【前瞻创想】Kurator分布式云原生平台实战:从架构解析到多集群统一管理深度实践
【前瞻创想】Kurator分布式云原生平台实战:从架构解析到多集群统一管理深度实践
【前瞻创想】Kurator分布式云原生平台实战:从架构解析到多集群统一管理深度实践
摘要
本文深入探讨Kurator这一开源分布式云原生平台的核心架构、创新价值与实践应用。Kurator站在Kubernetes、Istio、Prometheus、FluxCD、KubeEdge、Volcano、Karmada、Kyverno等优秀云原生项目的肩膀上,为用户提供统一的多云多集群管理能力,涵盖资源编排、调度、流量管理、监控等多个维度。文章从Kurator的技术架构解析入手,详细阐述了环境搭建、Fleet多集群管理、GitOps实现、Karmada跨集群调度、KubeEdge边缘计算集成以及Volcano批处理优化等核心功能的实战经验,通过深度技术剖析与代码示例,帮助读者掌握分布式云原生基础设施的构建与管理方法,为企业数字化转型提供技术支撑。
一、Kurator平台概述与核心价值
Kurator的核心价值参考图: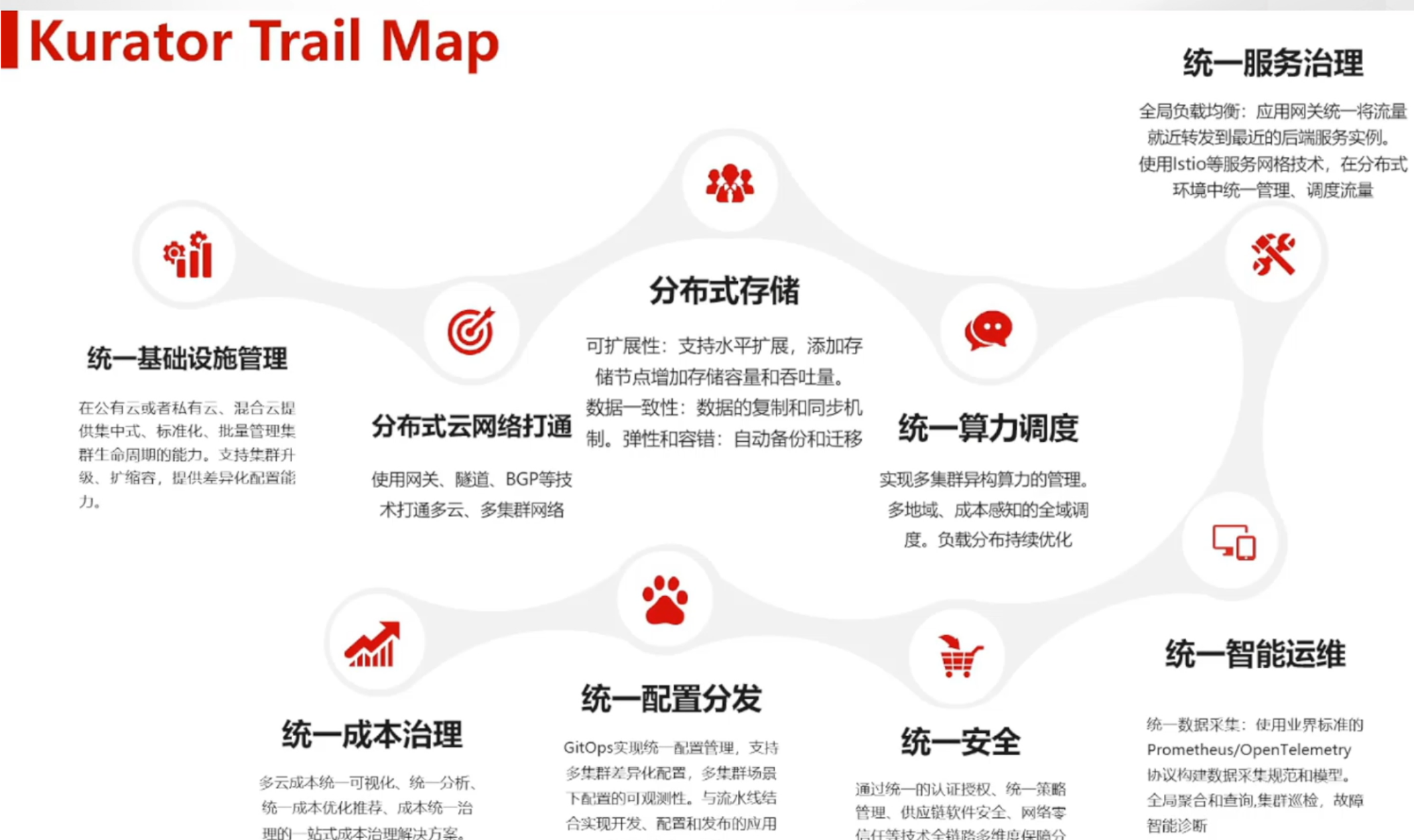
1.1 Kurator的诞生背景与设计理念
随着企业数字化转型的深入,云原生技术已成为支撑业务创新的核心基础设施。然而,多云、混合云、边缘计算等场景的复杂性给企业带来了新的挑战:如何统一管理分布在不同地域、不同环境的计算资源?如何实现跨集群的服务发现与通信?如何保证一致的安全策略与合规要求?
Kurator正是在这样的背景下应运而生。作为一个开源的分布式云原生平台,Kurator的设计理念是"站在巨人的肩膀上",通过集成和增强现有的优秀云原生项目,为用户提供一个完整、统一的解决方案。Kurator不是要重新发明轮子,而是要将这些轮子组装成一辆能够适应各种地形的越野车。
Kurator的核心设计原则包括:
- 统一抽象层:为多云多集群环境提供统一的API和管理界面
- 声明式配置:通过Infrastructure-as-Code的方式管理基础设施
- 开放集成:保持与现有云原生生态的兼容性,避免厂商锁定
- 边缘友好:原生支持边缘计算场景,实现云边协同
- 开箱即用:提供一键安装的云原生软件栈,降低使用门槛
1.2 核心技术栈集成与创新优势
Kurator集成了众多优秀的开源云原生项目,每个项目都在特定领域发挥着重要作用:
多集群管理:Karmada提供了跨集群的资源分发、弹性伸缩和故障转移能力;KubeEdge专注于边缘计算场景,实现了云边协同;Fleet作为Kurator的核心抽象,统一管理这些多集群能力。
服务网格与流量管理:Istio提供了强大的服务网格能力,包括流量管理、安全、可观察性等。Kurator在此基础上实现了跨集群的服务发现和通信。
监控与可观测性:Prometheus作为事实标准的监控系统,被Kurator深度集成,提供跨集群的指标聚合和告警能力。
GitOps与持续交付:FluxCD和Helm的集成使得Kurator能够以声明式的方式管理应用部署,实现GitOps工作流。
批处理与AI/ML工作负载:Volcano作为Kubernetes原生的批处理调度器,为AI/ML、大数据等计算密集型工作负载提供优化调度。
Kurator的创新优势在于将这些组件有机整合,提供统一的用户体验和管理界面。例如,在多集群管理方面,Kurator不仅集成了Karmada,还提供了集群生命周期管理、服务相同性、身份相同性等高级功能,这些都是单一组件无法提供的。
1.3 分布式云原生的未来发展趋势
Kurator未来发展方向参考图:
从社区参与和技术演进的角度看,分布式云原生技术将朝着以下几个方向发展:
标准化与互操作性:随着CNCF(云原生计算基金会)对多集群、边缘计算等领域的标准化工作推进,不同平台之间的互操作性将得到提升。Kurator作为集成平台,将在标准化过程中发挥重要作用。
AI与自动化的深度集成:未来的云原生平台将更加智能化,通过AI/ML技术实现自动扩缩容、异常检测、根因分析等能力。Volcano在AI工作负载调度方面的优化已经体现了这一趋势。
边缘计算的普及:5G、IoT的发展将推动边缘计算从概念走向大规模落地。KubeEdge等边缘计算框架的成熟,使得Kurator能够更好地支持边缘场景。
安全与合规的强化:随着数据隐私法规的完善,分布式环境下的安全与合规将成为重中之重。Kurator通过Kyverno等策略引擎,提供统一的安全策略管理。
开发者体验优化:简化开发者的使用门槛,提供更好的本地开发体验、调试工具和文档支持,将是云原生平台竞争的关键。
二、Kurator架构深度解析
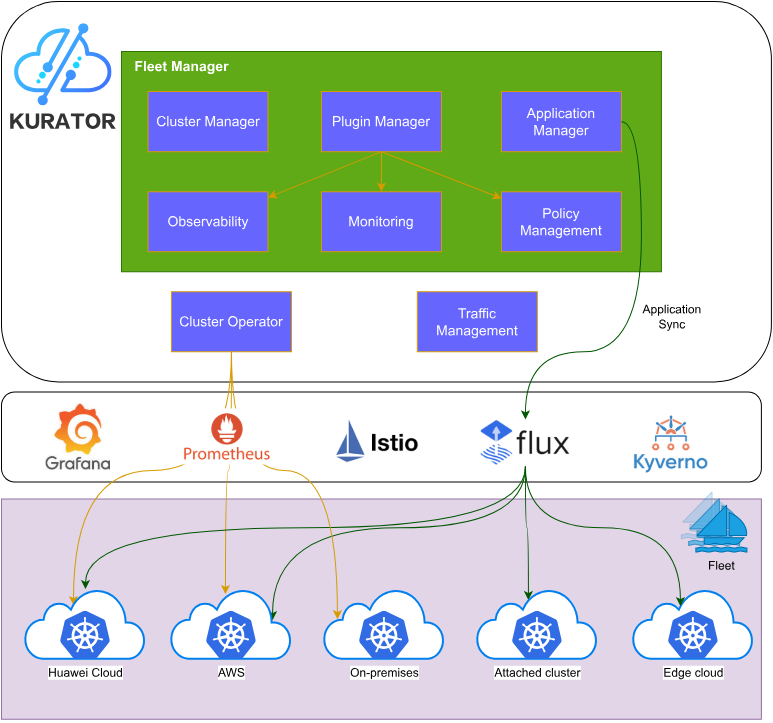
2.1 多云多集群管理架构
Kurator的架构设计以多云多集群管理为核心,通过分层抽象实现了复杂环境的统一管理。其架构可以分为以下几个层次:
基础设施层:涵盖公有云、私有云、边缘节点等不同类型的基础设施。Kurator通过统一的接口抽象这些异构资源,使得上层应用无需关心底层细节。
集群管理层:Fleet是Kurator的核心抽象,代表一组逻辑上相关的集群。Fleet支持集群的注册、注销、状态监控等生命周期管理操作。每个Fleet可以包含不同类型的集群(如云端Kubernetes集群、边缘KubeEdge集群等)。
应用管理层:提供跨集群的应用部署、服务发现、配置同步等能力。Kurator通过GitOps方式(基于FluxCD)实现应用的声明式管理,确保多集群环境的一致性。
策略管理层:通过Kyverno等策略引擎,实现跨集群的安全策略、资源配额、网络策略等的统一管理。这确保了即使在分布式环境中,也能保持一致的安全基线。
# Fleet资源示例
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
meta
name: production-fleet
spec:
clusters:
- name: cluster-east
kubeconfigSecret: cluster-east-kubeconfig
- name: cluster-west
kubeconfigSecret: cluster-west-kubeconfig
- name: edge-cluster-1
kubeconfigSecret: edge-cluster-1-kubeconfig
# 统一策略配置
policies:
- name: security-policy
type: kyverno
spec:
validationFailureAction: enforce
rules:
- name: require-pod-labels
match:
resources:
kinds:
- Pod
validate:
message: "Pods must have app label"
pattern:
meta
labels:
app: "?*"
2.2 统一资源编排与调度机制
Kurator在资源编排和调度方面的创新主要体现在对Karmada和Volcano的深度集成上。
Karmada集成:Karmada提供了跨集群的资源分发能力,Kurator在此基础上增加了更高级的抽象。例如,通过Fleet的命名空间相同性(Namespace Sameness)功能,可以在多个集群中创建同名的命名空间,确保应用在不同集群中有一致的运行环境。
Volcano调度优化:对于AI/ML、大数据等批处理工作负载,Kurator集成了Volcano调度器。Volcano提供了队列(Queue)、PodGroup等高级调度概念,支持gang调度、优先级调度、抢占等高级功能,显著提升了批处理工作负载的资源利用率和执行效率。
统一调度API:Kurator提供了统一的调度API,屏蔽了底层不同调度器的复杂性。开发者可以通过简单的配置指定应用的调度策略,而无需深入了解Karmada或Volcano的内部机制。
# Volcano Job示例
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: ai-training-job
spec:
minAvailable: 4
schedulerName: volcano
queue: high-priority
tasks:
- replicas: 4
name: worker
template:
spec:
containers:
- image: tensorflow/tensorflow:latest-gpu
name: tensorflow
resources:
limits:
nvidia.com/gpu: 1
nodeSelector:
node-type: gpu-node
2.3 服务网格与可观测性集成
lstio服务网格参考图: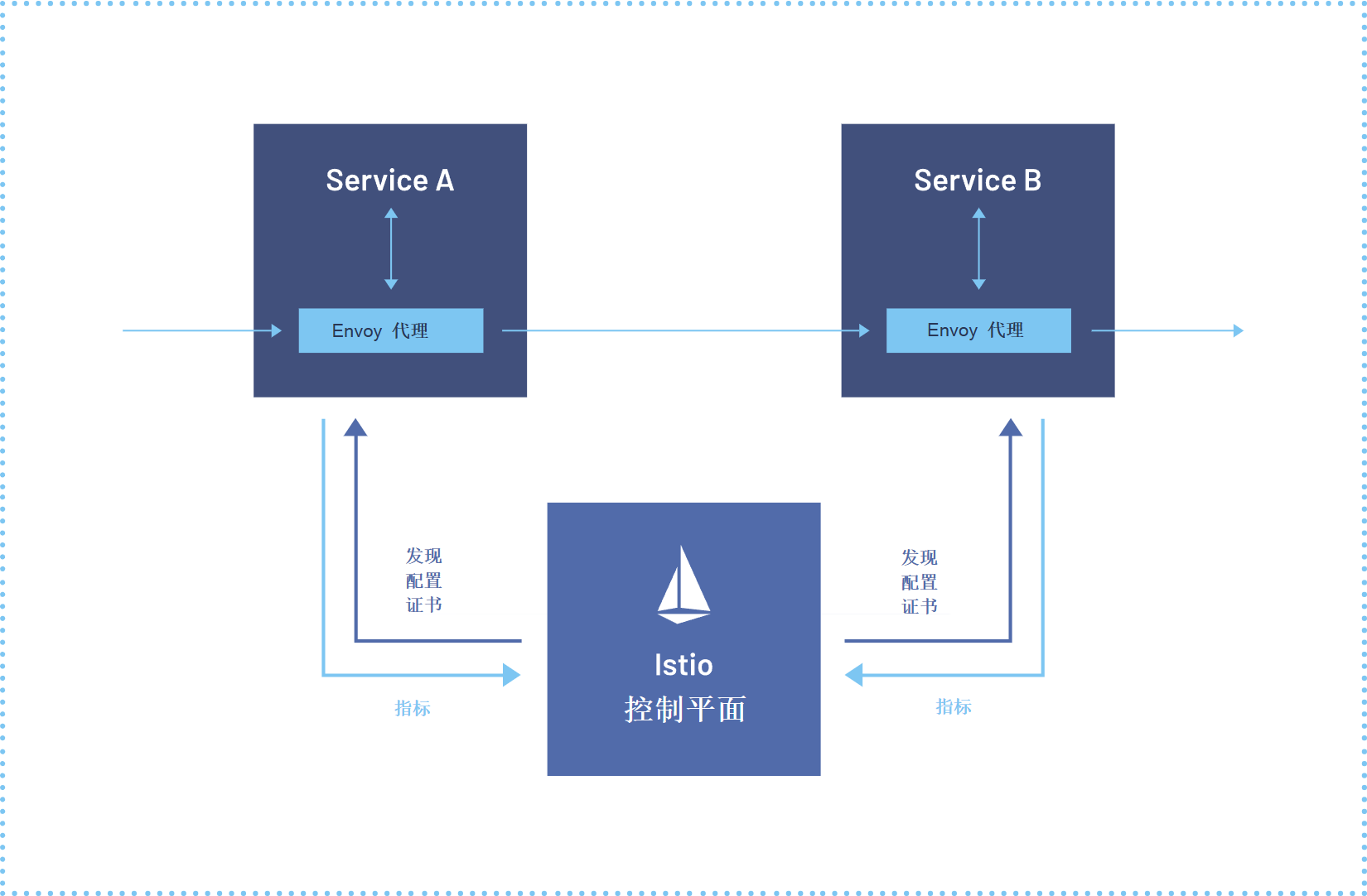
在服务网格和可观测性方面,Kurator深度集成了Istio和Prometheus,为分布式环境提供统一的服务治理和监控能力。
跨集群服务发现:Kurator通过Istio的多集群支持,实现了跨集群的服务发现和通信。服务可以透明地调用其他集群中的服务,无需关心底层网络拓扑。
统一流量管理:Istio的流量管理能力(如金丝雀发布、蓝绿部署、故障注入等)在Kurator中得到了增强,支持跨集群的流量策略定义。例如,可以定义将10%的流量导向新版本服务,无论该服务部署在哪个集群。
聚合监控指标:Kurator集成了Prometheus,能够从所有集群中收集监控指标,并在统一的仪表板中展示。这包括基础设施指标(CPU、内存、网络)、应用指标(请求延迟、错误率)以及业务指标。
分布式追踪:通过Jaeger或Zipkin集成,Kurator支持跨集群的分布式追踪,帮助开发者理解请求在多个服务和集群间的流转路径,快速定位性能瓶颈。
# Istio跨集群Gateway配置
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
meta
name: cross-cluster-gateway
spec:
selector:
istio: ingressgateway
servers:
- port:
number: 443
name: https
protocol: HTTPS
tls:
mode: SIMPLE
credentialName: cluster-tls-cert
hosts:
- "*.example.com"
---
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
meta
name: cross-cluster-service
spec:
hosts:
- service.example.com
gateways:
- cross-cluster-gateway
http:
- route:
- destination:
host: service-prod
subset: v1
weight: 90
- destination:
host: service-staging
subset: v2
weight: 10
三、环境搭建与安装实践
3.1 前置条件与环境准备
在开始安装Kurator之前,需要准备以下环境和依赖:
硬件要求:
- 管理节点:至少4核CPU、8GB内存、50GB存储
- 工作节点:根据业务需求配置,建议至少2核CPU、4GB内存
- 网络:稳定的互联网连接,各节点间网络互通
软件依赖:
- 操作系统:Linux(推荐Ubuntu 20.04/22.04或CentOS 7/8)
- Kubernetes:v1.23或更高版本
- Docker或containerd:容器运行时
- kubectl:Kubernetes命令行工具
- helm:Helm包管理器
- git:版本控制工具
网络准备:
- 配置DNS解析,确保集群内服务发现正常工作
- 开放必要的端口(6443、2379-2380、10250等)
- 如果涉及跨集群通信,需要确保集群间网络连通性
# 安装基础依赖
sudo apt-get update
sudo apt-get install -y apt-transport-https ca-certificates curl gnupg lsb-release git wget
# 安装Docker
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
echo "deb [arch=amd64 signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
sudo apt-get install -y docker-ce docker-ce-cli containerd.io
# 安装kubectl
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl"
sudo install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl
# 安装helm
curl https://baltocdn.com/helm/signing.asc | sudo apt-key add -
echo "deb https://baltocdn.com/helm/stable/debian/ all main" | sudo tee /etc/apt/sources.list.d/helm-stable-debian.list
sudo apt-get update
sudo apt-get install -y helm
3.2 Kurator源码获取与安装流程
获取Kurator源码有两种方式,根据要求,我们使用git clone命令:
可以看到这是gitCode的源码文件
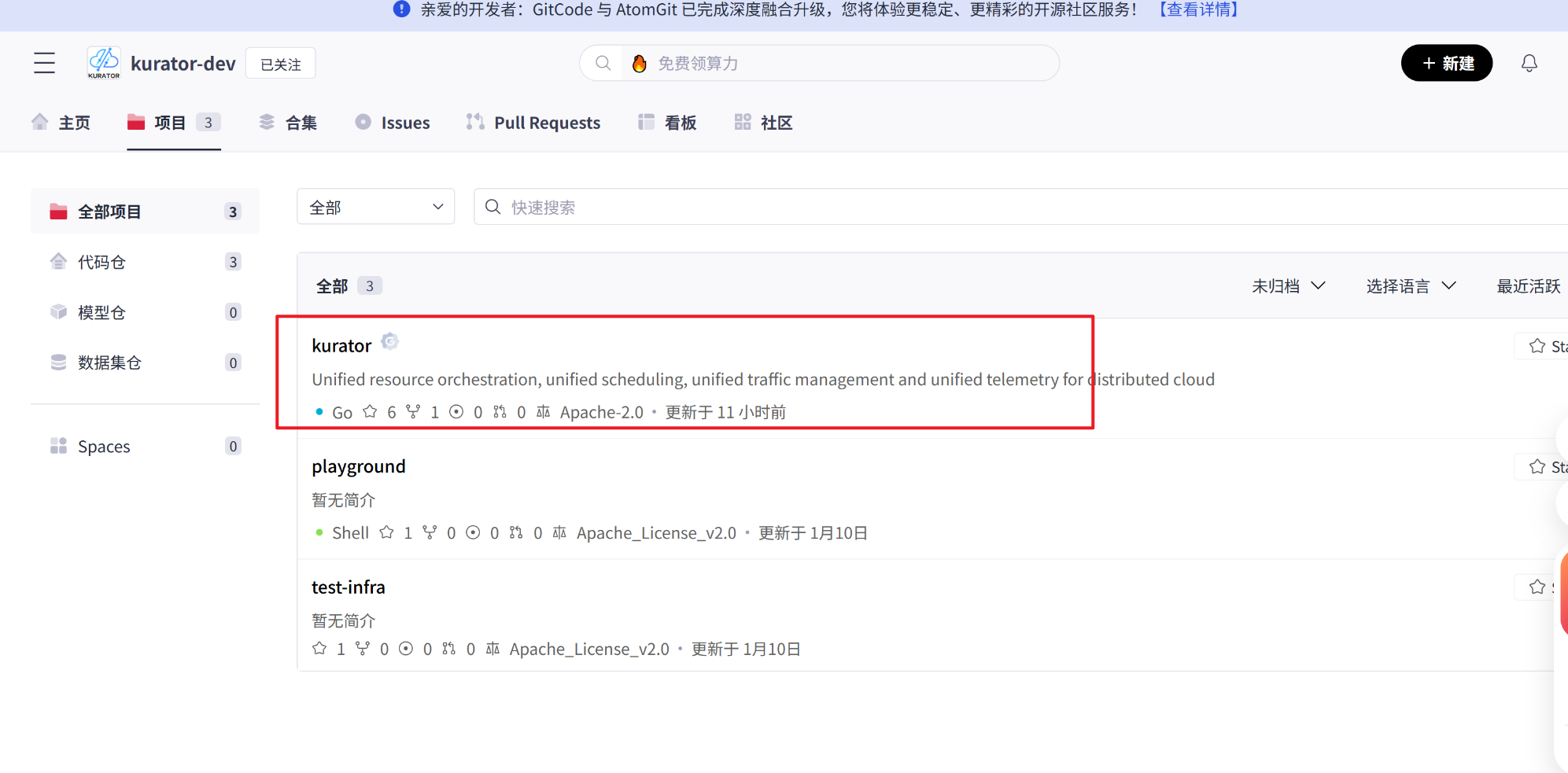
我们可以拉取下来
git clone https://github.com/kurator-dev/kurator.git
源码文件如下,接下来就可以使用了
安装Kurator主要有两种方式:通过Helm Chart安装或通过kuratorctl命令行工具安装。这里我们介绍使用kuratorctl的方式:
# 构建kuratorctl工具
make build
sudo cp _output/bin/kuratorctl /usr/local/bin/
# 初始化Kurator
kuratorctl init --components all
# 验证安装
kubectl get pods -n kurator-system
安装过程中,Kurator会部署以下核心组件:
- kurator-controller-manager:核心控制器,管理Fleet、Cluster等自定义资源
- kurator-webhook:准入控制和验证webhook
- fleet-manager:Fleet管理控制器
- karmada-controller:Karmada集成控制器
- kubeedge-controller:KubeEdge集成控制器
- volcano-scheduler:Volcano调度器
- istio-system:Istio服务网格组件
- monitoring-system:Prometheus监控组件
对于生产环境,建议使用Helm Chart进行更精细的配置:
# 添加Kurator Helm仓库
helm repo add kurator https://kurator-dev.github.io/charts
helm repo update
# 创建命名空间
kubectl create namespace kurator-system
# 安装Kurator
helm install kurator kurator/kurator \
--namespace kurator-system \
--set components.karmada.enabled=true \
--set components.kubeedge.enabled=true \
--set components.volcano.enabled=true \
--set components.istio.enabled=true \
--set components.prometheus.enabled=true
3.3 验证安装与基础配置
安装完成后,需要验证各组件是否正常运行,并进行基础配置:
# 检查Kurator核心组件状态
kubectl get pods -n kurator-system -w
# 检查Fleet自定义资源定义
kubectl get crd | grep kurator.dev
# 创建第一个Fleet
cat <<EOF | kubectl apply -f -
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
meta
name: my-first-fleet
spec:
clusters: []
EOF
# 配置集群访问凭证
# 假设我们有两个集群:cluster-1和cluster-2
kubectl create secret generic cluster-1-kubeconfig --from-file=kubeconfig=./cluster-1.kubeconfig -n kurator-system
kubectl create secret generic cluster-2-kubeconfig --from-file=kubeconfig=./cluster-2.kubeconfig -n kurator-system
# 将集群加入Fleet
cat <<EOF | kubectl apply -f -
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
meta
name: my-first-fleet
spec:
clusters:
- name: cluster-1
kubeconfigSecret: cluster-1-kubeconfig
- name: cluster-2
kubeconfigSecret: cluster-2-kubeconfig
EOF
完成基础配置后,可以通过Kurator Dashboard进行可视化管理:
# 端口转发访问Dashboard
kubectl port-forward svc/kurator-dashboard -n kurator-system 8080:80
# 访问 http://localhost:8080
Dashboard提供了集群管理、应用部署、监控告警等一站式管理界面,大大简化了多集群环境的操作复杂度。
四、Fleet多集群管理实战
4.1 Fleet集群注册与生命周期管理
Fleet 的集群注册官方参考图: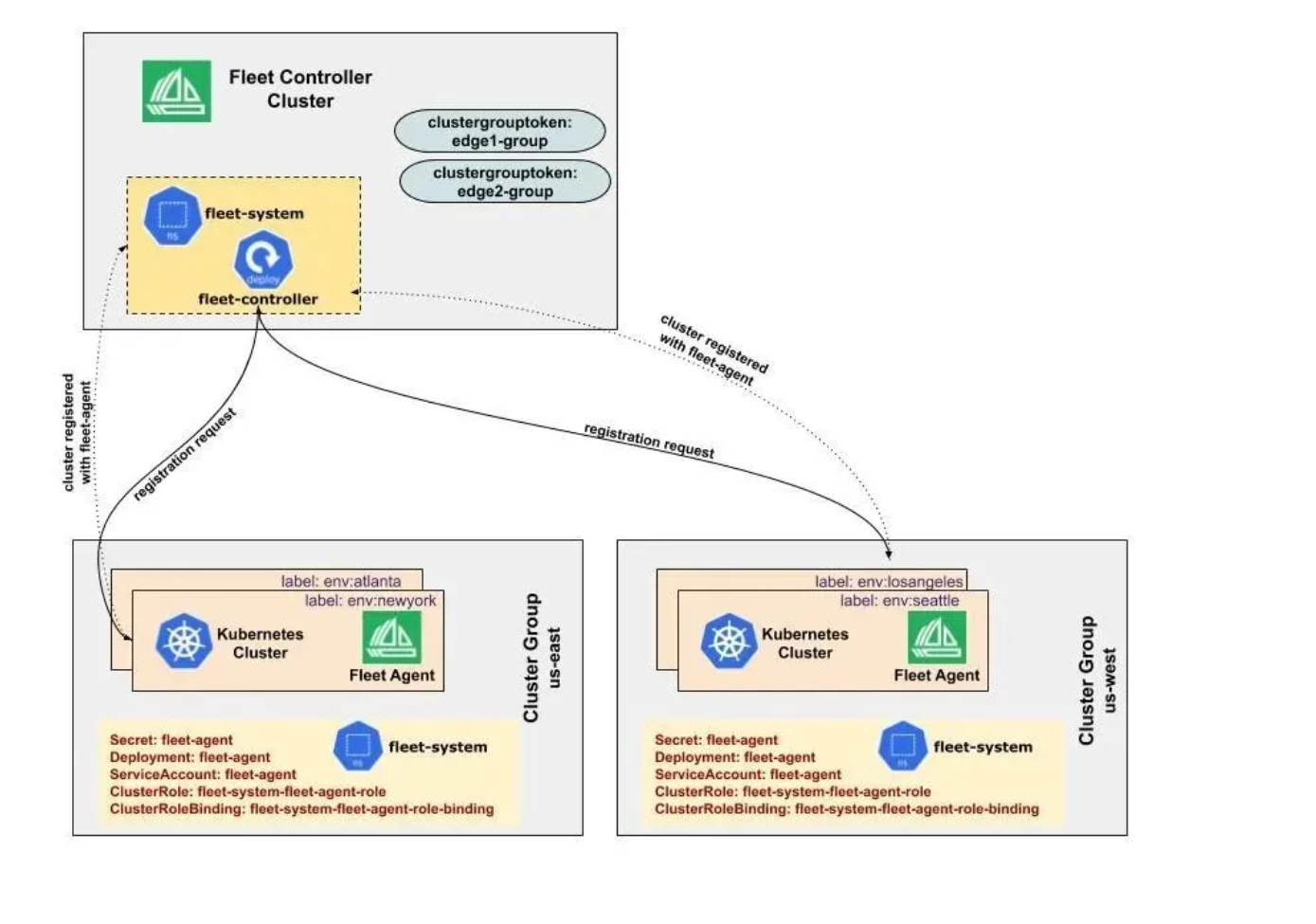
Kurator集群生命周期管理官方参考图: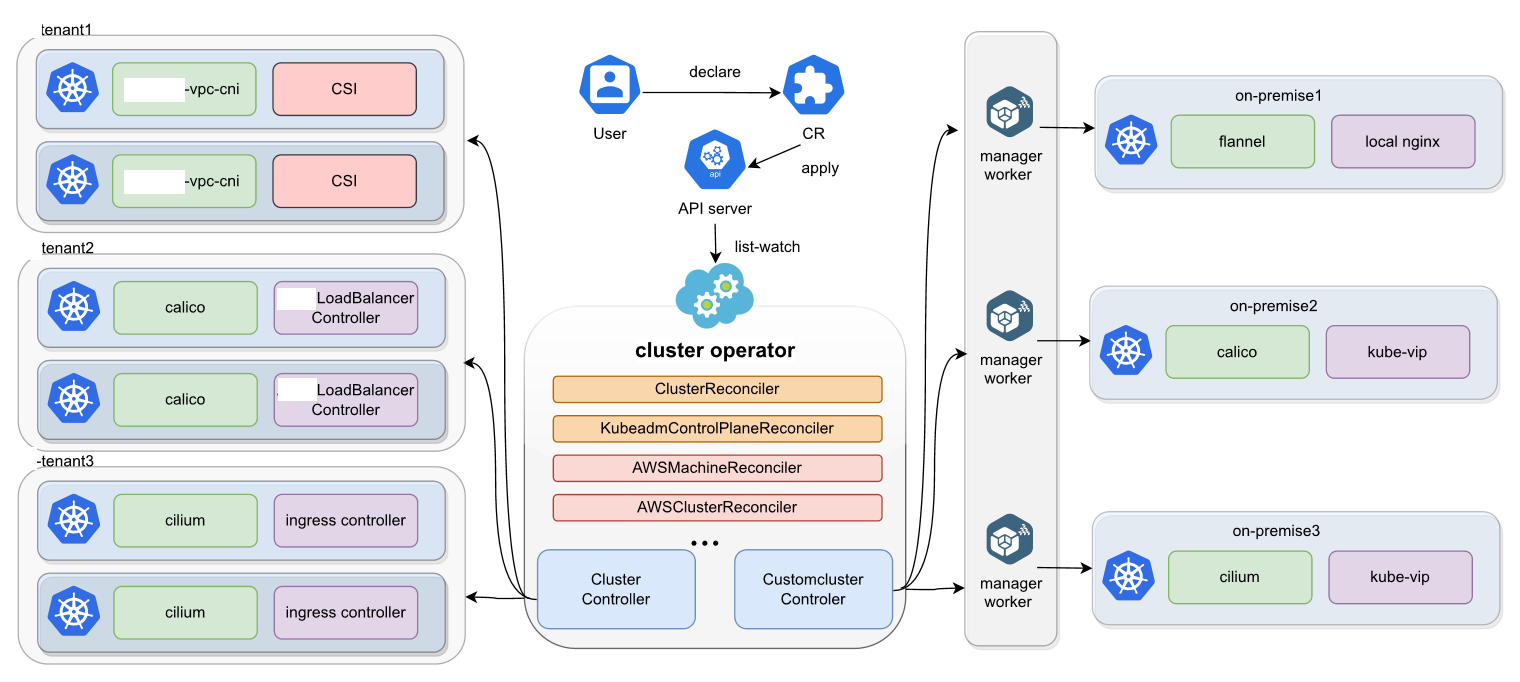
Fleet是Kurator中管理多集群的核心抽象。一个Fleet代表一组逻辑上相关的集群,可以是同一环境(如生产环境)的集群,也可以是同一地域的集群。Fleet提供了集群的注册、状态监控、升级、备份等全生命周期管理能力。
集群注册流程:
- 准备目标集群的kubeconfig文件
- 将kubeconfig创建为Kubernetes Secret
- 在Fleet资源中引用该Secret
- Fleet控制器自动注册集群并同步状态
# 完整的Fleet配置示例
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
meta
name: production-fleet
namespace: kurator-system
spec:
# 集群列表
clusters:
- name: aws-us-east-1
kubeconfigSecret: aws-us-east-1-kubeconfig
labels:
region: us-east-1
cloud: aws
env: production
- name: azure-westeurope
kubeconfigSecret: azure-westeurope-kubeconfig
labels:
region: westeurope
cloud: azure
env: production
- name: edge-site-shanghai
kubeconfigSecret: edge-site-shanghai-kubeconfig
labels:
location: shanghai
type: edge
env: production
# 集群生命周期管理配置
lifecycle:
upgradeStrategy: rollingUpdate
maxUnavailable: 1
backup:
enabled: true
schedule: "0 2 * * *"
retention: 7
# 资源配额
resourceQuota:
cpu: "100"
memory: 200Gi
storage: 1000Gi
Fleet控制器会定期检查集群状态,包括:
- API Server可用性
- 节点状态
- 资源使用情况
- 组件健康状态
当集群状态异常时,Fleet控制器会触发告警,并根据配置的策略进行自动修复或通知管理员。
4.2 跨集群服务相同性实现
Fleet 队列中的服务相同性官方参考图: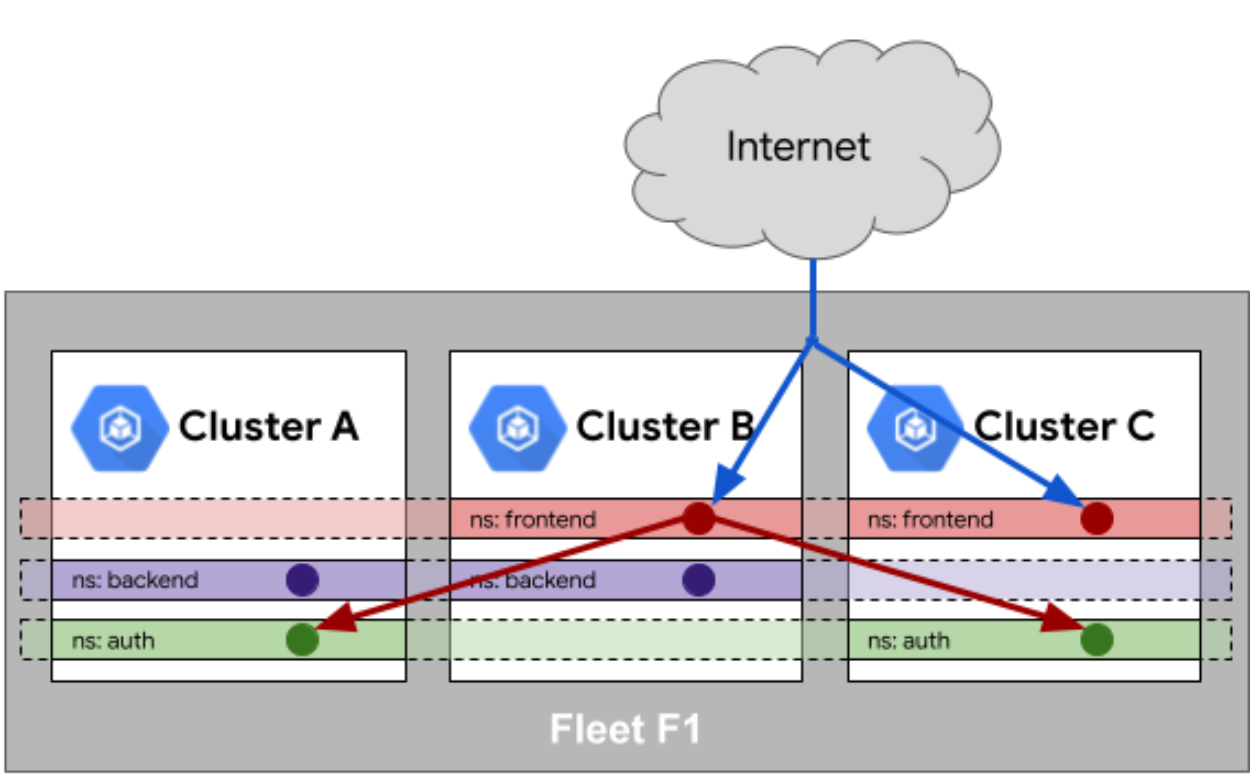
在多集群环境中,服务相同性(Service Sameness)是一个关键需求。它确保在不同集群中部署的同名服务具有相同的行为和访问方式。Kurator通过以下机制实现服务相同性:
服务DNS统一:Kurator为Fleet中的所有集群配置统一的DNS域,例如<service-name>.<namespace>.svc.fleet.kurator.dev。无论服务部署在哪个集群,都可以通过这个统一的DNS名称访问。
服务网格集成:通过Istio的服务网格能力,Kurator实现了跨集群的服务发现和负载均衡。Istio控制平面会聚合所有集群的服务信息,数据平面(Envoy代理)会根据全局服务视图进行流量路由。
外部访问统一:对于需要从集群外部访问的服务,Kurator提供统一的Ingress配置,支持跨集群的流量分配策略。
# 跨集群服务配置示例
apiVersion: v1
kind: Service
meta
name: frontend-service
namespace: default
annotations:
# 指定服务在Fleet中的相同性
fleet.kurator.dev/service-sameness: "true"
# 跨集群流量分配策略
fleet.kurator.dev/traffic-strategy: weighted
spec:
selector:
app: frontend
ports:
- port: 80
targetPort: 8080
type: ClusterIP
---
# 跨集群Ingress配置
apiVersion: networking.k8s.io/v1
kind: Ingress
meta
name: frontend-ingress
namespace: default
spec:
rules:
- host: frontend.example.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: frontend-service
port:
number: 80
tls:
- hosts:
- frontend.example.com
secretName: frontend-tls
当用户访问frontend-service.default.svc.fleet.kurator.dev时,请求会被智能地路由到最近的或负载最低的集群中的服务实例,实现透明的跨集群服务访问。
4.3 统一策略管理与安全控制
Kurator 统一策略管理参考图: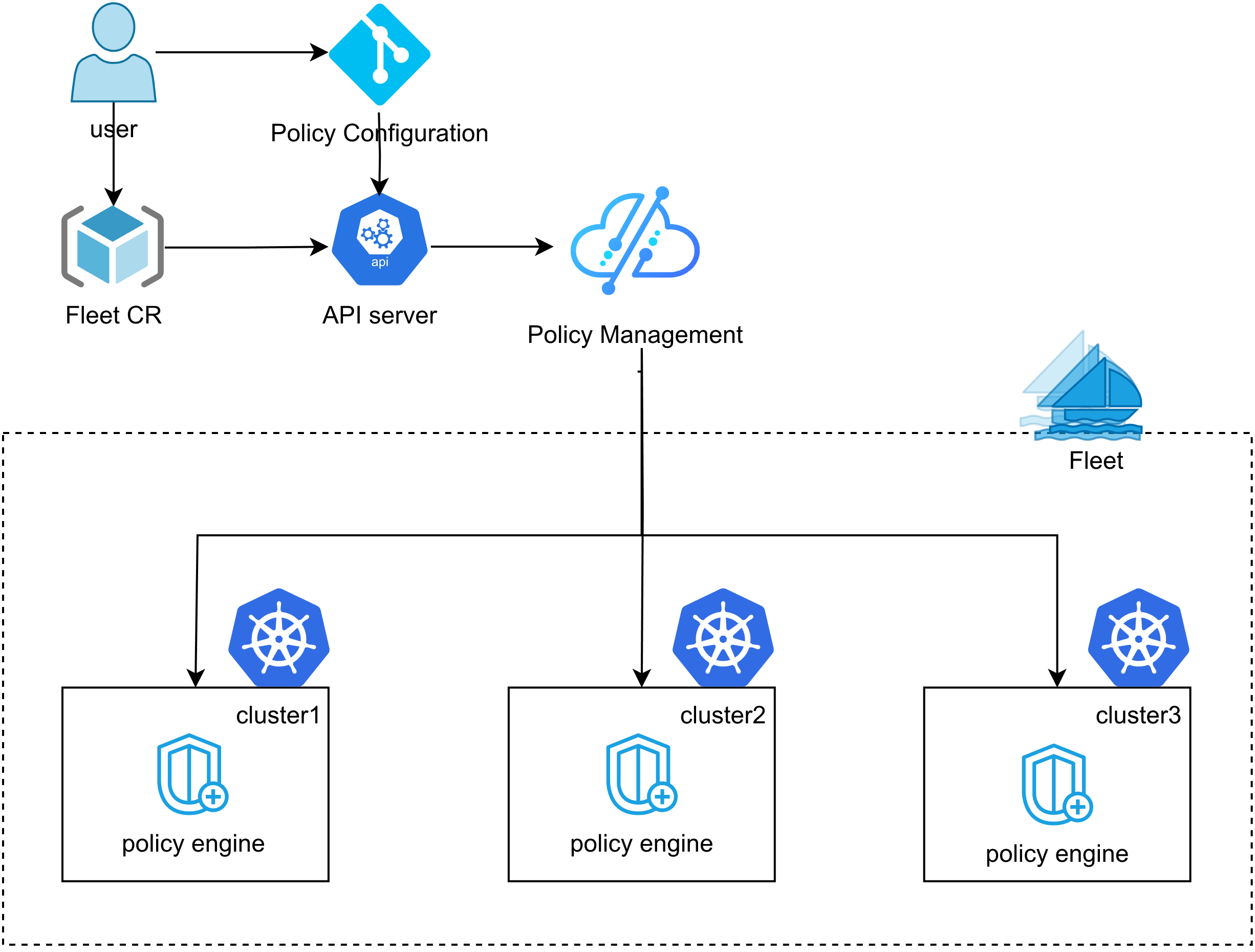
在多集群环境中,保持一致的安全策略至关重要。Kurator集成了Kyverno等策略引擎,提供统一的策略管理能力。
策略类型:
- Pod安全策略:控制Pod的运行权限、卷挂载、能力集等
- 网络策略:定义集群内外的网络访问规则
- 资源配额:限制命名空间或用户的资源使用
- 配置合规:确保资源配置符合企业标准和最佳实践
策略分发机制:Kurator将策略定义为Fleet级别的资源,自动分发到所有注册的集群。当新集群加入Fleet时,策略会自动同步;当策略更新时,所有集群会自动应用新策略。
# Kyverno策略示例:强制所有Pod设置资源请求和限制
apiVersion: kyverno.io/v1
kind: ClusterPolicy
meta
name: require-resources
annotations:
policies.kurator.dev/enabled: "true"
policies.kurator.dev/fleet: production-fleet
spec:
validationFailureAction: enforce
rules:
- name: validate-resources
match:
resources:
kinds:
- Pod
validate:
message: "CPU and memory resource requests and limits are required"
pattern:
spec:
containers:
- resources:
requests:
memory: "?*"
cpu: "?*"
limits:
memory: "?*"
cpu: "?*"
- name: prevent-privileged
match:
resources:
kinds:
- Pod
validate:
message: "Privileged containers are not allowed"
pattern:
spec:
containers:
- securityContext:
privileged: "false"
Kurator还提供了策略审计功能,定期检查集群中资源是否符合定义的策略,并生成合规报告。这在金融、医疗等高度监管的行业中尤为重要。
五、GitOps与CI/CD流水线实践
5.1 GitOps在边缘计算中的应用
边缘计算中的 GitOps 官方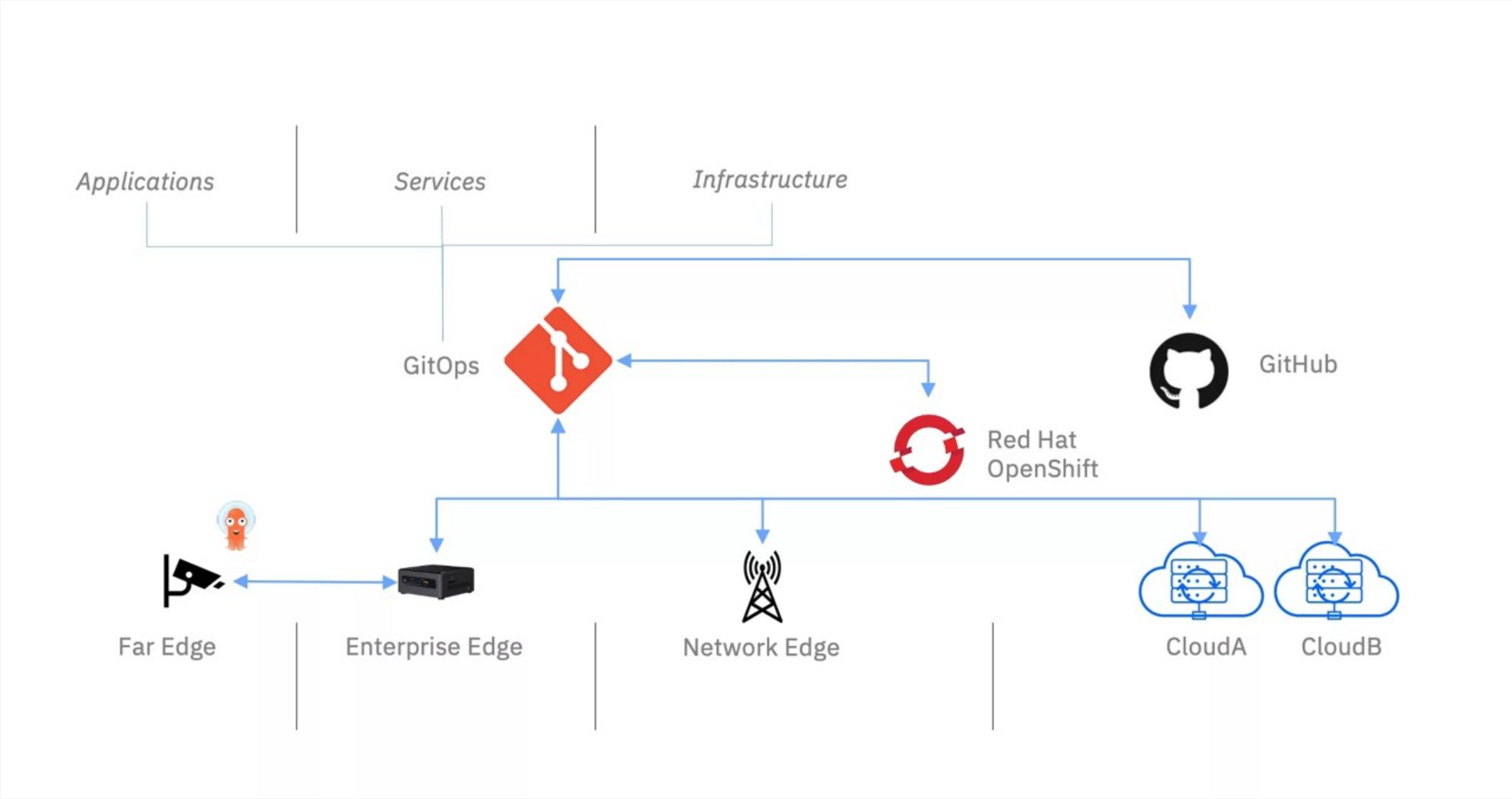
GitOps作为一种声明式的基础设施和应用管理方法,在边缘计算场景中具有独特优势。边缘环境通常面临网络不稳定、资源受限、管理复杂等挑战,GitOps的以下特性恰好能应对这些挑战:
离线操作能力:边缘节点可能处于弱网或断网状态,GitOps的"拉模式"(Pull-based)允许边缘节点在连接恢复时自动同步期望状态,而不需要中心控制平面的持续连接。
版本控制与回滚:所有配置变更都通过Git仓库进行版本控制,任何问题都可以快速回滚到已知的良好状态,这在边缘环境的故障恢复中至关重要。
安全合规:Git的审计日志提供了完整的变更历史,满足边缘计算场景的合规要求。同时,通过PR(Pull Request)流程,可以实现变更的审批和审核。
一致性保证:无论边缘节点数量多少,GitOps都能确保所有节点最终达到相同的配置状态,解决了边缘环境的一致性难题。
Kurator通过集成FluxCD,为边缘计算提供了完整的GitOps支持。以下是一个边缘计算场景的GitOps架构:
# FluxCD GitRepository配置
apiVersion: source.toolkit.fluxcd.io/v1beta1
kind: GitRepository
meta
name: edge-config-repo
namespace: kurator-system
spec:
url: https://github.com/your-org/edge-configs.git
ref:
branch: main
interval: 5m
secretRef:
name: git-repo-secret
---
# Kustomization配置,定义如何应用配置
apiVersion: kustomize.toolkit.fluxcd.io/v1beta1
kind: Kustomization
meta
name: edge-apps
namespace: kurator-system
spec:
targetNamespace: edge-apps
path: ./edge-apps
prune: true
sourceRef:
kind: GitRepository
name: edge-config-repo
interval: 5m
timeout: 2m
# 边缘环境的健康检查
healthChecks:
- apiVersion: apps/v1
kind: Deployment
name: edge-collector
namespace: edge-apps
5.2 FluxCD集成与Helm应用管理
FluxCD Helm 应用的示意图: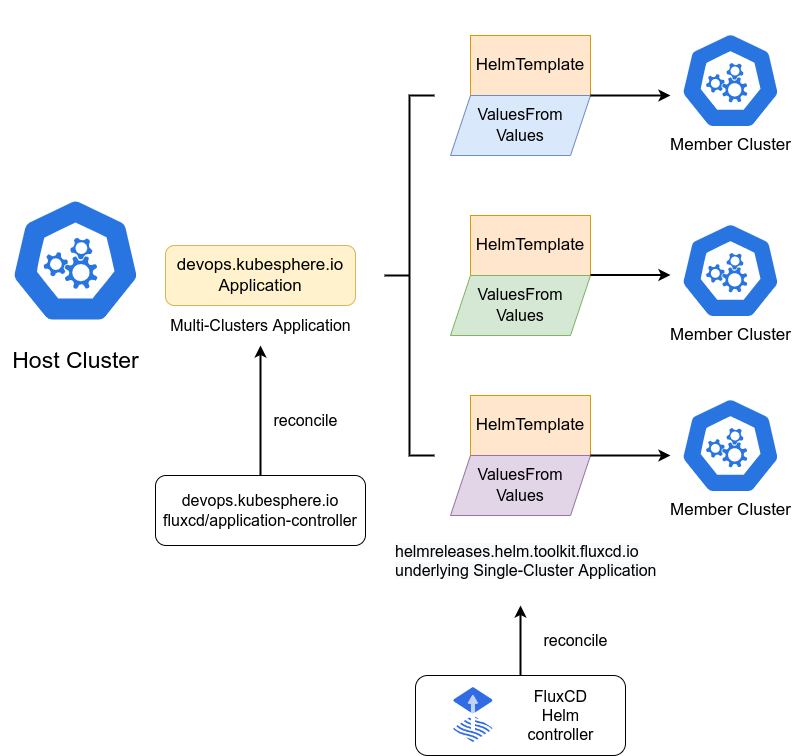
Kurator深度集成了FluxCD和Helm,提供了强大的应用管理能力。FluxCD负责从Git仓库同步配置,Helm负责应用的打包和部署,两者结合实现了完整的GitOps工作流。
FluxCD核心组件:
- Source Controller:负责监控Git仓库、Helm仓库等源的变化
- Kustomize Controller:负责应用Kustomize配置
- Helm Controller:负责管理Helm Release生命周期
- Notification Controller:负责发送事件通知
Helm应用管理:Kurator通过FluxCD Helm控制器,实现了Helm Chart的自动化部署和升级。支持依赖管理、版本控制、回滚等高级功能。
# HelmRelease配置示例
apiVersion: helm.toolkit.fluxcd.io/v2beta1
kind: HelmRelease
metadata:
name: prometheus
namespace: monitoring
spec:
chart:
spec:
chart: prometheus
version: "15.5.1"
sourceRef:
kind: HelmRepository
name: prometheus-community
namespace: flux-system
interval: 5m
# 值覆盖
values:
server:
persistentVolume:
enabled: true
size: 10Gi
resources:
limits:
cpu: 500m
memory: 1Gi
requests:
cpu: 200m
memory: 512Mi
# 依赖其他应用
dependsOn:
- name: cert-manager
namespace: cert-manager
# 健康检查
install:
createNamespace: true
remediation:
retries: 3
upgrade:
cleanupOnFail: true
remediation:
retries: 3
Kurator还提供了Helm Chart的统一管理界面,支持Chart版本控制、依赖解析、配置验证等功能,大大简化了复杂应用的管理。
5.3 Kurator CI/CD流水线构建
Kurator CI/CD流水线过程如图所示: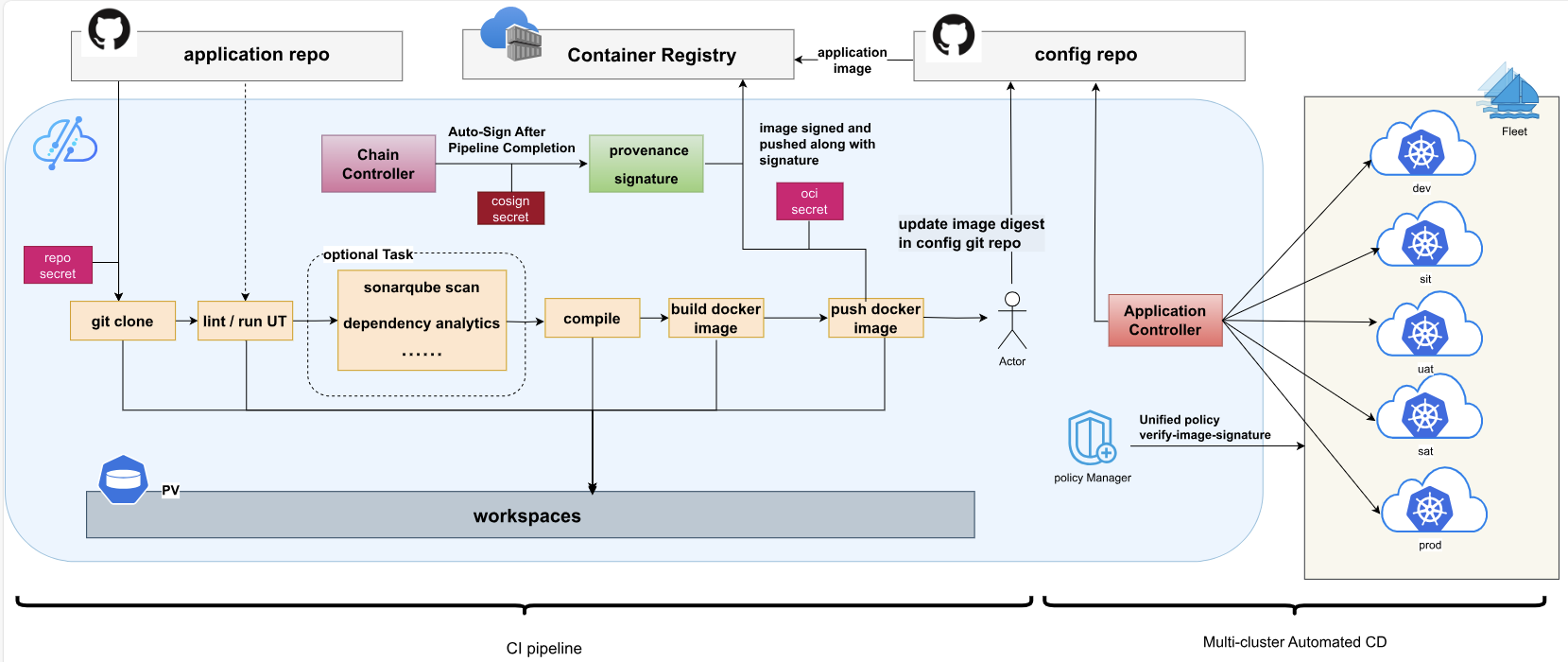
基于GitOps理念,Kurator构建了完整的CI/CD流水线,实现了从代码提交到生产环境部署的自动化流程。
流水线阶段:
- 代码构建:通过Tekton或Argo Workflows执行代码构建、单元测试
- 镜像构建:构建Docker镜像并推送到镜像仓库
- 配置生成:生成Kubernetes manifest或Helm values
- Git提交:将配置变更提交到Git仓库
- 自动同步:FluxCD检测到Git变更,自动同步到集群
- 验证与监控:验证部署结果,监控应用健康状态
多环境支持:Kurator的CI/CD流水线支持开发、测试、预发布、生产等多环境,通过不同的Git分支或目录结构实现环境隔离。
# Tekton流水线示例
apiVersion: tekton.dev/v1beta1
kind: Pipeline
meta
name: app-deploy-pipeline
spec:
params:
- name: git-repo-url
type: string
- name: git-revision
type: string
- name: image-tag
type: string
tasks:
- name: clone-repo
taskRef:
name: git-clone
params:
- name: url
value: $(params.git-repo-url)
- name: revision
value: $(params.git-revision)
- name: build-image
taskRef:
name: kaniko-build
params:
- name: image-tag
value: $(params.image-tag)
runAfter:
- clone-repo
- name: generate-manifests
taskRef:
name: kustomize-build
params:
- name: environment
value: staging
runAfter:
- build-image
- name: commit-to-config-repo
taskRef:
name: git-commit
params:
- name: repo-url
value: https://github.com/your-org/configs.git
- name: commit-message
value: "Deploy app $(params.image-tag)"
runAfter:
- generate-manifests
Kurator的CI/CD流水线具有以下优势:
- 声明式配置:所有流水线步骤都通过YAML定义,可版本控制
- 环境一致性:通过相同的流程管理所有环境,减少环境差异
- 安全合规:所有变更都经过Git审计,满足合规要求
- 自助服务:开发团队可以自主管理应用部署,无需运维介入
六、Karmada跨集群调度深度解析
6.1 Karmada架构与核心概念
Karmada架构官方参考图: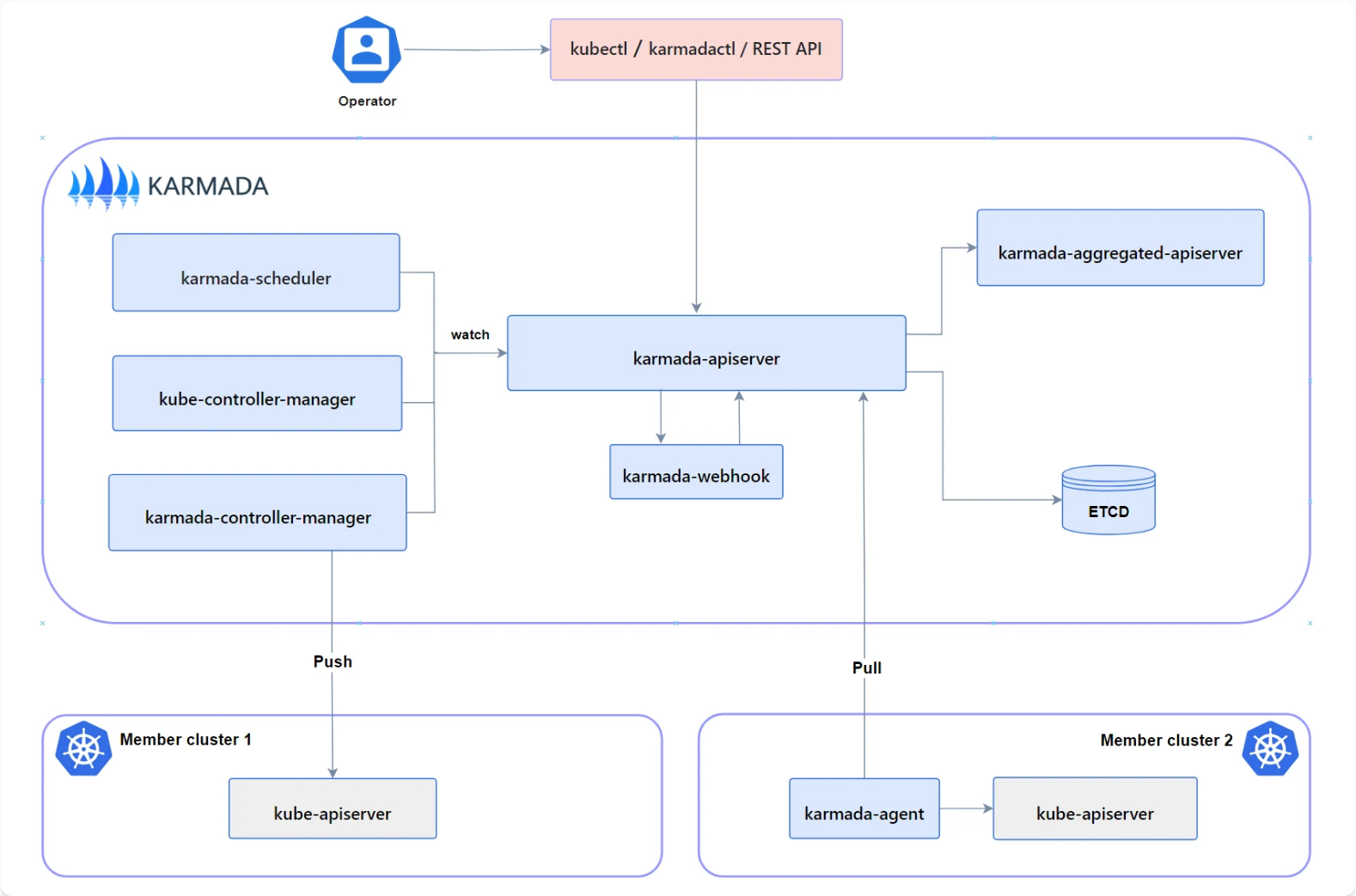
Karmada是Kurator集成的核心多集群管理组件,它提供了跨集群的资源调度、分发和弹性伸缩能力。Karmada的架构设计借鉴了Kubernetes的声明式API和控制器模式,同时针对多集群场景进行了优化。
Karmada核心组件:
- karmada-control-plane:控制平面,运行API Server、Controller Manager、Scheduler等
- karmada-agent:部署在成员集群中,负责与控制平面通信和资源同步
- karmada-scheduler:负责将资源调度到合适的成员集群
- karmada-controller-manager:包含多个控制器,管理PropagationPolicy、Cluster等资源
核心概念:
- PropagationPolicy:定义资源如何分发到成员集群,包括集群选择、副本分配等策略
- Cluster:表示一个成员集群,包含集群状态、资源容量等信息
- ResourceBinding:资源在成员集群中的绑定信息,由系统自动生成
- Work:在成员集群中实际创建的资源对象
Kurator对Karmada进行了增强,提供了更高级的抽象和更友好的用户界面。例如,Kurator的Fleet概念封装了Karmada的Cluster和PropagationPolicy,简化了多集群管理的复杂性。
# Karmada PropagationPolicy示例
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
meta
name: frontend-policy
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: frontend
placement:
clusterAffinity:
clusterNames:
- cluster-east
- cluster-west
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightList:
- targetCluster:
clusterNames:
- cluster-east
weight: 60
- targetCluster:
clusterNames:
- cluster-west
weight: 40
6.2 跨集群弹性伸缩实践
Kurator通过Karmada实现了跨集群的弹性伸缩能力,可以根据全局负载情况动态调整各集群中的应用副本数。
弹性伸缩策略:
- 基于指标:根据CPU、内存、自定义指标等进行伸缩
- 基于时间:根据预定义的时间表进行伸缩(如工作日/周末)
- 基于集群负载:根据各集群的资源利用率进行动态分配
- 手动干预:支持手动调整副本数,系统会自动同步到所有集群
实现机制:Kurator扩展了Kubernetes的HorizontalPodAutoscaler(HPA),创建了MultiClusterHPA资源,能够跨集群收集指标并进行全局伸缩决策。
# MultiClusterHPA配置示例
apiVersion: autoscaling.kurator.dev/v1alpha1
kind: MultiClusterHPA
meta
name: frontend-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: frontend
minReplicas: 10
maxReplicas: 100
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
clusterReplicaDistribution:
- clusterName: cluster-east
maxReplicas: 60
minReplicas: 5
- clusterName: cluster-west
maxReplicas: 40
minReplicas: 5
strategy:
type: Balanced
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
当全局CPU利用率超过70%时,MultiClusterHPA会自动增加总副本数,并根据各集群的当前负载情况智能分配新增的副本。例如,如果cluster-east的CPU利用率为80%,cluster-west为60%,则新增的副本会优先分配到cluster-west,以实现负载均衡。
6.3 资源分发与同步机制
Karmada的资源分发机制是Kurator多集群能力的核心。它通过声明式API和最终一致性模型,确保资源在多个集群中保持同步。
分发流程:
- 用户在Karmada控制平面创建资源(如Deployment)
- PropagationPolicy匹配该资源,创建ResourceBinding
- karmada-scheduler为ResourceBinding分配目标集群
- karmada-controller-manager创建Work对象,包含要分发的资源
- karmada-agent将Work同步到成员集群,创建实际资源
- karmada-agent监控成员集群中资源的状态,同步回控制平面
冲突解决:当多个集群对同一资源进行修改时,Karmada采用"控制平面优先"的原则,控制平面的变更会覆盖成员集群的本地变更。Kurator在此基础上增加了冲突检测和通知机制,避免意外覆盖。
状态聚合:Kurator提供了统一的资源状态视图,聚合了所有集群中资源的状态。例如,一个Deployment的全局状态是所有集群中对应Deployment状态的聚合,包括副本数、就绪状态、健康状态等。
# 查看跨集群Deployment状态
kuratorctl get deployment frontend --cluster=cluster-east,cluster-west
# 输出示例
NAME CLUSTER READY UP-TO-DATE AVAILABLE AGE
frontend cluster-east 6/6 6 6 2d
frontend cluster-west 4/4 4 4 2d
frontend GLOBAL 10/10 10 10 2d
这种资源分发与同步机制确保了多集群环境中的一致性和可靠性,是Kurator实现统一管理的基础。
七、KubeEdge边缘计算集成
7.1 KubeEdge核心组件与架构
KubeEdge是Kurator集成的边缘计算框架,它将Kubernetes的能力扩展到边缘节点,实现了云边协同。KubeEdge的架构设计考虑了边缘环境的特殊性:网络不稳定、资源受限、设备异构等。
KubeEdge核心组件:
- CloudCore:运行在云端,负责与Kubernetes API Server通信,管理边缘节点
- CloudHub:WebSocket服务器,与EdgeHub通信
- EdgeController:管理边缘节点的生命周期
- DeviceController:管理边缘设备
- EdgeCore:运行在边缘节点,负责运行应用和管理设备
- EdgeHub:与CloudHub通信,同步配置和状态
- MetaManager:本地数据库,缓存云端配置
- Edged:轻量级Kubelet,管理Pod生命周期
- DeviceTwin:设备状态同步
- EventBus:MQTT客户端,与设备通信
- ServiceBus:HTTP客户端,访问云服务
Kurator对KubeEdge进行了增强集成,提供了统一的边缘节点管理界面、监控告警、应用分发等能力。通过Kurator,用户可以将边缘节点视为普通的Kubernetes节点,使用相同的工具和API进行管理。
# KubeEdge节点配置示例
apiVersion: edge.kurator.dev/v1alpha1
kind: EdgeNode
metadata:
name: edge-node-001
spec:
labels:
location: factory-floor
type: industrial
taints:
- key: edge
value: "true"
effect: NoSchedule
resources:
cpu: "4"
memory: 8Gi
storage: 100Gi
network:
type: cellular
bandwidth: 10Mbps
latency: 100ms
# 设备管理
devices:
- name: temperature-sensor
protocol: modbus
address: 192.168.1.100
- name: camera-001
protocol: rtsp
address: rtsp://192.168.1.101/stream
7.2 边缘-云协同工作流
Kurator实现了完整的边缘-云协同工作流,包括应用分发、数据同步、策略执行等。
应用分发流程:
- 用户在云端定义应用(Deployment、Service等)
- Kurator根据节点标签和污点,将应用调度到合适的边缘节点
- KubeEdge将应用配置同步到边缘节点
- EdgeCore在边缘节点启动应用
- 应用状态同步回云端,供全局监控
数据同步策略:
- 全量同步:所有数据都同步到云端,适合关键数据
- 增量同步:只同步变化的数据,减少带宽消耗
- 过滤同步:根据规则过滤数据,只同步需要的数据
- 延迟同步:在网络条件好时再同步,适应不稳定网络
边缘自治:当边缘节点与云端断开连接时,EdgeCore可以基于本地缓存继续运行应用,保证业务连续性。连接恢复后,自动同步状态和配置变更。
# 边缘应用配置示例
apiVersion: apps/v1
kind: Deployment
metadata:
name: edge-collector
namespace: edge-apps
spec:
replicas: 1
selector:
matchLabels:
app: edge-collector
template:
meta
labels:
app: edge-collector
# 指定为边缘应用
edge.kurator.dev/app: "true"
spec:
nodeSelector:
edge.kurator.dev/node: "true"
tolerations:
- key: edge
operator: Equal
value: "true"
effect: NoSchedule
containers:
- name: collector
image: edge-collector:v1.0
resources:
limits:
cpu: 500m
memory: 256Mi
requests:
cpu: 100m
memory: 128Mi
volumeMounts:
- name: data-volume
mountPath: /data
env:
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
volumes:
- name: data-volume
hostPath:
path: /var/lib/edge-data
7.3 边缘节点管理与监控
Kurator提供了完整的边缘节点管理与监控能力,帮助运维人员管理大规模边缘基础设施。
节点生命周期管理:
- 自动注册:边缘节点启动时自动向云端注册
- 状态监控:实时监控节点在线状态、资源使用情况
- 远程维护:支持远程重启、升级、配置更新
- 故障自愈:当节点异常时,自动迁移应用到其他节点
监控指标:
- 基础设施指标:CPU、内存、磁盘、网络
- 边缘应用指标:应用健康状态、性能指标
- 设备指标:传感器数据、设备状态
- 网络指标:连接质量、同步延迟、带宽使用
告警策略:
- 离线告警:当边缘节点长时间离线时告警
- 资源告警:当CPU、内存、磁盘使用率过高时告警
- 应用告警:当边缘应用异常时告警
- 设备告警:当设备状态异常时告警
# 边缘监控配置示例
apiVersion: monitoring.kurator.dev/v1alpha1
kind: EdgeMonitor
metadata:
name: factory-floor-monitor
spec:
selector:
location: factory-floor
metrics:
- name: cpu_usage
interval: 30s
threshold:
warning: 80
critical: 90
- name: memory_usage
interval: 30s
threshold:
warning: 85
critical: 95
- name: device_temperature
interval: 60s
threshold:
warning: 70
critical: 85
alerts:
- name: edge-node-offline
condition: status == "Offline"
duration: 5m
severity: critical
message: "Edge node {{.node}} is offline for more than 5 minutes"
- name: high-temperature
condition: device_temperature > 80
duration: 2m
severity: warning
message: "Device temperature is high on node {{.node}}"
通过Kurator的边缘管理能力,企业可以构建大规模、可靠的边缘计算基础设施,支持智能制造、智慧城市、车联网等场景。
八、Volcano批处理调度优化
8.1 Volcano调度架构与优势
Volcano是Kurator集成的批处理调度器,专为AI/ML、大数据、HPC等计算密集型工作负载优化。与Kubernetes默认调度器相比,Volcano在以下方面具有显著优势:
Gang调度:确保一组Pod要么全部调度成功,要么全部失败,避免部分调度导致的资源浪费和死锁。这对分布式训练任务(如TensorFlow、PyTorch)至关重要。
队列管理:提供多队列支持,不同队列可以有不同的优先级、资源配额和调度策略,满足多租户场景的需求。
高级调度策略:支持Binpack(紧凑调度)、Spread(分散调度)、Topology(拓扑感知)等多种调度策略,优化资源利用率和性能。
抢占与回收:当高优先级任务需要资源时,可以抢占低优先级任务的资源,并在任务完成后回收资源,提高集群资源利用率。
亲和性与反亲和性:支持复杂的Pod间亲和性和反亲和性规则,优化任务性能(如数据本地性)。
Kurator对Volcano进行了深度集成,提供了统一的API和管理界面。用户可以通过简单的配置使用Volcano的高级调度能力,而无需深入了解底层细节。
# Volcano Queue配置示例
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
meta
name: high-priority
spec:
weight: 10
reclaimable: true
capability:
cpu: "100"
memory: 200Gi
nvidia.com/gpu: "20"
# 队列访问控制
permission:
- namespace: ai-team
action: "*"
- namespace: data-team
action: "read"
8.2 Job、Queue与PodGroup管理
Volcano引入了几个核心概念来优化批处理工作负载:Job、Queue和PodGroup。
VolcanoJob:扩展了Kubernetes Job,支持更复杂的任务依赖、生命周期管理和错误处理。一个VolcanoJob可以包含多个Task,每个Task定义了Pod模板和副本数。
Queue:资源池,用于隔离不同团队或任务类型的资源。队列可以设置资源配额、权重和调度策略,实现多租户资源管理。
PodGroup:一组需要同时调度的Pod,用于实现Gang调度。PodGroup定义了最小可用Pod数、调度超时等参数。
Kurator提供了这些资源的统一管理界面,并与Karmada集成,支持跨集群的批处理任务调度。
# 复杂的VolcanoJob示例
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
meta
name: distributed-training
spec:
minAvailable: 8
schedulerName: volcano
queue: ai-training
plugins:
ssh: []
env: []
svc: []
tasks:
- replicas: 1
name: master
policies:
- event: TaskCompleted
action: CompleteJob
template:
spec:
containers:
- image: tensorflow/tf-operator:master
name: tensorflow
command: ["python", "/opt/train.py", "--role=master"]
resources:
limits:
nvidia.com/gpu: 1
nodeSelector:
node-type: gpu-node
- replicas: 7
name: worker
template:
spec:
containers:
- image: tensorflow/tf-operator:master
name: tensorflow
command: ["python", "/opt/train.py", "--role=worker"]
resources:
limits:
nvidia.com/gpu: 1
nodeSelector:
node-type: gpu-node
在这个示例中,一个分布式训练任务包含1个master和7个worker,总共8个GPU Pod。Volcano会确保这8个Pod要么全部调度成功,要么全部失败,避免了部分调度导致的资源浪费。
8.3 AI/ML工作负载优化实践
Kurator结合Volcano,为AI/ML工作负载提供了端到端的优化方案,从数据准备到模型训练和推理。
数据本地性优化:通过拓扑感知调度,将计算任务调度到数据所在的节点,减少数据传输开销。Volcano支持多种存储系统(如HDFS、Ceph、S3)的数据本地性感知。
GPU共享与隔离:支持GPU时间片共享和显存隔离,提高GPU资源利用率。Kurator集成了NVIDIA GPU Operator,提供完整的GPU管理能力。
弹性训练:支持训练任务的动态扩缩容,根据训练进度和资源情况调整worker数量。Kurator的MultiClusterHPA可以跨集群扩展训练任务。
模型版本管理:集成MLflow等模型管理工具,支持模型版本控制、实验跟踪和模型部署。
推理服务优化:通过Istio和Knative,提供自动扩缩容、蓝绿部署、金丝雀发布等推理服务管理能力。
# AI训练任务优化示例
# train.py
import tensorflow as tf
from tensorflow.distribute import MultiWorkerMirroredStrategy
# 自动检测集群配置
strategy = MultiWorkerMirroredStrategy()
# 数据加载优化
def load_data():
# 使用TFRecord格式,提高I/O性能
dataset = tf.data.TFRecordDataset(filenames, num_parallel_reads=tf.data.AUTOTUNE)
dataset = dataset.map(parse_fn, num_parallel_calls=tf.data.AUTOTUNE)
dataset = dataset.batch(batch_size)
dataset = dataset.prefetch(tf.data.AUTOTUNE) # 预取数据
return dataset
# 模型定义
with strategy.scope():
model = tf.keras.Sequential([...])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy')
# 训练
dataset = load_data()
model.fit(dataset, epochs=10, callbacks=[
# 集成MLflow,跟踪实验
tf.keras.callbacks.TensorBoard(log_dir='/logs'),
tf.keras.callbacks.ModelCheckpoint('/models/checkpoint')
])
# 保存模型
model.save('/models/final')
Kurator通过统一的平台,将AI/ML的整个生命周期(数据准备、训练、部署、监控)集成在一起,大大简化了AI工作负载的管理复杂度。企业可以专注于业务创新,而无需担心基础设施的复杂性。
总结与展望
Kurator作为开源分布式云原生平台,通过集成和增强现有优秀云原生项目,为用户提供了统一的多云多集群管理能力。本文从架构解析到实践应用,详细探讨了Kurator的核心功能和技术优势。
核心价值总结:
- 统一管理:通过Fleet抽象,统一管理多云、混合云、边缘节点等异构环境
- 开箱即用:一键安装集成的云原生软件栈,降低使用门槛
- GitOps驱动:基于FluxCD的声明式配置管理,确保环境一致性
- 智能调度:结合Karmada和Volcano,提供跨集群和批处理优化的调度能力
- 边缘友好:深度集成KubeEdge,支持边缘计算场景
- 可观测性:统一的监控、告警、追踪能力,提升运维效率
未来发展方向:
- AI驱动的自治系统:通过AI/ML技术实现自动扩缩容、异常检测、根因分析
- 多云成本优化:智能选择最优云提供商和区域,降低总体拥有成本
- 增强安全能力:零信任架构、机密计算、合规自动化
- 开发者体验优化:简化本地开发、调试、测试流程
- 生态扩展:集成更多云原生项目,支持更广泛的场景
Kurator作为云原生技术的重要实践者,将持续推动分布式云原生技术的发展,为企业数字化转型提供强大支撑。通过开放、协作的社区模式,Kurator将与全球开发者共同构建下一代云原生基础设施。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)