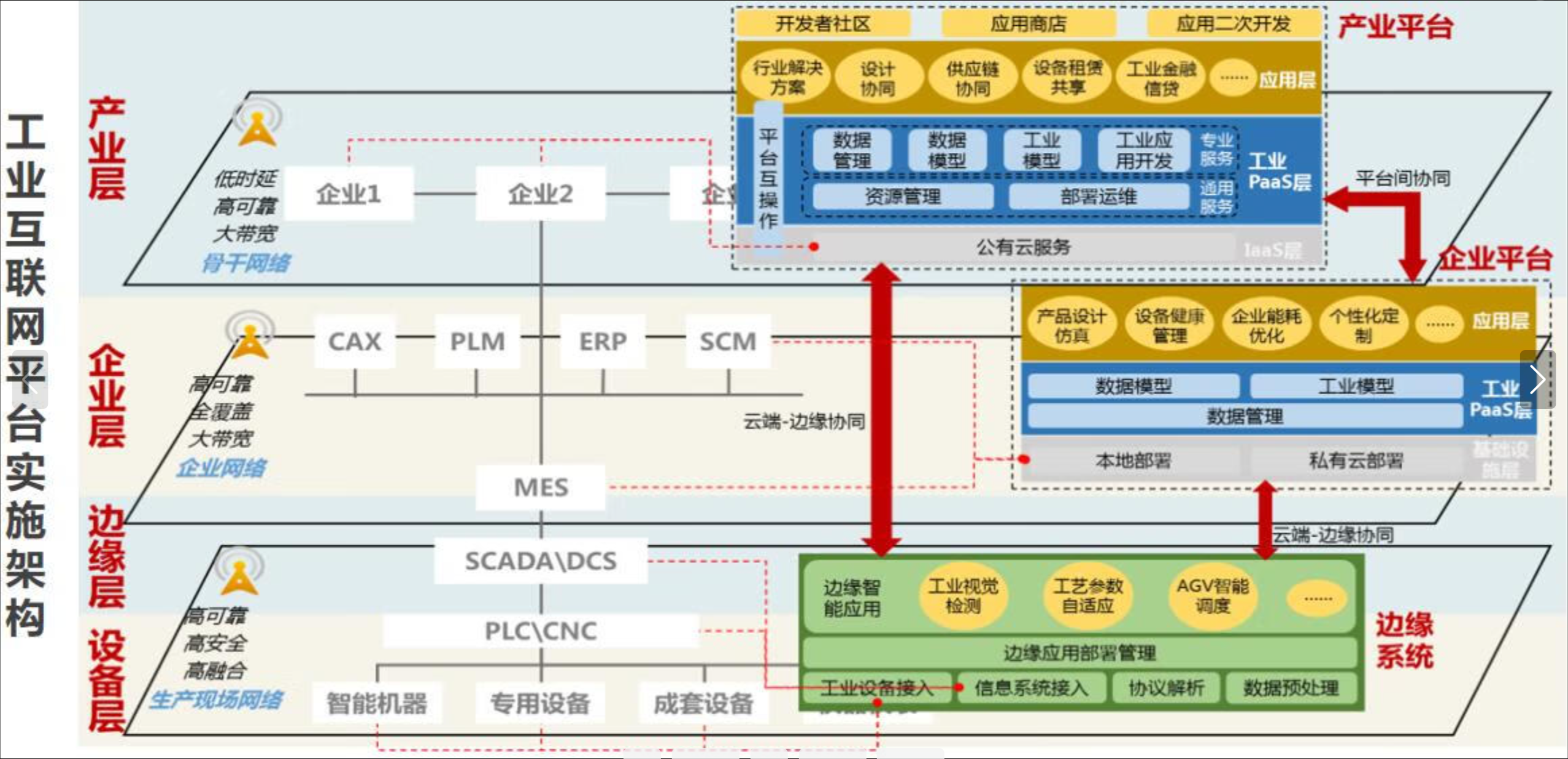
在 Kurator 体系下,部署云边应用变得非常丝滑。它的部署架构通常是:Hub 集群下发应用指令给 KubeEdge 的 CloudCore,CloudCore 通过双向多路复用的消息隧道(比如 WebSocket 或者 QUIC)把指令传给边缘节点。这种架构解决了由于边缘节点通常在私网、没有公网 IP 导致的“连不上”的问题。
这里我们写一个简单的云边应用分发 YAML 示例,看起来就像我们手动针对边缘节点打的补丁:
# 这是一个模拟云边应用分发的资源定义
# 我们通过 nodeSelector 把应用定向到边缘节点
apiVersion: apps/v1
kind: Deployment
metadata:
name: edge-worker-app
labels:
app: edge-computing
spec:
replicas: 1
selector:
matchLabels:
app: edge-computing
template:
metadata:
labels:
app: edge-computing
spec:
# 关键点:让 Pod 调度到 KubeEdge 管理的边缘节点上
nodeSelector:
node-role.kubernetes.io/edge: ""
containers:
- name: worker
image: my-registry/edge-worker:v1.0.2
resources:
limits:
cpu: "100m"
memory: "128Mi"
# 边缘端通常资源有限,所以配置要写得比较“抠门”
算力“及时雨”:Volcano 是如何搞定复杂调度与 CI/CD 的 🌋
当你的集群不只是跑 Web 应用,还要跑 AI 训练、大数据计算或者复杂的 CI/CD 流水线时,K8s 原生的调度器就显得有点力不从心了。这时候 Volcano 就上场了。
Volcano 调度架构深度解析
Volcano 的架构是插件化的。它在原生 K8s 调度逻辑之上,增加了一个 Action(动作) 和 Plugin(插件) 的概念。
- Action:比如 Enqueue(入队)、Allocate(分配)、Preempt(抢占)。
- Plugin:比如 Gang Scheduling(成组调度)、Binpack(装箱调度)。
在复杂的 CI/CD 流程中,如果你有一个任务需要 10 个 Pod 同时启动才能运行(比如分布式编译),原生调度器可能会一个一个调度,最后发现资源不够,导致死锁。Volcano 的 Gang Scheduling 架构会确保“要么 10 个全上,要么一个都不上”,这极大地提高了资源利用率。
Volcano 的应用场景与 CI/CD 流程
在 Kurator 的 CI/CD 完整流程 中,Volcano 扮演了底座的角色。
- 触发阶段:代码提交到仓库,触发 Kurator 的 Pipeline。
- 构建阶段:Pipeline 会拉起大量的构建任务。这时候,Volcano 会根据优先级和集群空闲情况,把这些重计算任务调度到最合适的节点。
- 分发阶段:构建好的镜像通过 Fleet 架构分发到各个集群。
- 部署阶段:结合前面提到的 Rollout 功能,实现自动化上线。
来看一段手撸的 Volcano Job 定义,这通常用于处理 CI/CD 中的并行测试任务:
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: cicd-parallel-test
spec:
minAvailable: 3 # 至少有3个副本同时就绪才开始跑任务,典型的 Gang Scheduling
schedulerName: volcano # 明确告诉 K8s,这活儿归 Volcano 管
tasks:
- replicas: 5
name: test-runner
template:
spec:
containers:
- name: tester
image: cicd-tools/pytest-runner:latest
command: ["/bin/sh", "-c", "python -m pytest ./tests"]
resources:
requests:
cpu: "1"
memory: "2Gi"
restartPolicy: OnFailure
运维不抓瞎:统一监控架构下的多集群治理方案 📊
管好了部署和调度,最后还得看监控。如果每个集群都要登录上去看 Grafana,那运维人员非得疯了不可。
Kurator 的统一监控架构
Kurator 提倡的是一种“联邦监控”的架构。它在 Hub 集群部署一个聚合层,通过 Prometheus 的 Remote Write(远程写)或者 Federation(联邦)模式,把各个成员集群的指标拉取回来。
它的精妙之处在于指标的“降采样”和“统一视图”。在成员集群里,我们可以保留精细的实时指标;在 Hub 集群,我们只看汇总的健康状态和关键告警。
统一视图下的运维实操
这种架构下,我们只需要配置一套报警规则。比如,当 Fleet 中任何一个集群的 CPU 使用率超过 90%,Hub 集群的监控中心就会立刻感知并推送钉钉或邮件。它还能配合 KubeEdge,把边缘端的那些断断续续的指标也整合进来,让你在中心端就能看到全球业务的“体温表”。
写到这里,你会发现 Kurator 其实是把一群“偏科天才”聚在一起组了个队。Fleet 管大局,Rollout 管稳妥,KubeEdge 管边缘,Volcano 管算力。这一套组合拳下来,多集群管理的那些坑基本都被填平了。
如果你正准备把业务切到多集群或者云边协同架构,不妨按着上面的逻辑,先把代码 clone 下来,从手搓一个简单的部署 YAML 开始。实践出真知,等你自己撸出几套复杂的调度策略时,你就真的入门了。
怎么样,对这套架构还有哪里觉得“玄乎”的吗?咱们可以接着聊聊具体的避坑指南。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)